<!--
Title: AWS InsuranceLake
Description: Serverless modern data lake solution and reference architecture fit for the insurance industry built on AWS
Author: cvisi@amazon.com
-->
# InsuranceLake Infrastructure
## Overview
This solution guidance helps you deploy extract, transform, load (ETL) processes and data storage resources to create InsuranceLake. It uses Amazon Simple Storage Service (Amazon S3) buckets for storage, [AWS Glue](https://docs.aws.amazon.com/glue/) for data transformation, and [AWS Cloud Development Kit (CDK) Pipelines](https://docs.aws.amazon.com/cdk/latest/guide/cdk_pipeline.html). The solution is originally based on the AWS blog [Deploy data lake ETL jobs using CDK Pipelines](https://aws.amazon.com/blogs/devops/deploying-data-lake-etl-jobs-using-cdk-pipelines/).
The best way to learn about InsuranceLake is to follow the [Quickstart guide](https://aws-solutions-library-samples.github.io/aws-insurancelake-etl/quickstart/) and try it out.
The InsuranceLake solution is comprised of two codebases: [Infrastructure](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure) and [ETL](https://github.com/aws-solutions-library-samples/aws-insurancelake-etl).
Specifically, this solution helps you to:
* Deploy a "3 Cs" (Collect, Cleanse, Consume) architecture InsuranceLake.
* Deploy ETL jobs needed to make common insurance industry data souces available in a data lake.
* Use pySpark Glue jobs and supporting resoures to perform data transforms in a modular approach.
* Build and replicate the application in multiple environments quickly.
* Deploy ETL jobs from a central deployment account to multiple AWS environments such as Dev, Test, and Prod.
* Leverage the benefit of self-mutating feature of CDK Pipelines; specifically, the pipeline itself is infrastructure as code and can be changed as part of the deployment.
* Increase the speed of prototyping, testing, and deployment of new ETL jobs.
---
## Contents
* [Architecture](#architecture)
* [Collect, Cleanse, Consume](#collect-cleanse-consume)
* [Infrastructure](#infrastructure)
* [Codebase](#codebase)
* [Source code Structure](#source-code-structure)
* [Automation Scripts](#automation-scripts)
* [Authors and Reviewers](#authors-and-reviewers)
* [License Summary](#license-summary)
---
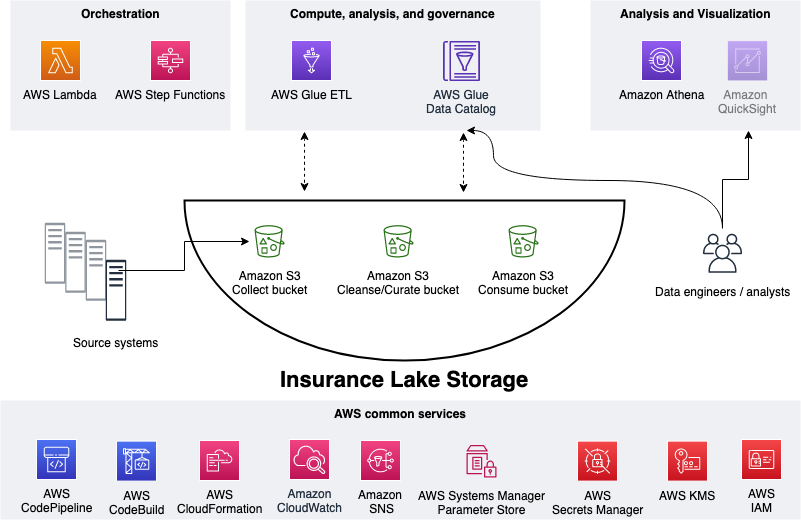
## Architecture
This section explains the overall InsuranceLake architecture and the components of the infrastructure.
### Collect, Cleanse, Consume
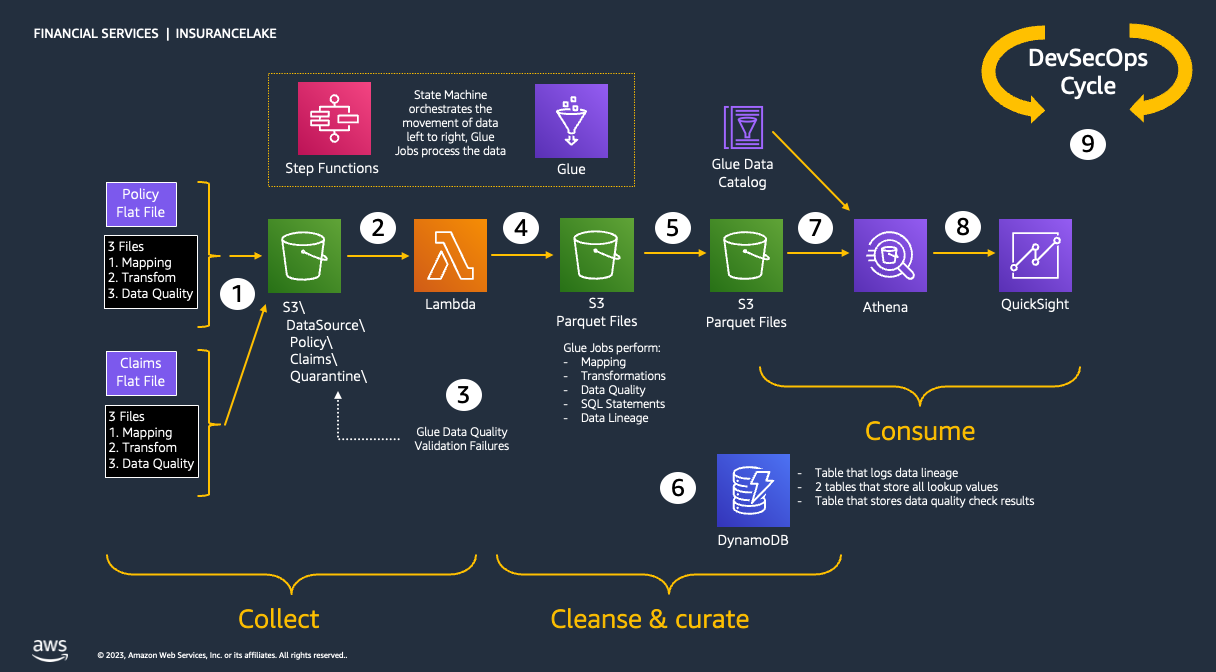
As shown in the figure below, we use S3 for storage, specifically three different S3 buckets:
1. Collect bucket to store raw data in its original format.
1. Cleanse/Curate bucket to store the data that meets the quality and consistency requirements for the data source.
1. Consume bucket for data that is used by analysts and data consumers (for example, Amazon Quicksight, Amazon Sagemaker).
InsuranceLake is designed to support a number of source systems with different file formats and data partitions. To demonstrate, we have provided a CSV parser and sample data files for a source system with two data tables, which are uploaded to the Collect bucket.
We use AWS Lambda and AWS Step Functions for orchestration and scheduling of ETL workloads. We then use AWS Glue with PySpark for ETL and data cataloging, Amazon DynamoDB for transformation persistence, Amazon Athena for interactive queries and analysis. We use various AWS services for logging, monitoring, security, authentication, authorization, notification, build, and deployment.
**Note:** [AWS Lake Formation](https://aws.amazon.com/lake-formation/) is a service that makes it easy to set up a secure data lake in days. [Amazon QuickSight](https://aws.amazon.com/quicksight/) is a scalable, serverless, embeddable, machine learning-powered business intelligence (BI) service built for the cloud. [Amazon DataZone](https://aws.amazon.com/datazone/) is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources. These three services are not used in this solution but can be added.
---
### Infrastructure
The figure below represents the infrastructure resources we provision for the data lake.
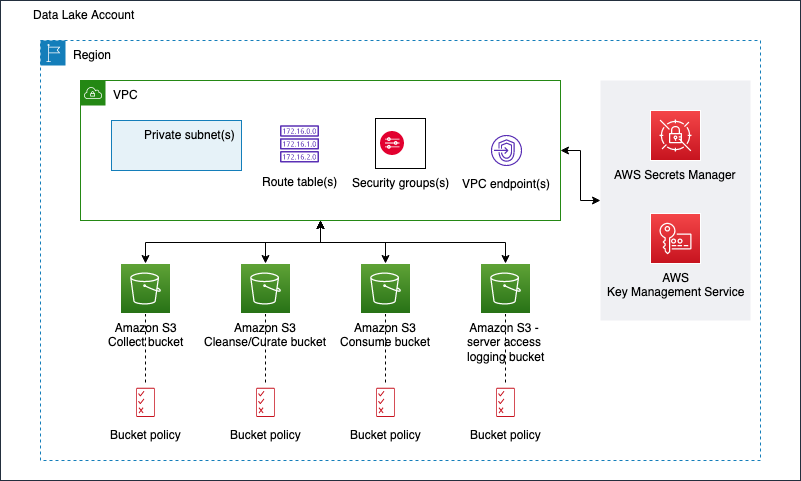
* S3 buckets for:
* Collected (raw) data
* Cleansed and Curated data
* Consume-ready (prepared) data
* Server access logging
* Optional Amazon Virtual Private Cloud (Amazon VPC)
* Subnets
* Security groups
* Route table(s)
* Amazon VPC endpoints
* Supporting services, such as AWS Key Management Service (KMS)
---
## Codebase
### Source Code Structure
The table below explains how this source code is structured.
| File / Folder | Description
|------------------| -------------
| [app.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/app.py) | Application entry point
| [code_commit_stack.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/code_commit_stack.py) | Optional stack to deploy an empty CodeCommit respository for mirroring
| [pipeline_stack.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/pipeline_stack.py) | CodePipeline stack entry point
| [pipeline_deploy_stage.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/pipeline_deploy_stage.py) | CodePipeline deploy stage entry point
| [s3_bucket_zones_stack.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/s3_bucket_zones_stack.py) | Stack to create three S3 buckets (Collect, Cleanse, and Consume), supporting S3 bucket for server access logging, and KMS Key to enable server side encryption for all buckets
| [vpc_stack.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/vpc_stack.py) | Stack to create all resources related to Amazon VPC, including virtual private clouds across multiple availability zones (AZs), security groups, and Amazon VPC endpoints
| [test](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/test)| This folder contains pytest unit tests
| [resources](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/resources)| This folder has static resources such as architecture diagrams
---
### Automation scripts
The table below lists the automation scripts to complete steps before the deployment.
| Script | Purpose
|-----------| -------------
| [bootstrap_deployment_account.sh](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/prerequisites/bootstrap_deployment_account.sh) | Used to bootstrap deployment account
| [bootstrap_target_account.sh](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/prerequisites/bootstrap_target_account.sh) | Used to bootstrap target environments for example dev, test, and production
| [configure_account_secrets.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/prerequisites/configure_account_secrets.py) | Used to configure account secrets for GitHub access token
---
## Authors
The following people are involved in the design, architecture, development, testing, and review of this solution:
* **Cory Visi**, Senior Solutions Architect, Amazon Web Services
* **Ratnadeep Bardhan Roy**, Senior Solutions Architect, Amazon Web Services
* **Jose Guay**, Enterprise Support, Amazon Web Services
* **Isaiah Grant**, Cloud Consultant, 2nd Watch, Inc.
* **Muhammad Zahid Ali**, Data Architect, Amazon Web Services
* **Ravi Itha**, Senior Data Architect, Amazon Web Services
* **Justiono Putro**, Cloud Infrastructure Architect, Amazon Web Services
* **Mike Apted**, Principal Solutions Architect, Amazon Web Services
* **Nikunj Vaidya**, Senior DevOps Specialist, Amazon Web Services
---
## License Summary
This sample code is made available under the MIT-0 license. See the LICENSE file.
Copyright Amazon.com and its affiliates; all rights reserved. This file is Amazon Web Services Content and may not be duplicated or distributed without permission.
Raw data
{
"_id": null,
"home_page": "https://github.com/aws-samples/aws-insurancelake-infrastructure",
"name": "aws-insurancelake-infrastructure",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.9",
"maintainer_email": null,
"keywords": "aws-insurancelake-infrastructure aws cdk insurance datalake s3 vpc python",
"author": "Cory Visi <cvisi@amazon.com>, Ratnadeep Bardhan Roy <rdbroy@amazon.com>, Jose Guay <jrguay@amazon.com>, Isaiah Grant <igrant@2ndwatch.com>, Ravi Itha <itharav@amazon.com>, Zahid Muhammad Ali <zhidli@amazon.com>",
"author_email": null,
"download_url": "https://files.pythonhosted.org/packages/46/30/606fc4e49ef671c9f7338eb67577654d172c5eec1cd76e50bf8dbea712e0/aws_insurancelake_infrastructure-4.1.2.tar.gz",
"platform": null,
"description": "<!--\n Title: AWS InsuranceLake\n Description: Serverless modern data lake solution and reference architecture fit for the insurance industry built on AWS\n Author: cvisi@amazon.com\n -->\n# InsuranceLake Infrastructure\n\n## Overview\n\nThis solution guidance helps you deploy extract, transform, load (ETL) processes and data storage resources to create InsuranceLake. It uses Amazon Simple Storage Service (Amazon S3) buckets for storage, [AWS Glue](https://docs.aws.amazon.com/glue/) for data transformation, and [AWS Cloud Development Kit (CDK) Pipelines](https://docs.aws.amazon.com/cdk/latest/guide/cdk_pipeline.html). The solution is originally based on the AWS blog [Deploy data lake ETL jobs using CDK Pipelines](https://aws.amazon.com/blogs/devops/deploying-data-lake-etl-jobs-using-cdk-pipelines/).\n\nThe best way to learn about InsuranceLake is to follow the [Quickstart guide](https://aws-solutions-library-samples.github.io/aws-insurancelake-etl/quickstart/) and try it out.\n\nThe InsuranceLake solution is comprised of two codebases: [Infrastructure](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure) and [ETL](https://github.com/aws-solutions-library-samples/aws-insurancelake-etl).\n\nSpecifically, this solution helps you to:\n\n* Deploy a \"3 Cs\" (Collect, Cleanse, Consume) architecture InsuranceLake.\n* Deploy ETL jobs needed to make common insurance industry data souces available in a data lake.\n* Use pySpark Glue jobs and supporting resoures to perform data transforms in a modular approach.\n* Build and replicate the application in multiple environments quickly.\n* Deploy ETL jobs from a central deployment account to multiple AWS environments such as Dev, Test, and Prod.\n* Leverage the benefit of self-mutating feature of CDK Pipelines; specifically, the pipeline itself is infrastructure as code and can be changed as part of the deployment.\n* Increase the speed of prototyping, testing, and deployment of new ETL jobs.\n\n\n\n---\n\n## Contents\n\n* [Architecture](#architecture)\n * [Collect, Cleanse, Consume](#collect-cleanse-consume)\n * [Infrastructure](#infrastructure)\n* [Codebase](#codebase)\n * [Source code Structure](#source-code-structure)\n * [Automation Scripts](#automation-scripts)\n * [Authors and Reviewers](#authors-and-reviewers)\n* [License Summary](#license-summary)\n\n---\n\n## Architecture\n\nThis section explains the overall InsuranceLake architecture and the components of the infrastructure.\n\n### Collect, Cleanse, Consume\n\nAs shown in the figure below, we use S3 for storage, specifically three different S3 buckets:\n1. Collect bucket to store raw data in its original format.\n1. Cleanse/Curate bucket to store the data that meets the quality and consistency requirements for the data source.\n1. Consume bucket for data that is used by analysts and data consumers (for example, Amazon Quicksight, Amazon Sagemaker).\n\nInsuranceLake is designed to support a number of source systems with different file formats and data partitions. To demonstrate, we have provided a CSV parser and sample data files for a source system with two data tables, which are uploaded to the Collect bucket.\n\nWe use AWS Lambda and AWS Step Functions for orchestration and scheduling of ETL workloads. We then use AWS Glue with PySpark for ETL and data cataloging, Amazon DynamoDB for transformation persistence, Amazon Athena for interactive queries and analysis. We use various AWS services for logging, monitoring, security, authentication, authorization, notification, build, and deployment.\n\n**Note:** [AWS Lake Formation](https://aws.amazon.com/lake-formation/) is a service that makes it easy to set up a secure data lake in days. [Amazon QuickSight](https://aws.amazon.com/quicksight/) is a scalable, serverless, embeddable, machine learning-powered business intelligence (BI) service built for the cloud. [Amazon DataZone](https://aws.amazon.com/datazone/) is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources. These three services are not used in this solution but can be added.\n\n\n\n---\n\n### Infrastructure\n\nThe figure below represents the infrastructure resources we provision for the data lake.\n\n\n\n* S3 buckets for:\n * Collected (raw) data\n * Cleansed and Curated data\n * Consume-ready (prepared) data\n * Server access logging\n* Optional Amazon Virtual Private Cloud (Amazon VPC)\n * Subnets\n * Security groups\n * Route table(s)\n * Amazon VPC endpoints\n* Supporting services, such as AWS Key Management Service (KMS)\n\n---\n\n## Codebase\n\n### Source Code Structure\n\nThe table below explains how this source code is structured.\n\n| File / Folder | Description\n|------------------| -------------\n| [app.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/app.py) | Application entry point \n| [code_commit_stack.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/code_commit_stack.py) | Optional stack to deploy an empty CodeCommit respository for mirroring\n| [pipeline_stack.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/pipeline_stack.py) | CodePipeline stack entry point\n| [pipeline_deploy_stage.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/pipeline_deploy_stage.py) | CodePipeline deploy stage entry point\n| [s3_bucket_zones_stack.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/s3_bucket_zones_stack.py) | Stack to create three S3 buckets (Collect, Cleanse, and Consume), supporting S3 bucket for server access logging, and KMS Key to enable server side encryption for all buckets\n| [vpc_stack.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/vpc_stack.py) | Stack to create all resources related to Amazon VPC, including virtual private clouds across multiple availability zones (AZs), security groups, and Amazon VPC endpoints\n| [test](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/test)| This folder contains pytest unit tests\n| [resources](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/resources)| This folder has static resources such as architecture diagrams\n\n---\n\n### Automation scripts\n\nThe table below lists the automation scripts to complete steps before the deployment.\n\n| Script | Purpose\n|-----------| -------------\n| [bootstrap_deployment_account.sh](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/prerequisites/bootstrap_deployment_account.sh) | Used to bootstrap deployment account\n| [bootstrap_target_account.sh](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/prerequisites/bootstrap_target_account.sh) | Used to bootstrap target environments for example dev, test, and production\n| [configure_account_secrets.py](https://github.com/aws-solutions-library-samples/aws-insurancelake-infrastructure/blob/main/lib/prerequisites/configure_account_secrets.py) | Used to configure account secrets for GitHub access token\n\n---\n\n## Authors\n\nThe following people are involved in the design, architecture, development, testing, and review of this solution:\n\n* **Cory Visi**, Senior Solutions Architect, Amazon Web Services\n* **Ratnadeep Bardhan Roy**, Senior Solutions Architect, Amazon Web Services\n* **Jose Guay**, Enterprise Support, Amazon Web Services\n* **Isaiah Grant**, Cloud Consultant, 2nd Watch, Inc.\n* **Muhammad Zahid Ali**, Data Architect, Amazon Web Services\n* **Ravi Itha**, Senior Data Architect, Amazon Web Services\n* **Justiono Putro**, Cloud Infrastructure Architect, Amazon Web Services\n* **Mike Apted**, Principal Solutions Architect, Amazon Web Services\n* **Nikunj Vaidya**, Senior DevOps Specialist, Amazon Web Services\n\n---\n\n## License Summary\n\nThis sample code is made available under the MIT-0 license. See the LICENSE file.\n\nCopyright Amazon.com and its affiliates; all rights reserved. This file is Amazon Web Services Content and may not be duplicated or distributed without permission.\n",
"bugtrack_url": null,
"license": "MIT-0",
"summary": "A CDK Python app for deploying foundational infrastructure for InsuranceLake in AWS",
"version": "4.1.2",
"project_urls": {
"Homepage": "https://github.com/aws-samples/aws-insurancelake-infrastructure"
},
"split_keywords": [
"aws-insurancelake-infrastructure",
"aws",
"cdk",
"insurance",
"datalake",
"s3",
"vpc",
"python"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "c43e0cc797ec368dc28d5526b60b5ae7ce84789c3feeaefd8f308e497985bb64",
"md5": "a3b71c6e4988e25e65557070d7e1f0ed",
"sha256": "83aad4160a14394654be644829b0ac3576fe0b5dcac3a550f9e9114cbb8eef6b"
},
"downloads": -1,
"filename": "aws_insurancelake_infrastructure-4.1.2-py3-none-any.whl",
"has_sig": false,
"md5_digest": "a3b71c6e4988e25e65557070d7e1f0ed",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.9",
"size": 22298,
"upload_time": "2024-10-08T16:01:05",
"upload_time_iso_8601": "2024-10-08T16:01:05.802156Z",
"url": "https://files.pythonhosted.org/packages/c4/3e/0cc797ec368dc28d5526b60b5ae7ce84789c3feeaefd8f308e497985bb64/aws_insurancelake_infrastructure-4.1.2-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "4630606fc4e49ef671c9f7338eb67577654d172c5eec1cd76e50bf8dbea712e0",
"md5": "796f078e6130ddd509009f715947fd25",
"sha256": "6c103d73b4a621999a6d465f702a6e48f4e4374f2d301df89cf5d26e44edf7d7"
},
"downloads": -1,
"filename": "aws_insurancelake_infrastructure-4.1.2.tar.gz",
"has_sig": false,
"md5_digest": "796f078e6130ddd509009f715947fd25",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.9",
"size": 21190,
"upload_time": "2024-10-08T16:01:06",
"upload_time_iso_8601": "2024-10-08T16:01:06.735969Z",
"url": "https://files.pythonhosted.org/packages/46/30/606fc4e49ef671c9f7338eb67577654d172c5eec1cd76e50bf8dbea712e0/aws_insurancelake_infrastructure-4.1.2.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-10-08 16:01:06",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "aws-samples",
"github_project": "aws-insurancelake-infrastructure",
"travis_ci": false,
"coveralls": true,
"github_actions": true,
"requirements": [],
"lcname": "aws-insurancelake-infrastructure"
}


