| Name | flowrunner JSON |
| Version |
0.2.3
 JSON
JSON |
| download |
| home_page | |
| Summary | Flowrunner is a lightweight package to organize and represent Data Engineering/Science workflows |
| upload_time | 2023-06-08 15:59:53 |
| maintainer | |
| docs_url | None |
| author | |
| requires_python | >=3.8 |
| license | BSD 3-Clause License Copyright (c) 2023, Prithvijit All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. 3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. |
| keywords |
data engineering
data science
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# flowrunner: A lightweight Data Engineering/Science Flow package
[](https://codecov.io/gh/prithvijitguha/FlowRunner)



[](https://flowrunner.readthedocs.io/en/latest/?badge=latest)
[](https://www.python.org/downloads/release/python-380/)
[](https://www.python.org/downloads/release/python-390/)
[](https://github.com/psf/black)
[](https://pycqa.github.io/isort/)
[](https://github.com/pre-commit/pre-commit)
## What is it?
**flowrunner** is a lightweight package to organize and represent Data Engineering/Science workflows. Its designed to be
integrated with any pre-existing framework like pandas or PySpark
## Main Features
- Lazy evaluation of DAG: flowrunner does not force you to execute/run your dag until you want to, only run it when its explicitly mentioned as `run`
- Easy syntax to build new Flows
- Easy data sharing between methods in a `Flow` using attributes
- Data store to store output of a function(incase it has `return`) for later
- Param store to easily pass reusable parameters to `Flow`
- Visualizing your flow as a DAG
## Installing flowrunner
To install flowrunner, following commands will work
Source code is hosted at https://github.com/prithvijitguha/flowRunner
```sh
pip install flowrunner
```
Or install from source
```sh
pip install git+https://github.com/prithvijitguha/flowrunner@main
```
## Usage
Here is a quick example to run as is
```python
# example.py
from flowrunner import BaseFlow, step, start, end
class ExampleFlow(BaseFlow):
@start
@step(next=['method2', 'method3'])
def method1(self):
self.a = 1
@step(next=['method4'])
def method2(self):
self.a += 1
@step(next=['method4'])
def method3(self):
self.a += 2
@end
@step
def method4(self):
self.a += 3
print("output of flow is:", self.a)
```
You can run the flow with the following command
```console
$ python -m flowrunner run example.py
output of flow is: 7
```
Or in a notebook/script like this:
```python
ExampleFlow.run()
```
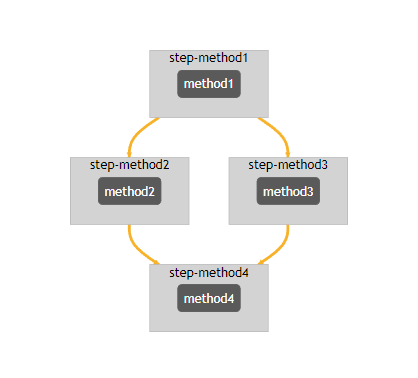
## Visualize Flow as DAG(Directed Acyclical Graph)
```python
ExampleFlow().display()
```
Your output will look like this.
Or can be run in cli like this:
```sh
python -m flowrunner display example.py
```
For CLI usage we create a file called `exampleflow.html` in the current directory with the same output
## Show your Flow
```python
ExampleFlow().show()
```
```console
2023-03-08 22:35:24 LAPTOP flowrunner.system.logger[12692] INFO Found flow ExampleFlow
2023-03-08 22:35:24 LAPTOP flowrunner.system.logger[12692] DEBUG Validating flow for ExampleFlow
✅ Validated number of start nodes
✅ Validated start nodes 'next' values
✅ Validate number of middle_nodes
✅ Validated middle_nodes 'next' values
✅ Validated end nodes
✅ Validated start nodes 'next' values
2023-03-08 22:35:24 LAPTOP flowrunner.system.logger[12692] DEBUG Show flow for ExampleFlow
method1
?
Next=method2, method3
method2
?
Next=method4
method3
?
Next=method4
```
Or through CLI like below
```console
python -m flowrunner show example.py
```
## Pandas Example
```python
# -*- coding: utf-8 -*-
import pandas as pd
from flowrunner import BaseFlow, end, start, step
class ExamplePandas(BaseFlow):
@start
@step(next=["transformation_function_1", "transformation_function_2"])
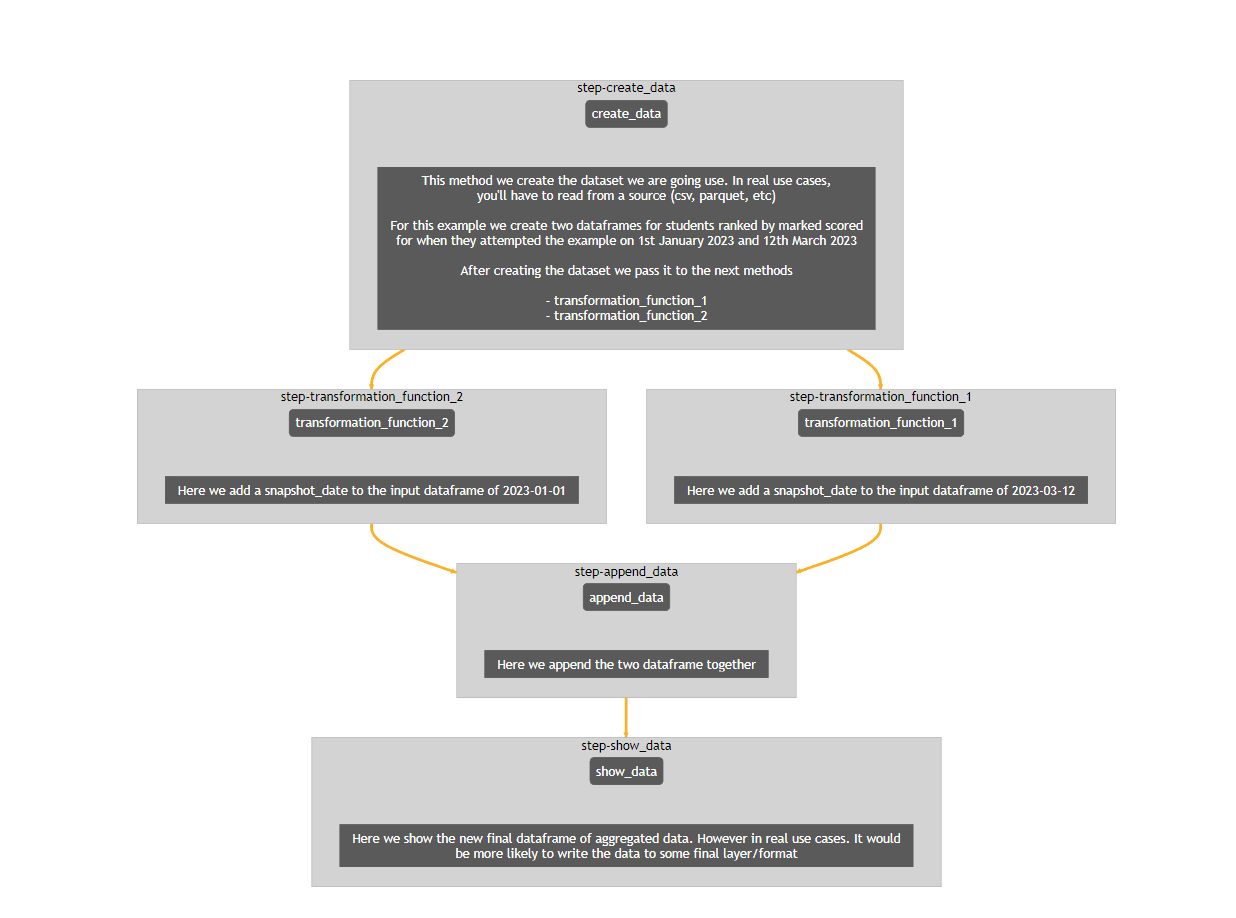
def create_data(self):
"""
This method we create the dataset we are going use. In real use cases,
you'll have to read from a source (csv, parquet, etc)
For this example we create two dataframes for students ranked by marked scored
for when they attempted the example on 1st January 2023 and 12th March 2023
After creating the dataset we pass it to the next methods
- transformation_function_1
- transformation_function_2
"""
data1 = {"Name": ["Hermione", "Harry", "Ron"], "marks": [100, 85, 75]}
data2 = {"Name": ["Hermione", "Ron", "Harry"], "marks": [100, 90, 80]}
df1 = pd.DataFrame(data1, index=["rank1", "rank2", "rank3"])
df2 = pd.DataFrame(data2, index=["rank1", "rank2", "rank3"])
self.input_data_1 = df1
self.input_data_2 = df2
@step(next=["append_data"])
def transformation_function_1(self):
"""
Here we add a snapshot_date to the input dataframe of 2023-03-12
"""
transformed_df = self.input_data_1
transformed_df.insert(1, "snapshot_date", "2023-03-12")
self.transformed_df_1 = transformed_df
@step(next=["append_data"])
def transformation_function_2(self):
"""
Here we add a snapshot_date to the input dataframe of 2023-01-01
"""
transformed_df = self.input_data_2
transformed_df.insert(1, "snapshot_date", "2023-01-01")
self.transformed_df_2 = transformed_df
@step(next=["show_data"])
def append_data(self):
"""
Here we append the two dataframe together
"""
self.final_df = pd.concat([self.transformed_df_1, self.transformed_df_2])
@end
@step
def show_data(self):
"""
Here we show the new final dataframe of aggregated data. However in real use cases. It would
be more likely to write the data to some final layer/format
"""
print(self.final_df)
return self.final_df
```
Now when you run `ExamplePandas().display()` you get the following output
## PySpark Example
```python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit
from flowrunner import BaseFlow, end, start, step
spark = SparkSession.builder.getOrCreate()
class ExamplePySpark(BaseFlow):
@start
@step(next=["transformation_function_1", "transformation_function_2"])
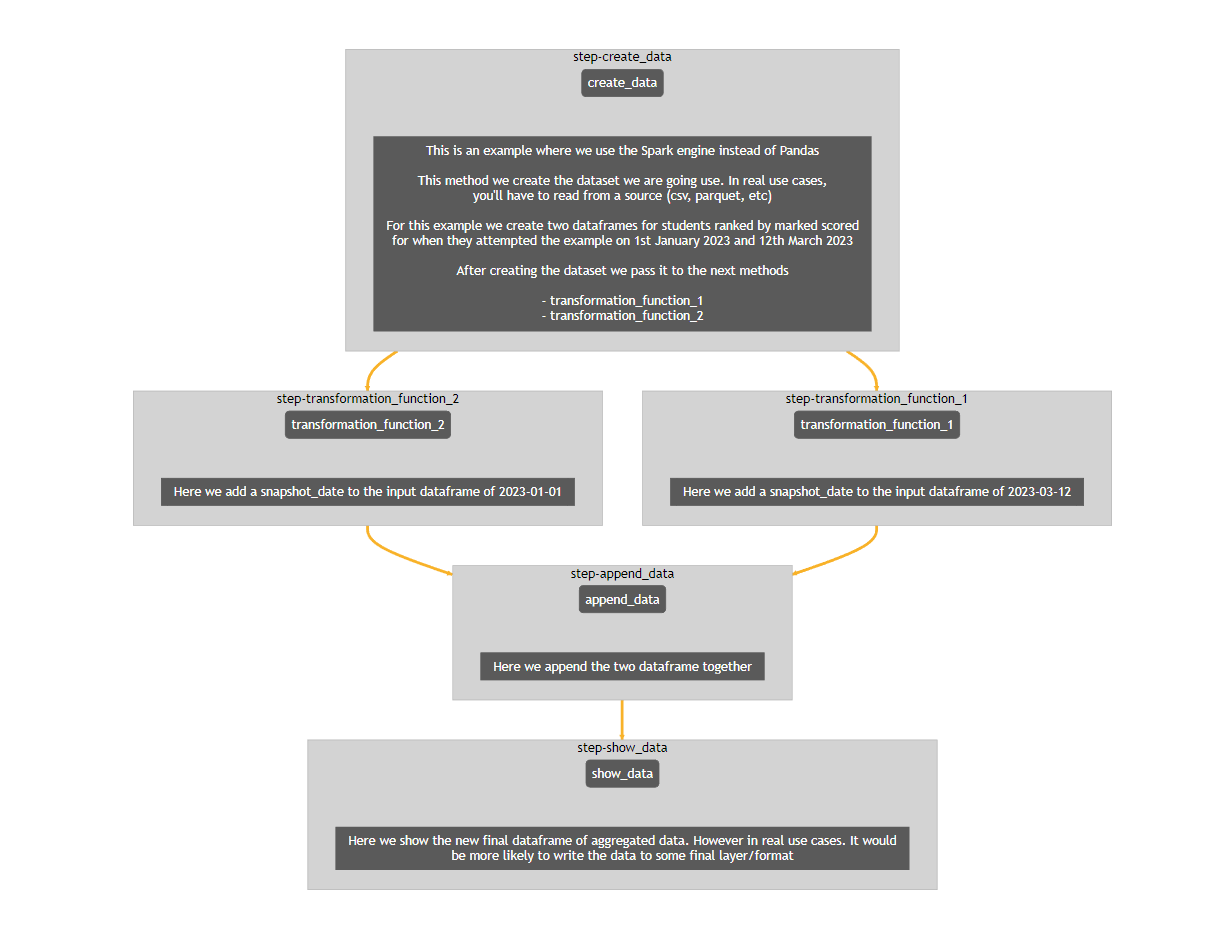
def create_data(self):
"""
This is an example where we use the Spark engine instead of Pandas
This method we create the dataset we are going use. In real use cases,
you'll have to read from a source (csv, parquet, etc)
For this example we create two dataframes for students ranked by marked scored
for when they attempted the example on 1st January 2023 and 12th March 2023
After creating the dataset we pass it to the next methods
- transformation_function_1
- transformation_function_2
"""
data1 = [
("Hermione",100),
("Harry", 85),
("Ron", 75),
]
data2 = [
("Hermione",100),
("Harry", 90),
("Ron", 80),
]
columns = ["Name", "marks"]
rdd1 = spark.sparkContext.parallelize(data1)
rdd2 = spark.sparkContext.parallelize(data2)
self.df1 = spark.createDataFrame(rdd1).toDF(*columns)
self.df2 = spark.createDataFrame(rdd2).toDF(*columns)
@step(next=["append_data"])
def transformation_function_1(self):
"""
Here we add a snapshot_date to the input dataframe of 2023-03-12
"""
self.transformed_df_1 = self.df1.withColumn("snapshot_date", lit("2023-03-12"))
@step(next=["append_data"])
def transformation_function_2(self):
"""
Here we add a snapshot_date to the input dataframe of 2023-01-01
"""
self.transformed_df_2 = self.df2.withColumn("snapshot_date", lit("2023-01-01"))
@step(next=["show_data"])
def append_data(self):
"""
Here we append the two dataframe together
"""
self.final_df = self.transformed_df_1.union(self.transformed_df_2)
@end
@step
def show_data(self):
"""
Here we show the new final dataframe of aggregated data. However in real use cases. It would
be more likely to write the data to some final layer/format
"""
self.final_df.show()
return self.final_df
```
Now when you run `ExamplePySpark().display()` you get the following output
## Documentation
Check out the latest documentation here: [FlowRunner documentation](https://flowrunner.readthedocs.io/en/latest/)
## Contributing
All contributions are welcome :smiley:
If you are interested in contributing, please check out this page: [FlowRunner Contribution Page](https://flowrunner.readthedocs.io/en/latest/contributing_guide_code.html)
Raw data
{
"_id": null,
"home_page": "",
"name": "flowrunner",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": "",
"keywords": "Data Engineering,Data Science",
"author": "",
"author_email": "Prithvijit Guha <prithvijit_guha2@hotmail.com>",
"download_url": "https://files.pythonhosted.org/packages/e9/78/1371e713fca0b2abfa7894cefa0b501a3eef9857566d37567d86a8d2d7b3/flowrunner-0.2.3.tar.gz",
"platform": null,
"description": "# flowrunner: A lightweight Data Engineering/Science Flow package\n\n[](https://codecov.io/gh/prithvijitguha/FlowRunner) \n \n \n \n[](https://flowrunner.readthedocs.io/en/latest/?badge=latest) \n[](https://www.python.org/downloads/release/python-380/) \n[](https://www.python.org/downloads/release/python-390/) \n[](https://github.com/psf/black) \n[](https://pycqa.github.io/isort/) \n[](https://github.com/pre-commit/pre-commit)\n\n## What is it?\n**flowrunner** is a lightweight package to organize and represent Data Engineering/Science workflows. Its designed to be\nintegrated with any pre-existing framework like pandas or PySpark\n\n## Main Features\n- Lazy evaluation of DAG: flowrunner does not force you to execute/run your dag until you want to, only run it when its explicitly mentioned as `run`\n- Easy syntax to build new Flows\n- Easy data sharing between methods in a `Flow` using attributes\n- Data store to store output of a function(incase it has `return`) for later\n- Param store to easily pass reusable parameters to `Flow`\n- Visualizing your flow as a DAG\n\n## Installing flowrunner\nTo install flowrunner, following commands will work\n\nSource code is hosted at https://github.com/prithvijitguha/flowRunner\n\n```sh\npip install flowrunner\n```\n\nOr install from source\n```sh\npip install git+https://github.com/prithvijitguha/flowrunner@main\n```\n\n## Usage\n\nHere is a quick example to run as is\n\n```python\n# example.py\nfrom flowrunner import BaseFlow, step, start, end\n\nclass ExampleFlow(BaseFlow):\n @start\n @step(next=['method2', 'method3'])\n def method1(self):\n self.a = 1\n\n @step(next=['method4'])\n def method2(self):\n self.a += 1\n\n @step(next=['method4'])\n def method3(self):\n self.a += 2\n\n @end\n @step\n def method4(self):\n self.a += 3\n print(\"output of flow is:\", self.a)\n```\n\nYou can run the flow with the following command\n```console\n$ python -m flowrunner run example.py\noutput of flow is: 7\n```\n\nOr in a notebook/script like this:\n\n```python\nExampleFlow.run()\n```\n\n\n## Visualize Flow as DAG(Directed Acyclical Graph)\n\n```python\nExampleFlow().display()\n```\n\nYour output will look like this.\n\n\n\n\nOr can be run in cli like this:\n\n```sh\npython -m flowrunner display example.py\n```\n\n\nFor CLI usage we create a file called `exampleflow.html` in the current directory with the same output\n\n## Show your Flow\n\n```python\nExampleFlow().show()\n```\n\n```console\n2023-03-08 22:35:24 LAPTOP flowrunner.system.logger[12692] INFO Found flow ExampleFlow\n2023-03-08 22:35:24 LAPTOP flowrunner.system.logger[12692] DEBUG Validating flow for ExampleFlow\n\u2705 Validated number of start nodes\n\u2705 Validated start nodes 'next' values\n\u2705 Validate number of middle_nodes\n\u2705 Validated middle_nodes 'next' values\n\u2705 Validated end nodes\n\u2705 Validated start nodes 'next' values\n2023-03-08 22:35:24 LAPTOP flowrunner.system.logger[12692] DEBUG Show flow for ExampleFlow\nmethod1\n\n?\n Next=method2, method3\n\n\nmethod2\n\n?\n Next=method4\n\n\nmethod3\n\n?\n Next=method4\n```\n\nOr through CLI like below\n```console\npython -m flowrunner show example.py\n```\n\n## Pandas Example\n\n```python\n\n# -*- coding: utf-8 -*-\nimport pandas as pd\n\nfrom flowrunner import BaseFlow, end, start, step\n\n\nclass ExamplePandas(BaseFlow):\n @start\n @step(next=[\"transformation_function_1\", \"transformation_function_2\"])\n def create_data(self):\n \"\"\"\n This method we create the dataset we are going use. In real use cases,\n you'll have to read from a source (csv, parquet, etc)\n\n For this example we create two dataframes for students ranked by marked scored\n for when they attempted the example on 1st January 2023 and 12th March 2023\n\n After creating the dataset we pass it to the next methods\n\n - transformation_function_1\n - transformation_function_2\n \"\"\"\n data1 = {\"Name\": [\"Hermione\", \"Harry\", \"Ron\"], \"marks\": [100, 85, 75]}\n\n data2 = {\"Name\": [\"Hermione\", \"Ron\", \"Harry\"], \"marks\": [100, 90, 80]}\n\n df1 = pd.DataFrame(data1, index=[\"rank1\", \"rank2\", \"rank3\"])\n\n df2 = pd.DataFrame(data2, index=[\"rank1\", \"rank2\", \"rank3\"])\n\n self.input_data_1 = df1\n self.input_data_2 = df2\n\n @step(next=[\"append_data\"])\n def transformation_function_1(self):\n \"\"\"\n Here we add a snapshot_date to the input dataframe of 2023-03-12\n \"\"\"\n transformed_df = self.input_data_1\n transformed_df.insert(1, \"snapshot_date\", \"2023-03-12\")\n self.transformed_df_1 = transformed_df\n\n @step(next=[\"append_data\"])\n def transformation_function_2(self):\n \"\"\"\n Here we add a snapshot_date to the input dataframe of 2023-01-01\n \"\"\"\n transformed_df = self.input_data_2\n transformed_df.insert(1, \"snapshot_date\", \"2023-01-01\")\n self.transformed_df_2 = transformed_df\n\n @step(next=[\"show_data\"])\n def append_data(self):\n \"\"\"\n Here we append the two dataframe together\n \"\"\"\n self.final_df = pd.concat([self.transformed_df_1, self.transformed_df_2])\n\n @end\n @step\n def show_data(self):\n \"\"\"\n Here we show the new final dataframe of aggregated data. However in real use cases. It would\n be more likely to write the data to some final layer/format\n \"\"\"\n print(self.final_df)\n return self.final_df\n```\n\nNow when you run `ExamplePandas().display()` you get the following output\n\n\n\n\n\n## PySpark Example\n\n```python\n\n# -*- coding: utf-8 -*-\nfrom pyspark.sql import SparkSession\nfrom pyspark.sql.functions import lit\n\nfrom flowrunner import BaseFlow, end, start, step\n\nspark = SparkSession.builder.getOrCreate()\n\n\nclass ExamplePySpark(BaseFlow):\n @start\n @step(next=[\"transformation_function_1\", \"transformation_function_2\"])\n def create_data(self):\n \"\"\"\n This is an example where we use the Spark engine instead of Pandas\n\n This method we create the dataset we are going use. In real use cases,\n you'll have to read from a source (csv, parquet, etc)\n\n For this example we create two dataframes for students ranked by marked scored\n for when they attempted the example on 1st January 2023 and 12th March 2023\n\n After creating the dataset we pass it to the next methods\n\n - transformation_function_1\n - transformation_function_2\n \"\"\"\n\n data1 = [\n (\"Hermione\",100),\n (\"Harry\", 85),\n (\"Ron\", 75),\n ]\n\n data2 = [\n (\"Hermione\",100),\n (\"Harry\", 90),\n (\"Ron\", 80),\n ]\n\n columns = [\"Name\", \"marks\"]\n\n rdd1 = spark.sparkContext.parallelize(data1)\n rdd2 = spark.sparkContext.parallelize(data2)\n self.df1 = spark.createDataFrame(rdd1).toDF(*columns)\n self.df2 = spark.createDataFrame(rdd2).toDF(*columns)\n\n @step(next=[\"append_data\"])\n def transformation_function_1(self):\n \"\"\"\n Here we add a snapshot_date to the input dataframe of 2023-03-12\n \"\"\"\n\n self.transformed_df_1 = self.df1.withColumn(\"snapshot_date\", lit(\"2023-03-12\"))\n\n @step(next=[\"append_data\"])\n def transformation_function_2(self):\n \"\"\"\n Here we add a snapshot_date to the input dataframe of 2023-01-01\n \"\"\"\n self.transformed_df_2 = self.df2.withColumn(\"snapshot_date\", lit(\"2023-01-01\"))\n\n @step(next=[\"show_data\"])\n def append_data(self):\n \"\"\"\n Here we append the two dataframe together\n \"\"\"\n self.final_df = self.transformed_df_1.union(self.transformed_df_2)\n\n @end\n @step\n def show_data(self):\n \"\"\"\n Here we show the new final dataframe of aggregated data. However in real use cases. It would\n be more likely to write the data to some final layer/format\n \"\"\"\n self.final_df.show()\n return self.final_df\n\n```\n\nNow when you run `ExamplePySpark().display()` you get the following output\n\n\n\n## Documentation\nCheck out the latest documentation here: [FlowRunner documentation](https://flowrunner.readthedocs.io/en/latest/)\n\n## Contributing\nAll contributions are welcome :smiley:\n\nIf you are interested in contributing, please check out this page: [FlowRunner Contribution Page](https://flowrunner.readthedocs.io/en/latest/contributing_guide_code.html)\n",
"bugtrack_url": null,
"license": "BSD 3-Clause License Copyright (c) 2023, Prithvijit All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. 3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. ",
"summary": "Flowrunner is a lightweight package to organize and represent Data Engineering/Science workflows",
"version": "0.2.3",
"project_urls": {
"Documentation": "https://flowrunner.readthedocs.io/en/latest/",
"Homepage": "https://github.com/prithvijitguha/flowrunner",
"Issues": "https://github.com/prithvijitguha/flowrunner/issues"
},
"split_keywords": [
"data engineering",
"data science"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "50c3661a3f8df2eb7a0c1a5a8207ea2a7a8505ee75d5d375074ba434da9b3a43",
"md5": "159756eddf2a96fd03e425176eeb547b",
"sha256": "16272ab0aa5303b9237eb4ba48bab416c5963c5147d56316341d2e7b3a99634b"
},
"downloads": -1,
"filename": "flowrunner-0.2.3-py3-none-any.whl",
"has_sig": false,
"md5_digest": "159756eddf2a96fd03e425176eeb547b",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.8",
"size": 29199,
"upload_time": "2023-06-08T15:59:51",
"upload_time_iso_8601": "2023-06-08T15:59:51.692079Z",
"url": "https://files.pythonhosted.org/packages/50/c3/661a3f8df2eb7a0c1a5a8207ea2a7a8505ee75d5d375074ba434da9b3a43/flowrunner-0.2.3-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "e9781371e713fca0b2abfa7894cefa0b501a3eef9857566d37567d86a8d2d7b3",
"md5": "2cc4d70fb032117075a66ff532953f5c",
"sha256": "0d56235b712a47aacd72bfa23a55c3e384d996f1df19c1fb9ee7359aa558c85f"
},
"downloads": -1,
"filename": "flowrunner-0.2.3.tar.gz",
"has_sig": false,
"md5_digest": "2cc4d70fb032117075a66ff532953f5c",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 303623,
"upload_time": "2023-06-08T15:59:53",
"upload_time_iso_8601": "2023-06-08T15:59:53.749268Z",
"url": "https://files.pythonhosted.org/packages/e9/78/1371e713fca0b2abfa7894cefa0b501a3eef9857566d37567d86a8d2d7b3/flowrunner-0.2.3.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-06-08 15:59:53",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "prithvijitguha",
"github_project": "flowrunner",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "flowrunner"
}
