[](https://badge.fury.io/py/bwsample)
[](https://img.shields.io/pypi/dm/bwsample)
[](https://doi.org/10.21105/joss.03324)
[](https://zenodo.org/badge/latestdoi/335090754)
[](https://gitter.im/satzbeleg/community?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
[](https://snyk.io/advisor/python/bwsample)
# bwsample: Sampling and Evaluation of Best-Worst Scaling sets
Sampling algorithm for best-worst scaling (BWS) sets, extracting pairs from evaluated BWS sets, count in dictionary of keys sparse matrix, and compute scores based on it.
The package `bwsample` addresses three areas:
* [Sampling](#sampling)
* [Counting](#counting)
* [Ranking](#ranking)
## Installation
The `bwsample` [git repo](http://github.com/satzbeleg/bwsample) is available as [PyPi package](https://pypi.org/project/bwsample)
```sh
pip install "bwsample>=0.7.0"
```
## Overview
The `bwsample` can be deployed at different stages to prepare BWS example sets and post-process evaluated BWS sets.
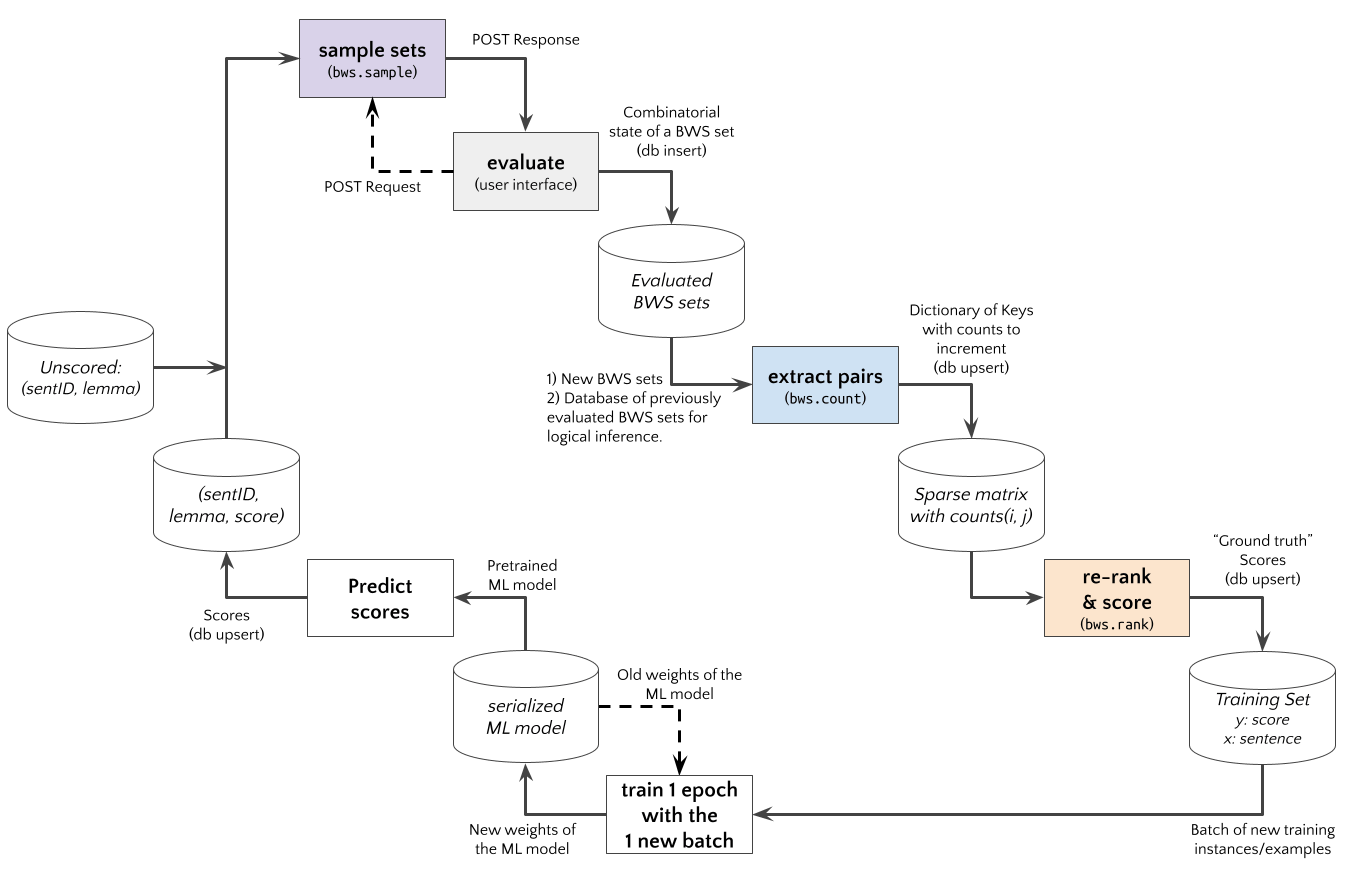
An *Active Learning* experiment using an Web App with BWS user interface to judge sentence examples is shown in the diagram below. The `bwsample` would be implemented in a (python based) REST API. The App requests new BWS example sets, and `bwsample.sample` generates these. After the App posts the evaluation results to the API, `bwsample.count` extract new pairwise data from evaluated BWS sets. The pairwise comparision matrix can be used by `bwsample.rank` to compute scores for a new updated training set.
## Sampling
**Input Data:**
The input data `examples` for `bwsample.sample` should be a `List[anything]`.
For example, `List[Dict[ID,DATA]]` with identifiers using the key `"id"` and the associated data using the key `"data"`, e.g.
```python
examples = [
{"id": "id1", "data": "data..."},
{"id": "id2", "data": ["other", "data"]},
{"id": "id3", "data": {"key", "value"}},
{"id": "id4", "data": "lorem"},
{"id": "id5", "data": "ipsum"},
{"id": "id6", "data": "blind"},
{"id": "id7", "data": "text"}
]
```
**Call the function:**
The number of items per BWS set `n_items` (`M`) must be specified, e.g. `n_items=4` if your App displays four items.
The `'overlap'` algorithm assigns every `i*(M-1)+1`-th example to two consecutive BWS sets, so that `1/(M-1)` of examples are evaluated two times.
The `'twice'` algorithm connects the remaining `(M-2)/(M-1)` non-overlapping from `'overlapping'` so that all examples occur twice.
The total number of sampled BWS sets might differ accordingly.
```python
import bwsample as bws
samples = bws.sample(examples, n_items=4, method='overlap')
```
**Output Data:**
The output has the following structure
```
[
[{'id': 'id1', 'data': 'data...'}, {'id': 'id2', 'data': ['other', 'data']}, {'id': 'id3', 'data': {'key', 'value'}}, {'id': 'id4', 'data': 'lorem'}],
[{'id': 'id1', 'data': 'data...'}, {'id': 'id4', 'data': 'lorem'}, {'id': 'id5', 'data': 'ipsum'}, {'id': 'id6', 'data': 'blind'}]
]
```
**Warning**: `len(examples)` must be a multiple of `(n_items - 1)`
**References:**
- Section 5 (page 4) in: Hamster, U. A. (2021, March 9). Extracting Pairwise Comparisons Data from Best-Worst Scaling Surveys by Logical Inference. [https://doi.org/10.31219/osf.io/qkxej](https://doi.org/10.31219/osf.io/qkxej)
## Counting
**Input Data:**
The input data`evaluations` for `bwsample.count` should structured as `List[Tuple[List[ItemState], List[ItemID]]]`.
The labelling/annotation application should produce a list of item states `List[ItemState]` with the states `BEST:1`, `WORST:2` and `NOT:0` for each item.
And the corresponding list of IDs `List[ItemID]` for each item or resp. example.
```python
evaluations = (
([0, 0, 2, 1], ['id1', 'id2', 'id3', 'id4']),
([0, 1, 0, 2], ['id4', 'id5', 'id6', 'id7']),
([1, 2, 0, 0], ['id7', 'id8', 'id9', 'id1'])
)
```
**Call the function:**
```python
import bwsample as bws
agg_dok, direct_dok, direct_detail, logical_dok, logical_detail = bws.count(evaluations)
```
**Output Data:**
The function `bwsample.count` outputs Dictionary of Keys (DOK) with the data structure `Dict[Tuple[ItemID, ItemID], int]`, e.g. `agg_dok`, `direct_dok`, `direct_detail["bw"]`, etc., what contain variants which pairs where counted:
- `agg_dok`
- `direct_dok`
- `direct_detail["bw"]` -- `BEST>WORST`
- `direct_detail["bn"]` -- `BEST>NOT`
- `direct_detail["nw"]` -- `NOT>WORST`
- `logical_dok`
- `logical_detail["nn"]` -- `D>E>F vs X>E>Z`
- `logical_detail["nb"]` -- `D>E>F vs E>Y>Z`
- `logical_detail["nw"]` -- `D>E>F vs X>Y>E`
- `logical_detail["bn"]` -- `D>E>F vs X>D>Z`
- `logical_detail["bw"]` -- `D>E>F vs X>Y>D`
- `logical_detail["wn"]` -- `D>E>F vs X>F>Z`
- `logical_detail["wb"]` -- `D>E>F vs F>Y>Z`
**Limit the Database Size:**
Logical Inference has quadratic complexity, and it might be beneficial to limit the database what can be done by the `logical_database` parameter.
```python
import bwsample as bws
agg_dok, direct_dok, direct_detail, logical_dok, logical_detail = bws.count(
evaluations, logical_database=evaluations[:1])
```
**Update Frequencies:**
The function `bwsample.count` is an update function, i.e. you can provide previous count or resp. frequency data (e.g. `logical_dok`) or start from scratch (e.g. `agg_dok=None`).
```python
import bwsample as bws
evaluations = [...]
direct_dok = {...}
direct_detail = {...}
logical_dok = {...}
logical_detail = {...}
database = [...]
agg_dok, direct_dok, direct_detail, logical_dok, logical_detail = bws.count(
evaluations, direct_dok=direct_dok, direct_detail=direct_detail,
logical_dok=logical_dok, logical_detail=logical_detail, logical_database=database)
```
**References:**
- Section 3-4 in: Hamster, U. A. (2021, March 9). Extracting Pairwise Comparisons Data from Best-Worst Scaling Surveys by Logical Inference. [https://doi.org/10.31219/osf.io/qkxej](https://doi.org/10.31219/osf.io/qkxej)
## Ranking
**Input Data:**
The input data is a Dictionary of Keys (DoK) object produced by `bwsample.count`.
**Call the function:**
The function `bwsample.rank` computes a python index variable with a proposed ordering (`ranked`), and ordered list of example IDs (`ordids`), scores (`scores`) and further information depending on the selected `method`.
```python
import bwsample as bws
ranked, ordids, metrics, scores, info = bws.rank(dok, method='ratio', adjust='quantile')
```
**Available methods:**
Computed from extracted pairs:
- `'ratio'` -- Simple ratios for each pair, and sum ratios for each item.
- `'approx'` -- Chi-Squared based p-value (Hoaglin Approximation) for each pair, and sum 1-pval for each item (Beh et al, 2018)
- `'btl'` -- Bradley-Terry-Luce (BTL) model estimated with MM algorithm (Hunter, 2004).
- `'eigen'` -- Eigenvectors of the reciprocal pairwise comparison matrix (Saaty, 2003).
- `'trans'` -- Estimate transition probability of the next item to be better.
The implementations `ratio`, `pvalue`, `'btl'`, `'eigen'`, and `'trans'` are fully based on sparse matrix operations and `scipy.sparse` algorithms, and avoid accidental conversions to dense matrices.
**References:**
- Hoaglin Approximation for p-values: Beh, E., 2018. Exploring How to Simply Approximate the P-value of a Chi-squared Statistic. AJS 47, 63–75. [https://doi.org/10.17713/ajs.v47i3.757](https://doi.org/10.17713/ajs.v47i3.757)
- Eigenvector solution in: Saaty, T. L. (2003). Decision-making with the AHP: Why is the principal eigenvector nec- essary. European Journal of Operational Research, 145(1), 85–91. [https://doi.org/10.1016/S0377-2217(02)00227-8](https://doi.org/10.1016/S0377-2217(02)00227-8)
- Estimating the BTL model in: Hunter, D. R. (2004). MM algorithms for generalized Bradley-Terry models. The Annals of Statistics, 32(1), 384–406. [https://doi.org/10.1214/aos/1079120141](https://doi.org/10.1214/aos/1079120141)
- MaxDiff score in: Orme, B. (2009). MaxDiff Analysis: Simple Counting, Individual-Level Logit, and HB. [https://sawtoothsoftware.com/uploads/sawtoothsoftware/originals/f89a6537-1cae-4fb5-afad-9d325c2a3143.pdf](https://sawtoothsoftware.com/uploads/sawtoothsoftware/originals/f89a6537-1cae-4fb5-afad-9d325c2a3143.pdf)
- Hamster, U. A. (2021, April 1). Pairwise comparison based ranking and scoring algorithms. [https://doi.org/10.31219/osf.io/ev7fw](https://doi.org/10.31219/osf.io/ev7fw)
## Appendix
### Install a virtual environment
In order to run the Jupyter notebooks or want to work on this project (e.g. unit tests, syntax checks) you should install a Python virtual environment.
```sh
python3.7 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt --no-cache-dir
pip install -r requirements-dev.txt --no-cache-dir
pip install -r requirements-demo.txt --no-cache-dir
```
(If your git repo is stored in a folder with whitespaces, then don't use the subfolder `.venv`. Use an absolute path without whitespaces.)
### Python commands
* Jupyter for the examples: `jupyter lab`
* Check syntax: `flake8 --ignore=F401 --exclude=$(grep -v '^#' .gitignore | xargs | sed -e 's/ /,/g')`
* Run Unit Tests: `pytest`
Publish
```sh
# pandoc README.md --from markdown --to rst -s -o README.rst
python setup.py sdist
twine check dist/*
twine upload -r pypi dist/*
```
### Clean up
```sh
find . -type f -name "*.pyc" | xargs rm
find . -type d -name "__pycache__" | xargs rm -r
rm -r .pytest_cache
rm -r .venv
```
### Support
Please [open an issue](https://github.com/satzbeleg/bwsample/issues/new) for support.
### Contributing
Please contribute using [Github Flow](https://guides.github.com/introduction/flow/). Create a branch, add commits, and [open a pull request](https://github.com/satzbeleg/bwsample/compare/).
### Acknowledgements
This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - [433249742](https://gepris.dfg.de/gepris/projekt/433249742). Project duration: 2020-2023.
### Citation
Please cite the peer-reviewed JOSS paper [](https://doi.org/10.21105/joss.03324) when using this software for any purpose.
Raw data
{
"_id": null,
"home_page": "http://github.com/ulf1/bwsample",
"name": "bwsample",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.7",
"maintainer_email": "",
"keywords": "",
"author": "Ulf Hamster",
"author_email": "554c46@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/37/c3/ac4ee564b4667332a2d47e8b43f70c16490306f46f6c9e93fae8d11d80f8/bwsample-0.7.0.tar.gz",
"platform": null,
"description": "[](https://badge.fury.io/py/bwsample)\n[](https://img.shields.io/pypi/dm/bwsample)\n[](https://doi.org/10.21105/joss.03324)\n[](https://zenodo.org/badge/latestdoi/335090754)\n[](https://gitter.im/satzbeleg/community?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)\n[](https://snyk.io/advisor/python/bwsample)\n\n\n\n# bwsample: Sampling and Evaluation of Best-Worst Scaling sets\nSampling algorithm for best-worst scaling (BWS) sets, extracting pairs from evaluated BWS sets, count in dictionary of keys sparse matrix, and compute scores based on it.\n\nThe package `bwsample` addresses three areas:\n\n* [Sampling](#sampling)\n* [Counting](#counting)\n* [Ranking](#ranking)\n\n## Installation\nThe `bwsample` [git repo](http://github.com/satzbeleg/bwsample) is available as [PyPi package](https://pypi.org/project/bwsample)\n\n```sh\npip install \"bwsample>=0.7.0\"\n```\n\n## Overview\nThe `bwsample` can be deployed at different stages to prepare BWS example sets and post-process evaluated BWS sets.\nAn *Active Learning* experiment using an Web App with BWS user interface to judge sentence examples is shown in the diagram below. The `bwsample` would be implemented in a (python based) REST API. The App requests new BWS example sets, and `bwsample.sample` generates these. After the App posts the evaluation results to the API, `bwsample.count` extract new pairwise data from evaluated BWS sets. The pairwise comparision matrix can be used by `bwsample.rank` to compute scores for a new updated training set.\n\n\n\n## Sampling\n**Input Data:**\nThe input data `examples` for `bwsample.sample` should be a `List[anything]`.\nFor example, `List[Dict[ID,DATA]]` with identifiers using the key `\"id\"` and the associated data using the key `\"data\"`, e.g.\n\n```python\nexamples = [\n {\"id\": \"id1\", \"data\": \"data...\"},\n {\"id\": \"id2\", \"data\": [\"other\", \"data\"]},\n {\"id\": \"id3\", \"data\": {\"key\", \"value\"}},\n {\"id\": \"id4\", \"data\": \"lorem\"},\n {\"id\": \"id5\", \"data\": \"ipsum\"},\n {\"id\": \"id6\", \"data\": \"blind\"},\n {\"id\": \"id7\", \"data\": \"text\"}\n]\n```\n\n**Call the function:**\nThe number of items per BWS set `n_items` (`M`) must be specified, e.g. `n_items=4` if your App displays four items.\nThe `'overlap'` algorithm assigns every `i*(M-1)+1`-th example to two consecutive BWS sets, so that `1/(M-1)` of examples are evaluated two times.\nThe `'twice'` algorithm connects the remaining `(M-2)/(M-1)` non-overlapping from `'overlapping'` so that all examples occur twice.\nThe total number of sampled BWS sets might differ accordingly.\n\n```python\nimport bwsample as bws\nsamples = bws.sample(examples, n_items=4, method='overlap')\n```\n\n**Output Data:**\nThe output has the following structure\n\n```\n[\n [{'id': 'id1', 'data': 'data...'}, {'id': 'id2', 'data': ['other', 'data']}, {'id': 'id3', 'data': {'key', 'value'}}, {'id': 'id4', 'data': 'lorem'}], \n [{'id': 'id1', 'data': 'data...'}, {'id': 'id4', 'data': 'lorem'}, {'id': 'id5', 'data': 'ipsum'}, {'id': 'id6', 'data': 'blind'}]\n]\n```\n\n**Warning**: `len(examples)` must be a multiple of `(n_items - 1)`\n\n**References:**\n\n- Section 5 (page 4) in: Hamster, U. A. (2021, March 9). Extracting Pairwise Comparisons Data from Best-Worst Scaling Surveys by Logical Inference. [https://doi.org/10.31219/osf.io/qkxej](https://doi.org/10.31219/osf.io/qkxej)\n\n\n## Counting\n**Input Data:**\nThe input data`evaluations` for `bwsample.count` should structured as `List[Tuple[List[ItemState], List[ItemID]]]`. \nThe labelling/annotation application should produce a list of item states `List[ItemState]` with the states `BEST:1`, `WORST:2` and `NOT:0` for each item. \nAnd the corresponding list of IDs `List[ItemID]` for each item or resp. example.\n\n```python\nevaluations = (\n ([0, 0, 2, 1], ['id1', 'id2', 'id3', 'id4']), \n ([0, 1, 0, 2], ['id4', 'id5', 'id6', 'id7']),\n ([1, 2, 0, 0], ['id7', 'id8', 'id9', 'id1'])\n)\n```\n\n**Call the function:**\n\n```python\nimport bwsample as bws\nagg_dok, direct_dok, direct_detail, logical_dok, logical_detail = bws.count(evaluations)\n```\n\n\n**Output Data:**\nThe function `bwsample.count` outputs Dictionary of Keys (DOK) with the data structure `Dict[Tuple[ItemID, ItemID], int]`, e.g. `agg_dok`, `direct_dok`, `direct_detail[\"bw\"]`, etc., what contain variants which pairs where counted:\n\n- `agg_dok`\n - `direct_dok`\n - `direct_detail[\"bw\"]` -- `BEST>WORST`\n - `direct_detail[\"bn\"]` -- `BEST>NOT`\n - `direct_detail[\"nw\"]` -- `NOT>WORST`\n - `logical_dok`\n - `logical_detail[\"nn\"]` -- `D>E>F vs X>E>Z`\n - `logical_detail[\"nb\"]` -- `D>E>F vs E>Y>Z`\n - `logical_detail[\"nw\"]` -- `D>E>F vs X>Y>E`\n - `logical_detail[\"bn\"]` -- `D>E>F vs X>D>Z`\n - `logical_detail[\"bw\"]` -- `D>E>F vs X>Y>D`\n - `logical_detail[\"wn\"]` -- `D>E>F vs X>F>Z`\n - `logical_detail[\"wb\"]` -- `D>E>F vs F>Y>Z`\n\n\n**Limit the Database Size:**\nLogical Inference has quadratic complexity, and it might be beneficial to limit the database what can be done by the `logical_database` parameter.\n\n```python\nimport bwsample as bws\nagg_dok, direct_dok, direct_detail, logical_dok, logical_detail = bws.count(\n evaluations, logical_database=evaluations[:1])\n```\n\n**Update Frequencies:**\nThe function `bwsample.count` is an update function, i.e. you can provide previous count or resp. frequency data (e.g. `logical_dok`) or start from scratch (e.g. `agg_dok=None`).\n\n```python\nimport bwsample as bws\n\nevaluations = [...]\ndirect_dok = {...}\ndirect_detail = {...}\nlogical_dok = {...}\nlogical_detail = {...}\ndatabase = [...]\n\nagg_dok, direct_dok, direct_detail, logical_dok, logical_detail = bws.count(\n evaluations, direct_dok=direct_dok, direct_detail=direct_detail,\n logical_dok=logical_dok, logical_detail=logical_detail, logical_database=database)\n```\n\n**References:**\n\n- Section 3-4 in: Hamster, U. A. (2021, March 9). Extracting Pairwise Comparisons Data from Best-Worst Scaling Surveys by Logical Inference. [https://doi.org/10.31219/osf.io/qkxej](https://doi.org/10.31219/osf.io/qkxej)\n\n\n## Ranking\n**Input Data:**\nThe input data is a Dictionary of Keys (DoK) object produced by `bwsample.count`. \n\n**Call the function:**\nThe function `bwsample.rank` computes a python index variable with a proposed ordering (`ranked`), and ordered list of example IDs (`ordids`), scores (`scores`) and further information depending on the selected `method`.\n\n```python\nimport bwsample as bws\nranked, ordids, metrics, scores, info = bws.rank(dok, method='ratio', adjust='quantile')\n```\n\n**Available methods:**\nComputed from extracted pairs:\n\n- `'ratio'` -- Simple ratios for each pair, and sum ratios for each item.\n- `'approx'` -- Chi-Squared based p-value (Hoaglin Approximation) for each pair, and sum 1-pval for each item (Beh et al, 2018)\n- `'btl'` -- Bradley-Terry-Luce (BTL) model estimated with MM algorithm (Hunter, 2004).\n- `'eigen'` -- Eigenvectors of the reciprocal pairwise comparison matrix (Saaty, 2003).\n- `'trans'` -- Estimate transition probability of the next item to be better.\n\nThe implementations `ratio`, `pvalue`, `'btl'`, `'eigen'`, and `'trans'` are fully based on sparse matrix operations and `scipy.sparse` algorithms, and avoid accidental conversions to dense matrices.\n\n\n**References:**\n- Hoaglin Approximation for p-values: Beh, E., 2018. Exploring How to Simply Approximate the P-value of a Chi-squared Statistic. AJS 47, 63\u201375. [https://doi.org/10.17713/ajs.v47i3.757](https://doi.org/10.17713/ajs.v47i3.757)\n- Eigenvector solution in: Saaty, T. L. (2003). Decision-making with the AHP: Why is the principal eigenvector nec- essary. European Journal of Operational Research, 145(1), 85\u201391. [https://doi.org/10.1016/S0377-2217(02)00227-8](https://doi.org/10.1016/S0377-2217(02)00227-8)\n- Estimating the BTL model in: Hunter, D. R. (2004). MM algorithms for generalized Bradley-Terry models. The Annals of Statistics, 32(1), 384\u2013406. [https://doi.org/10.1214/aos/1079120141](https://doi.org/10.1214/aos/1079120141)\n- MaxDiff score in: Orme, B. (2009). MaxDiff Analysis: Simple Counting, Individual-Level Logit, and HB. [https://sawtoothsoftware.com/uploads/sawtoothsoftware/originals/f89a6537-1cae-4fb5-afad-9d325c2a3143.pdf](https://sawtoothsoftware.com/uploads/sawtoothsoftware/originals/f89a6537-1cae-4fb5-afad-9d325c2a3143.pdf)\n- Hamster, U. A. (2021, April 1). Pairwise comparison based ranking and scoring algorithms. [https://doi.org/10.31219/osf.io/ev7fw](https://doi.org/10.31219/osf.io/ev7fw)\n\n\n## Appendix\n\n### Install a virtual environment\nIn order to run the Jupyter notebooks or want to work on this project (e.g. unit tests, syntax checks) you should install a Python virtual environment.\n\n```sh\npython3.7 -m venv .venv\nsource .venv/bin/activate\npip install --upgrade pip\npip install -r requirements.txt --no-cache-dir\npip install -r requirements-dev.txt --no-cache-dir\npip install -r requirements-demo.txt --no-cache-dir\n```\n\n(If your git repo is stored in a folder with whitespaces, then don't use the subfolder `.venv`. Use an absolute path without whitespaces.)\n\n### Python commands\n\n* Jupyter for the examples: `jupyter lab`\n* Check syntax: `flake8 --ignore=F401 --exclude=$(grep -v '^#' .gitignore | xargs | sed -e 's/ /,/g')`\n* Run Unit Tests: `pytest`\n\nPublish\n\n```sh\n# pandoc README.md --from markdown --to rst -s -o README.rst\npython setup.py sdist \ntwine check dist/*\ntwine upload -r pypi dist/*\n```\n\n### Clean up \n\n```sh\nfind . -type f -name \"*.pyc\" | xargs rm\nfind . -type d -name \"__pycache__\" | xargs rm -r\nrm -r .pytest_cache\nrm -r .venv\n```\n\n\n### Support\nPlease [open an issue](https://github.com/satzbeleg/bwsample/issues/new) for support.\n\n\n### Contributing\nPlease contribute using [Github Flow](https://guides.github.com/introduction/flow/). Create a branch, add commits, and [open a pull request](https://github.com/satzbeleg/bwsample/compare/).\n\n\n### Acknowledgements\nThis work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - [433249742](https://gepris.dfg.de/gepris/projekt/433249742). Project duration: 2020-2023.\n\n### Citation\nPlease cite the peer-reviewed JOSS paper [](https://doi.org/10.21105/joss.03324) when using this software for any purpose.\n",
"bugtrack_url": null,
"license": "Apache License 2.0",
"summary": "Sampling algorithm for best-worst scaling sets.",
"version": "0.7.0",
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "37c3ac4ee564b4667332a2d47e8b43f70c16490306f46f6c9e93fae8d11d80f8",
"md5": "a6d7f889f129359f7e08ae25c14f2988",
"sha256": "13825fc6957ae25317748ba2c186dba60891cea762433c189a4dcdbab8c568d5"
},
"downloads": -1,
"filename": "bwsample-0.7.0.tar.gz",
"has_sig": false,
"md5_digest": "a6d7f889f129359f7e08ae25c14f2988",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.7",
"size": 26659,
"upload_time": "2023-02-10T11:03:16",
"upload_time_iso_8601": "2023-02-10T11:03:16.595049Z",
"url": "https://files.pythonhosted.org/packages/37/c3/ac4ee564b4667332a2d47e8b43f70c16490306f46f6c9e93fae8d11d80f8/bwsample-0.7.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-02-10 11:03:16",
"github": true,
"gitlab": false,
"bitbucket": false,
"github_user": "ulf1",
"github_project": "bwsample",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"requirements": [],
"lcname": "bwsample"
}

