| Name | know JSON |
| Version |
0.1.19
 JSON
JSON |
| download |
| home_page | https://github.com/otosense/know |
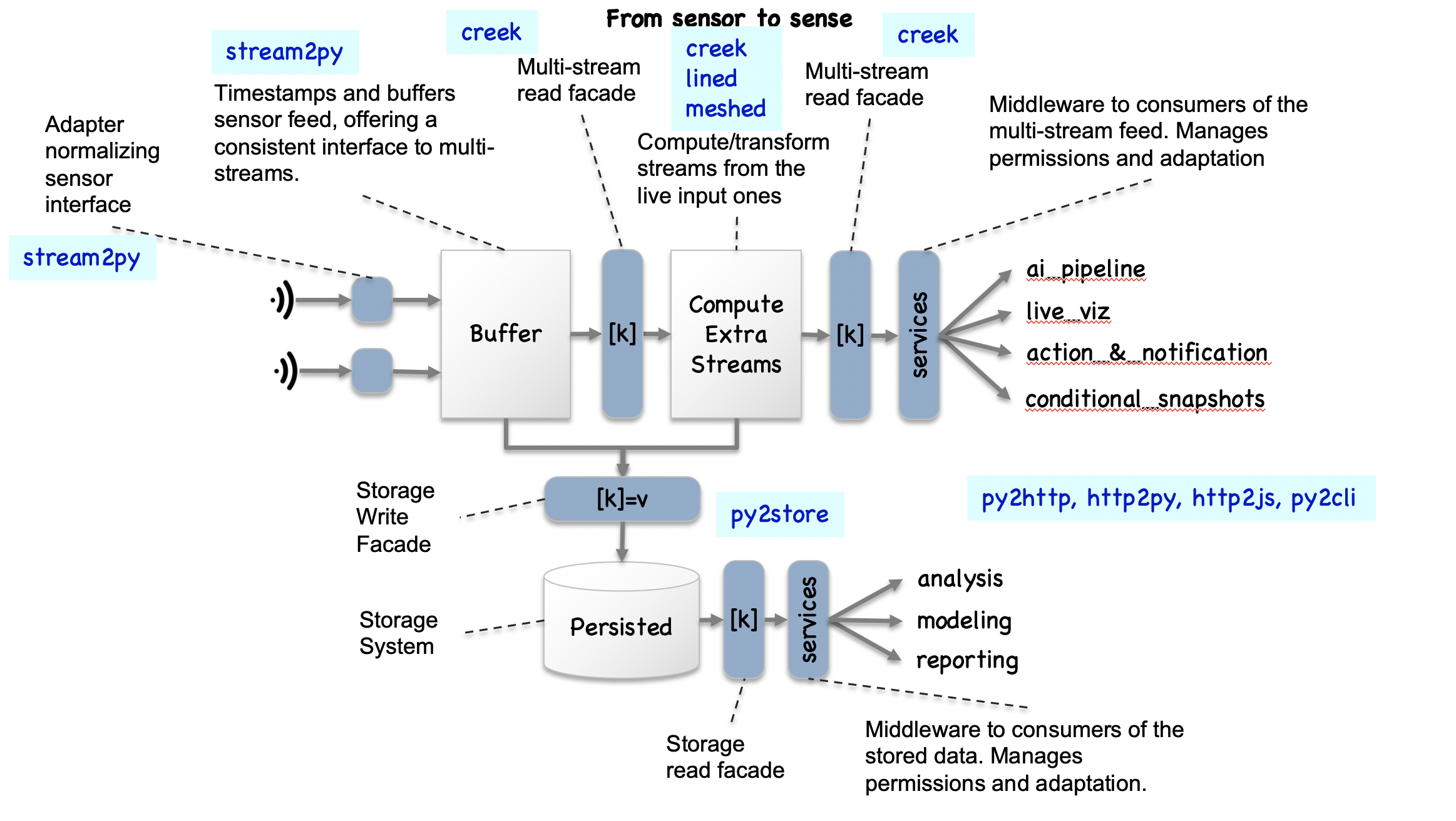
| Summary | Funnel live streams of data into storage and other processes |
| upload_time | 2023-01-12 13:20:23 |
| maintainer | |
| docs_url | None |
| author | OtoSense |
| requires_python | |
| license | apache-2.0 |
| keywords |
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# know
Build live stream tools
To install: ```pip install know```
The tools are made to be able to create live streams of data
(e.g. from sensors) and funnel them into proceses with a consistent interfaces.
One important process being the process that will store all or part of
the data, through a simple storage-system-agnositic facade.
```python
proc = LiveProc(
source=Sources( # make a multi-source object (which will manage buffering and timing)
audio=AudioSource(...),
plc=PlcSource(...),
video=VideoSource(...),
),
services=Services( # make a multi-data service (and/or writer/transformer) object
storage=Store(...),
notifications=Notif(...),
live_viz=LiveViz(...),
),
... # other settings for the process (logging, etc.)
)
proc() # run the process
```
With a variety of sources, target storage systems, etc.
# Examples
## Recording Audio
```python
from know.audio_to_store import *
wfs = demo_live_data_acquisition(chk_size=100_000, end_idx=300_000, logger=print)
print(f"{len(wfs)=}")
```
The `end_idx=300_000` is there to automatically stop the demo after 300 thousand bytes are acquired
(at the default rates that's about 1.5 seconds).
If you specify `end_idx=None`, the process will run until you interrupt it.
## Recording Audio, with more control
Here's what's actually being fed to the demo when you don't specify any explicit `live_source` or `store`.
You can use this to try different combinations of specs out:
```python
from know.audio_to_store import *
wfs = demo_live_data_acquisition(
live_source=LiveWf(
input_device_index=None, # if None, will try to guess the device index
sr=44100,
sample_width=2,
chk_size=4096,
stream_buffer_size_s=60,
),
store=mk_session_block_wf_store(
rootdir=None, # will choose one for you
# template examples: '{session}_{block}.wav' '{session}/d/{block}.pcm', '{session}/{block}', 'demo/s_{session}/blocks/{block}.wav'
template='{session}/d/{block}.pcm', #
pattern=r'\d+',
value_trans=int
),
chk_size=100_000,
end_idx=300_000,
logger=print
)
print(f"{len(wfs)=}")
```
What you want to see above, is how you can easily change the folder/file template you use to store data.
Below, we'll also show how you can change the data storage system backend completely,
using a mongo database instead!
##
Here, see how you can use MongoDB to store your data.
For this, you'll need to have a [mongoDB](https://www.mongodb.com/) server running locally,
and [mongodol](https://pypi.org/project/mongodol/) installed (`pip install mongodol`).
```python
from know.audio_to_store import mk_mongo_single_data
def _cast_data_field_to_json_list(d):
return list(map(int, d))
play_nice_with_json = wrap_kvs(data_of_obj=_cast_data_field_to_json_list)
mongo_store = play_nice_with_json(
mk_mongo_single_data(
mgc='mongodol/test', # enter here, the `db_name/collection_name` you want to use (uses local mongo client)
key_fields=('session', 'block'),
data_field='data'
)
)
wfs = demo_live_data_acquisition(
live_source=LiveWf(
input_device_index=None, # if None, will try to guess the device index
sr=44100,
sample_width=2,
chk_size=4096,
stream_buffer_size_s=60,
),
store=mongo_store,
chk_size=100_000,
end_idx=300_000,
logger=print
)
print(f"{len(wfs)=}")
```
Raw data
{
"_id": null,
"home_page": "https://github.com/otosense/know",
"name": "know",
"maintainer": "",
"docs_url": null,
"requires_python": "",
"maintainer_email": "",
"keywords": "",
"author": "OtoSense",
"author_email": "",
"download_url": "https://files.pythonhosted.org/packages/12/9f/e4e975f2112508d7e2b1b986292f1169951a55a55f9fcffe245b2559c755/know-0.1.19.tar.gz",
"platform": "any",
"description": "# know\n\nBuild live stream tools\n\nTo install:\t```pip install know```\n\nThe tools are made to be able to create live streams of data \n(e.g. from sensors) and funnel them into proceses with a consistent interfaces. \nOne important process being the process that will store all or part of \nthe data, through a simple storage-system-agnositic facade. \n\n```python\nproc = LiveProc(\n source=Sources( # make a multi-source object (which will manage buffering and timing)\n audio=AudioSource(...),\n plc=PlcSource(...),\n video=VideoSource(...),\n ),\n services=Services( # make a multi-data service (and/or writer/transformer) object\n storage=Store(...),\n notifications=Notif(...),\n live_viz=LiveViz(...),\n ),\n ... # other settings for the process (logging, etc.)\n)\n\nproc() # run the process\n```\n\nWith a variety of sources, target storage systems, etc.\n\n\n\n\n\n# Examples\n\n## Recording Audio\n\n```python\nfrom know.audio_to_store import *\n\nwfs = demo_live_data_acquisition(chk_size=100_000, end_idx=300_000, logger=print)\nprint(f\"{len(wfs)=}\")\n```\n\nThe `end_idx=300_000` is there to automatically stop the demo after 300 thousand bytes are acquired \n(at the default rates that's about 1.5 seconds). \n\nIf you specify `end_idx=None`, the process will run until you interrupt it.\n\n## Recording Audio, with more control\n\nHere's what's actually being fed to the demo when you don't specify any explicit `live_source` or `store`. \nYou can use this to try different combinations of specs out:\n\n```python\nfrom know.audio_to_store import *\n\nwfs = demo_live_data_acquisition(\n live_source=LiveWf(\n input_device_index=None, # if None, will try to guess the device index\n sr=44100,\n sample_width=2,\n chk_size=4096,\n stream_buffer_size_s=60,\n ),\n store=mk_session_block_wf_store(\n rootdir=None, # will choose one for you\n # template examples: '{session}_{block}.wav' '{session}/d/{block}.pcm', '{session}/{block}', 'demo/s_{session}/blocks/{block}.wav'\n template='{session}/d/{block}.pcm', # \n pattern=r'\\d+',\n value_trans=int\n ),\n chk_size=100_000,\n end_idx=300_000,\n logger=print\n)\nprint(f\"{len(wfs)=}\")\n```\n\nWhat you want to see above, is how you can easily change the folder/file template you use to store data. \n\nBelow, we'll also show how you can change the data storage system backend completely, \nusing a mongo database instead!\n\n\n## \n\nHere, see how you can use MongoDB to store your data. \nFor this, you'll need to have a [mongoDB](https://www.mongodb.com/) server running locally, \nand [mongodol](https://pypi.org/project/mongodol/) installed (`pip install mongodol`). \n\n```python\n\nfrom know.audio_to_store import mk_mongo_single_data\n\n\ndef _cast_data_field_to_json_list(d):\n return list(map(int, d))\n\n\nplay_nice_with_json = wrap_kvs(data_of_obj=_cast_data_field_to_json_list)\n\nmongo_store = play_nice_with_json(\n mk_mongo_single_data(\n mgc='mongodol/test', # enter here, the `db_name/collection_name` you want to use (uses local mongo client)\n key_fields=('session', 'block'),\n data_field='data'\n )\n)\n\nwfs = demo_live_data_acquisition(\n live_source=LiveWf(\n input_device_index=None, # if None, will try to guess the device index\n sr=44100,\n sample_width=2,\n chk_size=4096,\n stream_buffer_size_s=60,\n ),\n store=mongo_store,\n chk_size=100_000,\n end_idx=300_000,\n logger=print\n)\nprint(f\"{len(wfs)=}\")\n```",
"bugtrack_url": null,
"license": "apache-2.0",
"summary": "Funnel live streams of data into storage and other processes",
"version": "0.1.19",
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "129fe4e975f2112508d7e2b1b986292f1169951a55a55f9fcffe245b2559c755",
"md5": "264a9440f946361bc0a78d45604bdac4",
"sha256": "b024117a3678efa35163849c84a1c569348771e234bbd09dd9b72303ca90c266"
},
"downloads": -1,
"filename": "know-0.1.19.tar.gz",
"has_sig": false,
"md5_digest": "264a9440f946361bc0a78d45604bdac4",
"packagetype": "sdist",
"python_version": "source",
"requires_python": null,
"size": 38057,
"upload_time": "2023-01-12T13:20:23",
"upload_time_iso_8601": "2023-01-12T13:20:23.488060Z",
"url": "https://files.pythonhosted.org/packages/12/9f/e4e975f2112508d7e2b1b986292f1169951a55a55f9fcffe245b2559c755/know-0.1.19.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-01-12 13:20:23",
"github": true,
"gitlab": false,
"bitbucket": false,
"github_user": "otosense",
"github_project": "know",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "know"
}
