| Name | astrapy JSON |
| Version |
2.0.1
 JSON
JSON |
| download |
| home_page | None |
| Summary | AstraPy is a Pythonic SDK for DataStax Astra and its Data API |
| upload_time | 2025-03-27 17:23:55 |
| maintainer | None |
| docs_url | None |
| author | Stefano Lottini |
| requires_python | <4.0.0,>=3.8.0 |
| license | None |
| keywords |
|
| VCS |
|
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# AstraPy
A pythonic client for [DataStax Astra DB](https://astra.datastax.com).
_This README targets **AstraPy version 2.0+**. Click [here](https://github.com/datastax/astrapy/blob/4601c5fa749925d961de1f114ca27690d1a71b13/README.md) for v1 and [here](https://github.com/datastax/astrapy/blob/cd3f5ce8146093e10a095709c0f5c3f8e3f2c7da/README.md) for the v0 API (which you should not really be using by now)._
## Quickstart
Install with `pip install astrapy`.
Get the *API Endpoint* and the *Token* to your Astra DB instance at [astra.datastax.com](https://astra.datastax.com).
Try the following code after replacing the connection parameters:
```python
from astrapy import DataAPIClient
from astrapy.constants import VectorMetric
from astrapy.ids import UUID
from astrapy.info import CollectionDefinition
ASTRA_DB_APPLICATION_TOKEN = "AstraCS:..."
ASTRA_DB_API_ENDPOINT = "https://01234567-....apps.astra.datastax.com"
# Connect and create the Database object
my_client = DataAPIClient()
my_database = my_client.get_database(
ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
# Create a vector collection
my_collection = my_database.create_collection(
"dreams_collection",
definition=(
CollectionDefinition.builder()
.set_vector_dimension(3)
.set_vector_metric(VectorMetric.COSINE)
.build()
)
)
# Populate the collection with some documents
my_collection.insert_many(
[
{
"_id": UUID("018e65c9-e33d-749b-9386-e848739582f0"),
"summary": "Riding the waves",
"tags": ["sport"],
"$vector": [0, 0.2, 1],
},
{
"summary": "Friendly aliens in town",
"tags": ["scifi"],
"$vector": [-0.3, 0, 0.8],
},
{
"summary": "Meeting Beethoven at the dentist",
"$vector": [0.2, 0.6, 0],
},
],
)
my_collection.update_one(
{"tags": "sport"},
{"$set": {"summary": "Surfers' paradise"}},
)
# Run a vector search
cursor = my_collection.find(
{},
sort={"$vector": [0, 0.2, 0.4]},
limit=2,
include_similarity=True,
)
for result in cursor:
print(f"{result['summary']}: {result['$similarity']}")
# This would print:
# Surfers' paradise: 0.98238194
# Friendly aliens in town: 0.91873914
# Resource cleanup
my_collection.drop()
```
Next steps:
- More info and usage patterns are given in the docstrings of classes and methods
- [Data API reference](https://docs.datastax.com/en/astra-db-serverless/api-reference/overview.html)
- [AstraPy reference](https://docs.datastax.com/en/astra-api-docs/_attachments/python-client/astrapy/index.html)
- Package on [PyPI](https://pypi.org/project/astrapy/)
### Server-side embeddings
AstraPy works with the "vectorize" feature of the Data API. This means that one can define server-side computation for vector embeddings and use text strings in place of a document vector, both in writing and in reading.
The transformation of said text into an embedding is handled by the Data API, using a provider and model you specify.
```python
my_collection = database.create_collection(
"my_vectorize_collection",
definition=(
CollectionDefinition.builder()
.set_vector_service(
provider="example_vendor",
model_name="embedding_model_name",
authentication={"providerKey": "<STORED_API_KEY_NAME>"} # if needed
)
.build()
)
)
my_collection.insert_one({"$vectorize": "text to make into embedding"})
documents = my_collection.find(sort={"$vectorize": "vector search query text"})
```
See the [Data API reference](https://docs.datastax.com/en/astra-db-serverless/databases/embedding-generation.html)
for more on this topic.
### Hybrid search
AstraPy supports the supports the "find and rerank" Data API command,
which performs a hybrid search by combining results from a lexical search
and a vector-based search in a single operation.
```python
r_results = my_collection.find_and_rerank(
sort={"$hybrid": "query text"},
limit=10,
include_scores=True,
)
for r_result in r_results:
print(r_result.document, r_results.scores)
```
The Data API must support the primitive (and one must not have
disabled the feature at collection-creation time).
See the Data API reference, and the docstring for the `find_and_rerank` method,
for more on this topic.
### Using Tables
The example above uses a _collection_, where schemaless "documents" can be stored and retrieved.
Here is an equivalent code that uses Tables, i.e. uniform, structured data where each _row_ has the
same _columns_, which are of a specific type:
```python
from astrapy import DataAPIClient
from astrapy.constants import VectorMetric
from astrapy.data_types import DataAPIVector
from astrapy.info import (
CreateTableDefinition,
ColumnType,
TableVectorIndexDefinition,
TableVectorIndexOptions,
)
ASTRA_DB_APPLICATION_TOKEN = "AstraCS:..."
ASTRA_DB_API_ENDPOINT = "https://01234567-....apps.astra.datastax.com"
# Connect and create the Database object
my_client = DataAPIClient()
my_database = my_client.get_database(
ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
# Create a table and a vector index on it
table_definition = (
CreateTableDefinition.builder()
.add_column("dream_id", ColumnType.INT)
.add_column("summary", ColumnType.TEXT)
.add_set_column("tags", ColumnType.TEXT)
.add_vector_column("dream_vector", dimension=3)
.add_partition_by(["dream_id"])
.build()
)
index_options=TableVectorIndexOptions(
metric=VectorMetric.COSINE,
)
my_table = my_database.create_table("dreams_table", definition=table_definition, if_not_exists=True)
my_table.create_vector_index("dreams_table_vec_idx", column="dream_vector", options=index_options, if_not_exists=True)
# Populate the table with some rows
my_table.insert_many(
[
{
"dream_id": 103,
"summary": "Riding the waves",
"tags": ["sport"],
"dream_vector": DataAPIVector([0, 0.2, 1]),
},
{
"dream_id": 119,
"summary": "Friendly aliens in town",
"tags": ["scifi"],
"dream_vector": DataAPIVector([-0.3, 0, 0.8]),
},
{
"dream_id": 37,
"summary": "Meeting Beethoven at the dentist",
"dream_vector": DataAPIVector([0.2, 0.6, 0]),
},
],
)
my_table.update_one(
{"dream_id": 103},
{"$set": {"summary": "Surfers' paradise"}},
)
# Run a vector search
cursor = my_table.find(
{},
sort={"dream_vector": DataAPIVector([0, 0.2, 0.4])},
limit=2,
include_similarity=True,
)
for result in cursor:
print(f"{result['summary']}: {result['$similarity']}")
# This would print:
# Surfers' paradise: 0.98238194
# Friendly aliens in town: 0.91873914
# Resource cleanup
my_table.drop()
```
For more on Tables, consult the [Data API documentation about Tables](https://docs.datastax.com/en/astra-db-serverless/api-reference/tables.html). Note that most features of Collections, with due modifications, hold for Tables as well (e.g. "vectorize", i.e. server-side embeddings).
#### Maps as association lists
In the Data API, table `map` columns with key of a type other than text
have to be expressed as association lists,
i.e. nested lists of lists: `[[key1, value1], [key2, value2], ...]`.
AstraPy objects can be configured to always do so automatically, for a seamless
experience.
See the API Option `serdes_options.encode_maps_as_lists_in_tables` for details.
### Usage with HCD and other non-Astra installations
The main difference when targeting e.g. a Hyper-Converged Database (HCD)
installation is how the client is
initialized. Here is a short example showing just how to get to a `Database`
(what comes next is unchaged compared to using Astra DB).
```python
from astrapy import DataAPIClient
from astrapy.constants import Environment
from astrapy.authentication import UsernamePasswordTokenProvider
# Build a token
tp = UsernamePasswordTokenProvider("username", "password")
# Initialize the client and get a "Database" object
client = DataAPIClient(environment=Environment.HCD)
database = client.get_database("http://localhost:8181", token=tp)
```
For more on this case, please consult the [dedicated reference](https://docs.datastax.com/en/hyper-converged-database/1.0/connect/python-client.html).
## AstraPy's API
### Abstraction diagram
AstraPy's abstractions for working at the data and admin layers are structured
as depicted by this diagram:

Here's a small admin-oriented example:
```python
from astrapy import DataAPIClient
# this must have "Database Administrator" permissions:
ASTRA_DB_APPLICATION_TOKEN = "AstraCS:..."
my_client = DataAPIClient(ASTRA_DB_APPLICATION_TOKEN)
my_astra_admin = my_client.get_admin()
database_list = list(my_astra_admin.list_databases())
db_info = database_list[0].info
print(db_info.name, db_info.id, db_info.region)
my_database_admin = my_astra_admin.get_database_admin(db_info.id)
my_database_admin.list_keyspaces()
my_database_admin.create_keyspace("my_dreamspace")
```
### Exceptions
The package comes with its own set of exceptions, arranged in this hierarchy:
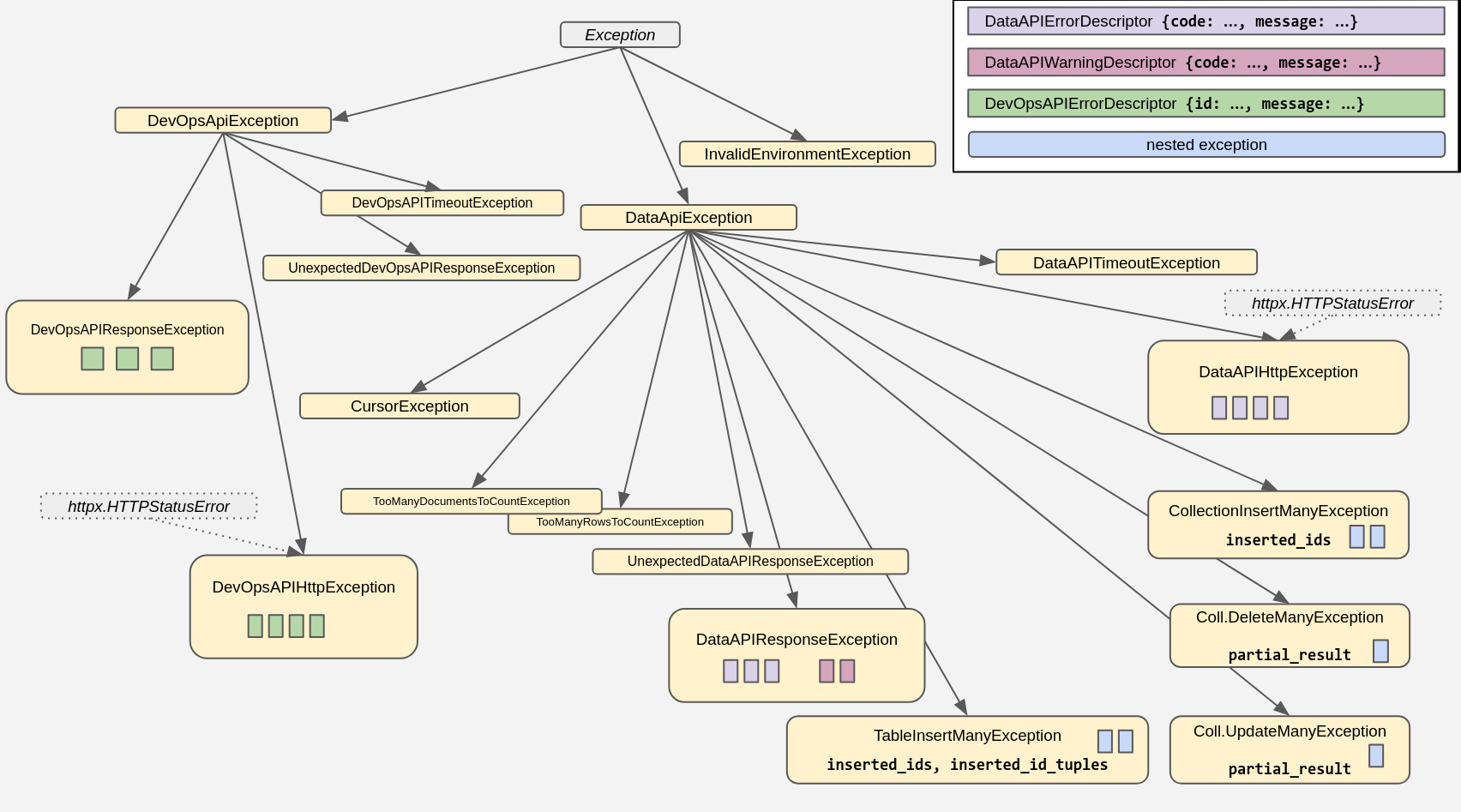
For more information, and code examples, check out the docstrings and consult
the API reference linked above.
### API Options
You can configure many aspects of the interaction with the API by providing
customized "API Options" objects when either spawning a client, copying objects,
or spawning "children classes" (such as a Table from a Database).
For the details, please check the docstring for `astrapy.api_options.APIOptions`
and the other classes in that module. Here is a small example script to show a
practical starting point:
```python
from astrapy import DataAPIClient
from astrapy.api_options import (
APIOptions,
SerdesOptions,
)
# Disable custom datatypes in all reads:
no_cdt_options = APIOptions(
serdes_options=SerdesOptions(
custom_datatypes_in_reading=False,
)
)
my_client = DataAPIClient(api_options=no_cdt_options)
# These spawned objects inherit that setting:
my_database = my_client.get_database(
"https://...",
token="my-token-1",
)
my_table = my_database.get_table("my_table")
```
### Working with dates in Collections and Tables
Date and datetime objects, i.e. instances of the standard library
`datetime.datetime` and `datetime.date` classes, can be used
anywhere when sending documents and queries to the API.
By default, what you get back is an instance of `astrapy.data_types.DataAPITimestamp`
(which has a much wider range of expressable timestamps than Python's stdlib).
If you want to revert to using the standard library `datetime.datetime`, you can do so
by turn on the `APIOptions.SerdesOptions.custom_datatypes_in_reading` API Options setting for the
collection/table object (note that this setting affects the returned format for several other table data types).
If you choose to have timestamps returned as standard-library `datetime.datetime` objects,
both for collections and tables, you may supply a specific timezone for these
(the default is UTC). You do so by providing an appropriate `datetime.timezone` value
to the `APIOptions.SerdesOptions.datetime_tz` API Options setting for the
collection/table object. You can also specify `None` for a timezone, in which case
the resulting values will be timezone-unaware (or "naive") datetimes.
_Naive_ datetimes (i.e. those without a timezone information attached)
are inherently ambiguous when it comes to translating them into a unambiguous timestamp.
For this reason, if you want to work with naive datetimes, and in particular you want
AstraPy to accept them for writes, you need to explicitly
turn on the `APIOptions.SerdesOptions.accept_naive_datetimes` API Options setting for the
collection/table object, otherwise AstraPy will raise an error.
_Remember that what effectively gets_
_written to DB is always a (numeric) **timestamp**: for naive quantities, this timestamp value depends_
_on the implied timezone used in the conversion, potentially leading to unexpected results_
_e.g. if multiple applications are running with different locale settings._
The following diagram summarizes the behaviour of the write and read paths for datetime objects,
depending on the `SerdesOptions` settings:

Here an example code snippet showing how to switch to having reads return regular `datetime` objects
and have them set to one's desired timezone offset:
```python
from datetime import timezone,timedelta
from astrapy import DataAPIClient
from astrapy.api_options import APIOptions, SerdesOptions
my_timezone = timezone(timedelta(hours=4, minutes=30))
my_client = DataAPIClient()
my_database = my_client.get_database(
ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
spawn_api_options=APIOptions(
serdes_options=SerdesOptions(
custom_datatypes_in_reading=False,
datetime_tzinfo=my_timezone,
),
),
)
my_collection = my_database.get_collection("my_collection")
# This document will have datetimes set to the desired timezone
document = my_collection.find_one({"code": 123})
```
### Working with ObjectIds and UUIDs in Collections
Astrapy repackages the ObjectId from `bson` and the UUID class and utilities
from the `uuid` package and its `uuidv6` extension. You can also use them directly.
Even when setting a default ID type for a collection, you still retain the freedom
to use any ID type for any document:
```python
from astrapy import DataAPIClient
from astrapy.constants import DefaultIdType
from astrapy.ids import ObjectId, uuid8, UUID
import bson
ASTRA_DB_APPLICATION_TOKEN = "AstraCS:..."
ASTRA_DB_API_ENDPOINT = "https://01234567-....apps.astra.datastax.com"
my_client = DataAPIClient()
my_database = my_client.get_database(
ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
my_collection = my_database.create_collection(
"ecommerce",
definition=CollectionDefinition.builder().set_default_id(
DefaultIdType.UUIDV6
).build(),
)
my_collection.insert_one({"_id": ObjectId("65fd9b52d7fabba03349d013")})
my_collection.find({
"_id": UUID("018e65c9-e33d-749b-9386-e848739582f0"),
})
my_collection.update_one(
{"tag": "in_stock"},
{"$set": {"inventory_id": bson.objectid.ObjectId()}},
upsert=True,
)
my_collection.insert_one({"_id": uuid8()})
```
### Escaping field names
Field names containing special characters (`.` and `&`) must be correctly escaped
in certain Data API commands. It is a responsibility of the user to ensure escaping
is done when needed; however, AstraPy offers utilities to escape sequences of "path
segments" and -- should it ever be needed -- unescape path-strings back into
literal segments:
```python
from astrapy.utils.document_paths import escape_field_names, unescape_field_path
print(escape_field_names("f1", "f2", 12, "g.&3"))
# prints: f1.f2.12.g&.&&3
print(escape_field_names(["f1", "f2", 12, "g.&3"]))
# prints: f1.f2.12.g&.&&3
print(unescape_field_path("a&&&.b.c.d.12"))
# prints: ['a&.b', 'c', 'd', '12']
```
## For contributors
First install poetry with `pip install poetry` and then the project dependencies with `poetry install --with dev`.
Linter, style and typecheck should all pass for a PR:
```bash
make format
```
With `make format-fix` the style and imports are autofixed (by `ruff`)
Features must be thoroughly covered in tests (have a look at `tests/*` to infer
naming convention and module structure).
### Running tests
Tests are grouped in:
- "base", covering general-purpose astrapy functionality. Divided in unit/integration;
- "vectorize", extensively running a base workload on all provider/integration choices;
- "admin", doing a whole sweep of admin operations. Very slow on Astra DB.
Astrapy's CI only runs "base". The others are to be checked manually when it's needed.
Tests can be run on three types of Data API _targets_ (with slight differences in what is applicable):
- **DockerCompose**: DSE+Data API, started by the test initialization with `docker-compose`. _Note that in this case you will have to manually destroy the created containers._
- **nonAstra**: a ready-to-use (user-supplied) local Data API (e.g. using `tests/dse_compose`)
- **Astra**: an Astra DB target account (or two, as some tests are specific to dev environment)
Depending on the test, different environment variables are needed: refer to
the templates in `tests/env_templates`. The "basic" credentials (one of the three options)
are always required, _even for unit testing_.
#### Sample testing commands
Base:
```
# choose one:
poetry run pytest tests/base
poetry run pytest tests/base/unit
poetry run pytest tests/base/integration
```
Admin:
```
# depending on the environment, different 'admin tests' will run:
poetry run pytest tests/admin
```
Extended vectorize:
```
# very many env. variables required for this one:
poetry run pytest tests/vectorize
# restrict to some combination(s) with e.g.:
EMBEDDING_MODEL_TAGS="openai/text-embedding-3-large/HEADER/0,voyageAI/voyage-finance-2/SHARED_SECRET/f" \
poetry run pytest tests/vectorize/integration/test_vectorize_providers.py \
-k test_vectorize_usage_auth_type_header_sync
```
All the usual `pytest` ways of restricting the test selection hold
(e.g. `poetry run pytest tests/idiomatic/unit` or `[...] -k <test_name_selector>`). Also e.g.:
```
# suppress log noise
poetry run pytest [...] -o log_cli=0
# increase log level
poetry run pytest [...] -o log_cli=1 --log-cli-level=10
```
### Special tests (2025-03-25, Temporary provisions)
Running special tests taking `find_and_rerank` into account, until dev/prod/local discrepancies resolved.
**Prod** (usual CI) just runs as is and skips f.a.r.r.
**Dev** (manual CI on a hybrid-capable cloud Data API). One must:
1. launch integration tests with `ASTRAPY_TEST_FINDANDRERANK=y`
2. ... but also setting "ASTRAPY_TEST_FINDANDRERANK_SUPPRESS_LEXICAL=y" to suppress actual non-null `"$lexical"` sorts, if not rolled out yet.
**Local** (manual CI on a hybrid-capable locally-running Data API). One must:
1. launch integration tests with `ASTRAPY_TEST_FINDANDRERANK=y`
2. ... but also with `ASTRAPY_FINDANDRERANK_USE_RERANKER_HEADER=y` to pass a reranker API key where needed
3. ... which requires an environment variable `HEADER_RERANKING_API_KEY_NVIDIA` to be set with the `AstraCS:...` dev token.
## Appendices
### Appendix A: quick reference for key imports
_Note: check `tests/base/unit/test_imports.py` for more._
Client, data and admin abstractions
```python
from astrapy import (
AstraDBAdmin,
AstraDBDatabaseAdmin,
AsyncCollection,
AsyncDatabase,
AsyncTable,
Collection,
Database,
DataAPIClient,
DataAPIDatabaseAdmin,
Table,
)
```
Constants for data-related use:
```python
from astrapy.constants import (
DefaultIdType,
Environment,
MapEncodingMode,
ReturnDocument,
SortMode,
VectorMetric,
)
```
Cursor for find-like operations:
```python
from astrapy.cursors import (
AbstractCursor,
AsyncCollectionFindAndRerankCursor,
AsyncCollectionFindCursor,
AsyncTableFindCursor,
CollectionFindAndRerankCursor,
CollectionFindCursor,
CursorState,
RerankedResult,
TableFindCursor,
)
```
ObjectIds and UUIDs:
```python
from astrapy.ids import (
UUID,
ObjectId,
uuid1,
uuid3,
uuid4,
uuid5,
uuid6,
uuid7,
uuid8,
)
```
API Options:
```python
from astrapy.api_options import (
APIOptions,
DataAPIURLOptions,
DevOpsAPIURLOptions,
SerdesOptions,
TimeoutOptions,
)
```
Data types:
```python
from astrapy.data_types import (
DataAPITimestamp,
DataAPIVector,
DataAPIDate,
DataAPIDuration,
DataAPIMap,
DataAPISet,
DataAPITime,
)
```
Info/metadata classes:
```python
from astrapy.info import (
AlterTableAddColumns,
AlterTableAddVectorize,
AlterTableDropColumns,
AlterTableDropVectorize,
AstraDBAdminDatabaseInfo,
AstraDBDatabaseInfo,
CollectionDefaultIDOptions,
CollectionDefinition,
CollectionDescriptor,
CollectionInfo,
CollectionLexicalOptions,
CollectionRerankOptions,
CollectionVectorOptions,
ColumnType,
CreateTableDefinition,
EmbeddingProvider,
EmbeddingProviderAuthentication,
EmbeddingProviderModel,
EmbeddingProviderParameter,
EmbeddingProviderToken,
FindEmbeddingProvidersResult,
FindRerankingProvidersResult,
ListTableDefinition,
ListTableDescriptor,
RerankingProvider,
RerankingProviderAuthentication,
RerankingProviderModel,
RerankingProviderParameter,
RerankingProviderToken,
RerankServiceOptions,
TableAPIIndexSupportDescriptor,
TableAPISupportDescriptor,
TableBaseIndexDefinition,
TableIndexDefinition,
TableIndexDescriptor,
TableIndexOptions,
TableInfo,
TableKeyValuedColumnType,
TableKeyValuedColumnTypeDescriptor,
TablePrimaryKeyDescriptor,
TableScalarColumnTypeDescriptor,
TableUnsupportedColumnTypeDescriptor,
TableUnsupportedIndexDefinition,
TableValuedColumnType,
TableValuedColumnTypeDescriptor,
TableVectorColumnTypeDescriptor,
TableVectorIndexDefinition,
TableVectorIndexOptions,
VectorServiceOptions,
)
```
Authentication:
```python
from astrapy.authentication import (
StaticTokenProvider,
UsernamePasswordTokenProvider,
EmbeddingAPIKeyHeaderProvider,
AWSEmbeddingHeadersProvider,
)
```
### Appendix B: compatibility with pre-1.0.0 library
If your code still uses the pre-1.0.0 astrapy (i.e. `from astrapy.db import AstraDB, AstraDBCollection` and so on)
you are strongly advised to migrate to the current API. All of the astrapy pre-1.0 API (later dubbed "core")
works throughout *astrapy v1*, albeit with a deprecation warning on astrapy v. 1.5.
Version 2 drops "core" support entirely. In order to use astrapy version 2.0+, you need to migrate your application.
Check the links at the beginning of this README for the updated documentation and API reference.
Check out previous versions of this README for more on "core": [1.5.2](https://github.com/datastax/astrapy/blob/4601c5fa749925d961de1f114ca27690d1a71b13/README.md) and [pre-1.0](https://github.com/datastax/astrapy/blob/cd3f5ce8146093e10a095709c0f5c3f8e3f2c7da/README.md).
Raw data
{
"_id": null,
"home_page": null,
"name": "astrapy",
"maintainer": null,
"docs_url": null,
"requires_python": "<4.0.0,>=3.8.0",
"maintainer_email": null,
"keywords": null,
"author": "Stefano Lottini",
"author_email": "stefano.lottini@datastax.com",
"download_url": "https://files.pythonhosted.org/packages/0c/c9/5c9488664f99f2b9738d8e4823f8a0474897f39a17c0676430f548834adb/astrapy-2.0.1.tar.gz",
"platform": null,
"description": "# AstraPy\n\nA pythonic client for [DataStax Astra DB](https://astra.datastax.com).\n\n_This README targets **AstraPy version 2.0+**. Click [here](https://github.com/datastax/astrapy/blob/4601c5fa749925d961de1f114ca27690d1a71b13/README.md) for v1 and [here](https://github.com/datastax/astrapy/blob/cd3f5ce8146093e10a095709c0f5c3f8e3f2c7da/README.md) for the v0 API (which you should not really be using by now)._\n\n\n## Quickstart\n\nInstall with `pip install astrapy`.\n\nGet the *API Endpoint* and the *Token* to your Astra DB instance at [astra.datastax.com](https://astra.datastax.com).\n\nTry the following code after replacing the connection parameters:\n\n```python\nfrom astrapy import DataAPIClient\nfrom astrapy.constants import VectorMetric\nfrom astrapy.ids import UUID\nfrom astrapy.info import CollectionDefinition\n\n\nASTRA_DB_APPLICATION_TOKEN = \"AstraCS:...\"\nASTRA_DB_API_ENDPOINT = \"https://01234567-....apps.astra.datastax.com\"\n\n# Connect and create the Database object\nmy_client = DataAPIClient()\nmy_database = my_client.get_database(\n ASTRA_DB_API_ENDPOINT,\n token=ASTRA_DB_APPLICATION_TOKEN,\n)\n\n# Create a vector collection\nmy_collection = my_database.create_collection(\n \"dreams_collection\",\n definition=(\n CollectionDefinition.builder()\n .set_vector_dimension(3)\n .set_vector_metric(VectorMetric.COSINE)\n .build()\n )\n)\n\n# Populate the collection with some documents\nmy_collection.insert_many(\n [\n {\n \"_id\": UUID(\"018e65c9-e33d-749b-9386-e848739582f0\"),\n \"summary\": \"Riding the waves\",\n \"tags\": [\"sport\"],\n \"$vector\": [0, 0.2, 1],\n },\n {\n \"summary\": \"Friendly aliens in town\",\n \"tags\": [\"scifi\"],\n \"$vector\": [-0.3, 0, 0.8],\n },\n {\n \"summary\": \"Meeting Beethoven at the dentist\",\n \"$vector\": [0.2, 0.6, 0],\n },\n ],\n)\n\nmy_collection.update_one(\n {\"tags\": \"sport\"},\n {\"$set\": {\"summary\": \"Surfers' paradise\"}},\n)\n\n# Run a vector search\ncursor = my_collection.find(\n {},\n sort={\"$vector\": [0, 0.2, 0.4]},\n limit=2,\n include_similarity=True,\n)\n\nfor result in cursor:\n print(f\"{result['summary']}: {result['$similarity']}\")\n\n# This would print:\n# Surfers' paradise: 0.98238194\n# Friendly aliens in town: 0.91873914\n\n# Resource cleanup\nmy_collection.drop()\n```\n\nNext steps:\n\n- More info and usage patterns are given in the docstrings of classes and methods\n- [Data API reference](https://docs.datastax.com/en/astra-db-serverless/api-reference/overview.html)\n- [AstraPy reference](https://docs.datastax.com/en/astra-api-docs/_attachments/python-client/astrapy/index.html)\n- Package on [PyPI](https://pypi.org/project/astrapy/)\n\n### Server-side embeddings\n\nAstraPy works with the \"vectorize\" feature of the Data API. This means that one can define server-side computation for vector embeddings and use text strings in place of a document vector, both in writing and in reading.\nThe transformation of said text into an embedding is handled by the Data API, using a provider and model you specify.\n\n```python\nmy_collection = database.create_collection(\n \"my_vectorize_collection\",\n definition=(\n CollectionDefinition.builder()\n .set_vector_service(\n provider=\"example_vendor\",\n model_name=\"embedding_model_name\",\n authentication={\"providerKey\": \"<STORED_API_KEY_NAME>\"} # if needed\n )\n .build()\n )\n)\n\nmy_collection.insert_one({\"$vectorize\": \"text to make into embedding\"})\n\ndocuments = my_collection.find(sort={\"$vectorize\": \"vector search query text\"})\n```\n\nSee the [Data API reference](https://docs.datastax.com/en/astra-db-serverless/databases/embedding-generation.html)\nfor more on this topic.\n\n### Hybrid search\n\nAstraPy supports the supports the \"find and rerank\" Data API command,\nwhich performs a hybrid search by combining results from a lexical search\nand a vector-based search in a single operation.\n\n```python\nr_results = my_collection.find_and_rerank(\n sort={\"$hybrid\": \"query text\"},\n limit=10,\n include_scores=True,\n)\n\nfor r_result in r_results:\n print(r_result.document, r_results.scores)\n```\n\nThe Data API must support the primitive (and one must not have\ndisabled the feature at collection-creation time).\n\nSee the Data API reference, and the docstring for the `find_and_rerank` method,\nfor more on this topic.\n\n### Using Tables\n\nThe example above uses a _collection_, where schemaless \"documents\" can be stored and retrieved.\nHere is an equivalent code that uses Tables, i.e. uniform, structured data where each _row_ has the\nsame _columns_, which are of a specific type:\n\n```python\nfrom astrapy import DataAPIClient\nfrom astrapy.constants import VectorMetric\nfrom astrapy.data_types import DataAPIVector\nfrom astrapy.info import (\n CreateTableDefinition,\n ColumnType,\n TableVectorIndexDefinition,\n TableVectorIndexOptions,\n)\n\n\nASTRA_DB_APPLICATION_TOKEN = \"AstraCS:...\"\nASTRA_DB_API_ENDPOINT = \"https://01234567-....apps.astra.datastax.com\"\n\n# Connect and create the Database object\nmy_client = DataAPIClient()\nmy_database = my_client.get_database(\n ASTRA_DB_API_ENDPOINT,\n token=ASTRA_DB_APPLICATION_TOKEN,\n)\n\n# Create a table and a vector index on it\ntable_definition = (\n CreateTableDefinition.builder()\n .add_column(\"dream_id\", ColumnType.INT)\n .add_column(\"summary\", ColumnType.TEXT)\n .add_set_column(\"tags\", ColumnType.TEXT)\n .add_vector_column(\"dream_vector\", dimension=3)\n .add_partition_by([\"dream_id\"])\n .build()\n)\nindex_options=TableVectorIndexOptions(\n metric=VectorMetric.COSINE,\n)\nmy_table = my_database.create_table(\"dreams_table\", definition=table_definition, if_not_exists=True)\nmy_table.create_vector_index(\"dreams_table_vec_idx\", column=\"dream_vector\", options=index_options, if_not_exists=True)\n\n# Populate the table with some rows\nmy_table.insert_many(\n [\n {\n \"dream_id\": 103,\n \"summary\": \"Riding the waves\",\n \"tags\": [\"sport\"],\n \"dream_vector\": DataAPIVector([0, 0.2, 1]),\n },\n {\n \"dream_id\": 119,\n \"summary\": \"Friendly aliens in town\",\n \"tags\": [\"scifi\"],\n \"dream_vector\": DataAPIVector([-0.3, 0, 0.8]),\n },\n {\n \"dream_id\": 37,\n \"summary\": \"Meeting Beethoven at the dentist\",\n \"dream_vector\": DataAPIVector([0.2, 0.6, 0]),\n },\n ],\n)\n\nmy_table.update_one(\n {\"dream_id\": 103},\n {\"$set\": {\"summary\": \"Surfers' paradise\"}},\n)\n\n# Run a vector search\ncursor = my_table.find(\n {},\n sort={\"dream_vector\": DataAPIVector([0, 0.2, 0.4])},\n limit=2,\n include_similarity=True,\n)\n\nfor result in cursor:\n print(f\"{result['summary']}: {result['$similarity']}\")\n\n# This would print:\n# Surfers' paradise: 0.98238194\n# Friendly aliens in town: 0.91873914\n\n# Resource cleanup\nmy_table.drop()\n```\n\nFor more on Tables, consult the [Data API documentation about Tables](https://docs.datastax.com/en/astra-db-serverless/api-reference/tables.html). Note that most features of Collections, with due modifications, hold for Tables as well (e.g. \"vectorize\", i.e. server-side embeddings).\n\n#### Maps as association lists\n\nIn the Data API, table `map` columns with key of a type other than text\nhave to be expressed as association lists,\ni.e. nested lists of lists: `[[key1, value1], [key2, value2], ...]`.\n\nAstraPy objects can be configured to always do so automatically, for a seamless\nexperience.\nSee the API Option `serdes_options.encode_maps_as_lists_in_tables` for details.\n\n### Usage with HCD and other non-Astra installations\n\nThe main difference when targeting e.g. a Hyper-Converged Database (HCD)\ninstallation is how the client is\ninitialized. Here is a short example showing just how to get to a `Database`\n(what comes next is unchaged compared to using Astra DB).\n\n```python\nfrom astrapy import DataAPIClient\nfrom astrapy.constants import Environment\nfrom astrapy.authentication import UsernamePasswordTokenProvider\n\n\n# Build a token\ntp = UsernamePasswordTokenProvider(\"username\", \"password\")\n\n# Initialize the client and get a \"Database\" object\nclient = DataAPIClient(environment=Environment.HCD)\ndatabase = client.get_database(\"http://localhost:8181\", token=tp)\n```\n\nFor more on this case, please consult the [dedicated reference](https://docs.datastax.com/en/hyper-converged-database/1.0/connect/python-client.html).\n\n## AstraPy's API\n\n### Abstraction diagram\n\nAstraPy's abstractions for working at the data and admin layers are structured\nas depicted by this diagram:\n\n\n\nHere's a small admin-oriented example:\n\n```python\nfrom astrapy import DataAPIClient\n\n\n# this must have \"Database Administrator\" permissions:\nASTRA_DB_APPLICATION_TOKEN = \"AstraCS:...\"\n\nmy_client = DataAPIClient(ASTRA_DB_APPLICATION_TOKEN)\n\nmy_astra_admin = my_client.get_admin()\n\ndatabase_list = list(my_astra_admin.list_databases())\n\ndb_info = database_list[0].info\nprint(db_info.name, db_info.id, db_info.region)\n\nmy_database_admin = my_astra_admin.get_database_admin(db_info.id)\n\nmy_database_admin.list_keyspaces()\nmy_database_admin.create_keyspace(\"my_dreamspace\")\n```\n\n### Exceptions\n\nThe package comes with its own set of exceptions, arranged in this hierarchy:\n\n\n\nFor more information, and code examples, check out the docstrings and consult\nthe API reference linked above.\n\n### API Options\n\nYou can configure many aspects of the interaction with the API by providing\ncustomized \"API Options\" objects when either spawning a client, copying objects,\nor spawning \"children classes\" (such as a Table from a Database).\n\nFor the details, please check the docstring for `astrapy.api_options.APIOptions`\nand the other classes in that module. Here is a small example script to show a\npractical starting point:\n\n```python\nfrom astrapy import DataAPIClient\nfrom astrapy.api_options import (\n APIOptions,\n SerdesOptions,\n)\n\n# Disable custom datatypes in all reads:\nno_cdt_options = APIOptions(\n serdes_options=SerdesOptions(\n custom_datatypes_in_reading=False,\n )\n)\nmy_client = DataAPIClient(api_options=no_cdt_options)\n\n# These spawned objects inherit that setting:\nmy_database = my_client.get_database(\n \"https://...\",\n token=\"my-token-1\",\n)\nmy_table = my_database.get_table(\"my_table\")\n```\n\n### Working with dates in Collections and Tables\n\nDate and datetime objects, i.e. instances of the standard library\n`datetime.datetime` and `datetime.date` classes, can be used\nanywhere when sending documents and queries to the API.\n\nBy default, what you get back is an instance of `astrapy.data_types.DataAPITimestamp`\n(which has a much wider range of expressable timestamps than Python's stdlib).\nIf you want to revert to using the standard library `datetime.datetime`, you can do so\nby turn on the `APIOptions.SerdesOptions.custom_datatypes_in_reading` API Options setting for the\ncollection/table object (note that this setting affects the returned format for several other table data types).\n\nIf you choose to have timestamps returned as standard-library `datetime.datetime` objects,\nboth for collections and tables, you may supply a specific timezone for these\n(the default is UTC). You do so by providing an appropriate `datetime.timezone` value\nto the `APIOptions.SerdesOptions.datetime_tz` API Options setting for the\ncollection/table object. You can also specify `None` for a timezone, in which case\nthe resulting values will be timezone-unaware (or \"naive\") datetimes.\n\n_Naive_ datetimes (i.e. those without a timezone information attached)\nare inherently ambiguous when it comes to translating them into a unambiguous timestamp.\nFor this reason, if you want to work with naive datetimes, and in particular you want\nAstraPy to accept them for writes, you need to explicitly\nturn on the `APIOptions.SerdesOptions.accept_naive_datetimes` API Options setting for the\ncollection/table object, otherwise AstraPy will raise an error.\n\n_Remember that what effectively gets_\n_written to DB is always a (numeric) **timestamp**: for naive quantities, this timestamp value depends_\n_on the implied timezone used in the conversion, potentially leading to unexpected results_\n_e.g. if multiple applications are running with different locale settings._\n\nThe following diagram summarizes the behaviour of the write and read paths for datetime objects,\ndepending on the `SerdesOptions` settings:\n\n\n\nHere an example code snippet showing how to switch to having reads return regular `datetime` objects\nand have them set to one's desired timezone offset:\n\n```python\nfrom datetime import timezone,timedelta\n\nfrom astrapy import DataAPIClient\nfrom astrapy.api_options import APIOptions, SerdesOptions\n\nmy_timezone = timezone(timedelta(hours=4, minutes=30))\n\nmy_client = DataAPIClient()\nmy_database = my_client.get_database(\n ASTRA_DB_API_ENDPOINT,\n token=ASTRA_DB_APPLICATION_TOKEN,\n spawn_api_options=APIOptions(\n serdes_options=SerdesOptions(\n custom_datatypes_in_reading=False,\n datetime_tzinfo=my_timezone,\n ),\n ),\n)\n\nmy_collection = my_database.get_collection(\"my_collection\")\n# This document will have datetimes set to the desired timezone\ndocument = my_collection.find_one({\"code\": 123})\n```\n\n### Working with ObjectIds and UUIDs in Collections\n\nAstrapy repackages the ObjectId from `bson` and the UUID class and utilities\nfrom the `uuid` package and its `uuidv6` extension. You can also use them directly.\n\nEven when setting a default ID type for a collection, you still retain the freedom\nto use any ID type for any document:\n\n```python\nfrom astrapy import DataAPIClient\nfrom astrapy.constants import DefaultIdType\nfrom astrapy.ids import ObjectId, uuid8, UUID\n\nimport bson\n\nASTRA_DB_APPLICATION_TOKEN = \"AstraCS:...\"\nASTRA_DB_API_ENDPOINT = \"https://01234567-....apps.astra.datastax.com\"\n\nmy_client = DataAPIClient()\nmy_database = my_client.get_database(\n ASTRA_DB_API_ENDPOINT,\n token=ASTRA_DB_APPLICATION_TOKEN,\n)\n\nmy_collection = my_database.create_collection(\n \"ecommerce\",\n definition=CollectionDefinition.builder().set_default_id(\n DefaultIdType.UUIDV6\n ).build(),\n)\n\nmy_collection.insert_one({\"_id\": ObjectId(\"65fd9b52d7fabba03349d013\")})\nmy_collection.find({\n \"_id\": UUID(\"018e65c9-e33d-749b-9386-e848739582f0\"),\n})\n\nmy_collection.update_one(\n {\"tag\": \"in_stock\"},\n {\"$set\": {\"inventory_id\": bson.objectid.ObjectId()}},\n upsert=True,\n)\n\nmy_collection.insert_one({\"_id\": uuid8()})\n```\n\n### Escaping field names\n\nField names containing special characters (`.` and `&`) must be correctly escaped\nin certain Data API commands. It is a responsibility of the user to ensure escaping\nis done when needed; however, AstraPy offers utilities to escape sequences of \"path\nsegments\" and -- should it ever be needed -- unescape path-strings back into\nliteral segments:\n\n```python\nfrom astrapy.utils.document_paths import escape_field_names, unescape_field_path\n\nprint(escape_field_names(\"f1\", \"f2\", 12, \"g.&3\"))\n# prints: f1.f2.12.g&.&&3\nprint(escape_field_names([\"f1\", \"f2\", 12, \"g.&3\"]))\n# prints: f1.f2.12.g&.&&3\nprint(unescape_field_path(\"a&&&.b.c.d.12\"))\n# prints: ['a&.b', 'c', 'd', '12']\n```\n\n## For contributors\n\nFirst install poetry with `pip install poetry` and then the project dependencies with `poetry install --with dev`.\n\nLinter, style and typecheck should all pass for a PR:\n\n```bash\nmake format\n```\n\nWith `make format-fix` the style and imports are autofixed (by `ruff`)\n\nFeatures must be thoroughly covered in tests (have a look at `tests/*` to infer\nnaming convention and module structure).\n\n### Running tests\n\nTests are grouped in:\n- \"base\", covering general-purpose astrapy functionality. Divided in unit/integration;\n- \"vectorize\", extensively running a base workload on all provider/integration choices;\n- \"admin\", doing a whole sweep of admin operations. Very slow on Astra DB.\n\nAstrapy's CI only runs \"base\". The others are to be checked manually when it's needed.\n\nTests can be run on three types of Data API _targets_ (with slight differences in what is applicable):\n\n- **DockerCompose**: DSE+Data API, started by the test initialization with `docker-compose`. _Note that in this case you will have to manually destroy the created containers._\n- **nonAstra**: a ready-to-use (user-supplied) local Data API (e.g. using `tests/dse_compose`)\n- **Astra**: an Astra DB target account (or two, as some tests are specific to dev environment)\n\nDepending on the test, different environment variables are needed: refer to\nthe templates in `tests/env_templates`. The \"basic\" credentials (one of the three options)\nare always required, _even for unit testing_.\n\n#### Sample testing commands\n\nBase:\n\n```\n# choose one:\npoetry run pytest tests/base\npoetry run pytest tests/base/unit\npoetry run pytest tests/base/integration\n```\n\nAdmin:\n\n```\n# depending on the environment, different 'admin tests' will run:\npoetry run pytest tests/admin\n```\n\nExtended vectorize:\n\n```\n# very many env. variables required for this one:\npoetry run pytest tests/vectorize\n\n# restrict to some combination(s) with e.g.:\nEMBEDDING_MODEL_TAGS=\"openai/text-embedding-3-large/HEADER/0,voyageAI/voyage-finance-2/SHARED_SECRET/f\" \\\n poetry run pytest tests/vectorize/integration/test_vectorize_providers.py \\\n -k test_vectorize_usage_auth_type_header_sync\n```\n\nAll the usual `pytest` ways of restricting the test selection hold\n(e.g. `poetry run pytest tests/idiomatic/unit` or `[...] -k <test_name_selector>`). Also e.g.:\n\n```\n# suppress log noise\npoetry run pytest [...] -o log_cli=0\n\n# increase log level\npoetry run pytest [...] -o log_cli=1 --log-cli-level=10\n```\n\n### Special tests (2025-03-25, Temporary provisions)\n\nRunning special tests taking `find_and_rerank` into account, until dev/prod/local discrepancies resolved.\n\n**Prod** (usual CI) just runs as is and skips f.a.r.r.\n\n**Dev** (manual CI on a hybrid-capable cloud Data API). One must:\n\n1. launch integration tests with `ASTRAPY_TEST_FINDANDRERANK=y`\n2. ... but also setting \"ASTRAPY_TEST_FINDANDRERANK_SUPPRESS_LEXICAL=y\" to suppress actual non-null `\"$lexical\"` sorts, if not rolled out yet.\n \n**Local** (manual CI on a hybrid-capable locally-running Data API). One must:\n\n1. launch integration tests with `ASTRAPY_TEST_FINDANDRERANK=y`\n2. ... but also with `ASTRAPY_FINDANDRERANK_USE_RERANKER_HEADER=y` to pass a reranker API key where needed\n3. ... which requires an environment variable `HEADER_RERANKING_API_KEY_NVIDIA` to be set with the `AstraCS:...` dev token.\n\n## Appendices\n\n### Appendix A: quick reference for key imports\n\n_Note: check `tests/base/unit/test_imports.py` for more._\n\nClient, data and admin abstractions\n\n```python\nfrom astrapy import (\n AstraDBAdmin,\n AstraDBDatabaseAdmin,\n AsyncCollection,\n AsyncDatabase,\n AsyncTable,\n Collection,\n Database,\n DataAPIClient,\n DataAPIDatabaseAdmin,\n Table,\n)\n```\n\nConstants for data-related use:\n\n```python\nfrom astrapy.constants import (\n DefaultIdType,\n Environment,\n MapEncodingMode,\n ReturnDocument,\n SortMode,\n VectorMetric,\n)\n```\n\nCursor for find-like operations:\n\n```python\nfrom astrapy.cursors import (\n AbstractCursor,\n AsyncCollectionFindAndRerankCursor,\n AsyncCollectionFindCursor,\n AsyncTableFindCursor,\n CollectionFindAndRerankCursor,\n CollectionFindCursor,\n CursorState,\n RerankedResult,\n TableFindCursor,\n)\n```\n\nObjectIds and UUIDs:\n\n```python\nfrom astrapy.ids import (\n UUID,\n ObjectId,\n uuid1,\n uuid3,\n uuid4,\n uuid5,\n uuid6,\n uuid7,\n uuid8,\n)\n```\n\nAPI Options:\n\n```python\nfrom astrapy.api_options import (\n APIOptions,\n DataAPIURLOptions,\n DevOpsAPIURLOptions,\n SerdesOptions,\n TimeoutOptions,\n)\n```\n\nData types:\n\n```python\nfrom astrapy.data_types import (\n DataAPITimestamp,\n DataAPIVector,\n DataAPIDate,\n DataAPIDuration,\n DataAPIMap,\n DataAPISet,\n DataAPITime,\n)\n```\n\nInfo/metadata classes:\n\n```python\nfrom astrapy.info import (\n AlterTableAddColumns,\n AlterTableAddVectorize,\n AlterTableDropColumns,\n AlterTableDropVectorize,\n AstraDBAdminDatabaseInfo,\n AstraDBDatabaseInfo,\n CollectionDefaultIDOptions,\n CollectionDefinition,\n CollectionDescriptor,\n CollectionInfo,\n CollectionLexicalOptions,\n CollectionRerankOptions,\n CollectionVectorOptions,\n ColumnType,\n CreateTableDefinition,\n EmbeddingProvider,\n EmbeddingProviderAuthentication,\n EmbeddingProviderModel,\n EmbeddingProviderParameter,\n EmbeddingProviderToken,\n FindEmbeddingProvidersResult,\n FindRerankingProvidersResult,\n ListTableDefinition,\n ListTableDescriptor,\n RerankingProvider,\n RerankingProviderAuthentication,\n RerankingProviderModel,\n RerankingProviderParameter,\n RerankingProviderToken,\n RerankServiceOptions,\n TableAPIIndexSupportDescriptor,\n TableAPISupportDescriptor,\n TableBaseIndexDefinition,\n TableIndexDefinition,\n TableIndexDescriptor,\n TableIndexOptions,\n TableInfo,\n TableKeyValuedColumnType,\n TableKeyValuedColumnTypeDescriptor,\n TablePrimaryKeyDescriptor,\n TableScalarColumnTypeDescriptor,\n TableUnsupportedColumnTypeDescriptor,\n TableUnsupportedIndexDefinition,\n TableValuedColumnType,\n TableValuedColumnTypeDescriptor,\n TableVectorColumnTypeDescriptor,\n TableVectorIndexDefinition,\n TableVectorIndexOptions,\n VectorServiceOptions,\n)\n```\n\nAuthentication:\n\n```python\nfrom astrapy.authentication import (\n StaticTokenProvider,\n UsernamePasswordTokenProvider,\n EmbeddingAPIKeyHeaderProvider,\n AWSEmbeddingHeadersProvider,\n)\n```\n\n### Appendix B: compatibility with pre-1.0.0 library\n\nIf your code still uses the pre-1.0.0 astrapy (i.e. `from astrapy.db import AstraDB, AstraDBCollection` and so on)\nyou are strongly advised to migrate to the current API. All of the astrapy pre-1.0 API (later dubbed \"core\")\nworks throughout *astrapy v1*, albeit with a deprecation warning on astrapy v. 1.5.\n\nVersion 2 drops \"core\" support entirely. In order to use astrapy version 2.0+, you need to migrate your application.\nCheck the links at the beginning of this README for the updated documentation and API reference.\n\nCheck out previous versions of this README for more on \"core\": [1.5.2](https://github.com/datastax/astrapy/blob/4601c5fa749925d961de1f114ca27690d1a71b13/README.md) and [pre-1.0](https://github.com/datastax/astrapy/blob/cd3f5ce8146093e10a095709c0f5c3f8e3f2c7da/README.md).\n",
"bugtrack_url": null,
"license": null,
"summary": "AstraPy is a Pythonic SDK for DataStax Astra and its Data API",
"version": "2.0.1",
"project_urls": null,
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "906d1481615ec3b97e1b8c9058c43c804e02612642d5114a26812894e42fb9b4",
"md5": "3b889b6fc40082b155285a817dd3c74e",
"sha256": "4fa37f2955e7543a29e78565833de0dc8e39316ccc2f66263a4665b5871b7739"
},
"downloads": -1,
"filename": "astrapy-2.0.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "3b889b6fc40082b155285a817dd3c74e",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": "<4.0.0,>=3.8.0",
"size": 300495,
"upload_time": "2025-03-27T17:23:53",
"upload_time_iso_8601": "2025-03-27T17:23:53.255442Z",
"url": "https://files.pythonhosted.org/packages/90/6d/1481615ec3b97e1b8c9058c43c804e02612642d5114a26812894e42fb9b4/astrapy-2.0.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "0cc95c9488664f99f2b9738d8e4823f8a0474897f39a17c0676430f548834adb",
"md5": "7c086a831ca99f2ebbc8ca2757361bf7",
"sha256": "3a35ebd7af5c24f0abe400f9b2778dc5e8812c78ae247f97704be27e6cb9dc5a"
},
"downloads": -1,
"filename": "astrapy-2.0.1.tar.gz",
"has_sig": false,
"md5_digest": "7c086a831ca99f2ebbc8ca2757361bf7",
"packagetype": "sdist",
"python_version": "source",
"requires_python": "<4.0.0,>=3.8.0",
"size": 252460,
"upload_time": "2025-03-27T17:23:55",
"upload_time_iso_8601": "2025-03-27T17:23:55.462264Z",
"url": "https://files.pythonhosted.org/packages/0c/c9/5c9488664f99f2b9738d8e4823f8a0474897f39a17c0676430f548834adb/astrapy-2.0.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-03-27 17:23:55",
"github": false,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"lcname": "astrapy"
}
