# CPIExtract (Compound-Protein Interaction Extract)
## A software package to collect and harmonize small molecule and protein interactions
#### Authors: Andrea Piras, Shi Chenghao, Michael Sebek, Gordana Ispirova, Giulia Menichetti (giulia.menichetti@channing.harvard.edu)
## Introduction
The binding interactions between small molecules and proteins are the basis of cellular functions.
Yet, experimental data available regarding compound-protein interaction (CPI) is not harmonized into a single
entity but rather scattered across multiple institutions, each maintaining databases with different formats.
Extracting information from these multiple sources remains challenging due to data heterogeneity.
CPIExtract interactively extracts, filters and harmonizes CPI data from 9 databases, providing the output in tabular format (csv).\
The package provides two separate pipelines:
- Comp2Prot: Extract protein target interactions for compounds provided as input
- Prot2Comp: Extract compound interactions for proteins provided as input
### Comp2Prot
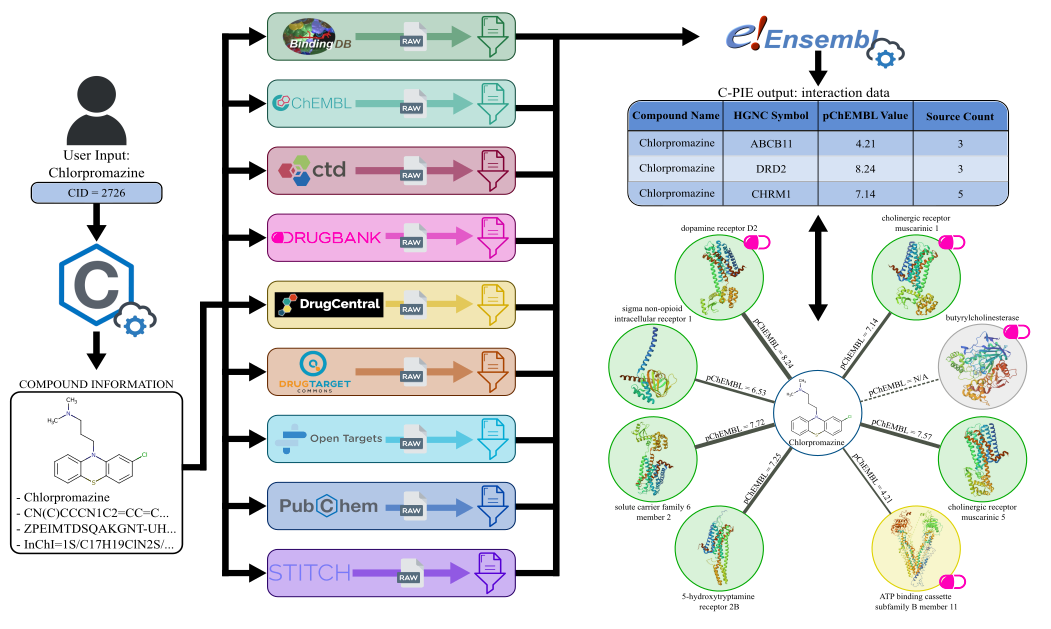
The pipeline extracts compound information from an input identifier using the [PubChem REST API](https://pubchempy.readthedocs.io/en/latest/), accessed with the [`PubChemPy`](https://github.com/mcs07/PubChemPy) Python package. Then, it uses the information to perform compound matching for each database, extracting raw interaction data. This data is then filtered for each database with a custom filter, ensuring only high-quality interactions are returned in the output. Finally, protein data are extracted using the [`Biomart`](https://github.com/sebriois/biomart) Python package, harmonizing the information from the 9 databases. The collected output is finally returned to the user in a `.csv` file. \
An exemplary pipeline workflow is depicted in the figure below. An equivalent output network is also shown.
### Prot2Comp
The pipeline follows a workflow similar to the other pipeline. It extracts protein information from an input identifier using the Biomart Python package. It performs the same database matching and filtering and then harmonizes the interaction data extracting compounds information with the PubChemPy Python package. The output is finally returned to the user in a `.csv` file.
## Getting started
### Setting up a work environment
#### I. With installing the package
1. Installing the necessary dependencies:
##### Option A: working with Conda
Working with Conda is recommended, but it is not essential. If you choose to work with Conda, these are the steps you need to take:
- Ensure you have Conda installed.
- Download the `environment.yml` and navigate to the directory of your local/remote machine where the file is located.
- Create a new conda environment with the `environment.yml` file:
```bash
conda env create -f environment.yml
```
- Activate your new conda environment:
```bash
conda activate CPIExtract
```
##### Option B: working without Conda
- Ensure the following dependencies are installed before proceeding:
```bash
pip install numpy pandas mysql-connector-python biomart pubchempy chembl-webresource-client
```
2. Install the package:
```bash
pip install cpiextract
```
#### II. Without installing the package
1. Ensure you have Python installed.
2. Copy the project to your local or remote machine:
```bash
git clone https://github.com/menicgiulia/CPIExtract.git
```
3. Navigate to the project directory:
```bash
cd CPIExtract-main
```
4. Installing the necessary dependencies:
##### Option A: working with Conda
Working with Conda is recommended, but it is not essential. If you choose to work with Conda, these are the steps you need to take:
- Ensure you have Conda installed.
- Create a new conda environment with the `environment.yml` file:
```bash
conda env create -f environment.yml
```
- Activate your new conda environment:
```bash
conda activate CPIExtract
```
##### Option B: working without Conda
- Ensure the following dependencies are installed before proceeding:
```bash
pip install numpy pandas mysql-connector-python biomart pubchempy chembl-webresource-client
```
5. Set up your PYTHONPATH (Replace `/user_path_to/CPIExtract-main/cpiextract` with the appropriate path of the package in your local/remote machine.):
_On Linux/Mac_:
```bash
export PYTHONPATH="/user_path_to/CPIExtract-main/cpiextract":$PYTHONPATH
```
_On Windows shell_:
```bash
set PYTHONPATH="C:\\user_path_to\\CPIExtract-main\\cpiextract";%PYTHONPATH%
```
_On Powershell_:
```bash
$env:PYTHONPATH = "C:\\user_path_to\\CPIExtract-main\\cpiextract;" + $env:PYTHONPATH
```
#### Using Jupyter Notebooks
We provide several Jupyer Notebooks to simplify the databases' download and maintenance. To use these notebooks, follow these steps:
- Make sure you have the `jupyter` package installed.
```bash
pip install jupyter
```
- Start the Jupyter Kernel
a) If you are working on a local machine:
```bash
jupyter notebook --browser="browser_of_choice"
```
Or:
```bash
jupyter lab --browser="browser_of_choice"
```
Replace browser_of_choice with your preferred browser (e.g., chrome, firefox). The browser window should pop up automatically. If it doesn't, copy and paste the link provided in the terminal into your browser. The link should look something like this:
* http://localhost:8889/tree?token=5d4ebdddaf6cb1be76fd95c4dde891f24fd941da909129e6
b) If you are working on a remote machine:
```bash
jupyter notebook --no-browser
```
Then copy and paste the link provided in the terminal in your local browser of choice, it should look something like this:
* http://localhost:8888/?token=9feac8ff1d5ba3a86cf8c4309f4988e7db95f42d28fd7772
- Navigate to the selected notebook in the Jupyter Notebook interface and start executing the cells.
### Data Download
To operate the package, and try the examples it is necessary to have downloaded databases `.csv` and `.tsv` files either in a local directory or stored in a mySQL server as tables. The compressed preprocessed data necessary to reproduce the results in the manuscript are provided in subdirectory `data` - `Databases.zip`. This data is intended for use with the [Local Execution mode](#local-execution). Please make sure to download the `.zip` file separately and not with the whole GitHub directory.
Create a local folder, name it `data` and extract the files with the following code, which will save the databases in `data/Databases` subdirectory(Replace `/user_path_to/data/` with the appropriate path of the package in your local/remote machine):
_On Linux/Mac_:
```bash
cd /user_path_to/data/
mkdir -p Databases
unzip Databases.zip -d Databases/
```
_On Windows shell/Powershell_:
```bash
cd user_path_to\\data
mkdir Databases
tar -xf Databases.zip -C Databases\\
```
#### Data Update
Although the data used is up to date, each database periodically releases updated versions that will make the zipped data obsolete.
For this reason, we suggest periodically redownloading the databases to have the latest CPI information available.
We also strongly recommend preprocessing the databases to obtain significantly faster execution times. \
To ease this process, we provide two notebooks to download ([db_download.ipynb](db_download.ipynb)) and preprocess ([db_preprocessing.ipynb](db_preprocessing.ipynb)) the databases.
### SQL Server
Users can also load the databases into a mySQL server.
1. We suggest using [mySQL Workbench CE](https://dev.mysql.com/downloads/workbench/). Once set up, create a database schema named `cpie`.
2. (If the package has been installed with pip) \
Download the [`dbs_config.json`](data/dbs_config.json) and save it into the data folder.
3. Load the **downloaded and preprocessed** databases as tables into the SQL database, which can be done using the provided [SQL_load.ipynb](SQL_load.ipynb) notebook.
## Example execution
### Pipelines instantiation
The package allows the user to execute two pipelines, Compound-Proteins-Extraction (Comp2Prot) and the Protein-Compounds-Extraction (Prot2Comp). The Comp2Prot pipeline retrieves proteins interacting with the small molecule passed as input, while Prot2Comp returns compounds interacting with the input protein. Both pipelines comprise three phases: input data extraction, data filtering, and harmonization.
The package is designed to support multiple user scenarios based on different storage and software availability.
##### Option A: Local execution
When running the pipeline locally, it is essential to load the databases first. To do this, please refer to the example jupyter notebook `Comp2Prot_example.ipynb` and follow the instructions in cell `[2]: Load in Required Datasets`.
Before loading the data make sure you are in the parent directory of `data` or adjust `data_path` according to your setup.
```python
from cpiextract import Comp2Prot, Prot2Comp
import pandas as pd
import os
# Root data path
data_path = 'data/Databases/'
#Downloaded from BindingDB on 3/30/2023
file_path=os.path.join(data_path, 'BindingDB.csv')
BDB_data=pd.read_csv(file_path,sep=',',usecols=['CID', 'Ligand SMILES','Ligand InChI','BindingDB MonomerID','Ligand InChI Key','BindingDB Ligand Name','Target Name Assigned by Curator or DataSource','Target Source Organism According to Curator or DataSource','Ki (nM)','IC50 (nM)','Kd (nM)','EC50 (nM)','pH','Temp (C)','Curation/DataSource','UniProt (SwissProt) Entry Name of Target Chain','UniProt (SwissProt) Primary ID of Target Chain'],on_bad_lines='skip')
#Downloaded from STITCH on 2/22/2023
file_path=os.path.join(data_path, 'STITCH.tsv')
sttch_data=pd.read_csv(file_path,sep='\t')
#Downloaded from ChEMBL on 2/01/2024
file_path=os.path.join(data_path, 'ChEMBL.csv')
chembl_data=pd.read_csv(file_path,sep=',')
file_path=os.path.join(data_path, 'CTD.csv')
CTD_data=pd.read_csv(file_path,sep=',')
#Downloaded from DTC on 2/24/2023
file_path=os.path.join(data_path, 'DTC.csv')
DTC_data=pd.read_csv(file_path,sep=',',usecols=['CID', 'compound_id','standard_inchi_key','target_id','gene_names','wildtype_or_mutant','mutation_info','standard_type','standard_relation','standard_value','standard_units','activity_comment','pubmed_id','doc_type'])
#Downloaded from DrugBank on 3/2/2022
file_path=os.path.join(data_path, 'DB.csv')
DB_data=pd.read_csv(file_path, sep=',')
#Downloaded from DrugCentral on 2/25/2024
file_path=os.path.join(data_path, 'DrugCentral.csv')
DC_data=pd.read_csv(file_path, sep=',')
# Data stored in pandas dataframes
data = {
'chembl': chembl_data,
'bdb': BDB_data,
'stitch': sttch_data,
'ctd': CTD_data,
'dtc': DTC_data,
'db': DB_data,
'dc': DC_data
}
C2P = Comp2Prot(execution_mode='local', dbs=data)
P2C = Prot2Comp(execution_mode='local', dbs=data)
```
##### Option B: Server execution
The databases are stored on the mySQL server.
```python
from cpiextract import Comp2Prot, Prot2Comp
# Exmeplative dictionary containing the configuration info to connect to the mySQL server
info = {
"host": "XXX.XX.XX.XXX",
"user": "user",
"password": "password",
"database": "cpie",
}
C2P = Comp2Prot(execution_mode='server', server_info=info)
P2C = Prot2Comp(execution_mode='server', server_info=info)
```
### How to run the pipelines
Once instantiated, the user can choose between the functions `comp_interactions` or `comp_interactions_select` for Comp2Prot, and the functions `prot_interactions` or `prot_interactions_select` for Prot2Comp.
#### Comp2Prot
The function `comp_interactions` from Comp2Prot accepts the following parameters:
- `input_id` - the compound id
- `pChEMBL_thresh` - the minimum interaction pChEMBL value required to be added to the output file
- `stitch_stereo` - to select whether to consider the specific compound stereochemistry or group all stereoisomers interactions from STITCH
- `otp_biblio` - to select whether to include the *bibliography* data from OTP. This parameter is only available for Comp2Prot as OTP provides only known drug interactions for proteins
- `dtc_mutated` - to select whether also to consider interactions with mutated target proteins from DTC
- `dc_extra` - to select whether to include possibly non-Homo sapiens interactions
The output will include all the interactions found and a data frame containing the statements for all the datasets for the specific input compound.
```python
# Chlorpromazine InChIKey
comp_id = 'ZPEIMTDSQAKGNT-UHFFFAOYSA-N'
interactions, db_states = C2P.comp_interactions(input_id=comp_id, pChEMBL_thres=0, stitch_stereo=True, otp_biblio=False, dtc_mutated=False, dc_extra=False)
```
To extract interactions only from selected databases, use the alternate function specifying which databases to use in an underscore-separated string (to include all databases, which equates to using the previous function, use `'pc_chembl_bdb_stitch_ctd_dtc_otp_dc_db'`). In the following example, only four databases are used to limit the output size.
```python
# Chlorpromazine InChIKey
comp_id = 'ZPEIMTDSQAKGNT-UHFFFAOYSA-N'
# Interactions extracted from PubChem, ChEMBL, DB and DTC only.
interactions, db_states = C2P.comp_interactions_select(input_id=comp_id, selected_dbs='pc_chembl_db_dtc', pChEMBL_thres=0, stitch_stereo=True, otp_biblio=False, dtc_mutated=False, dc_extra=False)
```
#### Prot2Comp
Prot2Comp works similarly, with the exception that both functions only have the following additional parameters, as OTP will retrieve only known compounds interacting with the input protein:
- `pChEMBL_thresh` - the minimum interaction pChEMBL value required to be added to the output file
- `stitch_stereo` - to select whether to consider the specific compound stereochemistry or group all stereoisomers interactions from STITCH
- `dtc_mutated` - to select whether also to consider interactions with mutated target proteins from DTC
- `dc_extra` - to select whether to include possibly non-Homo sapiens interactions
Here are two examples demonstrating the use of the two functions from Prot2Comp:
```python
# HGNC symbol for Kallikrein-1
prot_id = 'KLK1'
interactions, db_states = P2C.prot_interactions(input_id=prot_id, pChEMBL_thres=0, stitch_stereo=True, dtc_mutated=False, dc_extra=False)
# Interactions extracted from PubChem, ChEMBL, DB and DTC only.
interactions, db_states = P2C.prot_interactions_select(input_id=prot_id, selected_dbs='pc_chembl_db_dtc', pChEMBL_thres=0, stitch_stereo=True, dtc_mutated=False, dc_extra=False)
```
## Package Structure
Root folder organization (```__init__.py``` files removed for simplicity):
```plaintext
│ .gitignore
│ environment.yml // current conda env settings used
│ README.md
│ Comp2Prot_example.ipynb // Comp2Prot pipeline testing notebook
│ Prot2Comp_example.ipynb // Prot2Comp pipeline testing notebook
│
├───data // data storage location
│ ├───dbs_config.json // file with databases configuration for the mySQL server
│ ├───input // pipeline input data location
│ │ ├───db_compounds.csv // DrugBank compounds example dataset
│ │ └───db_proteins.csv // DrugBank protein example dataset
│ └───output // pipeline output data location
│ ├───C2P.csv // Comp2Prot output file for db_compounds.csv
│ └───P2C.csv // Prot2Comp output file for db_proteins.csv
│
└───cpiextract
│
├───data_manager
│ ├───APIManager.py // to extract raw data from databases' APIs
│ ├───DataManager.py // Abstract data manager class
│ ├───LocalManager.py // to extract raw data from downloaded databases
│ └───SQLManager.py // to extract raw data from SQL server
│
├───databases
│ ├───BindingDB.py // BDB database class
│ ├───ChEMBL.py // ChEMBLB database class
│ ├───CTD.py // CTD database class
│ ├───Database.py // Abstract database class
│ ├───DrugBank.py // DB database class
│ ├───DrugCentral.py // DC database class
│ ├───DTC.py // DTC database class
│ ├───OTP.py // OTP database class
│ ├───PubChem.py // PubChem database class
│ └───Stitch.py // STITCH database class
│
├───pipelines
│ ├───Comp2Prot.py // Comp2Prot pipeline class
│ ├───Pipeline // Abstract pipeline class
│ └───Prot2Comp.py // Prot2Comp pipeline class
│
├───servers
│ ├───BiomartServer.py // to connect to Biomart API
│ ├───ChEMBLServer.py // to connect to ChEMBL API
│ └───PubChemServer.py // to connect to PubChem API
│
├───sql_server
│ └───sql_connection.py // to connect to the SQL server
│
└───utils
├───helper.py // helper functions and classes
└───identifiers.py // functions to extract identifiers for compounds and proteins
```
## Further information
- Details about each function (what is it used for, what are the input parameters, the possible values of the input parameters, what is the output) from the pipeline are available in the `cpiextract` folder, in the comments before each class function.
- An example of the use of the implemented functions is available in the jupyter notebooks [Comp2Prot_example.ipynb](Comp2Prot_example.ipynb) and [Prot2Comp_example.ipynb](Prot2Comp_example.ipynb), which can be executed to test the proper installation of the package and it's functionalities.
## License
This project is licensed under the terms of the MIT license.
Raw data
{
"_id": null,
"home_page": null,
"name": "cpiextract",
"maintainer": null,
"docs_url": null,
"requires_python": null,
"maintainer_email": null,
"keywords": "data-science, bioinformatics, cheminformatics, proteins, network-science, data-harmonization, binding-affinity, chemical-compounds",
"author": "Andrea Piras, Shi Chenghao, Michael Sebek, Gordana Ispirova, Giulia Menichetti",
"author_email": "giulia.menichetti@channing.harvard.edu",
"download_url": "https://files.pythonhosted.org/packages/e3/a3/103d190603c976f5988e936e0676a5953bb9172b8d1e5666fbb40e0c8252/cpiextract-0.1.3.tar.gz",
"platform": null,
"description": "# CPIExtract (Compound-Protein Interaction Extract)\n## A software package to collect and harmonize small molecule and protein interactions\n#### Authors: Andrea Piras, Shi Chenghao, Michael Sebek, Gordana Ispirova, Giulia Menichetti (giulia.menichetti@channing.harvard.edu)\n\n## Introduction\n\nThe binding interactions between small molecules and proteins are the basis of cellular functions.\nYet, experimental data available regarding compound-protein interaction (CPI) is not harmonized into a single\nentity but rather scattered across multiple institutions, each maintaining databases with different formats.\nExtracting information from these multiple sources remains challenging due to data heterogeneity.\n\nCPIExtract interactively extracts, filters and harmonizes CPI data from 9 databases, providing the output in tabular format (csv).\\\nThe package provides two separate pipelines:\n- Comp2Prot: Extract protein target interactions for compounds provided as input\n- Prot2Comp: Extract compound interactions for proteins provided as input\n \n### Comp2Prot\n\nThe pipeline extracts compound information from an input identifier using the [PubChem REST API](https://pubchempy.readthedocs.io/en/latest/), accessed with the [`PubChemPy`](https://github.com/mcs07/PubChemPy) Python package. Then, it uses the information to perform compound matching for each database, extracting raw interaction data. This data is then filtered for each database with a custom filter, ensuring only high-quality interactions are returned in the output. Finally, protein data are extracted using the [`Biomart`](https://github.com/sebriois/biomart) Python package, harmonizing the information from the 9 databases. The collected output is finally returned to the user in a `.csv` file. \\\nAn exemplary pipeline workflow is depicted in the figure below. An equivalent output network is also shown.\n\n\n\n\n### Prot2Comp\n\nThe pipeline follows a workflow similar to the other pipeline. It extracts protein information from an input identifier using the Biomart Python package. It performs the same database matching and filtering and then harmonizes the interaction data extracting compounds information with the PubChemPy Python package. The output is finally returned to the user in a `.csv` file. \n\n## Getting started \n\n### Setting up a work environment\n\n#### I. With installing the package\n\n1. Installing the necessary dependencies:\n \n \n##### Option A: working with Conda\n\nWorking with Conda is recommended, but it is not essential. If you choose to work with Conda, these are the steps you need to take:\n\n- Ensure you have Conda installed.\n\n- Download the `environment.yml` and navigate to the directory of your local/remote machine where the file is located.\n\n- Create a new conda environment with the `environment.yml` file:\n\n ```bash\n conda env create -f environment.yml\n ```\n \n- Activate your new conda environment:\n\n ```bash\n conda activate CPIExtract\n ```\n \n##### Option B: working without Conda\n\n- Ensure the following dependencies are installed before proceeding:\n\n ```bash\n pip install numpy pandas mysql-connector-python biomart pubchempy chembl-webresource-client \n ```\n\n2. Install the package:\n\n ```bash\n pip install cpiextract\n ```\n\n#### II. Without installing the package\n\n1. Ensure you have Python installed.\n \n2. Copy the project to your local or remote machine:\n\n ```bash\n git clone https://github.com/menicgiulia/CPIExtract.git\n ```\n3. Navigate to the project directory:\n\n ```bash\n cd CPIExtract-main\n ```\n\n4. Installing the necessary dependencies:\n \n \n##### Option A: working with Conda\n\nWorking with Conda is recommended, but it is not essential. If you choose to work with Conda, these are the steps you need to take:\n\n- Ensure you have Conda installed.\n\n- Create a new conda environment with the `environment.yml` file:\n\n ```bash\n conda env create -f environment.yml\n ```\n\n- Activate your new conda environment:\n\n ```bash\n conda activate CPIExtract\n ```\n \n##### Option B: working without Conda\n\n- Ensure the following dependencies are installed before proceeding:\n\n ```bash\n pip install numpy pandas mysql-connector-python biomart pubchempy chembl-webresource-client\n ```\n \n5. Set up your PYTHONPATH (Replace `/user_path_to/CPIExtract-main/cpiextract` with the appropriate path of the package in your local/remote machine.):\n\n _On Linux/Mac_:\n \n ```bash\n export PYTHONPATH=\"/user_path_to/CPIExtract-main/cpiextract\":$PYTHONPATH\n ```\n \n _On Windows shell_:\n\n ```bash\n set PYTHONPATH=\"C:\\\\user_path_to\\\\CPIExtract-main\\\\cpiextract\";%PYTHONPATH%\n ```\n \n _On Powershell_:\n\n ```bash\n $env:PYTHONPATH = \"C:\\\\user_path_to\\\\CPIExtract-main\\\\cpiextract;\" + $env:PYTHONPATH\n ```\n \n#### Using Jupyter Notebooks\n\nWe provide several Jupyer Notebooks to simplify the databases' download and maintenance. To use these notebooks, follow these steps:\n\n- Make sure you have the `jupyter` package installed.\n\n ```bash\n pip install jupyter\n ```\n \n- Start the Jupyter Kernel\n\n a) If you are working on a local machine:\n\n ```bash\n jupyter notebook --browser=\"browser_of_choice\"\n ```\n \n Or:\n\n ```bash\n jupyter lab --browser=\"browser_of_choice\"\n ``` \n \n Replace browser_of_choice with your preferred browser (e.g., chrome, firefox). The browser window should pop up automatically. If it doesn't, copy and paste the link provided in the terminal into your browser. The link should look something like this:\n\n \n * http://localhost:8889/tree?token=5d4ebdddaf6cb1be76fd95c4dde891f24fd941da909129e6\n \n \n b) If you are working on a remote machine:\n \n ```bash\n jupyter notebook --no-browser\n ```\n \n Then copy and paste the link provided in the terminal in your local browser of choice, it should look something like this:\n\n \n * http://localhost:8888/?token=9feac8ff1d5ba3a86cf8c4309f4988e7db95f42d28fd7772\n \n \n- Navigate to the selected notebook in the Jupyter Notebook interface and start executing the cells.\n\n### Data Download\n\nTo operate the package, and try the examples it is necessary to have downloaded databases `.csv` and `.tsv` files either in a local directory or stored in a mySQL server as tables. The compressed preprocessed data necessary to reproduce the results in the manuscript are provided in subdirectory `data` - `Databases.zip`. This data is intended for use with the [Local Execution mode](#local-execution). Please make sure to download the `.zip` file separately and not with the whole GitHub directory.\n\nCreate a local folder, name it `data` and extract the files with the following code, which will save the databases in `data/Databases` subdirectory(Replace `/user_path_to/data/` with the appropriate path of the package in your local/remote machine):\n\n _On Linux/Mac_:\n \n ```bash\n cd /user_path_to/data/\n mkdir -p Databases\n unzip Databases.zip -d Databases/\n ```\n \n _On Windows shell/Powershell_:\n\n ```bash\n cd user_path_to\\\\data\n mkdir Databases\n tar -xf Databases.zip -C Databases\\\\\n ```\n\n#### Data Update\n\nAlthough the data used is up to date, each database periodically releases updated versions that will make the zipped data obsolete. \nFor this reason, we suggest periodically redownloading the databases to have the latest CPI information available.\nWe also strongly recommend preprocessing the databases to obtain significantly faster execution times. \\\nTo ease this process, we provide two notebooks to download ([db_download.ipynb](db_download.ipynb)) and preprocess ([db_preprocessing.ipynb](db_preprocessing.ipynb)) the databases.\n\n### SQL Server\n\nUsers can also load the databases into a mySQL server. \n\n1. We suggest using [mySQL Workbench CE](https://dev.mysql.com/downloads/workbench/). Once set up, create a database schema named `cpie`.\n2. (If the package has been installed with pip) \\\nDownload the [`dbs_config.json`](data/dbs_config.json) and save it into the data folder.\n3. Load the **downloaded and preprocessed** databases as tables into the SQL database, which can be done using the provided [SQL_load.ipynb](SQL_load.ipynb) notebook.\n\n## Example execution\n\n### Pipelines instantiation\n\nThe package allows the user to execute two pipelines, Compound-Proteins-Extraction (Comp2Prot) and the Protein-Compounds-Extraction (Prot2Comp). The Comp2Prot pipeline retrieves proteins interacting with the small molecule passed as input, while Prot2Comp returns compounds interacting with the input protein. Both pipelines comprise three phases: input data extraction, data filtering, and harmonization.\nThe package is designed to support multiple user scenarios based on different storage and software availability.\n\n##### Option A: Local execution\n\nWhen running the pipeline locally, it is essential to load the databases first. To do this, please refer to the example jupyter notebook `Comp2Prot_example.ipynb` and follow the instructions in cell `[2]: Load in Required Datasets`.\nBefore loading the data make sure you are in the parent directory of `data` or adjust `data_path` according to your setup.\n\n```python \nfrom cpiextract import Comp2Prot, Prot2Comp\nimport pandas as pd\nimport os\n\n# Root data path\ndata_path = 'data/Databases/'\n\n#Downloaded from BindingDB on 3/30/2023\nfile_path=os.path.join(data_path, 'BindingDB.csv')\nBDB_data=pd.read_csv(file_path,sep=',',usecols=['CID', 'Ligand SMILES','Ligand InChI','BindingDB MonomerID','Ligand InChI Key','BindingDB Ligand Name','Target Name Assigned by Curator or DataSource','Target Source Organism According to Curator or DataSource','Ki (nM)','IC50 (nM)','Kd (nM)','EC50 (nM)','pH','Temp (C)','Curation/DataSource','UniProt (SwissProt) Entry Name of Target Chain','UniProt (SwissProt) Primary ID of Target Chain'],on_bad_lines='skip')\n\n#Downloaded from STITCH on 2/22/2023\nfile_path=os.path.join(data_path, 'STITCH.tsv')\nsttch_data=pd.read_csv(file_path,sep='\\t')\n\n#Downloaded from ChEMBL on 2/01/2024\nfile_path=os.path.join(data_path, 'ChEMBL.csv')\nchembl_data=pd.read_csv(file_path,sep=',')\n\nfile_path=os.path.join(data_path, 'CTD.csv')\nCTD_data=pd.read_csv(file_path,sep=',')\n\n#Downloaded from DTC on 2/24/2023\nfile_path=os.path.join(data_path, 'DTC.csv')\nDTC_data=pd.read_csv(file_path,sep=',',usecols=['CID', 'compound_id','standard_inchi_key','target_id','gene_names','wildtype_or_mutant','mutation_info','standard_type','standard_relation','standard_value','standard_units','activity_comment','pubmed_id','doc_type'])\n\n#Downloaded from DrugBank on 3/2/2022\nfile_path=os.path.join(data_path, 'DB.csv')\nDB_data=pd.read_csv(file_path, sep=',')\n\n#Downloaded from DrugCentral on 2/25/2024\nfile_path=os.path.join(data_path, 'DrugCentral.csv')\nDC_data=pd.read_csv(file_path, sep=',')\n\n# Data stored in pandas dataframes\ndata = {\n 'chembl': chembl_data,\n 'bdb': BDB_data,\n 'stitch': sttch_data,\n 'ctd': CTD_data,\n 'dtc': DTC_data,\n 'db': DB_data,\n 'dc': DC_data\n}\n\nC2P = Comp2Prot(execution_mode='local', dbs=data)\nP2C = Prot2Comp(execution_mode='local', dbs=data)\n```\n\n##### Option B: Server execution\n\nThe databases are stored on the mySQL server. \n\n```python\nfrom cpiextract import Comp2Prot, Prot2Comp\n\n# Exmeplative dictionary containing the configuration info to connect to the mySQL server\ninfo = {\n \"host\": \"XXX.XX.XX.XXX\",\n \"user\": \"user\",\n \"password\": \"password\",\n \"database\": \"cpie\",\n}\n\nC2P = Comp2Prot(execution_mode='server', server_info=info)\nP2C = Prot2Comp(execution_mode='server', server_info=info)\n```\n### How to run the pipelines\n\nOnce instantiated, the user can choose between the functions `comp_interactions` or `comp_interactions_select` for Comp2Prot, and the functions `prot_interactions` or `prot_interactions_select` for Prot2Comp. \n\n#### Comp2Prot\n\nThe function `comp_interactions` from Comp2Prot accepts the following parameters:\n\n- `input_id` - the compound id\n- `pChEMBL_thresh` - the minimum interaction pChEMBL value required to be added to the output file\n- `stitch_stereo` - to select whether to consider the specific compound stereochemistry or group all stereoisomers interactions from STITCH\n- `otp_biblio` - to select whether to include the *bibliography* data from OTP. This parameter is only available for Comp2Prot as OTP provides only known drug interactions for proteins\n- `dtc_mutated` - to select whether also to consider interactions with mutated target proteins from DTC\n- `dc_extra` - to select whether to include possibly non-Homo sapiens interactions\n\nThe output will include all the interactions found and a data frame containing the statements for all the datasets for the specific input compound.\n\n```python\n# Chlorpromazine InChIKey\ncomp_id = 'ZPEIMTDSQAKGNT-UHFFFAOYSA-N'\n\ninteractions, db_states = C2P.comp_interactions(input_id=comp_id, pChEMBL_thres=0, stitch_stereo=True, otp_biblio=False, dtc_mutated=False, dc_extra=False)\n```\n\nTo extract interactions only from selected databases, use the alternate function specifying which databases to use in an underscore-separated string (to include all databases, which equates to using the previous function, use `'pc_chembl_bdb_stitch_ctd_dtc_otp_dc_db'`). In the following example, only four databases are used to limit the output size.\n\n```python\n# Chlorpromazine InChIKey\ncomp_id = 'ZPEIMTDSQAKGNT-UHFFFAOYSA-N'\n\n# Interactions extracted from PubChem, ChEMBL, DB and DTC only.\ninteractions, db_states = C2P.comp_interactions_select(input_id=comp_id, selected_dbs='pc_chembl_db_dtc', pChEMBL_thres=0, stitch_stereo=True, otp_biblio=False, dtc_mutated=False, dc_extra=False)\n```\n\n#### Prot2Comp\n\nProt2Comp works similarly, with the exception that both functions only have the following additional parameters, as OTP will retrieve only known compounds interacting with the input protein:\n\n- `pChEMBL_thresh` - the minimum interaction pChEMBL value required to be added to the output file\n- `stitch_stereo` - to select whether to consider the specific compound stereochemistry or group all stereoisomers interactions from STITCH\n- `dtc_mutated` - to select whether also to consider interactions with mutated target proteins from DTC\n- `dc_extra` - to select whether to include possibly non-Homo sapiens interactions\n\nHere are two examples demonstrating the use of the two functions from Prot2Comp:\n\n```python\n# HGNC symbol for Kallikrein-1\nprot_id = 'KLK1'\n\ninteractions, db_states = P2C.prot_interactions(input_id=prot_id, pChEMBL_thres=0, stitch_stereo=True, dtc_mutated=False, dc_extra=False)\n\n# Interactions extracted from PubChem, ChEMBL, DB and DTC only.\ninteractions, db_states = P2C.prot_interactions_select(input_id=prot_id, selected_dbs='pc_chembl_db_dtc', pChEMBL_thres=0, stitch_stereo=True, dtc_mutated=False, dc_extra=False)\n```\n\n## Package Structure\n\nRoot folder organization (```__init__.py``` files removed for simplicity):\n\n```plaintext\n\u2502 .gitignore\n\u2502 environment.yml // current conda env settings used\n\u2502 README.md\n\u2502 Comp2Prot_example.ipynb // Comp2Prot pipeline testing notebook\n\u2502 Prot2Comp_example.ipynb // Prot2Comp pipeline testing notebook\n\u2502\n\u251c\u2500\u2500\u2500data // data storage location\n\u2502 \u251c\u2500\u2500\u2500dbs_config.json // file with databases configuration for the mySQL server\n\u2502 \u251c\u2500\u2500\u2500input // pipeline input data location\n\u2502 \u2502 \u251c\u2500\u2500\u2500db_compounds.csv // DrugBank compounds example dataset\n\u2502 \u2502 \u2514\u2500\u2500\u2500db_proteins.csv // DrugBank protein example dataset\n\u2502 \u2514\u2500\u2500\u2500output // pipeline output data location\n\u2502 \u251c\u2500\u2500\u2500C2P.csv // Comp2Prot output file for db_compounds.csv\n\u2502 \u2514\u2500\u2500\u2500P2C.csv // Prot2Comp output file for db_proteins.csv\n\u2502\n\u2514\u2500\u2500\u2500cpiextract\n \u2502 \n \u251c\u2500\u2500\u2500data_manager \n \u2502 \u251c\u2500\u2500\u2500APIManager.py // to extract raw data from databases' APIs\n \u2502 \u251c\u2500\u2500\u2500DataManager.py // Abstract data manager class\n \u2502 \u251c\u2500\u2500\u2500LocalManager.py // to extract raw data from downloaded databases\n \u2502 \u2514\u2500\u2500\u2500SQLManager.py // to extract raw data from SQL server\n \u2502\n \u251c\u2500\u2500\u2500databases\n \u2502 \u251c\u2500\u2500\u2500BindingDB.py // BDB database class\n \u2502 \u251c\u2500\u2500\u2500ChEMBL.py // ChEMBLB database class\n \u2502 \u251c\u2500\u2500\u2500CTD.py // CTD database class\n \u2502 \u251c\u2500\u2500\u2500Database.py // Abstract database class\n \u2502 \u251c\u2500\u2500\u2500DrugBank.py // DB database class\n \u2502 \u251c\u2500\u2500\u2500DrugCentral.py // DC database class\n \u2502 \u251c\u2500\u2500\u2500DTC.py // DTC database class\n \u2502 \u251c\u2500\u2500\u2500OTP.py // OTP database class\n \u2502 \u251c\u2500\u2500\u2500PubChem.py // PubChem database class\n \u2502 \u2514\u2500\u2500\u2500Stitch.py // STITCH database class\n \u2502\n \u251c\u2500\u2500\u2500pipelines \n \u2502 \u251c\u2500\u2500\u2500Comp2Prot.py // Comp2Prot pipeline class\n \u2502 \u251c\u2500\u2500\u2500Pipeline // Abstract pipeline class\n \u2502 \u2514\u2500\u2500\u2500Prot2Comp.py // Prot2Comp pipeline class\n \u2502\n \u251c\u2500\u2500\u2500servers \n \u2502 \u251c\u2500\u2500\u2500BiomartServer.py // to connect to Biomart API\n \u2502 \u251c\u2500\u2500\u2500ChEMBLServer.py // to connect to ChEMBL API\n \u2502 \u2514\u2500\u2500\u2500PubChemServer.py // to connect to PubChem API\n \u2502\n \u251c\u2500\u2500\u2500sql_server \n \u2502 \u2514\u2500\u2500\u2500sql_connection.py // to connect to the SQL server\n \u2502\n \u2514\u2500\u2500\u2500utils \n \u251c\u2500\u2500\u2500helper.py // helper functions and classes\n \u2514\u2500\u2500\u2500identifiers.py // functions to extract identifiers for compounds and proteins\n```\n\n## Further information\n\n- Details about each function (what is it used for, what are the input parameters, the possible values of the input parameters, what is the output) from the pipeline are available in the `cpiextract` folder, in the comments before each class function. \n- An example of the use of the implemented functions is available in the jupyter notebooks [Comp2Prot_example.ipynb](Comp2Prot_example.ipynb) and [Prot2Comp_example.ipynb](Prot2Comp_example.ipynb), which can be executed to test the proper installation of the package and it's functionalities.\n\n## License\n\nThis project is licensed under the terms of the MIT license.\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "CPIExtract is a software package to collect and harmonize small molecule and protein interactions.",
"version": "0.1.3",
"project_urls": null,
"split_keywords": [
"data-science",
" bioinformatics",
" cheminformatics",
" proteins",
" network-science",
" data-harmonization",
" binding-affinity",
" chemical-compounds"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "504754bb779a5fc9faea23ba9619feebcdc2876b06e71397013c97f700c84a74",
"md5": "471c80d0fa88c6f5d3da5ea5cc40d152",
"sha256": "749203bf6a38ffebc2cda808fe7d85f9a72d3ed0d284282ab06ff7216d3320dc"
},
"downloads": -1,
"filename": "cpiextract-0.1.3-py3-none-any.whl",
"has_sig": false,
"md5_digest": "471c80d0fa88c6f5d3da5ea5cc40d152",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": null,
"size": 57400,
"upload_time": "2024-06-21T13:17:58",
"upload_time_iso_8601": "2024-06-21T13:17:58.016102Z",
"url": "https://files.pythonhosted.org/packages/50/47/54bb779a5fc9faea23ba9619feebcdc2876b06e71397013c97f700c84a74/cpiextract-0.1.3-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "e3a3103d190603c976f5988e936e0676a5953bb9172b8d1e5666fbb40e0c8252",
"md5": "aa563b599607743b9bb2d56a7396168c",
"sha256": "e6f3157404d10c96acf4ba98a4a592594b393310cec8ad44feb8b6ac6456fe08"
},
"downloads": -1,
"filename": "cpiextract-0.1.3.tar.gz",
"has_sig": false,
"md5_digest": "aa563b599607743b9bb2d56a7396168c",
"packagetype": "sdist",
"python_version": "source",
"requires_python": null,
"size": 44804,
"upload_time": "2024-06-21T13:17:59",
"upload_time_iso_8601": "2024-06-21T13:17:59.174439Z",
"url": "https://files.pythonhosted.org/packages/e3/a3/103d190603c976f5988e936e0676a5953bb9172b8d1e5666fbb40e0c8252/cpiextract-0.1.3.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-06-21 13:17:59",
"github": false,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"lcname": "cpiextract"
}
