> [!TIP]
> This project is a complementary to the __Protect AI Model__ project that can be found in the [repo](https://github.com/dahmansphi/protectai). To this end, to understand the entire idea you shall make sure to read both documentations.
# About the Package
## Author's Words
Welcome to **the first Edition of ATTACK AI MODEL SIMULATION- attackai Tool** official documentation. I am Dr. Deniz Dahman the creator of the BireyselValue algorithm and the author of this package. In the following section you will have a brief introduction on the principal idea of the __attackai__ tool. In addition, a reference to the academic publication on this potential type of __cyber attack__ and potential __defence__. Before going ahead, I would like to let you know that I have done this work as an independent scientist without any fund or similar capacity.
I am dedicated to proceeding and seek further improvement on the proposed method at all costs. To this end if you wish to contribute in any way to this work, please find further details in the contributing section.
## Contributing
If you wish to contribute to the creator of this project and the author, you may want to check possible ways on:
> `To Contribute in any way possible, thank you, you can check` :
1. view options to subscribe on [Dahman's Phi Services Website](https://dahmansphi.com/subscriptions/)
2. subscribe to this channel [Dahman's Phi Services](https://www.youtube.com/@dahmansphi)
3. you can support on [patreon](https://patreon.com/user?u=118924481)
If you prefer *any other way of contribution*, please feel free to contact me directly on [contact](https://dahmansphi.com/contact/).
*Thank you*
# Introduction
## The Data poisoning
The current revolution of the __AI framework__ has become almost the main element in every solution that we use daily. Many industries heavily rely on those AI models to generate responses accordingly. In fact, it has become a trend that once a product utilizes AI as its backend, then its potential to penetrate marketplace is substantially higher than the one doesn't.
This trend has pushed many industries to consider __the implementation of AI models__ in the tire of their business process. This rush is understandable from the way that those industries believe; for businesses to secure a place in today’s competitive market, they must catch up with the most recent advances in the realm of technology. However, one must ask what is this __AI problem solving paradigm__ anyway?
In my published project [the Big Bang of Data Science](https://dahmansphi.com/the-big-bang-of-data-science/) I do provide a comprehensive answer to this question, from abstract and concrete perspective. But let me just summaries both perspectives in a few lines.
Basically, AI model is a mathematical tool, so to speak. It mainly relies on an important stage, __the training stage__. As a metaphor, imagine it as a human brain that learns over time from the surroundings and the circumstances where it lives. Those surroundings and circumstances are the cultures, beliefs, people, etc. Once this brain is shaped and formed, it starts to make decisions and offers answers. Yet, we from the outside start to judge those decisions and answers and the brain would react to those judgements.
AI models are mimicking such paradigm. The human brain is __the mathematical equation__ of the model, the surroundings and the circumstances are __the training samples__ that we feed to the mathematical equation to learn, the judgements by the surroundings are __the calculation of those misclassified cases__ which known as obtaining the derivatives. Obviously, we then __aim to have a model that can give accurate answers__ with a minimum level of mistakes.
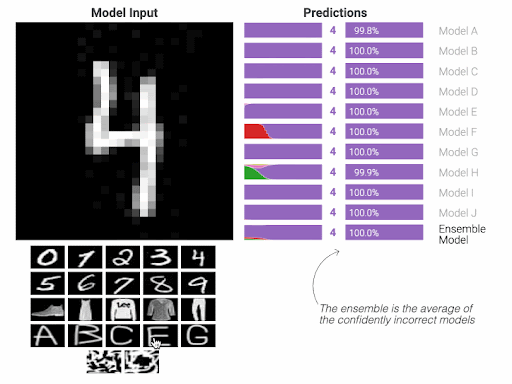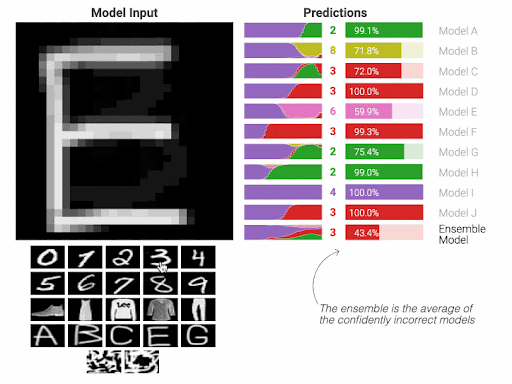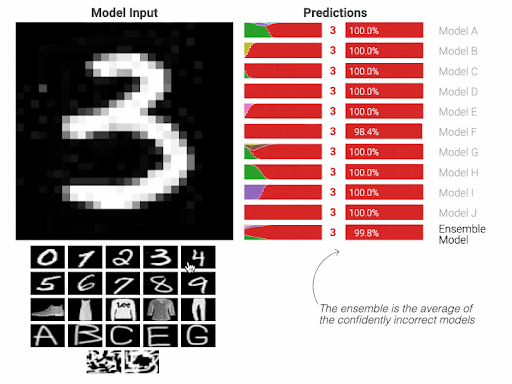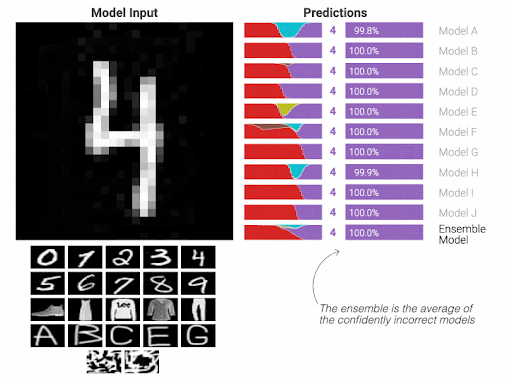
Once the technical workflow of the AI is understood, it should be clear then that the __training samples__ from which the AI model learns are the most important element of this entire flow. This element can be thought of as the __adjudicator__ whether the model will __succeed or fail__.
To this end, such element is a target for __adversaries__ who aim to fail the model. If such __attack__ is successful, then it’s known as __data poisoning attack__.
```Data poisoning is a type of cyberattack in which an adversary intentionally compromises a training dataset used by an AI or machine learning (ML) model to influence or manipulate the operation of that model```
Such type of attack can be done in several ways:
- [x] Intentionally injecting false or misleading information within the training dataset,
- [x] Modifying the existing dataset,
- [x] Deleting a portion of the dataset.
Unfortunately, such __cyber-attack__ could go undetected for so long due to the framework of the AI at the first place. Furthermore, __the lack of fundamental understanding__ of the AI black-box, and the __employing of ready-to-use AI models__ by industry practicians without the comprehensive understanding of the mathematics behind the entire framework.
However, there are some signs that might lead to the observation that the __AI model__ is compromised. Some of those signs are:
1. __Model degradation__: Has the performance of the model inexplicably worsened over time?
Unintended outputs Does the model behave unexpectedly and produce unintended results that cannot be explained by the training team?
2. __Increase in false positives/negatives__: Has the accuracy of the model inexplicably changed over time? Has the user community noticed a sudden spike in problematic or incorrect decisions?
3. __Biased results__: Does the model return results that skew toward a certain direction or demographic (indicating the possibility of bias introduction)?
4. __Breaches or other security events__: Has the organization experienced an attack or security event that could indicate they are an active target and/or that could have created a pathway for adversaries to access and manipulate training data?
5. __Unusual employee activity__: Does an employee show an unusual interest in understanding the intricacies of the training data and/or the security measures employed to protect it?
The following __gif__ illustrates the kind of data poisoning attack on __AI Model__. It basically shows how the __alphas or weights__ are influenced by the new training samples which the model uses __to update itself__.

To this end, such matters must be considered by the company AI division once they decide to employ the __AI problem-solving paradigm__.
## attackai package __version__1.0
To understand the consequence of such an attack, it would be great if available tools could simulate the attack itself. This is where I do introduce the __attackai__ tool. This tool basically illustrates two types of attacks:
1. __corrupt data sample attack__: in this type of attack the attacker manages to corrupt the data sample of __AI model__ during the stage of __AI continues learning__. Basically, the expected workflow of __AI model__ is that after building the first model, it should __continue__ learning from new samples, and as a result the alphas or as known __weights__ of the model will be updated accordingly. Thus, if a new patch of those samples is corrupted in any way, then the __new updated AI model__ will update the weights based on poisoned samples. This is where symptoms of __degraded AI results__ can be observed then.
2. __crazy the model__: this second type of attack is way dangerous than the first one. Let me give you an example, if I would teach the model that a certain image of __dog__ is a __dog label__ and another image of a __cat__ is a __cat label__ then the model will construct its internal __weights__ based on this information. If one manages to __swap__ such labels by classifying a __dog__ as a __cat__ and a __cat__ as a __dog__ then this is where the model could go __crazy__.
> [!IMPORTANT]
> __This tool illustrates the prior two types of attack for an educational purpose ONLY. The author provides NO WARRANTY OF ANY KIND, INCLUDING THE WARRANTY OF DESIGN, MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE__.
# Installation
> [!TIP]
> The simulation using __attackai__ is done on a __binary class__ images dataset, referenced in the below section. The _gif_ illustrations shows the storyline as assumed.

## Data Availability
The NIH chest radiographs that support the findings of this project are publicly available at https://nihcc.app.box.com/v/ChestXray-NIHCC and https://www.kaggle.com/c/rsna-pneumonia-detection-challenge. The Indiana University Hospital Network database is available at https://openi.nlm.nih.gov/. The WCMC pediatric data that support the findings of this study are available in the identifier 10.17632/rscbjbr9sj.3
## Project Setup
### Story line
Basically, the storyline of the simulation is simulated on a __chest X-ray dataset__, outlined [above](#data-availability). The outline of the story goes as follows:
1. A fictious healthcare center is operating as a __chest X-ray__ diagnosis place.
2. In its workflow, called the __old paradigm__, the case _person_ has a chest X-ray scan; then the __scanned image__ is delivered to a domain expert, the Pulmonologist, to examine the image; and finally, the results are presented to the case person.
3. The clinic decides to move to a __new paradigm__, by integrating a new layer for diagnosis that lays between the case input and the domain expert diagnosis. The new proposed block is to implement an __AI agent__ that essentially diagnosis the case and predict its label as __Normal or Pneumonia__, then that will pass to the domain expert to confirm.
### Environment Setup
In the first phase the clinic creates the __AI Model__, that is by following:
1. Main folder that contains subfolders __(train, and test)__; in each there are subfolders of classes for __(normal and pneumonia)__ cases
2. The images basically are transformed into __tensors__ which then are fed into a neural network with x hidden layers, the system works until it produces the main predictive model __x-ray-ai.h5__
3. This model contains the valid __ratios weights__ that done the math to make the predictions
### Pipeline Setup
The AI team then decides to create the pipeline to update the mode as follows:
1. On a weekly basis the new cases are collected
2. Then the same setup as mentioned above is created for the folders
3. The original model then used to make the current update using the new batches of __x-ray images__
4. Technically speaking, that new input will update the model in a way that change the model weights values
### AI Model Poisoning
If the adversary has access to the __weekly sources__ from where the model makes its update, then the model over time will have the bad results of any potential fails to __make the right predictions__. Assume the adversary has that access, then can utilize the __attackai__ to make the attack of any type as outlined in [type one attack](#type-one-attack) or [type two attack](#type-two-attack).
## Install attackai
> [!TIP]
> make sure to create the project setup as outlined [above](#project-setup).
to install the package all what you have to do:
```
pip install attackai
```
You should then be able to use the package. You may want to confirm the installation
```
pip show attackai
```
The result then shall be as:
```
Name: attackai
Version: 1.0.0
Summary: Simulation of poisoning attack on AI model
Home-page: https://github.com/dahmansphi/attackai
Author: Dr. Deniz Dahman's
Author-email: dahmansphi@gmail.com
```
## Employ the attackai -**Conditions**
> [!IMPORTANT]
> It’s mandatory, to use the first edition of attackai, to make sure the __update__ folder that have the subfolders of the __normal and Pneumonia__ as illustrated in the gif above.
## Detour in the attackai package- Build-in
Once your installation is done, and you have met all the conditions, then you may want to check
the build-in functions of the attackai and understand each.
Essentially, if you create an instance from the attackai as so:
```
from attackai import AttackAI
inst = AttackAI()
```
now this **inst** instance offers you access to those build in functions that you need.
this is a screenshot:
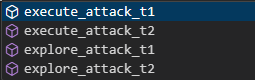
Once you have attackai instance, here are the details of the right sequence to employ the attack:
### type one attack:
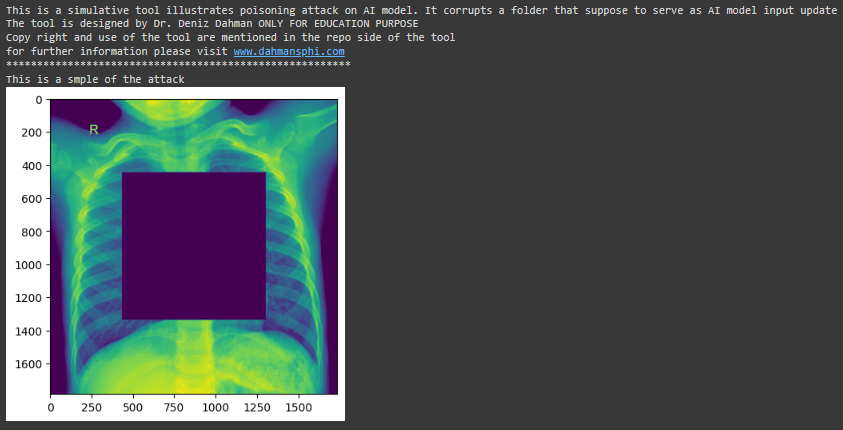
In this attack the aim of the adversary is __to corrupt__ the training sample. To illustrate that; you can first make use of the `explore_attack_t1()` function. The function takes two main args __path to the update folder__ and __size of the attack__. the later implies by how mush you wish to corrupt the image. In addtion, there is an optional arg that is the __stamp__ option, which offers to make stamp on the image which you attack. the follwoing graph illustrate that:
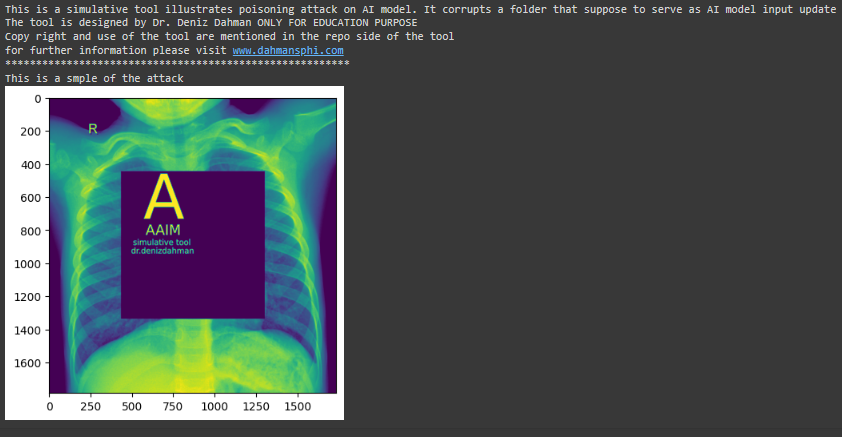
once you justify the result you can __execute the attack__ using the `execute_attack_t1()`, the results of the attack is illustrated in the following graph:

### type two attack:
In this attack the aim of the adversary is __to swap__ the contents of both classes. To illustrate that; you can first make use of the `explore_attack_t2()` function. The function takes ONE main arg __path to the update folder__. the follwoing graph illustrate that:
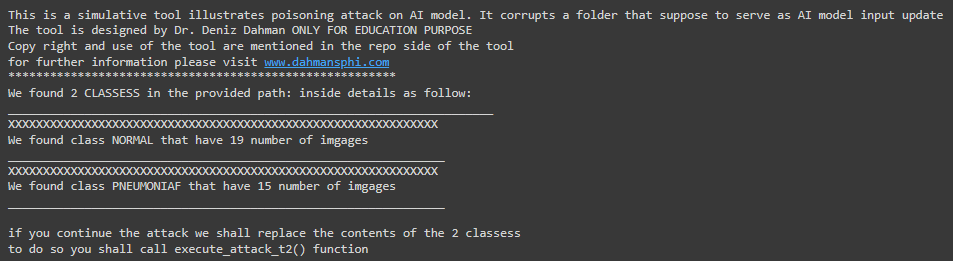
once you justify the result you can __execute the attack__ using the `execute_attack_t2()`.
## Conclusion on installation and employing
Once the attack is done, you need to observe the effect, that is the part where you need to check the documentation of the __protectai__ tool. In the documentation, first I will illustrate the result of both attacks, then I propose the method to make the defense from such attack.
# Reference
please follow up on the project page to find the academic published paper on the project
Raw data
{
"_id": null,
"home_page": null,
"name": "attackai",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.9",
"maintainer_email": null,
"keywords": "Cybersecurity, Machine Learning, Artificial Intelligence, Poisoning attack",
"author": "Dr. Deniz Dahman's",
"author_email": "dahmansphi@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/8a/36/6f93ad9fa1175d7ee65f706a4a846092134e9af10926b9e5360b296b601a/attackai-1.0.0.tar.gz",
"platform": null,
"description": "\r\n> [!TIP]\r\n> This project is a complementary to the __Protect AI Model__ project that can be found in the [repo](https://github.com/dahmansphi/protectai). To this end, to understand the entire idea you shall make sure to read both documentations.\r\n\r\n# About the Package\r\n## Author's Words\r\nWelcome to **the first Edition of ATTACK AI MODEL SIMULATION- attackai Tool** official documentation. I am Dr. Deniz Dahman the creator of the BireyselValue algorithm and the author of this package. In the following section you will have a brief introduction on the principal idea of the __attackai__ tool. In addition, a reference to the academic publication on this potential type of __cyber attack__ and potential __defence__. Before going ahead, I would like to let you know that I have done this work as an independent scientist without any fund or similar capacity. \r\nI am dedicated to proceeding and seek further improvement on the proposed method at all costs. To this end if you wish to contribute in any way to this work, please find further details in the contributing section. \r\n \r\n## Contributing \r\n\r\nIf you wish to contribute to the creator of this project and the author, you may want to check possible ways on: \r\n\r\n> `To Contribute in any way possible, thank you, you can check` :\r\n\r\n1. view options to subscribe on [Dahman's Phi Services Website](https://dahmansphi.com/subscriptions/)\r\n2. subscribe to this channel [Dahman's Phi Services](https://www.youtube.com/@dahmansphi) \r\n3. you can support on [patreon](https://patreon.com/user?u=118924481) \r\n\r\n\r\nIf you prefer *any other way of contribution*, please feel free to contact me directly on [contact](https://dahmansphi.com/contact/). \r\n\r\n*Thank you*\r\n\r\n# Introduction\r\n\r\n## The Data poisoning\r\nThe current revolution of the __AI framework__ has become almost the main element in every solution that we use daily. Many industries heavily rely on those AI models to generate responses accordingly. In fact, it has become a trend that once a product utilizes AI as its backend, then its potential to penetrate marketplace is substantially higher than the one doesn't.\r\n\r\nThis trend has pushed many industries to consider __the implementation of AI models__ in the tire of their business process. This rush is understandable from the way that those industries believe; for businesses to secure a place in today\u2019s competitive market, they must catch up with the most recent advances in the realm of technology. However, one must ask what is this __AI problem solving paradigm__ anyway? \r\n\r\nIn my published project [the Big Bang of Data Science](https://dahmansphi.com/the-big-bang-of-data-science/) I do provide a comprehensive answer to this question, from abstract and concrete perspective. But let me just summaries both perspectives in a few lines. \r\n\r\nBasically, AI model is a mathematical tool, so to speak. It mainly relies on an important stage, __the training stage__. As a metaphor, imagine it as a human brain that learns over time from the surroundings and the circumstances where it lives. Those surroundings and circumstances are the cultures, beliefs, people, etc. Once this brain is shaped and formed, it starts to make decisions and offers answers. Yet, we from the outside start to judge those decisions and answers and the brain would react to those judgements. \r\n\r\nAI models are mimicking such paradigm. The human brain is __the mathematical equation__ of the model, the surroundings and the circumstances are __the training samples__ that we feed to the mathematical equation to learn, the judgements by the surroundings are __the calculation of those misclassified cases__ which known as obtaining the derivatives. Obviously, we then __aim to have a model that can give accurate answers__ with a minimum level of mistakes. \r\n\r\n \r\n\r\nOnce the technical workflow of the AI is understood, it should be clear then that the __training samples__ from which the AI model learns are the most important element of this entire flow. This element can be thought of as the __adjudicator__ whether the model will __succeed or fail__. \r\nTo this end, such element is a target for __adversaries__ who aim to fail the model. If such __attack__ is successful, then it\u2019s known as __data poisoning attack__. \r\n\r\n```Data poisoning is a type of cyberattack in which an adversary intentionally compromises a training dataset used by an AI or machine learning (ML) model to influence or manipulate the operation of that model``` \r\n\r\nSuch type of attack can be done in several ways: \r\n- [x] Intentionally injecting false or misleading information within the training dataset, \r\n- [x] Modifying the existing dataset, \r\n- [x] Deleting a portion of the dataset. \r\n\r\nUnfortunately, such __cyber-attack__ could go undetected for so long due to the framework of the AI at the first place. Furthermore, __the lack of fundamental understanding__ of the AI black-box, and the __employing of ready-to-use AI models__ by industry practicians without the comprehensive understanding of the mathematics behind the entire framework.\r\n\r\nHowever, there are some signs that might lead to the observation that the __AI model__ is compromised. Some of those signs are: \r\n\r\n1. __Model degradation__: Has the performance of the model inexplicably worsened over time?\r\nUnintended outputs\tDoes the model behave unexpectedly and produce unintended results that cannot be explained by the training team?\r\n2. __Increase in false positives/negatives__: Has the accuracy of the model inexplicably changed over time? Has the user community noticed a sudden spike in problematic or incorrect decisions?\r\n3. __Biased results__: Does the model return results that skew toward a certain direction or demographic (indicating the possibility of bias introduction)?\r\n4. __Breaches or other security events__: Has the organization experienced an attack or security event that could indicate they are an active target and/or that could have created a pathway for adversaries to access and manipulate training data?\r\n5. __Unusual employee activity__: Does an employee show an unusual interest in understanding the intricacies of the training data and/or the security measures employed to protect it?\r\n\r\nThe following __gif__ illustrates the kind of data poisoning attack on __AI Model__. It basically shows how the __alphas or weights__ are influenced by the new training samples which the model uses __to update itself__.\r\n\r\n \r\n\r\n\r\nTo this end, such matters must be considered by the company AI division once they decide to employ the __AI problem-solving paradigm__. \r\n\r\n\r\n## attackai package __version__1.0\r\nTo understand the consequence of such an attack, it would be great if available tools could simulate the attack itself. This is where I do introduce the __attackai__ tool. This tool basically illustrates two types of attacks: \r\n\r\n1. __corrupt data sample attack__: in this type of attack the attacker manages to corrupt the data sample of __AI model__ during the stage of __AI continues learning__. Basically, the expected workflow of __AI model__ is that after building the first model, it should __continue__ learning from new samples, and as a result the alphas or as known __weights__ of the model will be updated accordingly. Thus, if a new patch of those samples is corrupted in any way, then the __new updated AI model__ will update the weights based on poisoned samples. This is where symptoms of __degraded AI results__ can be observed then. \r\n\r\n2. __crazy the model__: this second type of attack is way dangerous than the first one. Let me give you an example, if I would teach the model that a certain image of __dog__ is a __dog label__ and another image of a __cat__ is a __cat label__ then the model will construct its internal __weights__ based on this information. If one manages to __swap__ such labels by classifying a __dog__ as a __cat__ and a __cat__ as a __dog__ then this is where the model could go __crazy__. \r\n\r\n> [!IMPORTANT]\r\n> __This tool illustrates the prior two types of attack for an educational purpose ONLY. The author provides NO WARRANTY OF ANY KIND, INCLUDING THE WARRANTY OF DESIGN, MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE__. \r\n\r\n# Installation \r\n> [!TIP]\r\n> The simulation using __attackai__ is done on a __binary class__ images dataset, referenced in the below section. The _gif_ illustrations shows the storyline as assumed.\r\n\r\n\r\n\r\n## Data Availability\r\nThe NIH chest radiographs that support the findings of this project are publicly available at https://nihcc.app.box.com/v/ChestXray-NIHCC and https://www.kaggle.com/c/rsna-pneumonia-detection-challenge. The Indiana University Hospital Network database is available at https://openi.nlm.nih.gov/. The WCMC pediatric data that support the findings of this study are available in the identifier 10.17632/rscbjbr9sj.3\r\n\r\n## Project Setup\r\n### Story line\r\nBasically, the storyline of the simulation is simulated on a __chest X-ray dataset__, outlined [above](#data-availability). The outline of the story goes as follows: \r\n\r\n1. A fictious healthcare center is operating as a __chest X-ray__ diagnosis place. \r\n2. In its workflow, called the __old paradigm__, the case _person_ has a chest X-ray scan; then the __scanned image__ is delivered to a domain expert, the Pulmonologist, to examine the image; and finally, the results are presented to the case person. \r\n3. The clinic decides to move to a __new paradigm__, by integrating a new layer for diagnosis that lays between the case input and the domain expert diagnosis. The new proposed block is to implement an __AI agent__ that essentially diagnosis the case and predict its label as __Normal or Pneumonia__, then that will pass to the domain expert to confirm. \r\n\r\n### Environment Setup\r\nIn the first phase the clinic creates the __AI Model__, that is by following: \r\n1. Main folder that contains subfolders __(train, and test)__; in each there are subfolders of classes for __(normal and pneumonia)__ cases \r\n2. The images basically are transformed into __tensors__ which then are fed into a neural network with x hidden layers, the system works until it produces the main predictive model __x-ray-ai.h5__ \r\n3. This model contains the valid __ratios weights__ that done the math to make the predictions \r\n\r\n### Pipeline Setup\r\nThe AI team then decides to create the pipeline to update the mode as follows: \r\n1. On a weekly basis the new cases are collected \r\n2. Then the same setup as mentioned above is created for the folders \r\n3. The original model then used to make the current update using the new batches of __x-ray images__ \r\n4. Technically speaking, that new input will update the model in a way that change the model weights values \r\n\r\n### AI Model Poisoning \r\nIf the adversary has access to the __weekly sources__ from where the model makes its update, then the model over time will have the bad results of any potential fails to __make the right predictions__. Assume the adversary has that access, then can utilize the __attackai__ to make the attack of any type as outlined in [type one attack](#type-one-attack) or [type two attack](#type-two-attack).\r\n\r\n## Install attackai\r\n\r\n> [!TIP]\r\n> make sure to create the project setup as outlined [above](#project-setup).\r\n\r\nto install the package all what you have to do:\r\n```\r\npip install attackai\r\n```\r\nYou should then be able to use the package. You may want to confirm the installation\r\n\r\n```\r\npip show attackai\r\n```\r\nThe result then shall be as:\r\n\r\n```\r\nName: attackai\r\nVersion: 1.0.0\r\nSummary: Simulation of poisoning attack on AI model\r\nHome-page: https://github.com/dahmansphi/attackai\r\nAuthor: Dr. Deniz Dahman's\r\nAuthor-email: dahmansphi@gmail.com\r\n```\r\n\r\n## Employ the attackai -**Conditions**\r\n\r\n> [!IMPORTANT]\r\n> It\u2019s mandatory, to use the first edition of attackai, to make sure the __update__ folder that have the subfolders of the __normal and Pneumonia__ as illustrated in the gif above. \r\n\r\n## Detour in the attackai package- Build-in\r\nOnce your installation is done, and you have met all the conditions, then you may want to check \r\nthe build-in functions of the attackai and understand each. \r\nEssentially, if you create an instance from the attackai as so: \r\n\r\n```\r\nfrom attackai import AttackAI\r\ninst = AttackAI()\r\n```\r\nnow this **inst** instance offers you access to those build in functions that you need. \r\nthis is a screenshot:\r\n\r\n\r\n\r\nOnce you have attackai instance, here are the details of the right sequence to employ the attack:\r\n\r\n### type one attack:\r\n\r\nIn this attack the aim of the adversary is __to corrupt__ the training sample. To illustrate that; you can first make use of the `explore_attack_t1()` function. The function takes two main args __path to the update folder__ and __size of the attack__. the later implies by how mush you wish to corrupt the image. In addtion, there is an optional arg that is the __stamp__ option, which offers to make stamp on the image which you attack. the follwoing graph illustrate that:\r\n\r\n\r\n\r\n\r\nonce you justify the result you can __execute the attack__ using the `execute_attack_t1()`, the results of the attack is illustrated in the following graph:\r\n\r\n\r\n### type two attack:\r\nIn this attack the aim of the adversary is __to swap__ the contents of both classes. To illustrate that; you can first make use of the `explore_attack_t2()` function. The function takes ONE main arg __path to the update folder__. the follwoing graph illustrate that:\r\n\r\n\r\n\r\nonce you justify the result you can __execute the attack__ using the `execute_attack_t2()`. \r\n\r\n## Conclusion on installation and employing \r\nOnce the attack is done, you need to observe the effect, that is the part where you need to check the documentation of the __protectai__ tool. In the documentation, first I will illustrate the result of both attacks, then I propose the method to make the defense from such attack. \r\n\r\n\r\n\r\n# Reference\r\n\r\nplease follow up on the project page to find the academic published paper on the project\r\n \r\n",
"bugtrack_url": null,
"license": null,
"summary": "Simulation of poisoning attack on AI model",
"version": "1.0.0",
"project_urls": {
"Project": "https://dahmansphi.com/attackai",
"Source": "https://github.com/dahmansphi/attackai"
},
"split_keywords": [
"cybersecurity",
" machine learning",
" artificial intelligence",
" poisoning attack"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "fae7b28e8a77c5d534a20db104d7c933f3ebec423731fb4cfa4228ccc9de037e",
"md5": "f3be5c1852894ae90554f5df243d97c6",
"sha256": "8bee1429aac641769303fb5c0c5a7cdef0bd5c006156fda376c057def0dc343f"
},
"downloads": -1,
"filename": "attackai-1.0.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "f3be5c1852894ae90554f5df243d97c6",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.9",
"size": 21673,
"upload_time": "2024-05-05T13:25:04",
"upload_time_iso_8601": "2024-05-05T13:25:04.636534Z",
"url": "https://files.pythonhosted.org/packages/fa/e7/b28e8a77c5d534a20db104d7c933f3ebec423731fb4cfa4228ccc9de037e/attackai-1.0.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "8a366f93ad9fa1175d7ee65f706a4a846092134e9af10926b9e5360b296b601a",
"md5": "f6731dc48d290f56cab00eacb866122f",
"sha256": "97651af15e911469d3596bbd27fe2f97e8196a756e7587991a4dede38283993f"
},
"downloads": -1,
"filename": "attackai-1.0.0.tar.gz",
"has_sig": false,
"md5_digest": "f6731dc48d290f56cab00eacb866122f",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.9",
"size": 27290,
"upload_time": "2024-05-05T13:25:06",
"upload_time_iso_8601": "2024-05-05T13:25:06.254614Z",
"url": "https://files.pythonhosted.org/packages/8a/36/6f93ad9fa1175d7ee65f706a4a846092134e9af10926b9e5360b296b601a/attackai-1.0.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-05-05 13:25:06",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "dahmansphi",
"github_project": "attackai",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "attackai"
}

