# labellint
**Stop wasting GPU hours. Lint your labels first.**
A high-precision, zero-BS command-line tool that finds thousands of logical inconsistencies and statistical anomalies in your computer vision annotation files before they silently kill your model's performance.
<div align="center">
</div>
---
## The Silent Killer: Why Your 45% mAP Isn't a Model Problem
You've done everything right. You've architected a state-of-the-art model, curated a massive dataset, and launched a multi-day training job on a multi-GPU node. The cloud provider bill is climbing into the thousands.
You wait 48 hours. **The result is 45% mAP.**
Your first instinct is to blame the code. You spend the next week in a demoralizing cycle of debugging the model, tweaking the optimizer, and re-tuning the learning rate. You are looking in the wrong place.
The problem isn't your model. It's your data. Buried deep within your `annotations.json` are thousands of tiny, invisible errors—the "data-centric bugs" that no amount of code-centric debugging can fix:
* **Logical Inconsistencies:** A single annotator on your team labeled `"Car"` while everyone else labeled `"car"`, fracturing your most important class and poisoning your class distribution.
* **Geometric Flaws:** A data conversion script produced a dozen bounding boxes with `width=0`. These are landmines for your data loader, causing silent failures or NaN losses that are impossible to trace.
* **Relational Errors:** An "orphaned" annotation points to an image that was deleted weeks ago, guaranteeing a `KeyError` deep inside your training loop.
* **Statistical Anomalies:** A handful of "sliver" bounding boxes with extreme 100:1 aspect ratios are creating massive, unstable gradients, preventing your model from converging.
These errors are the silent killers of MLOps. They are invisible to the naked eye and catastrophic to the training process. **`labellint` is the quality gate that makes them visible.**
## Installation: Get a Grip on Your Data in 60 Seconds
`labellint` is a standalone Python CLI tool. It requires Python 3.8+ and has no heavy dependencies. Get it with `pip`.
```bash
# It is recommended to install labellint within your project's virtual environment
pip install labellint
```
Verify the installation. You should see the help menu.
```bash
labellint --help
```
That's it. You're ready to scan.
## Usage: From Chaos to Clarity in One Command
The workflow is designed to be brutally simple. Point the `scan` command at your annotation file.
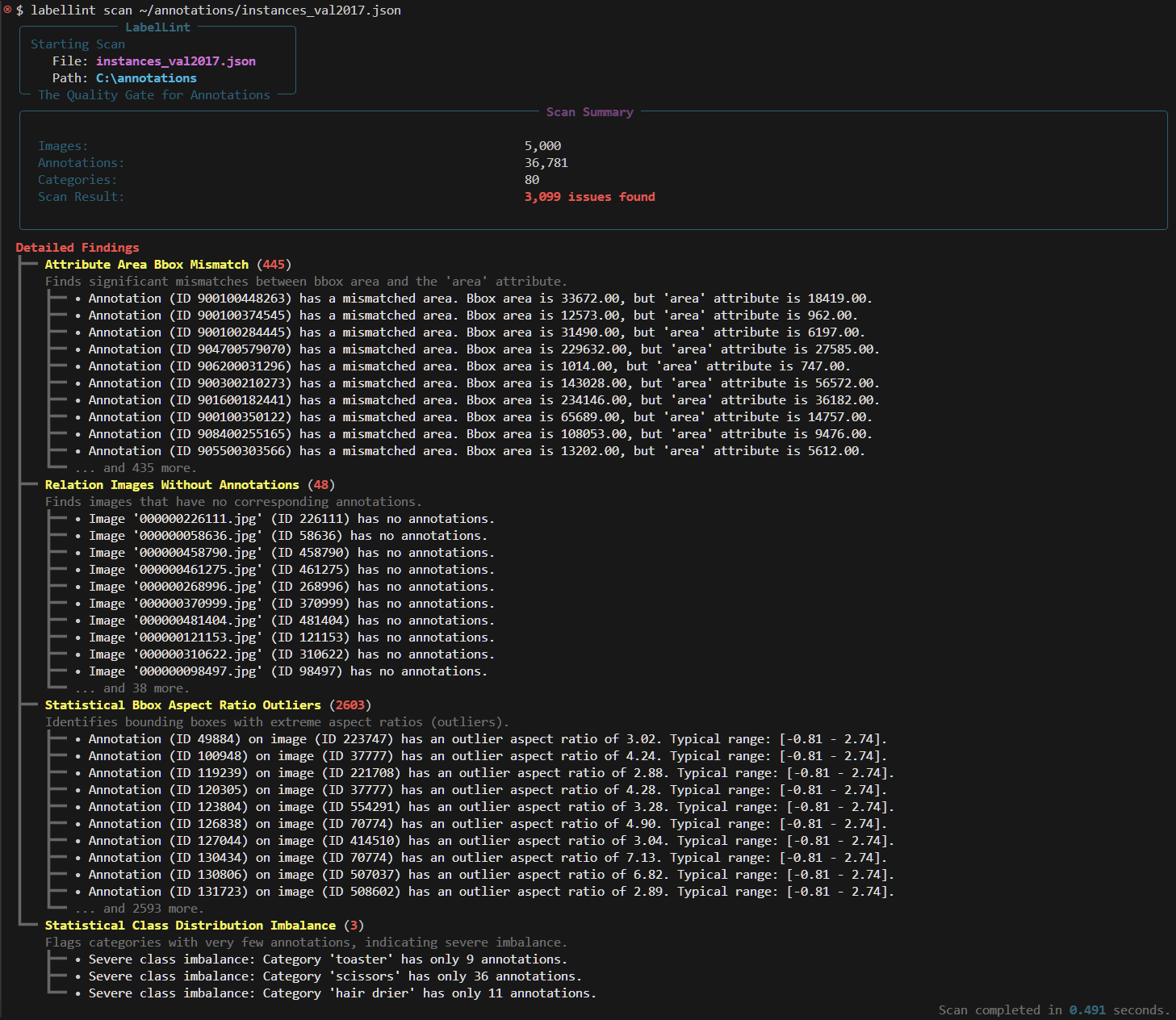
#### **1. Quick Interactive Scan**
This is your first-pass diagnostic. It provides a rich, color-coded summary directly in your terminal, truncated for readability.
```bash
labellint scan /path/to/your/coco_annotations.json
```
The output will immediately tell you the scale of your data quality problem.
#### **2. Full Report Export for Deep-Dive Analysis**
When the interactive scan reveals thousands of issues, you need the full, unfiltered list. Use the `--out` flag to dump a complete report in machine-readable JSON. The summary will still be printed to the terminal for context.
```bash
labellint scan /path/to/your/coco_annotations.json --out detailed_report.json
```
You now have a `detailed_report.json` file containing every single annotation ID, image ID, and error message, ready to be parsed by your data cleaning scripts or inspected in your editor.
#### **3. Integration as a CI/CD Quality Gate**
`labellint` is built for automation. The `scan` command exits with a status code of `0` if no issues are found and `1` if any issues are found. This allows you to use it as a non-negotiable quality gate in your training scripts or CI/CD pipelines.
**Prevent a bad dataset from ever reaching a GPU:**
```bash
# In your training script or Jenkins/GitHub Actions workflow
echo "--- Running Data Quality Check ---"
labellint scan ./data/train.json && {
echo "✅ Data quality check passed. Starting training job...";
python train.py --data ./data/;
} || {
echo "❌ Data quality check failed. Aborting training job.";
exit 1;
}
```
This simple command prevents thousands of dollars in wasted compute by ensuring that only validated, high-quality data enters the training pipeline.
## What It Finds: A Tour of the Arsenal
`labellint` is not a blunt instrument. It is a suite of precision tools, each designed to find a specific category of data error.
* **Schema & Relational Integrity:** This is the foundation. Does your data respect its own structure?
* **Orphaned Annotations:** Finds labels pointing to images that don't exist.
* **Orphaned Categories:** Finds labels pointing to categories that don't exist.
* **Duplicate Category IDs:** Catches critical schema violations where two different classes share the same ID.
* **Geometric & Attribute Validation:** This checks the physical properties of your labels.
* **Zero-Area Bounding Boxes:** Finds corrupt labels with a width or height of zero.
* **Out-of-Bounds Boxes:** Finds labels that extend beyond the pixel dimensions of their parent image.
* **Area/Bbox Mismatch:** Validates that `bbox` area (`w*h`) is consistent with the `area` field for non-polygonal labels, catching errors from bad data conversion.
* **Logical Consistency:** This catches the "human errors" that plague team-based annotation projects.
* **Inconsistent Capitalization:** The classic `"Car"` vs. `"car"` problem that can silently halve the number of examples for your most important class.
* **Duplicate Category Names:** Finds redundant definitions, e.g., two separate categories both named "person".
* **Statistical Anomaly Detection:** This is where `labellint` goes beyond simple errors to find high-risk patterns.
* **Bounding Box Aspect Ratio Outliers:** Uses statistical analysis (IQR) to find boxes with extreme aspect ratios. These are often annotation mistakes ("sliver boxes") that can destabilize model training.
* **Severe Class Imbalance:** Flags categories with a dangerously low number of annotations, providing a critical warning about data-starved classes *before* you discover them via poor performance metrics.
For a complete, up-to-date list of all rules and their descriptions, run `labellint rules`.
For a deep dive into the logic and implementation of each rule, please see the **[Project Wiki](https://github.com/SunK3R/labellint/wiki)**.
## The `labellint` Philosophy
1. **No Magic, Just Logic:** `labellint` is a deterministic, rules-based engine. It does not use AI to "guess" at errors. Its findings are repeatable, verifiable, and precise.
2. **Report, Don't Alter:** The tool will never modify your annotation files. Its sole purpose is to provide a high-fidelity report of potential issues. The engineer, as the domain expert, is always in control of the final decision.
3. **Speed is a Feature:** By operating only on metadata, `labellint` can analyze millions of annotations in seconds. This ensures it can be integrated into any workflow without becoming a bottleneck.
## Contributing
This is a new tool solving an old problem. Bug reports, feature requests, and pull requests are welcome. The project is built on a foundation of clean code and is enforced by a strict CI pipeline.
1. **Open an Issue:** Before starting work on a major contribution, please open an issue to discuss your idea.
2. **Set up the Development Environment:** Fork the repository and use `pip install -e ".[dev]"` to install the project in editable mode with all testing and linting dependencies.
3. **Adhere to Quality Standards:** All contributions must pass the full test suite (`pytest`) and the linter (`ruff check .`). We maintain 99% or Above test coverage.
## Changelog
Project updates and version history are documented in the [`CHANGELog.md`](https://github.com/SunK3R/labellint/blob/main/CHANGELOG.md) file.
---
Raw data
{
"_id": null,
"home_page": null,
"name": "labellint",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.9",
"maintainer_email": null,
"keywords": "computer-vision, annotations, linter, quality-assurance, data-validation, mlops, coco, yolo, pascal-voc, pydantic, cli",
"author": null,
"author_email": "Sooraj K R <soorajkr03@gmail.com>",
"download_url": "https://files.pythonhosted.org/packages/c7/c6/374732e96cdd1b0317966dd973c054a60a35db4e4411f985001e9549323c/labellint-0.1.2.tar.gz",
"platform": null,
"description": "# labellint\r\n\r\n**Stop wasting GPU hours. Lint your labels first.**\r\n\r\nA high-precision, zero-BS command-line tool that finds thousands of logical inconsistencies and statistical anomalies in your computer vision annotation files before they silently kill your model's performance.\r\n\r\n<div align=\"center\">\r\n\r\n\r\n\r\n</div>\r\n\r\n---\r\n\r\n## The Silent Killer: Why Your 45% mAP Isn't a Model Problem\r\n\r\nYou've done everything right. You've architected a state-of-the-art model, curated a massive dataset, and launched a multi-day training job on a multi-GPU node. The cloud provider bill is climbing into the thousands.\r\n\r\nYou wait 48 hours. **The result is 45% mAP.**\r\n\r\nYour first instinct is to blame the code. You spend the next week in a demoralizing cycle of debugging the model, tweaking the optimizer, and re-tuning the learning rate. You are looking in the wrong place.\r\n\r\nThe problem isn't your model. It's your data. Buried deep within your `annotations.json` are thousands of tiny, invisible errors\u2014the \"data-centric bugs\" that no amount of code-centric debugging can fix:\r\n\r\n* **Logical Inconsistencies:** A single annotator on your team labeled `\"Car\"` while everyone else labeled `\"car\"`, fracturing your most important class and poisoning your class distribution.\r\n* **Geometric Flaws:** A data conversion script produced a dozen bounding boxes with `width=0`. These are landmines for your data loader, causing silent failures or NaN losses that are impossible to trace.\r\n* **Relational Errors:** An \"orphaned\" annotation points to an image that was deleted weeks ago, guaranteeing a `KeyError` deep inside your training loop.\r\n* **Statistical Anomalies:** A handful of \"sliver\" bounding boxes with extreme 100:1 aspect ratios are creating massive, unstable gradients, preventing your model from converging.\r\n\r\nThese errors are the silent killers of MLOps. They are invisible to the naked eye and catastrophic to the training process. **`labellint` is the quality gate that makes them visible.**\r\n\r\n## Installation: Get a Grip on Your Data in 60 Seconds\r\n\r\n`labellint` is a standalone Python CLI tool. It requires Python 3.8+ and has no heavy dependencies. Get it with `pip`.\r\n\r\n```bash\r\n# It is recommended to install labellint within your project's virtual environment\r\npip install labellint\r\n```\r\n\r\nVerify the installation. You should see the help menu.\r\n```bash\r\nlabellint --help\r\n```\r\n\r\nThat's it. You're ready to scan.\r\n\r\n## Usage: From Chaos to Clarity in One Command\r\n\r\nThe workflow is designed to be brutally simple. Point the `scan` command at your annotation file.\r\n\r\n#### **1. Quick Interactive Scan**\r\n\r\nThis is your first-pass diagnostic. It provides a rich, color-coded summary directly in your terminal, truncated for readability.\r\n\r\n```bash\r\nlabellint scan /path/to/your/coco_annotations.json\r\n```\r\n\r\nThe output will immediately tell you the scale of your data quality problem.\r\n\r\n#### **2. Full Report Export for Deep-Dive Analysis**\r\n\r\nWhen the interactive scan reveals thousands of issues, you need the full, unfiltered list. Use the `--out` flag to dump a complete report in machine-readable JSON. The summary will still be printed to the terminal for context.\r\n\r\n```bash\r\nlabellint scan /path/to/your/coco_annotations.json --out detailed_report.json\r\n```\r\n\r\nYou now have a `detailed_report.json` file containing every single annotation ID, image ID, and error message, ready to be parsed by your data cleaning scripts or inspected in your editor.\r\n\r\n#### **3. Integration as a CI/CD Quality Gate**\r\n\r\n`labellint` is built for automation. The `scan` command exits with a status code of `0` if no issues are found and `1` if any issues are found. This allows you to use it as a non-negotiable quality gate in your training scripts or CI/CD pipelines.\r\n\r\n**Prevent a bad dataset from ever reaching a GPU:**\r\n\r\n```bash\r\n# In your training script or Jenkins/GitHub Actions workflow\r\necho \"--- Running Data Quality Check ---\"\r\nlabellint scan ./data/train.json && {\r\n echo \"\u2705 Data quality check passed. Starting training job...\";\r\n python train.py --data ./data/;\r\n} || {\r\n echo \"\u274c Data quality check failed. Aborting training job.\";\r\n exit 1;\r\n}\r\n```\r\nThis simple command prevents thousands of dollars in wasted compute by ensuring that only validated, high-quality data enters the training pipeline.\r\n\r\n## What It Finds: A Tour of the Arsenal\r\n\r\n`labellint` is not a blunt instrument. It is a suite of precision tools, each designed to find a specific category of data error.\r\n\r\n* **Schema & Relational Integrity:** This is the foundation. Does your data respect its own structure?\r\n * **Orphaned Annotations:** Finds labels pointing to images that don't exist.\r\n * **Orphaned Categories:** Finds labels pointing to categories that don't exist.\r\n * **Duplicate Category IDs:** Catches critical schema violations where two different classes share the same ID.\r\n\r\n* **Geometric & Attribute Validation:** This checks the physical properties of your labels.\r\n * **Zero-Area Bounding Boxes:** Finds corrupt labels with a width or height of zero.\r\n * **Out-of-Bounds Boxes:** Finds labels that extend beyond the pixel dimensions of their parent image.\r\n * **Area/Bbox Mismatch:** Validates that `bbox` area (`w*h`) is consistent with the `area` field for non-polygonal labels, catching errors from bad data conversion.\r\n\r\n* **Logical Consistency:** This catches the \"human errors\" that plague team-based annotation projects.\r\n * **Inconsistent Capitalization:** The classic `\"Car\"` vs. `\"car\"` problem that can silently halve the number of examples for your most important class.\r\n * **Duplicate Category Names:** Finds redundant definitions, e.g., two separate categories both named \"person\".\r\n\r\n* **Statistical Anomaly Detection:** This is where `labellint` goes beyond simple errors to find high-risk patterns.\r\n * **Bounding Box Aspect Ratio Outliers:** Uses statistical analysis (IQR) to find boxes with extreme aspect ratios. These are often annotation mistakes (\"sliver boxes\") that can destabilize model training.\r\n * **Severe Class Imbalance:** Flags categories with a dangerously low number of annotations, providing a critical warning about data-starved classes *before* you discover them via poor performance metrics.\r\n\r\nFor a complete, up-to-date list of all rules and their descriptions, run `labellint rules`.\r\n\r\nFor a deep dive into the logic and implementation of each rule, please see the **[Project Wiki](https://github.com/SunK3R/labellint/wiki)**.\r\n\r\n## The `labellint` Philosophy\r\n\r\n1. **No Magic, Just Logic:** `labellint` is a deterministic, rules-based engine. It does not use AI to \"guess\" at errors. Its findings are repeatable, verifiable, and precise.\r\n2. **Report, Don't Alter:** The tool will never modify your annotation files. Its sole purpose is to provide a high-fidelity report of potential issues. The engineer, as the domain expert, is always in control of the final decision.\r\n3. **Speed is a Feature:** By operating only on metadata, `labellint` can analyze millions of annotations in seconds. This ensures it can be integrated into any workflow without becoming a bottleneck.\r\n\r\n## Contributing\r\n\r\nThis is a new tool solving an old problem. Bug reports, feature requests, and pull requests are welcome. The project is built on a foundation of clean code and is enforced by a strict CI pipeline.\r\n\r\n1. **Open an Issue:** Before starting work on a major contribution, please open an issue to discuss your idea.\r\n2. **Set up the Development Environment:** Fork the repository and use `pip install -e \".[dev]\"` to install the project in editable mode with all testing and linting dependencies.\r\n3. **Adhere to Quality Standards:** All contributions must pass the full test suite (`pytest`) and the linter (`ruff check .`). We maintain 99% or Above test coverage.\r\n\r\n## Changelog\r\n\r\nProject updates and version history are documented in the [`CHANGELog.md`](https://github.com/SunK3R/labellint/blob/main/CHANGELOG.md) file.\r\n\r\n---\r\n",
"bugtrack_url": null,
"license": null,
"summary": "A high-precision CLI for finding errors in your computer vision annotation files before you waste GPU hours.",
"version": "0.1.2",
"project_urls": {
"Bug Tracker": "https://github.com/SunK3R/labellint/issues",
"Documentation": "https://github.com/SunK3R/labellint/blob/main/README.md",
"Homepage": "https://github.com/SunK3R/labellint",
"License": "https://github.com/SunK3R/labellint/blob/main/LICENSE",
"Repository": "https://github.com/SunK3R/labellint"
},
"split_keywords": [
"computer-vision",
" annotations",
" linter",
" quality-assurance",
" data-validation",
" mlops",
" coco",
" yolo",
" pascal-voc",
" pydantic",
" cli"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "139e939dc51f6b0b268cbb6ca5d1866919c09aa86e521bd15e30454bb96c7668",
"md5": "a5b64493630bf71fbfadccf2dee3844a",
"sha256": "38f00d1b3584399f7fa2f6d8212be136ead0332ea45dc2d9014fec0a56c56bc8"
},
"downloads": -1,
"filename": "labellint-0.1.2-py3-none-any.whl",
"has_sig": false,
"md5_digest": "a5b64493630bf71fbfadccf2dee3844a",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.9",
"size": 18987,
"upload_time": "2025-07-21T12:44:55",
"upload_time_iso_8601": "2025-07-21T12:44:55.945873Z",
"url": "https://files.pythonhosted.org/packages/13/9e/939dc51f6b0b268cbb6ca5d1866919c09aa86e521bd15e30454bb96c7668/labellint-0.1.2-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "c7c6374732e96cdd1b0317966dd973c054a60a35db4e4411f985001e9549323c",
"md5": "5e1ba5c87c286f309373e009421dac65",
"sha256": "51cee8461c208121680095c291d47cbae10ff02576d61761bb31447f008a7e73"
},
"downloads": -1,
"filename": "labellint-0.1.2.tar.gz",
"has_sig": false,
"md5_digest": "5e1ba5c87c286f309373e009421dac65",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.9",
"size": 34499,
"upload_time": "2025-07-21T12:44:57",
"upload_time_iso_8601": "2025-07-21T12:44:57.549632Z",
"url": "https://files.pythonhosted.org/packages/c7/c6/374732e96cdd1b0317966dd973c054a60a35db4e4411f985001e9549323c/labellint-0.1.2.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-07-21 12:44:57",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "SunK3R",
"github_project": "labellint",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "labellint"
}

