| Name | cleanlab JSON |
| Version |
2.7.0
 JSON
JSON |
| download |
| home_page | None |
| Summary | The standard package for data-centric AI, machine learning with label errors, and automatically finding and fixing dataset issues in Python. |
| upload_time | 2024-09-26 16:50:28 |
| maintainer | None |
| docs_url | None |
| author | None |
| requires_python | >=3.8 |
| license | GNU AFFERO GENERAL PUBLIC LICENSE Version 3, 19 November 2007 Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/> Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed. Preamble The GNU Affero General Public License is a free, copyleft license for software and other kinds of works, specifically designed to ensure cooperation with the community in the case of network server software. The licenses for most software and other practical works are designed to take away your freedom to share and change the works. By contrast, our General Public Licenses are intended to guarantee your freedom to share and change all versions of a program--to make sure it remains free software for all its users. When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for them if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs, and that you know you can do these things. Developers that use our General Public Licenses protect your rights with two steps: (1) assert copyright on the software, and (2) offer you this License which gives you legal permission to copy, distribute and/or modify the software. A secondary benefit of defending all users' freedom is that improvements made in alternate versions of the program, if they receive widespread use, become available for other developers to incorporate. Many developers of free software are heartened and encouraged by the resulting cooperation. However, in the case of software used on network servers, this result may fail to come about. The GNU General Public License permits making a modified version and letting the public access it on a server without ever releasing its source code to the public. The GNU Affero General Public License is designed specifically to ensure that, in such cases, the modified source code becomes available to the community. It requires the operator of a network server to provide the source code of the modified version running there to the users of that server. Therefore, public use of a modified version, on a publicly accessible server, gives the public access to the source code of the modified version. An older license, called the Affero General Public License and published by Affero, was designed to accomplish similar goals. This is a different license, not a version of the Affero GPL, but Affero has released a new version of the Affero GPL which permits relicensing under this license. The precise terms and conditions for copying, distribution and modification follow. TERMS AND CONDITIONS 0. Definitions. "This License" refers to version 3 of the GNU Affero General Public License. "Copyright" also means copyright-like laws that apply to other kinds of works, such as semiconductor masks. "The Program" refers to any copyrightable work licensed under this License. Each licensee is addressed as "you". "Licensees" and "recipients" may be individuals or organizations. To "modify" a work means to copy from or adapt all or part of the work in a fashion requiring copyright permission, other than the making of an exact copy. The resulting work is called a "modified version" of the earlier work or a work "based on" the earlier work. A "covered work" means either the unmodified Program or a work based on the Program. To "propagate" a work means to do anything with it that, without permission, would make you directly or secondarily liable for infringement under applicable copyright law, except executing it on a computer or modifying a private copy. Propagation includes copying, distribution (with or without modification), making available to the public, and in some countries other activities as well. To "convey" a work means any kind of propagation that enables other parties to make or receive copies. Mere interaction with a user through a computer network, with no transfer of a copy, is not conveying. An interactive user interface displays "Appropriate Legal Notices" to the extent that it includes a convenient and prominently visible feature that (1) displays an appropriate copyright notice, and (2) tells the user that there is no warranty for the work (except to the extent that warranties are provided), that licensees may convey the work under this License, and how to view a copy of this License. If the interface presents a list of user commands or options, such as a menu, a prominent item in the list meets this criterion. 1. Source Code. The "source code" for a work means the preferred form of the work for making modifications to it. "Object code" means any non-source form of a work. A "Standard Interface" means an interface that either is an official standard defined by a recognized standards body, or, in the case of interfaces specified for a particular programming language, one that is widely used among developers working in that language. The "System Libraries" of an executable work include anything, other than the work as a whole, that (a) is included in the normal form of packaging a Major Component, but which is not part of that Major Component, and (b) serves only to enable use of the work with that Major Component, or to implement a Standard Interface for which an implementation is available to the public in source code form. A "Major Component", in this context, means a major essential component (kernel, window system, and so on) of the specific operating system (if any) on which the executable work runs, or a compiler used to produce the work, or an object code interpreter used to run it. The "Corresponding Source" for a work in object code form means all the source code needed to generate, install, and (for an executable work) run the object code and to modify the work, including scripts to control those activities. However, it does not include the work's System Libraries, or general-purpose tools or generally available free programs which are used unmodified in performing those activities but which are not part of the work. For example, Corresponding Source includes interface definition files associated with source files for the work, and the source code for shared libraries and dynamically linked subprograms that the work is specifically designed to require, such as by intimate data communication or control flow between those subprograms and other parts of the work. The Corresponding Source need not include anything that users can regenerate automatically from other parts of the Corresponding Source. The Corresponding Source for a work in source code form is that same work. 2. Basic Permissions. All rights granted under this License are granted for the term of copyright on the Program, and are irrevocable provided the stated conditions are met. This License explicitly affirms your unlimited permission to run the unmodified Program. The output from running a covered work is covered by this License only if the output, given its content, constitutes a covered work. This License acknowledges your rights of fair use or other equivalent, as provided by copyright law. You may make, run and propagate covered works that you do not convey, without conditions so long as your license otherwise remains in force. You may convey covered works to others for the sole purpose of having them make modifications exclusively for you, or provide you with facilities for running those works, provided that you comply with the terms of this License in conveying all material for which you do not control copyright. Those thus making or running the covered works for you must do so exclusively on your behalf, under your direction and control, on terms that prohibit them from making any copies of your copyrighted material outside their relationship with you. Conveying under any other circumstances is permitted solely under the conditions stated below. Sublicensing is not allowed; section 10 makes it unnecessary. 3. Protecting Users' Legal Rights From Anti-Circumvention Law. No covered work shall be deemed part of an effective technological measure under any applicable law fulfilling obligations under article 11 of the WIPO copyright treaty adopted on 20 December 1996, or similar laws prohibiting or restricting circumvention of such measures. When you convey a covered work, you waive any legal power to forbid circumvention of technological measures to the extent such circumvention is effected by exercising rights under this License with respect to the covered work, and you disclaim any intention to limit operation or modification of the work as a means of enforcing, against the work's users, your or third parties' legal rights to forbid circumvention of technological measures. 4. Conveying Verbatim Copies. You may convey verbatim copies of the Program's source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice; keep intact all notices stating that this License and any non-permissive terms added in accord with section 7 apply to the code; keep intact all notices of the absence of any warranty; and give all recipients a copy of this License along with the Program. You may charge any price or no price for each copy that you convey, and you may offer support or warranty protection for a fee. 5. Conveying Modified Source Versions. You may convey a work based on the Program, or the modifications to produce it from the Program, in the form of source code under the terms of section 4, provided that you also meet all of these conditions: a) The work must carry prominent notices stating that you modified it, and giving a relevant date. b) The work must carry prominent notices stating that it is released under this License and any conditions added under section 7. This requirement modifies the requirement in section 4 to "keep intact all notices". c) You must license the entire work, as a whole, under this License to anyone who comes into possession of a copy. This License will therefore apply, along with any applicable section 7 additional terms, to the whole of the work, and all its parts, regardless of how they are packaged. This License gives no permission to license the work in any other way, but it does not invalidate such permission if you have separately received it. d) If the work has interactive user interfaces, each must display Appropriate Legal Notices; however, if the Program has interactive interfaces that do not display Appropriate Legal Notices, your work need not make them do so. A compilation of a covered work with other separate and independent works, which are not by their nature extensions of the covered work, and which are not combined with it such as to form a larger program, in or on a volume of a storage or distribution medium, is called an "aggregate" if the compilation and its resulting copyright are not used to limit the access or legal rights of the compilation's users beyond what the individual works permit. Inclusion of a covered work in an aggregate does not cause this License to apply to the other parts of the aggregate. 6. Conveying Non-Source Forms. You may convey a covered work in object code form under the terms of sections 4 and 5, provided that you also convey the machine-readable Corresponding Source under the terms of this License, in one of these ways: a) Convey the object code in, or embodied in, a physical product (including a physical distribution medium), accompanied by the Corresponding Source fixed on a durable physical medium customarily used for software interchange. b) Convey the object code in, or embodied in, a physical product (including a physical distribution medium), accompanied by a written offer, valid for at least three years and valid for as long as you offer spare parts or customer support for that product model, to give anyone who possesses the object code either (1) a copy of the Corresponding Source for all the software in the product that is covered by this License, on a durable physical medium customarily used for software interchange, for a price no more than your reasonable cost of physically performing this conveying of source, or (2) access to copy the Corresponding Source from a network server at no charge. c) Convey individual copies of the object code with a copy of the written offer to provide the Corresponding Source. This alternative is allowed only occasionally and noncommercially, and only if you received the object code with such an offer, in accord with subsection 6b. d) Convey the object code by offering access from a designated place (gratis or for a charge), and offer equivalent access to the Corresponding Source in the same way through the same place at no further charge. You need not require recipients to copy the Corresponding Source along with the object code. If the place to copy the object code is a network server, the Corresponding Source may be on a different server (operated by you or a third party) that supports equivalent copying facilities, provided you maintain clear directions next to the object code saying where to find the Corresponding Source. Regardless of what server hosts the Corresponding Source, you remain obligated to ensure that it is available for as long as needed to satisfy these requirements. e) Convey the object code using peer-to-peer transmission, provided you inform other peers where the object code and Corresponding Source of the work are being offered to the general public at no charge under subsection 6d. A separable portion of the object code, whose source code is excluded from the Corresponding Source as a System Library, need not be included in conveying the object code work. A "User Product" is either (1) a "consumer product", which means any tangible personal property which is normally used for personal, family, or household purposes, or (2) anything designed or sold for incorporation into a dwelling. In determining whether a product is a consumer product, doubtful cases shall be resolved in favor of coverage. For a particular product received by a particular user, "normally used" refers to a typical or common use of that class of product, regardless of the status of the particular user or of the way in which the particular user actually uses, or expects or is expected to use, the product. A product is a consumer product regardless of whether the product has substantial commercial, industrial or non-consumer uses, unless such uses represent the only significant mode of use of the product. "Installation Information" for a User Product means any methods, procedures, authorization keys, or other information required to install and execute modified versions of a covered work in that User Product from a modified version of its Corresponding Source. The information must suffice to ensure that the continued functioning of the modified object code is in no case prevented or interfered with solely because modification has been made. If you convey an object code work under this section in, or with, or specifically for use in, a User Product, and the conveying occurs as part of a transaction in which the right of possession and use of the User Product is transferred to the recipient in perpetuity or for a fixed term (regardless of how the transaction is characterized), the Corresponding Source conveyed under this section must be accompanied by the Installation Information. But this requirement does not apply if neither you nor any third party retains the ability to install modified object code on the User Product (for example, the work has been installed in ROM). The requirement to provide Installation Information does not include a requirement to continue to provide support service, warranty, or updates for a work that has been modified or installed by the recipient, or for the User Product in which it has been modified or installed. Access to a network may be denied when the modification itself materially and adversely affects the operation of the network or violates the rules and protocols for communication across the network. Corresponding Source conveyed, and Installation Information provided, in accord with this section must be in a format that is publicly documented (and with an implementation available to the public in source code form), and must require no special password or key for unpacking, reading or copying. 7. Additional Terms. "Additional permissions" are terms that supplement the terms of this License by making exceptions from one or more of its conditions. Additional permissions that are applicable to the entire Program shall be treated as though they were included in this License, to the extent that they are valid under applicable law. If additional permissions apply only to part of the Program, that part may be used separately under those permissions, but the entire Program remains governed by this License without regard to the additional permissions. When you convey a copy of a covered work, you may at your option remove any additional permissions from that copy, or from any part of it. (Additional permissions may be written to require their own removal in certain cases when you modify the work.) You may place additional permissions on material, added by you to a covered work, for which you have or can give appropriate copyright permission. Notwithstanding any other provision of this License, for material you add to a covered work, you may (if authorized by the copyright holders of that material) supplement the terms of this License with terms: a) Disclaiming warranty or limiting liability differently from the terms of sections 15 and 16 of this License; or b) Requiring preservation of specified reasonable legal notices or author attributions in that material or in the Appropriate Legal Notices displayed by works containing it; or c) Prohibiting misrepresentation of the origin of that material, or requiring that modified versions of such material be marked in reasonable ways as different from the original version; or d) Limiting the use for publicity purposes of names of licensors or authors of the material; or e) Declining to grant rights under trademark law for use of some trade names, trademarks, or service marks; or f) Requiring indemnification of licensors and authors of that material by anyone who conveys the material (or modified versions of it) with contractual assumptions of liability to the recipient, for any liability that these contractual assumptions directly impose on those licensors and authors. All other non-permissive additional terms are considered "further restrictions" within the meaning of section 10. If the Program as you received it, or any part of it, contains a notice stating that it is governed by this License along with a term that is a further restriction, you may remove that term. If a license document contains a further restriction but permits relicensing or conveying under this License, you may add to a covered work material governed by the terms of that license document, provided that the further restriction does not survive such relicensing or conveying. If you add terms to a covered work in accord with this section, you must place, in the relevant source files, a statement of the additional terms that apply to those files, or a notice indicating where to find the applicable terms. Additional terms, permissive or non-permissive, may be stated in the form of a separately written license, or stated as exceptions; the above requirements apply either way. 8. Termination. You may not propagate or modify a covered work except as expressly provided under this License. Any attempt otherwise to propagate or modify it is void, and will automatically terminate your rights under this License (including any patent licenses granted under the third paragraph of section 11). However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation. Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice. Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, you do not qualify to receive new licenses for the same material under section 10. 9. Acceptance Not Required for Having Copies. You are not required to accept this License in order to receive or run a copy of the Program. Ancillary propagation of a covered work occurring solely as a consequence of using peer-to-peer transmission to receive a copy likewise does not require acceptance. However, nothing other than this License grants you permission to propagate or modify any covered work. These actions infringe copyright if you do not accept this License. Therefore, by modifying or propagating a covered work, you indicate your acceptance of this License to do so. 10. Automatic Licensing of Downstream Recipients. Each time you convey a covered work, the recipient automatically receives a license from the original licensors, to run, modify and propagate that work, subject to this License. You are not responsible for enforcing compliance by third parties with this License. An "entity transaction" is a transaction transferring control of an organization, or substantially all assets of one, or subdividing an organization, or merging organizations. If propagation of a covered work results from an entity transaction, each party to that transaction who receives a copy of the work also receives whatever licenses to the work the party's predecessor in interest had or could give under the previous paragraph, plus a right to possession of the Corresponding Source of the work from the predecessor in interest, if the predecessor has it or can get it with reasonable efforts. You may not impose any further restrictions on the exercise of the rights granted or affirmed under this License. For example, you may not impose a license fee, royalty, or other charge for exercise of rights granted under this License, and you may not initiate litigation (including a cross-claim or counterclaim in a lawsuit) alleging that any patent claim is infringed by making, using, selling, offering for sale, or importing the Program or any portion of it. 11. Patents. A "contributor" is a copyright holder who authorizes use under this License of the Program or a work on which the Program is based. The work thus licensed is called the contributor's "contributor version". A contributor's "essential patent claims" are all patent claims owned or controlled by the contributor, whether already acquired or hereafter acquired, that would be infringed by some manner, permitted by this License, of making, using, or selling its contributor version, but do not include claims that would be infringed only as a consequence of further modification of the contributor version. For purposes of this definition, "control" includes the right to grant patent sublicenses in a manner consistent with the requirements of this License. Each contributor grants you a non-exclusive, worldwide, royalty-free patent license under the contributor's essential patent claims, to make, use, sell, offer for sale, import and otherwise run, modify and propagate the contents of its contributor version. In the following three paragraphs, a "patent license" is any express agreement or commitment, however denominated, not to enforce a patent (such as an express permission to practice a patent or covenant not to sue for patent infringement). To "grant" such a patent license to a party means to make such an agreement or commitment not to enforce a patent against the party. If you convey a covered work, knowingly relying on a patent license, and the Corresponding Source of the work is not available for anyone to copy, free of charge and under the terms of this License, through a publicly available network server or other readily accessible means, then you must either (1) cause the Corresponding Source to be so available, or (2) arrange to deprive yourself of the benefit of the patent license for this particular work, or (3) arrange, in a manner consistent with the requirements of this License, to extend the patent license to downstream recipients. "Knowingly relying" means you have actual knowledge that, but for the patent license, your conveying the covered work in a country, or your recipient's use of the covered work in a country, would infringe one or more identifiable patents in that country that you have reason to believe are valid. If, pursuant to or in connection with a single transaction or arrangement, you convey, or propagate by procuring conveyance of, a covered work, and grant a patent license to some of the parties receiving the covered work authorizing them to use, propagate, modify or convey a specific copy of the covered work, then the patent license you grant is automatically extended to all recipients of the covered work and works based on it. A patent license is "discriminatory" if it does not include within the scope of its coverage, prohibits the exercise of, or is conditioned on the non-exercise of one or more of the rights that are specifically granted under this License. You may not convey a covered work if you are a party to an arrangement with a third party that is in the business of distributing software, under which you make payment to the third party based on the extent of your activity of conveying the work, and under which the third party grants, to any of the parties who would receive the covered work from you, a discriminatory patent license (a) in connection with copies of the covered work conveyed by you (or copies made from those copies), or (b) primarily for and in connection with specific products or compilations that contain the covered work, unless you entered into that arrangement, or that patent license was granted, prior to 28 March 2007. Nothing in this License shall be construed as excluding or limiting any implied license or other defenses to infringement that may otherwise be available to you under applicable patent law. 12. No Surrender of Others' Freedom. If conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot convey a covered work so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not convey it at all. For example, if you agree to terms that obligate you to collect a royalty for further conveying from those to whom you convey the Program, the only way you could satisfy both those terms and this License would be to refrain entirely from conveying the Program. 13. Remote Network Interaction; Use with the GNU General Public License. Notwithstanding any other provision of this License, if you modify the Program, your modified version must prominently offer all users interacting with it remotely through a computer network (if your version supports such interaction) an opportunity to receive the Corresponding Source of your version by providing access to the Corresponding Source from a network server at no charge, through some standard or customary means of facilitating copying of software. This Corresponding Source shall include the Corresponding Source for any work covered by version 3 of the GNU General Public License that is incorporated pursuant to the following paragraph. Notwithstanding any other provision of this License, you have permission to link or combine any covered work with a work licensed under version 3 of the GNU General Public License into a single combined work, and to convey the resulting work. The terms of this License will continue to apply to the part which is the covered work, but the work with which it is combined will remain governed by version 3 of the GNU General Public License. 14. Revised Versions of this License. The Free Software Foundation may publish revised and/or new versions of the GNU Affero General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. Each version is given a distinguishing version number. If the Program specifies that a certain numbered version of the GNU Affero General Public License "or any later version" applies to it, you have the option of following the terms and conditions either of that numbered version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of the GNU Affero General Public License, you may choose any version ever published by the Free Software Foundation. If the Program specifies that a proxy can decide which future versions of the GNU Affero General Public License can be used, that proxy's public statement of acceptance of a version permanently authorizes you to choose that version for the Program. Later license versions may give you additional or different permissions. However, no additional obligations are imposed on any author or copyright holder as a result of your choosing to follow a later version. 15. Disclaimer of Warranty. THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION. 16. Limitation of Liability. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. 17. Interpretation of Sections 15 and 16. If the disclaimer of warranty and limitation of liability provided above cannot be given local legal effect according to their terms, reviewing courts shall apply local law that most closely approximates an absolute waiver of all civil liability in connection with the Program, unless a warranty or assumption of liability accompanies a copy of the Program in return for a fee. END OF TERMS AND CONDITIONS How to Apply These Terms to Your New Programs If you develop a new program, and you want it to be of the greatest possible use to the public, the best way to achieve this is to make it free software which everyone can redistribute and change under these terms. To do so, attach the following notices to the program. It is safest to attach them to the start of each source file to most effectively state the exclusion of warranty; and each file should have at least the "copyright" line and a pointer to where the full notice is found. <one line to give the program's name and a brief idea of what it does.> Copyright (C) <year> <name of author> This program is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more details. You should have received a copy of the GNU Affero General Public License along with this program. If not, see <https://www.gnu.org/licenses/>. Also add information on how to contact you by electronic and paper mail. If your software can interact with users remotely through a computer network, you should also make sure that it provides a way for users to get its source. For example, if your program is a web application, its interface could display a "Source" link that leads users to an archive of the code. There are many ways you could offer source, and different solutions will be better for different programs; see section 13 for the specific requirements. You should also get your employer (if you work as a programmer) or school, if any, to sign a "copyright disclaimer" for the program, if necessary. For more information on this, and how to apply and follow the GNU AGPL, see <https://www.gnu.org/licenses/>. |
| keywords |
machine_learning
data_cleaning
confident_learning
classification
weak_supervision
learning_with_noisy_labels
unsupervised_learning
datacentric_ai
datacentric
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |

|
<p align="center">
<img src="https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/cleanlab_logo_open_source.png" width=60% height=60%>
</p>
<div align="center">
<a href="https://pypi.org/pypi/cleanlab/" target="_blank"><img src="https://img.shields.io/pypi/v/cleanlab.svg" alt="pypi_versions"></a>
<a href="https://pypi.org/pypi/cleanlab/" target="_blank"><img src="https://img.shields.io/badge/python-3.8%2B-blue" alt="py_versions"></a>
<a href="https://app.codecov.io/gh/cleanlab/cleanlab" target="_blank"><img src="https://codecov.io/gh/cleanlab/cleanlab/branch/master/graph/badge.svg" alt="coverage"></a>
<a href="https://github.com/cleanlab/cleanlab/stargazers/" target="_blank"><img src="https://img.shields.io/github/stars/cleanlab/cleanlab?style=social&maxAge=2592000" alt="Github Stars"></a>
<a href="https://cleanlab.ai/slack" target="_blank"><img src="https://img.shields.io/static/v1?logo=slack&style=flat&color=white&label=slack&message=join" alt="Slack Community"></a>
<a href="https://twitter.com/CleanlabAI" target="_blank"><img src="https://img.shields.io/twitter/follow/CleanlabAI?style=social" alt="Twitter"></a>
</div>
<h4 align="center">
<p>
<a href="https://docs.cleanlab.ai/">Documentation</a> |
<a href="https://github.com/cleanlab/examples">Examples</a> |
<a href="https://cleanlab.ai/blog/">Blog</a> |
<a href="#citation-and-related-publications">Research</a> |
<a href="#try-easy-mode-with-cleanlab-studio">Cleanlab Studio</a> |
<a href="#join-our-community">Community</a>
<p>
</h4>
cleanlab helps you **clean** data and **lab**els by automatically detecting issues in a ML dataset. To facilitate **machine learning with messy, real-world data**, this data-centric AI package uses your *existing* models to estimate dataset problems that can be fixed to train even *better* models.
<p align="center">
<img src="https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/datalab_issues.png" width=74% height=74%>
</p>
<p align="center">
Examples of various issues in Cat/Dog dataset <b>automatically detected</b> by cleanlab via this code:
</p>
```python
lab = cleanlab.Datalab(data=dataset, label="column_name_for_labels")
# Fit any ML model, get its feature_embeddings & pred_probs for your data
lab.find_issues(features=feature_embeddings, pred_probs=pred_probs)
lab.report()
```
- Use cleanlab to automatically check every: [image](https://docs.cleanlab.ai/stable/tutorials/datalab/image.html), [text](https://docs.cleanlab.ai/stable/tutorials/datalab/text.html), [audio](https://docs.cleanlab.ai/stable/tutorials/datalab/audio.html), or [tabular](https://docs.cleanlab.ai/stable/tutorials/datalab/tabular.html) dataset.
- Use cleanlab to automatically: [detect data issues (outliers, duplicates, label errors, etc)](https://docs.cleanlab.ai/stable/tutorials/datalab/datalab_quickstart.html), [train robust models](https://docs.cleanlab.ai/stable/tutorials/indepth_overview.html), [infer consensus + annotator-quality for multi-annotator data](https://docs.cleanlab.ai/stable/tutorials/multiannotator.html), [suggest data to (re)label next (active learning)](https://github.com/cleanlab/examples/blob/master/active_learning_multiannotator/active_learning.ipynb).
---
### Try easy mode with Cleanlab Studio
While this open-source package **finds** data issues, its utility depends on you having: a good existing ML model + an interface to efficiently **fix** these issues in your dataset. Providing all these pieces, [Cleanlab Studio](https://cleanlab.ai/blog/data-centric-ai/) is a Data Curation platform to **find and fix** problems in any {image, text, tabular} dataset. Cleanlab Studio [automatically](https://cleanlab.ai/blog/data-centric-ai/) runs optimized algorithms from this package on top of **AutoML & Foundation** models fit to your data, and presents detected issues (+ AI-suggested fixes) in an intelligent [data correction interface](https://www.youtube.com/playlist?list=PLn_2rr2ltYqA1uAC0AnRbPyY-wWVf1aeg).
**[Try it for free!](https://cleanlab.ai/signup/)** Adopting Cleanlab Studio enables users of this package to:
- Work 100x faster (1 min to analyze your raw data with **zero** code or ML work; optionally use [Python API](https://help.cleanlab.ai/tutorials/))
- Produce better-quality data (10x more [types of issues](https://help.cleanlab.ai/guide/concepts/cleanlab_columns/) auto detected & **corrected** via built-in AI)
- Accomplish more (auto-label data, deploy ML instantly, audit LLM inputs/outputs, moderate content, ...)
- Monitor incoming data and detect issues in real-time (integrate your data pipeline on an [Enterprise plan](https://cleanlab.ai/sales/))
<p align="center">
<img src="https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/ml-with-cleanlab-studio.png" alt="The modern AI pipeline automated with Cleanlab Studio">
</p>
## Run cleanlab open-source
This cleanlab package runs on Python 3.8+ and supports Linux, macOS, as well as Windows.
- Get started [here](https://docs.cleanlab.ai/)! Install via `pip` or `conda`.
- Developers who install the bleeding-edge from source should refer to [this master branch documentation](https://docs.cleanlab.ai/master/index.html).
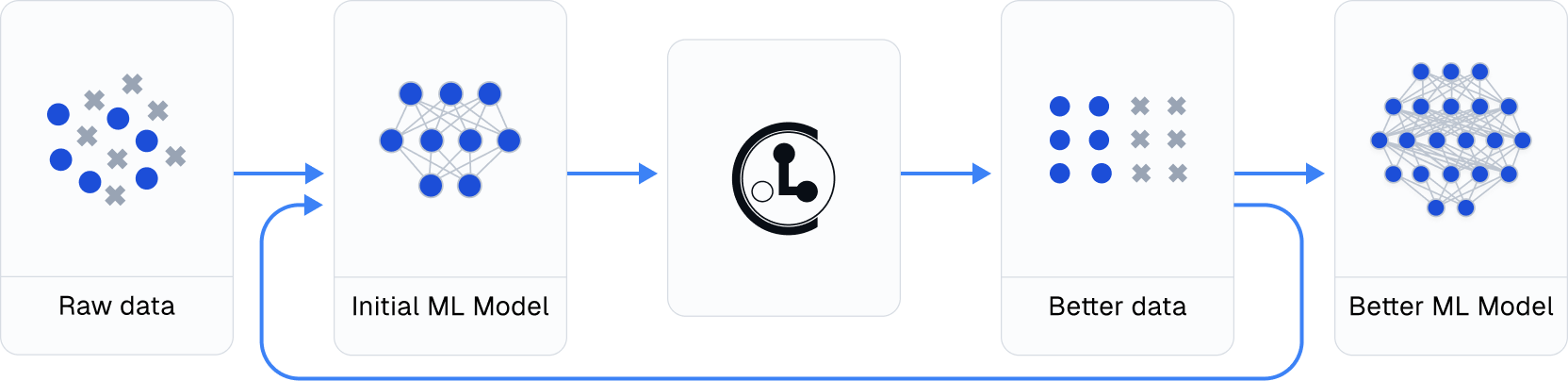
**Practicing data-centric AI can look like this:**
1. Train initial ML model on original dataset.
2. Utilize this model to diagnose data issues (via cleanlab methods) and improve the dataset.
3. Train the same model on the improved dataset.
4. Try various modeling techniques to further improve performance.
Most folks jump from Step 1 → 4, but you may achieve big gains without *any* change to your modeling code by using cleanlab!
Continuously boost performance by iterating Steps 2 → 4 (and try to evaluate with *cleaned* data).
## Use cleanlab with any model and in most ML tasks
All features of cleanlab work with **any dataset** and **any model**. Yes, any model: PyTorch, Tensorflow, Keras, JAX, HuggingFace, OpenAI, XGBoost, scikit-learn, etc.
cleanlab is useful across a wide variety of Machine Learning tasks. Specific tasks this data-centric AI package offers dedicated functionality for include:
1. [Binary and multi-class classification](https://docs.cleanlab.ai/stable/tutorials/indepth_overview.html)
2. [Multi-label classification](https://docs.cleanlab.ai/stable/tutorials/multilabel_classification.html) (e.g. image/document tagging)
3. [Token classification](https://docs.cleanlab.ai/stable/tutorials/token_classification.html) (e.g. entity recognition in text)
4. [Regression](https://docs.cleanlab.ai/stable/tutorials/regression.html) (predicting numerical column in a dataset)
5. [Image segmentation](https://docs.cleanlab.ai/stable/tutorials/segmentation.html) (images with per-pixel annotations)
6. [Object detection](https://docs.cleanlab.ai/stable/tutorials/object_detection.html) (images with bounding box annotations)
7. [Classification with data labeled by multiple annotators](https://docs.cleanlab.ai/stable/tutorials/multiannotator.html)
8. [Active learning with multiple annotators](https://github.com/cleanlab/examples/blob/master/active_learning_multiannotator/active_learning.ipynb) (suggest which data to label or re-label to improve model most)
9. [Outlier detection](https://docs.cleanlab.ai/stable/tutorials/outliers.html) (identify atypical data that appears out of distribution)
For other ML tasks, cleanlab can still help you improve your dataset if appropriately applied.
See our [Example Notebooks](https://github.com/cleanlab/examples) and [Blog](https://cleanlab.ai/blog/).
## So fresh, so cleanlab
Beyond automatically catching [all sorts of issues](https://docs.cleanlab.ai/stable/cleanlab/datalab/guide/issue_type_description.html) lurking in your data, this data-centric AI package helps you deal with **noisy labels** and train more **robust ML models**.
Here's an example:
```python
# cleanlab works with **any classifier**. Yup, you can use PyTorch/TensorFlow/OpenAI/XGBoost/etc.
cl = cleanlab.classification.CleanLearning(sklearn.YourFavoriteClassifier())
# cleanlab finds data and label issues in **any dataset**... in ONE line of code!
label_issues = cl.find_label_issues(data, labels)
# cleanlab trains a robust version of your model that works more reliably with noisy data.
cl.fit(data, labels)
# cleanlab estimates the predictions you would have gotten if you had trained with *no* label issues.
cl.predict(test_data)
# A universal data-centric AI tool, cleanlab quantifies class-level issues and overall data quality, for any dataset.
cleanlab.dataset.health_summary(labels, confident_joint=cl.confident_joint)
```
cleanlab **clean**s your data's **lab**els via state-of-the-art *confident learning* algorithms, published in this [paper](https://jair.org/index.php/jair/article/view/12125) and [blog](https://l7.curtisnorthcutt.com/confident-learning). See some of the datasets cleaned with cleanlab at [labelerrors.com](https://labelerrors.com).
cleanlab is:
1. **backed by theory** -- with [provable guarantees](https://arxiv.org/abs/1911.00068) of exact label noise estimation, even with imperfect models.
2. **fast** -- code is parallelized and scalable.
4. **easy to use** -- one line of code to find mislabeled data, bad annotators, outliers, or train noise-robust models.
6. **general** -- works with **[any dataset](https://labelerrors.com/)** (text, image, tabular, audio,...) + **any model** (PyTorch, OpenAI, XGBoost,...)
<br/>

<p align="center">
Examples of incorrect given labels in various image datasets <a href="https://l7.curtisnorthcutt.com/label-errors">found and corrected</a> using cleanlab.
While these examples are from image datasets, this also works for text, audio, tabular data.
</p>
## Citation and related publications
cleanlab is based on peer-reviewed research. Here are relevant papers to cite if you use this package:
<details><summary><a href="https://arxiv.org/abs/1911.00068">Confident Learning (JAIR '21)</a> (<b>click to show bibtex</b>) </summary>
@article{northcutt2021confidentlearning,
title={Confident Learning: Estimating Uncertainty in Dataset Labels},
author={Curtis G. Northcutt and Lu Jiang and Isaac L. Chuang},
journal={Journal of Artificial Intelligence Research (JAIR)},
volume={70},
pages={1373--1411},
year={2021}
}
</details>
<details><summary><a href="https://arxiv.org/abs/1705.01936">Rank Pruning (UAI '17)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{northcutt2017rankpruning,
author={Northcutt, Curtis G. and Wu, Tailin and Chuang, Isaac L.},
title={Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels},
booktitle = {Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence},
series = {UAI'17},
year = {2017},
location = {Sydney, Australia},
numpages = {10},
url = {http://auai.org/uai2017/proceedings/papers/35.pdf},
publisher = {AUAI Press},
}
</details>
<details><summary><a href="https://people.csail.mit.edu/jonasmueller/info/LabelQuality_icml.pdf"> Label Quality Scoring (ICML '22)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{kuan2022labelquality,
title={Model-agnostic label quality scoring to detect real-world label errors},
author={Kuan, Johnson and Mueller, Jonas},
booktitle={ICML DataPerf Workshop},
year={2022}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2207.03061"> Out-of-Distribution Detection (ICML '22)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{kuan2022ood,
title={Back to the Basics: Revisiting Out-of-Distribution Detection Baselines},
author={Kuan, Johnson and Mueller, Jonas},
booktitle={ICML Workshop on Principles of Distribution Shift},
year={2022}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2210.03920"> Token Classification Label Errors (NeurIPS '22)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{wang2022tokenerrors,
title={Detecting label errors in token classification data},
author={Wang, Wei-Chen and Mueller, Jonas},
booktitle={NeurIPS Workshop on Interactive Learning for Natural Language Processing (InterNLP)},
year={2022}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2210.06812"> CROWDLAB for Data with Multiple Annotators (NeurIPS '22)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{goh2022crowdlab,
title={CROWDLAB: Supervised learning to infer consensus labels and quality scores for data with multiple annotators},
author={Goh, Hui Wen and Tkachenko, Ulyana and Mueller, Jonas},
booktitle={NeurIPS Human in the Loop Learning Workshop},
year={2022}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2301.11856"> ActiveLab: Active learning with data re-labeling (ICLR '23)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{goh2023activelab,
title={ActiveLab: Active Learning with Re-Labeling by Multiple Annotators},
author={Goh, Hui Wen and Mueller, Jonas},
booktitle={ICLR Workshop on Trustworthy ML},
year={2023}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2211.13895"> Incorrect Annotations in Multi-Label Classification (ICLR '23)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{thyagarajan2023multilabel,
title={Identifying Incorrect Annotations in Multi-Label Classification Data},
author={Thyagarajan, Aditya and Snorrason, Elías and Northcutt, Curtis and Mueller, Jonas},
booktitle={ICLR Workshop on Trustworthy ML},
year={2023}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2305.15696"> Detecting Dataset Drift and Non-IID Sampling (ICML '23)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{cummings2023drift,
title={Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors},
author={Cummings, Jesse and Snorrason, Elías and Mueller, Jonas},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2305.16583"> Detecting Errors in Numerical Data (ICML '23)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{zhou2023errors,
title={Detecting Errors in Numerical Data via any Regression Model},
author={Zhou, Hang and Mueller, Jonas and Kumar, Mayank and Wang, Jane-Ling and Lei, Jing},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2309.00832"> ObjectLab: Mislabeled Images in Object Detection Data (ICML '23)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{tkachenko2023objectlab,
title={ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data},
author={Tkachenko, Ulyana and Thyagarajan, Aditya and Mueller, Jonas},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
</details>
<details><summary><a href="https://arxiv.org/abs/2307.05080"> Label Errors in Segmentation Data (ICML '23)</a> (<b>click to show bibtex</b>) </summary>
@inproceedings{lad2023segmentation,
title={Estimating label quality and errors in semantic segmentation data via any model},
author={Lad, Vedang and Mueller, Jonas},
booktitle={ICML Workshop on Data-centric Machine Learning Research},
year={2023}
}
</details>
To understand/cite other cleanlab functionality not described above, check out our [additional publications](https://cleanlab.ai/research/).
## Other resources
- [Example Notebooks demonstrating practical applications of this package](https://github.com/cleanlab/examples)
- [Cleanlab Blog](https://cleanlab.ai/blog/)
- [Blog post: Introduction to Confident Learning](https://l7.curtisnorthcutt.com/confident-learning)
- [NeurIPS 2021 paper: Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks](https://arxiv.org/abs/2103.14749)
- [Introduction to Data-centric AI (MIT IAP Course 2023)](https://dcai.csail.mit.edu/)
- [Release notes for past versions](https://github.com/cleanlab/cleanlab/releases)
## Join our community
* Learn, discuss, and shape the future of cleanlab in our 1000+ member [Slack community](https://cleanlab.ai/slack).
* Interested in contributing? See the [contributing guide](CONTRIBUTING.md), [development guide](DEVELOPMENT.md), and [ideas on useful contributions](https://github.com/cleanlab/cleanlab/wiki#ideas-for-contributing-to-cleanlab). We welcome your help building a standard open-source platform for data-centric AI!
* Have questions? Check out [our FAQ](https://docs.cleanlab.ai/stable/tutorials/faq.html), [Github Issues](https://github.com/cleanlab/cleanlab/issues?q=is%3Aissue), or [Slack](https://cleanlab.ai/slack).
* Need professional help with your Data/AI project? Email us: team@cleanlab.ai <br>
For instance, we can help you **monitor incoming data and detect issues in real-time**.
## License
Copyright (c) 2017 Cleanlab Inc.
cleanlab is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
cleanlab is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
See [GNU Affero General Public LICENSE](https://github.com/cleanlab/cleanlab/blob/master/LICENSE) for details.
You can email us to discuss licensing: team@cleanlab.ai
### Commercial licensing
Commercial licensing is available for teams and enterprises that want to use cleanlab in production workflows, but are unable to open-source their code [as is required by the current license](https://github.com/cleanlab/cleanlab/blob/master/LICENSE). Please email us: team@cleanlab.ai
Raw data
{
"_id": null,
"home_page": null,
"name": "cleanlab",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": null,
"keywords": "machine_learning, data_cleaning, confident_learning, classification, weak_supervision, learning_with_noisy_labels, unsupervised_learning, datacentric_ai, datacentric",
"author": null,
"author_email": "\"Cleanlab Inc.\" <team@cleanlab.ai>",
"download_url": "https://files.pythonhosted.org/packages/5c/fc/87c1cc718d0db4558a896061592f99b8cf32211b35c6d145975f2480800a/cleanlab-2.7.0.tar.gz",
"platform": null,
"description": "<p align=\"center\">\n <img src=\"https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/cleanlab_logo_open_source.png\" width=60% height=60%>\n</p>\n\n<div align=\"center\">\n<a href=\"https://pypi.org/pypi/cleanlab/\" target=\"_blank\"><img src=\"https://img.shields.io/pypi/v/cleanlab.svg\" alt=\"pypi_versions\"></a>\n<a href=\"https://pypi.org/pypi/cleanlab/\" target=\"_blank\"><img src=\"https://img.shields.io/badge/python-3.8%2B-blue\" alt=\"py_versions\"></a>\n<a href=\"https://app.codecov.io/gh/cleanlab/cleanlab\" target=\"_blank\"><img src=\"https://codecov.io/gh/cleanlab/cleanlab/branch/master/graph/badge.svg\" alt=\"coverage\"></a>\n<a href=\"https://github.com/cleanlab/cleanlab/stargazers/\" target=\"_blank\"><img src=\"https://img.shields.io/github/stars/cleanlab/cleanlab?style=social&maxAge=2592000\" alt=\"Github Stars\"></a>\n<a href=\"https://cleanlab.ai/slack\" target=\"_blank\"><img src=\"https://img.shields.io/static/v1?logo=slack&style=flat&color=white&label=slack&message=join\" alt=\"Slack Community\"></a>\n<a href=\"https://twitter.com/CleanlabAI\" target=\"_blank\"><img src=\"https://img.shields.io/twitter/follow/CleanlabAI?style=social\" alt=\"Twitter\"></a>\n</div>\n\n<h4 align=\"center\">\n <p>\n <a href=\"https://docs.cleanlab.ai/\">Documentation</a> |\n <a href=\"https://github.com/cleanlab/examples\">Examples</a> |\n <a href=\"https://cleanlab.ai/blog/\">Blog</a> |\n <a href=\"#citation-and-related-publications\">Research</a> |\n <a href=\"#try-easy-mode-with-cleanlab-studio\">Cleanlab Studio</a> |\n <a href=\"#join-our-community\">Community</a>\n <p>\n</h4>\n\ncleanlab helps you **clean** data and **lab**els by automatically detecting issues in a ML dataset. To facilitate **machine learning with messy, real-world data**, this data-centric AI package uses your *existing* models to estimate dataset problems that can be fixed to train even *better* models.\n \n\n<p align=\"center\">\n <img src=\"https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/datalab_issues.png\" width=74% height=74%>\n</p>\n<p align=\"center\">\n Examples of various issues in Cat/Dog dataset <b>automatically detected</b> by cleanlab via this code: \n</p>\n\n```python\n lab = cleanlab.Datalab(data=dataset, label=\"column_name_for_labels\")\n # Fit any ML model, get its feature_embeddings & pred_probs for your data\n lab.find_issues(features=feature_embeddings, pred_probs=pred_probs)\n lab.report()\n```\n\n- Use cleanlab to automatically check every: [image](https://docs.cleanlab.ai/stable/tutorials/datalab/image.html), [text](https://docs.cleanlab.ai/stable/tutorials/datalab/text.html), [audio](https://docs.cleanlab.ai/stable/tutorials/datalab/audio.html), or [tabular](https://docs.cleanlab.ai/stable/tutorials/datalab/tabular.html) dataset.\n- Use cleanlab to automatically: [detect data issues (outliers, duplicates, label errors, etc)](https://docs.cleanlab.ai/stable/tutorials/datalab/datalab_quickstart.html), [train robust models](https://docs.cleanlab.ai/stable/tutorials/indepth_overview.html), [infer consensus + annotator-quality for multi-annotator data](https://docs.cleanlab.ai/stable/tutorials/multiannotator.html), [suggest data to (re)label next (active learning)](https://github.com/cleanlab/examples/blob/master/active_learning_multiannotator/active_learning.ipynb).\n\n\n---\n\n### Try easy mode with Cleanlab Studio \n\nWhile this open-source package **finds** data issues, its utility depends on you having: a good existing ML model + an interface to efficiently **fix** these issues in your dataset. Providing all these pieces, [Cleanlab Studio](https://cleanlab.ai/blog/data-centric-ai/) is a Data Curation platform to **find and fix** problems in any {image, text, tabular} dataset. Cleanlab Studio [automatically](https://cleanlab.ai/blog/data-centric-ai/) runs optimized algorithms from this package on top of **AutoML & Foundation** models fit to your data, and presents detected issues (+ AI-suggested fixes) in an intelligent [data correction interface](https://www.youtube.com/playlist?list=PLn_2rr2ltYqA1uAC0AnRbPyY-wWVf1aeg).\n\n**[Try it for free!](https://cleanlab.ai/signup/)** Adopting Cleanlab Studio enables users of this package to:\n- Work 100x faster (1 min to analyze your raw data with **zero** code or ML work; optionally use [Python API](https://help.cleanlab.ai/tutorials/))\n- Produce better-quality data (10x more [types of issues](https://help.cleanlab.ai/guide/concepts/cleanlab_columns/) auto detected & **corrected** via built-in AI)\n- Accomplish more (auto-label data, deploy ML instantly, audit LLM inputs/outputs, moderate content, ...)\n- Monitor incoming data and detect issues in real-time (integrate your data pipeline\u00a0on an [Enterprise plan](https://cleanlab.ai/sales/)) \n\n<p align=\"center\">\n <img src=\"https://raw.githubusercontent.com/cleanlab/assets/master/cleanlab/ml-with-cleanlab-studio.png\" alt=\"The modern AI pipeline automated with Cleanlab Studio\">\n</p>\n\n\n## Run cleanlab open-source\n\nThis cleanlab package runs on Python 3.8+ and supports Linux, macOS, as well as Windows.\n\n- Get started [here](https://docs.cleanlab.ai/)! Install via `pip` or `conda`.\n- Developers who install the bleeding-edge from source should refer to [this master branch documentation](https://docs.cleanlab.ai/master/index.html).\n\n**Practicing data-centric AI can look like this:**\n1. Train initial ML model on original dataset.\n2. Utilize this model to diagnose data issues (via cleanlab methods) and improve the dataset.\n3. Train the same model on the improved dataset. \n4. Try various modeling techniques to further improve performance.\n\nMost folks jump from Step 1 \u2192 4, but you may achieve big gains without *any* change to your modeling code by using cleanlab!\nContinuously boost performance by iterating Steps 2 \u2192 4 (and try to evaluate\u00a0with *cleaned* data).\n\n\n\n\n## Use cleanlab with any model and in most ML tasks\n\nAll features of cleanlab work with **any dataset** and **any model**. Yes, any model: PyTorch, Tensorflow, Keras, JAX, HuggingFace, OpenAI, XGBoost, scikit-learn, etc.\n\ncleanlab is useful across a wide variety of Machine Learning tasks. Specific tasks this data-centric AI package offers dedicated functionality for include:\n1. [Binary and multi-class classification](https://docs.cleanlab.ai/stable/tutorials/indepth_overview.html)\n2. [Multi-label classification](https://docs.cleanlab.ai/stable/tutorials/multilabel_classification.html) (e.g. image/document tagging)\n3. [Token classification](https://docs.cleanlab.ai/stable/tutorials/token_classification.html) (e.g. entity recognition in text)\n4. [Regression](https://docs.cleanlab.ai/stable/tutorials/regression.html) (predicting numerical column in a dataset)\n5. [Image segmentation](https://docs.cleanlab.ai/stable/tutorials/segmentation.html) (images with per-pixel annotations)\n6. [Object detection](https://docs.cleanlab.ai/stable/tutorials/object_detection.html) (images with bounding box annotations)\n7. [Classification with data labeled by multiple annotators](https://docs.cleanlab.ai/stable/tutorials/multiannotator.html)\n8. [Active learning with multiple annotators](https://github.com/cleanlab/examples/blob/master/active_learning_multiannotator/active_learning.ipynb) (suggest which data to label or re-label to improve model most)\n9. [Outlier detection](https://docs.cleanlab.ai/stable/tutorials/outliers.html) (identify atypical data that appears out of distribution)\n\nFor other ML tasks, cleanlab can still help you improve your dataset if appropriately applied.\nSee our [Example Notebooks](https://github.com/cleanlab/examples) and [Blog](https://cleanlab.ai/blog/).\n\n\n## So fresh, so cleanlab\n\nBeyond automatically catching [all sorts of issues](https://docs.cleanlab.ai/stable/cleanlab/datalab/guide/issue_type_description.html) lurking in your data, this data-centric AI package helps you deal with **noisy labels** and train more **robust ML models**.\nHere's an example:\n\n```python\n\n# cleanlab works with **any classifier**. Yup, you can use PyTorch/TensorFlow/OpenAI/XGBoost/etc.\ncl = cleanlab.classification.CleanLearning(sklearn.YourFavoriteClassifier())\n\n# cleanlab finds data and label issues in **any dataset**... in ONE line of code!\nlabel_issues = cl.find_label_issues(data, labels)\n\n# cleanlab trains a robust version of your model that works more reliably with noisy data.\ncl.fit(data, labels)\n\n# cleanlab estimates the predictions you would have gotten if you had trained with *no* label issues.\ncl.predict(test_data)\n\n# A universal data-centric AI tool, cleanlab quantifies class-level issues and overall data quality, for any dataset.\ncleanlab.dataset.health_summary(labels, confident_joint=cl.confident_joint)\n```\n\ncleanlab **clean**s your data's **lab**els via state-of-the-art *confident learning* algorithms, published in this [paper](https://jair.org/index.php/jair/article/view/12125) and [blog](https://l7.curtisnorthcutt.com/confident-learning). See some of the datasets cleaned with cleanlab at [labelerrors.com](https://labelerrors.com).\n\ncleanlab is:\n\n1. **backed by theory** -- with [provable guarantees](https://arxiv.org/abs/1911.00068) of exact label noise estimation, even with imperfect models.\n2. **fast** -- code is parallelized and scalable.\n4. **easy to use** -- one line of code to find mislabeled data, bad annotators, outliers, or train noise-robust models.\n6. **general** -- works with **[any dataset](https://labelerrors.com/)** (text, image, tabular, audio,...) + **any model** (PyTorch, OpenAI, XGBoost,...)\n<br/>\n\n\n<p align=\"center\">\nExamples of incorrect given labels in various image datasets <a href=\"https://l7.curtisnorthcutt.com/label-errors\">found and corrected</a> using cleanlab. \nWhile these examples are from image datasets, this also works for text, audio, tabular data.\n</p>\n\n\n## Citation and related publications\n\ncleanlab is based on peer-reviewed research. Here are relevant papers to cite if you use this package:\n\n<details><summary><a href=\"https://arxiv.org/abs/1911.00068\">Confident Learning (JAIR '21)</a> (<b>click to show bibtex</b>) </summary>\n\n @article{northcutt2021confidentlearning,\n title={Confident Learning: Estimating Uncertainty in Dataset Labels},\n author={Curtis G. Northcutt and Lu Jiang and Isaac L. Chuang},\n journal={Journal of Artificial Intelligence Research (JAIR)},\n volume={70},\n pages={1373--1411},\n year={2021}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/1705.01936\">Rank Pruning (UAI '17)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{northcutt2017rankpruning,\n author={Northcutt, Curtis G. and Wu, Tailin and Chuang, Isaac L.},\n title={Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels},\n booktitle = {Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence},\n series = {UAI'17},\n year = {2017},\n location = {Sydney, Australia},\n numpages = {10},\n url = {http://auai.org/uai2017/proceedings/papers/35.pdf},\n publisher = {AUAI Press},\n }\n\n</details>\n\n<details><summary><a href=\"https://people.csail.mit.edu/jonasmueller/info/LabelQuality_icml.pdf\"> Label Quality Scoring (ICML '22)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{kuan2022labelquality,\n title={Model-agnostic label quality scoring to detect real-world label errors},\n author={Kuan, Johnson and Mueller, Jonas},\n booktitle={ICML DataPerf Workshop},\n year={2022}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2207.03061\"> Out-of-Distribution Detection (ICML '22)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{kuan2022ood,\n title={Back to the Basics: Revisiting Out-of-Distribution Detection Baselines},\n author={Kuan, Johnson and Mueller, Jonas},\n booktitle={ICML Workshop on Principles of Distribution Shift},\n year={2022}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2210.03920\"> Token Classification Label Errors (NeurIPS '22)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{wang2022tokenerrors,\n title={Detecting label errors in token classification data},\n author={Wang, Wei-Chen and Mueller, Jonas},\n booktitle={NeurIPS Workshop on Interactive Learning for Natural Language Processing (InterNLP)},\n year={2022}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2210.06812\"> CROWDLAB for Data with Multiple Annotators (NeurIPS '22)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{goh2022crowdlab,\n title={CROWDLAB: Supervised learning to infer consensus labels and quality scores for data with multiple annotators},\n author={Goh, Hui Wen and Tkachenko, Ulyana and Mueller, Jonas},\n booktitle={NeurIPS Human in the Loop Learning Workshop},\n year={2022}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2301.11856\"> ActiveLab: Active learning with data re-labeling (ICLR '23)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{goh2023activelab,\n title={ActiveLab: Active Learning with Re-Labeling by Multiple Annotators},\n author={Goh, Hui Wen and Mueller, Jonas},\n booktitle={ICLR Workshop on Trustworthy ML},\n year={2023}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2211.13895\"> Incorrect Annotations in Multi-Label Classification (ICLR '23)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{thyagarajan2023multilabel,\n title={Identifying Incorrect Annotations in Multi-Label Classification Data},\n author={Thyagarajan, Aditya and Snorrason, El\u00edas and Northcutt, Curtis and Mueller, Jonas},\n booktitle={ICLR Workshop on Trustworthy ML},\n year={2023}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2305.15696\"> Detecting Dataset Drift and Non-IID Sampling (ICML '23)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{cummings2023drift,\n title={Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors},\n author={Cummings, Jesse and Snorrason, El\u00edas and Mueller, Jonas},\n booktitle={ICML Workshop on Data-centric Machine Learning Research},\n year={2023}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2305.16583\"> Detecting Errors in Numerical Data (ICML '23)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{zhou2023errors,\n title={Detecting Errors in Numerical Data via any Regression Model},\n author={Zhou, Hang and Mueller, Jonas and Kumar, Mayank and Wang, Jane-Ling and Lei, Jing},\n booktitle={ICML Workshop on Data-centric Machine Learning Research},\n year={2023}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2309.00832\"> ObjectLab: Mislabeled Images in Object Detection Data (ICML '23)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{tkachenko2023objectlab,\n title={ObjectLab: Automated Diagnosis of Mislabeled Images in Object Detection Data},\n author={Tkachenko, Ulyana and Thyagarajan, Aditya and Mueller, Jonas},\n booktitle={ICML Workshop on Data-centric Machine Learning Research},\n year={2023}\n }\n\n</details>\n\n<details><summary><a href=\"https://arxiv.org/abs/2307.05080\"> Label Errors in Segmentation Data (ICML '23)</a> (<b>click to show bibtex</b>) </summary>\n\n @inproceedings{lad2023segmentation,\n title={Estimating label quality and errors in semantic segmentation data via any model},\n author={Lad, Vedang and Mueller, Jonas},\n booktitle={ICML Workshop on Data-centric Machine Learning Research},\n year={2023}\n }\n\n</details>\n\nTo understand/cite other cleanlab functionality not described above, check out our [additional publications](https://cleanlab.ai/research/).\n\n\n## Other resources\n\n- [Example Notebooks demonstrating practical applications of this package](https://github.com/cleanlab/examples)\n\n- [Cleanlab Blog](https://cleanlab.ai/blog/)\n\n- [Blog post: Introduction to Confident Learning](https://l7.curtisnorthcutt.com/confident-learning)\n\n- [NeurIPS 2021 paper: Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks](https://arxiv.org/abs/2103.14749)\n\n- [Introduction to Data-centric AI (MIT IAP Course 2023)](https://dcai.csail.mit.edu/)\n\n- [Release notes for past versions](https://github.com/cleanlab/cleanlab/releases)\n\n\n## Join our community\n\n* Learn, discuss, and shape the future of cleanlab in our 1000+ member [Slack community](https://cleanlab.ai/slack).\n\n* Interested in contributing? See the [contributing guide](CONTRIBUTING.md), [development guide](DEVELOPMENT.md), and [ideas on useful contributions](https://github.com/cleanlab/cleanlab/wiki#ideas-for-contributing-to-cleanlab). We welcome your help building a standard open-source platform for data-centric AI!\n\n* Have questions? Check out [our FAQ](https://docs.cleanlab.ai/stable/tutorials/faq.html), [Github Issues](https://github.com/cleanlab/cleanlab/issues?q=is%3Aissue), or [Slack](https://cleanlab.ai/slack).\n\n* Need professional help with your Data/AI project? Email us: team@cleanlab.ai <br>\nFor instance, we can help you **monitor incoming data and detect issues in real-time**.\n\n## License\n\nCopyright (c) 2017 Cleanlab Inc.\n\ncleanlab is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.\n\ncleanlab is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.\n\nSee [GNU Affero General Public LICENSE](https://github.com/cleanlab/cleanlab/blob/master/LICENSE) for details.\nYou can email us to discuss licensing: team@cleanlab.ai\n\n### Commercial licensing\n\nCommercial licensing is available for teams and enterprises that want to use cleanlab in production workflows, but are unable to open-source their code [as is required by the current license](https://github.com/cleanlab/cleanlab/blob/master/LICENSE). Please email us: team@cleanlab.ai\n",
"bugtrack_url": null,
"license": " GNU AFFERO GENERAL PUBLIC LICENSE Version 3, 19 November 2007 Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/> Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed. Preamble The GNU Affero General Public License is a free, copyleft license for software and other kinds of works, specifically designed to ensure cooperation with the community in the case of network server software. The licenses for most software and other practical works are designed to take away your freedom to share and change the works. By contrast, our General Public Licenses are intended to guarantee your freedom to share and change all versions of a program--to make sure it remains free software for all its users. When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for them if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs, and that you know you can do these things. Developers that use our General Public Licenses protect your rights with two steps: (1) assert copyright on the software, and (2) offer you this License which gives you legal permission to copy, distribute and/or modify the software. A secondary benefit of defending all users' freedom is that improvements made in alternate versions of the program, if they receive widespread use, become available for other developers to incorporate. Many developers of free software are heartened and encouraged by the resulting cooperation. However, in the case of software used on network servers, this result may fail to come about. The GNU General Public License permits making a modified version and letting the public access it on a server without ever releasing its source code to the public. The GNU Affero General Public License is designed specifically to ensure that, in such cases, the modified source code becomes available to the community. It requires the operator of a network server to provide the source code of the modified version running there to the users of that server. Therefore, public use of a modified version, on a publicly accessible server, gives the public access to the source code of the modified version. An older license, called the Affero General Public License and published by Affero, was designed to accomplish similar goals. This is a different license, not a version of the Affero GPL, but Affero has released a new version of the Affero GPL which permits relicensing under this license. The precise terms and conditions for copying, distribution and modification follow. TERMS AND CONDITIONS 0. Definitions. \"This License\" refers to version 3 of the GNU Affero General Public License. \"Copyright\" also means copyright-like laws that apply to other kinds of works, such as semiconductor masks. \"The Program\" refers to any copyrightable work licensed under this License. Each licensee is addressed as \"you\". \"Licensees\" and \"recipients\" may be individuals or organizations. To \"modify\" a work means to copy from or adapt all or part of the work in a fashion requiring copyright permission, other than the making of an exact copy. The resulting work is called a \"modified version\" of the earlier work or a work \"based on\" the earlier work. A \"covered work\" means either the unmodified Program or a work based on the Program. To \"propagate\" a work means to do anything with it that, without permission, would make you directly or secondarily liable for infringement under applicable copyright law, except executing it on a computer or modifying a private copy. Propagation includes copying, distribution (with or without modification), making available to the public, and in some countries other activities as well. To \"convey\" a work means any kind of propagation that enables other parties to make or receive copies. Mere interaction with a user through a computer network, with no transfer of a copy, is not conveying. An interactive user interface displays \"Appropriate Legal Notices\" to the extent that it includes a convenient and prominently visible feature that (1) displays an appropriate copyright notice, and (2) tells the user that there is no warranty for the work (except to the extent that warranties are provided), that licensees may convey the work under this License, and how to view a copy of this License. If the interface presents a list of user commands or options, such as a menu, a prominent item in the list meets this criterion. 1. Source Code. The \"source code\" for a work means the preferred form of the work for making modifications to it. \"Object code\" means any non-source form of a work. A \"Standard Interface\" means an interface that either is an official standard defined by a recognized standards body, or, in the case of interfaces specified for a particular programming language, one that is widely used among developers working in that language. The \"System Libraries\" of an executable work include anything, other than the work as a whole, that (a) is included in the normal form of packaging a Major Component, but which is not part of that Major Component, and (b) serves only to enable use of the work with that Major Component, or to implement a Standard Interface for which an implementation is available to the public in source code form. A \"Major Component\", in this context, means a major essential component (kernel, window system, and so on) of the specific operating system (if any) on which the executable work runs, or a compiler used to produce the work, or an object code interpreter used to run it. The \"Corresponding Source\" for a work in object code form means all the source code needed to generate, install, and (for an executable work) run the object code and to modify the work, including scripts to control those activities. However, it does not include the work's System Libraries, or general-purpose tools or generally available free programs which are used unmodified in performing those activities but which are not part of the work. For example, Corresponding Source includes interface definition files associated with source files for the work, and the source code for shared libraries and dynamically linked subprograms that the work is specifically designed to require, such as by intimate data communication or control flow between those subprograms and other parts of the work. The Corresponding Source need not include anything that users can regenerate automatically from other parts of the Corresponding Source. The Corresponding Source for a work in source code form is that same work. 2. Basic Permissions. All rights granted under this License are granted for the term of copyright on the Program, and are irrevocable provided the stated conditions are met. This License explicitly affirms your unlimited permission to run the unmodified Program. The output from running a covered work is covered by this License only if the output, given its content, constitutes a covered work. This License acknowledges your rights of fair use or other equivalent, as provided by copyright law. You may make, run and propagate covered works that you do not convey, without conditions so long as your license otherwise remains in force. You may convey covered works to others for the sole purpose of having them make modifications exclusively for you, or provide you with facilities for running those works, provided that you comply with the terms of this License in conveying all material for which you do not control copyright. Those thus making or running the covered works for you must do so exclusively on your behalf, under your direction and control, on terms that prohibit them from making any copies of your copyrighted material outside their relationship with you. Conveying under any other circumstances is permitted solely under the conditions stated below. Sublicensing is not allowed; section 10 makes it unnecessary. 3. Protecting Users' Legal Rights From Anti-Circumvention Law. No covered work shall be deemed part of an effective technological measure under any applicable law fulfilling obligations under article 11 of the WIPO copyright treaty adopted on 20 December 1996, or similar laws prohibiting or restricting circumvention of such measures. When you convey a covered work, you waive any legal power to forbid circumvention of technological measures to the extent such circumvention is effected by exercising rights under this License with respect to the covered work, and you disclaim any intention to limit operation or modification of the work as a means of enforcing, against the work's users, your or third parties' legal rights to forbid circumvention of technological measures. 4. Conveying Verbatim Copies. You may convey verbatim copies of the Program's source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice; keep intact all notices stating that this License and any non-permissive terms added in accord with section 7 apply to the code; keep intact all notices of the absence of any warranty; and give all recipients a copy of this License along with the Program. You may charge any price or no price for each copy that you convey, and you may offer support or warranty protection for a fee. 5. Conveying Modified Source Versions. You may convey a work based on the Program, or the modifications to produce it from the Program, in the form of source code under the terms of section 4, provided that you also meet all of these conditions: a) The work must carry prominent notices stating that you modified it, and giving a relevant date. b) The work must carry prominent notices stating that it is released under this License and any conditions added under section 7. This requirement modifies the requirement in section 4 to \"keep intact all notices\". c) You must license the entire work, as a whole, under this License to anyone who comes into possession of a copy. This License will therefore apply, along with any applicable section 7 additional terms, to the whole of the work, and all its parts, regardless of how they are packaged. This License gives no permission to license the work in any other way, but it does not invalidate such permission if you have separately received it. d) If the work has interactive user interfaces, each must display Appropriate Legal Notices; however, if the Program has interactive interfaces that do not display Appropriate Legal Notices, your work need not make them do so. A compilation of a covered work with other separate and independent works, which are not by their nature extensions of the covered work, and which are not combined with it such as to form a larger program, in or on a volume of a storage or distribution medium, is called an \"aggregate\" if the compilation and its resulting copyright are not used to limit the access or legal rights of the compilation's users beyond what the individual works permit. Inclusion of a covered work in an aggregate does not cause this License to apply to the other parts of the aggregate. 6. Conveying Non-Source Forms. You may convey a covered work in object code form under the terms of sections 4 and 5, provided that you also convey the machine-readable Corresponding Source under the terms of this License, in one of these ways: a) Convey the object code in, or embodied in, a physical product (including a physical distribution medium), accompanied by the Corresponding Source fixed on a durable physical medium customarily used for software interchange. b) Convey the object code in, or embodied in, a physical product (including a physical distribution medium), accompanied by a written offer, valid for at least three years and valid for as long as you offer spare parts or customer support for that product model, to give anyone who possesses the object code either (1) a copy of the Corresponding Source for all the software in the product that is covered by this License, on a durable physical medium customarily used for software interchange, for a price no more than your reasonable cost of physically performing this conveying of source, or (2) access to copy the Corresponding Source from a network server at no charge. c) Convey individual copies of the object code with a copy of the written offer to provide the Corresponding Source. This alternative is allowed only occasionally and noncommercially, and only if you received the object code with such an offer, in accord with subsection 6b. d) Convey the object code by offering access from a designated place (gratis or for a charge), and offer equivalent access to the Corresponding Source in the same way through the same place at no further charge. You need not require recipients to copy the Corresponding Source along with the object code. If the place to copy the object code is a network server, the Corresponding Source may be on a different server (operated by you or a third party) that supports equivalent copying facilities, provided you maintain clear directions next to the object code saying where to find the Corresponding Source. Regardless of what server hosts the Corresponding Source, you remain obligated to ensure that it is available for as long as needed to satisfy these requirements. e) Convey the object code using peer-to-peer transmission, provided you inform other peers where the object code and Corresponding Source of the work are being offered to the general public at no charge under subsection 6d. A separable portion of the object code, whose source code is excluded from the Corresponding Source as a System Library, need not be included in conveying the object code work. A \"User Product\" is either (1) a \"consumer product\", which means any tangible personal property which is normally used for personal, family, or household purposes, or (2) anything designed or sold for incorporation into a dwelling. In determining whether a product is a consumer product, doubtful cases shall be resolved in favor of coverage. For a particular product received by a particular user, \"normally used\" refers to a typical or common use of that class of product, regardless of the status of the particular user or of the way in which the particular user actually uses, or expects or is expected to use, the product. A product is a consumer product regardless of whether the product has substantial commercial, industrial or non-consumer uses, unless such uses represent the only significant mode of use of the product. \"Installation Information\" for a User Product means any methods, procedures, authorization keys, or other information required to install and execute modified versions of a covered work in that User Product from a modified version of its Corresponding Source. The information must suffice to ensure that the continued functioning of the modified object code is in no case prevented or interfered with solely because modification has been made. If you convey an object code work under this section in, or with, or specifically for use in, a User Product, and the conveying occurs as part of a transaction in which the right of possession and use of the User Product is transferred to the recipient in perpetuity or for a fixed term (regardless of how the transaction is characterized), the Corresponding Source conveyed under this section must be accompanied by the Installation Information. But this requirement does not apply if neither you nor any third party retains the ability to install modified object code on the User Product (for example, the work has been installed in ROM). The requirement to provide Installation Information does not include a requirement to continue to provide support service, warranty, or updates for a work that has been modified or installed by the recipient, or for the User Product in which it has been modified or installed. Access to a network may be denied when the modification itself materially and adversely affects the operation of the network or violates the rules and protocols for communication across the network. Corresponding Source conveyed, and Installation Information provided, in accord with this section must be in a format that is publicly documented (and with an implementation available to the public in source code form), and must require no special password or key for unpacking, reading or copying. 7. Additional Terms. \"Additional permissions\" are terms that supplement the terms of this License by making exceptions from one or more of its conditions. Additional permissions that are applicable to the entire Program shall be treated as though they were included in this License, to the extent that they are valid under applicable law. If additional permissions apply only to part of the Program, that part may be used separately under those permissions, but the entire Program remains governed by this License without regard to the additional permissions. When you convey a copy of a covered work, you may at your option remove any additional permissions from that copy, or from any part of it. (Additional permissions may be written to require their own removal in certain cases when you modify the work.) You may place additional permissions on material, added by you to a covered work, for which you have or can give appropriate copyright permission. Notwithstanding any other provision of this License, for material you add to a covered work, you may (if authorized by the copyright holders of that material) supplement the terms of this License with terms: a) Disclaiming warranty or limiting liability differently from the terms of sections 15 and 16 of this License; or b) Requiring preservation of specified reasonable legal notices or author attributions in that material or in the Appropriate Legal Notices displayed by works containing it; or c) Prohibiting misrepresentation of the origin of that material, or requiring that modified versions of such material be marked in reasonable ways as different from the original version; or d) Limiting the use for publicity purposes of names of licensors or authors of the material; or e) Declining to grant rights under trademark law for use of some trade names, trademarks, or service marks; or f) Requiring indemnification of licensors and authors of that material by anyone who conveys the material (or modified versions of it) with contractual assumptions of liability to the recipient, for any liability that these contractual assumptions directly impose on those licensors and authors. All other non-permissive additional terms are considered \"further restrictions\" within the meaning of section 10. If the Program as you received it, or any part of it, contains a notice stating that it is governed by this License along with a term that is a further restriction, you may remove that term. If a license document contains a further restriction but permits relicensing or conveying under this License, you may add to a covered work material governed by the terms of that license document, provided that the further restriction does not survive such relicensing or conveying. If you add terms to a covered work in accord with this section, you must place, in the relevant source files, a statement of the additional terms that apply to those files, or a notice indicating where to find the applicable terms. Additional terms, permissive or non-permissive, may be stated in the form of a separately written license, or stated as exceptions; the above requirements apply either way. 8. Termination. You may not propagate or modify a covered work except as expressly provided under this License. Any attempt otherwise to propagate or modify it is void, and will automatically terminate your rights under this License (including any patent licenses granted under the third paragraph of section 11). However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation. Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice. Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, you do not qualify to receive new licenses for the same material under section 10. 9. Acceptance Not Required for Having Copies. You are not required to accept this License in order to receive or run a copy of the Program. Ancillary propagation of a covered work occurring solely as a consequence of using peer-to-peer transmission to receive a copy likewise does not require acceptance. However, nothing other than this License grants you permission to propagate or modify any covered work. These actions infringe copyright if you do not accept this License. Therefore, by modifying or propagating a covered work, you indicate your acceptance of this License to do so. 10. Automatic Licensing of Downstream Recipients. Each time you convey a covered work, the recipient automatically receives a license from the original licensors, to run, modify and propagate that work, subject to this License. You are not responsible for enforcing compliance by third parties with this License. An \"entity transaction\" is a transaction transferring control of an organization, or substantially all assets of one, or subdividing an organization, or merging organizations. If propagation of a covered work results from an entity transaction, each party to that transaction who receives a copy of the work also receives whatever licenses to the work the party's predecessor in interest had or could give under the previous paragraph, plus a right to possession of the Corresponding Source of the work from the predecessor in interest, if the predecessor has it or can get it with reasonable efforts. You may not impose any further restrictions on the exercise of the rights granted or affirmed under this License. For example, you may not impose a license fee, royalty, or other charge for exercise of rights granted under this License, and you may not initiate litigation (including a cross-claim or counterclaim in a lawsuit) alleging that any patent claim is infringed by making, using, selling, offering for sale, or importing the Program or any portion of it. 11. Patents. A \"contributor\" is a copyright holder who authorizes use under this License of the Program or a work on which the Program is based. The work thus licensed is called the contributor's \"contributor version\". A contributor's \"essential patent claims\" are all patent claims owned or controlled by the contributor, whether already acquired or hereafter acquired, that would be infringed by some manner, permitted by this License, of making, using, or selling its contributor version, but do not include claims that would be infringed only as a consequence of further modification of the contributor version. For purposes of this definition, \"control\" includes the right to grant patent sublicenses in a manner consistent with the requirements of this License. Each contributor grants you a non-exclusive, worldwide, royalty-free patent license under the contributor's essential patent claims, to make, use, sell, offer for sale, import and otherwise run, modify and propagate the contents of its contributor version. In the following three paragraphs, a \"patent license\" is any express agreement or commitment, however denominated, not to enforce a patent (such as an express permission to practice a patent or covenant not to sue for patent infringement). To \"grant\" such a patent license to a party means to make such an agreement or commitment not to enforce a patent against the party. If you convey a covered work, knowingly relying on a patent license, and the Corresponding Source of the work is not available for anyone to copy, free of charge and under the terms of this License, through a publicly available network server or other readily accessible means, then you must either (1) cause the Corresponding Source to be so available, or (2) arrange to deprive yourself of the benefit of the patent license for this particular work, or (3) arrange, in a manner consistent with the requirements of this License, to extend the patent license to downstream recipients. \"Knowingly relying\" means you have actual knowledge that, but for the patent license, your conveying the covered work in a country, or your recipient's use of the covered work in a country, would infringe one or more identifiable patents in that country that you have reason to believe are valid. If, pursuant to or in connection with a single transaction or arrangement, you convey, or propagate by procuring conveyance of, a covered work, and grant a patent license to some of the parties receiving the covered work authorizing them to use, propagate, modify or convey a specific copy of the covered work, then the patent license you grant is automatically extended to all recipients of the covered work and works based on it. A patent license is \"discriminatory\" if it does not include within the scope of its coverage, prohibits the exercise of, or is conditioned on the non-exercise of one or more of the rights that are specifically granted under this License. You may not convey a covered work if you are a party to an arrangement with a third party that is in the business of distributing software, under which you make payment to the third party based on the extent of your activity of conveying the work, and under which the third party grants, to any of the parties who would receive the covered work from you, a discriminatory patent license (a) in connection with copies of the covered work conveyed by you (or copies made from those copies), or (b) primarily for and in connection with specific products or compilations that contain the covered work, unless you entered into that arrangement, or that patent license was granted, prior to 28 March 2007. Nothing in this License shall be construed as excluding or limiting any implied license or other defenses to infringement that may otherwise be available to you under applicable patent law. 12. No Surrender of Others' Freedom. If conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot convey a covered work so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not convey it at all. For example, if you agree to terms that obligate you to collect a royalty for further conveying from those to whom you convey the Program, the only way you could satisfy both those terms and this License would be to refrain entirely from conveying the Program. 13. Remote Network Interaction; Use with the GNU General Public License. Notwithstanding any other provision of this License, if you modify the Program, your modified version must prominently offer all users interacting with it remotely through a computer network (if your version supports such interaction) an opportunity to receive the Corresponding Source of your version by providing access to the Corresponding Source from a network server at no charge, through some standard or customary means of facilitating copying of software. This Corresponding Source shall include the Corresponding Source for any work covered by version 3 of the GNU General Public License that is incorporated pursuant to the following paragraph. Notwithstanding any other provision of this License, you have permission to link or combine any covered work with a work licensed under version 3 of the GNU General Public License into a single combined work, and to convey the resulting work. The terms of this License will continue to apply to the part which is the covered work, but the work with which it is combined will remain governed by version 3 of the GNU General Public License. 14. Revised Versions of this License. The Free Software Foundation may publish revised and/or new versions of the GNU Affero General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. Each version is given a distinguishing version number. If the Program specifies that a certain numbered version of the GNU Affero General Public License \"or any later version\" applies to it, you have the option of following the terms and conditions either of that numbered version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of the GNU Affero General Public License, you may choose any version ever published by the Free Software Foundation. If the Program specifies that a proxy can decide which future versions of the GNU Affero General Public License can be used, that proxy's public statement of acceptance of a version permanently authorizes you to choose that version for the Program. Later license versions may give you additional or different permissions. However, no additional obligations are imposed on any author or copyright holder as a result of your choosing to follow a later version. 15. Disclaimer of Warranty. THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM \"AS IS\" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION. 16. Limitation of Liability. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. 17. Interpretation of Sections 15 and 16. If the disclaimer of warranty and limitation of liability provided above cannot be given local legal effect according to their terms, reviewing courts shall apply local law that most closely approximates an absolute waiver of all civil liability in connection with the Program, unless a warranty or assumption of liability accompanies a copy of the Program in return for a fee. END OF TERMS AND CONDITIONS How to Apply These Terms to Your New Programs If you develop a new program, and you want it to be of the greatest possible use to the public, the best way to achieve this is to make it free software which everyone can redistribute and change under these terms. To do so, attach the following notices to the program. It is safest to attach them to the start of each source file to most effectively state the exclusion of warranty; and each file should have at least the \"copyright\" line and a pointer to where the full notice is found. <one line to give the program's name and a brief idea of what it does.> Copyright (C) <year> <name of author> This program is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more details. You should have received a copy of the GNU Affero General Public License along with this program. If not, see <https://www.gnu.org/licenses/>. Also add information on how to contact you by electronic and paper mail. If your software can interact with users remotely through a computer network, you should also make sure that it provides a way for users to get its source. For example, if your program is a web application, its interface could display a \"Source\" link that leads users to an archive of the code. There are many ways you could offer source, and different solutions will be better for different programs; see section 13 for the specific requirements. You should also get your employer (if you work as a programmer) or school, if any, to sign a \"copyright disclaimer\" for the program, if necessary. For more information on this, and how to apply and follow the GNU AGPL, see <https://www.gnu.org/licenses/>. ",
"summary": "The standard package for data-centric AI, machine learning with label errors, and automatically finding and fixing dataset issues in Python.",
"version": "2.7.0",
"project_urls": {
"Bug Tracker": "https://github.com/cleanlab/cleanlab/issues",
"Documentation": "https://docs.cleanlab.ai",
"Homepage": "https://cleanlab.ai",
"Source Code": "https://github.com/cleanlab/cleanlab"
},
"split_keywords": [
"machine_learning",
" data_cleaning",
" confident_learning",
" classification",
" weak_supervision",
" learning_with_noisy_labels",
" unsupervised_learning",
" datacentric_ai",
" datacentric"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "48269c4cee7cfd60059319c9c5a462da8f0a1906da4fee59f2789e1f1ef656f3",
"md5": "18dfe8b237304536cb557fd88e96b077",
"sha256": "cf9273574a7f156b3e01c189dfd21a34de3b80767cecd1ee8befa9522fc9badb"
},
"downloads": -1,
"filename": "cleanlab-2.7.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "18dfe8b237304536cb557fd88e96b077",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.8",
"size": 347815,
"upload_time": "2024-09-26T16:50:26",
"upload_time_iso_8601": "2024-09-26T16:50:26.541162Z",
"url": "https://files.pythonhosted.org/packages/48/26/9c4cee7cfd60059319c9c5a462da8f0a1906da4fee59f2789e1f1ef656f3/cleanlab-2.7.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "5cfc87c1cc718d0db4558a896061592f99b8cf32211b35c6d145975f2480800a",
"md5": "5ca0fed67660130cf07559cf7f83917a",
"sha256": "a58ff4a9997c393a9b37ed68e7471b54366213a5459f957f4a864b4d123a55c4"
},
"downloads": -1,
"filename": "cleanlab-2.7.0.tar.gz",
"has_sig": false,
"md5_digest": "5ca0fed67660130cf07559cf7f83917a",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 308778,
"upload_time": "2024-09-26T16:50:28",
"upload_time_iso_8601": "2024-09-26T16:50:28.643602Z",
"url": "https://files.pythonhosted.org/packages/5c/fc/87c1cc718d0db4558a896061592f99b8cf32211b35c6d145975f2480800a/cleanlab-2.7.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-09-26 16:50:28",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "cleanlab",
"github_project": "cleanlab",
"travis_ci": false,
"coveralls": true,
"github_actions": true,
"lcname": "cleanlab"
}
