
> [!TIP]
> This project complements the __Differential Privacy with AI & ML__ project available in the [repository](https://github.com/dahmansphi/differential_privacy_with_ai_and_ml). To fully grasp the concept, make sure to read both documentations.
# About the Package
## Author's Words
Welcome to the first edition of the Disguise Data Tool official documentation. I am Deniz Dahman, Ph.D., the creator of the [BireyselValue](https://github.com/dahmansphi/bireyselvalue_v1) algorithm and the author of this package. In the following section, you will find a brief introduction to the principal idea of the __disguisedata__ tool, along with a reference to the academic publication on the method and its mathematical foundations. Before proceeding, I would like to inform you that I have conducted this work as an independent scientist without any funding or similar support. I am dedicated to continuing and seeking further improvements on the proposed method at all costs. If you wish to contribute in any way to this work, please find further details in the contributing section.
## Contributing
If you wish to support the creator of this project, you might want to explore possible ways on:
> `Thank you for your willingness to contribute in any way possible. You can check links below for more information on how to get involved.` :
1. view options to subscribe on [Dahman's Phi Services Website](https://dahmansphi.com/subscriptions/)
2. subscribe to this channel [Dahman's Phi Services](https://www.youtube.com/@dahmansphi)
3. you can support on [patreon](https://patreon.com/user?u=118924481)
If you prefer *any other way of contribution*, please feel free to contact me directly on [contact](https://dahmansphi.com/contact/).
*Thank you*
# Introduction
## History and Purpose of Synthetic Data
The concept of synthetic data has roots in scientific modeling and simulations, dating back to the early 20th century. For instance, audio and voice synthesis research began in the 1930s. The development of software synthesizers in the 1970s marked a significant advancement in creating synthetic data. In 1993, the idea of fully synthetic data for privacy-preserving statistical analysis was introduced to the research community. Today, synthetic data is extensively used in various fields, including healthcare, finance, and defense, to train AI models and conduct simulations. More importantly, synthetic data continues to evolve, offering innovative solutions to data scarcity, privacy, and bias challenges in the AI and machine learning landscape.
Synthetic data serves multiple purposes. It enhances AI models, safeguards sensitive information, reduces bias, and offers an alternative when real-world data is scarce or unavailable:
- [x] __Training AI Models__: Synthetic data is widely used to train machine learning models, especially when real-world data is scarce or sensitive. It helps in creating diverse datasets that improve model accuracy and robustness,
- [x] **Privacy Protection:** By using synthetic data, organizations can avoid privacy issues associated with real data, such as patient information in healthcare,
- [x] **Testing and Validation:** Synthetic data allows for extensive testing and validation of systems without the need for real data, which might be difficult to obtain or use due to privacy concerns.
- [x] **Testing and Validation:** Synthetic data allows for extensive testing and validation of systems without the need for real data, which might be difficult to obtain or use due to privacy concerns.
- [x] **Bias Reduction:** It helps in reducing biases in datasets, ensuring that AI models are trained on balanced and representative data.
## disguisedata __version__1.0

There are numerous tools available to generate synthetic data using various techniques. This is where I introduce the __disguisedata__ tool. This tool helps to disguise data based on a mathematical foundational concept. In particular, it relies on two important indicators in the original dataset:
1. __The norm__: Initially, it captures the general norm of the dataset, involving every entry in the set. This norm is then used to scale the dataset to a range of values. It is considered the **secret key** used later to convert the synthetic data into the same scale as the original.
2. __The Geometrical Shape of a Data Point__: The second crucial indicator for the **disguisedata** method is the geometric shape of a data point in the original dataset. Each point can be represented as a right-angled triangle, which can be scaled up or down. Every point along the hypotenuse line of the triangle represents a potential replica of the original point. The accompanying figure demonstrates this concept.
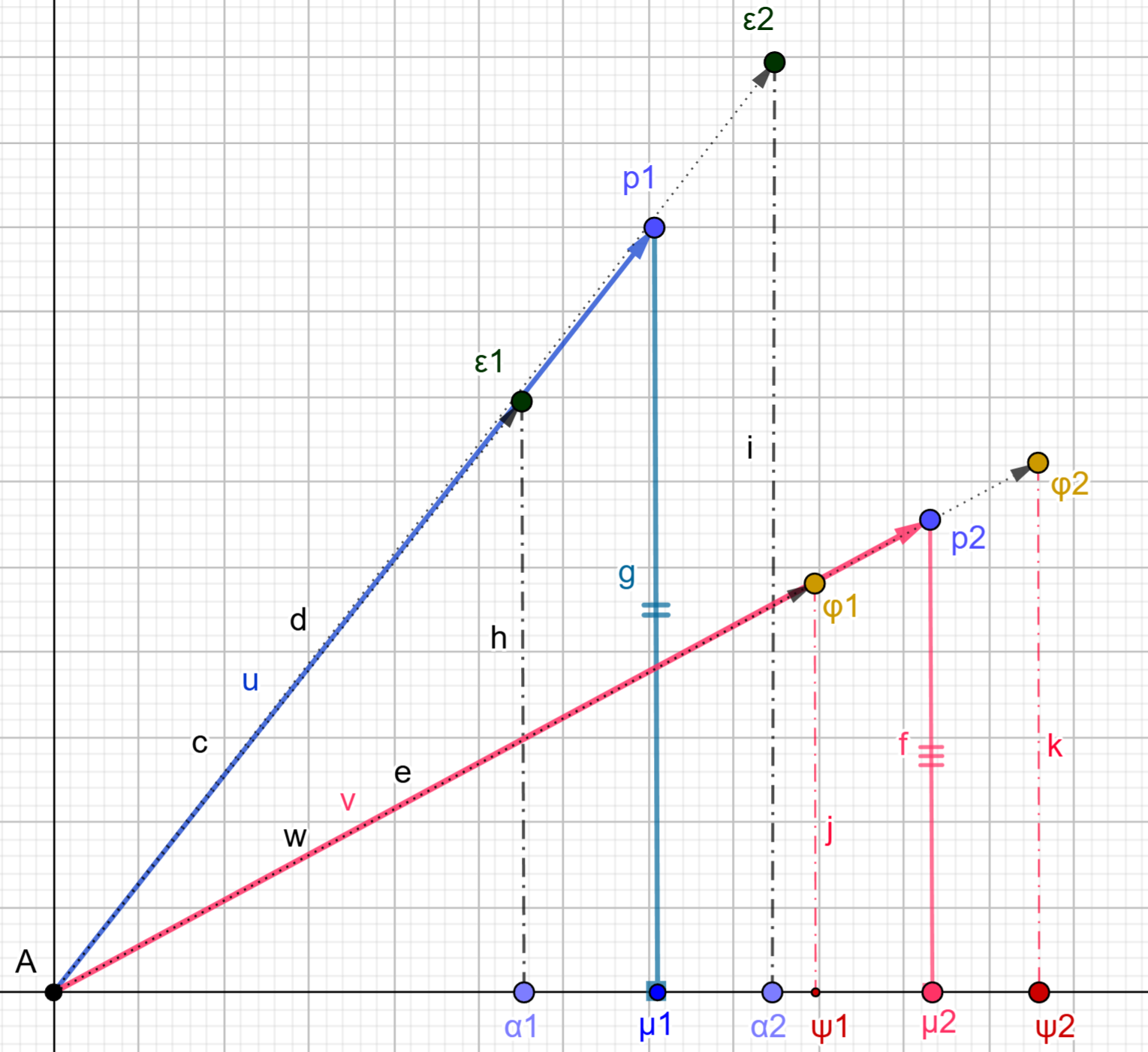
> [!IMPORTANT]
> **This tool demonstrates the proposed method solely for educational purposes. The author provides no warranty of any kind, including the warranty of design, merchantability, and fitness for a particular purpose**.
# Installation
> [!TIP]
> The simulation using __disguisedata__ was conducted on three datasets, which are referenced in the section below.
## Data Availability
1. Breast Cancer Wisconsin (Diagnostic) Dataset available in [UCI Machine Learning Repository] at https://archive.ics.uci.edu/dataset/17/breast+cancer+wisconsin+diagnostic , reference (Street 1993)
2. The Dry Bean Dataset available in [UCI Machine Learning Repository] at https://doi.org/10.24432/C50S4B , reference (Koklu 2020)
## Install disguisedata
to install the package all what you have to do:
```
pip install disguisedata==1.0.4
```
You should then be able to use the package. It might be a good idea to confirm the installation to ensure everything is set up correctly.
```
pip show disguisedata
```
The result then shall be as:
```
Name: disguisedata
Version: 1.0.4
Summary: A tiny tool for generating synthetic data from the original one
Home-page: https://github.com/dahmansphi/disguisedata
Author: Deniz Dahman's, Ph.D.
Author-email: dahmansphi@gmail.com
```
> [!IMPORTANT]
> **Sometimes, the `seaborn` library isn't installed during setup. If that's the case, you'll need to install it manually.**
## Employ the disguisedata -**Conditions**
> [!IMPORTANT]
> It's mandatory to provide the instance of the class with the **NumPy** array of the original dataset, which does not include the **y** feature or the target variable.
## Detour in the disguisedata package- Build-in
Once your installation is complete and all conditions are met, you may want to explore the built-in functions of the `disguisedata` package to understand each one. Essentially, you can create an instance from the `disguisedata` class as follows:
```
from disguisedata.disguisedata import Disguisedata
inst = Disguisedata()
```
Now this instance offers you access to the built-in functions that you need. Here is a screenshot:

Once you have the **disguisedata** instance, follow these steps to obtain the new disguised data:
### Control and Get the data format:
The first function you want to employ is `feedDs` using:
```
data = inst.feedDs(ds=ds)
```
This function takes one argument, which is the NumPy dataset, and it controls the conditions and returns a formatted, scaled dataset that is ready for the action of disguise.
### Acquire two distinct variants of disguised synthetic data.:
The function `discover_effect` allows you to explore how the disguised data differs from the original data. It is called using:
```
setData = inst.discover_effect(data=data, effect=effect)
```
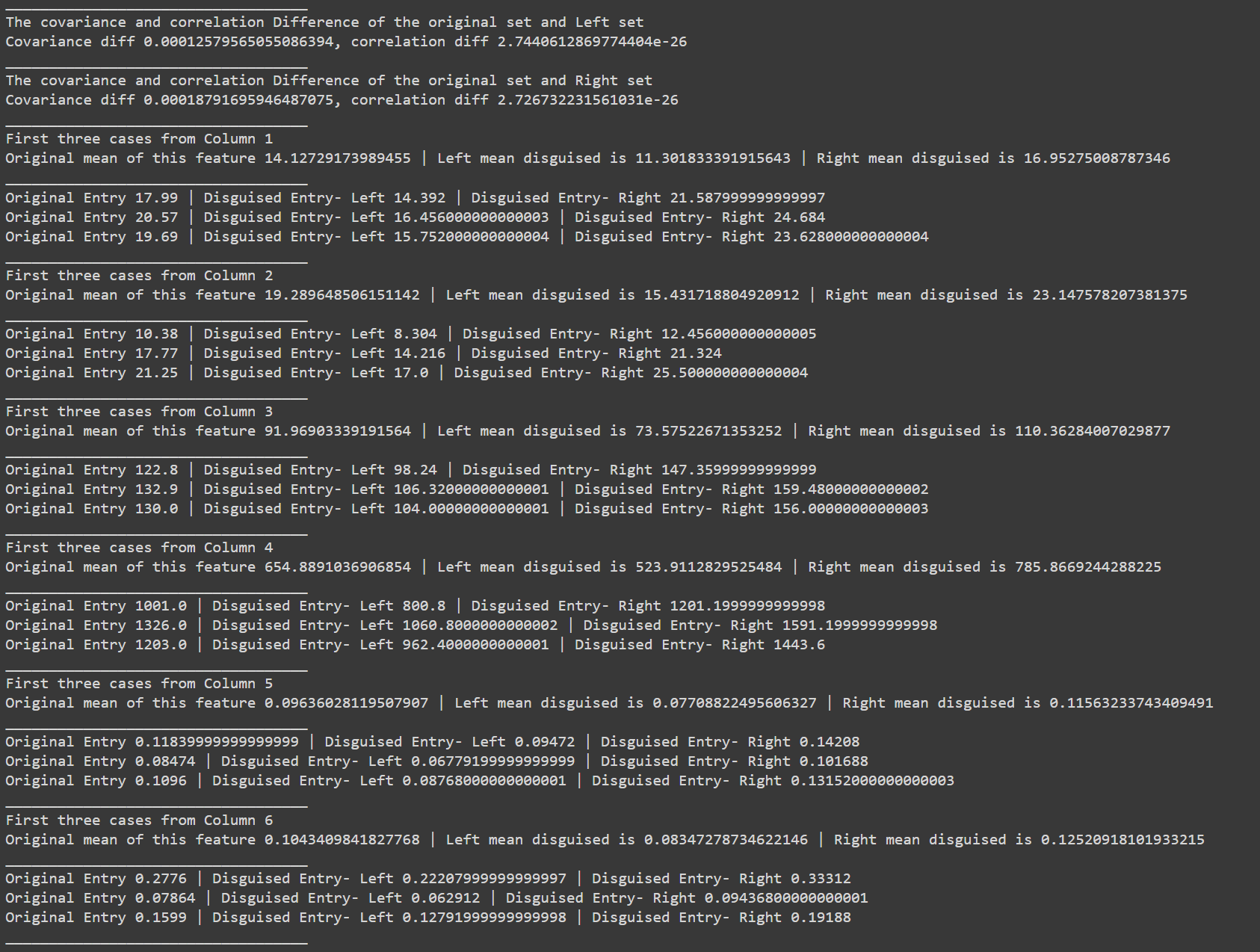
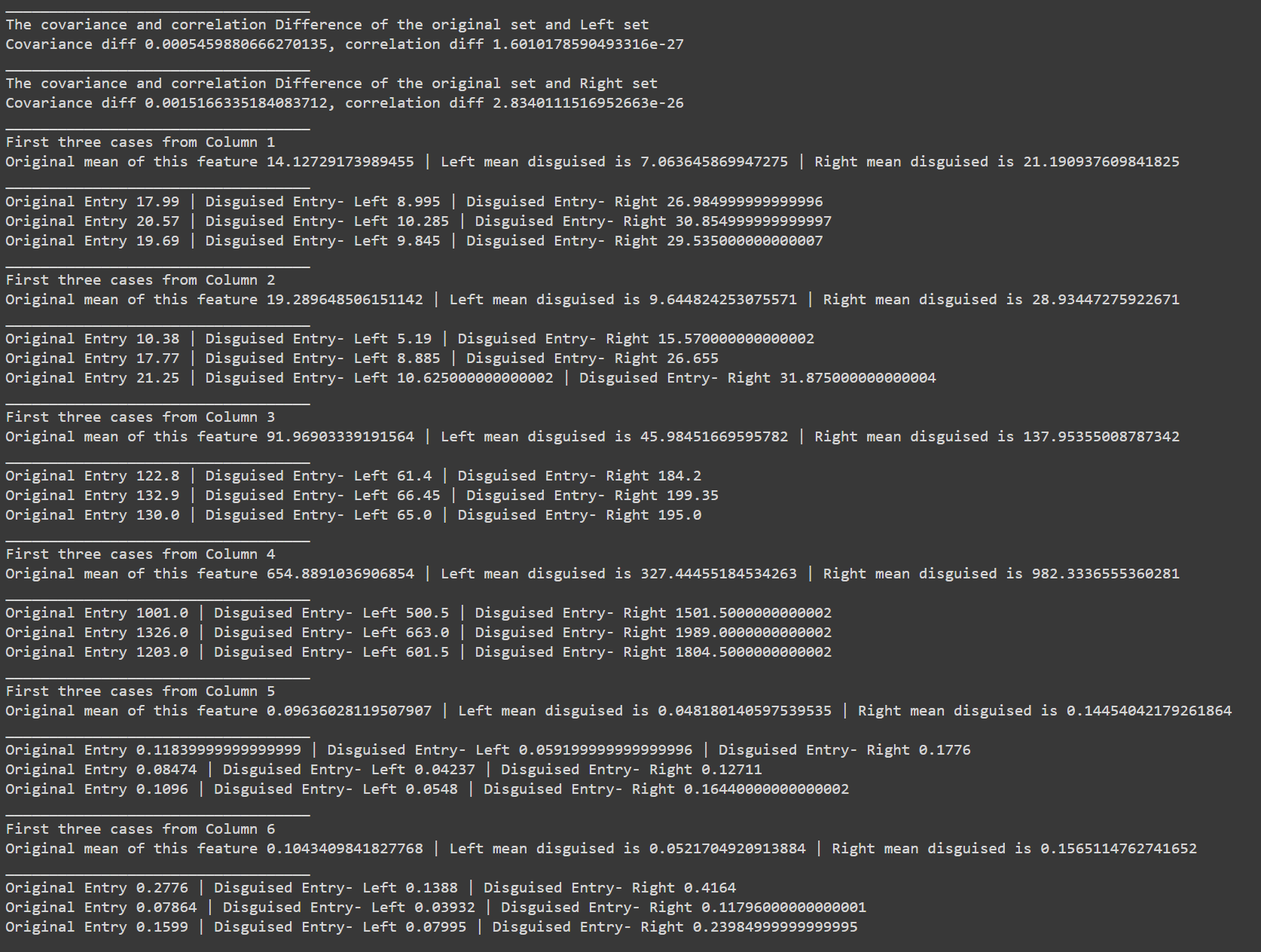
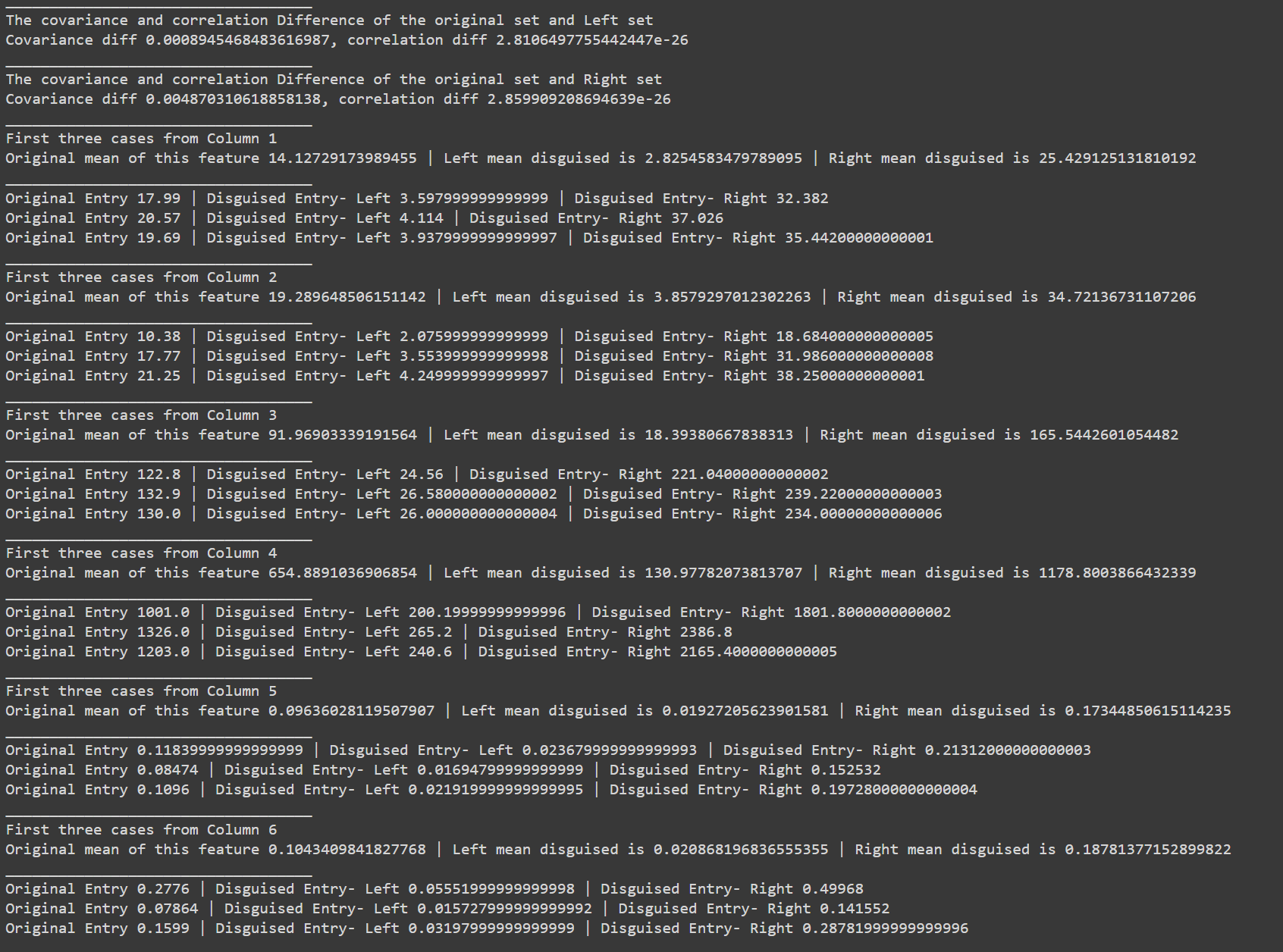
This function takes **two arguments**: the first is the formatted dataset returned from the previous function, The second parameter is the effect value, denoted as ρ; this value should range from 0 to 0.9. For a detailed understanding of its function, one may consult the relevant academic paper.
> [!IMPORTANT]
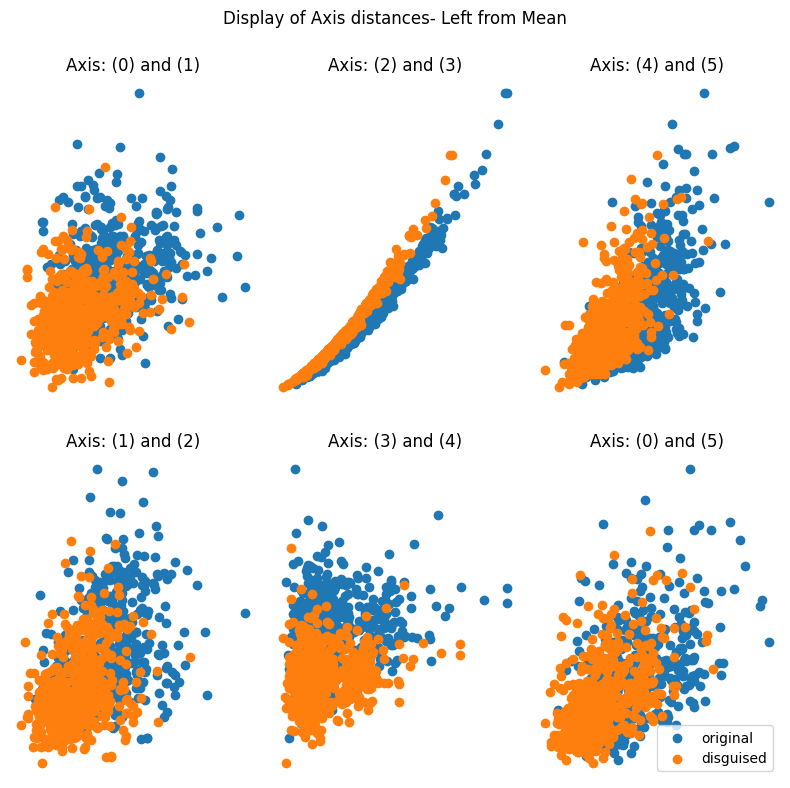
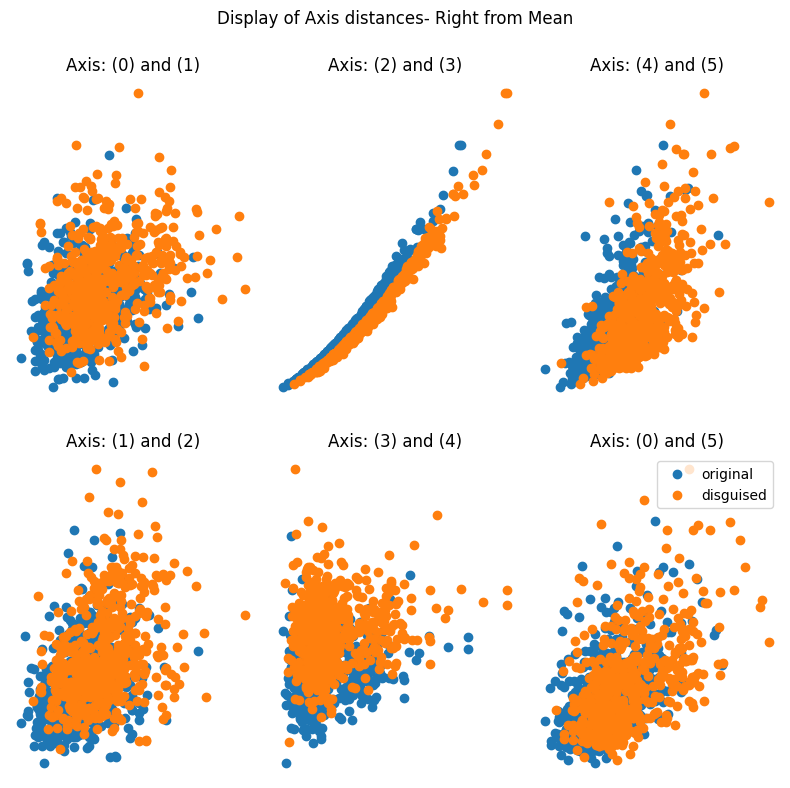
> The function should return two disguised synthetic datasets; one contains values that are to the left of the original, and the other contains values to the right. You can use the `setData[0]` or `setData[1]` variable to examine each one.
> [!TIP]
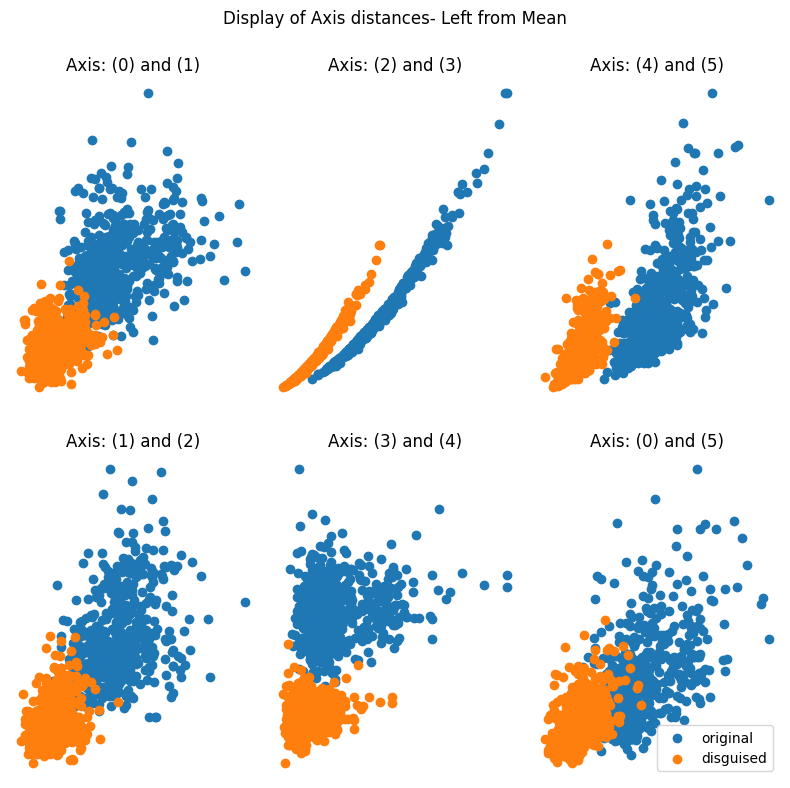
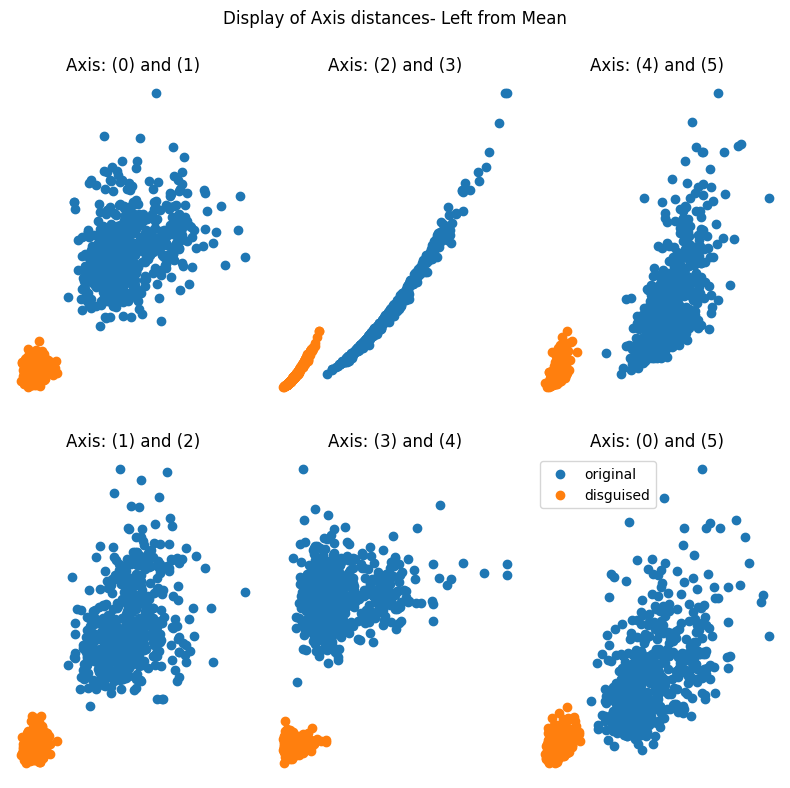
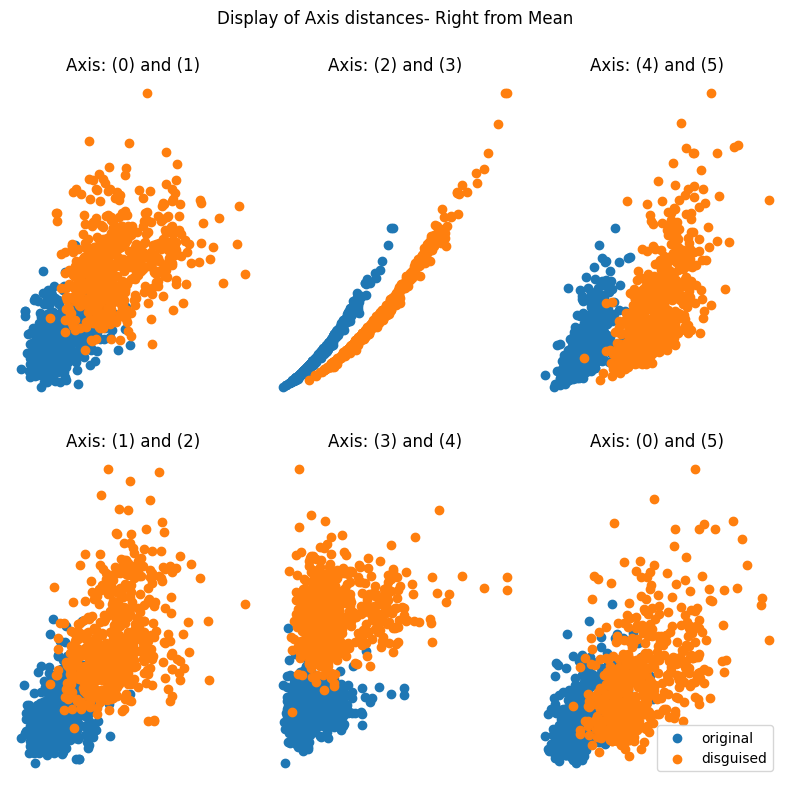
> It's important to observe how the screenshot shows the location of the disguised data from the original dataset. The report then illustrates how the values are altered according to the parameter adjustments. Additionally, it presents the differences in the mean and correlation between the original and disguised data.
Here are some outputs from the function using three different values of ρ (0.2; 0.5; and 0.9):
### at ρ = 0.2
### at ρ = 0.5
### at ρ = 0.9
## Conclusion on installation and employment of the method
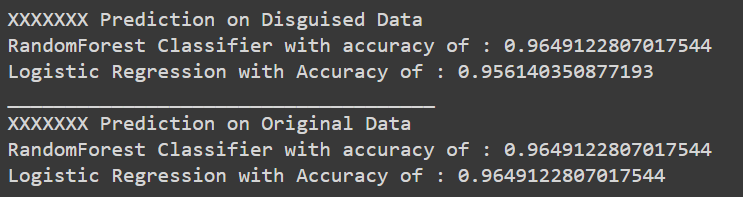
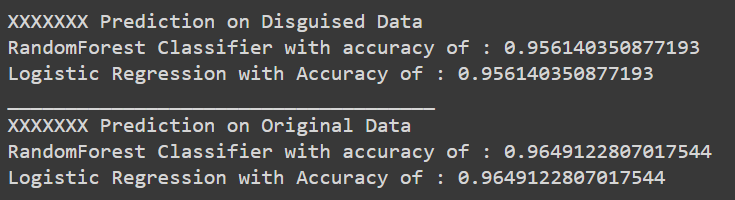
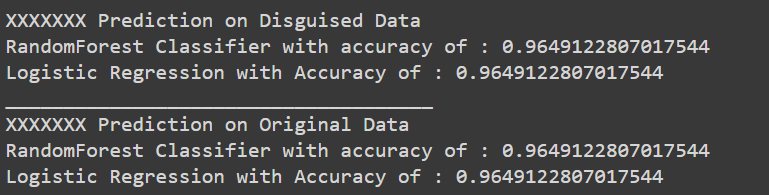
It is possible to test the results returned based on the proposed method. I used two predictive methods on the original and the disguised dataset to observe the effect on accuracy. The conclusion is that there are almost identical results between both predictions, which implies that the proposed method is effective in generating realistic disguised data that maintains privacy.
__at ρ = 0.2__
__at ρ = 0.5__
__at ρ = 0.8__
# Reference
please follow up on the [publication](https://dahmansphi.com/publications/) in the website to find the academic [published paper](https://dahmansphi.com)
Raw data
{
"_id": null,
"home_page": null,
"name": "disguisedata",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.9",
"maintainer_email": null,
"keywords": "Cybersecurity, Machine Learning, Artificial Intelligence, Synthetic Data",
"author": "Deniz Dahman's, Ph.D.",
"author_email": "dahmansphi@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/b1/5f/d2a56ee16bab50af3c0957b5624d6d1c36f5e9a1c29bce567bc1e3c6807a/disguisedata-1.0.4.tar.gz",
"platform": null,
"description": "\r\n \r\n\r\n> [!TIP]\r\n> This project complements the __Differential Privacy with AI & ML__ project available in the [repository](https://github.com/dahmansphi/differential_privacy_with_ai_and_ml). To fully grasp the concept, make sure to read both documentations.\r\n\r\n# About the Package\r\n## Author's Words\r\nWelcome to the first edition of the Disguise Data Tool official documentation. I am Deniz Dahman, Ph.D., the creator of the [BireyselValue](https://github.com/dahmansphi/bireyselvalue_v1) algorithm and the author of this package. In the following section, you will find a brief introduction to the principal idea of the __disguisedata__ tool, along with a reference to the academic publication on the method and its mathematical foundations. Before proceeding, I would like to inform you that I have conducted this work as an independent scientist without any funding or similar support. I am dedicated to continuing and seeking further improvements on the proposed method at all costs. If you wish to contribute in any way to this work, please find further details in the contributing section.\r\n \r\n## Contributing \r\n\r\nIf you wish to support the creator of this project, you might want to explore possible ways on:\r\n\r\n> `Thank you for your willingness to contribute in any way possible. You can check links below for more information on how to get involved.` :\r\n\r\n1. view options to subscribe on [Dahman's Phi Services Website](https://dahmansphi.com/subscriptions/)\r\n2. subscribe to this channel [Dahman's Phi Services](https://www.youtube.com/@dahmansphi) \r\n3. you can support on [patreon](https://patreon.com/user?u=118924481) \r\n\r\n\r\nIf you prefer *any other way of contribution*, please feel free to contact me directly on [contact](https://dahmansphi.com/contact/). \r\n\r\n*Thank you*\r\n\r\n# Introduction\r\n\r\n## History and Purpose of Synthetic Data\r\n \r\nThe concept of synthetic data has roots in scientific modeling and simulations, dating back to the early 20th century. For instance, audio and voice synthesis research began in the 1930s. The development of software synthesizers in the 1970s marked a significant advancement in creating synthetic data. In 1993, the idea of fully synthetic data for privacy-preserving statistical analysis was introduced to the research community. Today, synthetic data is extensively used in various fields, including healthcare, finance, and defense, to train AI models and conduct simulations. More importantly, synthetic data continues to evolve, offering innovative solutions to data scarcity, privacy, and bias challenges in the AI and machine learning landscape.\r\n\r\nSynthetic data serves multiple purposes. It enhances AI models, safeguards sensitive information, reduces bias, and offers an alternative when real-world data is scarce or unavailable: \r\n- [x] __Training AI Models__: Synthetic data is widely used to train machine learning models, especially when real-world data is scarce or sensitive. It helps in creating diverse datasets that improve model accuracy and robustness, \r\n- [x] **Privacy Protection:** By using synthetic data, organizations can avoid privacy issues associated with real data, such as patient information in healthcare, \r\n- [x] **Testing and Validation:** Synthetic data allows for extensive testing and validation of systems without the need for real data, which might be difficult to obtain or use due to privacy concerns. \r\n- [x] **Testing and Validation:** Synthetic data allows for extensive testing and validation of systems without the need for real data, which might be difficult to obtain or use due to privacy concerns.\r\n- [x] **Bias Reduction:** It helps in reducing biases in datasets, ensuring that AI models are trained on balanced and representative data.\r\n\r\n\r\n## disguisedata __version__1.0\r\n\r\n \r\n\r\nThere are numerous tools available to generate synthetic data using various techniques. This is where I introduce the __disguisedata__ tool. This tool helps to disguise data based on a mathematical foundational concept. In particular, it relies on two important indicators in the original dataset: \r\n\r\n1. __The norm__: Initially, it captures the general norm of the dataset, involving every entry in the set. This norm is then used to scale the dataset to a range of values. It is considered the **secret key** used later to convert the synthetic data into the same scale as the original.\r\n\r\n2. __The Geometrical Shape of a Data Point__: The second crucial indicator for the **disguisedata** method is the geometric shape of a data point in the original dataset. Each point can be represented as a right-angled triangle, which can be scaled up or down. Every point along the hypotenuse line of the triangle represents a potential replica of the original point. The accompanying figure demonstrates this concept.\r\n\r\n \r\n\r\n\r\n> [!IMPORTANT]\r\n> **This tool demonstrates the proposed method solely for educational purposes. The author provides no warranty of any kind, including the warranty of design, merchantability, and fitness for a particular purpose**. \r\n\r\n# Installation \r\n> [!TIP]\r\n> The simulation using __disguisedata__ was conducted on three datasets, which are referenced in the section below. \r\n\r\n## Data Availability\r\n1. Breast Cancer Wisconsin (Diagnostic) Dataset available in [UCI Machine Learning Repository] at https://archive.ics.uci.edu/dataset/17/breast+cancer+wisconsin+diagnostic , reference (Street 1993)\r\n2. The Dry Bean Dataset available in [UCI Machine Learning Repository] at https://doi.org/10.24432/C50S4B , reference (Koklu 2020) \r\n\r\n## Install disguisedata\r\n\r\nto install the package all what you have to do:\r\n```\r\npip install disguisedata==1.0.4\r\n```\r\nYou should then be able to use the package. It might be a good idea to confirm the installation to ensure everything is set up correctly.\r\n\r\n```\r\npip show disguisedata\r\n```\r\nThe result then shall be as:\r\n\r\n```\r\nName: disguisedata\r\nVersion: 1.0.4\r\nSummary: A tiny tool for generating synthetic data from the original one\r\nHome-page: https://github.com/dahmansphi/disguisedata\r\nAuthor: Deniz Dahman's, Ph.D.\r\nAuthor-email: dahmansphi@gmail.com\r\n```\r\n> [!IMPORTANT]\r\n> **Sometimes, the `seaborn` library isn't installed during setup. If that's the case, you'll need to install it manually.** \r\n\r\n\r\n## Employ the disguisedata -**Conditions**\r\n\r\n> [!IMPORTANT]\r\n> It's mandatory to provide the instance of the class with the **NumPy** array of the original dataset, which does not include the **y** feature or the target variable.\r\n\r\n## Detour in the disguisedata package- Build-in\r\nOnce your installation is complete and all conditions are met, you may want to explore the built-in functions of the `disguisedata` package to understand each one. Essentially, you can create an instance from the `disguisedata` class as follows:\r\n\r\n```\r\nfrom disguisedata.disguisedata import Disguisedata\r\ninst = Disguisedata()\r\n```\r\nNow this instance offers you access to the built-in functions that you need. Here is a screenshot:\r\n\r\n\r\n\r\nOnce you have the **disguisedata** instance, follow these steps to obtain the new disguised data:\r\n\r\n### Control and Get the data format:\r\n\r\nThe first function you want to employ is `feedDs` using: \r\n```\r\ndata = inst.feedDs(ds=ds)\r\n```\r\nThis function takes one argument, which is the NumPy dataset, and it controls the conditions and returns a formatted, scaled dataset that is ready for the action of disguise.\r\n\r\n### Acquire two distinct variants of disguised synthetic data.:\r\n\r\nThe function `discover_effect` allows you to explore how the disguised data differs from the original data. It is called using: \r\n```\r\nsetData = inst.discover_effect(data=data, effect=effect)\r\n``` \r\n\r\nThis function takes **two arguments**: the first is the formatted dataset returned from the previous function, The second parameter is the effect value, denoted as \u03c1; this value should range from 0 to 0.9. For a detailed understanding of its function, one may consult the relevant academic paper. \r\n\r\n> [!IMPORTANT]\r\n> The function should return two disguised synthetic datasets; one contains values that are to the left of the original, and the other contains values to the right. You can use the `setData[0]` or `setData[1]` variable to examine each one.\r\n\r\n> [!TIP]\r\n> It's important to observe how the screenshot shows the location of the disguised data from the original dataset. The report then illustrates how the values are altered according to the parameter adjustments. Additionally, it presents the differences in the mean and correlation between the original and disguised data.\r\n\r\nHere are some outputs from the function using three different values of \u03c1 (0.2; 0.5; and 0.9):\r\n\r\n\r\n### at \u03c1 = 0.2\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n### at \u03c1 = 0.5\r\n\r\n\r\n\r\n\r\n\r\n\r\n### at \u03c1 = 0.9\r\n\r\n\r\n\r\n\r\n\r\n\r\n## Conclusion on installation and employment of the method \r\nIt is possible to test the results returned based on the proposed method. I used two predictive methods on the original and the disguised dataset to observe the effect on accuracy. The conclusion is that there are almost identical results between both predictions, which implies that the proposed method is effective in generating realistic disguised data that maintains privacy.\r\n\r\n__at \u03c1 = 0.2__\r\n\r\n\r\n\r\n__at \u03c1 = 0.5__\r\n\r\n\r\n\r\n__at \u03c1 = 0.8__\r\n\r\n\r\n\r\n\r\n# Reference\r\n\r\nplease follow up on the [publication](https://dahmansphi.com/publications/) in the website to find the academic [published paper](https://dahmansphi.com)\r\n \r\n",
"bugtrack_url": null,
"license": null,
"summary": "A tiny tool for generating synthetic data from the original one",
"version": "1.0.4",
"project_urls": {
"Project": "https://dahmansphi.com/disguisedata",
"Source": "https://github.com/dahmansphi/disguisedata"
},
"split_keywords": [
"cybersecurity",
" machine learning",
" artificial intelligence",
" synthetic data"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "29b030ab337286d241a702f6d8fe9e47e178b223e7469ba4c5402e8cb7392f8b",
"md5": "555d1dad11e78764a08aa2890cae2f60",
"sha256": "93a0d532075388791cee5a8ff5d99d3e217b456ee733d6def6c46ae0557a231a"
},
"downloads": -1,
"filename": "disguisedata-1.0.4-py3-none-any.whl",
"has_sig": false,
"md5_digest": "555d1dad11e78764a08aa2890cae2f60",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.9",
"size": 20398,
"upload_time": "2024-07-24T06:23:32",
"upload_time_iso_8601": "2024-07-24T06:23:32.894354Z",
"url": "https://files.pythonhosted.org/packages/29/b0/30ab337286d241a702f6d8fe9e47e178b223e7469ba4c5402e8cb7392f8b/disguisedata-1.0.4-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "b15fd2a56ee16bab50af3c0957b5624d6d1c36f5e9a1c29bce567bc1e3c6807a",
"md5": "624328de508b96f659318f7e6ccd2e8a",
"sha256": "70e0f94673c1bbd9d9aa04ac8efa2496004bdd2814d4df1344a3ee6e6121f611"
},
"downloads": -1,
"filename": "disguisedata-1.0.4.tar.gz",
"has_sig": false,
"md5_digest": "624328de508b96f659318f7e6ccd2e8a",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.9",
"size": 24350,
"upload_time": "2024-07-24T06:23:34",
"upload_time_iso_8601": "2024-07-24T06:23:34.473594Z",
"url": "https://files.pythonhosted.org/packages/b1/5f/d2a56ee16bab50af3c0957b5624d6d1c36f5e9a1c29bce567bc1e3c6807a/disguisedata-1.0.4.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-07-24 06:23:34",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "dahmansphi",
"github_project": "disguisedata",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "disguisedata"
}

