| Name | botasaurus2 JSON |
| Version |
1.4.13
 JSON
JSON |
| download |
| home_page | None |
| Summary | Patching fork of botasaurus, The All in One Framework to build Awesome Scrapers. |
| upload_time | 2024-06-18 18:44:06 |
| maintainer | None |
| docs_url | None |
| author | Chetan Jain |
| requires_python | <4.0,>=3.10 |
| license | MIT |
| keywords |
|
| VCS |
|
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
<p align="center">
<img src="https://raw.githubusercontent.com/omkarcloud/botasaurus/master/images/mascot.png" alt="botasaurus" />
</p>
<div align="center" style="margin-top: 0;">
<h1>🤖 Botasaurus 🤖</h1>
</div>
<h3 align="center">
The All in One Framework to build Awesome Scrapers.
</h3>
<p align="center">
<b>The web has evolved. Finally, web scraping has too.</b>
</p>
<p align="center">
<img src="https://views.whatilearened.today/views/github/omkarcloud/botasaurus.svg" width="80px" height="28px" alt="View" />
</p>
<p align="center">
<a href="https://gitpod.io/#https://github.com/omkarcloud/botasaurus-starter">
<img alt="Run in Gitpod" src="https://gitpod.io/button/open-in-gitpod.svg" />
</a>
</p>
## In a nutshell
Botasaurus is an all-in-one web scraping framework that enables you to build awesome scrapers in less time. It solves the key pain points that we, as developers, face when scraping the modern web.
Our mission is to make creating awesome scrapers easy for everyone.
## Features
Botasaurus is built for creating awesome scrapers. It comes fully baked, with batteries included. Here is a list of things it can do that no other web scraping framework can:
- **Most Stealthiest Framework LITERALLY**: Based on the benchmarks, which we encourage you to read [here](https://github.com/omkarcloud/botasaurus-vs-undetected-chromedriver-vs-puppeteer-stealth-benchmarks), our framework stands as the most stealthy in both the JS and Python universes. It is more stealthy than the popular Python library `undetected-chromedriver` and the well-known JavaScript library `puppeteer-stealth`. Botasaurus can easily visit websites like `https://nowsecure.nl/`. With Botasaurus, you don't need to waste time finding ways to unblock a website. For usage, [see this FAQ.](https://github.com/omkarcloud/botasaurus/tree/master#can-you-bypass-cloudflareimperva-challenges)
- **Access Cloudflare Websites with Simple HTTP Requests:** We can access Cloudflare-protected pages using simple HTTP requests. Saving you both time and money spent on proxies. For usage, [see this FAQ.](https://github.com/omkarcloud/botasaurus/tree/master#how-to-scrape-cloudflare-protected-websites-with-simple-http-requests)
- **SSL Support for Authenticated Proxy:** We are the first and only Python Web Scraping Framework as of writing to offer SSL support for authenticated proxies. No other browser automation libraries be it seleniumwire, puppeteer, playwright offers this important web scraping feature, this feautre enables you to easily access Cloudflare protected websites when using authenticated proxies, which would otherwise be blocked if you used only the bare authenticated proxy.
- **Use Any Chrome Extension with Just 1 Line of Code:** Easily integrate any Chrome extension, be it a Captcha Solving Extension, Adblocker, or any other from the Chrome Web Store, with just [one line of code.](https://github.com/omkarcloud/botasaurus#how-to-use-chrome-extensions). Say Sayonara, to the manual process of downloading, unzipping, configuring, and loading extensions.
- **Sitemap Support:** With just [one line of code](https://github.com/omkarcloud/botasaurus#how-to-extract-links-from-a-sitemap), you can get all links for a website.
- **Data Cleaners:** Make your scrapers robust by cleaning data with expert created data cleaners.
- **Debuggability:** When a crash occurs due to an incorrect selector, etc., Botasaurus pauses the browser instead of closing it, facilitating painless on-the-spot debugging.
- **Caching:** Botasaurus allows you to cache web scraping results, ensuring lightning-fast performance on subsequent scrapes.
- **Easy Configuration:** Easily save hours of Development Time with easy parallelization, profile, and proxy configuration. We make asynchronous, parallel scraping a child's play.
- **Build Robust Scrapers:** Easily configure retry on exceptions to ensure no errors comes in between you and the data
- **Time-Saving Selenium Shortcuts:** Botasaurus comes with numerous Selenium shortcuts to make web scraping incredibly easy.
## 🚀 Getting Started with Botasaurus
Welcome to Botasaurus! Let’s dive right in with a straightforward example to understand how it works.
In this tutorial, we will go through the steps to scrape the heading text from [https://www.omkar.cloud/](https://www.omkar.cloud/).
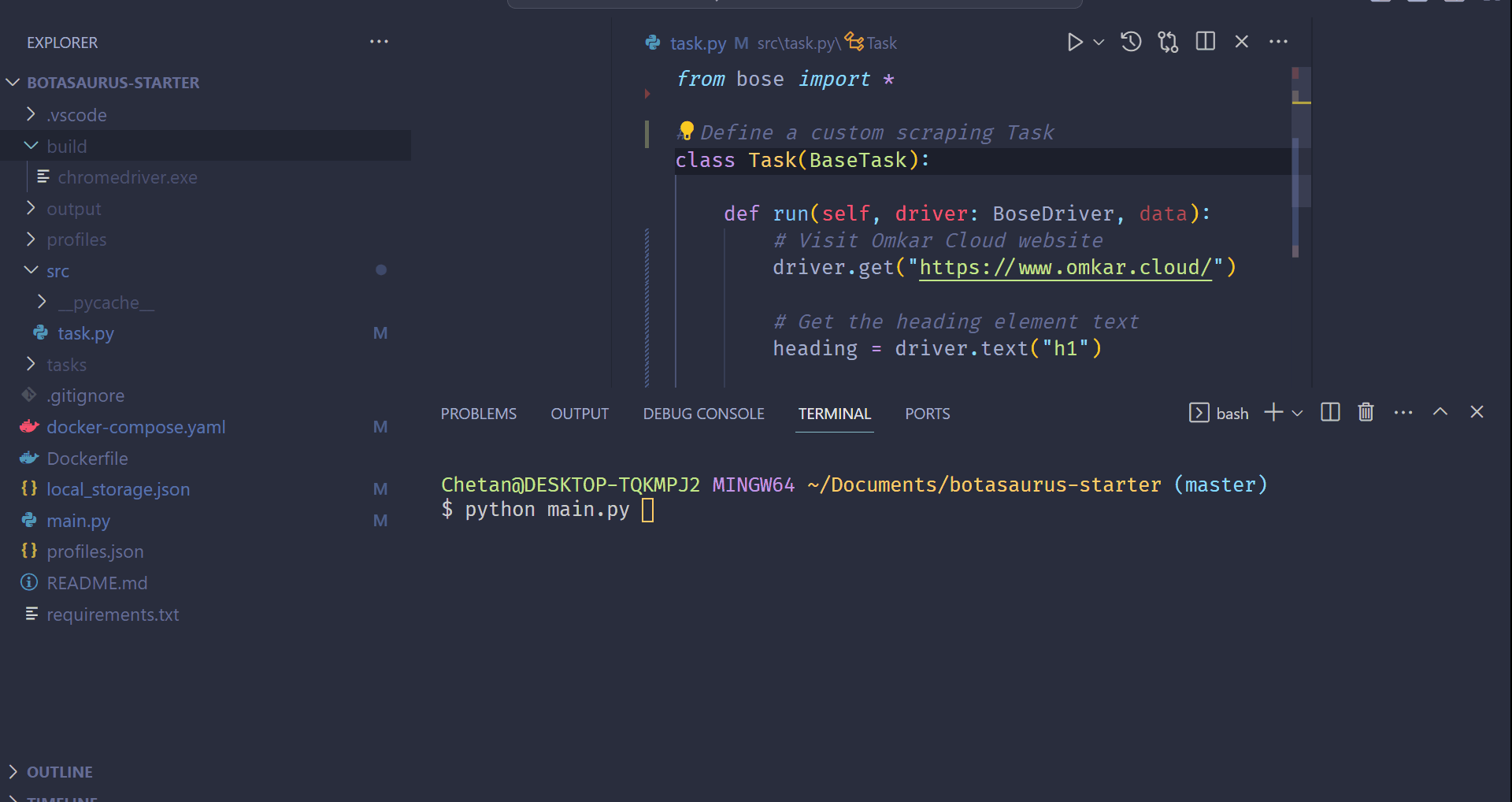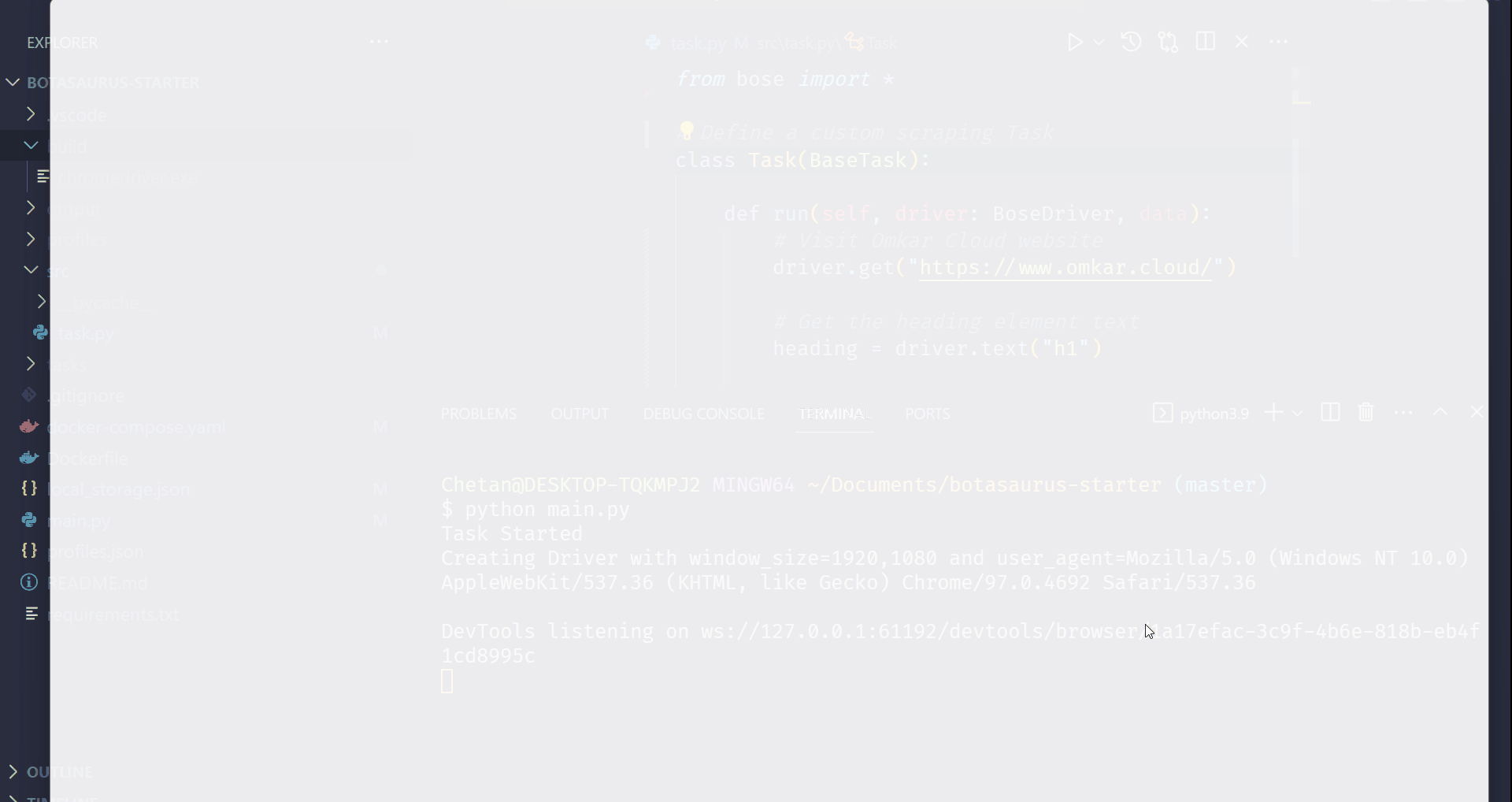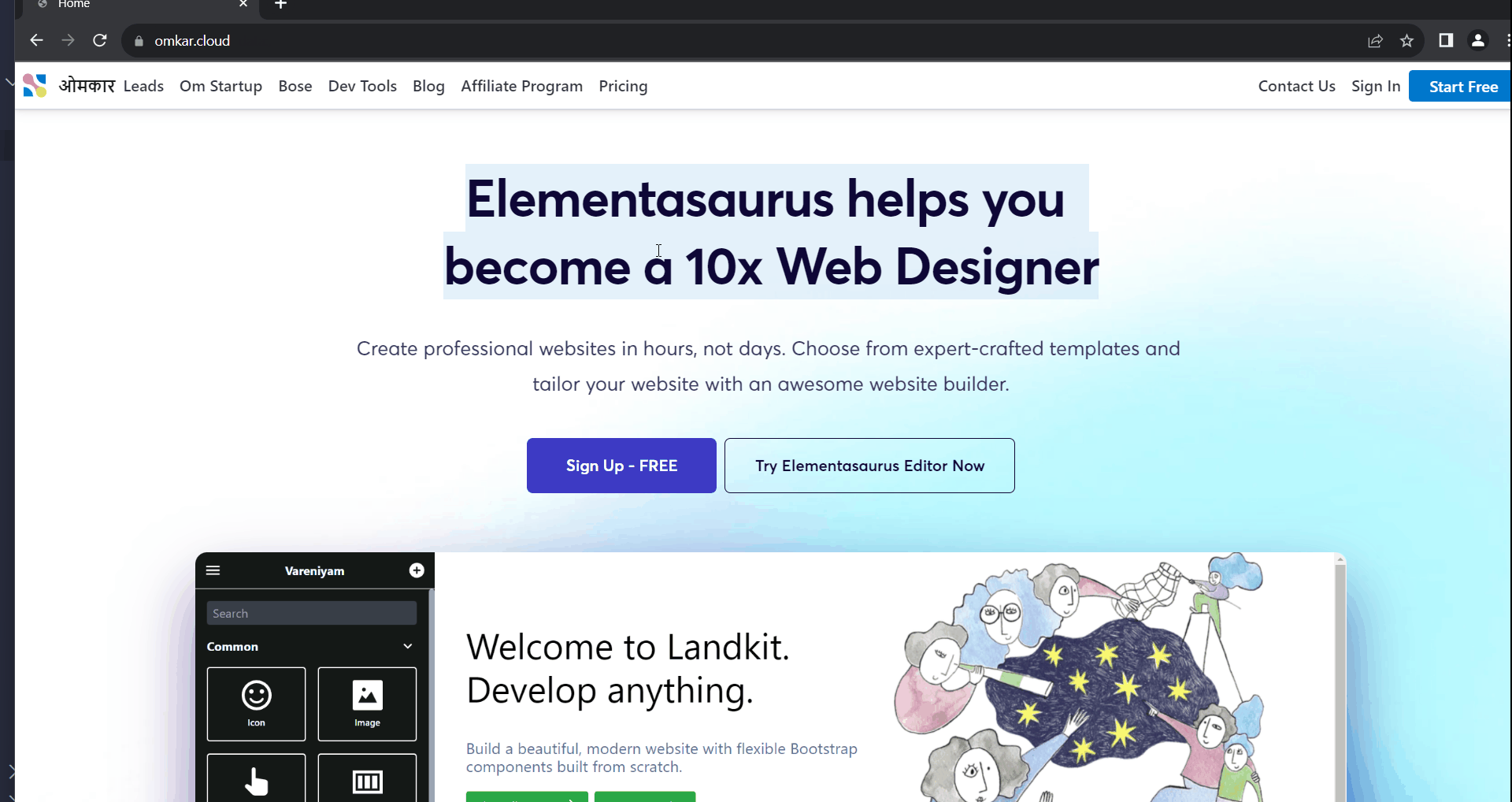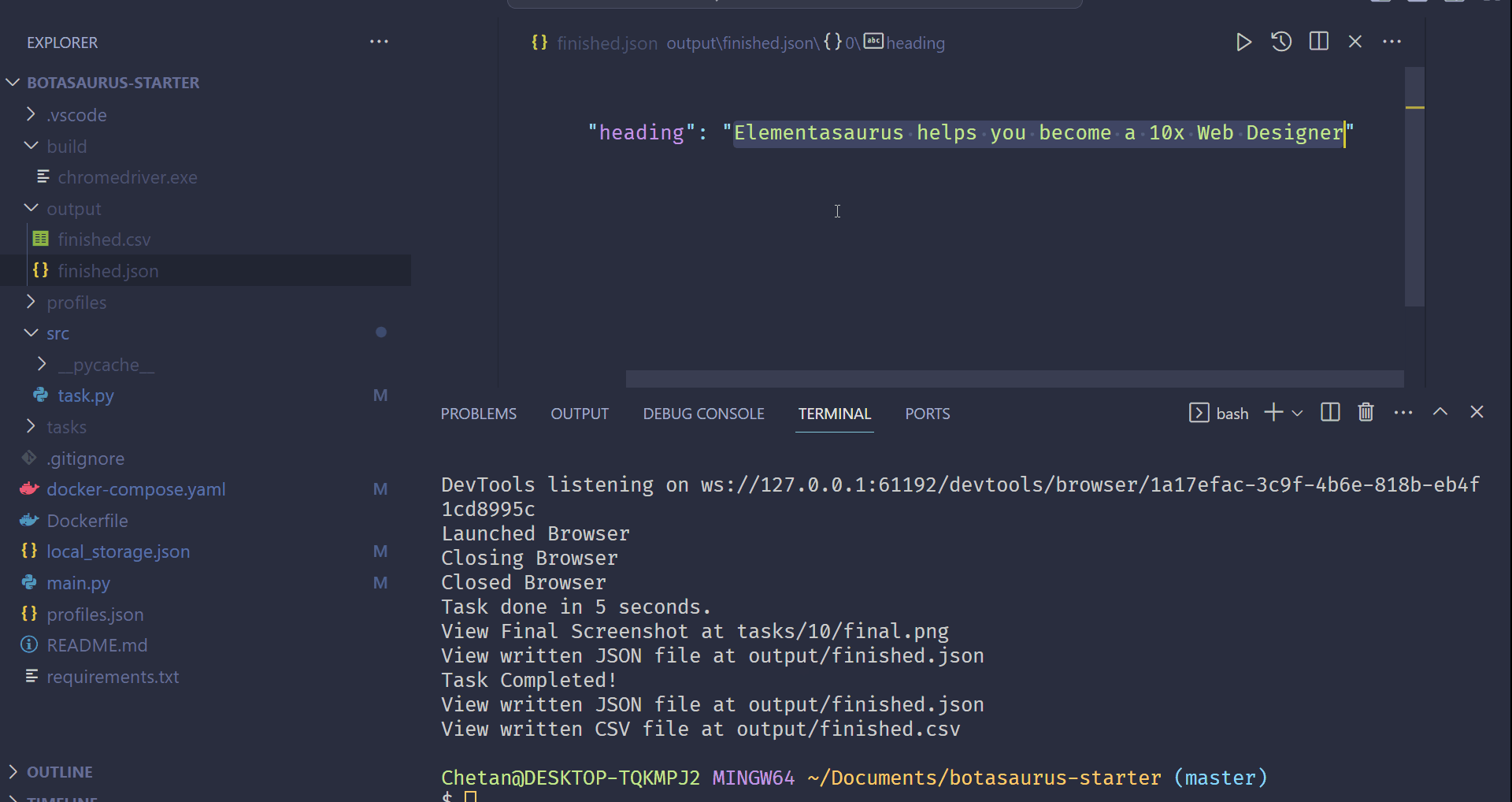
### Step 1: Install Botasaurus
First things first, you need to install Botasaurus. Run the following command in your terminal:
```shell
python -m pip install botasaurus
```
### Step 2: Set Up Your Botasaurus Project
Next, let’s set up the project:
1. Create a directory for your Botasaurus project and navigate into it:
```shell
mkdir my-botasaurus-project
cd my-botasaurus-project
code . # This will open the project in VSCode if you have it installed
```
### Step 3: Write the Scraping Code
Now, create a Python script named `main.py` in your project directory and insert the following code:
```python
from botasaurus import *
@browser
def scrape_heading_task(driver: AntiDetectDriver, data):
# Navigate to the Omkar Cloud website
driver.get("https://www.omkar.cloud/")
# Retrieve the heading element's text
heading = driver.text("h1")
# Save the data as a JSON file in output/scrape_heading_task.json
return {
"heading": heading
}
if __name__ == "__main__":
# Initiate the web scraping task
scrape_heading_task()
```
Let’s understand this code:
- We define a custom scraping task, `scrape_heading_task`, decorated with `@browser`:
```python
@browser
def scrape_heading_task(driver: AntiDetectDriver, data):
```
- Botasaurus automatically provides an Anti Detection Selenium driver to our function:
```python
def scrape_heading_task(driver: AntiDetectDriver, data):
```
- Inside the function, we:
- Navigate to Omkar Cloud
- Extract the heading text
- Return the data to be automatically saved as `scrape_heading_task.json` by Botasaurus:
```python
driver.get("https://www.omkar.cloud/")
heading = driver.text("h1")
return {"heading": heading}
```
- Finally, we initiate the scraping task:
```python
if __name__ == "__main__":
scrape_heading_task()
```
### Step 4: Run the Scraping Task
Time to run your bot:
```shell
python main.py
```
After executing the script, it will:
- Launch Google Chrome
- Navigate to [omkar.cloud](https://www.omkar.cloud/)
- Extract the heading text
- Save it automatically as `output/scrape_heading_task.json`.

Now, let’s explore another way to scrape the heading using the `request` module. Replace the previous code in `main.py` with the following:
```python
from botasaurus import *
@request
def scrape_heading_task(request: AntiDetectRequests, data):
# Navigate to the Omkar Cloud website
soup = request.bs4("https://www.omkar.cloud/")
# Retrieve the heading element's text
heading = soup.find('h1').get_text()
# Save the data as a JSON file in output/scrape_heading_task.json
return {
"heading": heading
}
if __name__ == "__main__":
# Initiate the web scraping task
scrape_heading_task()
```
In this code:
- We are using the BeautifulSoup (bs4) module to parse and scrape the heading.
- The `request` object provided is not a standard Python request object but an Anti Detect request object, which also preserves cookies.
### Step 5: Run the Scraping Task (Using Anti Detect Requests)
Finally, run the bot again:
```shell
python main.py
```
This time, you will observe the same result as before, but instead of using Anti Detect Selenium, we are utilizing the Anti Detect request module.
*Note: If you don't have Python installed, then you can run Botasaurus in Gitpod, a browser-based development environment, by following [this section](https://github.com/omkarcloud/botasaurus#how-to-run-botasaurus-in-gitpod).*
## 💡 Understanding Botasaurus
Let's learn about the features of Botasaurus that assist you in web scraping and automation.
### Could you show me an example where you access Cloudflare Protected Website?
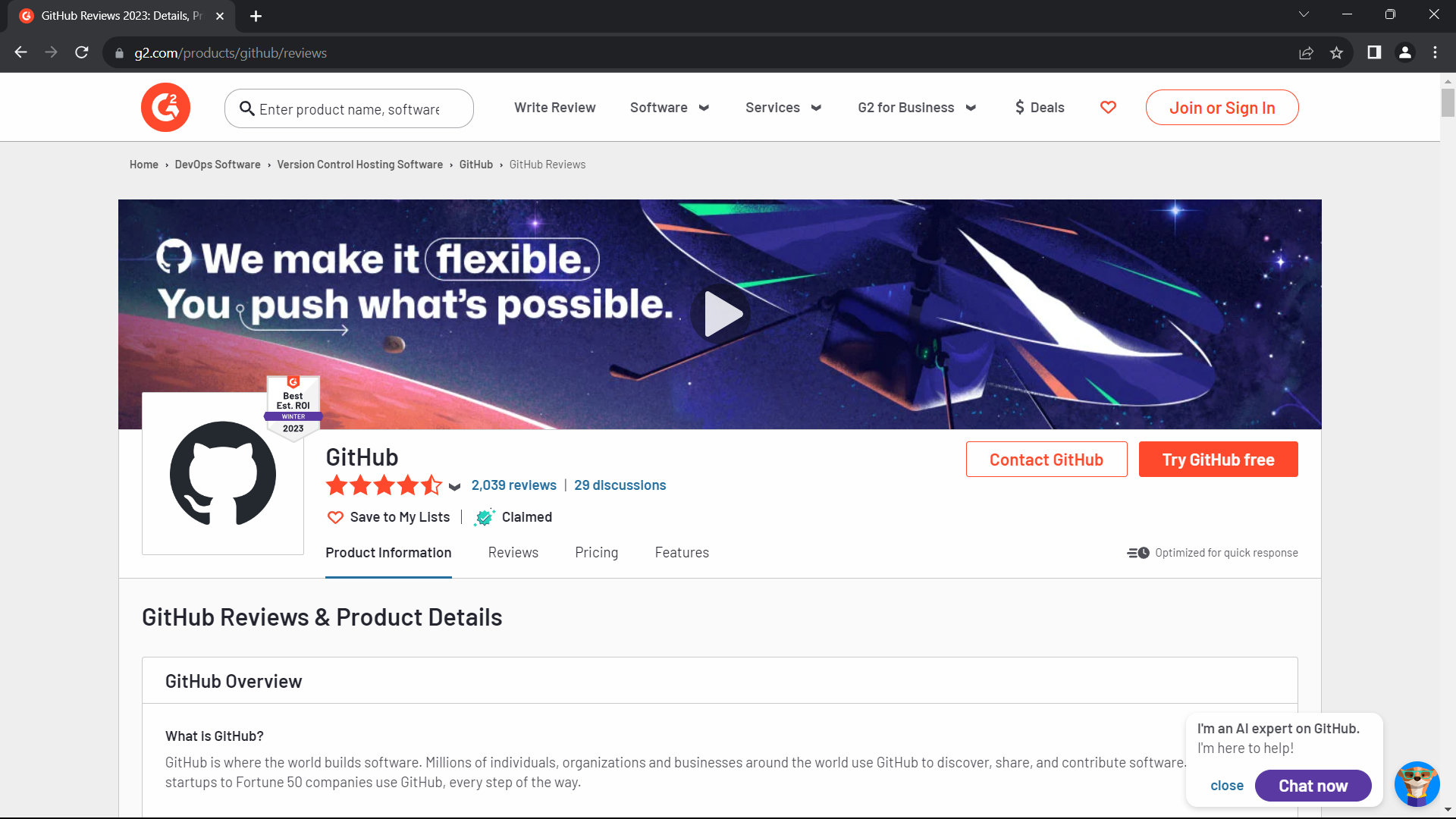
Sure, Run the following Python code to access G2.com, a website protected by Cloudflare:
```python
from botasaurus import *
@browser()
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.google_get("https://www.g2.com/products/github/reviews")
heading = driver.text('h1')
print(heading)
return heading
scrape_heading_task()
```
After running this script, you'll notice that the G2 page opens successfully, and the code prints the page's heading.
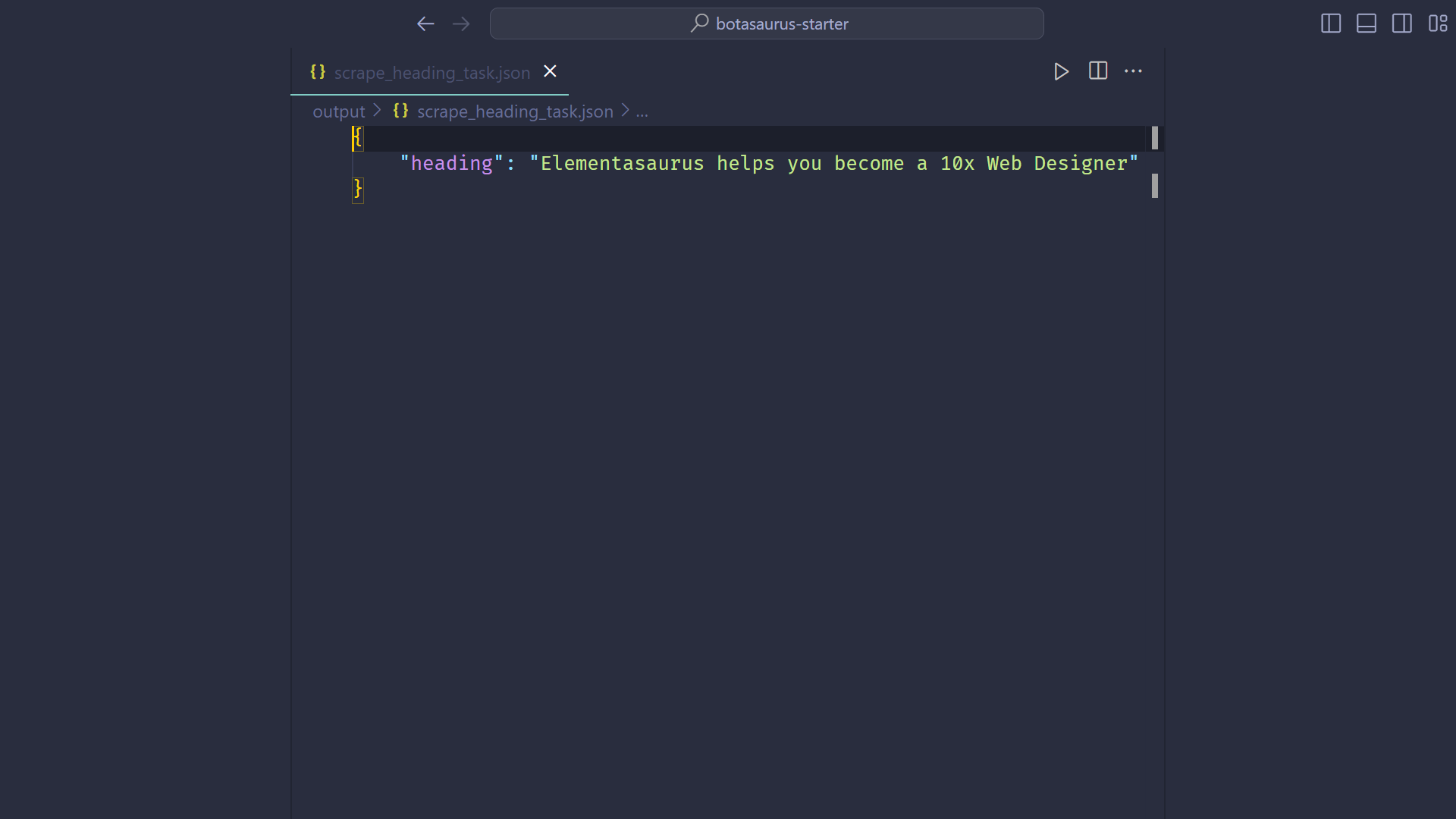
### How to Scrape Multiple Data Points/Links?
To scrape multiple data points or links, define the `data` variable and provide a list of items to be scraped:
```python
@browser(data=["https://www.omkar.cloud/", "https://www.omkar.cloud/blog/", "https://stackoverflow.com/"])
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
```
Botasaurus will launch a new browser instance for each item in the list and merge and store the results in `scrape_heading_task.json` at the end of the scraping.
Please note that the `data` parameter can also handle items such as dictionaries.
```python
@browser(data=[{"name": "Mahendra Singh Dhoni", ...}, {"name": "Virender Sehwag", ...}])
def scrape_heading_task(driver: AntiDetectDriver, data: dict):
# ...
```
### How to Scrape in Parallel?
To scrape data in parallel, set the `parallel` option in the browser decorator:
```python
@browser(parallel=3, data=["https://www.omkar.cloud/", ...])
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
```
### How to know how many scrapers to run parallely?
To determine the optimal number of parallel scrapers, pass the `bt.calc_max_parallel_browsers` function, which calculates the maximum number of browsers that can be run in parallel based on the available RAM:
```python
@browser(parallel=bt.calc_max_parallel_browsers, data=["https://www.omkar.cloud/", ...])
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
```
*Example: If you have 5.8 GB of free RAM, `bt.calc_max_parallel_browsers` would return 10, indicating you can run up to 10 browsers in parallel.*
### How to Cache the Web Scraping Results?
To cache web scraping results and avoid re-scraping the same data, set `cache=True` in the decorator:
```python
@browser(cache=True, data=["https://www.omkar.cloud/", ...])
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
```
### How Botasaurus helps me in debugging?
Botasaurus enhances the debugging experience by pausing the browser instead of closing it when an error occurs. This allows you to inspect the page and understand what went wrong, which can be especially helpful in debugging and removing the hassle of reproducing edge cases.
Botasaurus also plays a beep sound to alert you when an error occurs.
### How to Block Resources like CSS, Images, and Fonts to Save Bandwidth?
Blocking resources such as CSS, images, and fonts can significantly speed up your web scraping tasks, reduce bandwidth usage, and save money spent on proxies.
For example, a page that originally takes 4 seconds and 12 MB's to load might only take one second and 100 KB to load after css, images, etc have been blocked.
To block images, simply use the `block_resources` parameter. For example:
```python
@browser(block_resources=True) # Blocks ['.css', '.jpg', '.jpeg', '.png', '.svg', '.gif', '.woff', '.pdf', '.zip']
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.get("https://www.omkar.cloud/")
driver.prompt()
scrape_heading_task()
```
If you wish to block only images and fonts, while allowing CSS files, you can set `block_images` like this:
```python
@browser(block_images=True) # Blocks ['.jpg', '.jpeg', '.png', '.svg', '.gif', '.woff', '.pdf', '.zip']
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.get("https://www.omkar.cloud/")
driver.prompt()
scrape_heading_task()
```
To block a specific set of resources, such as only JavaScript, CSS, fonts, etc., specify them in the following manner:
```python
@browser(block_resources=['.js', '.css', '.jpg', '.jpeg', '.png', '.svg', '.gif', '.woff', '.pdf', '.zip'])
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.get("https://www.omkar.cloud/")
driver.prompt()
scrape_heading_task()
```
### How to Configure UserAgent, Proxy, Chrome Profile, Headless, etc.?
To configure various settings such as UserAgent, Proxy, Chrome Profile, and headless mode, you can specify them in the decorator as shown below:
```python
from botasaurus import *
@browser(
headless=True,
profile='my-profile',
# proxy="http://your_proxy_address:your_proxy_port", TODO: Replace with your own proxy
user_agent=bt.UserAgent.user_agent_106
)
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.get("https://www.omkar.cloud/")
driver.prompt()
scrape_heading_task()
```
You can also pass additional parameters when calling the scraping function, as demonstrated below:
```python
@browser()
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
data = "https://www.omkar.cloud/"
scrape_heading_task(
data,
headless=True,
profile='my-profile',
proxy="http://your_proxy_address:your_proxy_port",
user_agent=bt.UserAgent.user_agent_106
)
```
Furthermore, it's possible to define functions that dynamically set these parameters based on the data item. For instance, to set the profile dynamically according to the data item, you can use the following approach:
```python
@browser(profile=lambda data: data["profile"], headless=True, proxy="http://your_proxy_address:your_proxy_port", user_agent=bt.UserAgent.user_agent_106)
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
data = {"link": "https://www.omkar.cloud/", "profile": "my-profile"}
scrape_heading_task(data)
```
Additionally, if you need to pass metadata that is common across all data items, such as an API Key, you can do so by adding it as a `metadata` parameter. For example:
```python
@browser()
def scrape_heading_task(driver: AntiDetectDriver, data, metadata):
print("metadata:", metadata)
print("data:", data)
data = {"link": "https://www.omkar.cloud/", "profile": "my-profile"}
scrape_heading_task(
data,
metadata={"api_key": "BDEC26..."}
)
```
<!-- ### How Can I Save Data With a Different Name Instead of 'all.json'?
To save the data with a different filename, pass the desired filename along with the data in a tuple as shown below:
```python
@browser(block_resources=True, cache=True)
def scrape_article_links(driver: AntiDetectDriver, data):
# Visit the Omkar Cloud website
driver.get("https://www.omkar.cloud/blog/")
links = driver.links("h3 a")
filename = "links"
return filename, links
```
-->
### Do you support SSL for Authenticated Proxies?
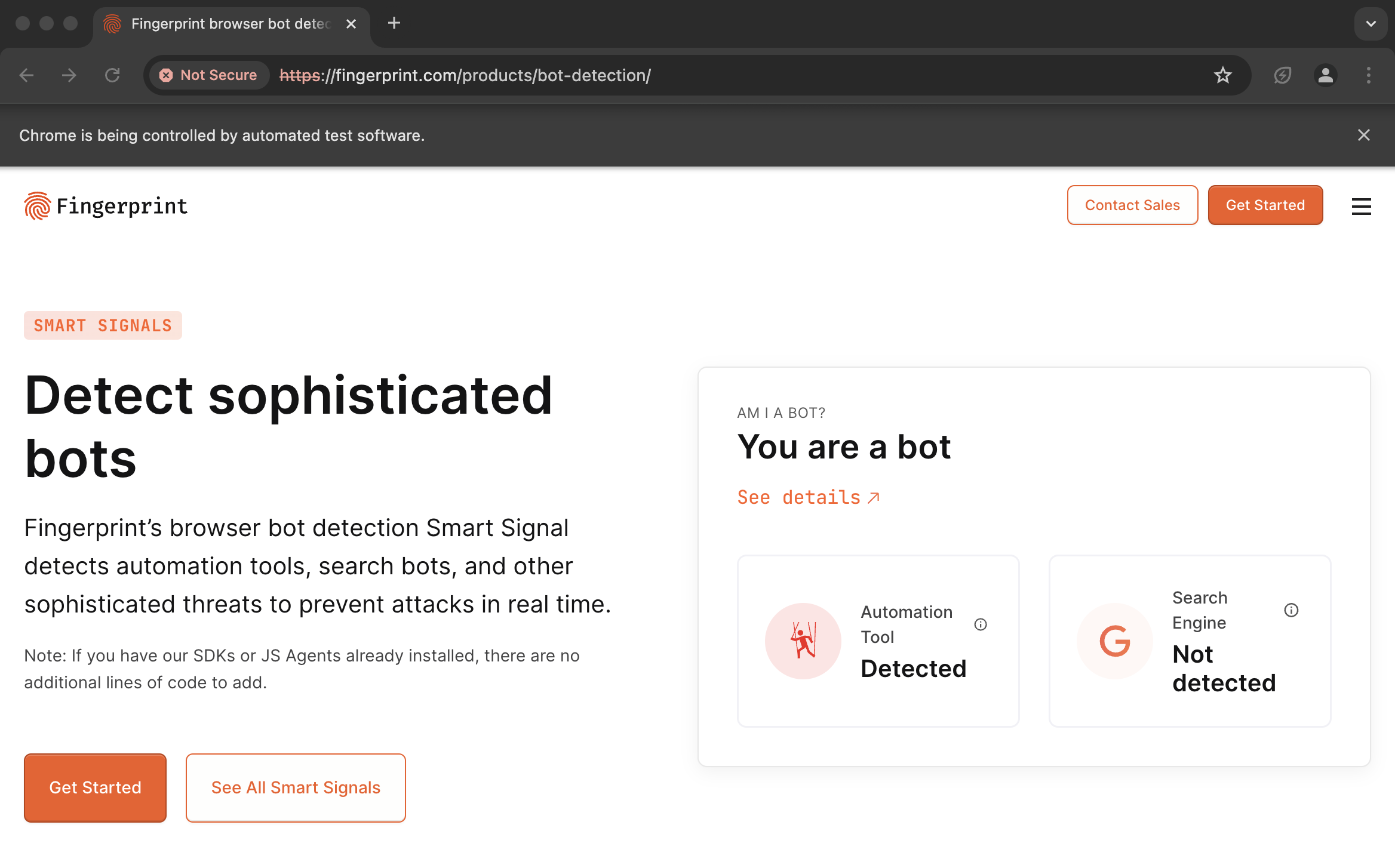
Yes, we are the first Python Library to support SSL for authenticated proxies. Proxy providers like BrightData, IPRoyal, and others typically provide authenticated proxies in the format "http://username:password@proxy-provider-domain:port". For example, "http://greyninja:awesomepassword@geo.iproyal.com:12321".
However, if you use an authenticated proxy with a library like seleniumwire to scrape a Cloudflare protected website like G2.com, you will surely be blocked because you are using a non-SSL connection.
To verify this, run the following code:
First, install the necessary packages:
```bash
python -m pip install selenium_wire chromedriver_autoinstaller_fix
```
Then, execute this Python script:
```python
from seleniumwire import webdriver
from chromedriver_autoinstaller_fix import install
# Define the proxy
proxy_options = {
'proxy': {
'http': 'http://username:password@proxy-provider-domain:port', # TODO: Replace with your own proxy
'https': 'http://username:password@proxy-provider-domain:port', # TODO: Replace with your own proxy
}
}
# Install and set up the driver
driver_path = install()
driver = webdriver.Chrome(driver_path, seleniumwire_options=proxy_options)
# Navigate to the desired URL
link = 'https://www.g2.com/products/github/reviews'
driver.get("https://www.google.com/")
driver.execute_script(f'window.location.href = "{link}"')
# Prompt for user input
input("Press Enter to exit...")
# Clean up
driver.quit()
```
You will definitely encounter a block by Cloudflare:
However, using proxies with Botasaurus prevents this issue. See the difference by running the following code:
```python
from botasaurus import *
@browser(proxy="http://username:password@proxy-provider-domain:port") # TODO: Replace with your own proxy
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.google_get("https://www.g2.com/products/github/reviews")
driver.prompt()
scrape_heading_task()
```
Result:

NOTE: To run the code above, you will need Node.js installed.
### How to Access Cloudflare-Protected Websites Using Simple HTTP Requests?
We can access Cloudflare-protected pages using simple HTTP requests.
All you need to do is specify the `use_stealth` option.
Sounds too good to be true? Run the following code to see it in action:
```python
from botasaurus import *
@request(use_stealth=True)
def scrape_heading_task(request: AntiDetectRequests, data):
response = request.get('https://www.g2.com/products/github/reviews')
print(response.status_code)
return response.text
scrape_heading_task()
```
### Can you access websites protected by Cloudflare JS Challenge?
Yes, we can. Let's learn about various challenges and the best ways to solve them.
*Connection Challenge*
This is the most popular challenge and requires making a browser-like connection with appropriate headers to the target website. It's commonly used to protect:
- Product Pages
- Blog Pages
- Search Result Pages
Example Page: https://www.g2.com/products/github/reviews
#### What Does Not Work?
Using `cloudscraper` library fails because, while it sends browser-like user agents and headers, it does not establish a browser-like connection, leading to detection.
#### What Works?
- Use the stealth request mode and visit via Google (default behavior). [Recommended]
```python
from botasaurus import *
@request(use_stealth=True)
def scrape_heading_task(request: AntiDetectRequests, data):
response = request.get('https://www.g2.com/products/github/reviews')
print(response.status_code)
return response.text
scrape_heading_task()
```
- Use a real Chrome browser with Selenium and visit via Google. Example Code:
```python
from botasaurus import *
@browser()
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.google_get("https://www.g2.com/products/github/reviews")
driver.prompt()
heading = driver.text('h1')
return heading
scrape_heading_task()
```
*JS Challenge*
This challenge requires performing JS computations that differentiates a Chrome controlled by Selenium/Puppeteer/Playwright from a real Chrome.
It's commonly used to protect Auth pages:
Example Pages: https://nowsecure.nl/
#### What Does Not Work?
Bare `selenium` and `puppeteer` definitely do not work due to a lot of automation noise. `undetected-chromedriver` and `puppeteer-stealth` also fail to access sites protected by JS Challenge like https://nowsecure.nl/.
#### What Works?
The Stealth Browser can easily solve JS Challenges. See the truth for yourself by running this code:
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
@browser(
create_driver=create_stealth_driver(
start_url="https://nowsecure.nl/",
),
)
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.prompt()
heading = driver.text('h1')
return heading
scrape_heading_task()
```
*JS with Captcha Challenge*
This challenge involves JS computations plus solving a Captcha. It's used to protect pages which are rarely but sometimes visited by humans, like:
- 5th Page of G2 Reviews
- 8th Page of Google Search Results
Example Page: https://www.g2.com/products/github/reviews.html?page=5&product_id=github
#### What Does Not Work?
Again, tools like `selenium`, `puppeteer`, `undetected-chromedriver`, and `puppeteer-stealth` fail.
#### What Works?
The Stealth Browser can easily solve these challenges. See it in action by running this code:
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
@browser(
create_driver=create_stealth_driver(
start_url="https://www.g2.com/products/github/reviews.html?page=5&product_id=github",
),
)
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.prompt()
heading = driver.text('h1')
return heading
scrape_heading_task()
```
*Notes:*
1. In stealth browser mode, we default to an 8-second wait before connecting to the browser via Selenium because connecting too early gets us detected. You can customize the wait time by using the `wait` argument.
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
@browser(
create_driver=create_stealth_driver(
start_url="https://nowsecure.nl/",
wait=4, # Waits for 4 seconds before connecting to browser
),
)
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.prompt()
heading = driver.text('h1')
return heading
scrape_heading_task()
```
Here are some recommendations for wait times:
- For active development with fast internet, set the wait time to **4 seconds**. You most likely have a fast internet connection, so set the wait time to **4 seconds** when developing your Bot.
- If during development you have a slow internet connection, then stick with the default **8 seconds**.
<!-- - When running your bot in the cloud via proxies, increase the wait time to **20 seconds** due to longer data download times.
- For slow proxies, set the wait time to **28 seconds**. -->
2. If you get detected, try changing your IP. Let me share with you The **fastest**, **simplest**, and best of all, the **free** way to change your IP:
- **Connect your PC to the Internet via a Mobile Hotspot.**
- **Toggle airplane mode off and on on your mobile device.** This will assign you a new IP address.
- **Turn the hotspot back on.**
- **Voila, you have a new, high-quality mobile IP for free!**
<!-- 3. If you are running the bot in Docker on a server and experiencing detection issues, it's suggested to use residential proxies. -->
3. If you are automating Cloudflare Websites with JS Challenges like https://nowsecure.nl/, then you must pass start_url to solve them like this:
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
@browser(
create_driver=create_stealth_driver(
start_url="https://nowsecure.nl/", # Must for Websites Protected by Cloudflare JS Challenge
),
)
```
However, if you are automating websites not protected by Cloudflare or protected by Cloudflare Connection Challenge, then you may pass `None` to start_url. With this, we will also not perform a wait before connecting to Chrome, saving you time.
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
@browser(
create_driver=create_stealth_driver(
start_url=None, # Recommended for Websites not protected by Cloudflare or protected by Cloudflare Connection Challenge
),
)
```
4. Anti Detection Systems can detect fake randomly generated user agents. So, if you are getting detected, especially on Ubuntu with Cloudflare JS with Captcha Challenge, we recommend using your real user agent and window size, not a randomly generated one. Here's how you can do it:
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
@browser(
user_agent=bt.UserAgent.REAL,
window_size=bt.WindowSize.REAL,
create_driver=create_stealth_driver(
start_url="https://nowsecure.nl/",
),
)
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.prompt()
heading = driver.text('h1')
return heading
scrape_heading_task()
```
If you are doing web scraping of publicly available data, then the above code is good and recommended to be used. but stealth driver is fingerprintable using tools like [fingerprint](https://fingerprint.com/).
5. We expect to access Cloudflare websites 9 out of 10 times. However, in some cases, they do detect us for reasons like IP blacklisting. In such cases, you can use the following code snippet to make your scraper more robust:
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
def get_start_url(data):
return data
@browser(
# proxy="http://username:password@proxy-domain:12321" # optionally use proxy
# user_agent=bt.UserAgent.REAL, # Optionally use REAL User Agent
# window_size=bt.WindowSize.REAL, # Optionally use REAL Window Size
max_retry=5,
create_driver=create_stealth_driver(
start_url=get_start_url,
raise_exception=True,
),
)
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.prompt()
heading = driver.text('h1')
return heading
scrape_heading_task(["https://nowsecure.nl/", "https://steamdb.info/sub/363669/apps"])
```
The above code makes the scraper more robust by raising an exception when detected and retrying up to 5 times to visit the website.
### How to Solve Captchas in Web Scraping?
Facing captchas is really common and annoying hurdle in web scraping. Fortunately, CapSolver can be used to automatically solve captchas, saving both time and effort. Here's how you can use it:
```python
from botasaurus import *
from capsolver_extension_python import Capsolver
@browser(
extensions=[Capsolver(api_key="CAP-MY_KEY")], # Replace "CAP-MY_KEY" with your actual CapSolver Key
)
def solve_captcha(driver: AntiDetectDriver, data):
driver.get("https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php")
driver.prompt()
solve_captcha()
```
To solve captcha's with CapSolver, you will need Capsolver API Key. If you do not have a CapSolver API Key, follow the instructions [here](https://github.com/omkarcloud/botasaurus/blob/master/capsolver-sign-up.md) to create a CapSolver account and obtain one.
### How to Use Chrome Extensions?
Botasaurus allows the use of ANY Chrome Extension with just 1 Line of Code. Below is an example that uses the AdBlocker Chrome Extension:
```python
from botasaurus import *
from chrome_extension_python import Extension
@browser(
extensions=[Extension("https://chromewebstore.google.com/detail/adblock-%E2%80%94-best-ad-blocker/gighmmpiobklfepjocnamgkkbiglidom")], # Simply pass the Extension Link
)
def open_chrome(driver: AntiDetectDriver, data):
driver.prompt()
open_chrome()
```
Also, In some cases an extension requires additional configuration like API keys or credentials, for that you can create a Custom Extension. Learn how to create and configure Custom Extension [here](https://github.com/omkarcloud/chrome-extension-python).
### I want to Scrape a large number of Links, a new selenium driver is getting created for each new link, this increases the time to scrape data. How can I reuse Drivers?
Utilize the `reuse_driver` option to reuse drivers, reducing the time required for data scraping:
```python
@browser(reuse_driver=True)
def scrape_heading_task(driver: AntiDetectDriver, data):
# ...
```
### How to Extract Links from a Sitemap?
In web scraping, it is a common use case to scrape product pages, blogs, etc. But before scraping these pages, you need to get the links to these pages.
Many developers unnecessarily increase their work by writing code to visit each page one by one and scrape links, which they could have easily by just looking at the Sitemap.
The Botasaurus Sitemap Module makes this process easy as cake by allowing you to get all links or sitemaps using:
- The homepage URL (e.g., `https://www.omkar.cloud/`)
- A direct sitemap link (e.g., `https://www.omkar.cloud/sitemap.xml`)
- A `.gz` compressed sitemap
For example, to get a list of books from bookswagon.com, you can use following code:
```python
from botasaurus import *
from botasaurus.sitemap import Sitemap, Filters
links = (
Sitemap("https://www.bookswagon.com/googlesitemap/sitemapproducts-1.xml")
.filter(Filters.first_segment_equals("book"))
.links()
)
bt.write_temp_json(links)
```
**Output:**
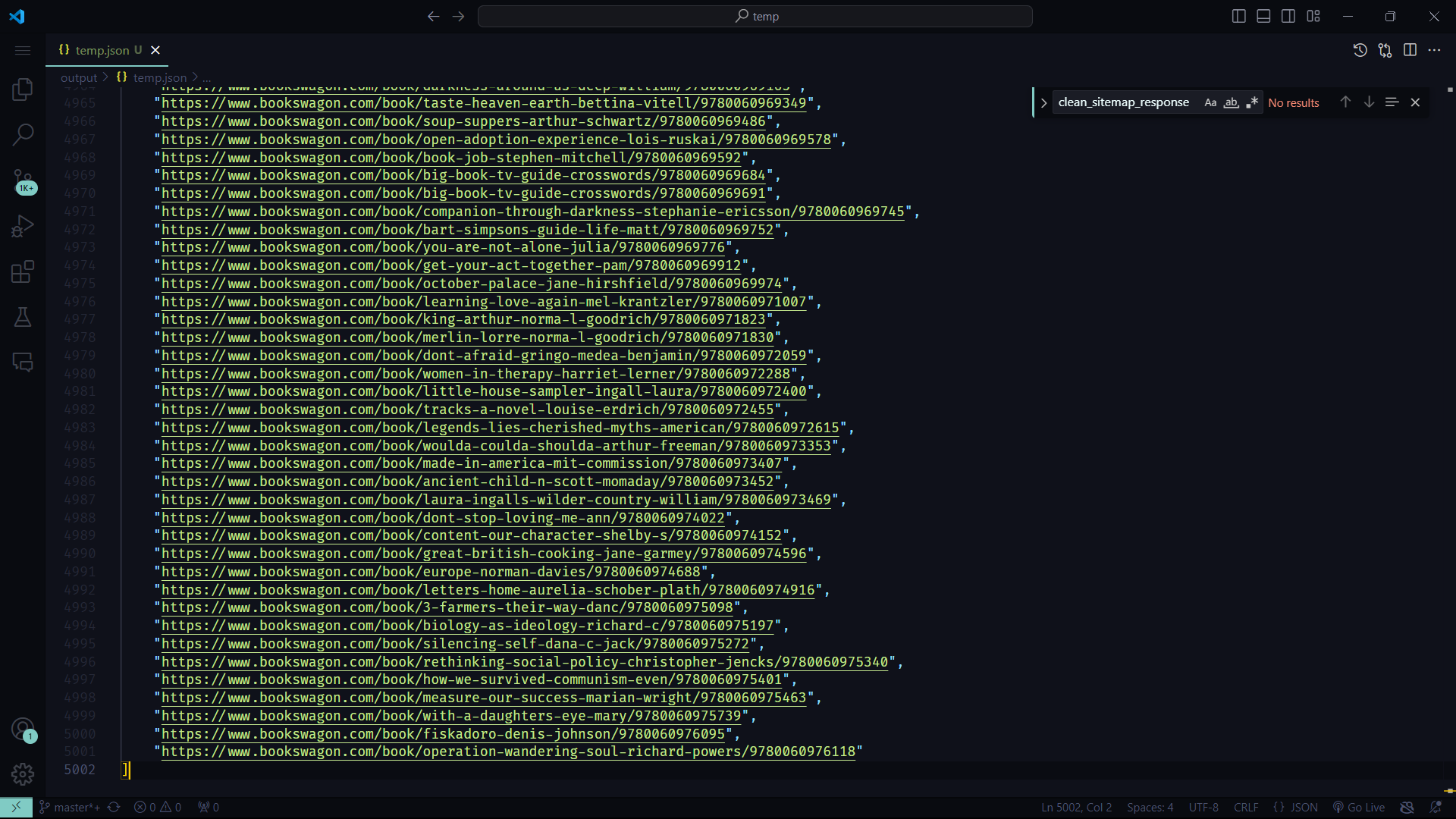
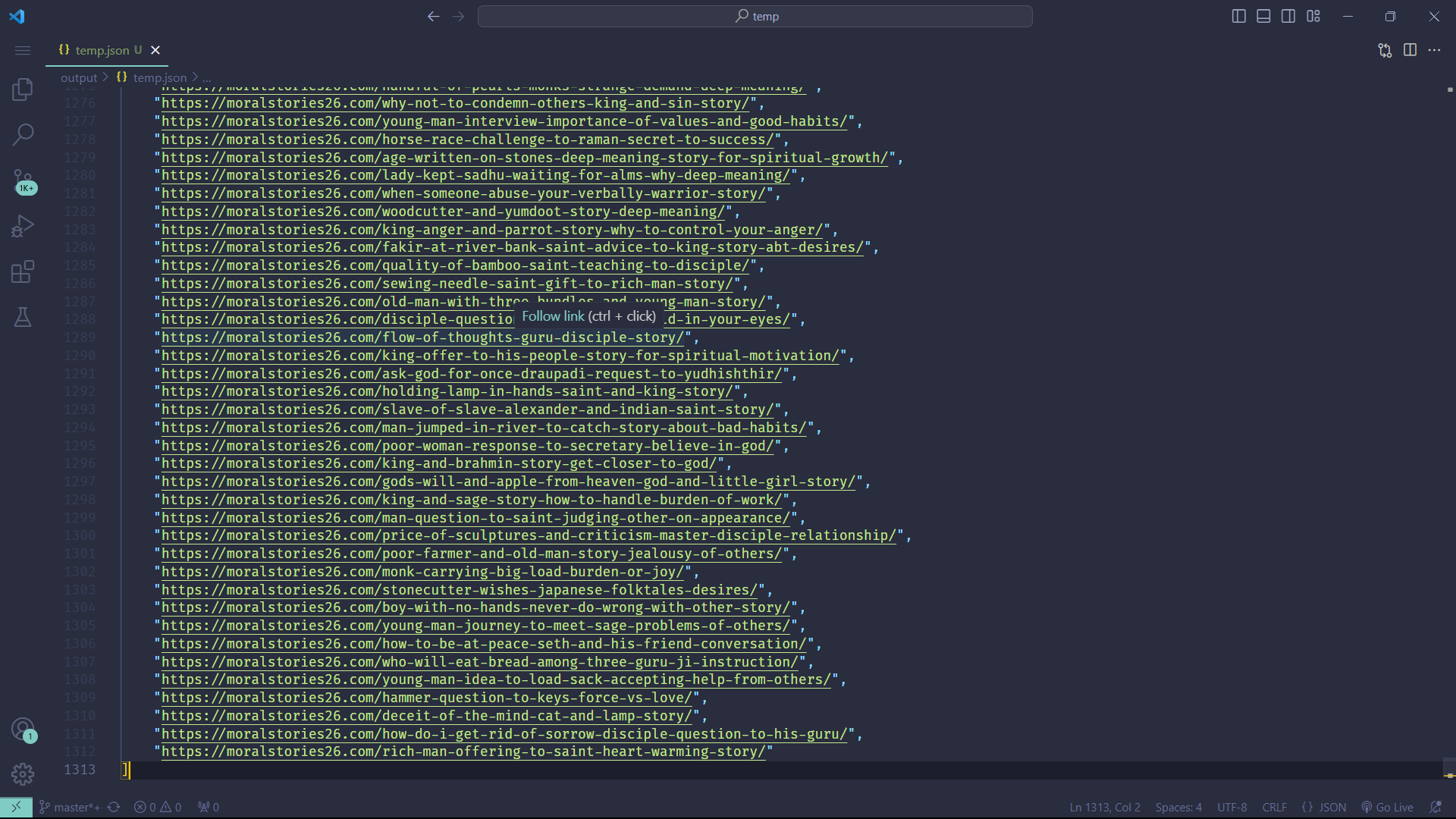
Or, Let's say you're in the mood for some reading and looking for good stories, the following code will get you over 1000+ stories from [moralstories26.com](https://moralstories26.com/):
```python
from botasaurus import *
from botasaurus.sitemap import Sitemap, Filters
links = (
Sitemap("https://moralstories26.com/")
.filter(
Filters.has_exactly_1_segment(),
Filters.first_segment_not_equals(
["about", "privacy-policy", "akbar-birbal", "animal", "education", "fables", "facts", "family", "famous-personalities", "folktales", "friendship", "funny", "heartbreaking", "inspirational", "life", "love", "management", "motivational", "mythology", "nature", "quotes", "spiritual", "uncategorized", "zen"]
),
)
.links()
)
bt.write_temp_json(links)
```
**Output:**
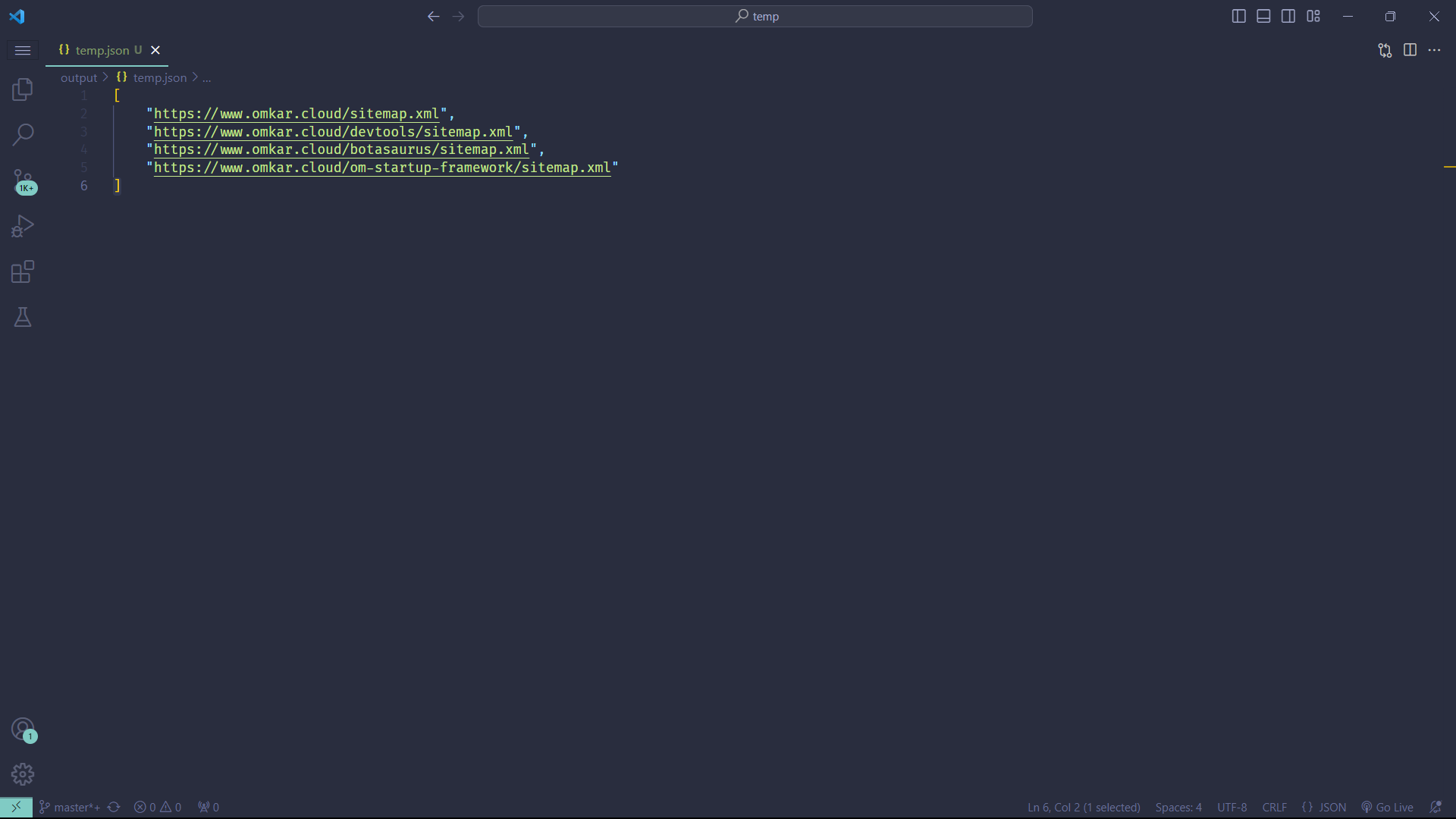
Also, Before scraping a site, it's useful to identify the available sitemaps. This can be easily done with the following code:
```python
from botasaurus import *
from botasaurus.sitemap import Sitemap
sitemaps = Sitemap("https://www.omkar.cloud/").sitemaps()
bt.write_temp_json(sitemaps)
```
**Output:**
To ensure your scrapers run super fast, we cache the Sitemap, but you may want to periodically refresh the cache, which you can do as follows:
```python
from botasaurus import *
from botasaurus.sitemap import Sitemap
from botasaurus.cache import Cache
sitemap = Sitemap(
[
"https://moralstories26.com/post-sitemap.xml",
"https://moralstories26.com/post-sitemap2.xml",
],
cache=Cache.REFRESH, # Refresh the cache with up-to-date stories.
)
links = sitemap.links()
bt.write_temp_json(links)
```
In summary, the sitemap is an awesome module for easily extracting links you want for web scraping.
### Could you show me a practical example where all these Botasaurus Features Come Together to accomplish a typical web scraping project?
Below is a practical example of how Botasaurus features come together in a typical web scraping project to scrape a list of links from a blog, and then visit each link to retrieve the article's heading and date:
```python
from botasaurus import *
@browser(block_resources=True,
cache=True,
parallel=bt.calc_max_parallel_browsers,
reuse_driver=True)
def scrape_articles(driver: AntiDetectDriver, link):
driver.get(link)
heading = driver.text("h1")
date = driver.text("time")
return {
"heading": heading,
"date": date,
"link": link,
}
@browser(block_resources=True, cache=True)
def scrape_article_links(driver: AntiDetectDriver, data):
# Visit the Omkar Cloud website
driver.get("https://www.omkar.cloud/blog/")
links = driver.links("h3 a")
return links
if __name__ == "__main__":
# Launch the web scraping task
links = scrape_article_links()
scrape_articles(links)
```
### How to Clean Data?
Botasaurus provides a module named `cl` that includes commonly used cleaning functions to save development time. Here are some of the most important ones:
1. **`cl.select`**
What `document.querySelector` is to js, is what `cl.select` is to json. This is the most used function in Botasaurus and is incredibly useful.
This powerful function is popular for safely selecting data from nested JSON.
Instead of using flaky code like this:
```python
from botasaurus import cl
data = {
"person": {
"data": {
"name": "Omkar",
"age": 21
}
},
"data": {
"friends": [
{"name": "John", "age": 21},
{"name": "Jane", "age": 21},
{"name": "Bob", "age": 21}
]
}
}
name = data.get('person', {}).get('data', {}).get('name', None)
if name:
name = name.upper()
else:
name = None
print(name)
```
You can write it as:
```python
from botasaurus import cl
data = {
"person": {
"data": {
"name": "Omkar",
"age": 21
}
},
"data": {
"friends": [
{"name": "John", "age": 21},
{"name": "Jane", "age": 21},
{"name": "Bob", "age": 21}
]
}
}
print(cl.select(data, 'name', map_data=lambda x: x.upper()))
```
`cl.select` returns `None` if the key is not found, instead of throwing an error.
```python
from botasaurus import cl
print(cl.select(data, 'name')) # Omkar
print(cl.select(data, 'friends', 0, 'name')) # John
print(cl.select(data, 'friends', 0, 'non_existing_key')) # None
```
You can also use `map_data` like this:
```python
from botasaurus import cl
cl.select(data, 'name', map_data=lambda x: x.upper()) # OMKAR
```
And use default values like this:
```python
from botasaurus import cl
cl.select(None, 'name', default="OMKAR") # OMKAR
```
2. **`cl.extract_numbers`**
```python
from botasaurus import cl
print(cl.extract_numbers("I can extract numbers with decimal like 4.5, or with comma like 1,000.")) # [4.5, 1000]
```
3. **More Functions**
```python
from botasaurus import cl
print(cl.extract_links("I can extract links like https://www.omkar.cloud/ or https://www.omkar.cloud/blog/")) # ['https://www.omkar.cloud/', 'https://www.omkar.cloud/blog/']
print(cl.rename_keys({"name": "Omkar", "age": 21}, {"name": "full_name"})) # {"full_name": "Omkar", "age": 21}
print(cl.sort_object_by_keys({"age": 21, "name": "Omkar"}, "name")) # {"name": "Omkar", "age": 21}
print(cl.extract_from_dict([{"name": "John", "age": 21}, {"name": "Jane", "age": 21}, {"name": "Bob", "age": 21}], "name")) # ["John", "Jane", "Bob"]
# ... And many more
```
### How to Read/Write JSON and CSV Files?
Botasaurus provides convenient methods for reading and writing data:
```python
# Data to write to the file
data = [
{"name": "John Doe", "age": 42},
{"name": "Jane Smith", "age": 27},
{"name": "Bob Johnson", "age": 35}
]
# Write the data to the file "data.json"
bt.write_json(data, "data.json")
# Read the contents of the file "data.json"
print(bt.read_json("data.json"))
# Write the data to the file "data.csv"
bt.write_csv(data, "data.csv")
# Read the contents of the file "data.csv"
print(bt.read_csv("data.csv"))
```
### How Can I Pause the Scraper to Inspect Things While Developing?
To pause the scraper and wait for user input before proceeding, use `bt.prompt()`:
```python
bt.prompt()
```
### How Does AntiDetectDriver Facilitate Easier Web Scraping?
AntiDetectDriver is a patched Version of Selenium that has been modified to avoid detection by bot protection services such as Cloudflare.
It also includes a variety of helper functions that make web scraping tasks easier.
You can learn about these methods [here](https://github.com/omkarcloud/botasaurus/blob/master/anti-detect-driver.md).
### What Features Does @request Support, Similar to @browser?
Similar to @browser, @request supports features like
- asynchronous execution [Will Learn Later]
- parallel processing
- caching
- user-agent customization
- proxies, etc.
Below is an example that showcases these features:
```python
@request(parallel=40, cache=True, proxy="http://your_proxy_address:your_proxy_port", data=["https://www.omkar.cloud/", ...])
def scrape_heading_task(request: AntiDetectDriver, link):
soup = request.bs4(link)
heading = soup.find('h1').get_text()
return {"heading": heading}
```
### I have an existing project into which I want to integrate the AntiDetectDriver/AntiDetectRequests.
You can create an instance of `AntiDetectDriver` as follows:
```python
driver = bt.create_driver()
# ... Code for scraping
driver.quit()
```
You can create an instance of `AntiDetectRequests` as follows:
```python
anti_detect_request = bt.create_request()
soup = anti_detect_request.bs4("https://www.omkar.cloud/")
# ... Additional code
```
---
### How to Run Botasaurus in Docker?
To run Botasaurus in Docker, use the Botasaurus Starter Template, which includes the necessary Dockerfile and Docker Compose configurations:
```
git clone https://github.com/omkarcloud/botasaurus-starter my-botasaurus-project
cd my-botasaurus-project
docker-compose build && docker-compose up
```
### How to Run Botasaurus in Gitpod?
Botasaurus Starter Template comes with the necessary `.gitpod.yml` to easily run it in Gitpod, a browser-based development environment. Set it up in just 5 minutes by following these steps:
1. Open Botasaurus Starter Template, by visiting [this link](https://gitpod.io/#https://github.com/omkarcloud/botasaurus-starter) and sign up on gitpod.

<!-- 2. To speed up scraping, select the Large 8 Core, 16 GB Ram Machine and click the `Continue` button.
 -->
2. In the terminal, run the following command to start scraping:
```bash
python main.py
```
## Advanced Features
### How Do I Configure the Output of My Scraping Function in Botasaurus?
To configure the output of your scraping function in Botasaurus, you can customize the behavior in several ways:
1. **Change Output Filename**: Use the `output` parameter in the decorator to specify a custom filename for the output.
```python
@browser(output="my-output")
def scrape_heading_task(driver: AntiDetectDriver, data):
# Your scraping logic here
```
2. **Disable Output**: If you don't want any output to be saved, set `output` to `None`.
```python
@browser(output=None)
def scrape_heading_task(driver: AntiDetectDriver, data):
# Your scraping logic here
```
3. **Dynamically Write Output**: To dynamically write output based on data and result, pass a function to the `output` parameter:
```python
def write_output(data, result):
bt.write_json(result, 'data')
bt.write_csv(result, 'data')
@browser(output=write_output)
def scrape_heading_task(driver: AntiDetectDriver, data):
# Your scraping logic here
```
4. **Save Outputs in Multiple Formats**: Use the `output_formats` parameter to save outputs in different formats like CSV and JSON.
```python
@browser(output_formats=[bt.Formats.CSV, bt.Formats.JSON])
def scrape_heading_task(driver: AntiDetectDriver, data):
# Your scraping logic here
```
These options provide flexibility in how you handle the output of your scraping tasks with Botasaurus.
### How to Run Drivers Asynchronously from the Main Process?
To execute drivers asynchronously, enable the `async` option and use `.get()` when you're ready to collect the results:
```python
from botasaurus import *
from time import sleep
@browser(
run_async=True, # Specify the Async option here
)
def scrape_heading(driver: AntiDetectDriver, data):
print("Sleeping for 5 seconds.")
sleep(5)
print("Slept for 5 seconds.")
return {}
if __name__ == "__main__":
# Launch web scraping tasks asynchronously
result1 = scrape_heading() # Launches asynchronously
result2 = scrape_heading() # Launches asynchronously
result1.get() # Wait for the first result
result2.get() # Wait for the second result
```
With this method, function calls run concurrently. The output will indicate that both function calls are executing in parallel.
### How to Asynchronously Add Multiple Items and Get Results?
The `async_queue` feature allows you to perform web scraping tasks in asyncronously in a queue, without waiting for each task to complete before starting the next one. To gather your results, simply use the `.get()` method when all tasks are in the queue.
#### Basic Example:
```python
from botasaurus import *
from time import sleep
@browser(async_queue=True)
def scrape_data(driver: AntiDetectDriver, data):
print("Starting a task.")
sleep(1) # Simulate a delay, e.g., waiting for a page to load
print("Task completed.")
return data
if __name__ == "__main__":
# Start scraping tasks without waiting for each to finish
async_queue = scrape_data() # Initializes the queue
# Add tasks to the queue
async_queue.put([1])
async_queue.put(2)
async_queue.put([3, 4])
# Retrieve results when ready
results = async_queue.get() # Expects to receive: [1, 2, 3, 4]
```
#### Practical Application for Web Scraping:
Here's how you could use `async_queue` to scrape webpage titles while scrolling through a list of links:
```python
from botasaurus import *
@browser(async_queue=True)
def scrape_title(driver: AntiDetectDriver, link):
driver.get(link) # Navigate to the link
return driver.title # Scrape the title of the webpage
@browser()
def scrape_all_titles(driver: AntiDetectDriver):
# ... Your code to visit the initial page ...
title_queue = scrape_title() # Initialize the asynchronous queue
while not end_of_page_detected(driver): # Replace with your end-of-list condition
title_queue.put(driver.links('a')) # Add each link to the queue
driver.scroll(".scrollable-element")
return title_queue.get() # Get all the scraped titles at once
if __name__ == "__main__":
all_titles = scrape_all_titles() # Call the function to start the scraping process
```
**Note:** The `async_queue` will only invoke the scraping function for unique links, avoiding redundant operations and keeping the main function (`scrape_all_titles`) cleaner.
### I want to repeatedly call the scraping function without creating new Selenium drivers each time. How can I achieve this?
Utilize the `keep_drivers_alive` option to maintain active driver sessions. Remember to call `.close()` when you're finished to release resources:
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
@browser(
keep_drivers_alive=True,
reuse_driver=True, # Also commonly paired with `keep_drivers_alive`
)
def scrape_data(driver: AntiDetectDriver, link):
driver.get(link)
if __name__ == "__main__":
scrape_data(["https://moralstories26.com/", "https://moralstories26.com/page/2/", "https://moralstories26.com/page/3/"])
# After completing all scraping tasks, call .close() to close the drivers.
scrape_data.close()
```
### How do I manage the Cache in Botasaurus?
You can use The Cache Module in Botasaurus to easily manage cached data. Here's a simple example explaining its usage:
```python
from botasaurus import *
from botasaurus.cache import Cache
# Example scraping function
@request
def scrape_data(data):
# Your scraping logic here
return {"processed": data}
# Sample data for scraping
input_data = {"key": "value"}
# Adding data to the cache
Cache.put(scrape_data, input_data, scrape_data(input_data))
# Checking if data is in the cache
if Cache.has(scrape_data, input_data):
# Retrieving data from the cache
cached_data = Cache.get(scrape_data, input_data)
# Removing specific data from the cache
Cache.remove(scrape_data, input_data)
# Clearing the complete cache for the scrape_data function
Cache.clear(scrape_data)
```
### Any Tips for Scraping Cloudflare-Protected Websites?
- Use stealth driver
- For large-scale scraping, opt for Data Center Proxies over Residential as Residential Proxies are really expensive. Sometimes you will get blocked; so, use retries as demonstrated in the code below:
```python
from botasaurus import *
from botasaurus.create_stealth_driver import create_stealth_driver
@browser(
create_driver=create_stealth_driver(
start_url="https://nowsecure.nl/",
),
proxy="http://username:password@datacenter-proxy-domain:12321",
max_retry=5, # A reliable default for most situations, will retry creating driver if detected.
block_resources=True, # Enhances efficiency and cost-effectiveness
)
def scrape_heading_task(driver: AntiDetectDriver, data):
heading = driver.text('h1')
print(heading)
return heading
```
### How Do I Close All Running Chrome Instances When Developing with Botasaurus?
While developing a scraper, you might need to interrupt the scraping process, often done by pressing `Ctrl + C`. However, this action does not automatically close the Chrome browsers, which can cause your computer to hang due to resource overuse.
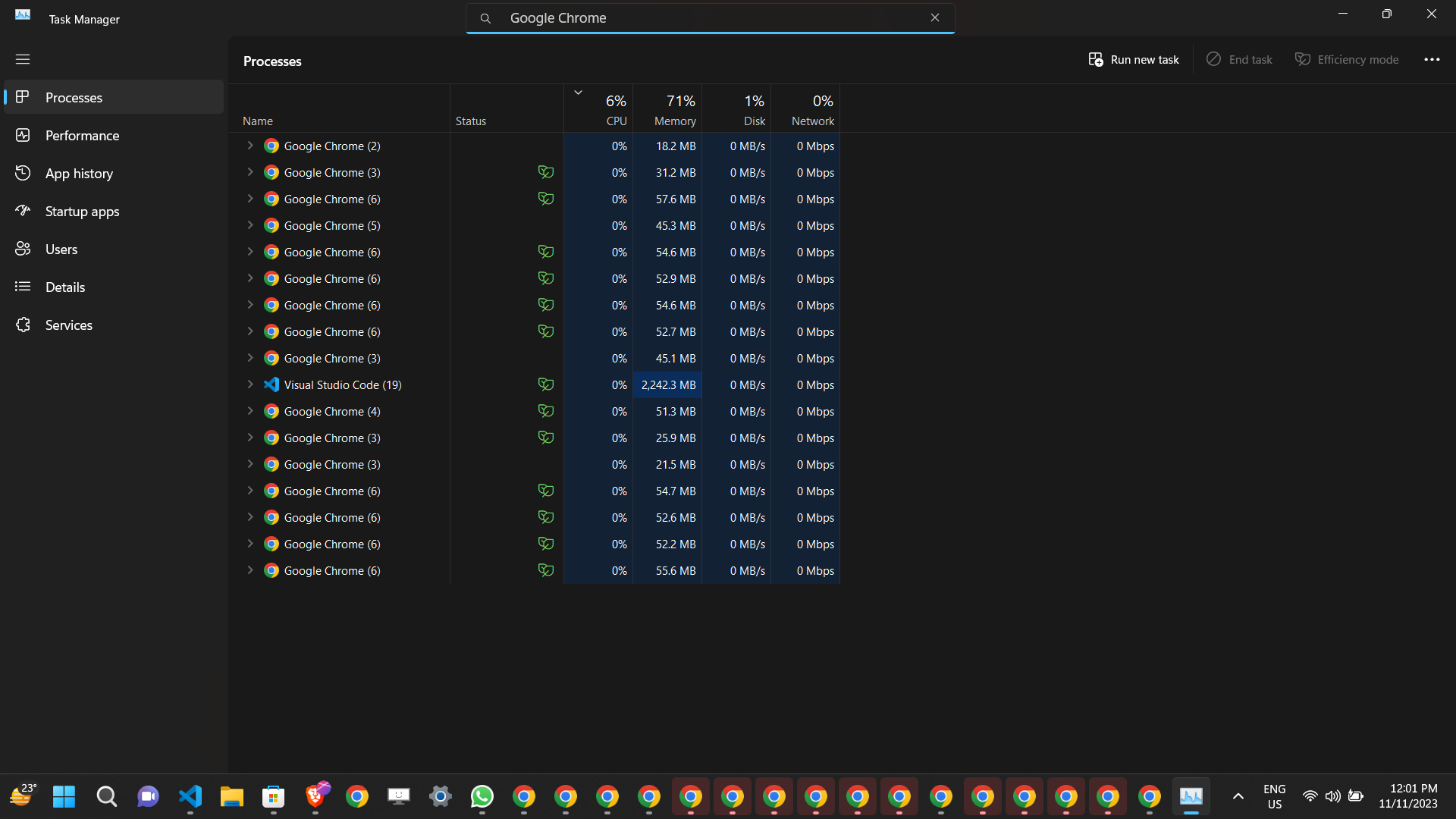
To prevent your PC from hanging, you need to close all running Chrome instances.
You can run following command to close all chromes
```shell
python -m botasaurus.close
```
Executing above command will close all Chrome instances, thereby helping to prevent your PC from hanging.
---
<!--
### What feautres are Coming in Botasaurus 4?
Botasaurus 4, which is currently in its beta phase, allows you to:
- A sms API to receive OTPs.
- Run bots in the cloud using a website UI and control their schedules, starting/stopping times, and view bot outputs in a web UI.
- Use Kubernetes to run thousands of bots in parallel.
- Schedule Scraping Tasks at specific times or intervals
- Whatsapp/Email Alerts
- MySQL/PostgreSQL Integration
- And Many More :) -->
<!-- Developers are actively using Botasaurus 4 in production environments and saving hours of Development Time. To get access to Botasaurus 4, please [reach out to us](mailto:chetan@omkar.cloud?subject=Access%20Botasaurus%204&body=I%20want%20to%20use%20Botasaurus%204%20and%20gain%20access%20to%20feature%3A%20%5BTELL%20YOUR%20FEATURE%5D) and let us know which feature you would like to access. -->
### Conclusion
Botasaurus is a powerful, flexible tool for web scraping.
Its various settings allow you to tailor the scraping process to your specific needs, improving both efficiency and convenience. Whether you're dealing with multiple data points, requiring parallel processing, or need to cache results, Botasaurus provides the features to streamline your scraping tasks.
### ❓ Need More Help or Have Additional Questions?
For further help, ask your question in GitHub Discussions. We'll be happy to help you out.
[](https://github.com/omkarcloud/botasaurus/discussions)
## Thanks
- Kudos to the Apify Team for creating the `got-scraping` and `proxy-chain` libraries. The implementation of stealth Anti Detect Requests and SSL-based Proxy Authentication wouldn't have been possible without their groundbreaking work on `got-scraping` and `proxy-chain`.
- Shout out to zfcsoftware for developing `puppeteer-real-browser`; it helped us in creating Botasaurus Anti Detected. Show your appreciation by subscribing to their [YouTube channel](https://www.youtube.com/@zfcsoftware/videos) ⚡.
- A special thanks to the Selenium team for creating Selenium, an invaluable tool in our toolkit.
- Thanks to Cloudflare, DataDome, Imperva, and all bot detectors. Had you not been there, we wouldn't be either 😅.
- Finally, a humongous thank you for choosing Botasaurus.
## Love It? [Star It! ⭐](https://github.com/omkarcloud/botasaurus)
Become one of our amazing stargazers by giving us a star ⭐ on GitHub!
It's just one click, but it means the world to me.
<a href="https://github.com/omkarcloud/botasaurus/stargazers">
<img src="https://bytecrank.com/nastyox/reporoster/php/stargazersSVG.php?user=omkarcloud&repo=botasaurus" alt="Stargazers for @omkarcloud/botasaurus">
</a>
## Sponsors
<a href="https://www.capsolver.com/?utm_source=github&utm_medium=banner_github&utm_campaign=botsaurus">
<img src="https://raw.githubusercontent.com/omkarcloud/botasaurus/master/images/capsolver.png" style="width: 70%;" alt="capsolver">
</a>
[Capsolver.com](https://www.capsolver.com/?utm_source=github&utm_medium=banner_github&utm_campaign=botsaurus) is an AI-powered service that provides automatic captcha solving capabilities. It supports a range of captcha types, including reCAPTCHA, hCaptcha, and FunCaptcha, AWS Captcha, Geetest, image captcha among others. Capsolver offers both Chrome and Firefox extensions for ease of use, API integration for developers, and various pricing packages to suit different needs.
## Disclaimer for Botasaurus Project
> By using Botasaurus, you agree to comply with all applicable local and international laws related to data scraping, copyright, and privacy. The developers of Botasaurus are not responsible for any misuse of this software. It is the sole responsibility of the user to ensure adherence to all relevant laws regarding data scraping, copyright, and privacy, and to use Botasaurus in an ethical and legal manner.
We take the concerns of the Botasaurus Project very seriously. For any inquiries or issues, please contact Chetan Jain at [chetan@omkar.cloud](mailto:chetan@omkar.cloud). We will take prompt and necessary action in response to your emails.
## Made with ❤️ in Bharat 🇮🇳 - Vande Mataram
Raw data
{
"_id": null,
"home_page": null,
"name": "botasaurus2",
"maintainer": null,
"docs_url": null,
"requires_python": "<4.0,>=3.10",
"maintainer_email": null,
"keywords": null,
"author": "Chetan Jain",
"author_email": "chetan@omkar.cloud",
"download_url": "https://files.pythonhosted.org/packages/65/05/ba49f7942cd0462b4622b5fb905f55deb3365a0209be28aa50612ba91a23/botasaurus2-1.4.13.tar.gz",
"platform": null,
"description": "<p align=\"center\">\n <img src=\"https://raw.githubusercontent.com/omkarcloud/botasaurus/master/images/mascot.png\" alt=\"botasaurus\" />\n</p>\n <div align=\"center\" style=\"margin-top: 0;\">\n <h1>\ud83e\udd16 Botasaurus \ud83e\udd16</h1>\n </div>\n\n<h3 align=\"center\">\n The All in One Framework to build Awesome Scrapers.\n</h3>\n\n<p align=\"center\">\n <b>The web has evolved. Finally, web scraping has too.</b>\n</p>\n\n\n<p align=\"center\">\n <img src=\"https://views.whatilearened.today/views/github/omkarcloud/botasaurus.svg\" width=\"80px\" height=\"28px\" alt=\"View\" />\n</p>\n\n\n<p align=\"center\">\n <a href=\"https://gitpod.io/#https://github.com/omkarcloud/botasaurus-starter\">\n <img alt=\"Run in Gitpod\" src=\"https://gitpod.io/button/open-in-gitpod.svg\" />\n </a>\n</p>\n\n\n\n## In a nutshell\n\nBotasaurus is an all-in-one web scraping framework that enables you to build awesome scrapers in less time. It solves the key pain points that we, as developers, face when scraping the modern web.\n\nOur mission is to make creating awesome scrapers easy for everyone.\n\n## Features\n\nBotasaurus is built for creating awesome scrapers. It comes fully baked, with batteries included. Here is a list of things it can do that no other web scraping framework can:\n\n- **Most Stealthiest Framework LITERALLY**: Based on the benchmarks, which we encourage you to read [here](https://github.com/omkarcloud/botasaurus-vs-undetected-chromedriver-vs-puppeteer-stealth-benchmarks), our framework stands as the most stealthy in both the JS and Python universes. It is more stealthy than the popular Python library `undetected-chromedriver` and the well-known JavaScript library `puppeteer-stealth`. Botasaurus can easily visit websites like `https://nowsecure.nl/`. With Botasaurus, you don't need to waste time finding ways to unblock a website. For usage, [see this FAQ.](https://github.com/omkarcloud/botasaurus/tree/master#can-you-bypass-cloudflareimperva-challenges)\n- **Access Cloudflare Websites with Simple HTTP Requests:** We can access Cloudflare-protected pages using simple HTTP requests. Saving you both time and money spent on proxies. For usage, [see this FAQ.](https://github.com/omkarcloud/botasaurus/tree/master#how-to-scrape-cloudflare-protected-websites-with-simple-http-requests)\n- **SSL Support for Authenticated Proxy:** We are the first and only Python Web Scraping Framework as of writing to offer SSL support for authenticated proxies. No other browser automation libraries be it seleniumwire, puppeteer, playwright offers this important web scraping feature, this feautre enables you to easily access Cloudflare protected websites when using authenticated proxies, which would otherwise be blocked if you used only the bare authenticated proxy.\n- **Use Any Chrome Extension with Just 1 Line of Code:** Easily integrate any Chrome extension, be it a Captcha Solving Extension, Adblocker, or any other from the Chrome Web Store, with just [one line of code.](https://github.com/omkarcloud/botasaurus#how-to-use-chrome-extensions). Say Sayonara, to the manual process of downloading, unzipping, configuring, and loading extensions. \n- **Sitemap Support:** With just [one line of code](https://github.com/omkarcloud/botasaurus#how-to-extract-links-from-a-sitemap), you can get all links for a website.\n- **Data Cleaners:** Make your scrapers robust by cleaning data with expert created data cleaners.\n- **Debuggability:** When a crash occurs due to an incorrect selector, etc., Botasaurus pauses the browser instead of closing it, facilitating painless on-the-spot debugging.\n- **Caching:** Botasaurus allows you to cache web scraping results, ensuring lightning-fast performance on subsequent scrapes.\n- **Easy Configuration:** Easily save hours of Development Time with easy parallelization, profile, and proxy configuration. We make asynchronous, parallel scraping a child's play.\n- **Build Robust Scrapers:** Easily configure retry on exceptions to ensure no errors comes in between you and the data\n- **Time-Saving Selenium Shortcuts:** Botasaurus comes with numerous Selenium shortcuts to make web scraping incredibly easy.\n\n## \ud83d\ude80 Getting Started with Botasaurus\n\nWelcome to Botasaurus! Let\u2019s dive right in with a straightforward example to understand how it works.\n\nIn this tutorial, we will go through the steps to scrape the heading text from [https://www.omkar.cloud/](https://www.omkar.cloud/).\n\n\n\n### Step 1: Install Botasaurus\n\nFirst things first, you need to install Botasaurus. Run the following command in your terminal:\n\n```shell\npython -m pip install botasaurus\n```\n\n### Step 2: Set Up Your Botasaurus Project\n\nNext, let\u2019s set up the project:\n\n1. Create a directory for your Botasaurus project and navigate into it:\n\n```shell\nmkdir my-botasaurus-project\ncd my-botasaurus-project\ncode . # This will open the project in VSCode if you have it installed\n```\n\n### Step 3: Write the Scraping Code\n\nNow, create a Python script named `main.py` in your project directory and insert the following code:\n\n```python\nfrom botasaurus import *\n\n@browser\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n # Navigate to the Omkar Cloud website\n driver.get(\"https://www.omkar.cloud/\")\n \n # Retrieve the heading element's text\n heading = driver.text(\"h1\")\n\n # Save the data as a JSON file in output/scrape_heading_task.json\n return {\n \"heading\": heading\n }\n \nif __name__ == \"__main__\":\n # Initiate the web scraping task\n scrape_heading_task()\n```\n\nLet\u2019s understand this code:\n\n- We define a custom scraping task, `scrape_heading_task`, decorated with `@browser`:\n```python\n@browser\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n``` \n\n- Botasaurus automatically provides an Anti Detection Selenium driver to our function:\n```python\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n``` \n\n- Inside the function, we:\n - Navigate to Omkar Cloud\n - Extract the heading text\n - Return the data to be automatically saved as `scrape_heading_task.json` by Botasaurus:\n```python\n driver.get(\"https://www.omkar.cloud/\")\n heading = driver.text(\"h1\")\n return {\"heading\": heading}\n``` \n\n- Finally, we initiate the scraping task:\n```python\nif __name__ == \"__main__\":\n scrape_heading_task()\n``` \n\n### Step 4: Run the Scraping Task\n\nTime to run your bot:\n\n```shell\npython main.py\n```\n\nAfter executing the script, it will:\n- Launch Google Chrome\n- Navigate to [omkar.cloud](https://www.omkar.cloud/)\n- Extract the heading text\n- Save it automatically as `output/scrape_heading_task.json`.\n\n\n\nNow, let\u2019s explore another way to scrape the heading using the `request` module. Replace the previous code in `main.py` with the following:\n\n```python\nfrom botasaurus import *\n\n@request\ndef scrape_heading_task(request: AntiDetectRequests, data):\n # Navigate to the Omkar Cloud website\n soup = request.bs4(\"https://www.omkar.cloud/\")\n \n # Retrieve the heading element's text\n heading = soup.find('h1').get_text()\n\n # Save the data as a JSON file in output/scrape_heading_task.json\n return {\n \"heading\": heading\n }\n \nif __name__ == \"__main__\":\n # Initiate the web scraping task\n scrape_heading_task()\n```\n\nIn this code:\n\n- We are using the BeautifulSoup (bs4) module to parse and scrape the heading.\n- The `request` object provided is not a standard Python request object but an Anti Detect request object, which also preserves cookies.\n\n### Step 5: Run the Scraping Task (Using Anti Detect Requests)\n\nFinally, run the bot again:\n\n```shell\npython main.py\n```\n\nThis time, you will observe the same result as before, but instead of using Anti Detect Selenium, we are utilizing the Anti Detect request module.\n\n*Note: If you don't have Python installed, then you can run Botasaurus in Gitpod, a browser-based development environment, by following [this section](https://github.com/omkarcloud/botasaurus#how-to-run-botasaurus-in-gitpod).*\n\n## \ud83d\udca1 Understanding Botasaurus\n\nLet's learn about the features of Botasaurus that assist you in web scraping and automation.\n\n### Could you show me an example where you access Cloudflare Protected Website?\n\nSure, Run the following Python code to access G2.com, a website protected by Cloudflare:\n\n```python\nfrom botasaurus import *\n\n@browser()\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.google_get(\"https://www.g2.com/products/github/reviews\")\n heading = driver.text('h1')\n print(heading)\n return heading\n\nscrape_heading_task()\n```\n\nAfter running this script, you'll notice that the G2 page opens successfully, and the code prints the page's heading.\n\n\n\n### How to Scrape Multiple Data Points/Links?\n\nTo scrape multiple data points or links, define the `data` variable and provide a list of items to be scraped:\n\n```python\n@browser(data=[\"https://www.omkar.cloud/\", \"https://www.omkar.cloud/blog/\", \"https://stackoverflow.com/\"])\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n # ...\n```\n\nBotasaurus will launch a new browser instance for each item in the list and merge and store the results in `scrape_heading_task.json` at the end of the scraping.\n\n\n\nPlease note that the `data` parameter can also handle items such as dictionaries.\n\n```python\n@browser(data=[{\"name\": \"Mahendra Singh Dhoni\", ...}, {\"name\": \"Virender Sehwag\", ...}])\ndef scrape_heading_task(driver: AntiDetectDriver, data: dict):\n # ...\n```\n\n### How to Scrape in Parallel?\n\nTo scrape data in parallel, set the `parallel` option in the browser decorator:\n\n```python\n@browser(parallel=3, data=[\"https://www.omkar.cloud/\", ...])\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n # ...\n```\n\n### How to know how many scrapers to run parallely?\n\nTo determine the optimal number of parallel scrapers, pass the `bt.calc_max_parallel_browsers` function, which calculates the maximum number of browsers that can be run in parallel based on the available RAM:\n\n```python\n@browser(parallel=bt.calc_max_parallel_browsers, data=[\"https://www.omkar.cloud/\", ...])\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n # ...\n```\n\n*Example: If you have 5.8 GB of free RAM, `bt.calc_max_parallel_browsers` would return 10, indicating you can run up to 10 browsers in parallel.*\n\n### How to Cache the Web Scraping Results?\n\nTo cache web scraping results and avoid re-scraping the same data, set `cache=True` in the decorator:\n\n```python\n@browser(cache=True, data=[\"https://www.omkar.cloud/\", ...])\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n # ... \n```\n\n\n### How Botasaurus helps me in debugging?\n\nBotasaurus enhances the debugging experience by pausing the browser instead of closing it when an error occurs. This allows you to inspect the page and understand what went wrong, which can be especially helpful in debugging and removing the hassle of reproducing edge cases.\n\nBotasaurus also plays a beep sound to alert you when an error occurs.\n\n\n\n### How to Block Resources like CSS, Images, and Fonts to Save Bandwidth?\n\nBlocking resources such as CSS, images, and fonts can significantly speed up your web scraping tasks, reduce bandwidth usage, and save money spent on proxies.\n\nFor example, a page that originally takes 4 seconds and 12 MB's to load might only take one second and 100 KB to load after css, images, etc have been blocked.\n\nTo block images, simply use the `block_resources` parameter. For example:\n\n```python\n@browser(block_resources=True) # Blocks ['.css', '.jpg', '.jpeg', '.png', '.svg', '.gif', '.woff', '.pdf', '.zip']\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.get(\"https://www.omkar.cloud/\")\n driver.prompt()\n \nscrape_heading_task() \n```\n\nIf you wish to block only images and fonts, while allowing CSS files, you can set `block_images` like this:\n\n```python\n@browser(block_images=True) # Blocks ['.jpg', '.jpeg', '.png', '.svg', '.gif', '.woff', '.pdf', '.zip']\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.get(\"https://www.omkar.cloud/\")\n driver.prompt()\n\nscrape_heading_task() \n```\n\nTo block a specific set of resources, such as only JavaScript, CSS, fonts, etc., specify them in the following manner:\n\n```python\n@browser(block_resources=['.js', '.css', '.jpg', '.jpeg', '.png', '.svg', '.gif', '.woff', '.pdf', '.zip'])\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.get(\"https://www.omkar.cloud/\")\n driver.prompt()\n\nscrape_heading_task() \n```\n\n### How to Configure UserAgent, Proxy, Chrome Profile, Headless, etc.?\n\nTo configure various settings such as UserAgent, Proxy, Chrome Profile, and headless mode, you can specify them in the decorator as shown below:\n\n```python\nfrom botasaurus import *\n\n@browser(\n headless=True, \n profile='my-profile', \n# proxy=\"http://your_proxy_address:your_proxy_port\", TODO: Replace with your own proxy\n user_agent=bt.UserAgent.user_agent_106\n)\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.get(\"https://www.omkar.cloud/\")\n driver.prompt()\n\nscrape_heading_task()\n```\n\n\nYou can also pass additional parameters when calling the scraping function, as demonstrated below:\n\n```python\n@browser()\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n # ...\n\ndata = \"https://www.omkar.cloud/\"\nscrape_heading_task(\n data, \n headless=True, \n profile='my-profile', \n proxy=\"http://your_proxy_address:your_proxy_port\",\n user_agent=bt.UserAgent.user_agent_106\n)\n```\n\nFurthermore, it's possible to define functions that dynamically set these parameters based on the data item. For instance, to set the profile dynamically according to the data item, you can use the following approach:\n\n```python\n@browser(profile=lambda data: data[\"profile\"], headless=True, proxy=\"http://your_proxy_address:your_proxy_port\", user_agent=bt.UserAgent.user_agent_106)\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n # ...\n\ndata = {\"link\": \"https://www.omkar.cloud/\", \"profile\": \"my-profile\"}\nscrape_heading_task(data)\n```\n\nAdditionally, if you need to pass metadata that is common across all data items, such as an API Key, you can do so by adding it as a `metadata` parameter. For example:\n\n```python\n@browser()\ndef scrape_heading_task(driver: AntiDetectDriver, data, metadata):\n print(\"metadata:\", metadata)\n print(\"data:\", data)\n\ndata = {\"link\": \"https://www.omkar.cloud/\", \"profile\": \"my-profile\"}\nscrape_heading_task(\n data, \n metadata={\"api_key\": \"BDEC26...\"}\n)\n```\n\n\n<!-- ### How Can I Save Data With a Different Name Instead of 'all.json'?\n\nTo save the data with a different filename, pass the desired filename along with the data in a tuple as shown below:\n\n```python\n@browser(block_resources=True, cache=True)\ndef scrape_article_links(driver: AntiDetectDriver, data):\n # Visit the Omkar Cloud website\n driver.get(\"https://www.omkar.cloud/blog/\")\n \n links = driver.links(\"h3 a\")\n\n filename = \"links\"\n return filename, links\n```\n -->\n\n\n\n\n### Do you support SSL for Authenticated Proxies?\n\nYes, we are the first Python Library to support SSL for authenticated proxies. Proxy providers like BrightData, IPRoyal, and others typically provide authenticated proxies in the format \"http://username:password@proxy-provider-domain:port\". For example, \"http://greyninja:awesomepassword@geo.iproyal.com:12321\".\n\nHowever, if you use an authenticated proxy with a library like seleniumwire to scrape a Cloudflare protected website like G2.com, you will surely be blocked because you are using a non-SSL connection. \n\nTo verify this, run the following code:\n\nFirst, install the necessary packages:\n```bash \npython -m pip install selenium_wire chromedriver_autoinstaller_fix\n```\n\nThen, execute this Python script:\n```python\nfrom seleniumwire import webdriver\nfrom chromedriver_autoinstaller_fix import install\n\n# Define the proxy\nproxy_options = {\n 'proxy': {\n 'http': 'http://username:password@proxy-provider-domain:port', # TODO: Replace with your own proxy\n 'https': 'http://username:password@proxy-provider-domain:port', # TODO: Replace with your own proxy\n }\n}\n\n# Install and set up the driver\ndriver_path = install()\ndriver = webdriver.Chrome(driver_path, seleniumwire_options=proxy_options)\n\n# Navigate to the desired URL\nlink = 'https://www.g2.com/products/github/reviews'\ndriver.get(\"https://www.google.com/\")\ndriver.execute_script(f'window.location.href = \"{link}\"')\n\n# Prompt for user input\ninput(\"Press Enter to exit...\")\n\n# Clean up\ndriver.quit()\n```\n\nYou will definitely encounter a block by Cloudflare:\n\n\n\nHowever, using proxies with Botasaurus prevents this issue. See the difference by running the following code:\n```python\nfrom botasaurus import *\n\n@browser(proxy=\"http://username:password@proxy-provider-domain:port\") # TODO: Replace with your own proxy \ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.google_get(\"https://www.g2.com/products/github/reviews\")\n driver.prompt()\nscrape_heading_task() \n``` \n\nResult: \n\n\nNOTE: To run the code above, you will need Node.js installed.\n\n### How to Access Cloudflare-Protected Websites Using Simple HTTP Requests?\n\nWe can access Cloudflare-protected pages using simple HTTP requests.\n\nAll you need to do is specify the `use_stealth` option.\n\nSounds too good to be true? Run the following code to see it in action:\n\n```python\nfrom botasaurus import *\n\n@request(use_stealth=True)\ndef scrape_heading_task(request: AntiDetectRequests, data):\n response = request.get('https://www.g2.com/products/github/reviews')\n print(response.status_code)\n return response.text\n\nscrape_heading_task()\n```\n\n### Can you access websites protected by Cloudflare JS Challenge?\n\nYes, we can. Let's learn about various challenges and the best ways to solve them.\n\n*Connection Challenge*\n\nThis is the most popular challenge and requires making a browser-like connection with appropriate headers to the target website. It's commonly used to protect:\n- Product Pages\n- Blog Pages\n- Search Result Pages\n\nExample Page: https://www.g2.com/products/github/reviews\n\n#### What Does Not Work?\n\nUsing `cloudscraper` library fails because, while it sends browser-like user agents and headers, it does not establish a browser-like connection, leading to detection.\n\n#### What Works?\n\n- Use the stealth request mode and visit via Google (default behavior). [Recommended]\n```python\nfrom botasaurus import *\n\n@request(use_stealth=True)\ndef scrape_heading_task(request: AntiDetectRequests, data):\n response = request.get('https://www.g2.com/products/github/reviews')\n print(response.status_code)\n return response.text\n\nscrape_heading_task()\n```\n\n- Use a real Chrome browser with Selenium and visit via Google. Example Code:\n```python\nfrom botasaurus import *\n\n@browser()\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.google_get(\"https://www.g2.com/products/github/reviews\")\n driver.prompt()\n heading = driver.text('h1')\n return heading\n\nscrape_heading_task()\n```\n\n*JS Challenge*\n\nThis challenge requires performing JS computations that differentiates a Chrome controlled by Selenium/Puppeteer/Playwright from a real Chrome. \n\nIt's commonly used to protect Auth pages:\n\nExample Pages: https://nowsecure.nl/\n\n#### What Does Not Work?\n\nBare `selenium` and `puppeteer` definitely do not work due to a lot of automation noise. `undetected-chromedriver` and `puppeteer-stealth` also fail to access sites protected by JS Challenge like https://nowsecure.nl/. \n\n#### What Works?\n\nThe Stealth Browser can easily solve JS Challenges. See the truth for yourself by running this code:\n\n```python\nfrom botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\n@browser(\n create_driver=create_stealth_driver(\n start_url=\"https://nowsecure.nl/\",\n ),\n)\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.prompt()\n heading = driver.text('h1')\n return heading\n\nscrape_heading_task() \n```\n\n*JS with Captcha Challenge*\n\nThis challenge involves JS computations plus solving a Captcha. It's used to protect pages which are rarely but sometimes visited by humans, like:\n- 5th Page of G2 Reviews\n- 8th Page of Google Search Results\n\nExample Page: https://www.g2.com/products/github/reviews.html?page=5&product_id=github\n\n#### What Does Not Work?\n\nAgain, tools like `selenium`, `puppeteer`, `undetected-chromedriver`, and `puppeteer-stealth` fail.\n\n#### What Works?\n\nThe Stealth Browser can easily solve these challenges. See it in action by running this code:\n\n```python\nfrom botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\n@browser(\n create_driver=create_stealth_driver(\n start_url=\"https://www.g2.com/products/github/reviews.html?page=5&product_id=github\",\n ),\n)\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.prompt()\n heading = driver.text('h1')\n return heading\n\nscrape_heading_task()\n```\n\n*Notes:*\n1. In stealth browser mode, we default to an 8-second wait before connecting to the browser via Selenium because connecting too early gets us detected. You can customize the wait time by using the `wait` argument. \n```python\nfrom botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\n@browser(\n create_driver=create_stealth_driver(\n start_url=\"https://nowsecure.nl/\",\n wait=4, # Waits for 4 seconds before connecting to browser\n ),\n)\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.prompt()\n heading = driver.text('h1')\n return heading\n\nscrape_heading_task()\n```\n\nHere are some recommendations for wait times:\n\n- For active development with fast internet, set the wait time to **4 seconds**. You most likely have a fast internet connection, so set the wait time to **4 seconds** when developing your Bot.\n- If during development you have a slow internet connection, then stick with the default **8 seconds**.\n<!-- - When running your bot in the cloud via proxies, increase the wait time to **20 seconds** due to longer data download times.\n- For slow proxies, set the wait time to **28 seconds**. -->\n\n2. If you get detected, try changing your IP. Let me share with you The **fastest**, **simplest**, and best of all, the **free** way to change your IP:\n\n- **Connect your PC to the Internet via a Mobile Hotspot.**\n- **Toggle airplane mode off and on on your mobile device.** This will assign you a new IP address.\n- **Turn the hotspot back on.**\n- **Voila, you have a new, high-quality mobile IP for free!**\n\n<!-- 3. If you are running the bot in Docker on a server and experiencing detection issues, it's suggested to use residential proxies. -->\n\n3. If you are automating Cloudflare Websites with JS Challenges like https://nowsecure.nl/, then you must pass start_url to solve them like this:\n```python\nfrom botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\n@browser(\n create_driver=create_stealth_driver(\n start_url=\"https://nowsecure.nl/\", # Must for Websites Protected by Cloudflare JS Challenge\n ),\n)\n```\n\nHowever, if you are automating websites not protected by Cloudflare or protected by Cloudflare Connection Challenge, then you may pass `None` to start_url. With this, we will also not perform a wait before connecting to Chrome, saving you time.\n\n```python\nfrom botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\n@browser(\n create_driver=create_stealth_driver(\n start_url=None, # Recommended for Websites not protected by Cloudflare or protected by Cloudflare Connection Challenge\n ),\n)\n```\n\n\n4. Anti Detection Systems can detect fake randomly generated user agents. So, if you are getting detected, especially on Ubuntu with Cloudflare JS with Captcha Challenge, we recommend using your real user agent and window size, not a randomly generated one. Here's how you can do it:\n```python\nfrom botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\n@browser(\n user_agent=bt.UserAgent.REAL, \n window_size=bt.WindowSize.REAL,\n create_driver=create_stealth_driver(\n start_url=\"https://nowsecure.nl/\",\n ),\n)\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.prompt()\n heading = driver.text('h1')\n return heading\n\nscrape_heading_task()\n```\n\nIf you are doing web scraping of publicly available data, then the above code is good and recommended to be used. but stealth driver is fingerprintable using tools like [fingerprint](https://fingerprint.com/).\n\n5. We expect to access Cloudflare websites 9 out of 10 times. However, in some cases, they do detect us for reasons like IP blacklisting. In such cases, you can use the following code snippet to make your scraper more robust:\n```python\nfrom botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\ndef get_start_url(data):\n return data\n\n@browser(\n # proxy=\"http://username:password@proxy-domain:12321\" # optionally use proxy\n # user_agent=bt.UserAgent.REAL, # Optionally use REAL User Agent\n # window_size=bt.WindowSize.REAL, # Optionally use REAL Window Size\n max_retry=5,\n create_driver=create_stealth_driver(\n start_url=get_start_url,\n raise_exception=True, \n ),\n)\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n driver.prompt()\n heading = driver.text('h1')\n return heading\n\nscrape_heading_task([\"https://nowsecure.nl/\", \"https://steamdb.info/sub/363669/apps\"])\n``` \n\nThe above code makes the scraper more robust by raising an exception when detected and retrying up to 5 times to visit the website.\n\n### How to Solve Captchas in Web Scraping?\n\nFacing captchas is really common and annoying hurdle in web scraping. Fortunately, CapSolver can be used to automatically solve captchas, saving both time and effort. Here's how you can use it:\n\n```python\nfrom botasaurus import *\nfrom capsolver_extension_python import Capsolver\n\n@browser(\n extensions=[Capsolver(api_key=\"CAP-MY_KEY\")], # Replace \"CAP-MY_KEY\" with your actual CapSolver Key\n) \ndef solve_captcha(driver: AntiDetectDriver, data):\n driver.get(\"https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php\")\n driver.prompt()\n\nsolve_captcha()\n```\n\nTo solve captcha's with CapSolver, you will need Capsolver API Key. If you do not have a CapSolver API Key, follow the instructions [here](https://github.com/omkarcloud/botasaurus/blob/master/capsolver-sign-up.md) to create a CapSolver account and obtain one.\n\n### How to Use Chrome Extensions?\n\nBotasaurus allows the use of ANY Chrome Extension with just 1 Line of Code. Below is an example that uses the AdBlocker Chrome Extension:\n\n```python\nfrom botasaurus import *\nfrom chrome_extension_python import Extension\n\n@browser(\n extensions=[Extension(\"https://chromewebstore.google.com/detail/adblock-%E2%80%94-best-ad-blocker/gighmmpiobklfepjocnamgkkbiglidom\")], # Simply pass the Extension Link\n) \ndef open_chrome(driver: AntiDetectDriver, data):\n driver.prompt()\n\nopen_chrome()\n```\n\nAlso, In some cases an extension requires additional configuration like API keys or credentials, for that you can create a Custom Extension. Learn how to create and configure Custom Extension [here](https://github.com/omkarcloud/chrome-extension-python).\n\n\n### I want to Scrape a large number of Links, a new selenium driver is getting created for each new link, this increases the time to scrape data. How can I reuse Drivers?\n\nUtilize the `reuse_driver` option to reuse drivers, reducing the time required for data scraping:\n\n```python\n@browser(reuse_driver=True)\ndef scrape_heading_task(driver: AntiDetectDriver, data):\n # ...\n```\n\n### How to Extract Links from a Sitemap?\n\nIn web scraping, it is a common use case to scrape product pages, blogs, etc. But before scraping these pages, you need to get the links to these pages.\n\nMany developers unnecessarily increase their work by writing code to visit each page one by one and scrape links, which they could have easily by just looking at the Sitemap.\n\nThe Botasaurus Sitemap Module makes this process easy as cake by allowing you to get all links or sitemaps using:\n- The homepage URL (e.g., `https://www.omkar.cloud/`)\n- A direct sitemap link (e.g., `https://www.omkar.cloud/sitemap.xml`)\n- A `.gz` compressed sitemap\n\nFor example, to get a list of books from bookswagon.com, you can use following code:\n\n```python\nfrom botasaurus import *\nfrom botasaurus.sitemap import Sitemap, Filters\n\nlinks = (\n Sitemap(\"https://www.bookswagon.com/googlesitemap/sitemapproducts-1.xml\")\n .filter(Filters.first_segment_equals(\"book\"))\n .links()\n)\nbt.write_temp_json(links)\n```\n\n**Output:** \n\n\n\nOr, Let's say you're in the mood for some reading and looking for good stories, the following code will get you over 1000+ stories from [moralstories26.com](https://moralstories26.com/):\n\n```python\nfrom botasaurus import *\nfrom botasaurus.sitemap import Sitemap, Filters\n\nlinks = (\n Sitemap(\"https://moralstories26.com/\")\n .filter(\n Filters.has_exactly_1_segment(),\n Filters.first_segment_not_equals(\n [\"about\", \"privacy-policy\", \"akbar-birbal\", \"animal\", \"education\", \"fables\", \"facts\", \"family\", \"famous-personalities\", \"folktales\", \"friendship\", \"funny\", \"heartbreaking\", \"inspirational\", \"life\", \"love\", \"management\", \"motivational\", \"mythology\", \"nature\", \"quotes\", \"spiritual\", \"uncategorized\", \"zen\"]\n ),\n )\n .links()\n)\n\nbt.write_temp_json(links)\n```\n\n**Output:** \n\n\n\nAlso, Before scraping a site, it's useful to identify the available sitemaps. This can be easily done with the following code:\n\n```python\nfrom botasaurus import *\nfrom botasaurus.sitemap import Sitemap\n\nsitemaps = Sitemap(\"https://www.omkar.cloud/\").sitemaps()\nbt.write_temp_json(sitemaps)\n```\n\n**Output:** \n\n\n\nTo ensure your scrapers run super fast, we cache the Sitemap, but you may want to periodically refresh the cache, which you can do as follows:\n\n```python\nfrom botasaurus import *\nfrom botasaurus.sitemap import Sitemap\nfrom botasaurus.cache import Cache\n\nsitemap = Sitemap(\n [\n \"https://moralstories26.com/post-sitemap.xml\",\n \"https://moralstories26.com/post-sitemap2.xml\",\n ],\n cache=Cache.REFRESH, # Refresh the cache with up-to-date stories.\n)\n\nlinks = sitemap.links()\nbt.write_temp_json(links)\n```\n\nIn summary, the sitemap is an awesome module for easily extracting links you want for web scraping.\n\n### Could you show me a practical example where all these Botasaurus Features Come Together to accomplish a typical web scraping project?\n\nBelow is a practical example of how Botasaurus features come together in a typical web scraping project to scrape a list of links from a blog, and then visit each link to retrieve the article's heading and date:\n\n```python\nfrom botasaurus import *\n\n@browser(block_resources=True,\n cache=True, \n parallel=bt.calc_max_parallel_browsers, \n reuse_driver=True)\ndef scrape_articles(driver: AntiDetectDriver, link):\n driver.get(link)\n\n heading = driver.text(\"h1\")\n date = driver.text(\"time\")\n\n return {\n \"heading\": heading, \n \"date\": date, \n \"link\": link, \n }\n\n@browser(block_resources=True, cache=True)\ndef scrape_article_links(driver: AntiDetectDriver, data):\n # Visit the Omkar Cloud website\n driver.get(\"https://www.omkar.cloud/blog/\")\n \n links = driver.links(\"h3 a\")\n\n return links\n\nif __name__ == \"__main__\":\n # Launch the web scraping task\n links = scrape_article_links()\n scrape_articles(links)\n```\n\n### How to Clean Data?\nBotasaurus provides a module named `cl` that includes commonly used cleaning functions to save development time. Here are some of the most important ones:\n\n1. **`cl.select`** \n What `document.querySelector` is to js, is what `cl.select` is to json. This is the most used function in Botasaurus and is incredibly useful.\n\n This powerful function is popular for safely selecting data from nested JSON.\n\n Instead of using flaky code like this:\n ```python\n from botasaurus import cl\n\n data = {\n \"person\": {\n \"data\": {\n \"name\": \"Omkar\",\n \"age\": 21\n }\n },\n \"data\": {\n \"friends\": [\n {\"name\": \"John\", \"age\": 21},\n {\"name\": \"Jane\", \"age\": 21},\n {\"name\": \"Bob\", \"age\": 21}\n ]\n }\n }\n\n name = data.get('person', {}).get('data', {}).get('name', None)\n if name:\n name = name.upper()\n else:\n name = None\n print(name)\n ```\n\n You can write it as:\n ```python\n from botasaurus import cl\n\n data = {\n \"person\": {\n \"data\": {\n \"name\": \"Omkar\",\n \"age\": 21\n }\n },\n \"data\": {\n \"friends\": [\n {\"name\": \"John\", \"age\": 21},\n {\"name\": \"Jane\", \"age\": 21},\n {\"name\": \"Bob\", \"age\": 21}\n ]\n }\n }\n print(cl.select(data, 'name', map_data=lambda x: x.upper()))\n ```\n\n `cl.select` returns `None` if the key is not found, instead of throwing an error.\n ```python\n from botasaurus import cl\n\n print(cl.select(data, 'name')) # Omkar\n print(cl.select(data, 'friends', 0, 'name')) # John\n print(cl.select(data, 'friends', 0, 'non_existing_key')) # None\n ```\n\n You can also use `map_data` like this:\n ```python\n from botasaurus import cl\n\n cl.select(data, 'name', map_data=lambda x: x.upper()) # OMKAR\n ```\n\n And use default values like this:\n ```python\n from botasaurus import cl\n\n cl.select(None, 'name', default=\"OMKAR\") # OMKAR\n ```\n\n2. **`cl.extract_numbers`**\n ```python\n from botasaurus import cl\n\n print(cl.extract_numbers(\"I can extract numbers with decimal like 4.5, or with comma like 1,000.\")) # [4.5, 1000]\n ```\n\n3. **More Functions**\n ```python\n from botasaurus import cl\n\n print(cl.extract_links(\"I can extract links like https://www.omkar.cloud/ or https://www.omkar.cloud/blog/\")) # ['https://www.omkar.cloud/', 'https://www.omkar.cloud/blog/']\n print(cl.rename_keys({\"name\": \"Omkar\", \"age\": 21}, {\"name\": \"full_name\"})) # {\"full_name\": \"Omkar\", \"age\": 21}\n print(cl.sort_object_by_keys({\"age\": 21, \"name\": \"Omkar\"}, \"name\")) # {\"name\": \"Omkar\", \"age\": 21}\n print(cl.extract_from_dict([{\"name\": \"John\", \"age\": 21}, {\"name\": \"Jane\", \"age\": 21}, {\"name\": \"Bob\", \"age\": 21}], \"name\")) # [\"John\", \"Jane\", \"Bob\"]\n # ... And many more\n ```\n### How to Read/Write JSON and CSV Files?\n\nBotasaurus provides convenient methods for reading and writing data:\n\n```python\n# Data to write to the file\ndata = [\n {\"name\": \"John Doe\", \"age\": 42},\n {\"name\": \"Jane Smith\", \"age\": 27},\n {\"name\": \"Bob Johnson\", \"age\": 35}\n]\n\n# Write the data to the file \"data.json\"\nbt.write_json(data, \"data.json\")\n\n# Read the contents of the file \"data.json\"\nprint(bt.read_json(\"data.json\"))\n\n# Write the data to the file \"data.csv\"\nbt.write_csv(data, \"data.csv\")\n\n# Read the contents of the file \"data.csv\"\nprint(bt.read_csv(\"data.csv\"))\n```\n\n### How Can I Pause the Scraper to Inspect Things While Developing?\n\nTo pause the scraper and wait for user input before proceeding, use `bt.prompt()`:\n\n```python\nbt.prompt()\n```\n\n### How Does AntiDetectDriver Facilitate Easier Web Scraping?\n\nAntiDetectDriver is a patched Version of Selenium that has been modified to avoid detection by bot protection services such as Cloudflare. \n\nIt also includes a variety of helper functions that make web scraping tasks easier.\n\nYou can learn about these methods [here](https://github.com/omkarcloud/botasaurus/blob/master/anti-detect-driver.md).\n\n### What Features Does @request Support, Similar to @browser?\n\nSimilar to @browser, @request supports features like \n - asynchronous execution [Will Learn Later]\n - parallel processing\n - caching\n - user-agent customization\n - proxies, etc.\n\nBelow is an example that showcases these features:\n\n\n```python\n@request(parallel=40, cache=True, proxy=\"http://your_proxy_address:your_proxy_port\", data=[\"https://www.omkar.cloud/\", ...])\ndef scrape_heading_task(request: AntiDetectDriver, link):\n soup = request.bs4(link)\n heading = soup.find('h1').get_text()\n return {\"heading\": heading}\n```\n\n### I have an existing project into which I want to integrate the AntiDetectDriver/AntiDetectRequests.\n\nYou can create an instance of `AntiDetectDriver` as follows:\n```python\ndriver = bt.create_driver()\n# ... Code for scraping\ndriver.quit()\n```\n\nYou can create an instance of `AntiDetectRequests` as follows:\n```python\nanti_detect_request = bt.create_request()\nsoup = anti_detect_request.bs4(\"https://www.omkar.cloud/\")\n# ... Additional code\n```\n\n--- \n\n### How to Run Botasaurus in Docker?\n\nTo run Botasaurus in Docker, use the Botasaurus Starter Template, which includes the necessary Dockerfile and Docker Compose configurations:\n\n```\ngit clone https://github.com/omkarcloud/botasaurus-starter my-botasaurus-project\ncd my-botasaurus-project\ndocker-compose build && docker-compose up\n```\n\n### How to Run Botasaurus in Gitpod?\n\nBotasaurus Starter Template comes with the necessary `.gitpod.yml` to easily run it in Gitpod, a browser-based development environment. Set it up in just 5 minutes by following these steps:\n\n1. Open Botasaurus Starter Template, by visiting [this link](https://gitpod.io/#https://github.com/omkarcloud/botasaurus-starter) and sign up on gitpod.\n \n \n \n<!-- 2. To speed up scraping, select the Large 8 Core, 16 GB Ram Machine and click the `Continue` button. \n\n  -->\n\n2. In the terminal, run the following command to start scraping:\n```bash\npython main.py\n```\n\n\n## Advanced Features\n\n\n### How Do I Configure the Output of My Scraping Function in Botasaurus?\nTo configure the output of your scraping function in Botasaurus, you can customize the behavior in several ways:\n\n1. **Change Output Filename**: Use the `output` parameter in the decorator to specify a custom filename for the output. \n ```python\n @browser(output=\"my-output\")\n def scrape_heading_task(driver: AntiDetectDriver, data): \n # Your scraping logic here\n ```\n\n2. **Disable Output**: If you don't want any output to be saved, set `output` to `None`.\n ```python\n @browser(output=None)\n def scrape_heading_task(driver: AntiDetectDriver, data): \n # Your scraping logic here\n ```\n\n3. **Dynamically Write Output**: To dynamically write output based on data and result, pass a function to the `output` parameter:\n ```python\n def write_output(data, result):\n bt.write_json(result, 'data')\n bt.write_csv(result, 'data')\n\n @browser(output=write_output) \n def scrape_heading_task(driver: AntiDetectDriver, data): \n # Your scraping logic here\n ```\n\n4. **Save Outputs in Multiple Formats**: Use the `output_formats` parameter to save outputs in different formats like CSV and JSON.\n ```python\n @browser(output_formats=[bt.Formats.CSV, bt.Formats.JSON]) \n def scrape_heading_task(driver: AntiDetectDriver, data): \n # Your scraping logic here\n ```\n\nThese options provide flexibility in how you handle the output of your scraping tasks with Botasaurus.\n\n### How to Run Drivers Asynchronously from the Main Process?\n\nTo execute drivers asynchronously, enable the `async` option and use `.get()` when you're ready to collect the results:\n\n```python\nfrom botasaurus import * \nfrom time import sleep\n\n@browser(\n run_async=True, # Specify the Async option here\n)\ndef scrape_heading(driver: AntiDetectDriver, data):\n print(\"Sleeping for 5 seconds.\")\n sleep(5)\n print(\"Slept for 5 seconds.\")\n return {}\n\nif __name__ == \"__main__\":\n # Launch web scraping tasks asynchronously\n result1 = scrape_heading() # Launches asynchronously\n result2 = scrape_heading() # Launches asynchronously\n\n result1.get() # Wait for the first result\n result2.get() # Wait for the second result\n```\n\nWith this method, function calls run concurrently. The output will indicate that both function calls are executing in parallel.\n\n### How to Asynchronously Add Multiple Items and Get Results?\n\nThe `async_queue` feature allows you to perform web scraping tasks in asyncronously in a queue, without waiting for each task to complete before starting the next one. To gather your results, simply use the `.get()` method when all tasks are in the queue.\n\n#### Basic Example:\n\n```python\nfrom botasaurus import * \nfrom time import sleep\n\n@browser(async_queue=True)\ndef scrape_data(driver: AntiDetectDriver, data):\n print(\"Starting a task.\")\n sleep(1) # Simulate a delay, e.g., waiting for a page to load\n print(\"Task completed.\")\n return data\n\nif __name__ == \"__main__\":\n # Start scraping tasks without waiting for each to finish\n async_queue = scrape_data() # Initializes the queue\n\n # Add tasks to the queue\n async_queue.put([1])\n async_queue.put(2)\n async_queue.put([3, 4])\n\n # Retrieve results when ready\n results = async_queue.get() # Expects to receive: [1, 2, 3, 4]\n```\n\n#### Practical Application for Web Scraping:\n\nHere's how you could use `async_queue` to scrape webpage titles while scrolling through a list of links:\n\n```python\nfrom botasaurus import * \n\n@browser(async_queue=True)\ndef scrape_title(driver: AntiDetectDriver, link):\n driver.get(link) # Navigate to the link\n return driver.title # Scrape the title of the webpage\n\n@browser()\ndef scrape_all_titles(driver: AntiDetectDriver):\n # ... Your code to visit the initial page ...\n\n title_queue = scrape_title() # Initialize the asynchronous queue\n \n while not end_of_page_detected(driver): # Replace with your end-of-list condition\n title_queue.put(driver.links('a')) # Add each link to the queue\n driver.scroll(\".scrollable-element\")\n \n\n return title_queue.get() # Get all the scraped titles at once\n\nif __name__ == \"__main__\":\n all_titles = scrape_all_titles() # Call the function to start the scraping process\n```\n\n**Note:** The `async_queue` will only invoke the scraping function for unique links, avoiding redundant operations and keeping the main function (`scrape_all_titles`) cleaner.\n\n### I want to repeatedly call the scraping function without creating new Selenium drivers each time. How can I achieve this?\n\nUtilize the `keep_drivers_alive` option to maintain active driver sessions. Remember to call `.close()` when you're finished to release resources:\n\n```python\nfrom botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\n@browser(\n keep_drivers_alive=True, \n reuse_driver=True, # Also commonly paired with `keep_drivers_alive`\n)\ndef scrape_data(driver: AntiDetectDriver, link):\n driver.get(link)\n\nif __name__ == \"__main__\":\n scrape_data([\"https://moralstories26.com/\", \"https://moralstories26.com/page/2/\", \"https://moralstories26.com/page/3/\"])\n # After completing all scraping tasks, call .close() to close the drivers.\n scrape_data.close()\n```\n\n\n### How do I manage the Cache in Botasaurus?\n\nYou can use The Cache Module in Botasaurus to easily manage cached data. Here's a simple example explaining its usage:\n\n```python\nfrom botasaurus import *\nfrom botasaurus.cache import Cache\n\n# Example scraping function\n@request\ndef scrape_data(data):\n # Your scraping logic here\n return {\"processed\": data}\n\n# Sample data for scraping\ninput_data = {\"key\": \"value\"}\n\n# Adding data to the cache\nCache.put(scrape_data, input_data, scrape_data(input_data))\n# Checking if data is in the cache\nif Cache.has(scrape_data, input_data):\n # Retrieving data from the cache\n cached_data = Cache.get(scrape_data, input_data)\n# Removing specific data from the cache\nCache.remove(scrape_data, input_data)\n# Clearing the complete cache for the scrape_data function\nCache.clear(scrape_data)\n```\n\n### Any Tips for Scraping Cloudflare-Protected Websites?\n- Use stealth driver\n- For large-scale scraping, opt for Data Center Proxies over Residential as Residential Proxies are really expensive. Sometimes you will get blocked; so, use retries as demonstrated in the code below:\n```python\n from botasaurus import *\nfrom botasaurus.create_stealth_driver import create_stealth_driver\n\n @browser(\n create_driver=create_stealth_driver(\n start_url=\"https://nowsecure.nl/\",\n ),\n proxy=\"http://username:password@datacenter-proxy-domain:12321\", \n max_retry=5, # A reliable default for most situations, will retry creating driver if detected.\n block_resources=True, # Enhances efficiency and cost-effectiveness\n )\n def scrape_heading_task(driver: AntiDetectDriver, data):\n heading = driver.text('h1')\n print(heading)\n return heading\n```\n\n\n### How Do I Close All Running Chrome Instances When Developing with Botasaurus?\n\nWhile developing a scraper, you might need to interrupt the scraping process, often done by pressing `Ctrl + C`. However, this action does not automatically close the Chrome browsers, which can cause your computer to hang due to resource overuse.\n\n\n\nTo prevent your PC from hanging, you need to close all running Chrome instances. \n\nYou can run following command to close all chromes\n\n```shell\npython -m botasaurus.close\n```\n\nExecuting above command will close all Chrome instances, thereby helping to prevent your PC from hanging.\n \n---\n\n<!-- \n### What feautres are Coming in Botasaurus 4?\nBotasaurus 4, which is currently in its beta phase, allows you to:\n - A sms API to receive OTPs.\n - Run bots in the cloud using a website UI and control their schedules, starting/stopping times, and view bot outputs in a web UI. \n - Use Kubernetes to run thousands of bots in parallel.\n - Schedule Scraping Tasks at specific times or intervals\n - Whatsapp/Email Alerts\n - MySQL/PostgreSQL Integration\n - And Many More :) -->\n \n<!-- Developers are actively using Botasaurus 4 in production environments and saving hours of Development Time. To get access to Botasaurus 4, please [reach out to us](mailto:chetan@omkar.cloud?subject=Access%20Botasaurus%204&body=I%20want%20to%20use%20Botasaurus%204%20and%20gain%20access%20to%20feature%3A%20%5BTELL%20YOUR%20FEATURE%5D) and let us know which feature you would like to access. -->\n \n\n### Conclusion\n\nBotasaurus is a powerful, flexible tool for web scraping. \n\nIts various settings allow you to tailor the scraping process to your specific needs, improving both efficiency and convenience. Whether you're dealing with multiple data points, requiring parallel processing, or need to cache results, Botasaurus provides the features to streamline your scraping tasks.\n\n### \u2753 Need More Help or Have Additional Questions?\n\nFor further help, ask your question in GitHub Discussions. We'll be happy to help you out.\n\n[](https://github.com/omkarcloud/botasaurus/discussions)\n\n## Thanks\n\n- Kudos to the Apify Team for creating the `got-scraping` and `proxy-chain` libraries. The implementation of stealth Anti Detect Requests and SSL-based Proxy Authentication wouldn't have been possible without their groundbreaking work on `got-scraping` and `proxy-chain`.\n- Shout out to zfcsoftware for developing `puppeteer-real-browser`; it helped us in creating Botasaurus Anti Detected. Show your appreciation by subscribing to their [YouTube channel](https://www.youtube.com/@zfcsoftware/videos) \u26a1.\n- A special thanks to the Selenium team for creating Selenium, an invaluable tool in our toolkit.\n- Thanks to Cloudflare, DataDome, Imperva, and all bot detectors. Had you not been there, we wouldn't be either \ud83d\ude05.\n- Finally, a humongous thank you for choosing Botasaurus.\n\n## Love It? [Star It! \u2b50](https://github.com/omkarcloud/botasaurus)\n\nBecome one of our amazing stargazers by giving us a star \u2b50 on GitHub!\n\nIt's just one click, but it means the world to me.\n\n<a href=\"https://github.com/omkarcloud/botasaurus/stargazers\">\n <img src=\"https://bytecrank.com/nastyox/reporoster/php/stargazersSVG.php?user=omkarcloud&repo=botasaurus\" alt=\"Stargazers for @omkarcloud/botasaurus\">\n</a>\n\n## Sponsors\n\n<a href=\"https://www.capsolver.com/?utm_source=github&utm_medium=banner_github&utm_campaign=botsaurus\">\n <img src=\"https://raw.githubusercontent.com/omkarcloud/botasaurus/master/images/capsolver.png\" style=\"width: 70%;\" alt=\"capsolver\">\n</a>\n\n[Capsolver.com](https://www.capsolver.com/?utm_source=github&utm_medium=banner_github&utm_campaign=botsaurus) is an AI-powered service that provides automatic captcha solving capabilities. It supports a range of captcha types, including reCAPTCHA, hCaptcha, and FunCaptcha, AWS Captcha, Geetest, image captcha among others. Capsolver offers both Chrome and Firefox extensions for ease of use, API integration for developers, and various pricing packages to suit different needs.\n\n## Disclaimer for Botasaurus Project\n\n> By using Botasaurus, you agree to comply with all applicable local and international laws related to data scraping, copyright, and privacy. The developers of Botasaurus are not responsible for any misuse of this software. It is the sole responsibility of the user to ensure adherence to all relevant laws regarding data scraping, copyright, and privacy, and to use Botasaurus in an ethical and legal manner.\n\nWe take the concerns of the Botasaurus Project very seriously. For any inquiries or issues, please contact Chetan Jain at [chetan@omkar.cloud](mailto:chetan@omkar.cloud). We will take prompt and necessary action in response to your emails.\n\n## Made with \u2764\ufe0f in Bharat \ud83c\uddee\ud83c\uddf3 - Vande Mataram\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "Patching fork of botasaurus, The All in One Framework to build Awesome Scrapers.",
"version": "1.4.13",
"project_urls": null,
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "c4d79880fe50299c3b5ae6ef1ddfa855fd22b869ba5fd23895af11f8e961d549",
"md5": "0bb3f5fdee537b3c5cb9cf4c1e223aec",
"sha256": "fef1d1aea06bb8ab57333b442d30c5a119fde24333706ab28e262edf13073fd3"
},
"downloads": -1,
"filename": "botasaurus2-1.4.13-py3-none-any.whl",
"has_sig": false,
"md5_digest": "0bb3f5fdee537b3c5cb9cf4c1e223aec",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": "<4.0,>=3.10",
"size": 94311,
"upload_time": "2024-06-18T18:43:18",
"upload_time_iso_8601": "2024-06-18T18:43:18.633925Z",
"url": "https://files.pythonhosted.org/packages/c4/d7/9880fe50299c3b5ae6ef1ddfa855fd22b869ba5fd23895af11f8e961d549/botasaurus2-1.4.13-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "6505ba49f7942cd0462b4622b5fb905f55deb3365a0209be28aa50612ba91a23",
"md5": "2ca192f26660dd6f9cea517824b544d6",
"sha256": "ddc28ca102cc0d758d3c92e9dc13eca3c068ca10f1cf30ddd9dcb004769566d7"
},
"downloads": -1,
"filename": "botasaurus2-1.4.13.tar.gz",
"has_sig": false,
"md5_digest": "2ca192f26660dd6f9cea517824b544d6",
"packagetype": "sdist",
"python_version": "source",
"requires_python": "<4.0,>=3.10",
"size": 95844,
"upload_time": "2024-06-18T18:44:06",
"upload_time_iso_8601": "2024-06-18T18:44:06.267638Z",
"url": "https://files.pythonhosted.org/packages/65/05/ba49f7942cd0462b4622b5fb905f55deb3365a0209be28aa50612ba91a23/botasaurus2-1.4.13.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-06-18 18:44:06",
"github": false,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"lcname": "botasaurus2"
}
