
# lpd
A Fast, Flexible Trainer with Callbacks and Extensions for PyTorch
``lpd`` derives from the Hebrew word *lapid* (לפיד) which means "torch".
## For latest PyPI stable release
[](https://badge.fury.io/py/lpd)
[](https://pepy.tech/project/lpd)

<!--  -->
There are 2 types of ``lpd`` packages available
* ``lpd`` which brings dependencies for pytorch, numpy and tensorboard
```sh
pip install lpd
```
* ``lpd-nodeps`` which **you provide** your own dependencies for pytorch, numpy and tensorboard
```sh
pip install lpd-nodeps
```
<b>[v0.4.10-beta](https://github.com/RoySadaka/lpd/releases) Release - contains the following:</b>
* ``TransformerEncoderStack`` to support activation as input
* ``PositionalEncoding`` to support more than 3 dimensions input
Previously on lpd:
* Updated Pipfile
* Fixed confusion matrix cpu/gpu device error
* Better handling on callbacks where apply_on_states=None (apply on all states)
* Bug fix in case validation samples are empty
* Bug fix in verbosity level 2 in train
* Verbosity change in torch_utils
* Fix to PositionalEncoding to be batch first
* Minor change to MatMul2D, use torch.matmul instead of torch.bmm
* Bug fix when saving full trainer that has tensorboard callback
* Added LossOptimizerHandlerAccumulateSamples
* Added LossOptimizerHandlerAccumulateBatches
## Usage
``lpd`` intended to properly structure your PyTorch model training.
The main usages are given below.
### Training your model
```python
from lpd.trainer import Trainer
from lpd.enums import Phase, State, MonitorType, MonitorMode, StatsType
from lpd.callbacks import LossOptimizerHandler, StatsPrint, ModelCheckPoint, Tensorboard, EarlyStopping, SchedulerStep, CallbackMonitor
from lpd.extensions.custom_schedulers import KerasDecay
from lpd.metrics import BinaryAccuracyWithLogits, FalsePositives
from lpd.utils.torch_utils import get_gpu_device_if_available
from lpd.utils.general_utils import seed_all
from lpd.utils.threshold_checker import AbsoluteThresholdChecker
seed_all(seed=42) # because its the answer to life and the universe
device = get_gpu_device_if_available() # with fallback to CPU if GPU not available
model = MyModel().to(device) # this is your model class, and its being sent to the relevant device
optimizer = torch.optim.SGD(params=model.parameters())
scheduler = KerasDecay(optimizer, decay=0.01, last_step=-1) # decay scheduler using keras formula
loss_func = torch.nn.BCEWithLogitsLoss().to(device) # this is your loss class, already sent to the relevant device
metrics = [BinaryAccuracyWithLogits(name='Accuracy'), FalsePositives(name='FP', num_class=2, threshold=0)] # define your metrics
# you can use some of the defined callbacks, or you can create your own
callbacks = [
LossOptimizerHandler(),
SchedulerStep(apply_on_phase=Phase.BATCH_END, apply_on_states=State.TRAIN),
ModelCheckPoint(checkpoint_dir,
checkpoint_file_name,
CallbackMonitor(monitor_type=MonitorType.LOSS,
stats_type=StatsType.VAL,
monitor_mode=MonitorMode.MIN),
save_best_only=True),
Tensorboard(summary_writer_dir=summary_writer_dir),
EarlyStopping(CallbackMonitor(monitor_type=MonitorType.METRIC,
stats_type=StatsType.VAL,
monitor_mode=MonitorMode.MAX,
patience=10,
metric_name='Accuracy'),
threshold_checker=AbsoluteThresholdChecker(monitor_mode=MonitorMode.MAX, threshold=0.01)),
StatsPrint(train_metrics_monitors=[CallbackMonitor(monitor_type=MonitorType.METRIC,
stats_type=StatsType.TRAIN,
monitor_mode=MonitorMode.MAX, # <-- notice MAX
metric_name='Accuracy'),
CallbackMonitor(monitor_type=MonitorType.METRIC,
stats_type=StatsType.TRAIN,
monitor_mode=MonitorMode.MIN, # <-- notice MIN
metric_name='FP')],
print_confusion_matrix=True) # since one of the metric (FalsePositives) is confusion matrix based, lets print the whole confusion matrix
]
trainer = Trainer(model,
device,
loss_func,
optimizer,
scheduler,
metrics,
train_data_loader, # DataLoader, Iterable or Generator
val_data_loader, # DataLoader, Iterable or Generator
train_steps,
val_steps,
callbacks,
name='Readme-Example')
trainer.train(num_epochs)
```
### Evaluating your model
``trainer.evaluate`` will return ``StatsResult`` that stores the loss and metrics results for the test set
```python
evaluation_result = trainer.evaluate(test_data_loader, test_steps)
```
### Making predictions
``Predictor`` class will generate output predictions from input samples.
``Predictor`` class can be created from ``Trainer``
```python
predictor_from_trainer = Predictor.from_trainer(trainer)
predictions = predictor_from_trainer.predict_batch(batch)
```
``Predictor`` class can also be created from saved checkpoint
```python
predictor_from_checkpoint = Predictor.from_checkpoint(checkpoint_dir,
checkpoint_file_name,
model, # nn.Module, weights will be loaded from checkpoint
device)
prediction = predictor_from_checkpoint.predict_sample(sample)
```
Lastly, ``Predictor`` class can be initialized explicitly
```python
predictor = Predictor(model,
device,
callbacks, # relevant only for prediction callbacks (see callbacks Phases and States)
name='lpd predictor')
predictions = predictor.predict_data_loader(data_loader, steps)
```
Just to be fair, you can also predict directly from ``Trainer`` class
```python
# On single sample:
prediction = trainer.predict_sample(sample)
# On batch:
predictions = trainer.predict_batch(batch)
# On Dataloader/Iterable/Generator:
predictions = trainer.predict_data_loader(data_loader, steps)
```
## TrainerStats
``Trainer`` tracks stats for `train/validate/test` and you can access them in your custom callbacks
or any other place that has access to your trainer.
Here are some examples
```python
train_loss = trainer.train_stats.get_loss() # the mean of the last epoch's train losses
val_loss = trainer.val_stats.get_loss() # the mean of the last epoch's validation losses
test_loss = trainer.test_stats.get_loss() # the mean of the test losses (available only after calling evaluate)
train_metrics = trainer.train_stats.get_metrics() # dict(metric_name, MetricMethod(values)) of the current epoch in train state
val_metrics = trainer.val_stats.get_metrics() # dict(metric_name, MetricMethod(values)) of the current epoch in validation state
test_metrics = trainer.test_stats.get_metrics() # dict(metric_name, MetricMethod(values)) of the test (available only after calling evaluate)
```
## Callbacks
Will be used to perform actions at various stages.
Some common callbacks are available under ``lpd.callbacks``, and you can also create your own, more details below.
In a callback, ``apply_on_phase`` (``lpd.enums.Phase``) will determine the execution phase,
and ``apply_on_states`` (``lpd.enums.State`` or ``list(lpd.enums.State)``) will determine the execution states
These are the current available phases and states, more might be added in future releases
### Training and Validation phases and states will behave as follow
```python
State.EXTERNAL
Phase.TRAIN_BEGIN
# train loop:
Phase.EPOCH_BEGIN
State.TRAIN
# batches loop:
Phase.BATCH_BEGIN
# batch
Phase.BATCH_END
State.VAL
# batches loop:
Phase.BATCH_BEGIN
# batch
Phase.BATCH_END
State.EXTERNAL
Phase.EPOCH_END
Phase.TRAIN_END
```
### Evaluation phases and states will behave as follow
```python
State.EXTERNAL
Phase.TEST_BEGIN
State.TEST
# batches loop:
Phase.BATCH_BEGIN
# batch
Phase.BATCH_END
State.EXTERNAL
Phase.TEST_END
```
### Predict phases and states will behave as follow
```python
State.EXTERNAL
Phase.PREDICT_BEGIN
State.PREDICT
# batches loop:
Phase.BATCH_BEGIN
# batch
Phase.BATCH_END
State.EXTERNAL
Phase.PREDICT_END
```
Callbacks will be executed under the relevant phase and state, and by their order.
With phases and states, you have full control over the timing of your callbacks.
Let's take a look at some of the callbacks ``lpd`` provides:
### LossOptimizerHandler Callback
Derives from ``LossOptimizerHandlerBase``, probably the most important callback during training 😎
Use ``LossOptimizerHandler`` to determine when to call:
```python
loss.backward(...)
optimizer.step(...)
optimizer.zero_grad(...)
```
Or, you may choose to create your own ``AwesomeLossOptimizerHandler`` class by deriving from ``LossOptimizerHandlerBase``.
``Trainer.train(...)`` will validate that at least one ``LossOptimizerHandlerBase`` callback was provided.
### LossOptimizerHandlerAccumulateBatches Callback
As well as ``LossOptimizerHandlerAccumulateSamples`` will call loss.backward() every batch, but invoke optimizer.step() and optimizer.zero_grad()
only after the defined num of batches (or samples) were accumulated
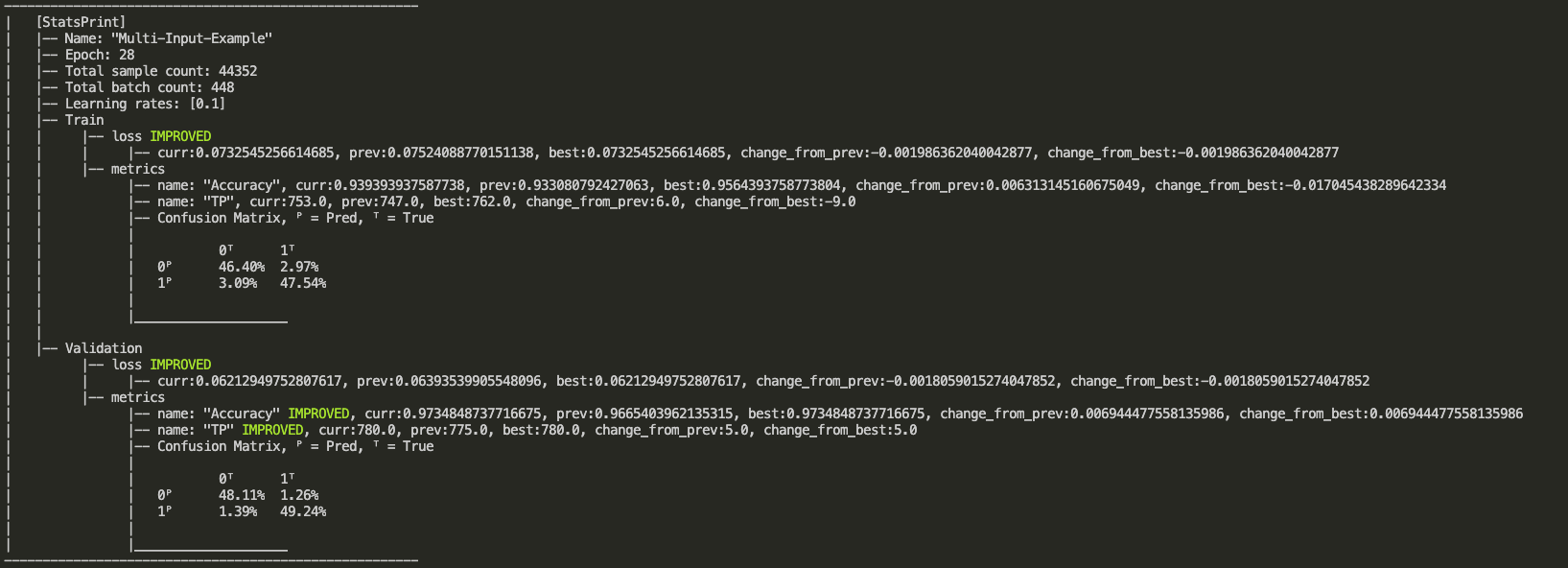
### StatsPrint Callback
``StatsPrint`` callback prints informative summary of the trainer stats including loss and metrics.
* ``CallbackMonitor`` can add nicer look with ``IMPROVED`` indication on improved loss or metric, see output example below.
* Loss (for all states) will be monitored as ``MonitorMode.MIN``
* For train metrics, provide your own monitors via ``train_metrics_monitors`` argument
* Validation metrics monitors will be added automatically according to ``train_metrics_monitors`` argument
```python
from lpd.enums import Phase, State, MonitorType, StatsType, MonitorMode
StatsPrint(apply_on_phase=Phase.EPOCH_END,
apply_on_states=State.EXTERNAL,
train_metrics_monitors=CallbackMonitor(monitor_type=MonitorType.METRIC,
stats_type=StatsType.TRAIN,
monitor_mode=MonitorMode.MAX,
metric_name='TruePositives'),
print_confusion_matrix_normalized=True) # in case you use one of the ConfusionMatrix metrics (e.g. TruePositives), you may also print the confusion matrix
```
Output example:
### ModelCheckPoint Callback
Saving a checkpoint when a monitored loss/metric has improved.
The callback will save the model, optimizer, scheduler, and epoch number.
You can also configure it to save Full Trainer.
For example, ``ModelCheckPoint`` that will save a new *full trainer checkpoint* every time the validation metric_name ``my_metric``
is getting higher than the highest value so far.
```python
ModelCheckPoint(Phase.EPOCH_END,
State.EXTERNAL,
checkpoint_dir,
checkpoint_file_name,
CallbackMonitor(monitor_type=MonitorType.METRIC, # It's a Metric and not a Loss
stats_type=StatsType.VAL, # check the value on the Validation set
monitor_mode=MonitorMode.MAX, # MAX indicates higher is better
metric_name='my_metric'), # since it's a Metric, mention its name
save_best_only=False,
save_full_trainer=True)
```
### EarlyStopping Callback
Stops the trainer when a monitored loss/metric has stopped improving.
For example, EarlyStopping that will monitor at the end of every epoch, and stop the trainer if the validation loss didn't improve (decrease) for the last 10 epochs.
```python
EarlyStopping(Phase.EPOCH_END,
State.EXTERNAL,
CallbackMonitor(monitor_type=MonitorType.LOSS,
stats_type=StatsType.VAL,
monitor_mode=MonitorMode.MIN,
patience=10))
```
### SchedulerStep Callback
Will invoke ``step()`` on your scheduler in the desired phase and state.
For example, SchedulerStep callback to invoke ``scheduler.step()`` at the end of every batch, in train state (as opposed to validation and test):
```python
from lpd.callbacks import SchedulerStep
from lpd.enums import Phase, State
SchedulerStep(apply_on_phase=Phase.BATCH_END, apply_on_states=State.TRAIN)
```
### Tensorboard Callback
Will export the loss and the metrics at a given phase and state, in a format that can be viewed on Tensorboard
```python
from lpd.callbacks import Tensorboard
Tensorboard(apply_on_phase=Phase.EPOCH_END,
apply_on_states=State.EXTERNAL,
summary_writer_dir=dir_path)
```
### TensorboardImage Callback
Will export images, in a format that can be viewed on Tensorboard.
For example, a TensorboardImage callback that will output all the images generated in validation
```python
from lpd.callbacks import TensorboardImage
TensorboardImage(apply_on_phase=Phase.BATCH_END,
apply_on_states=State.VAL,
summary_writer_dir=dir_path,
description='Generated Images',
outputs_parser=None)
```
Lets pass outputs_parser that will change the range of the outputs from [-1,1] to [0,255]
```python
from lpd.callbacks import TensorboardImage
def outputs_parser(input_output_label: InputOutputLabel):
outputs_scaled = (input_output_label.outputs + 1.0) / 2.0 * 255
outputs_scaled = torchvision.utils.make_grid(input_output_label.output)
return outputs_scaled
TensorboardImage(apply_on_phase=Phase.BATCH_END,
apply_on_states=State.VAL,
summary_writer_dir=dir_path,
description='Generated Images',
outputs_parser=outputs_parser)
```
### CollectOutputs Callback
Will collect model's outputs for the defined states.
CollectOutputs is automatically used by ``Trainer`` to collect the predictions when calling one of the ``predict`` methods.
```python
CollectOutputs(apply_on_phase=Phase.BATCH_END, apply_on_states=State.VAL)
```
### Create your custom callbacks
```python
from lpd.enums import Phase, State
from lpd.callbacks import CallbackBase
class MyAwesomeCallback(CallbackBase):
def __init__(self, apply_on_phase=Phase.BATCH_END, apply_on_states=[State.TRAIN, State.VAL]):
# make sure to call init parent class
super(MyAwesomeCallback, self).__init__(apply_on_phase, apply_on_states)
def __call__(self, callback_context): # <=== implement this method!
# your implementation here
# using callback_context, you can access anything in your trainer
# below are some examples to get the hang of it
val_loss = callback_context.val_stats.get_loss()
train_loss = callback_context.train_stats.get_loss()
train_metrics = callback_context.train_stats.get_metrics()
val_metrics = callback_context.val_stats.get_metrics()
optimizer = callback_context.optimizer
scheduler = callback_context.scheduler
trainer = callback_context.trainer
if val_loss < 0.0001:
# you can also mark the trainer to STOP training by calling stop()
trainer.stop()
```
Lets expand ``MyAwesomeCallback`` with ``CallbackMonitor`` to track if our validation loss is getting better
```python
from lpd.callbacks import CallbackBase, CallbackMonitor # <== CallbackMonitor added
from lpd.enums import Phase, State, MonitorType, StatsType, MonitorMode # <== added few needed enums to configure CallbackMonitor
class MyAwesomeCallback(CallbackBase):
def __init__(self, apply_on_phase=Phase.BATCH_END, apply_on_states=[State.TRAIN, State.VAL]):
super(MyAwesomeCallback, self).__init__(apply_on_phase, apply_on_states)
# adding CallbackMonitor to track VAL LOSS with regards to MIN (lower is better) and patience of 20 epochs
self.val_loss_monitor = CallbackMonitor(MonitorType.LOSS, StatsType.VAL, MonitorMode.MIN, patience=20)
def __call__(self, callback_context: CallbackContext): # <=== implement this method!
# same as before, using callback_context, you can access anything in your trainer
train_metrics = callback_context.train_stats.get_metrics()
val_metrics = callback_context.val_stats.get_metrics()
# invoke track() method on your monitor and pass callback_context as parameter
# since you configured your val_loss_monitor, it will get the relevant parameters from callback_context
monitor_result = self.val_loss_monitor.track(callback_context)
# monitor_result (lpd.callbacks.CallbackMonitorResult) contains informative properties
# for example lets check the status of the patience countdown
if monitor_result.has_patience():
print(f'[MyAwesomeCallback] - patience left: {monitor_result.patience_left}')
# Or, let's stop the trainer, by calling the trainer.stop()
# if our monitored value did not improve
if not monitor_result.has_improved():
print(f'[MyAwesomeCallback] - {monitor_result.description} has stopped improving')
callback_context.trainer.stop()
```
### CallbackMonitor, AbsoluteThresholdChecker and RelativeThresholdChecker
When using callbacks such as ``EarlyStopping``, a ``CallbackMonitor`` is provided to track
a certain metric and reset/trigger the stopping event (or any event in other callbacks).
``CallbackMonitor`` will internally use ``ThresholdChecker`` when comparing new value to old value
for the tracked metric, and ``AbsoluteThresholdChecker`` or ``RelativeThresholdChecker`` will be used
to check if the criteria was met.
The following example creates a ``CallbackMonitor`` that will track if the metric 'accuracy'
has increased with more then 1% using ``RelativeThresholdChecker``
```python
from lpd.utils.threshold_checker import RelativeThresholdChecker
relative_threshold_checker_1_percent = RelativeThresholdChecker(monitor_mode=MonitorMode.MAX, threshold=0.01)
CallbackMonitor(monitor_type=MonitorType.METRIC, # It's a Metric and not a Loss
stats_type=StatsType.VAL, # check the value on the Validation set
monitor_mode=MonitorMode.MAX, # MAX indicates higher is better
metric_name='accuracy', # since it's a Metric, mention its name
threshold_checker=relative_threshold_checker_1_percent) # track 1% increase from last highest value
```
## Metrics
``lpd.metrics`` provides metrics to check the accuracy of your model.
Let's create a custom metric using ``MetricBase`` and also show the use of ``BinaryAccuracyWithLogits`` in this example
```python
from lpd.metrics import BinaryAccuracyWithLogits, MetricBase
from lpd.enums import MetricMethod
# our custom metric
class InaccuracyWithLogits(MetricBase):
def __init__(self):
super(InaccuracyWithLogits, self).__init__(MetricMethod.MEAN) # use mean over the batches
self.bawl = BinaryAccuracyWithLogits() # we exploit BinaryAccuracyWithLogits for the computation
def __call__(self, y_pred, y_true): # <=== implement this method!
# your implementation here
acc = self.bawl(y_pred, y_true)
return 1 - acc # return the inaccuracy
# we can now define our metrics and pass them to the trainer
metrics = [BinaryAccuracyWithLogits(name='accuracy'), InaccuracyWithLogits(name='inaccuracy')]
```
Let's do another example, a custom metric ``Truthfulness`` based on confusion matrix using ``MetricConfusionMatrixBase``
```python
from lpd.metrics import MetricConfusionMatrixBase, TruePositives, TrueNegatives
from lpd.enums import ConfusionMatrixBasedMetric
# our custom metric
class Truthfulness(MetricConfusionMatrixBase):
def __init__(self, num_classes, labels=None, predictions_to_classes_convertor=None, threshold=0.5):
super(Truthfulness, self).__init__(num_classes, labels, predictions_to_classes_convertor, threshold)
self.tp = TruePositives(num_classes, labels, predictions_to_classes_convertor, threshold) # we exploit TruePositives for the computation
self.tn = TrueNegatives(num_classes, labels, predictions_to_classes_convertor, threshold) # we exploit TrueNegatives for the computation
def __call__(self, y_pred, y_true): # <=== implement this method!
tp_per_class = self.tp(y_pred, y_true)
tn_per_class = self.tn(y_pred, y_true)
# you can also access more confusion matrix metrics such as
f1score = self.get_stats(ConfusionMatrixBasedMetric.F1SCORE)
precision = self.get_stats(ConfusionMatrixBasedMetric.PRECISION)
recall = self.get_stats(ConfusionMatrixBasedMetric.RECALL)
# see ConfusionMatrixBasedMetric enum for more
return tp_per_class + tn_per_class
```
## Save and Load full Trainer
Sometimes you just want to save everything so you can continue training where you left off.
To do so, you may use ``ModelCheckPoint`` for saving full trainer by setting parameter
```python
save_full_trainer=True
```
Or, you can invoke it directly from your trainer
```python
your_trainer.save_trainer(dir_path, file_name)
```
Loading a trainer from checkpoint is as simple as:
```python
loaded_trainer = Trainer.load_trainer(dir_path, # the folder where the saved trainer file exists
trainer_file_name, # the saved trainer file name
model, # state_dict will be loaded
device,
loss_func, # state_dict will be loaded
optimizer, # state_dict will be loaded
scheduler, # state_dict will be loaded
train_data_loader, # provide new/previous data_loader
val_data_loader, # provide new/previous data_loader
train_steps,
val_steps)
```
### Utils
``lpd.utils`` provides ``torch_utils``, ``file_utils`` and ``general_utils``
For example, a good practice is to use ``seed_all`` as early as possible in your code, to make sure that results are reproducible:
```python
import lpd.utils.general_utils as gu
gu.seed_all(seed=42) # because its the answer to life and the universe
```
### Extensions
``lpd.extensions`` provides some custom PyTorch layers, and schedulers, these are just some stuff we like using when we create our models, to gain better flexibility.
So you can use them at your own will, more extensions are added from time to time.
## TODOS (more added frequently)
* Add Logger
* Add support for multiple schedulers
* Add support for multiple losses
* Add colab examples
## Something is missing?! please share with us
You can open an issue, but also feel free to email us at torch.lpd@gmail.com
Raw data
{
"_id": null,
"home_page": "https://github.com/roysadaka/lpd",
"name": "lpd-nodeps",
"maintainer": "lpd developers",
"docs_url": null,
"requires_python": ">=3.9",
"maintainer_email": "torch.lpd@gmail.com",
"keywords": "lpd-nodeps",
"author": "Roy Sadaka",
"author_email": "",
"download_url": "",
"platform": null,
"description": "\n\n# lpd\n\nA Fast, Flexible Trainer with Callbacks and Extensions for PyTorch\n\n``lpd`` derives from the Hebrew word *lapid* (\u05dc\u05e4\u05d9\u05d3) which means \"torch\".\n\n\n\n## For latest PyPI stable release \n[](https://badge.fury.io/py/lpd) \n[](https://pepy.tech/project/lpd)\n\n<!--  -->\n\nThere are 2 types of ``lpd`` packages available \n* ``lpd`` which brings dependencies for pytorch, numpy and tensorboard\n```sh\n pip install lpd\n```\n\n* ``lpd-nodeps`` which **you provide** your own dependencies for pytorch, numpy and tensorboard\n```sh\n pip install lpd-nodeps\n```\n\n<b>[v0.4.10-beta](https://github.com/RoySadaka/lpd/releases) Release - contains the following:</b> \n\n* ``TransformerEncoderStack`` to support activation as input\n* ``PositionalEncoding`` to support more than 3 dimensions input\n\n\nPreviously on lpd:\n* Updated Pipfile\n* Fixed confusion matrix cpu/gpu device error\n* Better handling on callbacks where apply_on_states=None (apply on all states)\n* Bug fix in case validation samples are empty\n* Bug fix in verbosity level 2 in train\n* Verbosity change in torch_utils\n* Fix to PositionalEncoding to be batch first\n* Minor change to MatMul2D, use torch.matmul instead of torch.bmm\n* Bug fix when saving full trainer that has tensorboard callback\n* Added LossOptimizerHandlerAccumulateSamples \n* Added LossOptimizerHandlerAccumulateBatches\n\n\n## Usage\n\n``lpd`` intended to properly structure your PyTorch model training. \nThe main usages are given below.\n\n### Training your model\n\n```python\n from lpd.trainer import Trainer\n from lpd.enums import Phase, State, MonitorType, MonitorMode, StatsType\n from lpd.callbacks import LossOptimizerHandler, StatsPrint, ModelCheckPoint, Tensorboard, EarlyStopping, SchedulerStep, CallbackMonitor\n from lpd.extensions.custom_schedulers import KerasDecay\n from lpd.metrics import BinaryAccuracyWithLogits, FalsePositives\n from lpd.utils.torch_utils import get_gpu_device_if_available\n from lpd.utils.general_utils import seed_all\n from lpd.utils.threshold_checker import AbsoluteThresholdChecker\n\n seed_all(seed=42) # because its the answer to life and the universe\n\n device = get_gpu_device_if_available() # with fallback to CPU if GPU not available\n model = MyModel().to(device) # this is your model class, and its being sent to the relevant device\n optimizer = torch.optim.SGD(params=model.parameters())\n scheduler = KerasDecay(optimizer, decay=0.01, last_step=-1) # decay scheduler using keras formula \n loss_func = torch.nn.BCEWithLogitsLoss().to(device) # this is your loss class, already sent to the relevant device\n metrics = [BinaryAccuracyWithLogits(name='Accuracy'), FalsePositives(name='FP', num_class=2, threshold=0)] # define your metrics\n \n\n # you can use some of the defined callbacks, or you can create your own\n callbacks = [\n LossOptimizerHandler(),\n SchedulerStep(apply_on_phase=Phase.BATCH_END, apply_on_states=State.TRAIN),\n ModelCheckPoint(checkpoint_dir, \n checkpoint_file_name, \n CallbackMonitor(monitor_type=MonitorType.LOSS, \n stats_type=StatsType.VAL, \n monitor_mode=MonitorMode.MIN),\n save_best_only=True), \n Tensorboard(summary_writer_dir=summary_writer_dir),\n EarlyStopping(CallbackMonitor(monitor_type=MonitorType.METRIC, \n stats_type=StatsType.VAL, \n monitor_mode=MonitorMode.MAX,\n patience=10,\n metric_name='Accuracy'),\n threshold_checker=AbsoluteThresholdChecker(monitor_mode=MonitorMode.MAX, threshold=0.01)),\n StatsPrint(train_metrics_monitors=[CallbackMonitor(monitor_type=MonitorType.METRIC,\n stats_type=StatsType.TRAIN,\n monitor_mode=MonitorMode.MAX, # <-- notice MAX\n metric_name='Accuracy'),\n CallbackMonitor(monitor_type=MonitorType.METRIC,\n stats_type=StatsType.TRAIN,\n monitor_mode=MonitorMode.MIN, # <-- notice MIN\n metric_name='FP')],\n print_confusion_matrix=True) # since one of the metric (FalsePositives) is confusion matrix based, lets print the whole confusion matrix\n ]\n\n trainer = Trainer(model, \n device, \n loss_func, \n optimizer,\n scheduler,\n metrics, \n train_data_loader, # DataLoader, Iterable or Generator\n val_data_loader, # DataLoader, Iterable or Generator\n train_steps,\n val_steps,\n callbacks,\n name='Readme-Example')\n \n trainer.train(num_epochs)\n```\n\n### Evaluating your model\n``trainer.evaluate`` will return ``StatsResult`` that stores the loss and metrics results for the test set \n```python\n evaluation_result = trainer.evaluate(test_data_loader, test_steps)\n```\n\n\n### Making predictions\n``Predictor`` class will generate output predictions from input samples.\n\n``Predictor`` class can be created from ``Trainer``\n```python\n predictor_from_trainer = Predictor.from_trainer(trainer)\n predictions = predictor_from_trainer.predict_batch(batch)\n```\n\n``Predictor`` class can also be created from saved checkpoint\n```python\n predictor_from_checkpoint = Predictor.from_checkpoint(checkpoint_dir,\n checkpoint_file_name,\n model, # nn.Module, weights will be loaded from checkpoint\n device)\n prediction = predictor_from_checkpoint.predict_sample(sample)\n```\nLastly, ``Predictor`` class can be initialized explicitly\n```python\n predictor = Predictor(model,\n device,\n callbacks, # relevant only for prediction callbacks (see callbacks Phases and States)\n name='lpd predictor')\n predictions = predictor.predict_data_loader(data_loader, steps)\n```\n\nJust to be fair, you can also predict directly from ``Trainer`` class \n```python\n # On single sample:\n prediction = trainer.predict_sample(sample)\n # On batch:\n predictions = trainer.predict_batch(batch)\n # On Dataloader/Iterable/Generator:\n predictions = trainer.predict_data_loader(data_loader, steps)\n```\n\n## TrainerStats\n``Trainer`` tracks stats for `train/validate/test` and you can access them in your custom callbacks\nor any other place that has access to your trainer.\n\nHere are some examples\n```python\n train_loss = trainer.train_stats.get_loss() # the mean of the last epoch's train losses\n val_loss = trainer.val_stats.get_loss() # the mean of the last epoch's validation losses\n test_loss = trainer.test_stats.get_loss() # the mean of the test losses (available only after calling evaluate)\n\n train_metrics = trainer.train_stats.get_metrics() # dict(metric_name, MetricMethod(values)) of the current epoch in train state\n val_metrics = trainer.val_stats.get_metrics() # dict(metric_name, MetricMethod(values)) of the current epoch in validation state\n test_metrics = trainer.test_stats.get_metrics() # dict(metric_name, MetricMethod(values)) of the test (available only after calling evaluate)\n```\n\n\n## Callbacks\nWill be used to perform actions at various stages. \nSome common callbacks are available under ``lpd.callbacks``, and you can also create your own, more details below. \nIn a callback, ``apply_on_phase`` (``lpd.enums.Phase``) will determine the execution phase, \nand ``apply_on_states`` (``lpd.enums.State`` or ``list(lpd.enums.State)``) will determine the execution states \nThese are the current available phases and states, more might be added in future releases\n\n### Training and Validation phases and states will behave as follow\n```python\n State.EXTERNAL\n Phase.TRAIN_BEGIN\n # train loop:\n Phase.EPOCH_BEGIN\n\n State.TRAIN\n # batches loop:\n Phase.BATCH_BEGIN\n # batch\n Phase.BATCH_END\n State.VAL\n # batches loop:\n Phase.BATCH_BEGIN\n # batch\n Phase.BATCH_END\n State.EXTERNAL\n\n Phase.EPOCH_END\n Phase.TRAIN_END\n```\n\n### Evaluation phases and states will behave as follow\n```python\n State.EXTERNAL\n Phase.TEST_BEGIN\n State.TEST\n # batches loop:\n Phase.BATCH_BEGIN\n # batch\n Phase.BATCH_END\n State.EXTERNAL\n Phase.TEST_END\n```\n\n\n### Predict phases and states will behave as follow\n```python\n State.EXTERNAL\n Phase.PREDICT_BEGIN\n State.PREDICT\n # batches loop:\n Phase.BATCH_BEGIN\n # batch\n Phase.BATCH_END\n State.EXTERNAL\n Phase.PREDICT_END\n```\nCallbacks will be executed under the relevant phase and state, and by their order. \nWith phases and states, you have full control over the timing of your callbacks. \nLet's take a look at some of the callbacks ``lpd`` provides:\n\n### LossOptimizerHandler Callback\nDerives from ``LossOptimizerHandlerBase``, probably the most important callback during training \ud83d\ude0e \nUse ``LossOptimizerHandler`` to determine when to call: \n```python\n loss.backward(...)\n optimizer.step(...)\n optimizer.zero_grad(...)\n```\nOr, you may choose to create your own ``AwesomeLossOptimizerHandler`` class by deriving from ``LossOptimizerHandlerBase``. \n``Trainer.train(...)`` will validate that at least one ``LossOptimizerHandlerBase`` callback was provided.\n\n### LossOptimizerHandlerAccumulateBatches Callback\nAs well as ``LossOptimizerHandlerAccumulateSamples`` will call loss.backward() every batch, but invoke optimizer.step() and optimizer.zero_grad() \nonly after the defined num of batches (or samples) were accumulated \n\n\n### StatsPrint Callback\n``StatsPrint`` callback prints informative summary of the trainer stats including loss and metrics. \n* ``CallbackMonitor`` can add nicer look with ``IMPROVED`` indication on improved loss or metric, see output example below. \n* Loss (for all states) will be monitored as ``MonitorMode.MIN``\n* For train metrics, provide your own monitors via ``train_metrics_monitors`` argument\n* Validation metrics monitors will be added automatically according to ``train_metrics_monitors`` argument\n\n```python\n from lpd.enums import Phase, State, MonitorType, StatsType, MonitorMode\n\n StatsPrint(apply_on_phase=Phase.EPOCH_END, \n apply_on_states=State.EXTERNAL, \n train_metrics_monitors=CallbackMonitor(monitor_type=MonitorType.METRIC,\n stats_type=StatsType.TRAIN,\n monitor_mode=MonitorMode.MAX,\n metric_name='TruePositives'),\n print_confusion_matrix_normalized=True) # in case you use one of the ConfusionMatrix metrics (e.g. TruePositives), you may also print the confusion matrix \n```\nOutput example: \n\n\n\n\n\n### ModelCheckPoint Callback\nSaving a checkpoint when a monitored loss/metric has improved. \nThe callback will save the model, optimizer, scheduler, and epoch number. \nYou can also configure it to save Full Trainer. \nFor example, ``ModelCheckPoint`` that will save a new *full trainer checkpoint* every time the validation metric_name ``my_metric`` \nis getting higher than the highest value so far.\n\n```python\n ModelCheckPoint(Phase.EPOCH_END, \n State.EXTERNAL,\n checkpoint_dir, \n checkpoint_file_name,\n CallbackMonitor(monitor_type=MonitorType.METRIC, # It's a Metric and not a Loss \n stats_type=StatsType.VAL, # check the value on the Validation set\n monitor_mode=MonitorMode.MAX, # MAX indicates higher is better\n metric_name='my_metric'), # since it's a Metric, mention its name\n save_best_only=False, \n save_full_trainer=True)\n```\n\n### EarlyStopping Callback\nStops the trainer when a monitored loss/metric has stopped improving. \nFor example, EarlyStopping that will monitor at the end of every epoch, and stop the trainer if the validation loss didn't improve (decrease) for the last 10 epochs.\n```python\nEarlyStopping(Phase.EPOCH_END, \n State.EXTERNAL,\n CallbackMonitor(monitor_type=MonitorType.LOSS, \n stats_type=StatsType.VAL, \n monitor_mode=MonitorMode.MIN,\n patience=10))\n```\n\n### SchedulerStep Callback\n\nWill invoke ``step()`` on your scheduler in the desired phase and state. \nFor example, SchedulerStep callback to invoke ``scheduler.step()`` at the end of every batch, in train state (as opposed to validation and test):\n```python\n from lpd.callbacks import SchedulerStep\n from lpd.enums import Phase, State\n SchedulerStep(apply_on_phase=Phase.BATCH_END, apply_on_states=State.TRAIN)\n```\n\n\n### Tensorboard Callback\nWill export the loss and the metrics at a given phase and state, in a format that can be viewed on Tensorboard \n```python\n from lpd.callbacks import Tensorboard\n Tensorboard(apply_on_phase=Phase.EPOCH_END, \n apply_on_states=State.EXTERNAL, \n summary_writer_dir=dir_path)\n```\n\n\n### TensorboardImage Callback\nWill export images, in a format that can be viewed on Tensorboard. \nFor example, a TensorboardImage callback that will output all the images generated in validation\n```python\n from lpd.callbacks import TensorboardImage\n TensorboardImage(apply_on_phase=Phase.BATCH_END, \n apply_on_states=State.VAL, \n summary_writer_dir=dir_path,\n description='Generated Images',\n outputs_parser=None)\n```\nLets pass outputs_parser that will change the range of the outputs from [-1,1] to [0,255]\n```python\n from lpd.callbacks import TensorboardImage\n\n def outputs_parser(input_output_label: InputOutputLabel):\n outputs_scaled = (input_output_label.outputs + 1.0) / 2.0 * 255\n outputs_scaled = torchvision.utils.make_grid(input_output_label.output)\n return outputs_scaled\n\n TensorboardImage(apply_on_phase=Phase.BATCH_END, \n apply_on_states=State.VAL, \n summary_writer_dir=dir_path,\n description='Generated Images',\n outputs_parser=outputs_parser)\n```\n\n\n### CollectOutputs Callback\nWill collect model's outputs for the defined states. \nCollectOutputs is automatically used by ``Trainer`` to collect the predictions when calling one of the ``predict`` methods. \n```python\n CollectOutputs(apply_on_phase=Phase.BATCH_END, apply_on_states=State.VAL)\n```\n\n### Create your custom callbacks\n\n```python\n from lpd.enums import Phase, State\n from lpd.callbacks import CallbackBase\n\n class MyAwesomeCallback(CallbackBase):\n def __init__(self, apply_on_phase=Phase.BATCH_END, apply_on_states=[State.TRAIN, State.VAL]):\n # make sure to call init parent class\n super(MyAwesomeCallback, self).__init__(apply_on_phase, apply_on_states)\n\n def __call__(self, callback_context): # <=== implement this method!\n # your implementation here\n # using callback_context, you can access anything in your trainer\n # below are some examples to get the hang of it\n val_loss = callback_context.val_stats.get_loss()\n train_loss = callback_context.train_stats.get_loss()\n train_metrics = callback_context.train_stats.get_metrics()\n val_metrics = callback_context.val_stats.get_metrics()\n optimizer = callback_context.optimizer\n scheduler = callback_context.scheduler\n trainer = callback_context.trainer\n\n if val_loss < 0.0001:\n # you can also mark the trainer to STOP training by calling stop()\n trainer.stop()\n```\n\nLets expand ``MyAwesomeCallback`` with ``CallbackMonitor`` to track if our validation loss is getting better\n```python\n from lpd.callbacks import CallbackBase, CallbackMonitor # <== CallbackMonitor added\n from lpd.enums import Phase, State, MonitorType, StatsType, MonitorMode # <== added few needed enums to configure CallbackMonitor\n\n class MyAwesomeCallback(CallbackBase):\n def __init__(self, apply_on_phase=Phase.BATCH_END, apply_on_states=[State.TRAIN, State.VAL]):\n super(MyAwesomeCallback, self).__init__(apply_on_phase, apply_on_states)\n \n # adding CallbackMonitor to track VAL LOSS with regards to MIN (lower is better) and patience of 20 epochs\n self.val_loss_monitor = CallbackMonitor(MonitorType.LOSS, StatsType.VAL, MonitorMode.MIN, patience=20)\n\n def __call__(self, callback_context: CallbackContext): # <=== implement this method!\n # same as before, using callback_context, you can access anything in your trainer\n train_metrics = callback_context.train_stats.get_metrics()\n val_metrics = callback_context.val_stats.get_metrics()\n\n # invoke track() method on your monitor and pass callback_context as parameter\n # since you configured your val_loss_monitor, it will get the relevant parameters from callback_context\n monitor_result = self.val_loss_monitor.track(callback_context)\n\n # monitor_result (lpd.callbacks.CallbackMonitorResult) contains informative properties\n # for example lets check the status of the patience countdown\n\n if monitor_result.has_patience():\n print(f'[MyAwesomeCallback] - patience left: {monitor_result.patience_left}')\n\n # Or, let's stop the trainer, by calling the trainer.stop()\n # if our monitored value did not improve\n\n if not monitor_result.has_improved():\n print(f'[MyAwesomeCallback] - {monitor_result.description} has stopped improving')\n callback_context.trainer.stop()\n```\n\n\n### CallbackMonitor, AbsoluteThresholdChecker and RelativeThresholdChecker\nWhen using callbacks such as ``EarlyStopping``, a ``CallbackMonitor`` is provided to track \na certain metric and reset/trigger the stopping event (or any event in other callbacks). \n \n``CallbackMonitor`` will internally use ``ThresholdChecker`` when comparing new value to old value \nfor the tracked metric, and ``AbsoluteThresholdChecker`` or ``RelativeThresholdChecker`` will be used \nto check if the criteria was met. \nThe following example creates a ``CallbackMonitor`` that will track if the metric 'accuracy' \nhas increased with more then 1% using ``RelativeThresholdChecker``\n```python\n from lpd.utils.threshold_checker import RelativeThresholdChecker\n relative_threshold_checker_1_percent = RelativeThresholdChecker(monitor_mode=MonitorMode.MAX, threshold=0.01)\n\n CallbackMonitor(monitor_type=MonitorType.METRIC, # It's a Metric and not a Loss \n stats_type=StatsType.VAL, # check the value on the Validation set\n monitor_mode=MonitorMode.MAX, # MAX indicates higher is better\n metric_name='accuracy', # since it's a Metric, mention its name\n threshold_checker=relative_threshold_checker_1_percent) # track 1% increase from last highest value \n```\n\n\n\n## Metrics\n``lpd.metrics`` provides metrics to check the accuracy of your model. \nLet's create a custom metric using ``MetricBase`` and also show the use of ``BinaryAccuracyWithLogits`` in this example\n```python\n from lpd.metrics import BinaryAccuracyWithLogits, MetricBase\n from lpd.enums import MetricMethod\n\n # our custom metric\n class InaccuracyWithLogits(MetricBase):\n def __init__(self):\n super(InaccuracyWithLogits, self).__init__(MetricMethod.MEAN) # use mean over the batches\n self.bawl = BinaryAccuracyWithLogits() # we exploit BinaryAccuracyWithLogits for the computation\n\n def __call__(self, y_pred, y_true): # <=== implement this method!\n # your implementation here\n acc = self.bawl(y_pred, y_true)\n return 1 - acc # return the inaccuracy\n\n # we can now define our metrics and pass them to the trainer\n metrics = [BinaryAccuracyWithLogits(name='accuracy'), InaccuracyWithLogits(name='inaccuracy')]\n``` \n\nLet's do another example, a custom metric ``Truthfulness`` based on confusion matrix using ``MetricConfusionMatrixBase``\n```python\n from lpd.metrics import MetricConfusionMatrixBase, TruePositives, TrueNegatives\n from lpd.enums import ConfusionMatrixBasedMetric\n\n # our custom metric\n class Truthfulness(MetricConfusionMatrixBase):\n def __init__(self, num_classes, labels=None, predictions_to_classes_convertor=None, threshold=0.5):\n super(Truthfulness, self).__init__(num_classes, labels, predictions_to_classes_convertor, threshold)\n self.tp = TruePositives(num_classes, labels, predictions_to_classes_convertor, threshold) # we exploit TruePositives for the computation\n self.tn = TrueNegatives(num_classes, labels, predictions_to_classes_convertor, threshold) # we exploit TrueNegatives for the computation\n\n def __call__(self, y_pred, y_true): # <=== implement this method!\n tp_per_class = self.tp(y_pred, y_true)\n tn_per_class = self.tn(y_pred, y_true)\n\n # you can also access more confusion matrix metrics such as\n f1score = self.get_stats(ConfusionMatrixBasedMetric.F1SCORE)\n precision = self.get_stats(ConfusionMatrixBasedMetric.PRECISION)\n recall = self.get_stats(ConfusionMatrixBasedMetric.RECALL)\n # see ConfusionMatrixBasedMetric enum for more \n\n return tp_per_class + tn_per_class\n``` \n\n\n## Save and Load full Trainer\nSometimes you just want to save everything so you can continue training where you left off. \nTo do so, you may use ``ModelCheckPoint`` for saving full trainer by setting parameter\n```python\n save_full_trainer=True\n``` \nOr, you can invoke it directly from your trainer\n```python\n your_trainer.save_trainer(dir_path, file_name)\n``` \n\nLoading a trainer from checkpoint is as simple as:\n```python\n loaded_trainer = Trainer.load_trainer(dir_path, # the folder where the saved trainer file exists \n trainer_file_name, # the saved trainer file name \n model, # state_dict will be loaded\n device,\n loss_func, # state_dict will be loaded\n optimizer, # state_dict will be loaded\n scheduler, # state_dict will be loaded\n train_data_loader, # provide new/previous data_loader\n val_data_loader, # provide new/previous data_loader\n train_steps,\n val_steps)\n``` \n\n### Utils\n``lpd.utils`` provides ``torch_utils``, ``file_utils`` and ``general_utils`` \nFor example, a good practice is to use ``seed_all`` as early as possible in your code, to make sure that results are reproducible:\n```python\n import lpd.utils.general_utils as gu\n gu.seed_all(seed=42) # because its the answer to life and the universe\n```\n\n\n### Extensions\n``lpd.extensions`` provides some custom PyTorch layers, and schedulers, these are just some stuff we like using when we create our models, to gain better flexibility. \nSo you can use them at your own will, more extensions are added from time to time.\n\n## TODOS (more added frequently)\n* Add Logger\n* Add support for multiple schedulers \n* Add support for multiple losses\n* Add colab examples\n\n## Something is missing?! please share with us\nYou can open an issue, but also feel free to email us at torch.lpd@gmail.com\n",
"bugtrack_url": null,
"license": "MIT Licences",
"summary": "A Fast, Flexible Trainer with Callbacks and Extensions for PyTorch",
"version": "0.4.10",
"split_keywords": [
"lpd-nodeps"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "ec7a1101131471f370a0e7c837665874f0504c1c03d4a5157de5fee0cb7470c3",
"md5": "d852810f35860134f06132a06f453d47",
"sha256": "9117f55114eee6d4eb5148803a6d60fae0b8dea93fa78d78ba4ff277899aa9fa"
},
"downloads": -1,
"filename": "lpd_nodeps-0.4.10-py3-none-any.whl",
"has_sig": false,
"md5_digest": "d852810f35860134f06132a06f453d47",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.9",
"size": 48038,
"upload_time": "2023-02-04T06:43:48",
"upload_time_iso_8601": "2023-02-04T06:43:48.132059Z",
"url": "https://files.pythonhosted.org/packages/ec/7a/1101131471f370a0e7c837665874f0504c1c03d4a5157de5fee0cb7470c3/lpd_nodeps-0.4.10-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-02-04 06:43:48",
"github": true,
"gitlab": false,
"bitbucket": false,
"github_user": "roysadaka",
"github_project": "lpd",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "lpd-nodeps"
}

