# Articut 中文斷詞暨詞性標記服務
## [依語法結構計算,而非統計方法的中文斷詞。]
### [Articut API Website](https://api.droidtown.co/)
### [Document](https://api.droidtown.co/ArticutAPI/document/)
### [](https://youtu.be/AnvdKmVLlcA "Articut Demo")
## Benchmark
### 設計目標
名稱 | ArticutAPI | MP_ArticutAPI | WS_ArticutAPI |
:----------:|:-------------------:|:-------------------:|:------------------:|
產品 | Online / Docker | Docker | Docker |
技術 | HTTP Request | MultiProcessing | WebSocket |
特色 | 簡單易用 | 批次處理 | 即時處理 |
適用情景 | 任何 | 文本分析 | 聊天機器人 |
### 處理速度
名稱 | ArticutAPI | MP_ArticutAPI | WS_ArticutAPI |
:----------:|-------------:|-------------------:|-------------------:|
時間 | 0.1252 秒 | 0.1206 秒 | 0.0677 秒 |
### 大量文本
句數 | ArticutAPI | MP_ArticutAPI | WS_ArticutAPI |
:----------:|--------------:|-------------------:|------------------:|
方法 | parse() | bulk_parse(20) | parse() |
1K | 155 秒 | 8 秒 | 18 秒 |
2K | 306 秒 | 14 秒 | 35 秒 |
3K | 455 秒 | 17 秒 | 43 秒 |
- 測試平台爲 4 核心 CPU 並使用 4 個 Process。
- `MP_ArticutAPI`使用 bulk_parse(bulkSize=20) 方法。
- `WS_ArticutAPI`使用 parse() 方法。
----------------------
# ArticutAPI
## 安裝方法
```sh
pip3 install ArticutAPI
```
## 說明文件
函數說明請參閱 Docs/index.html
## 使用方法
### Articut CWS (Chinese word segmentation)
```
from ArticutAPI import Articut
from pprint import pprint
username = "" #這裡填入您在 https://api.droidtown.co 使用的帳號 email。若使用空字串,則預設使用每小時 2000 字的公用額度。
apikey = "" #這裡填入您在 https://api.droidtown.co 登入後取得的 api Key。若使用空字串,則預設使用每小時 2000 字的公用額度。
articut = Articut(username, apikey)
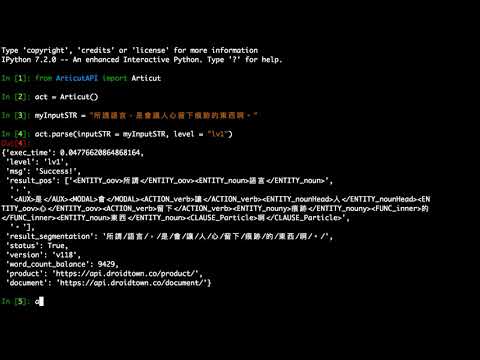
inputSTR = "會被大家盯上,才證明你有實力。"
resultDICT = articut.parse(inputSTR)
pprint(resultDICT)
```
### 回傳結果
```
{"exec_time": 0.06723856925964355,
"level": "lv2",
"msg": "Success!",
"result_pos": ["<MODAL>會</MODAL><ACTION_lightVerb>被</ACTION_lightVerb><ENTITY_nouny>大家</ENTITY_nouny><ACTION_verb>盯上</ACTION_verb>",
",",
"<MODAL>才</MODAL><ACTION_verb>證明</ACTION_verb><ENTITY_pronoun>你</ENTITY_pronoun><ACTION_verb>有</ACTION_verb><ENTITY_noun>實力</ENTITY_noun>",
"。"],
"result_segmentation": "會/被/大家/盯上/,/才/證明/你/有/實力/。/",
"status": True,
"version": "v118",
"word_count_balance": 9985,
"product": "https://api.droidtown.co/product/",
"document": "https://api.droidtown.co/document/"
}
```
### 列出斷詞結果所有詞性標記的內容詞 ###
可以依需求找出「名詞」、「動詞」或是「形容詞」…等詞彙語意本身已經完整的詞彙。
```
inputSTR = "你計劃過地球人類補完計劃"
resultDICT = articut.parse(inputSTR, level="lv1")
pprint(resultDICT["result_pos"])
#列出所有的 content word.
contentWordLIST = articut.getContentWordLIST(resultDICT)
pprint(contentWordLIST)
#列出所有的 verb word. (動詞)
verbStemLIST = articut.getVerbStemLIST(resultDICT)
pprint(verbStemLIST)
#列出所有的 noun word. (名詞)
nounStemLIST = articut.getNounStemLIST(resultDICT)
pprint(nounStemLIST)
#列出所有的 location word. (地方名稱)
locationStemLIST = articut.getLocationStemLIST(resultDICT)
pprint(locationStemLIST)
```
### 回傳結果 ###
```
#resultDICT["result_pos"]
["<ENTITY_pronoun>你</ENTITY_pronoun><ACTION_verb>計劃</ACTION_verb><ASPECT>過</ASPECT><LOCATION>地球</LOCATION><ENTITY_oov>人類</ENTITY_oov><ACTION_verb>補完</ACTION_verb><ENTITY_nounHead>計劃</ENTITY_nounHead>"]
#列出所有的 content word.
[[(47, 49, '計劃'), (117, 119, '人類'), (146, 147, '補'), (196, 198, '計劃')]]
#列出所有的 verb word. (動詞)
[[(47, 49, '計劃'), (146, 147, '補')]]
#列出所有的 noun word. (名詞)
[[(117, 119, '人類'), (196, 198, '計劃')]]
#列出所有的 location word. (地方名稱)
[[(91, 93, '地球')]]
```
### 取得 Articut 版本列表
```
resultDICT = articut.versions()
pprint(resultDICT)
```
### 回傳結果
```
{"msg": "Success!",
"status": True,
"versions": [{"level": ["lv1", "lv2"],
"release_date": "2019-04-25",
"version": "latest"},
{"level": ["lv1", "lv2"],
"release_date": "2019-04-25",
"version": "v118"},
{"level": ["lv1", "lv2"],
"release_date": "2019-04-24",
"version": "v117"},...
}
```
----------------------
## 進階用法
### 進階用法01 >> Articut Level :斷詞的深度。數字愈小,切得愈細 (預設: lv2)。
```
inputSTR = "小紅帽"
resultDICT = articut.parse(inputSTR, level="lv1")
pprint(resultDICT)
```
### 回傳結果 lv1
極致斷詞,適合 NLU 或機器自動翻譯使用。呈現結果將句子中的每個元素都儘量細分出來。
```
{"exec_time": 0.04814624786376953,
"level": "lv1",
"msg": "Success!",
"result_pos": ["<MODIFIER>小</MODIFIER><MODIFIER_color>紅</MODIFIER_color><ENTITY_nounHead>帽</ENTITY_nounHead>"],
"result_segmentation": "小/紅/帽/",
"status": True,
"version": "v118",
"word_count_balance": 9997,...}
```
### 回傳結果 lv2
詞組斷詞,適合文本分析、特徵值計算、關鍵字擷取…等應用。呈現結果將以具意義的最小單位呈現。
```
{"exec_time": 0.04195523262023926,
"level": "lv2",
"msg": "Success!",
"result_pos": ["<ENTITY_nouny>小紅帽</ENTITY_nouny>"],
"result_segmentation": "小紅帽/",
"status": True,
"version": "v118",
"word_count_balance": 9997,...}
```
----------------------
### 進階用法 02 >> UserDefinedDictFile :使用者自定詞典。
[](https://youtu.be/fOyyQyVkZ2k "Articut UserDefined Demo")
因為 Articut 只處理「語言知識」而不處理「百科知識」。
我們提供「使用者自定義」詞彙表的功能,使用 Dictionary 格式,請自行編寫。
UserDefinedFile.json
```
{"雷姆":["小老婆"],
"艾蜜莉亞":["大老婆"],
"初音未來": ["初音", "只是個軟體"],
"李敏鎬": ["全民歐巴", "歐巴"]}
```
runArticut.py
```
from ArticutAPI import Articut
from pprint import pprint
articut = Articut()
userDefined = "./UserDefinedFile.json"
inputSTR = "我的最愛是小老婆,不是初音未來。"
# 使用自定義詞典
resultDICT = articut.parse(inputSTR, userDefinedDictFILE=userDefined)
pprint(resultDICT)
# 未使用自定義詞典
resultDICT = articut.parse(inputSTR)
pprint(resultDICT)
```
### 回傳結果
```
# 使用自定義詞典
{"result_pos": ["<ENTITY_pronoun>我</ENTITY_pronoun><FUNC_inner>的</FUNC_inner><ACTION_verb>最愛</ACTION_verb><AUX>是</AUX><UserDefined>小老婆</UserDefined>",
",",
"<FUNC_negation>不</FUNC_negation><AUX>是</AUX><UserDefined>初音未來</UserDefined>",
"。"],
"result_segmentation": "我/的/最愛/是/小老婆/,/不/是/初音未來/。/",...}
# 未使用自定義詞典
{"result_pos": ["<ENTITY_pronoun>我</ENTITY_pronoun><FUNC_inner>的</FUNC_inner><ACTION_verb>最愛</ACTION_verb><AUX>是</AUX><ENTITY_nouny>小老婆</ENTITY_nouny>",
",",
"<FUNC_negation>不</FUNC_negation><AUX>是</AUX><ENTITY_nouny>初音</ENTITY_nouny><TIME_justtime>未來</TIME_justtime>",
"。"],
"result_segmentation": "我/的/最愛/是/小老婆/,/不/是/初音/未來/。/",...}
```
----------------------
### 進階用法 03 - 調用資料觀光資訊資料庫
政府開放平台中存有「交通部觀光局蒐集各政府機關所發佈空間化觀光資訊」。Articut 可取用其中的資訊,並標記為 \<KNOWLEDGE_place>
**上傳內容 (JSON 格式)**
```
{
"username": "test@email.com",
"api_key": "anapikeyfordocthatdoesnwork@all",
"input_str": "花蓮的原野牧場有一間餐廳",
"version": "v137",
"level": "lv1",
"opendata_place": true
}
```
**回傳內容 (JSON 格式)**
```
{
"exec_time": 0.013453006744384766,
"level": "lv1",
"msg": "Success!",
"result_pos": ["<LOCATION>花蓮</LOCATION><FUNC_inner>的</FUNC_inner><KNOWLEDGE_place>原野牧場</KNOWLEDGE_place><ACTION_verb>有</ACTION_verb><ENTITY_classifier>一間</ENTITY_classifier><ENTITY_noun>餐廳</ENTITY_noun>"],
"result_segmentation": "花蓮/的/原野牧場/有/一間/餐廳/",
"status": True,
"version": "v137",
"word_count_balance": 99987
}
```
----------------------
### 進階用法 04 - 基於 TF-IDF 算法的關鍵詞抽取
* articut.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
* sentence 為要提取關鍵詞的文本
* topK 為提取幾個 TF-IDF 的關鍵詞,預設值為 20
* withWeight 為是否返回關鍵詞權重值,預設值為 False
* allowPOS 僅抽取指定詞性的詞,預設值為空,亦即全部抽取
* articut.analyse.TFIDF(idf\_path=None) 新建 TFIDF 物件,idf_path 為 IDF 語料庫路徑
使用範例:
<https://github.com/Droidtown/ArticutAPI/blob/master/ArticutAPI.py#L624>
---
### 進階用法 05 - 基於 TextRank 算法的關鍵詞抽取
* articut.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=())
* sentence 為要提取關鍵詞的文本
* topK 為提取幾個 TF-IDF 的關鍵詞,預設值為 20
* withWeight 為是否返回關鍵詞權重值,預設值為 False
* allowPOS 僅抽取指定詞性的詞,預設值為空,亦即全部抽取
* articut.analyse.TextRank() 新建 TextRank 物件
算法論文:[TextRank: Bringing Order into Texts](http://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf)
### 基本思想:
1. 將待抽取關鍵詞的文本斷詞
2. 以固定的窗格大小 (預設值為 5,通過 span 屬性調整),詞之間的共現關係,建構出不帶權圖
3. 計算途中節點的 PageRank
使用範例:
<https://github.com/Droidtown/ArticutAPI/blob/master/ArticutAPI.py#L629>
---
### 進階用法 06 - 使用 GraphQL 查詢斷詞結果
[](https://youtu.be/0Ubx08WJ7rU)
### 使用 GraphiQL 工具
**環境需求**
```
Python 3.6.1
$ pip install graphene
$ pip install starlette
$ pip install jinja2
$ pip install uvicorn
```
執行 ArticutGraphQL.py 帶入 Articut 斷詞結果檔案路徑,並開啟瀏覽器輸入網址 http://0.0.0.0:8000/
```
$ python ArticutGraphQL.py articutResult.json
```
### 使用範例 01

### 使用範例 02

### 使用 Articut-GraphQL
安裝 graphene 模組
```
$ pip install graphene
```
### 使用範例 01
```
inputSTR = "地址:宜蘭縣宜蘭市縣政北七路六段55巷1號2樓"
result = articut.parse(inputSTR)
with open("articutResult.json", "w", encoding="utf-8") as resultFile:
json.dump(result, resultFile, ensure_ascii=False)
graphQLResult = articut.graphQL.query(
filePath="articutResult.json",
query="""
{
meta {
lang
description
}
doc {
text
tokens {
text
pos_
tag_
isStop
isEntity
isVerb
isTime
isClause
isKnowledge
}
}
}""")
pprint(graphQLResult)
```
### 回傳結果

### 使用範例 02
```
inputSTR = "劉克襄在本次活動當中,分享了台北中山北路一日遊路線。他表示當初自己領著柯文哲一同探索了雙連市場與中山捷運站的小吃與商圈,還有商圈內的文創商店與日系雜物店鋪,都令柯文哲留下深刻的印象。劉克襄也認為,雙連市場內的魯肉飯、圓仔湯與切仔麵,還有九條通的日式店家、居酒屋等特色,也能讓人感受到台北舊城區不一樣的魅力。"
result = articut.parse(inputSTR)
with open("articutResult.json", "w", encoding="utf-8") as resultFile:
json.dump(result, resultFile, ensure_ascii=False)
graphQLResult = articut.graphQL.query(
filePath="articutResult.json",
query="""
{
meta {
lang
description
}
doc {
text
ents {
persons {
text
pos_
tag_
}
}
}
}""")
pprint(graphQLResult)
```
### 回傳結果

Raw data
{
"_id": null,
"home_page": "https://github.com/Droidtown/ArticutAPI",
"name": "ArticutAPI",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.6.1",
"maintainer_email": null,
"keywords": "NLP, NLU, CWS, POS, NER, AI, artificial intelligence, Chinese word segmentation, computational linguistics, language, linguistics, graphQL, natural language, natural language processing, natural language understanding, parsing, part-of-speech-embdding, part-of-speech-tagger, pos-tagger, pos-tagging, syntax, tagging, text analytics",
"author": "Droidtown Linguistic Tech. Co. Ltd.",
"author_email": "info@droidtown.co",
"download_url": null,
"platform": null,
"description": "# Articut \u4e2d\u6587\u65b7\u8a5e\u66a8\u8a5e\u6027\u6a19\u8a18\u670d\u52d9\n## [\u4f9d\u8a9e\u6cd5\u7d50\u69cb\u8a08\u7b97\uff0c\u800c\u975e\u7d71\u8a08\u65b9\u6cd5\u7684\u4e2d\u6587\u65b7\u8a5e\u3002]\n\n### [Articut API Website](https://api.droidtown.co/)\n### [Document](https://api.droidtown.co/ArticutAPI/document/)\n### [](https://youtu.be/AnvdKmVLlcA \"Articut Demo\")\n\n## Benchmark\n### \u8a2d\u8a08\u76ee\u6a19\n\u540d\u7a31 | ArticutAPI | MP_ArticutAPI | WS_ArticutAPI | \n:----------:|:-------------------:|:-------------------:|:------------------:|\n\u7522\u54c1 | Online / Docker | Docker | Docker |\n\u6280\u8853 | HTTP Request | MultiProcessing | WebSocket |\n\u7279\u8272 | \u7c21\u55ae\u6613\u7528 | \u6279\u6b21\u8655\u7406 | \u5373\u6642\u8655\u7406 |\n\u9069\u7528\u60c5\u666f | \u4efb\u4f55 | \u6587\u672c\u5206\u6790 | \u804a\u5929\u6a5f\u5668\u4eba |\n\n### \u8655\u7406\u901f\u5ea6\n\u540d\u7a31 | ArticutAPI | MP_ArticutAPI | WS_ArticutAPI | \n:----------:|-------------:|-------------------:|-------------------:|\n\u6642\u9593 | 0.1252 \u79d2 | 0.1206 \u79d2 | 0.0677 \u79d2 |\n\n### \u5927\u91cf\u6587\u672c\n\u53e5\u6578 | ArticutAPI | MP_ArticutAPI | WS_ArticutAPI |\n:----------:|--------------:|-------------------:|------------------:|\n\u65b9\u6cd5 | parse() | bulk_parse(20) | parse() |\n1K | 155 \u79d2 | 8 \u79d2 | 18 \u79d2 |\n2K | 306 \u79d2 | 14 \u79d2 | 35 \u79d2 |\n3K | 455 \u79d2 | 17 \u79d2 | 43 \u79d2 |\n\n- \u6e2c\u8a66\u5e73\u53f0\u7232 4 \u6838\u5fc3 CPU \u4e26\u4f7f\u7528 4 \u500b Process\u3002\n- `MP_ArticutAPI`\u4f7f\u7528 bulk_parse(bulkSize=20) \u65b9\u6cd5\u3002\n- `WS_ArticutAPI`\u4f7f\u7528 parse() \u65b9\u6cd5\u3002\n\n----------------------\n\n# ArticutAPI\n\n## \u5b89\u88dd\u65b9\u6cd5\n```sh\npip3 install ArticutAPI\n```\n\n## \u8aaa\u660e\u6587\u4ef6\n\u51fd\u6578\u8aaa\u660e\u8acb\u53c3\u95b1 Docs/index.html\n\n## \u4f7f\u7528\u65b9\u6cd5\n### Articut CWS (Chinese word segmentation)\n```\nfrom ArticutAPI import Articut\nfrom pprint import pprint\nusername = \"\" #\u9019\u88e1\u586b\u5165\u60a8\u5728 https://api.droidtown.co \u4f7f\u7528\u7684\u5e33\u865f email\u3002\u82e5\u4f7f\u7528\u7a7a\u5b57\u4e32\uff0c\u5247\u9810\u8a2d\u4f7f\u7528\u6bcf\u5c0f\u6642 2000 \u5b57\u7684\u516c\u7528\u984d\u5ea6\u3002\napikey = \"\" #\u9019\u88e1\u586b\u5165\u60a8\u5728 https://api.droidtown.co \u767b\u5165\u5f8c\u53d6\u5f97\u7684 api Key\u3002\u82e5\u4f7f\u7528\u7a7a\u5b57\u4e32\uff0c\u5247\u9810\u8a2d\u4f7f\u7528\u6bcf\u5c0f\u6642 2000 \u5b57\u7684\u516c\u7528\u984d\u5ea6\u3002\narticut = Articut(username, apikey)\ninputSTR = \"\u6703\u88ab\u5927\u5bb6\u76ef\u4e0a\uff0c\u624d\u8b49\u660e\u4f60\u6709\u5be6\u529b\u3002\"\nresultDICT = articut.parse(inputSTR)\npprint(resultDICT)\n```\n### \u56de\u50b3\u7d50\u679c\n```\n{\"exec_time\": 0.06723856925964355,\n \"level\": \"lv2\",\n \"msg\": \"Success!\",\n \n \"result_pos\": [\"<MODAL>\u6703</MODAL><ACTION_lightVerb>\u88ab</ACTION_lightVerb><ENTITY_nouny>\u5927\u5bb6</ENTITY_nouny><ACTION_verb>\u76ef\u4e0a</ACTION_verb>\",\n \"\uff0c\",\n \"<MODAL>\u624d</MODAL><ACTION_verb>\u8b49\u660e</ACTION_verb><ENTITY_pronoun>\u4f60</ENTITY_pronoun><ACTION_verb>\u6709</ACTION_verb><ENTITY_noun>\u5be6\u529b</ENTITY_noun>\",\n \"\u3002\"],\n \"result_segmentation\": \"\u6703/\u88ab/\u5927\u5bb6/\u76ef\u4e0a/\uff0c/\u624d/\u8b49\u660e/\u4f60/\u6709/\u5be6\u529b/\u3002/\",\n \"status\": True,\n \"version\": \"v118\",\n \"word_count_balance\": 9985,\n \"product\": \"https://api.droidtown.co/product/\",\n \"document\": \"https://api.droidtown.co/document/\"\n}\n```\n\n### \u5217\u51fa\u65b7\u8a5e\u7d50\u679c\u6240\u6709\u8a5e\u6027\u6a19\u8a18\u7684\u5167\u5bb9\u8a5e ###\n\u53ef\u4ee5\u4f9d\u9700\u6c42\u627e\u51fa\u300c\u540d\u8a5e\u300d\u3001\u300c\u52d5\u8a5e\u300d\u6216\u662f\u300c\u5f62\u5bb9\u8a5e\u300d\u2026\u7b49\u8a5e\u5f59\u8a9e\u610f\u672c\u8eab\u5df2\u7d93\u5b8c\u6574\u7684\u8a5e\u5f59\u3002\n```\ninputSTR = \"\u4f60\u8a08\u5283\u904e\u5730\u7403\u4eba\u985e\u88dc\u5b8c\u8a08\u5283\"\nresultDICT = articut.parse(inputSTR, level=\"lv1\")\npprint(resultDICT[\"result_pos\"])\n\n#\u5217\u51fa\u6240\u6709\u7684 content word.\ncontentWordLIST = articut.getContentWordLIST(resultDICT)\npprint(contentWordLIST)\n\n#\u5217\u51fa\u6240\u6709\u7684 verb word. (\u52d5\u8a5e)\nverbStemLIST = articut.getVerbStemLIST(resultDICT)\npprint(verbStemLIST)\n\n#\u5217\u51fa\u6240\u6709\u7684 noun word. (\u540d\u8a5e)\nnounStemLIST = articut.getNounStemLIST(resultDICT)\npprint(nounStemLIST)\n\n#\u5217\u51fa\u6240\u6709\u7684 location word. (\u5730\u65b9\u540d\u7a31)\nlocationStemLIST = articut.getLocationStemLIST(resultDICT)\npprint(locationStemLIST)\n```\n\n### \u56de\u50b3\u7d50\u679c ###\n```\n#resultDICT[\"result_pos\"]\n[\"<ENTITY_pronoun>\u4f60</ENTITY_pronoun><ACTION_verb>\u8a08\u5283</ACTION_verb><ASPECT>\u904e</ASPECT><LOCATION>\u5730\u7403</LOCATION><ENTITY_oov>\u4eba\u985e</ENTITY_oov><ACTION_verb>\u88dc\u5b8c</ACTION_verb><ENTITY_nounHead>\u8a08\u5283</ENTITY_nounHead>\"]\n\n#\u5217\u51fa\u6240\u6709\u7684 content word.\n[[(47, 49, '\u8a08\u5283'), (117, 119, '\u4eba\u985e'), (146, 147, '\u88dc'), (196, 198, '\u8a08\u5283')]]\n\n#\u5217\u51fa\u6240\u6709\u7684 verb word. (\u52d5\u8a5e)\n[[(47, 49, '\u8a08\u5283'), (146, 147, '\u88dc')]]\n\n#\u5217\u51fa\u6240\u6709\u7684 noun word. (\u540d\u8a5e)\n[[(117, 119, '\u4eba\u985e'), (196, 198, '\u8a08\u5283')]]\n\n#\u5217\u51fa\u6240\u6709\u7684 location word. (\u5730\u65b9\u540d\u7a31)\n[[(91, 93, '\u5730\u7403')]]\n```\n\n### \u53d6\u5f97 Articut \u7248\u672c\u5217\u8868\n```\nresultDICT = articut.versions()\npprint(resultDICT)\n```\n### \u56de\u50b3\u7d50\u679c\n```\n{\"msg\": \"Success!\",\n \"status\": True,\n \"versions\": [{\"level\": [\"lv1\", \"lv2\"],\n \"release_date\": \"2019-04-25\",\n \"version\": \"latest\"},\n {\"level\": [\"lv1\", \"lv2\"],\n \"release_date\": \"2019-04-25\",\n \"version\": \"v118\"},\n {\"level\": [\"lv1\", \"lv2\"],\n \"release_date\": \"2019-04-24\",\n \"version\": \"v117\"},...\n}\n```\n\n----------------------\n\n## \u9032\u968e\u7528\u6cd5\n### \u9032\u968e\u7528\u6cd501 >> Articut Level :\u65b7\u8a5e\u7684\u6df1\u5ea6\u3002\u6578\u5b57\u6108\u5c0f\uff0c\u5207\u5f97\u6108\u7d30 (\u9810\u8a2d: lv2)\u3002\n```\ninputSTR = \"\u5c0f\u7d05\u5e3d\"\nresultDICT = articut.parse(inputSTR, level=\"lv1\")\npprint(resultDICT)\n```\n### \u56de\u50b3\u7d50\u679c lv1 \n\u6975\u81f4\u65b7\u8a5e\uff0c\u9069\u5408 NLU \u6216\u6a5f\u5668\u81ea\u52d5\u7ffb\u8b6f\u4f7f\u7528\u3002\u5448\u73fe\u7d50\u679c\u5c07\u53e5\u5b50\u4e2d\u7684\u6bcf\u500b\u5143\u7d20\u90fd\u5118\u91cf\u7d30\u5206\u51fa\u4f86\u3002\n```\n{\"exec_time\": 0.04814624786376953,\n \"level\": \"lv1\",\n \"msg\": \"Success!\",\n \"result_pos\": [\"<MODIFIER>\u5c0f</MODIFIER><MODIFIER_color>\u7d05</MODIFIER_color><ENTITY_nounHead>\u5e3d</ENTITY_nounHead>\"],\n \"result_segmentation\": \"\u5c0f/\u7d05/\u5e3d/\",\n \"status\": True,\n \"version\": \"v118\",\n \"word_count_balance\": 9997,...}\n```\n\n### \u56de\u50b3\u7d50\u679c lv2 \n\u8a5e\u7d44\u65b7\u8a5e\uff0c\u9069\u5408\u6587\u672c\u5206\u6790\u3001\u7279\u5fb5\u503c\u8a08\u7b97\u3001\u95dc\u9375\u5b57\u64f7\u53d6\u2026\u7b49\u61c9\u7528\u3002\u5448\u73fe\u7d50\u679c\u5c07\u4ee5\u5177\u610f\u7fa9\u7684\u6700\u5c0f\u55ae\u4f4d\u5448\u73fe\u3002\n```\n{\"exec_time\": 0.04195523262023926,\n \"level\": \"lv2\",\n \"msg\": \"Success!\",\n \"result_pos\": [\"<ENTITY_nouny>\u5c0f\u7d05\u5e3d</ENTITY_nouny>\"],\n \"result_segmentation\": \"\u5c0f\u7d05\u5e3d/\",\n \"status\": True,\n \"version\": \"v118\",\n \"word_count_balance\": 9997,...}\n```\n\n----------------------\n### \u9032\u968e\u7528\u6cd5 02 >> UserDefinedDictFile :\u4f7f\u7528\u8005\u81ea\u5b9a\u8a5e\u5178\u3002\n[](https://youtu.be/fOyyQyVkZ2k \"Articut UserDefined Demo\")\n\n\u56e0\u70ba Articut \u53ea\u8655\u7406\u300c\u8a9e\u8a00\u77e5\u8b58\u300d\u800c\u4e0d\u8655\u7406\u300c\u767e\u79d1\u77e5\u8b58\u300d\u3002\n\u6211\u5011\u63d0\u4f9b\u300c\u4f7f\u7528\u8005\u81ea\u5b9a\u7fa9\u300d\u8a5e\u5f59\u8868\u7684\u529f\u80fd\uff0c\u4f7f\u7528 Dictionary \u683c\u5f0f\uff0c\u8acb\u81ea\u884c\u7de8\u5beb\u3002\n\nUserDefinedFile.json\n```\n{\"\u96f7\u59c6\":[\"\u5c0f\u8001\u5a46\"],\n \"\u827e\u871c\u8389\u4e9e\":[\"\u5927\u8001\u5a46\"],\n \"\u521d\u97f3\u672a\u4f86\": [\"\u521d\u97f3\", \"\u53ea\u662f\u500b\u8edf\u9ad4\"],\n \"\u674e\u654f\u93ac\": [\"\u5168\u6c11\u6b50\u5df4\", \"\u6b50\u5df4\"]}\n```\n\nrunArticut.py\n```\nfrom ArticutAPI import Articut\nfrom pprint import pprint\n\narticut = Articut()\nuserDefined = \"./UserDefinedFile.json\"\ninputSTR = \"\u6211\u7684\u6700\u611b\u662f\u5c0f\u8001\u5a46\uff0c\u4e0d\u662f\u521d\u97f3\u672a\u4f86\u3002\"\n\n# \u4f7f\u7528\u81ea\u5b9a\u7fa9\u8a5e\u5178\nresultDICT = articut.parse(inputSTR, userDefinedDictFILE=userDefined)\npprint(resultDICT)\n\n# \u672a\u4f7f\u7528\u81ea\u5b9a\u7fa9\u8a5e\u5178\nresultDICT = articut.parse(inputSTR)\npprint(resultDICT)\n```\n\n### \u56de\u50b3\u7d50\u679c\n```\n# \u4f7f\u7528\u81ea\u5b9a\u7fa9\u8a5e\u5178\n{\"result_pos\": [\"<ENTITY_pronoun>\u6211</ENTITY_pronoun><FUNC_inner>\u7684</FUNC_inner><ACTION_verb>\u6700\u611b</ACTION_verb><AUX>\u662f</AUX><UserDefined>\u5c0f\u8001\u5a46</UserDefined>\",\n \"\uff0c\",\n \"<FUNC_negation>\u4e0d</FUNC_negation><AUX>\u662f</AUX><UserDefined>\u521d\u97f3\u672a\u4f86</UserDefined>\",\n \"\u3002\"],\n \"result_segmentation\": \"\u6211/\u7684/\u6700\u611b/\u662f/\u5c0f\u8001\u5a46/\uff0c/\u4e0d/\u662f/\u521d\u97f3\u672a\u4f86/\u3002/\",...}\n\n# \u672a\u4f7f\u7528\u81ea\u5b9a\u7fa9\u8a5e\u5178\n{\"result_pos\": [\"<ENTITY_pronoun>\u6211</ENTITY_pronoun><FUNC_inner>\u7684</FUNC_inner><ACTION_verb>\u6700\u611b</ACTION_verb><AUX>\u662f</AUX><ENTITY_nouny>\u5c0f\u8001\u5a46</ENTITY_nouny>\",\n \"\uff0c\",\n \"<FUNC_negation>\u4e0d</FUNC_negation><AUX>\u662f</AUX><ENTITY_nouny>\u521d\u97f3</ENTITY_nouny><TIME_justtime>\u672a\u4f86</TIME_justtime>\",\n \"\u3002\"],\n \"result_segmentation\": \"\u6211/\u7684/\u6700\u611b/\u662f/\u5c0f\u8001\u5a46/\uff0c/\u4e0d/\u662f/\u521d\u97f3/\u672a\u4f86/\u3002/\",...}\n```\n----------------------\n### \u9032\u968e\u7528\u6cd5 03 - \u8abf\u7528\u8cc7\u6599\u89c0\u5149\u8cc7\u8a0a\u8cc7\u6599\u5eab\n\u653f\u5e9c\u958b\u653e\u5e73\u53f0\u4e2d\u5b58\u6709\u300c\u4ea4\u901a\u90e8\u89c0\u5149\u5c40\u8490\u96c6\u5404\u653f\u5e9c\u6a5f\u95dc\u6240\u767c\u4f48\u7a7a\u9593\u5316\u89c0\u5149\u8cc7\u8a0a\u300d\u3002Articut \u53ef\u53d6\u7528\u5176\u4e2d\u7684\u8cc7\u8a0a\uff0c\u4e26\u6a19\u8a18\u70ba \\<KNOWLEDGE_place>\n\n**\u4e0a\u50b3\u5167\u5bb9 (JSON \u683c\u5f0f)**\n```\n{\n\t\"username\": \"test@email.com\",\n\t\"api_key\": \"anapikeyfordocthatdoesnwork@all\",\n\t\"input_str\": \"\u82b1\u84ee\u7684\u539f\u91ce\u7267\u5834\u6709\u4e00\u9593\u9910\u5ef3\",\n\t\"version\": \"v137\",\n\t\"level\": \"lv1\",\n\t\"opendata_place\": true\n}\n```\n\n**\u56de\u50b3\u5167\u5bb9 (JSON \u683c\u5f0f)**\n```\n{\n\t\"exec_time\": 0.013453006744384766,\n\t\"level\": \"lv1\",\n\t\"msg\": \"Success!\",\n\t\"result_pos\": [\"<LOCATION>\u82b1\u84ee</LOCATION><FUNC_inner>\u7684</FUNC_inner><KNOWLEDGE_place>\u539f\u91ce\u7267\u5834</KNOWLEDGE_place><ACTION_verb>\u6709</ACTION_verb><ENTITY_classifier>\u4e00\u9593</ENTITY_classifier><ENTITY_noun>\u9910\u5ef3</ENTITY_noun>\"],\n\t\"result_segmentation\": \"\u82b1\u84ee/\u7684/\u539f\u91ce\u7267\u5834/\u6709/\u4e00\u9593/\u9910\u5ef3/\",\n\t\"status\": True,\n\t\"version\": \"v137\",\n\t\"word_count_balance\": 99987\n}\n```\n----------------------\n\n### \u9032\u968e\u7528\u6cd5 04 - \u57fa\u65bc TF-IDF \u7b97\u6cd5\u7684\u95dc\u9375\u8a5e\u62bd\u53d6\n\n* articut.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())\n\t* sentence \u70ba\u8981\u63d0\u53d6\u95dc\u9375\u8a5e\u7684\u6587\u672c\n\t* topK \u70ba\u63d0\u53d6\u5e7e\u500b TF-IDF \u7684\u95dc\u9375\u8a5e\uff0c\u9810\u8a2d\u503c\u70ba 20\n\t* withWeight \u70ba\u662f\u5426\u8fd4\u56de\u95dc\u9375\u8a5e\u6b0a\u91cd\u503c\uff0c\u9810\u8a2d\u503c\u70ba False\n\t* allowPOS \u50c5\u62bd\u53d6\u6307\u5b9a\u8a5e\u6027\u7684\u8a5e\uff0c\u9810\u8a2d\u503c\u70ba\u7a7a\uff0c\u4ea6\u5373\u5168\u90e8\u62bd\u53d6\n* articut.analyse.TFIDF(idf\\_path=None) \u65b0\u5efa TFIDF \u7269\u4ef6\uff0cidf_path \u70ba IDF \u8a9e\u6599\u5eab\u8def\u5f91\n\n\u4f7f\u7528\u7bc4\u4f8b\uff1a\n<https://github.com/Droidtown/ArticutAPI/blob/master/ArticutAPI.py#L624>\n\n---\n\n### \u9032\u968e\u7528\u6cd5 05 - \u57fa\u65bc TextRank \u7b97\u6cd5\u7684\u95dc\u9375\u8a5e\u62bd\u53d6\n\n* articut.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=())\n\t* sentence \u70ba\u8981\u63d0\u53d6\u95dc\u9375\u8a5e\u7684\u6587\u672c\n\t* topK \u70ba\u63d0\u53d6\u5e7e\u500b TF-IDF \u7684\u95dc\u9375\u8a5e\uff0c\u9810\u8a2d\u503c\u70ba 20\n\t* withWeight \u70ba\u662f\u5426\u8fd4\u56de\u95dc\u9375\u8a5e\u6b0a\u91cd\u503c\uff0c\u9810\u8a2d\u503c\u70ba False\n\t* allowPOS \u50c5\u62bd\u53d6\u6307\u5b9a\u8a5e\u6027\u7684\u8a5e\uff0c\u9810\u8a2d\u503c\u70ba\u7a7a\uff0c\u4ea6\u5373\u5168\u90e8\u62bd\u53d6\n* articut.analyse.TextRank() \u65b0\u5efa TextRank \u7269\u4ef6\n\n\u7b97\u6cd5\u8ad6\u6587\uff1a[TextRank: Bringing Order into Texts](http://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf)\n\n### \u57fa\u672c\u601d\u60f3\uff1a\n\n1. \u5c07\u5f85\u62bd\u53d6\u95dc\u9375\u8a5e\u7684\u6587\u672c\u65b7\u8a5e\n2. \u4ee5\u56fa\u5b9a\u7684\u7a97\u683c\u5927\u5c0f (\u9810\u8a2d\u503c\u70ba 5\uff0c\u901a\u904e span \u5c6c\u6027\u8abf\u6574)\uff0c\u8a5e\u4e4b\u9593\u7684\u5171\u73fe\u95dc\u4fc2\uff0c\u5efa\u69cb\u51fa\u4e0d\u5e36\u6b0a\u5716\n3. \u8a08\u7b97\u9014\u4e2d\u7bc0\u9ede\u7684 PageRank\n\n\u4f7f\u7528\u7bc4\u4f8b\uff1a\n<https://github.com/Droidtown/ArticutAPI/blob/master/ArticutAPI.py#L629>\n\n---\n\n### \u9032\u968e\u7528\u6cd5 06 - \u4f7f\u7528 GraphQL \u67e5\u8a62\u65b7\u8a5e\u7d50\u679c\n[](https://youtu.be/0Ubx08WJ7rU)\n\n### \u4f7f\u7528 GraphiQL \u5de5\u5177\n\n**\u74b0\u5883\u9700\u6c42**\n\n```\nPython 3.6.1\n$ pip install graphene\n$ pip install starlette\n$ pip install jinja2\n$ pip install uvicorn\n```\n\n\u57f7\u884c ArticutGraphQL.py \u5e36\u5165 Articut \u65b7\u8a5e\u7d50\u679c\u6a94\u6848\u8def\u5f91\uff0c\u4e26\u958b\u555f\u700f\u89bd\u5668\u8f38\u5165\u7db2\u5740 http://0.0.0.0:8000/\n\n```\n$ python ArticutGraphQL.py articutResult.json\n```\n\n### \u4f7f\u7528\u7bc4\u4f8b 01\n\n\n### \u4f7f\u7528\u7bc4\u4f8b 02\n\n\n### \u4f7f\u7528 Articut-GraphQL\n\n\u5b89\u88dd graphene \u6a21\u7d44\n\n```\n$ pip install graphene\n```\n### \u4f7f\u7528\u7bc4\u4f8b 01\n```\ninputSTR = \"\u5730\u5740\uff1a\u5b9c\u862d\u7e23\u5b9c\u862d\u5e02\u7e23\u653f\u5317\u4e03\u8def\u516d\u6bb555\u5df71\u865f2\u6a13\"\nresult = articut.parse(inputSTR)\nwith open(\"articutResult.json\", \"w\", encoding=\"utf-8\") as resultFile:\n json.dump(result, resultFile, ensure_ascii=False)\n\t\ngraphQLResult = articut.graphQL.query(\n filePath=\"articutResult.json\",\n query=\"\"\"\n\t{\n\t meta {\n\t lang\n\t description\n\t }\n\t doc {\n\t text\n\t tokens {\n\t text\n\t pos_\n\t tag_\n\t isStop\n\t isEntity\n\t isVerb\n\t isTime\n\t isClause\n\t isKnowledge\n\t }\n\t }\n\t}\"\"\")\npprint(graphQLResult)\n```\n\n### \u56de\u50b3\u7d50\u679c\n\n\n### \u4f7f\u7528\u7bc4\u4f8b 02\n```\ninputSTR = \"\u5289\u514b\u8944\u5728\u672c\u6b21\u6d3b\u52d5\u7576\u4e2d\uff0c\u5206\u4eab\u4e86\u53f0\u5317\u4e2d\u5c71\u5317\u8def\u4e00\u65e5\u904a\u8def\u7dda\u3002\u4ed6\u8868\u793a\u7576\u521d\u81ea\u5df1\u9818\u8457\u67ef\u6587\u54f2\u4e00\u540c\u63a2\u7d22\u4e86\u96d9\u9023\u5e02\u5834\u8207\u4e2d\u5c71\u6377\u904b\u7ad9\u7684\u5c0f\u5403\u8207\u5546\u5708\uff0c\u9084\u6709\u5546\u5708\u5167\u7684\u6587\u5275\u5546\u5e97\u8207\u65e5\u7cfb\u96dc\u7269\u5e97\u92ea\uff0c\u90fd\u4ee4\u67ef\u6587\u54f2\u7559\u4e0b\u6df1\u523b\u7684\u5370\u8c61\u3002\u5289\u514b\u8944\u4e5f\u8a8d\u70ba\uff0c\u96d9\u9023\u5e02\u5834\u5167\u7684\u9b6f\u8089\u98ef\u3001\u5713\u4ed4\u6e6f\u8207\u5207\u4ed4\u9eb5\uff0c\u9084\u6709\u4e5d\u689d\u901a\u7684\u65e5\u5f0f\u5e97\u5bb6\u3001\u5c45\u9152\u5c4b\u7b49\u7279\u8272\uff0c\u4e5f\u80fd\u8b93\u4eba\u611f\u53d7\u5230\u53f0\u5317\u820a\u57ce\u5340\u4e0d\u4e00\u6a23\u7684\u9b45\u529b\u3002\"\nresult = articut.parse(inputSTR)\nwith open(\"articutResult.json\", \"w\", encoding=\"utf-8\") as resultFile:\n json.dump(result, resultFile, ensure_ascii=False)\n\t\ngraphQLResult = articut.graphQL.query(\n filePath=\"articutResult.json\",\n query=\"\"\"\n\t{\n\t meta {\n\t lang\n\t description\n\t }\n\t doc {\n\t text\n\t ents {\n\t persons {\n\t text\n\t pos_\n\t tag_\n\t }\n\t }\n\t }\n\t}\"\"\")\npprint(graphQLResult)\n```\n\t\n### \u56de\u50b3\u7d50\u679c\n\n\n",
"bugtrack_url": null,
"license": "MIT License",
"summary": "Articut NLP system provides not only finest results on Chinese word segmentaion (CWS), Part-of-Speech tagging (POS) and Named Entity Recogintion tagging (NER), but also the fastest online API service in the NLP industry.",
"version": "1.3.7",
"project_urls": {
"Documentation": "https://api.droidtown.co/ArticutAPI/document/",
"Homepage": "https://github.com/Droidtown/ArticutAPI",
"Source": "https://github.com/Droidtown/ArticutAPI"
},
"split_keywords": [
"nlp",
" nlu",
" cws",
" pos",
" ner",
" ai",
" artificial intelligence",
" chinese word segmentation",
" computational linguistics",
" language",
" linguistics",
" graphql",
" natural language",
" natural language processing",
" natural language understanding",
" parsing",
" part-of-speech-embdding",
" part-of-speech-tagger",
" pos-tagger",
" pos-tagging",
" syntax",
" tagging",
" text analytics"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "14b0eb9d0589d1a99fcc19780f3be8602a813553ca2b265e1154c213f8f0ac91",
"md5": "e9f07b193b5488efdb66a085c740bdef",
"sha256": "ceab56e1767f3e81ace194b49d36d5835168f511e6f6e2f374b29d55ddf9a4fe"
},
"downloads": -1,
"filename": "ArticutAPI-1.3.7-py3-none-any.whl",
"has_sig": false,
"md5_digest": "e9f07b193b5488efdb66a085c740bdef",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.6.1",
"size": 132450,
"upload_time": "2024-11-04T06:47:05",
"upload_time_iso_8601": "2024-11-04T06:47:05.678941Z",
"url": "https://files.pythonhosted.org/packages/14/b0/eb9d0589d1a99fcc19780f3be8602a813553ca2b265e1154c213f8f0ac91/ArticutAPI-1.3.7-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-11-04 06:47:05",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "Droidtown",
"github_project": "ArticutAPI",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "articutapi"
}

