<p align="center">
<a href="https://dev101.swanlab.cn">SwanLab在线版</a> · <a href="https://docs.dev101.swanlab.cn">文档</a> · <a href="https://geektechstudio.feishu.cn/wiki/NIZ9wp5LRiSqQykizbGcVzUKnic">微信</a> · <a href="https://github.com/swanhubx/swanlab/issues">报告问题</a> · <a href="https://geektechstudio.feishu.cn/share/base/form/shrcnyBlK8OMD0eweoFcc2SvWKc">建议反馈</a> · <a href="https://github.com/SwanHubX/SwanLab/blob/README-v0.3.0/CHANGELOG.md">更新日志</a>
</p>
<p align="center">
<a href="https://github.com/SwanHubX/SwanLab/blob/main/LICENSE"><img src="https://img.shields.io/github/license/SwanHubX/SwanLab.svg?color=brightgreen" alt="license"></a>
<a href="https://github.com/SwanHubX/SwanLab/commits/main"><img src="https://img.shields.io/github/last-commit/SwanHubX/SwanLab" alt="license"></a>
<a href="https://pypi.python.org/pypi/swanlab"><img src="https://img.shields.io/pypi/v/swanlab?color=orange" alt= /></a>
<a href="https://pepy.tech/project/swanlab"><img alt="pypi Download" src="https://static.pepy.tech/badge/swanlab"></a>
<a href="https://github.com/swanhubx/swanlab/issues"><img alt="issues" src="https://img.shields.io/github/issues/swanhubx/swanlab"></a>
<br>
<a href="https://dev101.swanlab.cn" target="_blank">
<img alt="Static Badge" src="https://img.shields.io/badge/Product-SwanLab云端版-636a3f"></a>
<a href="https://geektechstudio.feishu.cn/wiki/NIZ9wp5LRiSqQykizbGcVzUKnic" target="_blank">
<img alt="Static Badge" src="https://img.shields.io/badge/WeChat-微信-4cb55e"></a>
<a href="https://www.xiaohongshu.com/user/profile/605786b90000000001003a81" target="_blank">
<img alt="Static Badge" src="https://img.shields.io/badge/小红书-F04438"></a>
</p>
<div align="center">
<a href="https://github.com/SwanHubX/SwanLab/blob/main/README_en.md"><img alt="英文文档" src="https://img.shields.io/badge/English-d9d9d9"></a>
<a href="https://github.com/SwanHubX/SwanLab/blob/main/README.md"><img alt="中文文档" src="https://img.shields.io/badge/简体中文-d9d9d9"></a>
</div>
<details>
<summary>目录树</summary>
#### TOC
- [👋🏻 什么是SwanLab](#-什么是swanlab)
- [🏁 快速开始](#-快速开始)
- [1.安装](#1安装)
- [2.登录并获取API Key](#2登录并获取api-key)
- [3.将SwanLab与你的代码集成](#3将SwanLab与你的代码集成)
- [📃 更多案例](#-更多案例)
- [💻 自托管](#-自托管)
- [离线实验跟踪](#离线实验跟踪)
- [开启离线看板](#开启离线看板)
- [🚗 框架集成](#-框架集成)
- [🆚 与熟悉的工具的比较](#-与熟悉的工具的比较)
- [Tensorboard vs SwanLab](#tensorboard-vs-swanlab)
- [W&B vs SwanLab](#weights-and-biases-vs-swanlab)
- [🛣️ Roadmap](#%EF%B8%8F-roadmap)
- [两周内即将上线](#两周内即将上线)
- [三个月内规划上线](#三个月内规划上线)
- [长期关注](#长期关注)
- [👥 社区](#-社区)
- [社区与支持](#社区与支持)
- [SwanLab README徽章](#swanlab-readme徽章)
- [在论文中引用SwanLab](#在论文中引用swanlab)
- [为SwanLab做出贡献](#为swanlab做出贡献)
- [下载Icon](#下载icon)
- [📃 协议](#-协议)
<br/>
</details>
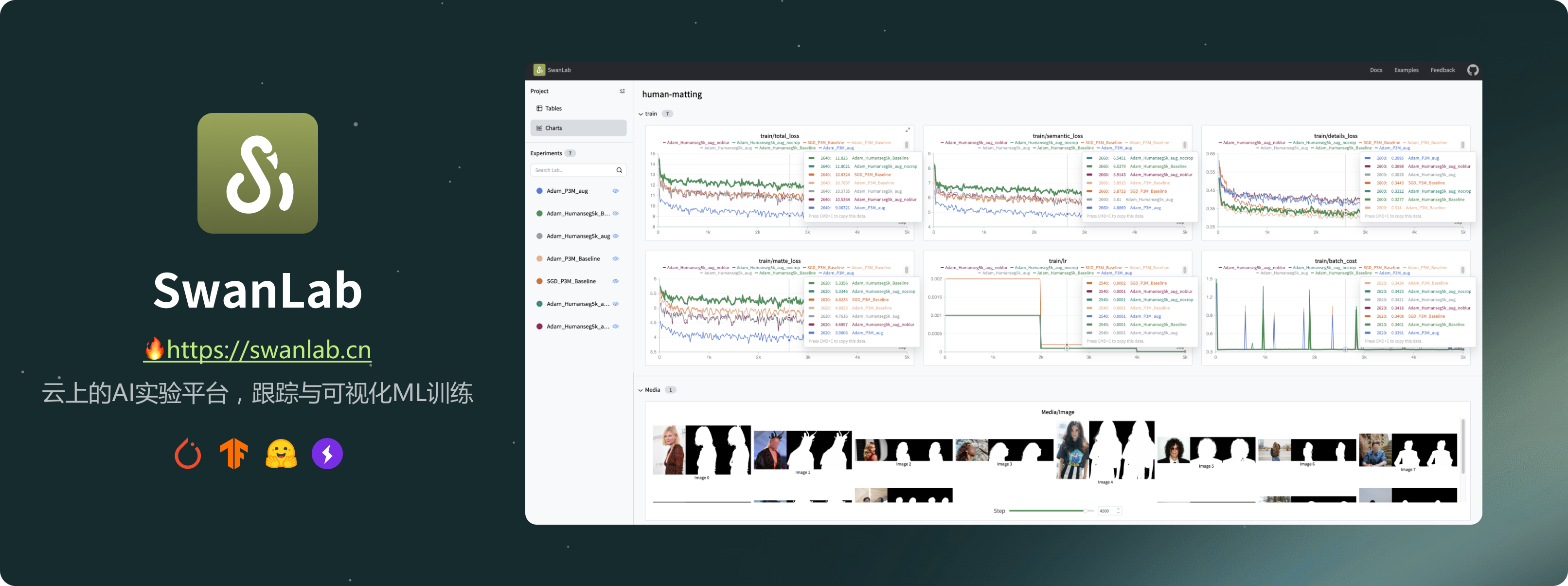
## 👋🏻 什么是SwanLab
SwanLab is an open-source, lightweight AI experiment tracking tool that provides a platform for tracking, comparing, and
collaborating on experiments, aiming to accelerate the research and development efficiency of AI teams by 100 times.
SwanLab是一款开源、轻量级的AI实验跟踪工具,提供了一个跟踪、比较、和协作实验的平台,旨在加速AI研发团队100倍的研发效率。
其提供了友好的API和漂亮的界面,结合了超参数跟踪、指标记录、在线协作、实验链接分享、实时消息通知等功能,让您可以快速跟踪ML实验、可视化过程、分享给同伴。
借助SwanLab,科研人员可以沉淀自己的每一次训练经验,与合作者无缝地交流和协作,机器学习工程师可以更快地开发可用于生产的模型。

以下是其核心特性列表:
**1. 📊实验指标与超参数跟踪**: 极简的代码嵌入您的机器学习pipeline,跟踪记录训练关键指标
- 自由的超参数与实验配置记录
- 支持的元数据类型:标量指标、图像、音频、文本、...
- 支持的图表类型:折线图、媒体图(图像、音频、文本)、...
- 自动记录:控制台logging、GPU硬件、Git信息、Python解释器、Python库列表、代码目录
**2. ⚡️全面的框架集成**: PyTorch、Tensorflow、PyTorch Lightning、🤗HuggingFace
Transformers、MMEngine、OpenAI、ZhipuAI、Hydra、...
**3. 📦组织实验**: 集中式仪表板,快速管理多个项目与实验,通过整体视图速览训练全局
**4. 🆚比较结果**: 通过在线表格与对比图表比较不同实验的超参数和结果,挖掘迭代灵感
**5. 👥在线协作**: 您可以与团队进行协作式训练,支持将实验实时同步在一个项目下,您可以在线查看团队的训练记录,基于结果发表看法与建议
**6. ✉️分享结果**: 复制和发送持久的URL来共享每个实验,方便地发送给伙伴,或嵌入到在线笔记中
**7. 💻支持自托管**: 支持不联网使用,自托管的社区版同样可以查看仪表盘与管理实验
> \[!IMPORTANT]
>
> **收藏项目**,你将从 GitHub 上无延迟地接收所有发布通知~⭐️

<br>
## 🏁 快速开始
### 1.安装
```bash
pip install swanlab
```
### 2.登录并获取API Key
1. 免费[注册账号](https://dev101.swanlab.cn)
2. 登录账号,在用户设置 > [API Key](https://dev101.swanlab.cn/settings) 里复制您的API Key
3. 打开终端,输入:
```bash
swanlab login
```
出现提示时,输入您的API Key,按下回车,完成登陆。
### 3.将SwanLab与你的代码集成
```python
import swanlab
# 初始化一个新的swanlab实验
swanlab.init(
project="my-first-ml",
config={'learning-rate': 0.003}
)
# 记录指标
for i in range(10):
swanlab.log({"loss": i})
```
大功告成!前往[SwanLab](https://dev101.swanlab.cn)查看你的第一个SwanLab实验。
<br>
## 📃 更多案例
<details>
<summary>MNIST</summary>
```python
import os
import torch
from torch import nn, optim, utils
import torch.nn.functional as F
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import swanlab
# CNN网络构建
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1 = nn.Conv2d(1, 10, 5) # 10, 24x24
self.conv2 = nn.Conv2d(10, 20, 3) # 128, 10x10
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 12
out = self.conv2(out) # 10
out = F.relu(out)
out = out.view(in_size, -1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out, dim=1)
return out
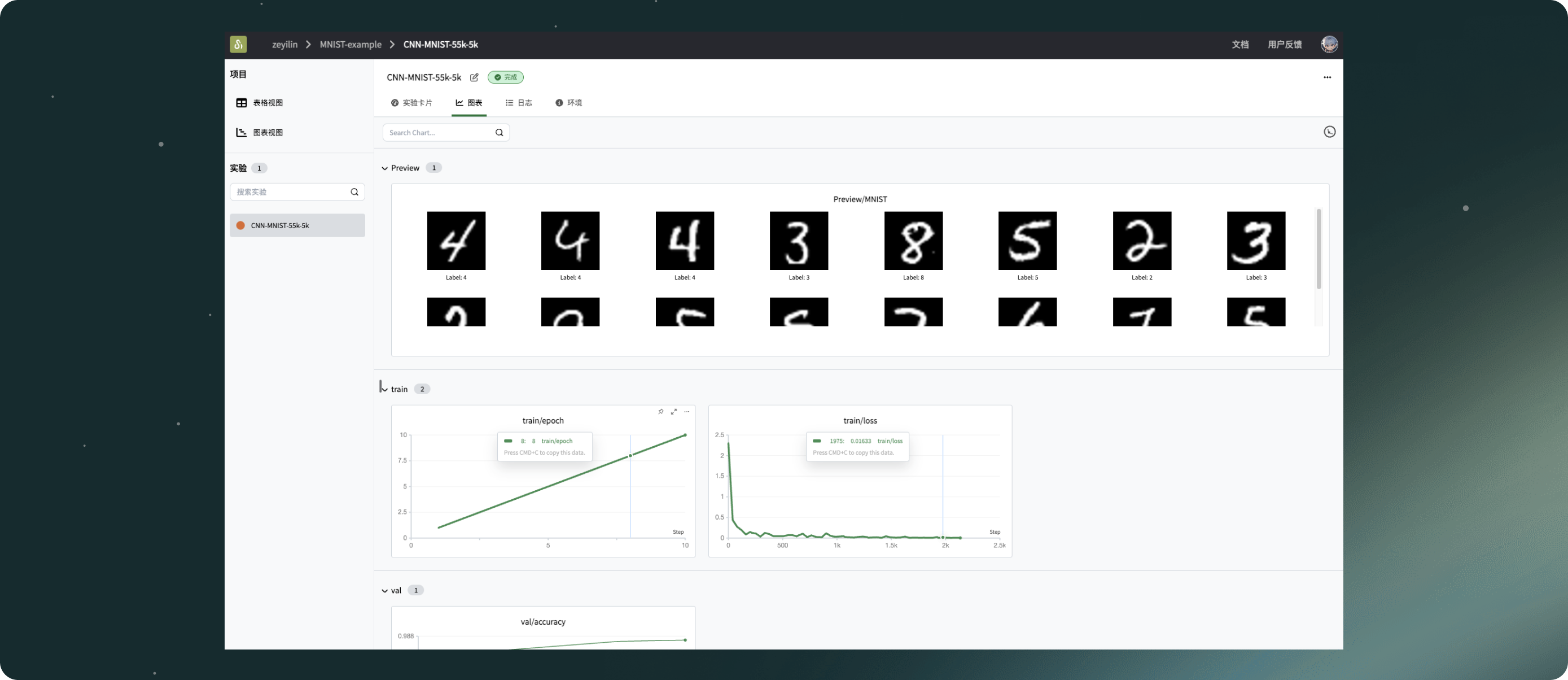
# 捕获并可视化前20张图像
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
# images: batch of images, labels: batch of labels
for i in range(images.shape[0]):
if images_logged < num_images:
# 使用swanlab.Image将图像转换为wandb可视化格式
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}"))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"MNIST-Preview": logged_images})
if __name__ == "__main__":
# 初始化swanlab
run = swanlab.init(
project="MNIST-example",
experiment_name="ConvNet",
description="Train ConvNet on MNIST dataset.",
config={
"model": "CNN",
"optim": "Adam",
"lr": 0.001,
"batch_size": 512,
"num_epochs": 10,
"train_dataset_num": 55000,
"val_dataset_num": 5000,
},
)
# 设置训练机、验证集和测试集
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(
dataset, [run.config.train_dataset_num, run.config.val_dataset_num]
)
train_loader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_loader = utils.data.DataLoader(val_dataset, batch_size=1, shuffle=False)
# 初始化模型、损失函数和优化器
model = ConvNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=run.config.lr)
# (可选)看一下数据集的前16张图像
log_images(train_loader, 16)
# 开始训练
for epoch in range(1, run.config.num_epochs):
swanlab.log({"train/epoch": epoch})
# 训练循环
for iter, batch in enumerate(train_loader):
x, y = batch
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
print(
f"Epoch [{epoch}/{run.config.num_epochs}], Iteration [{iter + 1}/{len(train_loader)}], Loss: {loss.item()}"
)
if iter % 20 == 0:
swanlab.log({"train/loss": loss.item()}, step=(epoch - 1) * len(train_loader) + iter)
# 每4个epoch验证一次
if epoch % 2 == 0:
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in val_loader:
x, y = batch
output = model(x)
_, predicted = torch.max(output, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
accuracy = correct / total
swanlab.log({"val/accuracy": accuracy})
```
</details>
<details>
<summary>FashionMNSIT-ResNet34</summary>
```python
import os
import torch
from torch import nn, optim, utils
import torch.nn.functional as F
from torchvision.datasets import FashionMNIST
from torchvision.transforms import ToTensor
import swanlab
# ResNet网络构建
class Basicblock(nn.Module):
def __init__(self, in_planes, planes, stride=1):
super(Basicblock, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=planes, out_channels=planes, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(planes),
)
if stride != 1 or in_planes != planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(planes)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes):
super(ResNet, self).__init__()
self.in_planes = 16
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16),
nn.ReLU()
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.block1 = self._make_layer(block, 16, num_block[0], stride=1)
self.block2 = self._make_layer(block, 32, num_block[1], stride=2)
self.block3 = self._make_layer(block, 64, num_block[2], stride=2)
# self.block4 = self._make_layer(block, 512, num_block[3], stride=2)
self.outlayer = nn.Linear(64, num_classes)
def _make_layer(self, block, planes, num_block, stride):
layers = []
for i in range(num_block):
if i == 0:
layers.append(block(self.in_planes, planes, stride))
else:
layers.append(block(planes, planes, 1))
self.in_planes = planes
return nn.Sequential(*layers)
def forward(self, x):
x = self.maxpool(self.conv1(x))
x = self.block1(x) # [200, 64, 28, 28]
x = self.block2(x) # [200, 128, 14, 14]
x = self.block3(x) # [200, 256, 7, 7]
# out = self.block4(out)
x = F.avg_pool2d(x, 7) # [200, 256, 1, 1]
x = x.view(x.size(0), -1) # [200,256]
out = self.outlayer(x)
return out
# 捕获并可视化前20张图像
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
# images: batch of images, labels: batch of labels
for i in range(images.shape[0]):
if images_logged < num_images:
# 使用swanlab.Image将图像转换为wandb可视化格式
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}", size=(128, 128)))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"Preview/MNIST": logged_images})
if __name__ == "__main__":
# 设置device
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化swanlab
run = swanlab.init(
project="FashionMNIST",
workspace="SwanLab",
experiment_name="Resnet18-Adam",
config={
"model": "Resnet34",
"optim": "Adam",
"lr": 0.001,
"batch_size": 32,
"num_epochs": 10,
"train_dataset_num": 55000,
"val_dataset_num": 5000,
"device": device,
"num_classes": 10,
},
)
# 设置训练机、验证集和测试集
dataset = FashionMNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(
dataset, [run.config.train_dataset_num, run.config.val_dataset_num]
)
train_loader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_loader = utils.data.DataLoader(val_dataset, batch_size=1, shuffle=False)
# 初始化模型、损失函数和优化器
if run.config.model == "Resnet18":
model = ResNet(Basicblock, [1, 1, 1, 1], 10)
elif run.config.model == "Resnet34":
model = ResNet(Basicblock, [2, 3, 5, 2], 10)
elif run.config.model == "Resnet50":
model = ResNet(Basicblock, [3, 4, 6, 3], 10)
model.to(torch.device(device))
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=run.config.lr)
# (可选)看一下数据集的前16张图像
log_images(train_loader, 16)
# 开始训练
for epoch in range(1, run.config.num_epochs + 1):
swanlab.log({"train/epoch": epoch}, step=epoch)
# 训练循环
for iter, batch in enumerate(train_loader):
x, y = batch
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
if iter % 40 == 0:
print(
f"Epoch [{epoch}/{run.config.num_epochs}], Iteration [{iter + 1}/{len(train_loader)}], Loss: {loss.item()}"
)
swanlab.log({"train/loss": loss.item()}, step=(epoch - 1) * len(train_loader) + iter)
# 每4个epoch验证一次
if epoch % 2 == 0:
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in val_loader:
x, y = batch
x, y = x.to(device), y.to(device)
output = model(x)
_, predicted = torch.max(output, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
accuracy = correct / total
swanlab.log({"val/accuracy": accuracy}, step=epoch)
```
</details>
<br>
## 💻 自托管
自托管社区版支持离线查看SwanLab仪表盘。
### 离线实验跟踪
在swanlab.init中设置`logir`和`cloud`这两个参数,即可离线跟踪实验:
```python
...
swanlab.init(
logdir='./logs',
cloud=False,
)
...
```
- 参数`cloud`设置为`False`,关闭将实验同步到云端
- 参数`logdir`的设置是可选的,它的作用是指定了SwanLab日志文件的保存位置(默认保存在`swanlog`文件夹下)
- 日志文件会在跟踪实验的过程中被创建和更新,离线看板的启动也将基于这些日志文件
其他部分和云端使用完全一致。
### 开启离线看板
打开终端,使用下面的指令,开启一个SwanLab仪表板:
```bash
swanlab watch -l ./logs
```
运行完成后,SwanLab会给你1个本地的URL链接(默认是[http://127.0.0.1:5092](http://127.0.0.1:5092))
访问该链接,就可以在浏览器用离线看板查看实验了。
<br>
## 🚗 框架集成
将您最喜欢的框架与SwanLab结合使用,[更多集成](https://docs.dev101.swanlab.cn/zh/guide_cloud/integration/integration-pytorch-lightning.html)。
<details>
<summary>
<strong>⚡️ PyTorch Lightning</strong>
</summary>
<br>
使用`SwanLabLogger`创建示例,并代入`Trainer`的`logger`参数中,即可实现SwanLab记录训练指标。
```python
from swanlab.integration.pytorch_lightning import SwanLabLogger
import importlib.util
import os
import pytorch_lightning as pl
from torch import nn, optim, utils
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
encoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 3))
decoder = nn.Sequential(nn.Linear(3, 128), nn.ReLU(), nn.Linear(128, 28 * 28))
class LitAutoEncoder(pl.LightningModule):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def training_step(self, batch, batch_idx):
# training_step defines the train loop.
# it is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
# Logging to TensorBoard (if installed) by default
self.log("train_loss", loss)
return loss
def test_step(self, batch, batch_idx):
# test_step defines the test loop.
# it is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
# Logging to TensorBoard (if installed) by default
self.log("test_loss", loss)
return loss
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=1e-3)
return optimizer
# init the autoencoder
autoencoder = LitAutoEncoder(encoder, decoder)
# setup data
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000])
test_dataset = MNIST(os.getcwd(), train=False, download=True, transform=ToTensor())
train_loader = utils.data.DataLoader(train_dataset)
val_loader = utils.data.DataLoader(val_dataset)
test_loader = utils.data.DataLoader(test_dataset)
swanlab_logger = SwanLabLogger(
project="swanlab_example",
experiment_name="example_experiment",
cloud=False,
)
trainer = pl.Trainer(limit_train_batches=100, max_epochs=5, logger=swanlab_logger)
trainer.fit(model=autoencoder, train_dataloaders=train_loader, val_dataloaders=val_loader)
trainer.test(dataloaders=test_loader)
```
</details>
<details>
<summary>
<strong> 🤗HuggingFace Transformers</strong>
</summary>
<br>
使用`SwanLabCallback`创建示例,并代入`Trainer`的`callbacks`参数中,即可实现SwanLab记录训练指标。
```python
import evaluate
import numpy as np
import swanlab
from swanlab.integration.huggingface import SwanLabCallback
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
dataset = load_dataset("yelp_review_full")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
metric = evaluate.load("accuracy")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
training_args = TrainingArguments(
output_dir="test_trainer",
report_to="none",
num_train_epochs=3,
logging_steps=50,
)
swanlab_callback = SwanLabCallback(experiment_name="TransformersTest", cloud=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
callbacks=[swanlab_callback],
)
trainer.train()
```
</details>
<br>
## 🆚 与熟悉的工具的比较
### Tensorboard vs SwanLab
- **☁️支持在线使用**:
通过SwanLab可以方便地将训练实验在云端在线同步与保存,便于远程查看训练进展、管理历史项目、分享实验链接、发送实时消息通知、多端看实验等。而Tensorboard是一个离线的实验跟踪工具。
- **👥多人协作**:
在进行多人、跨团队的机器学习协作时,通过SwanLab可以轻松管理多人的训练项目、分享实验链接、跨空间交流讨论。而Tensorboard主要为个人设计,难以进行多人协作和分享实验。
- **💻持久、集中的仪表板**:
无论你在何处训练模型,无论是在本地计算机上、在实验室集群还是在公有云的GPU实例中,你的结果都会记录到同一个集中式仪表板中。而使用TensorBoard需要花费时间从不同的机器复制和管理
TFEvent文件。
- **💪更强大的表格**:
通过SwanLab表格可以查看、搜索、过滤来自不同实验的结果,可以轻松查看数千个模型版本并找到适合不同任务的最佳性能模型。
TensorBoard 不适用于大型项目。
### Weights and Biases vs SwanLab
- Weights and Biases 是一个必须联网使用的闭源MLOps平台
- SwanLab 不仅支持联网使用,也支持开源、免费、自托管的版本
<br>
## 🛣️ Roadmap
工具在迭代与反馈中进化~,欢迎[提交功能建议](https://geektechstudio.feishu.cn/share/base/form/shrcnyBlK8OMD0eweoFcc2SvWKc)
### 两周内即将上线
- `Table`: 更灵活的多维表格图表,适用于LLM、AIGC、模型评估等场景
- **邮件通知📧**: 训练意外中断、训练完成、自定义情况等场景触达时,发送通知邮件
### 三个月内规划上线
- `Molecule`: 生物化学分子可视化图表
- `Plot`: 自由的图表绘制方式
- `Api`: 通过API访问SwanLab数据
- **系统硬件记录**: 记录GPU、CPU、磁盘、网络等一系列硬件情况
- **代码记录**: 记录训练代码
- **更多集成**: LightGBM、XGBoost、openai、chatglm、mm系列、...)
- ...
### 长期关注
- 最有利于AI团队创新的协同方式
- 最友好的UI交互
- 移动端看实验
<br>
## 👥 社区
### 社区与支持
- [GitHub Issues](https://github.com/SwanHubX/SwanLab/issues):使用SwanLab时遇到的错误和问题
- [电子邮件支持](zeyi.lin@swanhub.co):反馈关于使用SwanLab的问题
- <a href="https://geektechstudio.feishu.cn/wiki/NIZ9wp5LRiSqQykizbGcVzUKnic">微信交流群</a>:交流使用SwanLab的问题、分享最新的AI技术
### SwanLab README徽章
如果你喜欢在工作中使用 SwanLab,请将 SwanLab 徽章添加到你的README中:
[](https://github.com/swanhubx/swanlab)
```
[](https://github.com/swanhubx/swanlab)
```
### 在论文中引用SwanLab
如果您发现 SwanLab 对您的研究之旅有帮助,请考虑以下列格式引用:
```bibtex
@software{Zeyilin_SwanLab_2023,
author = {Zeyi Lin, Shaohong Chen, Kang Li, Qiushan Jiang, Zirui Cai, Kaifang Ji and {The SwanLab team}},
license = {Apache-2.0},
title = {{SwanLab}},
url = {https://github.com/swanhubx/swanlab},
year = {2023}
}
```
### 为SwanLab做出贡献
考虑为SwanLab做出贡献吗?首先,请花点时间阅读 [贡献指南](CONTRIBUTING.md)。
同时,我们非常欢迎通过社交媒体、活动和会议的分享来支持SwanLab,衷心感谢!
### 下载Icon
[SwanLab-Icon-SVG](https://raw.githubusercontent.com/SwanHubX/swanlab/main/readme_files/swanlab-logo.svg)
<br>
**Contributors**
<a href="https://github.com/swanhubx/swanlab/graphs/contributors">
<img src="https://contrib.rocks/image?repo=swanhubx/swanlab" />
</a>
<br>
## 📃 协议
本仓库遵循 [Apache 2.0 License](https://github.com/SwanHubX/SwanLab/blob/main/LICENSE) 开源协议
Raw data
{
"_id": null,
"home_page": null,
"name": "swanlab",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": null,
"keywords": "machine learning, reproducibility, visualization",
"author": null,
"author_email": "Cunyue <team@swanhub.co>, Feudalman <team@swanhub.co>, ZeYi Lin <team@swanhub.co>, KashiwaByte <team@swanhub.co>",
"download_url": "https://files.pythonhosted.org/packages/fe/8b/b590486d4811eb20a5e6bef7f3f4c3dca0df77b6b89edcf04db200e2ea3b/swanlab-0.3.1.tar.gz",
"platform": null,
"description": "\n\n<p align=\"center\">\n<a href=\"https://dev101.swanlab.cn\">SwanLab\u5728\u7ebf\u7248</a> \u00b7 <a href=\"https://docs.dev101.swanlab.cn\">\u6587\u6863</a> \u00b7 <a href=\"https://geektechstudio.feishu.cn/wiki/NIZ9wp5LRiSqQykizbGcVzUKnic\">\u5fae\u4fe1</a> \u00b7 <a href=\"https://github.com/swanhubx/swanlab/issues\">\u62a5\u544a\u95ee\u9898</a> \u00b7 <a href=\"https://geektechstudio.feishu.cn/share/base/form/shrcnyBlK8OMD0eweoFcc2SvWKc\">\u5efa\u8bae\u53cd\u9988</a> \u00b7 <a href=\"https://github.com/SwanHubX/SwanLab/blob/README-v0.3.0/CHANGELOG.md\">\u66f4\u65b0\u65e5\u5fd7</a>\n</p>\n\n<p align=\"center\">\n <a href=\"https://github.com/SwanHubX/SwanLab/blob/main/LICENSE\"><img src=\"https://img.shields.io/github/license/SwanHubX/SwanLab.svg?color=brightgreen\" alt=\"license\"></a>\n <a href=\"https://github.com/SwanHubX/SwanLab/commits/main\"><img src=\"https://img.shields.io/github/last-commit/SwanHubX/SwanLab\" alt=\"license\"></a>\n <a href=\"https://pypi.python.org/pypi/swanlab\"><img src=\"https://img.shields.io/pypi/v/swanlab?color=orange\" alt= /></a>\n <a href=\"https://pepy.tech/project/swanlab\"><img alt=\"pypi Download\" src=\"https://static.pepy.tech/badge/swanlab\"></a>\n <a href=\"https://github.com/swanhubx/swanlab/issues\"><img alt=\"issues\" src=\"https://img.shields.io/github/issues/swanhubx/swanlab\"></a> \n <br>\n <a href=\"https://dev101.swanlab.cn\" target=\"_blank\">\n <img alt=\"Static Badge\" src=\"https://img.shields.io/badge/Product-SwanLab\u4e91\u7aef\u7248-636a3f\"></a>\n <a href=\"https://geektechstudio.feishu.cn/wiki/NIZ9wp5LRiSqQykizbGcVzUKnic\" target=\"_blank\">\n <img alt=\"Static Badge\" src=\"https://img.shields.io/badge/WeChat-\u5fae\u4fe1-4cb55e\"></a>\n <a href=\"https://www.xiaohongshu.com/user/profile/605786b90000000001003a81\" target=\"_blank\">\n <img alt=\"Static Badge\" src=\"https://img.shields.io/badge/\u5c0f\u7ea2\u4e66-F04438\"></a>\n\n</p>\n\n<div align=\"center\">\n <a href=\"https://github.com/SwanHubX/SwanLab/blob/main/README_en.md\"><img alt=\"\u82f1\u6587\u6587\u6863\" src=\"https://img.shields.io/badge/English-d9d9d9\"></a>\n <a href=\"https://github.com/SwanHubX/SwanLab/blob/main/README.md\"><img alt=\"\u4e2d\u6587\u6587\u6863\" src=\"https://img.shields.io/badge/\u7b80\u4f53\u4e2d\u6587-d9d9d9\"></a>\n</div>\n\n<details>\n<summary>\u76ee\u5f55\u6811</summary>\n\n#### TOC\n\n- [\ud83d\udc4b\ud83c\udffb \u4ec0\u4e48\u662fSwanLab](#-\u4ec0\u4e48\u662fswanlab)\n- [\ud83c\udfc1 \u5feb\u901f\u5f00\u59cb](#-\u5feb\u901f\u5f00\u59cb)\n - [1.\u5b89\u88c5](#1\u5b89\u88c5)\n - [2.\u767b\u5f55\u5e76\u83b7\u53d6API Key](#2\u767b\u5f55\u5e76\u83b7\u53d6api-key)\n - [3.\u5c06SwanLab\u4e0e\u4f60\u7684\u4ee3\u7801\u96c6\u6210](#3\u5c06SwanLab\u4e0e\u4f60\u7684\u4ee3\u7801\u96c6\u6210)\n- [\ud83d\udcc3 \u66f4\u591a\u6848\u4f8b](#-\u66f4\u591a\u6848\u4f8b)\n- [\ud83d\udcbb \u81ea\u6258\u7ba1](#-\u81ea\u6258\u7ba1)\n - [\u79bb\u7ebf\u5b9e\u9a8c\u8ddf\u8e2a](#\u79bb\u7ebf\u5b9e\u9a8c\u8ddf\u8e2a)\n - [\u5f00\u542f\u79bb\u7ebf\u770b\u677f](#\u5f00\u542f\u79bb\u7ebf\u770b\u677f)\n- [\ud83d\ude97 \u6846\u67b6\u96c6\u6210](#-\u6846\u67b6\u96c6\u6210)\n- [\ud83c\udd9a \u4e0e\u719f\u6089\u7684\u5de5\u5177\u7684\u6bd4\u8f83](#-\u4e0e\u719f\u6089\u7684\u5de5\u5177\u7684\u6bd4\u8f83)\n - [Tensorboard vs SwanLab](#tensorboard-vs-swanlab)\n - [W&B vs SwanLab](#weights-and-biases-vs-swanlab)\n- [\ud83d\udee3\ufe0f Roadmap](#%EF%B8%8F-roadmap)\n - [\u4e24\u5468\u5185\u5373\u5c06\u4e0a\u7ebf](#\u4e24\u5468\u5185\u5373\u5c06\u4e0a\u7ebf)\n - [\u4e09\u4e2a\u6708\u5185\u89c4\u5212\u4e0a\u7ebf](#\u4e09\u4e2a\u6708\u5185\u89c4\u5212\u4e0a\u7ebf)\n - [\u957f\u671f\u5173\u6ce8](#\u957f\u671f\u5173\u6ce8)\n- [\ud83d\udc65 \u793e\u533a](#-\u793e\u533a)\n - [\u793e\u533a\u4e0e\u652f\u6301](#\u793e\u533a\u4e0e\u652f\u6301)\n - [SwanLab README\u5fbd\u7ae0](#swanlab-readme\u5fbd\u7ae0)\n - [\u5728\u8bba\u6587\u4e2d\u5f15\u7528SwanLab](#\u5728\u8bba\u6587\u4e2d\u5f15\u7528swanlab)\n - [\u4e3aSwanLab\u505a\u51fa\u8d21\u732e](#\u4e3aswanlab\u505a\u51fa\u8d21\u732e)\n - [\u4e0b\u8f7dIcon](#\u4e0b\u8f7dicon)\n- [\ud83d\udcc3 \u534f\u8bae](#-\u534f\u8bae)\n\n<br/>\n\n</details>\n\n## \ud83d\udc4b\ud83c\udffb \u4ec0\u4e48\u662fSwanLab\n\nSwanLab is an open-source, lightweight AI experiment tracking tool that provides a platform for tracking, comparing, and\ncollaborating on experiments, aiming to accelerate the research and development efficiency of AI teams by 100 times.\n\nSwanLab\u662f\u4e00\u6b3e\u5f00\u6e90\u3001\u8f7b\u91cf\u7ea7\u7684AI\u5b9e\u9a8c\u8ddf\u8e2a\u5de5\u5177\uff0c\u63d0\u4f9b\u4e86\u4e00\u4e2a\u8ddf\u8e2a\u3001\u6bd4\u8f83\u3001\u548c\u534f\u4f5c\u5b9e\u9a8c\u7684\u5e73\u53f0\uff0c\u65e8\u5728\u52a0\u901fAI\u7814\u53d1\u56e2\u961f100\u500d\u7684\u7814\u53d1\u6548\u7387\u3002\n\n\u5176\u63d0\u4f9b\u4e86\u53cb\u597d\u7684API\u548c\u6f02\u4eae\u7684\u754c\u9762\uff0c\u7ed3\u5408\u4e86\u8d85\u53c2\u6570\u8ddf\u8e2a\u3001\u6307\u6807\u8bb0\u5f55\u3001\u5728\u7ebf\u534f\u4f5c\u3001\u5b9e\u9a8c\u94fe\u63a5\u5206\u4eab\u3001\u5b9e\u65f6\u6d88\u606f\u901a\u77e5\u7b49\u529f\u80fd\uff0c\u8ba9\u60a8\u53ef\u4ee5\u5feb\u901f\u8ddf\u8e2aML\u5b9e\u9a8c\u3001\u53ef\u89c6\u5316\u8fc7\u7a0b\u3001\u5206\u4eab\u7ed9\u540c\u4f34\u3002\n\n\u501f\u52a9SwanLab\uff0c\u79d1\u7814\u4eba\u5458\u53ef\u4ee5\u6c89\u6dc0\u81ea\u5df1\u7684\u6bcf\u4e00\u6b21\u8bad\u7ec3\u7ecf\u9a8c\uff0c\u4e0e\u5408\u4f5c\u8005\u65e0\u7f1d\u5730\u4ea4\u6d41\u548c\u534f\u4f5c\uff0c\u673a\u5668\u5b66\u4e60\u5de5\u7a0b\u5e08\u53ef\u4ee5\u66f4\u5feb\u5730\u5f00\u53d1\u53ef\u7528\u4e8e\u751f\u4ea7\u7684\u6a21\u578b\u3002\n\n\n\n\u4ee5\u4e0b\u662f\u5176\u6838\u5fc3\u7279\u6027\u5217\u8868\uff1a\n\n**1. \ud83d\udcca\u5b9e\u9a8c\u6307\u6807\u4e0e\u8d85\u53c2\u6570\u8ddf\u8e2a**: \u6781\u7b80\u7684\u4ee3\u7801\u5d4c\u5165\u60a8\u7684\u673a\u5668\u5b66\u4e60pipeline\uff0c\u8ddf\u8e2a\u8bb0\u5f55\u8bad\u7ec3\u5173\u952e\u6307\u6807\n\n- \u81ea\u7531\u7684\u8d85\u53c2\u6570\u4e0e\u5b9e\u9a8c\u914d\u7f6e\u8bb0\u5f55\n- \u652f\u6301\u7684\u5143\u6570\u636e\u7c7b\u578b\uff1a\u6807\u91cf\u6307\u6807\u3001\u56fe\u50cf\u3001\u97f3\u9891\u3001\u6587\u672c\u3001...\n- \u652f\u6301\u7684\u56fe\u8868\u7c7b\u578b\uff1a\u6298\u7ebf\u56fe\u3001\u5a92\u4f53\u56fe\uff08\u56fe\u50cf\u3001\u97f3\u9891\u3001\u6587\u672c\uff09\u3001...\n- \u81ea\u52a8\u8bb0\u5f55\uff1a\u63a7\u5236\u53f0logging\u3001GPU\u786c\u4ef6\u3001Git\u4fe1\u606f\u3001Python\u89e3\u91ca\u5668\u3001Python\u5e93\u5217\u8868\u3001\u4ee3\u7801\u76ee\u5f55\n\n**2. \u26a1\ufe0f\u5168\u9762\u7684\u6846\u67b6\u96c6\u6210**: PyTorch\u3001Tensorflow\u3001PyTorch Lightning\u3001\ud83e\udd17HuggingFace\nTransformers\u3001MMEngine\u3001OpenAI\u3001ZhipuAI\u3001Hydra\u3001...\n\n**3. \ud83d\udce6\u7ec4\u7ec7\u5b9e\u9a8c**: \u96c6\u4e2d\u5f0f\u4eea\u8868\u677f\uff0c\u5feb\u901f\u7ba1\u7406\u591a\u4e2a\u9879\u76ee\u4e0e\u5b9e\u9a8c\uff0c\u901a\u8fc7\u6574\u4f53\u89c6\u56fe\u901f\u89c8\u8bad\u7ec3\u5168\u5c40\n\n**4. \ud83c\udd9a\u6bd4\u8f83\u7ed3\u679c**: \u901a\u8fc7\u5728\u7ebf\u8868\u683c\u4e0e\u5bf9\u6bd4\u56fe\u8868\u6bd4\u8f83\u4e0d\u540c\u5b9e\u9a8c\u7684\u8d85\u53c2\u6570\u548c\u7ed3\u679c\uff0c\u6316\u6398\u8fed\u4ee3\u7075\u611f\n\n**5. \ud83d\udc65\u5728\u7ebf\u534f\u4f5c**: \u60a8\u53ef\u4ee5\u4e0e\u56e2\u961f\u8fdb\u884c\u534f\u4f5c\u5f0f\u8bad\u7ec3\uff0c\u652f\u6301\u5c06\u5b9e\u9a8c\u5b9e\u65f6\u540c\u6b65\u5728\u4e00\u4e2a\u9879\u76ee\u4e0b\uff0c\u60a8\u53ef\u4ee5\u5728\u7ebf\u67e5\u770b\u56e2\u961f\u7684\u8bad\u7ec3\u8bb0\u5f55\uff0c\u57fa\u4e8e\u7ed3\u679c\u53d1\u8868\u770b\u6cd5\u4e0e\u5efa\u8bae\n\n**6. \u2709\ufe0f\u5206\u4eab\u7ed3\u679c**: \u590d\u5236\u548c\u53d1\u9001\u6301\u4e45\u7684URL\u6765\u5171\u4eab\u6bcf\u4e2a\u5b9e\u9a8c\uff0c\u65b9\u4fbf\u5730\u53d1\u9001\u7ed9\u4f19\u4f34\uff0c\u6216\u5d4c\u5165\u5230\u5728\u7ebf\u7b14\u8bb0\u4e2d\n\n**7. \ud83d\udcbb\u652f\u6301\u81ea\u6258\u7ba1**: \u652f\u6301\u4e0d\u8054\u7f51\u4f7f\u7528\uff0c\u81ea\u6258\u7ba1\u7684\u793e\u533a\u7248\u540c\u6837\u53ef\u4ee5\u67e5\u770b\u4eea\u8868\u76d8\u4e0e\u7ba1\u7406\u5b9e\u9a8c\n\n> \\[!IMPORTANT]\n>\n> **\u6536\u85cf\u9879\u76ee**\uff0c\u4f60\u5c06\u4ece GitHub \u4e0a\u65e0\u5ef6\u8fdf\u5730\u63a5\u6536\u6240\u6709\u53d1\u5e03\u901a\u77e5\uff5e\u2b50\ufe0f\n\n\n\n<br>\n\n## \ud83c\udfc1 \u5feb\u901f\u5f00\u59cb\n\n### 1.\u5b89\u88c5\n\n```bash\npip install swanlab\n```\n\n### 2.\u767b\u5f55\u5e76\u83b7\u53d6API Key\n\n1. \u514d\u8d39[\u6ce8\u518c\u8d26\u53f7](https://dev101.swanlab.cn)\n\n2. \u767b\u5f55\u8d26\u53f7\uff0c\u5728\u7528\u6237\u8bbe\u7f6e > [API Key](https://dev101.swanlab.cn/settings) \u91cc\u590d\u5236\u60a8\u7684API Key\n\n3. \u6253\u5f00\u7ec8\u7aef\uff0c\u8f93\u5165\uff1a\n\n```bash\nswanlab login\n```\n\n\u51fa\u73b0\u63d0\u793a\u65f6\uff0c\u8f93\u5165\u60a8\u7684API Key\uff0c\u6309\u4e0b\u56de\u8f66\uff0c\u5b8c\u6210\u767b\u9646\u3002\n\n### 3.\u5c06SwanLab\u4e0e\u4f60\u7684\u4ee3\u7801\u96c6\u6210\n\n```python\nimport swanlab\n\n# \u521d\u59cb\u5316\u4e00\u4e2a\u65b0\u7684swanlab\u5b9e\u9a8c\nswanlab.init(\n project=\"my-first-ml\",\n config={'learning-rate': 0.003}\n)\n\n# \u8bb0\u5f55\u6307\u6807\nfor i in range(10):\n swanlab.log({\"loss\": i})\n```\n\n\u5927\u529f\u544a\u6210\uff01\u524d\u5f80[SwanLab](https://dev101.swanlab.cn)\u67e5\u770b\u4f60\u7684\u7b2c\u4e00\u4e2aSwanLab\u5b9e\u9a8c\u3002\n\n\n\n<br>\n\n## \ud83d\udcc3 \u66f4\u591a\u6848\u4f8b\n\n<details>\n<summary>MNIST</summary>\n\n```python\nimport os\nimport torch\nfrom torch import nn, optim, utils\nimport torch.nn.functional as F\nfrom torchvision.datasets import MNIST\nfrom torchvision.transforms import ToTensor\nimport swanlab\n\n\n# CNN\u7f51\u7edc\u6784\u5efa\nclass ConvNet(nn.Module):\n def __init__(self):\n super().__init__()\n # 1,28x28\n self.conv1 = nn.Conv2d(1, 10, 5) # 10, 24x24\n self.conv2 = nn.Conv2d(10, 20, 3) # 128, 10x10\n self.fc1 = nn.Linear(20 * 10 * 10, 500)\n self.fc2 = nn.Linear(500, 10)\n\n def forward(self, x):\n in_size = x.size(0)\n out = self.conv1(x) # 24\n out = F.relu(out)\n out = F.max_pool2d(out, 2, 2) # 12\n out = self.conv2(out) # 10\n out = F.relu(out)\n out = out.view(in_size, -1)\n out = self.fc1(out)\n out = F.relu(out)\n out = self.fc2(out)\n out = F.log_softmax(out, dim=1)\n return out\n\n\n# \u6355\u83b7\u5e76\u53ef\u89c6\u5316\u524d20\u5f20\u56fe\u50cf\ndef log_images(loader, num_images=16):\n images_logged = 0\n logged_images = []\n for images, labels in loader:\n # images: batch of images, labels: batch of labels\n for i in range(images.shape[0]):\n if images_logged < num_images:\n # \u4f7f\u7528swanlab.Image\u5c06\u56fe\u50cf\u8f6c\u6362\u4e3awandb\u53ef\u89c6\u5316\u683c\u5f0f\n logged_images.append(swanlab.Image(images[i], caption=f\"Label: {labels[i]}\"))\n images_logged += 1\n else:\n break\n if images_logged >= num_images:\n break\n swanlab.log({\"MNIST-Preview\": logged_images})\n\n\nif __name__ == \"__main__\":\n\n # \u521d\u59cb\u5316swanlab\n run = swanlab.init(\n project=\"MNIST-example\",\n experiment_name=\"ConvNet\",\n description=\"Train ConvNet on MNIST dataset.\",\n config={\n \"model\": \"CNN\",\n \"optim\": \"Adam\",\n \"lr\": 0.001,\n \"batch_size\": 512,\n \"num_epochs\": 10,\n \"train_dataset_num\": 55000,\n \"val_dataset_num\": 5000,\n },\n )\n\n # \u8bbe\u7f6e\u8bad\u7ec3\u673a\u3001\u9a8c\u8bc1\u96c6\u548c\u6d4b\u8bd5\u96c6\n dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())\n train_dataset, val_dataset = utils.data.random_split(\n dataset, [run.config.train_dataset_num, run.config.val_dataset_num]\n )\n\n train_loader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)\n val_loader = utils.data.DataLoader(val_dataset, batch_size=1, shuffle=False)\n\n # \u521d\u59cb\u5316\u6a21\u578b\u3001\u635f\u5931\u51fd\u6570\u548c\u4f18\u5316\u5668\n model = ConvNet()\n criterion = nn.CrossEntropyLoss()\n optimizer = optim.Adam(model.parameters(), lr=run.config.lr)\n\n # \uff08\u53ef\u9009\uff09\u770b\u4e00\u4e0b\u6570\u636e\u96c6\u7684\u524d16\u5f20\u56fe\u50cf\n log_images(train_loader, 16)\n\n # \u5f00\u59cb\u8bad\u7ec3\n for epoch in range(1, run.config.num_epochs):\n swanlab.log({\"train/epoch\": epoch})\n # \u8bad\u7ec3\u5faa\u73af\n for iter, batch in enumerate(train_loader):\n x, y = batch\n optimizer.zero_grad()\n output = model(x)\n loss = criterion(output, y)\n loss.backward()\n optimizer.step()\n\n print(\n f\"Epoch [{epoch}/{run.config.num_epochs}], Iteration [{iter + 1}/{len(train_loader)}], Loss: {loss.item()}\"\n )\n\n if iter % 20 == 0:\n swanlab.log({\"train/loss\": loss.item()}, step=(epoch - 1) * len(train_loader) + iter)\n\n # \u6bcf4\u4e2aepoch\u9a8c\u8bc1\u4e00\u6b21\n if epoch % 2 == 0:\n model.eval()\n correct = 0\n total = 0\n with torch.no_grad():\n for batch in val_loader:\n x, y = batch\n output = model(x)\n _, predicted = torch.max(output, 1)\n total += y.size(0)\n correct += (predicted == y).sum().item()\n\n accuracy = correct / total\n swanlab.log({\"val/accuracy\": accuracy})\n\n```\n\n</details>\n\n<details>\n<summary>FashionMNSIT-ResNet34</summary>\n\n```python\nimport os\nimport torch\nfrom torch import nn, optim, utils\nimport torch.nn.functional as F\nfrom torchvision.datasets import FashionMNIST\nfrom torchvision.transforms import ToTensor\nimport swanlab\n\n\n# ResNet\u7f51\u7edc\u6784\u5efa\nclass Basicblock(nn.Module):\n def __init__(self, in_planes, planes, stride=1):\n super(Basicblock, self).__init__()\n self.conv1 = nn.Sequential(\n nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1, bias=False),\n nn.BatchNorm2d(planes),\n nn.ReLU()\n )\n self.conv2 = nn.Sequential(\n nn.Conv2d(in_channels=planes, out_channels=planes, kernel_size=3, stride=1, padding=1, bias=False),\n nn.BatchNorm2d(planes),\n )\n\n if stride != 1 or in_planes != planes:\n self.shortcut = nn.Sequential(\n nn.Conv2d(in_channels=in_planes, out_channels=planes, kernel_size=3, stride=stride, padding=1),\n nn.BatchNorm2d(planes)\n )\n else:\n self.shortcut = nn.Sequential()\n\n def forward(self, x):\n out = self.conv1(x)\n out = self.conv2(out)\n out += self.shortcut(x)\n out = F.relu(out)\n return out\n\n\nclass ResNet(nn.Module):\n def __init__(self, block, num_block, num_classes):\n super(ResNet, self).__init__()\n self.in_planes = 16\n self.conv1 = nn.Sequential(\n nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1),\n nn.BatchNorm2d(16),\n nn.ReLU()\n )\n self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)\n\n self.block1 = self._make_layer(block, 16, num_block[0], stride=1)\n self.block2 = self._make_layer(block, 32, num_block[1], stride=2)\n self.block3 = self._make_layer(block, 64, num_block[2], stride=2)\n # self.block4 = self._make_layer(block, 512, num_block[3], stride=2)\n\n self.outlayer = nn.Linear(64, num_classes)\n\n def _make_layer(self, block, planes, num_block, stride):\n layers = []\n for i in range(num_block):\n if i == 0:\n layers.append(block(self.in_planes, planes, stride))\n else:\n layers.append(block(planes, planes, 1))\n self.in_planes = planes\n return nn.Sequential(*layers)\n\n def forward(self, x):\n x = self.maxpool(self.conv1(x))\n x = self.block1(x) # [200, 64, 28, 28]\n x = self.block2(x) # [200, 128, 14, 14]\n x = self.block3(x) # [200, 256, 7, 7]\n # out = self.block4(out)\n x = F.avg_pool2d(x, 7) # [200, 256, 1, 1]\n x = x.view(x.size(0), -1) # [200,256]\n out = self.outlayer(x)\n return out\n\n\n# \u6355\u83b7\u5e76\u53ef\u89c6\u5316\u524d20\u5f20\u56fe\u50cf\ndef log_images(loader, num_images=16):\n images_logged = 0\n logged_images = []\n for images, labels in loader:\n # images: batch of images, labels: batch of labels\n for i in range(images.shape[0]):\n if images_logged < num_images:\n # \u4f7f\u7528swanlab.Image\u5c06\u56fe\u50cf\u8f6c\u6362\u4e3awandb\u53ef\u89c6\u5316\u683c\u5f0f\n logged_images.append(swanlab.Image(images[i], caption=f\"Label: {labels[i]}\", size=(128, 128)))\n images_logged += 1\n else:\n break\n if images_logged >= num_images:\n break\n swanlab.log({\"Preview/MNIST\": logged_images})\n\n\nif __name__ == \"__main__\":\n # \u8bbe\u7f6edevice\n try:\n use_mps = torch.backends.mps.is_available()\n except AttributeError:\n use_mps = False\n\n if torch.cuda.is_available():\n device = \"cuda\"\n elif use_mps:\n device = \"mps\"\n else:\n device = \"cpu\"\n\n # \u521d\u59cb\u5316swanlab\n run = swanlab.init(\n project=\"FashionMNIST\",\n workspace=\"SwanLab\",\n experiment_name=\"Resnet18-Adam\",\n config={\n \"model\": \"Resnet34\",\n \"optim\": \"Adam\",\n \"lr\": 0.001,\n \"batch_size\": 32,\n \"num_epochs\": 10,\n \"train_dataset_num\": 55000,\n \"val_dataset_num\": 5000,\n \"device\": device,\n \"num_classes\": 10,\n },\n )\n\n # \u8bbe\u7f6e\u8bad\u7ec3\u673a\u3001\u9a8c\u8bc1\u96c6\u548c\u6d4b\u8bd5\u96c6\n dataset = FashionMNIST(os.getcwd(), train=True, download=True, transform=ToTensor())\n train_dataset, val_dataset = utils.data.random_split(\n dataset, [run.config.train_dataset_num, run.config.val_dataset_num]\n )\n\n train_loader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)\n val_loader = utils.data.DataLoader(val_dataset, batch_size=1, shuffle=False)\n\n # \u521d\u59cb\u5316\u6a21\u578b\u3001\u635f\u5931\u51fd\u6570\u548c\u4f18\u5316\u5668\n if run.config.model == \"Resnet18\":\n model = ResNet(Basicblock, [1, 1, 1, 1], 10)\n elif run.config.model == \"Resnet34\":\n model = ResNet(Basicblock, [2, 3, 5, 2], 10)\n elif run.config.model == \"Resnet50\":\n model = ResNet(Basicblock, [3, 4, 6, 3], 10)\n\n model.to(torch.device(device))\n\n criterion = nn.CrossEntropyLoss()\n optimizer = optim.Adam(model.parameters(), lr=run.config.lr)\n\n # \uff08\u53ef\u9009\uff09\u770b\u4e00\u4e0b\u6570\u636e\u96c6\u7684\u524d16\u5f20\u56fe\u50cf\n log_images(train_loader, 16)\n\n # \u5f00\u59cb\u8bad\u7ec3\n for epoch in range(1, run.config.num_epochs + 1):\n swanlab.log({\"train/epoch\": epoch}, step=epoch)\n # \u8bad\u7ec3\u5faa\u73af\n for iter, batch in enumerate(train_loader):\n x, y = batch\n x, y = x.to(device), y.to(device)\n optimizer.zero_grad()\n output = model(x)\n loss = criterion(output, y)\n loss.backward()\n optimizer.step()\n\n if iter % 40 == 0:\n print(\n f\"Epoch [{epoch}/{run.config.num_epochs}], Iteration [{iter + 1}/{len(train_loader)}], Loss: {loss.item()}\"\n )\n swanlab.log({\"train/loss\": loss.item()}, step=(epoch - 1) * len(train_loader) + iter)\n\n # \u6bcf4\u4e2aepoch\u9a8c\u8bc1\u4e00\u6b21\n if epoch % 2 == 0:\n model.eval()\n correct = 0\n total = 0\n with torch.no_grad():\n for batch in val_loader:\n x, y = batch\n x, y = x.to(device), y.to(device)\n output = model(x)\n _, predicted = torch.max(output, 1)\n total += y.size(0)\n correct += (predicted == y).sum().item()\n\n accuracy = correct / total\n swanlab.log({\"val/accuracy\": accuracy}, step=epoch)\n```\n\n</details>\n\n\n<br>\n\n## \ud83d\udcbb \u81ea\u6258\u7ba1\n\n\u81ea\u6258\u7ba1\u793e\u533a\u7248\u652f\u6301\u79bb\u7ebf\u67e5\u770bSwanLab\u4eea\u8868\u76d8\u3002\n\n### \u79bb\u7ebf\u5b9e\u9a8c\u8ddf\u8e2a\n\n\u5728swanlab.init\u4e2d\u8bbe\u7f6e`logir`\u548c`cloud`\u8fd9\u4e24\u4e2a\u53c2\u6570\uff0c\u5373\u53ef\u79bb\u7ebf\u8ddf\u8e2a\u5b9e\u9a8c\uff1a\n\n```python\n...\n\nswanlab.init(\n logdir='./logs',\n cloud=False,\n)\n\n...\n```\n\n- \u53c2\u6570`cloud`\u8bbe\u7f6e\u4e3a`False`\uff0c\u5173\u95ed\u5c06\u5b9e\u9a8c\u540c\u6b65\u5230\u4e91\u7aef\n\n- \u53c2\u6570`logdir`\u7684\u8bbe\u7f6e\u662f\u53ef\u9009\u7684\uff0c\u5b83\u7684\u4f5c\u7528\u662f\u6307\u5b9a\u4e86SwanLab\u65e5\u5fd7\u6587\u4ef6\u7684\u4fdd\u5b58\u4f4d\u7f6e\uff08\u9ed8\u8ba4\u4fdd\u5b58\u5728`swanlog`\u6587\u4ef6\u5939\u4e0b\uff09\n\n - \u65e5\u5fd7\u6587\u4ef6\u4f1a\u5728\u8ddf\u8e2a\u5b9e\u9a8c\u7684\u8fc7\u7a0b\u4e2d\u88ab\u521b\u5efa\u548c\u66f4\u65b0\uff0c\u79bb\u7ebf\u770b\u677f\u7684\u542f\u52a8\u4e5f\u5c06\u57fa\u4e8e\u8fd9\u4e9b\u65e5\u5fd7\u6587\u4ef6\n\n\u5176\u4ed6\u90e8\u5206\u548c\u4e91\u7aef\u4f7f\u7528\u5b8c\u5168\u4e00\u81f4\u3002\n\n### \u5f00\u542f\u79bb\u7ebf\u770b\u677f\n\n\u6253\u5f00\u7ec8\u7aef\uff0c\u4f7f\u7528\u4e0b\u9762\u7684\u6307\u4ee4\uff0c\u5f00\u542f\u4e00\u4e2aSwanLab\u4eea\u8868\u677f:\n\n```bash\nswanlab watch -l ./logs\n```\n\n\u8fd0\u884c\u5b8c\u6210\u540e\uff0cSwanLab\u4f1a\u7ed9\u4f601\u4e2a\u672c\u5730\u7684URL\u94fe\u63a5\uff08\u9ed8\u8ba4\u662f[http://127.0.0.1:5092](http://127.0.0.1:5092)\uff09\n\n\u8bbf\u95ee\u8be5\u94fe\u63a5\uff0c\u5c31\u53ef\u4ee5\u5728\u6d4f\u89c8\u5668\u7528\u79bb\u7ebf\u770b\u677f\u67e5\u770b\u5b9e\u9a8c\u4e86\u3002\n\n<br>\n\n## \ud83d\ude97 \u6846\u67b6\u96c6\u6210\n\n\u5c06\u60a8\u6700\u559c\u6b22\u7684\u6846\u67b6\u4e0eSwanLab\u7ed3\u5408\u4f7f\u7528\uff0c[\u66f4\u591a\u96c6\u6210](https://docs.dev101.swanlab.cn/zh/guide_cloud/integration/integration-pytorch-lightning.html)\u3002\n\n<details>\n <summary>\n <strong>\u26a1\ufe0f PyTorch Lightning</strong>\n </summary>\n <br>\n\n\u4f7f\u7528`SwanLabLogger`\u521b\u5efa\u793a\u4f8b\uff0c\u5e76\u4ee3\u5165`Trainer`\u7684`logger`\u53c2\u6570\u4e2d\uff0c\u5373\u53ef\u5b9e\u73b0SwanLab\u8bb0\u5f55\u8bad\u7ec3\u6307\u6807\u3002\n\n```python\nfrom swanlab.integration.pytorch_lightning import SwanLabLogger\nimport importlib.util\nimport os\nimport pytorch_lightning as pl\nfrom torch import nn, optim, utils\nfrom torchvision.datasets import MNIST\nfrom torchvision.transforms import ToTensor\n\nencoder = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 3))\ndecoder = nn.Sequential(nn.Linear(3, 128), nn.ReLU(), nn.Linear(128, 28 * 28))\n\n\nclass LitAutoEncoder(pl.LightningModule):\n def __init__(self, encoder, decoder):\n super().__init__()\n self.encoder = encoder\n self.decoder = decoder\n\n def training_step(self, batch, batch_idx):\n # training_step defines the train loop.\n # it is independent of forward\n x, y = batch\n x = x.view(x.size(0), -1)\n z = self.encoder(x)\n x_hat = self.decoder(z)\n loss = nn.functional.mse_loss(x_hat, x)\n # Logging to TensorBoard (if installed) by default\n self.log(\"train_loss\", loss)\n return loss\n\n def test_step(self, batch, batch_idx):\n # test_step defines the test loop.\n # it is independent of forward\n x, y = batch\n x = x.view(x.size(0), -1)\n z = self.encoder(x)\n x_hat = self.decoder(z)\n loss = nn.functional.mse_loss(x_hat, x)\n # Logging to TensorBoard (if installed) by default\n self.log(\"test_loss\", loss)\n return loss\n\n def configure_optimizers(self):\n optimizer = optim.Adam(self.parameters(), lr=1e-3)\n return optimizer\n\n\n# init the autoencoder\nautoencoder = LitAutoEncoder(encoder, decoder)\n\n# setup data\ndataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())\ntrain_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000])\ntest_dataset = MNIST(os.getcwd(), train=False, download=True, transform=ToTensor())\n\ntrain_loader = utils.data.DataLoader(train_dataset)\nval_loader = utils.data.DataLoader(val_dataset)\ntest_loader = utils.data.DataLoader(test_dataset)\n\nswanlab_logger = SwanLabLogger(\n project=\"swanlab_example\",\n experiment_name=\"example_experiment\",\n cloud=False,\n)\n\ntrainer = pl.Trainer(limit_train_batches=100, max_epochs=5, logger=swanlab_logger)\n\ntrainer.fit(model=autoencoder, train_dataloaders=train_loader, val_dataloaders=val_loader)\ntrainer.test(dataloaders=test_loader)\n\n```\n\n</details>\n\n<details>\n<summary>\n <strong> \ud83e\udd17HuggingFace Transformers</strong>\n</summary>\n\n<br>\n\n\u4f7f\u7528`SwanLabCallback`\u521b\u5efa\u793a\u4f8b\uff0c\u5e76\u4ee3\u5165`Trainer`\u7684`callbacks`\u53c2\u6570\u4e2d\uff0c\u5373\u53ef\u5b9e\u73b0SwanLab\u8bb0\u5f55\u8bad\u7ec3\u6307\u6807\u3002\n\n```python\nimport evaluate\nimport numpy as np\nimport swanlab\nfrom swanlab.integration.huggingface import SwanLabCallback\nfrom datasets import load_dataset\nfrom transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments\n\n\ndef tokenize_function(examples):\n return tokenizer(examples[\"text\"], padding=\"max_length\", truncation=True)\n\n\ndef compute_metrics(eval_pred):\n logits, labels = eval_pred\n predictions = np.argmax(logits, axis=-1)\n return metric.compute(predictions=predictions, references=labels)\n\n\ndataset = load_dataset(\"yelp_review_full\")\n\ntokenizer = AutoTokenizer.from_pretrained(\"bert-base-cased\")\n\ntokenized_datasets = dataset.map(tokenize_function, batched=True)\n\nsmall_train_dataset = tokenized_datasets[\"train\"].shuffle(seed=42).select(range(1000))\nsmall_eval_dataset = tokenized_datasets[\"test\"].shuffle(seed=42).select(range(1000))\n\nmetric = evaluate.load(\"accuracy\")\n\nmodel = AutoModelForSequenceClassification.from_pretrained(\"bert-base-cased\", num_labels=5)\n\ntraining_args = TrainingArguments(\n output_dir=\"test_trainer\",\n report_to=\"none\",\n num_train_epochs=3,\n logging_steps=50,\n)\n\nswanlab_callback = SwanLabCallback(experiment_name=\"TransformersTest\", cloud=False)\n\ntrainer = Trainer(\n model=model,\n args=training_args,\n train_dataset=small_train_dataset,\n eval_dataset=small_eval_dataset,\n compute_metrics=compute_metrics,\n callbacks=[swanlab_callback],\n)\n\ntrainer.train()\n```\n\n</details>\n\n<br>\n\n## \ud83c\udd9a \u4e0e\u719f\u6089\u7684\u5de5\u5177\u7684\u6bd4\u8f83\n\n### Tensorboard vs SwanLab\n\n- **\u2601\ufe0f\u652f\u6301\u5728\u7ebf\u4f7f\u7528**\uff1a\n \u901a\u8fc7SwanLab\u53ef\u4ee5\u65b9\u4fbf\u5730\u5c06\u8bad\u7ec3\u5b9e\u9a8c\u5728\u4e91\u7aef\u5728\u7ebf\u540c\u6b65\u4e0e\u4fdd\u5b58\uff0c\u4fbf\u4e8e\u8fdc\u7a0b\u67e5\u770b\u8bad\u7ec3\u8fdb\u5c55\u3001\u7ba1\u7406\u5386\u53f2\u9879\u76ee\u3001\u5206\u4eab\u5b9e\u9a8c\u94fe\u63a5\u3001\u53d1\u9001\u5b9e\u65f6\u6d88\u606f\u901a\u77e5\u3001\u591a\u7aef\u770b\u5b9e\u9a8c\u7b49\u3002\u800cTensorboard\u662f\u4e00\u4e2a\u79bb\u7ebf\u7684\u5b9e\u9a8c\u8ddf\u8e2a\u5de5\u5177\u3002\n\n- **\ud83d\udc65\u591a\u4eba\u534f\u4f5c**\uff1a\n \u5728\u8fdb\u884c\u591a\u4eba\u3001\u8de8\u56e2\u961f\u7684\u673a\u5668\u5b66\u4e60\u534f\u4f5c\u65f6\uff0c\u901a\u8fc7SwanLab\u53ef\u4ee5\u8f7b\u677e\u7ba1\u7406\u591a\u4eba\u7684\u8bad\u7ec3\u9879\u76ee\u3001\u5206\u4eab\u5b9e\u9a8c\u94fe\u63a5\u3001\u8de8\u7a7a\u95f4\u4ea4\u6d41\u8ba8\u8bba\u3002\u800cTensorboard\u4e3b\u8981\u4e3a\u4e2a\u4eba\u8bbe\u8ba1\uff0c\u96be\u4ee5\u8fdb\u884c\u591a\u4eba\u534f\u4f5c\u548c\u5206\u4eab\u5b9e\u9a8c\u3002\n\n- **\ud83d\udcbb\u6301\u4e45\u3001\u96c6\u4e2d\u7684\u4eea\u8868\u677f**\uff1a\n \u65e0\u8bba\u4f60\u5728\u4f55\u5904\u8bad\u7ec3\u6a21\u578b\uff0c\u65e0\u8bba\u662f\u5728\u672c\u5730\u8ba1\u7b97\u673a\u4e0a\u3001\u5728\u5b9e\u9a8c\u5ba4\u96c6\u7fa4\u8fd8\u662f\u5728\u516c\u6709\u4e91\u7684GPU\u5b9e\u4f8b\u4e2d\uff0c\u4f60\u7684\u7ed3\u679c\u90fd\u4f1a\u8bb0\u5f55\u5230\u540c\u4e00\u4e2a\u96c6\u4e2d\u5f0f\u4eea\u8868\u677f\u4e2d\u3002\u800c\u4f7f\u7528TensorBoard\u9700\u8981\u82b1\u8d39\u65f6\u95f4\u4ece\u4e0d\u540c\u7684\u673a\u5668\u590d\u5236\u548c\u7ba1\u7406\n TFEvent\u6587\u4ef6\u3002\n\n- **\ud83d\udcaa\u66f4\u5f3a\u5927\u7684\u8868\u683c**\uff1a\n \u901a\u8fc7SwanLab\u8868\u683c\u53ef\u4ee5\u67e5\u770b\u3001\u641c\u7d22\u3001\u8fc7\u6ee4\u6765\u81ea\u4e0d\u540c\u5b9e\u9a8c\u7684\u7ed3\u679c\uff0c\u53ef\u4ee5\u8f7b\u677e\u67e5\u770b\u6570\u5343\u4e2a\u6a21\u578b\u7248\u672c\u5e76\u627e\u5230\u9002\u5408\u4e0d\u540c\u4efb\u52a1\u7684\u6700\u4f73\u6027\u80fd\u6a21\u578b\u3002\n TensorBoard \u4e0d\u9002\u7528\u4e8e\u5927\u578b\u9879\u76ee\u3002\n\n### Weights and Biases vs SwanLab\n\n- Weights and Biases \u662f\u4e00\u4e2a\u5fc5\u987b\u8054\u7f51\u4f7f\u7528\u7684\u95ed\u6e90MLOps\u5e73\u53f0\n\n- SwanLab \u4e0d\u4ec5\u652f\u6301\u8054\u7f51\u4f7f\u7528\uff0c\u4e5f\u652f\u6301\u5f00\u6e90\u3001\u514d\u8d39\u3001\u81ea\u6258\u7ba1\u7684\u7248\u672c\n\n<br>\n\n## \ud83d\udee3\ufe0f Roadmap\n\n\u5de5\u5177\u5728\u8fed\u4ee3\u4e0e\u53cd\u9988\u4e2d\u8fdb\u5316\uff5e\uff0c\u6b22\u8fce[\u63d0\u4ea4\u529f\u80fd\u5efa\u8bae](https://geektechstudio.feishu.cn/share/base/form/shrcnyBlK8OMD0eweoFcc2SvWKc)\n\n### \u4e24\u5468\u5185\u5373\u5c06\u4e0a\u7ebf\n\n- `Table`: \u66f4\u7075\u6d3b\u7684\u591a\u7ef4\u8868\u683c\u56fe\u8868\uff0c\u9002\u7528\u4e8eLLM\u3001AIGC\u3001\u6a21\u578b\u8bc4\u4f30\u7b49\u573a\u666f\n- **\u90ae\u4ef6\u901a\u77e5\ud83d\udce7**: \u8bad\u7ec3\u610f\u5916\u4e2d\u65ad\u3001\u8bad\u7ec3\u5b8c\u6210\u3001\u81ea\u5b9a\u4e49\u60c5\u51b5\u7b49\u573a\u666f\u89e6\u8fbe\u65f6\uff0c\u53d1\u9001\u901a\u77e5\u90ae\u4ef6\n\n### \u4e09\u4e2a\u6708\u5185\u89c4\u5212\u4e0a\u7ebf\n\n- `Molecule`: \u751f\u7269\u5316\u5b66\u5206\u5b50\u53ef\u89c6\u5316\u56fe\u8868\n- `Plot`: \u81ea\u7531\u7684\u56fe\u8868\u7ed8\u5236\u65b9\u5f0f\n- `Api`: \u901a\u8fc7API\u8bbf\u95eeSwanLab\u6570\u636e\n- **\u7cfb\u7edf\u786c\u4ef6\u8bb0\u5f55**: \u8bb0\u5f55GPU\u3001CPU\u3001\u78c1\u76d8\u3001\u7f51\u7edc\u7b49\u4e00\u7cfb\u5217\u786c\u4ef6\u60c5\u51b5\n- **\u4ee3\u7801\u8bb0\u5f55**: \u8bb0\u5f55\u8bad\u7ec3\u4ee3\u7801\n- **\u66f4\u591a\u96c6\u6210**: LightGBM\u3001XGBoost\u3001openai\u3001chatglm\u3001mm\u7cfb\u5217\u3001...\uff09\n- ...\n\n### \u957f\u671f\u5173\u6ce8\n\n- \u6700\u6709\u5229\u4e8eAI\u56e2\u961f\u521b\u65b0\u7684\u534f\u540c\u65b9\u5f0f\n- \u6700\u53cb\u597d\u7684UI\u4ea4\u4e92\n- \u79fb\u52a8\u7aef\u770b\u5b9e\u9a8c\n\n<br>\n\n## \ud83d\udc65 \u793e\u533a\n\n### \u793e\u533a\u4e0e\u652f\u6301\n\n- [GitHub Issues](https://github.com/SwanHubX/SwanLab/issues)\uff1a\u4f7f\u7528SwanLab\u65f6\u9047\u5230\u7684\u9519\u8bef\u548c\u95ee\u9898\n- [\u7535\u5b50\u90ae\u4ef6\u652f\u6301](zeyi.lin@swanhub.co)\uff1a\u53cd\u9988\u5173\u4e8e\u4f7f\u7528SwanLab\u7684\u95ee\u9898\n- <a href=\"https://geektechstudio.feishu.cn/wiki/NIZ9wp5LRiSqQykizbGcVzUKnic\">\u5fae\u4fe1\u4ea4\u6d41\u7fa4</a>\uff1a\u4ea4\u6d41\u4f7f\u7528SwanLab\u7684\u95ee\u9898\u3001\u5206\u4eab\u6700\u65b0\u7684AI\u6280\u672f\n\n### SwanLab README\u5fbd\u7ae0\n\n\u5982\u679c\u4f60\u559c\u6b22\u5728\u5de5\u4f5c\u4e2d\u4f7f\u7528 SwanLab\uff0c\u8bf7\u5c06 SwanLab \u5fbd\u7ae0\u6dfb\u52a0\u5230\u4f60\u7684README\u4e2d\uff1a\n\n[](https://github.com/swanhubx/swanlab)\n\n```\n[](https://github.com/swanhubx/swanlab)\n```\n\n### \u5728\u8bba\u6587\u4e2d\u5f15\u7528SwanLab\n\n\u5982\u679c\u60a8\u53d1\u73b0 SwanLab \u5bf9\u60a8\u7684\u7814\u7a76\u4e4b\u65c5\u6709\u5e2e\u52a9\uff0c\u8bf7\u8003\u8651\u4ee5\u4e0b\u5217\u683c\u5f0f\u5f15\u7528\uff1a\n\n```bibtex\n@software{Zeyilin_SwanLab_2023,\n author = {Zeyi Lin, Shaohong Chen, Kang Li, Qiushan Jiang, Zirui Cai, Kaifang Ji and {The SwanLab team}},\n license = {Apache-2.0},\n title = {{SwanLab}},\n url = {https://github.com/swanhubx/swanlab},\n year = {2023}\n}\n```\n\n### \u4e3aSwanLab\u505a\u51fa\u8d21\u732e\n\n\u8003\u8651\u4e3aSwanLab\u505a\u51fa\u8d21\u732e\u5417\uff1f\u9996\u5148\uff0c\u8bf7\u82b1\u70b9\u65f6\u95f4\u9605\u8bfb [\u8d21\u732e\u6307\u5357](CONTRIBUTING.md)\u3002\n\n\u540c\u65f6\uff0c\u6211\u4eec\u975e\u5e38\u6b22\u8fce\u901a\u8fc7\u793e\u4ea4\u5a92\u4f53\u3001\u6d3b\u52a8\u548c\u4f1a\u8bae\u7684\u5206\u4eab\u6765\u652f\u6301SwanLab\uff0c\u8877\u5fc3\u611f\u8c22\uff01\n\n### \u4e0b\u8f7dIcon\n\n[SwanLab-Icon-SVG](https://raw.githubusercontent.com/SwanHubX/swanlab/main/readme_files/swanlab-logo.svg)\n\n<br>\n\n**Contributors**\n\n<a href=\"https://github.com/swanhubx/swanlab/graphs/contributors\">\n <img src=\"https://contrib.rocks/image?repo=swanhubx/swanlab\" />\n</a>\n\n<br>\n\n## \ud83d\udcc3 \u534f\u8bae\n\n\u672c\u4ed3\u5e93\u9075\u5faa [Apache 2.0 License](https://github.com/SwanHubX/SwanLab/blob/main/LICENSE) \u5f00\u6e90\u534f\u8bae\n",
"bugtrack_url": null,
"license": null,
"summary": "Python library for streamlined tracking and management of AI training processes.",
"version": "0.3.1",
"project_urls": {
"Bug Reports": "https://github.com/SwanHubX/SwanLab/issues",
"Documentation": "https://geektechstudio.feishu.cn/wiki/space/7310593325374013444?ccm_open_type=lark_wiki_spaceLink&open_tab_from=wiki_home",
"Homepage": "https://swanhub.co",
"Source": "https://github.com/SwanHubX/SwanLab"
},
"split_keywords": [
"machine learning",
" reproducibility",
" visualization"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "97868622fc0d96d0dcbde43a4feb4568b7e3665fe8b37ae090db4f68d07413ef",
"md5": "4dd3ac43f318f87791763cbb38b36412",
"sha256": "eca6407c136e63a50aba649bde25b98a37a44d58e35409bc4984e42eb5a1857c"
},
"downloads": -1,
"filename": "swanlab-0.3.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "4dd3ac43f318f87791763cbb38b36412",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.8",
"size": 890769,
"upload_time": "2024-05-02T04:31:50",
"upload_time_iso_8601": "2024-05-02T04:31:50.428117Z",
"url": "https://files.pythonhosted.org/packages/97/86/8622fc0d96d0dcbde43a4feb4568b7e3665fe8b37ae090db4f68d07413ef/swanlab-0.3.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "fe8bb590486d4811eb20a5e6bef7f3f4c3dca0df77b6b89edcf04db200e2ea3b",
"md5": "fd88fa62e4c07f270bc21377dc89d028",
"sha256": "a4a5d182c39fd171331eec2c3cd2639b1ca98076132c2e16e48b8f54950549de"
},
"downloads": -1,
"filename": "swanlab-0.3.1.tar.gz",
"has_sig": false,
"md5_digest": "fd88fa62e4c07f270bc21377dc89d028",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 1245608,
"upload_time": "2024-05-02T04:31:52",
"upload_time_iso_8601": "2024-05-02T04:31:52.583847Z",
"url": "https://files.pythonhosted.org/packages/fe/8b/b590486d4811eb20a5e6bef7f3f4c3dca0df77b6b89edcf04db200e2ea3b/swanlab-0.3.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-05-02 04:31:52",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "SwanHubX",
"github_project": "SwanLab",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"requirements": [
{
"name": "soundfile",
"specs": []
},
{
"name": "pillow",
"specs": []
},
{
"name": "numpy",
"specs": []
},
{
"name": "cos-python-sdk-v5",
"specs": []
},
{
"name": "fastapi",
"specs": [
[
">=",
"0.110.1"
]
]
},
{
"name": "uvicorn",
"specs": [
[
">=",
"0.14.0"
]
]
},
{
"name": "requests",
"specs": []
},
{
"name": "click",
"specs": []
},
{
"name": "ujson",
"specs": []
},
{
"name": "PyYAML",
"specs": []
},
{
"name": "peewee",
"specs": []
},
{
"name": "psutil",
"specs": []
},
{
"name": "pynvml",
"specs": []
},
{
"name": "watchdog",
"specs": []
}
],
"lcname": "swanlab"
}

