# main_content_extractor
## Description
This library is designed for extracting only the main content from HTML.<br>
It was developed for obtaining information related to LLM and for data input to LangChain and LlamaIndex.<br>
<br>
Since this library contains element information and hierarchy information of HTML, it is useful when utilizing them.<br>
For example, it can be helpful in obtaining a list of links or headers from the main content.<br>
<br>
While `trafilatura` is an excellent library for main content extraction, it has issues such as missing necessary data or inability to output HTML.<br>
To address these problems, this library exists.<br>
<br>
The sequence of main content extraction is as follows:<br>
<br>
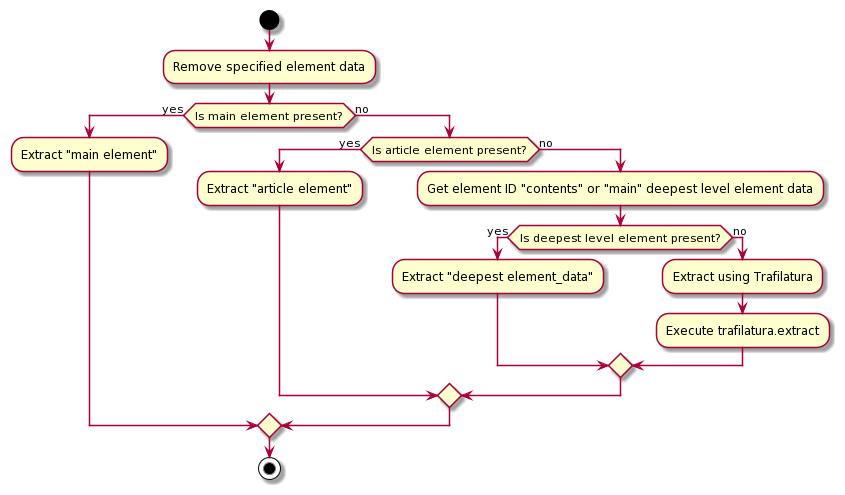
<br>
In addition to HTML format, output in Text format and Markdown format is also supported. This is to make it easier to output data in a format that is more convenient for LLM.<br>
<br>
The extraction of main content uses `trafilatura`.<br>
Since `trafilatura` cannot output in HTML format, it is output in XML format containing HTML information and then converted to HTML.<br>
The conversion from XML to HTML is irreversible and does not perfectly match the original data.<br>
<br>
## Installation
`pip install MainContentExtractor`
## HowToUse
```python
import requests
from main_content_extractor import MainContentExtractor
# Get HTML using requests
url = "https://developer.mozilla.org/ja/docs/Web"
response = requests.get(url)
response.encoding = 'utf-8'
content = response.text
# Get HTML with main content extracted from HTML
extracted_html = MainContentExtractor.extract(content)
# Get HTML with main content extracted from Markdown
extracted_markdown = MainContentExtractor.extract(content, output_format="markdown")
```
Raw data
{
"_id": null,
"home_page": "https://github.com/HawkClaws/main_content_extractor",
"name": "MainContentExtractor",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.6",
"maintainer_email": "",
"keywords": "",
"author": "HawkClaws",
"author_email": "",
"download_url": "https://files.pythonhosted.org/packages/01/de/634b620e845f48bf27cbe66816e60f0fdb12414f77c8916af60aec508b0d/MainContentExtractor-0.0.4.tar.gz",
"platform": null,
"description": "# main_content_extractor\r\n\r\n## Description\r\n\r\nThis library is designed for extracting only the main content from HTML.<br>\r\nIt was developed for obtaining information related to LLM and for data input to LangChain and LlamaIndex.<br>\r\n<br>\r\nSince this library contains element information and hierarchy information of HTML, it is useful when utilizing them.<br>\r\nFor example, it can be helpful in obtaining a list of links or headers from the main content.<br>\r\n<br>\r\nWhile `trafilatura` is an excellent library for main content extraction, it has issues such as missing necessary data or inability to output HTML.<br>\r\nTo address these problems, this library exists.<br>\r\n<br>\r\nThe sequence of main content extraction is as follows:<br>\r\n<br>\r\n\r\n<br>\r\nIn addition to HTML format, output in Text format and Markdown format is also supported. This is to make it easier to output data in a format that is more convenient for LLM.<br>\r\n<br>\r\nThe extraction of main content uses `trafilatura`.<br>\r\nSince `trafilatura` cannot output in HTML format, it is output in XML format containing HTML information and then converted to HTML.<br>\r\nThe conversion from XML to HTML is irreversible and does not perfectly match the original data.<br>\r\n<br>\r\n\r\n## Installation\r\n\r\n`pip install MainContentExtractor`\r\n\r\n## HowToUse\r\n\r\n```python\r\nimport requests\r\nfrom main_content_extractor import MainContentExtractor\r\n\r\n# Get HTML using requests\r\nurl = \"https://developer.mozilla.org/ja/docs/Web\"\r\nresponse = requests.get(url)\r\nresponse.encoding = 'utf-8'\r\ncontent = response.text\r\n\r\n# Get HTML with main content extracted from HTML\r\nextracted_html = MainContentExtractor.extract(content)\r\n\r\n# Get HTML with main content extracted from Markdown\r\nextracted_markdown = MainContentExtractor.extract(content, output_format=\"markdown\")\r\n```\r\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "A library to extract the main content from html. Developed for information on LLM and for feeding data into LangChain and LlamaIndex.",
"version": "0.0.4",
"project_urls": {
"Homepage": "https://github.com/HawkClaws/main_content_extractor",
"Source Code": "https://github.com/HawkClaws/main_content_extractor"
},
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "766232c33101b179d373d753d7c892b19f2ec22978b6c3c36d17a4a61d2169b6",
"md5": "b4b41514a88112eb1b8be45980d83ed2",
"sha256": "77684179436e28eb2e19be26657cb2bbd7c1f9213a2c3ee163a8f9dfbca64107"
},
"downloads": -1,
"filename": "MainContentExtractor-0.0.4-py3-none-any.whl",
"has_sig": false,
"md5_digest": "b4b41514a88112eb1b8be45980d83ed2",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.6",
"size": 5716,
"upload_time": "2023-12-10T08:05:00",
"upload_time_iso_8601": "2023-12-10T08:05:00.086883Z",
"url": "https://files.pythonhosted.org/packages/76/62/32c33101b179d373d753d7c892b19f2ec22978b6c3c36d17a4a61d2169b6/MainContentExtractor-0.0.4-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "01de634b620e845f48bf27cbe66816e60f0fdb12414f77c8916af60aec508b0d",
"md5": "7ee8d9663c17dbb737498d1421c6fd3f",
"sha256": "697acc05909fb2f786d9cf7d4ff5bfbf14e4c3359c3a6eadc7ed4403fc2e66e5"
},
"downloads": -1,
"filename": "MainContentExtractor-0.0.4.tar.gz",
"has_sig": false,
"md5_digest": "7ee8d9663c17dbb737498d1421c6fd3f",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.6",
"size": 5046,
"upload_time": "2023-12-10T08:05:02",
"upload_time_iso_8601": "2023-12-10T08:05:02.155867Z",
"url": "https://files.pythonhosted.org/packages/01/de/634b620e845f48bf27cbe66816e60f0fdb12414f77c8916af60aec508b0d/MainContentExtractor-0.0.4.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-12-10 08:05:02",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "HawkClaws",
"github_project": "main_content_extractor",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "maincontentextractor"
}

