# fast_csv_loader.py
The `csv_loader` function efficiently loads a partial portion of a large CSV file containing time-series data into a pandas DataFrame.
The function allows:
- Loading the last N lines from the end of the file.
- Loading the last N lines from a specific date.
It can load any type of time-series (both timezone aware and Naive) and daily or intraday data.
It is useful for loading large datasets that may not fit entirely into memory.
It also improves program execution time, when iterating or loading a large number of CSV files.
**Supports Python >= 3.8**
## Install
`pip install fast-csv-loader`
## Documentation
[https://bennythadikaran.github.io/fast_csv_loader/](https://bennythadikaran.github.io/fast_csv_loader/)
## Performance
Loading a portion of a large file is significantly faster than loading the entire file in memory.
Files used in the test were not particularly large. You may need to tweak the chunk_size parameter for your use case.
It is slower for smaller files or if you're loading nearly the entire portion of the file.
I chose a 6Kb chunk size based on testing with my specific requirements. Your requirements may differ.
### csv_loader vs pandas.read_csv
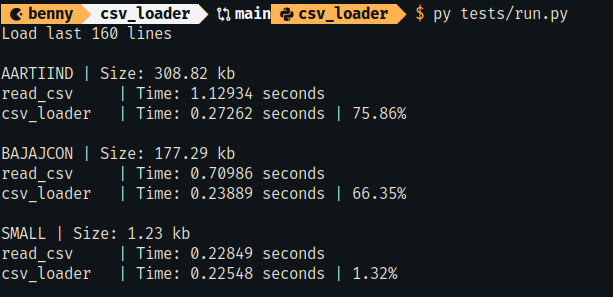
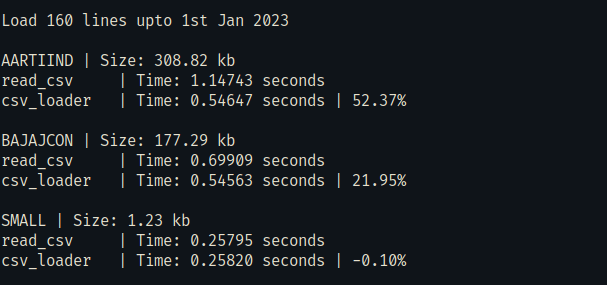
To run this performance test.
```bash
py tests/run.py
```
At the minimum, the CSV file must contain a Date and another column with newline chars at the end to correctly parse and load.
```
Date,Price\n
2023-12-01,200\n
```
## Unit Test
To run the test:
```bash
py tests/test_csv_loader.py
```
Raw data
{
"_id": null,
"home_page": null,
"name": "fast-csv-loader",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": null,
"keywords": "csv-loader, csv-reader, memory-efficient, pandas-dataframe, python3",
"author": "Benny Thadikaran",
"author_email": null,
"download_url": "https://files.pythonhosted.org/packages/a6/a4/fcc30670f110db96a9f08cff704fc92aa81ac1bb732a382b113746a50910/fast_csv_loader-1.0.1.tar.gz",
"platform": null,
"description": "# fast_csv_loader.py\n\nThe `csv_loader` function efficiently loads a partial portion of a large CSV file containing time-series data into a pandas DataFrame.\n\nThe function allows:\n\n- Loading the last N lines from the end of the file.\n- Loading the last N lines from a specific date.\n\nIt can load any type of time-series (both timezone aware and Naive) and daily or intraday data.\n\nIt is useful for loading large datasets that may not fit entirely into memory.\nIt also improves program execution time, when iterating or loading a large number of CSV files.\n\n**Supports Python >= 3.8**\n\n## Install\n\n`pip install fast-csv-loader`\n\n## Documentation\n\n[https://bennythadikaran.github.io/fast_csv_loader/](https://bennythadikaran.github.io/fast_csv_loader/)\n\n## Performance\n\nLoading a portion of a large file is significantly faster than loading the entire file in memory.\nFiles used in the test were not particularly large. You may need to tweak the chunk_size parameter for your use case.\n\nIt is slower for smaller files or if you're loading nearly the entire portion of the file.\n\nI chose a 6Kb chunk size based on testing with my specific requirements. Your requirements may differ.\n\n### csv_loader vs pandas.read_csv\n\n\n\n\n\nTo run this performance test.\n\n```bash\npy tests/run.py\n```\n\nAt the minimum, the CSV file must contain a Date and another column with newline chars at the end to correctly parse and load.\n\n```\nDate,Price\\n\n2023-12-01,200\\n\n```\n\n## Unit Test\n\nTo run the test:\n\n```bash\npy tests/test_csv_loader.py\n```\n",
"bugtrack_url": null,
"license": null,
"summary": "A fast and memory efficient way to load large CSV files (Timeseries data) into Pandas",
"version": "1.0.1",
"project_urls": {
"Bug Tracker": "https://github.com/BennyThadikaran/fast_csv_loader/issues",
"Homepage": "https://github.com/BennyThadikaran/fast_csv_loader"
},
"split_keywords": [
"csv-loader",
" csv-reader",
" memory-efficient",
" pandas-dataframe",
" python3"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "17faa842996e8fd633d710ca33673985216c1d345c2af1cf5a719fae258cb8ee",
"md5": "b275ead97b7d2b7618da23ad617a0709",
"sha256": "63f7937319bc4d6b5c8e910f4fa48b78ea1dba4e0c71b929f5fcc7f4ca02f54b"
},
"downloads": -1,
"filename": "fast_csv_loader-1.0.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "b275ead97b7d2b7618da23ad617a0709",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.8",
"size": 16985,
"upload_time": "2024-11-04T06:18:56",
"upload_time_iso_8601": "2024-11-04T06:18:56.069802Z",
"url": "https://files.pythonhosted.org/packages/17/fa/a842996e8fd633d710ca33673985216c1d345c2af1cf5a719fae258cb8ee/fast_csv_loader-1.0.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "a6a4fcc30670f110db96a9f08cff704fc92aa81ac1bb732a382b113746a50910",
"md5": "d92187a414f13ee9fa386ef92f0e00ae",
"sha256": "c35473284a2f7cec65987ac3cd6dc0ebeddccafd56fe2542869f835e855e9544"
},
"downloads": -1,
"filename": "fast_csv_loader-1.0.1.tar.gz",
"has_sig": false,
"md5_digest": "d92187a414f13ee9fa386ef92f0e00ae",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 17149,
"upload_time": "2024-11-04T06:18:57",
"upload_time_iso_8601": "2024-11-04T06:18:57.519318Z",
"url": "https://files.pythonhosted.org/packages/a6/a4/fcc30670f110db96a9f08cff704fc92aa81ac1bb732a382b113746a50910/fast_csv_loader-1.0.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-11-04 06:18:57",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "BennyThadikaran",
"github_project": "fast_csv_loader",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"requirements": [],
"lcname": "fast-csv-loader"
}

