## Fast & Lightweight License Plate OCR
[](https://github.com/ankandrew/fast-plate-ocr/actions)
[](https://keras.io/keras_3/)
[](https://pypi.python.org/pypi/fast-plate-ocr)
[](https://pypi.python.org/pypi/fast-plate-ocr)
[](https://github.com/astral-sh/ruff)
[](https://github.com/pylint-dev/pylint)
[](http://mypy-lang.org/)
[](https://onnx.ai/)
[](https://huggingface.co/spaces/ankandrew/fast-alpr)
[](https://ankandrew.github.io/fast-plate-ocr/)
[](https://pypi.python.org/pypi/fast-plate-ocr)

---
### Introduction
**Lightweight** and **fast** OCR models for license plate text recognition. You can train models from scratch or use
the trained models for inference.
The idea is to use this after a plate object detector, since the OCR expects the cropped plates.
### Features
- **Keras 3 Backend Support**: Compatible with **[TensorFlow](https://www.tensorflow.org/)**, **[JAX](https://github.com/google/jax)**, and **[PyTorch](https://pytorch.org/)** backends 🧠
- **Augmentation Variety**: Diverse **augmentations** via **[Albumentations](https://albumentations.ai/)** library 🖼️
- **Efficient Execution**: **Lightweight** models that are cheap to run 💰
- **ONNX Runtime Inference**: **Fast** and **optimized** inference with **[ONNX runtime](https://onnxruntime.ai/)** ⚡
- **User-Friendly CLI**: Simplified **CLI** for **training** and **validating** OCR models 🛠️
- **Model HUB**: Access to a collection of **pre-trained models** ready for inference 🌟
### Available Models
| Model Name | Time b=1<br/> (ms)<sup>[1]</sup> | Throughput <br/> (plates/second)<sup>[1]</sup> | Accuracy<sup>[2]</sup> | Dataset |
|:----------------------------------------:|:--------------------------------:|:----------------------------------------------:|:----------------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| `argentinian-plates-cnn-model` | 2.1 | 476 | 94.05% | Non-synthetic, plates up to 2020. Dataset [arg_plate_dataset.zip](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_plate_dataset.zip). |
| `argentinian-plates-cnn-synth-model` | 2.1 | 476 | 94.19% | Plates up to 2020 + synthetic plates. Dataset [arg_plate_dataset_plus_synth.zip](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_plate_dataset_plus_synth.zip). |
| `european-plates-mobile-vit-v2-model` | 2.9 | 344 | 92.5%<sup>[3]</sup> | European plates (from +40 countries, trained on 40k+ plates). |
| 🆕🔥 `global-plates-mobile-vit-v2-model` | 2.9 | 344 | 93.3%<sup>[4]</sup> | Worldwide plates (from +65 countries, trained on 85k+ plates). |
> [!TIP]
> Try `fast-plate-ocr` pre-trained models in [Hugging Spaces](https://huggingface.co/spaces/ankandrew/fast-alpr).
<details>
<summary>Notes</summary>
> [!NOTE]
> _<sup>[1]</sup> Inference on Mac M1 chip using CPUExecutionProvider. Utilizing CoreMLExecutionProvider accelerates speed by 5x in the CNN models._
>
> _<sup>[2]</sup> Accuracy is what we refer to as plate_acc. See [metrics section](#model-metrics)._
>
> _<sup>[3]</sup> For detailed accuracy for each country see [results](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/european_mobile_vit_v2_ocr_results.json) and the corresponding [val split](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/european_mobile_vit_v2_ocr_val.zip) used._
>
> _<sup>[4]</sup> For detailed accuracy for each country see [results](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/global_mobile_vit_v2_ocr_results.json)._
</details>
<details>
<summary>Reproduce results.</summary>
* Calculate Inference Time:
```shell
pip install fast_plate_ocr
```
```python
from fast_plate_ocr import ONNXPlateRecognizer
m = ONNXPlateRecognizer("argentinian-plates-cnn-model")
m.benchmark()
```
* Calculate Model accuracy:
```shell
pip install fast-plate-ocr[train]
curl -LO https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_cnn_ocr_config.yaml
curl -LO https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_cnn_ocr.keras
curl -LO https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_plate_benchmark.zip
unzip arg_plate_benchmark.zip
fast_plate_ocr valid \
-m arg_cnn_ocr.keras \
--config-file arg_cnn_ocr_config.yaml \
--annotations benchmark/annotations.csv
```
</details>
### Inference
For inference, install:
```shell
pip install fast_plate_ocr
```
#### Usage
To predict from disk image:
```python
from fast_plate_ocr import ONNXPlateRecognizer
m = ONNXPlateRecognizer('argentinian-plates-cnn-model')
print(m.run('test_plate.png'))
```
<details>
<summary>run demo</summary>

</details>
To run model benchmark:
```python
from fast_plate_ocr import ONNXPlateRecognizer
m = ONNXPlateRecognizer('argentinian-plates-cnn-model')
m.benchmark()
```
<details>
<summary>benchmark demo</summary>

</details>
Make sure to check out the [docs](https://ankandrew.github.io/fast-plate-ocr) for more information.
### CLI
<img src="https://github.com/ankandrew/fast-plate-ocr/blob/ac3d110c58f62b79072e3a7af15720bb52a45e4e/extra/cli_screenshot.png?raw=true" alt="CLI">
To train or use the CLI tool, you'll need to install:
```shell
pip install fast_plate_ocr[train]
```
> [!IMPORTANT]
> Make sure you have installed a supported backend for Keras.
#### Train Model
To train the model you will need:
1. A configuration used for the OCR model. Depending on your use case, you might have more plate slots or different set
of characters. Take a look at the config for Argentinian license plate as an example:
```yaml
# Config example for Argentinian License Plates
# The old license plates contain 6 slots/characters (i.e. JUH697)
# and new 'Mercosur' contain 7 slots/characters (i.e. AB123CD)
# Max number of plate slots supported. This represents the number of model classification heads.
max_plate_slots: 7
# All the possible character set for the model output.
alphabet: '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_'
# Padding character for plates which length is smaller than MAX_PLATE_SLOTS. It should still be present in the alphabet.
pad_char: '_'
# Image height which is fed to the model.
img_height: 70
# Image width which is fed to the model.
img_width: 140
```
2. A labeled dataset,
see [arg_plate_dataset.zip](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_plate_dataset.zip)
for the expected data format.
3. Run train script:
```shell
# You can set the backend to either TensorFlow, JAX or PyTorch
# (just make sure it is installed)
KERAS_BACKEND=tensorflow fast_plate_ocr train \
--annotations path_to_the_train.csv \
--val-annotations path_to_the_val.csv \
--config-file config.yaml \
--batch-size 128 \
--epochs 750 \
--dense \
--early-stopping-patience 100 \
--reduce-lr-patience 50
```
You will probably want to change the augmentation pipeline to apply to your dataset.
In order to do this define an Albumentations pipeline:
```python
import albumentations as A
transform_pipeline = A.Compose(
[
# ...
A.RandomBrightnessContrast(brightness_limit=0.1, contrast_limit=0.1, p=1),
A.MotionBlur(blur_limit=(3, 5), p=0.1),
A.CoarseDropout(max_holes=10, max_height=4, max_width=4, p=0.3),
# ... and any other augmentation ...
]
)
# Export to a file (this resultant YAML can be used by the train script)
A.save(transform_pipeline, "./transform_pipeline.yaml", data_format="yaml")
```
And then you can train using the custom transformation pipeline with the `--augmentation-path` option.
#### Visualize Augmentation
It's useful to visualize the augmentation pipeline before training the model. This helps us to identify
if we should apply more heavy augmentation or less, as it can hurt the model.
You might want to see the augmented image next to the original, to see how much it changed:
```shell
fast_plate_ocr visualize-augmentation \
--img-dir benchmark/imgs \
--columns 2 \
--show-original \
--augmentation-path '/transform_pipeline.yaml'
```
You will see something like:

#### Validate Model
After finishing training you can validate the model on a labeled test dataset.
Example:
```shell
fast_plate_ocr valid \
--model arg_cnn_ocr.keras \
--config-file arg_plate_example.yaml \
--annotations benchmark/annotations.csv
```
#### Visualize Predictions
Once you finish training your model, you can view the model predictions on raw data with:
```shell
fast_plate_ocr visualize-predictions \
--model arg_cnn_ocr.keras \
--img-dir benchmark/imgs \
--config-file arg_cnn_ocr_config.yaml
```
You will see something like:

#### Export as ONNX
Exporting the Keras model to ONNX format might be beneficial to speed-up inference time.
```shell
fast_plate_ocr export-onnx \
--model arg_cnn_ocr.keras \
--output-path arg_cnn_ocr.onnx \
--opset 18 \
--config-file arg_cnn_ocr_config.yaml
```
### Keras Backend
To train the model, you can install the ML Framework you like the most. **Keras 3** has
support for **TensorFlow**, **JAX** and **PyTorch** backends.
To change the Keras backend you can either:
1. Export `KERAS_BACKEND` environment variable, i.e. to use JAX for training:
```shell
KERAS_BACKEND=jax fast_plate_ocr train --config-file ...
```
2. Edit your local config file at `~/.keras/keras.json`.
_Note: You will probably need to install your desired framework for training._
### Model Architecture
The current model architecture is quite simple but effective.
See [cnn_ocr_model](https://github.com/ankandrew/cnn-ocr-lp/blob/e59b738bad86d269c82101dfe7a3bef49b3a77c7/fast_plate_ocr/train/model/models.py#L23-L23)
for implementation details.
The model output consists of several heads. Each head represents the prediction of a character of the
plate. If the plate consists of 7 characters at most (`max_plate_slots=7`), then the model would have 7 heads.
Example of Argentinian plates:
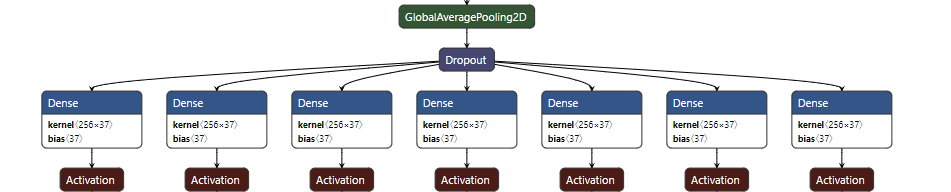
Each head will output a probability distribution over the `vocabulary` specified during training. So the output
prediction for a single plate will be of shape `(max_plate_slots, vocabulary_size)`.
### Model Metrics
During training, you will see the following metrics
* **plate_acc**: Compute the number of **license plates** that were **fully classified**. For a single plate, if the
ground truth is `ABC123` and the prediction is also `ABC123`, it would score 1. However, if the prediction was
`ABD123`, it would score 0, as **not all characters** were correctly classified.
* **cat_acc**: Calculate the accuracy of **individual characters** within the license plates that were
**correctly classified**. For example, if the correct label is `ABC123` and the prediction is `ABC133`, it would yield
a precision of 83.3% (5 out of 6 characters correctly classified), rather than 0% as in plate_acc, because it's not
completely classified correctly.
* **top_3_k**: Calculate how frequently the true character is included in the **top-3 predictions**
(the three predictions with the highest probability).
### Contributing
Contributions to the repo are greatly appreciated. Whether it's bug fixes, feature enhancements, or new models,
your contributions are warmly welcomed.
To start contributing or to begin development, you can follow these steps:
1. Clone repo
```shell
git clone https://github.com/ankandrew/fast-plate-ocr.git
```
2. Install all dependencies using [Poetry](https://python-poetry.org/docs/#installation):
```shell
poetry install --all-extras
```
3. To ensure your changes pass linting and tests before submitting a PR:
```shell
make checks
```
If you want to train a model and share it, we'll add it to the HUB 🚀
### TODO
- [ ] Expand model zoo.
- [ ] Use synthetic image plates.
- [ ] Finish and push TorchServe files.
- [ ] Use Google docstring style
Raw data
{
"_id": null,
"home_page": "https://github.com/ankandrew/fast-plate-ocr/",
"name": "fast-plate-ocr",
"maintainer": null,
"docs_url": null,
"requires_python": "<4.0,>=3.10",
"maintainer_email": null,
"keywords": "plate-recognition, license-plate-recognition, license-plate-ocr",
"author": "ankandrew",
"author_email": "61120139+ankandrew@users.noreply.github.com",
"download_url": "https://files.pythonhosted.org/packages/d9/c7/fec32bd1e3c11e01ae0f20c4b7c76c8b7d587203ea0e3c2b3afe53561081/fast_plate_ocr-0.3.0.tar.gz",
"platform": null,
"description": "## Fast & Lightweight License Plate OCR\n\n[](https://github.com/ankandrew/fast-plate-ocr/actions)\n[](https://keras.io/keras_3/)\n[](https://pypi.python.org/pypi/fast-plate-ocr)\n[](https://pypi.python.org/pypi/fast-plate-ocr)\n[](https://github.com/astral-sh/ruff)\n[](https://github.com/pylint-dev/pylint)\n[](http://mypy-lang.org/)\n[](https://onnx.ai/)\n[](https://huggingface.co/spaces/ankandrew/fast-alpr)\n[](https://ankandrew.github.io/fast-plate-ocr/)\n[](https://pypi.python.org/pypi/fast-plate-ocr)\n\n\n\n---\n\n### Introduction\n\n**Lightweight** and **fast** OCR models for license plate text recognition. You can train models from scratch or use\nthe trained models for inference.\n\nThe idea is to use this after a plate object detector, since the OCR expects the cropped plates.\n\n### Features\n\n- **Keras 3 Backend Support**: Compatible with **[TensorFlow](https://www.tensorflow.org/)**, **[JAX](https://github.com/google/jax)**, and **[PyTorch](https://pytorch.org/)** backends \ud83e\udde0\n- **Augmentation Variety**: Diverse **augmentations** via **[Albumentations](https://albumentations.ai/)** library \ud83d\uddbc\ufe0f\n- **Efficient Execution**: **Lightweight** models that are cheap to run \ud83d\udcb0\n- **ONNX Runtime Inference**: **Fast** and **optimized** inference with **[ONNX runtime](https://onnxruntime.ai/)** \u26a1\n- **User-Friendly CLI**: Simplified **CLI** for **training** and **validating** OCR models \ud83d\udee0\ufe0f\n- **Model HUB**: Access to a collection of **pre-trained models** ready for inference \ud83c\udf1f\n\n### Available Models\n\n| Model Name | Time b=1<br/> (ms)<sup>[1]</sup> | Throughput <br/> (plates/second)<sup>[1]</sup> | Accuracy<sup>[2]</sup> | Dataset |\n|:----------------------------------------:|:--------------------------------:|:----------------------------------------------:|:----------------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|\n| `argentinian-plates-cnn-model` | 2.1 | 476 | 94.05% | Non-synthetic, plates up to 2020. Dataset [arg_plate_dataset.zip](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_plate_dataset.zip). |\n| `argentinian-plates-cnn-synth-model` | 2.1 | 476 | 94.19% | Plates up to 2020 + synthetic plates. Dataset [arg_plate_dataset_plus_synth.zip](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_plate_dataset_plus_synth.zip). |\n| `european-plates-mobile-vit-v2-model` | 2.9 | 344 | 92.5%<sup>[3]</sup> | European plates (from +40 countries, trained on 40k+ plates). |\n| \ud83c\udd95\ud83d\udd25 `global-plates-mobile-vit-v2-model` | 2.9 | 344 | 93.3%<sup>[4]</sup> | Worldwide plates (from +65 countries, trained on 85k+ plates). |\n\n> [!TIP]\n> Try `fast-plate-ocr` pre-trained models in [Hugging Spaces](https://huggingface.co/spaces/ankandrew/fast-alpr).\n\n<details>\n <summary>Notes</summary>\n\n > [!NOTE]\n > _<sup>[1]</sup> Inference on Mac M1 chip using CPUExecutionProvider. Utilizing CoreMLExecutionProvider accelerates speed by 5x in the CNN models._\n >\n > _<sup>[2]</sup> Accuracy is what we refer to as plate_acc. See [metrics section](#model-metrics)._\n >\n > _<sup>[3]</sup> For detailed accuracy for each country see [results](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/european_mobile_vit_v2_ocr_results.json) and the corresponding [val split](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/european_mobile_vit_v2_ocr_val.zip) used._\n >\n > _<sup>[4]</sup> For detailed accuracy for each country see [results](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/global_mobile_vit_v2_ocr_results.json)._\n\n</details>\n\n<details>\n <summary>Reproduce results.</summary>\n\n* Calculate Inference Time:\n\n ```shell\n pip install fast_plate_ocr\n ```\n\n ```python\n from fast_plate_ocr import ONNXPlateRecognizer\n\n m = ONNXPlateRecognizer(\"argentinian-plates-cnn-model\")\n m.benchmark()\n ```\n* Calculate Model accuracy:\n\n ```shell\n pip install fast-plate-ocr[train]\n curl -LO https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_cnn_ocr_config.yaml\n curl -LO https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_cnn_ocr.keras\n curl -LO https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_plate_benchmark.zip\n unzip arg_plate_benchmark.zip\n fast_plate_ocr valid \\\n -m arg_cnn_ocr.keras \\\n --config-file arg_cnn_ocr_config.yaml \\\n --annotations benchmark/annotations.csv\n ```\n\n</details>\n\n### Inference\n\nFor inference, install:\n\n```shell\npip install fast_plate_ocr\n```\n\n#### Usage\n\nTo predict from disk image:\n\n```python\nfrom fast_plate_ocr import ONNXPlateRecognizer\n\nm = ONNXPlateRecognizer('argentinian-plates-cnn-model')\nprint(m.run('test_plate.png'))\n```\n\n<details>\n <summary>run demo</summary>\n\n\n\n</details>\n\nTo run model benchmark:\n\n```python\nfrom fast_plate_ocr import ONNXPlateRecognizer\n\nm = ONNXPlateRecognizer('argentinian-plates-cnn-model')\nm.benchmark()\n```\n\n<details>\n <summary>benchmark demo</summary>\n\n\n\n</details>\n\nMake sure to check out the [docs](https://ankandrew.github.io/fast-plate-ocr) for more information.\n\n### CLI\n\n<img src=\"https://github.com/ankandrew/fast-plate-ocr/blob/ac3d110c58f62b79072e3a7af15720bb52a45e4e/extra/cli_screenshot.png?raw=true\" alt=\"CLI\">\n\nTo train or use the CLI tool, you'll need to install:\n\n```shell\npip install fast_plate_ocr[train]\n```\n\n> [!IMPORTANT]\n> Make sure you have installed a supported backend for Keras.\n\n#### Train Model\n\nTo train the model you will need:\n\n1. A configuration used for the OCR model. Depending on your use case, you might have more plate slots or different set\n of characters. Take a look at the config for Argentinian license plate as an example:\n ```yaml\n # Config example for Argentinian License Plates\n # The old license plates contain 6 slots/characters (i.e. JUH697)\n # and new 'Mercosur' contain 7 slots/characters (i.e. AB123CD)\n\n # Max number of plate slots supported. This represents the number of model classification heads.\n max_plate_slots: 7\n # All the possible character set for the model output.\n alphabet: '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_'\n # Padding character for plates which length is smaller than MAX_PLATE_SLOTS. It should still be present in the alphabet.\n pad_char: '_'\n # Image height which is fed to the model.\n img_height: 70\n # Image width which is fed to the model.\n img_width: 140\n ```\n2. A labeled dataset,\n see [arg_plate_dataset.zip](https://github.com/ankandrew/fast-plate-ocr/releases/download/arg-plates/arg_plate_dataset.zip)\n for the expected data format.\n3. Run train script:\n ```shell\n # You can set the backend to either TensorFlow, JAX or PyTorch\n # (just make sure it is installed)\n KERAS_BACKEND=tensorflow fast_plate_ocr train \\\n --annotations path_to_the_train.csv \\\n --val-annotations path_to_the_val.csv \\\n --config-file config.yaml \\\n --batch-size 128 \\\n --epochs 750 \\\n --dense \\\n --early-stopping-patience 100 \\\n --reduce-lr-patience 50\n ```\n\nYou will probably want to change the augmentation pipeline to apply to your dataset.\n\nIn order to do this define an Albumentations pipeline:\n\n```python\nimport albumentations as A\n\ntransform_pipeline = A.Compose(\n [\n # ...\n A.RandomBrightnessContrast(brightness_limit=0.1, contrast_limit=0.1, p=1),\n A.MotionBlur(blur_limit=(3, 5), p=0.1),\n A.CoarseDropout(max_holes=10, max_height=4, max_width=4, p=0.3),\n # ... and any other augmentation ...\n ]\n)\n\n# Export to a file (this resultant YAML can be used by the train script)\nA.save(transform_pipeline, \"./transform_pipeline.yaml\", data_format=\"yaml\")\n```\n\nAnd then you can train using the custom transformation pipeline with the `--augmentation-path` option.\n\n#### Visualize Augmentation\n\nIt's useful to visualize the augmentation pipeline before training the model. This helps us to identify\nif we should apply more heavy augmentation or less, as it can hurt the model.\n\nYou might want to see the augmented image next to the original, to see how much it changed:\n\n```shell\nfast_plate_ocr visualize-augmentation \\\n --img-dir benchmark/imgs \\\n --columns 2 \\\n --show-original \\\n --augmentation-path '/transform_pipeline.yaml'\n```\n\nYou will see something like:\n\n\n\n#### Validate Model\n\nAfter finishing training you can validate the model on a labeled test dataset.\n\nExample:\n\n```shell\nfast_plate_ocr valid \\\n --model arg_cnn_ocr.keras \\\n --config-file arg_plate_example.yaml \\\n --annotations benchmark/annotations.csv\n```\n\n#### Visualize Predictions\n\nOnce you finish training your model, you can view the model predictions on raw data with:\n\n```shell\nfast_plate_ocr visualize-predictions \\\n --model arg_cnn_ocr.keras \\\n --img-dir benchmark/imgs \\\n --config-file arg_cnn_ocr_config.yaml\n```\n\nYou will see something like:\n\n\n\n#### Export as ONNX\n\nExporting the Keras model to ONNX format might be beneficial to speed-up inference time.\n\n```shell\nfast_plate_ocr export-onnx \\\n\t--model arg_cnn_ocr.keras \\\n\t--output-path arg_cnn_ocr.onnx \\\n\t--opset 18 \\\n\t--config-file arg_cnn_ocr_config.yaml\n```\n\n### Keras Backend\n\nTo train the model, you can install the ML Framework you like the most. **Keras 3** has\nsupport for **TensorFlow**, **JAX** and **PyTorch** backends.\n\nTo change the Keras backend you can either:\n\n1. Export `KERAS_BACKEND` environment variable, i.e. to use JAX for training:\n ```shell\n KERAS_BACKEND=jax fast_plate_ocr train --config-file ...\n ```\n2. Edit your local config file at `~/.keras/keras.json`.\n\n_Note: You will probably need to install your desired framework for training._\n\n### Model Architecture\n\nThe current model architecture is quite simple but effective.\nSee [cnn_ocr_model](https://github.com/ankandrew/cnn-ocr-lp/blob/e59b738bad86d269c82101dfe7a3bef49b3a77c7/fast_plate_ocr/train/model/models.py#L23-L23)\nfor implementation details.\n\nThe model output consists of several heads. Each head represents the prediction of a character of the\nplate. If the plate consists of 7 characters at most (`max_plate_slots=7`), then the model would have 7 heads.\n\nExample of Argentinian plates:\n\n\n\nEach head will output a probability distribution over the `vocabulary` specified during training. So the output\nprediction for a single plate will be of shape `(max_plate_slots, vocabulary_size)`.\n\n### Model Metrics\n\nDuring training, you will see the following metrics\n\n* **plate_acc**: Compute the number of **license plates** that were **fully classified**. For a single plate, if the\n ground truth is `ABC123` and the prediction is also `ABC123`, it would score 1. However, if the prediction was\n `ABD123`, it would score 0, as **not all characters** were correctly classified.\n\n* **cat_acc**: Calculate the accuracy of **individual characters** within the license plates that were\n **correctly classified**. For example, if the correct label is `ABC123` and the prediction is `ABC133`, it would yield\n a precision of 83.3% (5 out of 6 characters correctly classified), rather than 0% as in plate_acc, because it's not\n completely classified correctly.\n\n* **top_3_k**: Calculate how frequently the true character is included in the **top-3 predictions**\n (the three predictions with the highest probability).\n\n### Contributing\n\nContributions to the repo are greatly appreciated. Whether it's bug fixes, feature enhancements, or new models,\nyour contributions are warmly welcomed.\n\nTo start contributing or to begin development, you can follow these steps:\n\n1. Clone repo\n ```shell\n git clone https://github.com/ankandrew/fast-plate-ocr.git\n ```\n2. Install all dependencies using [Poetry](https://python-poetry.org/docs/#installation):\n ```shell\n poetry install --all-extras\n ```\n3. To ensure your changes pass linting and tests before submitting a PR:\n ```shell\n make checks\n ```\n\nIf you want to train a model and share it, we'll add it to the HUB \ud83d\ude80\n\n### TODO\n\n- [ ] Expand model zoo.\n- [ ] Use synthetic image plates.\n- [ ] Finish and push TorchServe files.\n- [ ] Use Google docstring style\n\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "Fast & Lightweight OCR for vehicle license plates.",
"version": "0.3.0",
"project_urls": {
"Documentation": "https://ankandrew.github.io/fast-plate-ocr",
"Homepage": "https://github.com/ankandrew/fast-plate-ocr/",
"Repository": "https://github.com/ankandrew/fast-plate-ocr/"
},
"split_keywords": [
"plate-recognition",
" license-plate-recognition",
" license-plate-ocr"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "aeaf53da65cc6df06782e5f4845a24f4489500f3513efddb55e05e70ab34340f",
"md5": "d8ce8840fbef3098387418057de40857",
"sha256": "9dcc2ddbb51a6261fedcf5e8c5af9a8907f4a2fa6242dbe4658a491876e89a4b"
},
"downloads": -1,
"filename": "fast_plate_ocr-0.3.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "d8ce8840fbef3098387418057de40857",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": "<4.0,>=3.10",
"size": 34418,
"upload_time": "2024-12-08T16:41:45",
"upload_time_iso_8601": "2024-12-08T16:41:45.559671Z",
"url": "https://files.pythonhosted.org/packages/ae/af/53da65cc6df06782e5f4845a24f4489500f3513efddb55e05e70ab34340f/fast_plate_ocr-0.3.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "d9c7fec32bd1e3c11e01ae0f20c4b7c76c8b7d587203ea0e3c2b3afe53561081",
"md5": "ef911ad7c48c7e953038b4640bebbe1f",
"sha256": "141f6fcefdd43fa688b8252f7e30d45e5aec2d38716e896b9562307fcbb923e8"
},
"downloads": -1,
"filename": "fast_plate_ocr-0.3.0.tar.gz",
"has_sig": false,
"md5_digest": "ef911ad7c48c7e953038b4640bebbe1f",
"packagetype": "sdist",
"python_version": "source",
"requires_python": "<4.0,>=3.10",
"size": 30234,
"upload_time": "2024-12-08T16:41:47",
"upload_time_iso_8601": "2024-12-08T16:41:47.671498Z",
"url": "https://files.pythonhosted.org/packages/d9/c7/fec32bd1e3c11e01ae0f20c4b7c76c8b7d587203ea0e3c2b3afe53561081/fast_plate_ocr-0.3.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-12-08 16:41:47",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "ankandrew",
"github_project": "fast-plate-ocr",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "fast-plate-ocr"
}

