`grab-sampler` is an efficient PyTorch-based sampler that supports GraB-style
example ordering by Online Gradient Balancing.
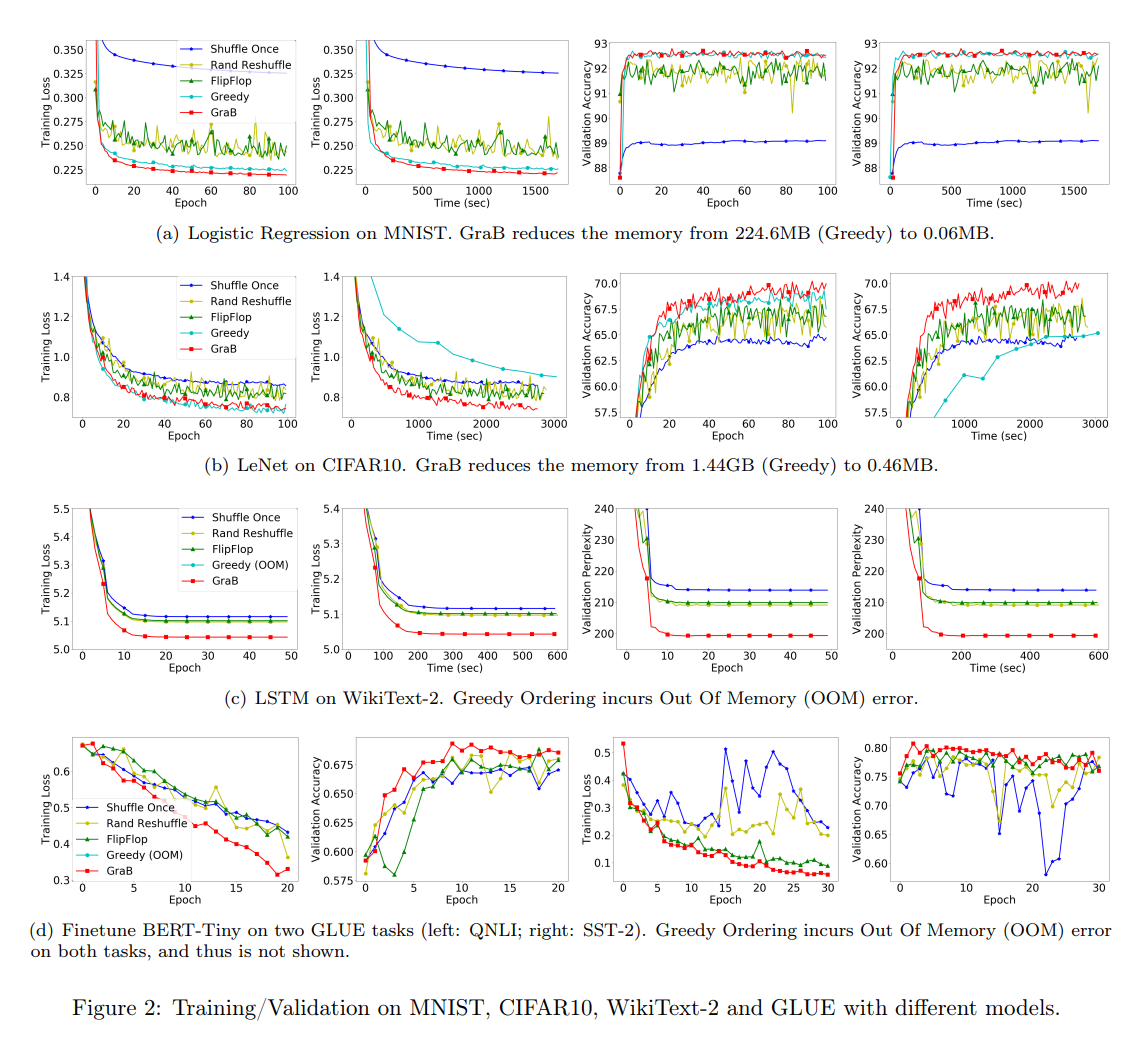
GraB algorithm takes O(d) extra memory and O(1) extra time compared with Random
Reshuffling.
Proposed in the
paper [GraB: Finding Provably Better Data Permutations than Random Reshuffling](https://arxiv.org/abs/2205.10733),
GraB (Gradient Balancing) is a data permutation algorithm that greedily choose
data orderings depending on per-sample gradients to further speed up
convergence of neural network training empirically.
Recent paper [Tighter Lower Bounds for Shuffling SGD: Random Permutations and Beyond
](https://arxiv.org/abs/2303.07160) shows that GraB provably achieves optimal
convergence
rate among arbitrary data permutations on SGD.
Observation shows that not only does GraB allow fast minimization of the
empirical risk, but also lets the model generalize better on multiple deep
learning tasks.
# Supported GraB Algorithms
- Mean Balance (Vanilla GraB, default)
- Pair Balance
- Recursive Balance
- Recursive Pair Balance
- Random Reshuffling (RR)
- Various experimental balance algorithms that doesn't provably outperform Mean Balance
In terms of balancing, all of the above algorithm supports
- Deterministic Balancing (default)
- Probabilistic Balancing
# Per-sample gradients, PyTorch 2, and Functional programming
GraB algorithm requires per-sample gradients while solving the *herding*
problem.
In general, it's hard to implement it in the vanilla PyTorch Automatic
Differentiation (AD) framework because the C++ kernel average the per-sample
gradients within a batch before it is passed to the next layer.
PyTorch 2 integrates Functorch that supports [efficient computation of
Per-sample Gradients](https://pytorch.org/tutorials/intermediate/per_sample_grads.html).
Alas, it requires
a [Functional programming](https://en.wikipedia.org/wiki/Functional_programming) style
of coding and requires the model to be pure functions, disallowing layers
including randomness (Dropout) or storing inter-batch statistics (BathNorm).
# Example Usage
To train a PyTorch model in a functional programming style using per-sample
gradients, one is likely to write a script like
```python
import torch
import torchopt
from torch.func import (
grad, grad_and_value, vmap, functional_call
)
from functools import partial
from grabsampler import GraBSampler
# Initiate model, loss function, and dataset
model = ...
loss_fn = ...
dataset = ...
# Transform model into functional programming
# https://pytorch.org/docs/master/func.migrating.html#functorch-make-functional
# https://pytorch.org/docs/stable/generated/torch.func.functional_call.html
params = dict(model.named_parameters())
buffers = dict(model.named_buffers())
# initiate optimizer, using torchopt package
optimizer = torchopt.sgd(...)
opt_state = optimizer.init(params) # init optimizer
###############################################################################
# Initiate GraB sampler and dataloader
sampler = GraBSampler(dataset, params) # <- add this init of GraB sampler
dataloader = torch.utils.data.DataLoader(dataset, sampler=sampler)
###############################################################################
# pure function
def compute_loss(model, loss_fn, params, buffers, inputs, targets):
prediction = functional_call(model, (params, buffers), (inputs,))
return loss_fn(prediction, targets)
# Compute per sample gradients and loss
ft_compute_sample_grad_and_loss = vmap(
grad_and_value(partial(compute_loss, model, loss_fn)),
in_dims=(None, None, 0, 0)
) # the only argument of compute_loss is batched along the first axis
for epoch in range(...):
for _, (x, y) in enumerate(dataloader):
ft_per_sample_grads, batch_loss = ft_compute_sample_grad_and_loss(
params, buffers, x, y
)
#######################################################################
sampler.step(ft_per_sample_grads) # <- step compute GraB algorithm
#######################################################################
# The following is equivalent to
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
grads = {k: g.mean(dim=0) for k, g in ft_per_sample_grads.items()}
updates, opt_state = optimizer.update(
grads, opt_state, params=params
) # get updates
params = torchopt.apply_updates(
params, updates
) # update model parameters
```
# Experiment Training Scripts
* [Image Classification](https://github.com/garywei944/grab_exp/blob/main/experiments/cv/cv.py) (
CIFAR-10, MNIST, etc)
* [Causal Language Modeling](https://github.com/garywei944/grab_exp/blob/main/experiments/nlp/clm/clm.py) (
Wikitext-103, OpenWebText, etc)
# How does `grab-sampler` work?
The reordering of data permutation happens at the beginning of each training
epoch, whenever an iterator of the dataloader is created,
e.g. `for _ in enumerate(dataloader):` internally calls `__iter__()` of the
`sampler` and updates the data ordering.
Raw data
{
"_id": null,
"home_page": "",
"name": "grab-sampler",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.10",
"maintainer_email": "",
"keywords": "GraB,data-permutation,PyTorch,dataloader,sampler",
"author": "",
"author_email": "garywei944 <garywei944@gmail.com>",
"download_url": "https://files.pythonhosted.org/packages/be/c0/dee2d2f21003b9fc0b09b0964f970c146fa9dc2491707494ca9156a73130/grab-sampler-0.1.3.tar.gz",
"platform": null,
"description": "`grab-sampler` is an efficient PyTorch-based sampler that supports GraB-style\nexample ordering by Online Gradient Balancing.\nGraB algorithm takes O(d) extra memory and O(1) extra time compared with Random\nReshuffling.\n\nProposed in the\npaper [GraB: Finding Provably Better Data Permutations than Random Reshuffling](https://arxiv.org/abs/2205.10733),\nGraB (Gradient Balancing) is a data permutation algorithm that greedily choose\ndata orderings depending on per-sample gradients to further speed up\nconvergence of neural network training empirically.\nRecent paper [Tighter Lower Bounds for Shuffling SGD: Random Permutations and Beyond\n](https://arxiv.org/abs/2303.07160) shows that GraB provably achieves optimal\nconvergence\nrate among arbitrary data permutations on SGD.\nObservation shows that not only does GraB allow fast minimization of the\nempirical risk, but also lets the model generalize better on multiple deep\nlearning tasks.\n\n\n\n# Supported GraB Algorithms\n\n- Mean Balance (Vanilla GraB, default)\n- Pair Balance\n- Recursive Balance\n- Recursive Pair Balance\n- Random Reshuffling (RR)\n- Various experimental balance algorithms that doesn't provably outperform Mean Balance\n\nIn terms of balancing, all of the above algorithm supports\n\n- Deterministic Balancing (default)\n- Probabilistic Balancing\n\n# Per-sample gradients, PyTorch 2, and Functional programming\n\nGraB algorithm requires per-sample gradients while solving the *herding*\nproblem.\nIn general, it's hard to implement it in the vanilla PyTorch Automatic\nDifferentiation (AD) framework because the C++ kernel average the per-sample\ngradients within a batch before it is passed to the next layer.\n\nPyTorch 2 integrates Functorch that supports [efficient computation of\nPer-sample Gradients](https://pytorch.org/tutorials/intermediate/per_sample_grads.html).\nAlas, it requires\na [Functional programming](https://en.wikipedia.org/wiki/Functional_programming) style\nof coding and requires the model to be pure functions, disallowing layers\nincluding randomness (Dropout) or storing inter-batch statistics (BathNorm).\n\n# Example Usage\n\nTo train a PyTorch model in a functional programming style using per-sample\ngradients, one is likely to write a script like\n\n```python\nimport torch\nimport torchopt\nfrom torch.func import (\n grad, grad_and_value, vmap, functional_call\n)\nfrom functools import partial\n\nfrom grabsampler import GraBSampler\n\n# Initiate model, loss function, and dataset\nmodel = ...\nloss_fn = ...\ndataset = ...\n\n# Transform model into functional programming\n# https://pytorch.org/docs/master/func.migrating.html#functorch-make-functional\n# https://pytorch.org/docs/stable/generated/torch.func.functional_call.html\nparams = dict(model.named_parameters())\nbuffers = dict(model.named_buffers())\n\n# initiate optimizer, using torchopt package\noptimizer = torchopt.sgd(...)\nopt_state = optimizer.init(params) # init optimizer\n\n###############################################################################\n# Initiate GraB sampler and dataloader\nsampler = GraBSampler(dataset, params) # <- add this init of GraB sampler\ndataloader = torch.utils.data.DataLoader(dataset, sampler=sampler)\n\n\n###############################################################################\n\n\n# pure function\ndef compute_loss(model, loss_fn, params, buffers, inputs, targets):\n prediction = functional_call(model, (params, buffers), (inputs,))\n\n return loss_fn(prediction, targets)\n\n\n# Compute per sample gradients and loss\nft_compute_sample_grad_and_loss = vmap(\n grad_and_value(partial(compute_loss, model, loss_fn)),\n in_dims=(None, None, 0, 0)\n) # the only argument of compute_loss is batched along the first axis\n\nfor epoch in range(...):\n for _, (x, y) in enumerate(dataloader):\n ft_per_sample_grads, batch_loss = ft_compute_sample_grad_and_loss(\n params, buffers, x, y\n )\n\n #######################################################################\n sampler.step(ft_per_sample_grads) # <- step compute GraB algorithm\n #######################################################################\n\n # The following is equivalent to\n # optimizer.zero_grad()\n # loss.backward()\n # optimizer.step()\n grads = {k: g.mean(dim=0) for k, g in ft_per_sample_grads.items()}\n updates, opt_state = optimizer.update(\n grads, opt_state, params=params\n ) # get updates\n params = torchopt.apply_updates(\n params, updates\n ) # update model parameters\n```\n\n# Experiment Training Scripts\n\n* [Image Classification](https://github.com/garywei944/grab_exp/blob/main/experiments/cv/cv.py) (\n CIFAR-10, MNIST, etc)\n* [Causal Language Modeling](https://github.com/garywei944/grab_exp/blob/main/experiments/nlp/clm/clm.py) (\n Wikitext-103, OpenWebText, etc)\n\n# How does `grab-sampler` work?\n\nThe reordering of data permutation happens at the beginning of each training\nepoch, whenever an iterator of the dataloader is created,\ne.g. `for _ in enumerate(dataloader):` internally calls `__iter__()` of the\n`sampler` and updates the data ordering.\n",
"bugtrack_url": null,
"license": "Apache Software License 2.0",
"summary": "Optimal Permutation-based SGD Data Sampler for PyTorch",
"version": "0.1.3",
"project_urls": {
"BugTracker": "https://github.com/garywei944/grab-sampler/issues",
"Repository": "https://github.com/garywei944/grab-sampler"
},
"split_keywords": [
"grab",
"data-permutation",
"pytorch",
"dataloader",
"sampler"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "5dd998bc9a402aa701e814b6896e8d3d5655d826126495a94adfaa255673dcfe",
"md5": "84713a2f7b702f1e262723fe39de2638",
"sha256": "b1184f41a91f1d23710c384f514db810dd7621dd1120ee808720bd16ff3dee69"
},
"downloads": -1,
"filename": "grab_sampler-0.1.3-py2.py3-none-any.whl",
"has_sig": false,
"md5_digest": "84713a2f7b702f1e262723fe39de2638",
"packagetype": "bdist_wheel",
"python_version": "py2.py3",
"requires_python": ">=3.10",
"size": 39539,
"upload_time": "2023-09-12T06:57:22",
"upload_time_iso_8601": "2023-09-12T06:57:22.128253Z",
"url": "https://files.pythonhosted.org/packages/5d/d9/98bc9a402aa701e814b6896e8d3d5655d826126495a94adfaa255673dcfe/grab_sampler-0.1.3-py2.py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "bec0dee2d2f21003b9fc0b09b0964f970c146fa9dc2491707494ca9156a73130",
"md5": "ee7959a5ba6d6e5b6498798add88d90f",
"sha256": "bdf98f39d16744f029982b969828a3f9ed3e475dbde79155c7b181d7639650ea"
},
"downloads": -1,
"filename": "grab-sampler-0.1.3.tar.gz",
"has_sig": false,
"md5_digest": "ee7959a5ba6d6e5b6498798add88d90f",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.10",
"size": 23581,
"upload_time": "2023-09-12T06:57:24",
"upload_time_iso_8601": "2023-09-12T06:57:24.032761Z",
"url": "https://files.pythonhosted.org/packages/be/c0/dee2d2f21003b9fc0b09b0964f970c146fa9dc2491707494ca9156a73130/grab-sampler-0.1.3.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-09-12 06:57:24",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "garywei944",
"github_project": "grab-sampler",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "grab-sampler"
}

