# MLArena
[](https://www.python.org/downloads/)
[](https://pypi.org/project/mlarena/)
[](https://opensource.org/licenses/MIT)
[](https://pytest.org/)
[](https://github.com/psf/black)
[](https://pycqa.github.io/isort/)
[](https://github.com/MenaWANG/mlarena/actions/workflows/mlarena.yml)
`mlarena` is an algorithm-agnostic machine learning toolkit for streamlined model training, diagnostics, and optimization. Implemented as a custom `mlflow.pyfunc` model, it ensures seamless integration with the MLflow ecosystem for robust experiment tracking, model versioning, and framework-agnostic deployment.
It blends smart automation that embeds ML best practices with comprehensive tools for expert-level customization and diagnostics. This unique combination fills the gap between manual ML development and fully automated AutoML platforms. Moreover, it comes with a suite of practical utilities for data analysis and visualizations - see our [comparison with AutoML platforms](https://github.com/MenaWANG/mlarena/blob/master/docs/comparision-autoML.md) to determine which approach best fits your needs.
## Publications
Read about the concepts and methodologies behind MLArena through these articles:
1. [Algorithm-Agnostic Model Building with MLflow](https://medium.com/data-science/algorithm-agnostic-model-building-with-mlflow-b106a5a29535?source=friends_link&sk=a43a376c46116970cd983420cfd68afe) - Published in Towards Data Science
> A foundational guide demonstrating how to build algorithm-agnostic ML pipelines using mlflow.pyfunc. The article explores creating generic model wrappers, encapsulating preprocessing logic, and leveraging MLflow's unified model representation for seamless algorithm transitions.
2. [Explainable Generic ML Pipeline with MLflow](https://medium.com/data-science/explainable-generic-ml-pipeline-with-mlflow-2494ca1b3f96?source=friends_link&sk=ebe917c37719516a5b5170efc1bd0b32) - Published in Towards Data Science
> An advanced implementation guide that extends the generic ML pipeline with more sophisticated preprocessing and SHAP-based model explanations. The article demonstrates how to build a production-ready pipeline that supports both classification and regression tasks, handles feature preprocessing, and provides interpretable model insights while maintaining algorithm agnosticism.
For quick guide over the package
3. [Build Algorithm-Agnostic ML Pipelines in a Breeze](https://contributor.insightmediagroup.io/build-algorithm-agnostic-ml-pipelines-in-a-breeze/) - Published in Towards Data Science
> This article discussed some key challenges in algorithm-agnostic ML Pipeline building and demonstractes how MLarena can help to address them. Although more functionalities have been added after the publication of the article on 7 July 2025, it is nonetheless a good overview of MLarena's core functionalies and a good quick guide for starting with the package.
On specific functionalities
4. [Help Your Model Learn the True Signal](https://towardsdatascience.com/help-your-model-learn-the-true-signal/)
> This article explores the challenges of investigating data points that disproportionately disrupt a model's ability to learn the dominant signal. By leveraging an algorithm-agnostic approach inspired by Cook's Distance, it provides a method to effectively identify and diagnose these disruptive data points, ensuring that models capture stable, generalizable patterns. This technique is implemented as a helper function `calculate_cooks_d_like_influence` in the MLarena package, and is compatiable with any sklearn style ML algorithms.
## Installation
The package is undergoing rapid development at the moment (pls see [CHANGELOG](https://github.com/MenaWANG/mlarena/blob/master/CHANGELOG.md) for details), it is therefore highly recommended to install with specific versions. For example
```bash
%pip install mlarena==0.4.5
```
If you are using the package in [Databricks ML Cluster with DBR runtime >= 16.0](https://learn.microsoft.com/en-us/azure/databricks/release-notes/runtime/16.0ml), you can install without dependencies like below:
```bash
%pip install mlarena==0.4.5 --no-deps
```
If you are using earlier DBR runtimes, simply install `optuna` in addition like below. Note: As of 2025-04-26, `optuna` is recommended by Databricks, while `hyperopt` will be [removed from Databricks ML Runtime](https://docs.databricks.com/aws/en/machine-learning/automl-hyperparam-tuning/).
```bash
%pip install mlarena==0.4.5 --no-deps
%pip install optuna==3.6.1
```
## Usage Example
* For quick start with a basic example, see [1.basic_usage.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/1.basic_usage.ipynb).
* For more advanced examples on model optimization, see [2.advanced_usage.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/2.advanced_usage.ipynb).
* For visualization utilities, see [3.utils_plot.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_plot.ipynb).
* For data cleaning and manipulation utilities, see [3.utils_data.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_data.ipynb).
* For statistical analysis utilities, see [3.utils_stats.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_stats.ipynb).
* For input/output utilities, see [3.utils_io.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_io.ipynb)
* For handling common challenges in machine learning, see [4.ml_discussions.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/4.ml_discussions.ipynb).
## Visual Examples:
### Quick Start
Train and evaluate models quickly with `mlarena`'s default preprocessing pipeline, comprehensive reporting, and model explainability. The framework handles the complexities behind the scenes, allowing you to focus on insights rather than boilerplate code. See [1.basic_usage.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/1.basic_usage.ipynb) for complete examples.
<br>
| Category | Classification Metrics & Plots | Regression Metrics & Plots |
|-------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
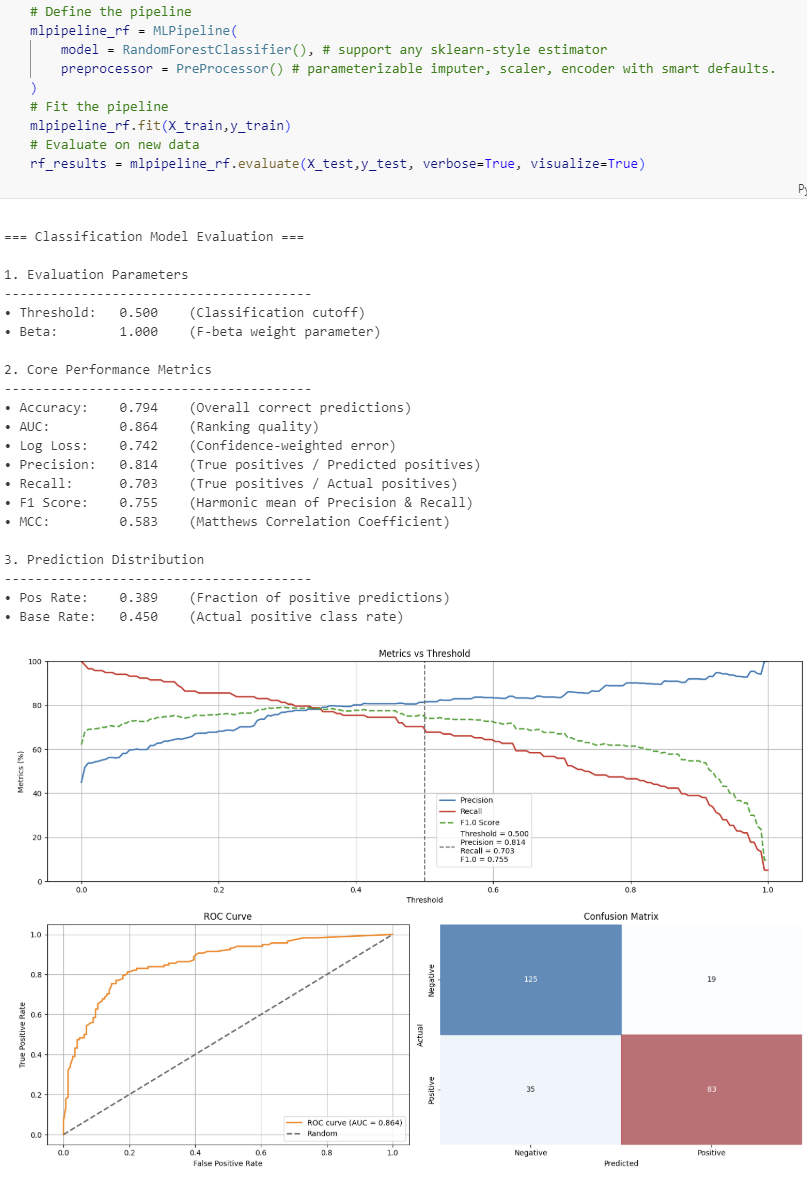
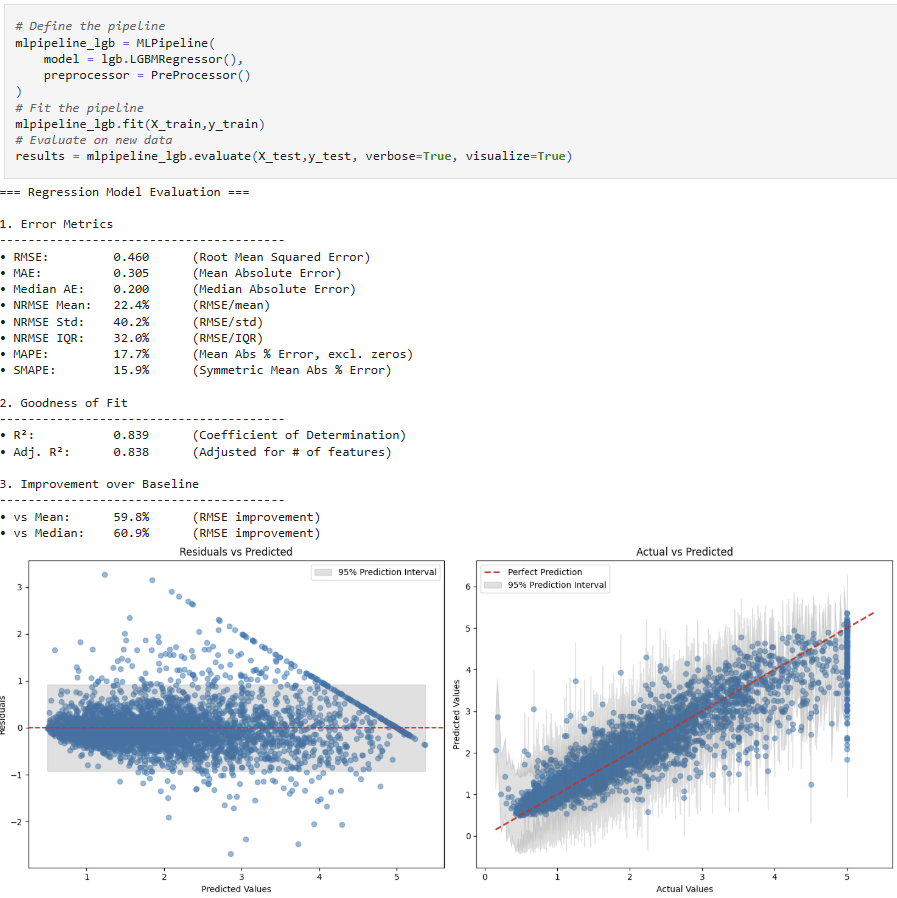
| Metrics | **Evaluation Parameters**<br>• Threshold (classification cutoff)<br>• Beta (F-beta weight parameter)<br><br>**Core Performance Metrics**<br>• Accuracy (overall correct predictions)<br>• Precision (true positives / predicted positives)<br>• Recall (true positives / actual positives)<br>• F1 Score (harmonic mean of Precision & Recall)<br>• Fβ Score (weighted harmonic mean, if β ≠ 1)<br>• MCC (Matthews Correlation Coefficient)<br>• AUC (ranking quality)<br>• Log Loss (confidence-weighted error)<br><br>**Prediction Distribution**<br>• Positive Rate (fraction of positive predictions)<br>• Base Rate (actual positive class rate) | **Error Metrics**<br>• RMSE (Root Mean Squared Error)<br>• MAE (Mean Absolute Error)<br>• Median Absolute Error<br>• NRMSE (Normalized RMSE as % of) <ul style="margin-top:0;margin-bottom:0;"><li>mean</li><li>std</li><li>IQR</li></ul>• MAPE (Mean Absolute Percentage Error, excl. zeros)<br>• SMAPE (Symmetric Mean Absolute Percentage Error)<br><br>**Goodness of Fit**<br>• R² (Coefficient of Determination)<br>• Adjusted R²<br><br>**Improvement over Baseline**<br>• RMSE Improvement over Mean Baseline (%)<br>• RMSE Improvement over Median Baseline (%) |
| Plots | • Metrics vs Threshold (Precision, Recall, Fβ, with vertical threshold line)<br>• ROC Curve<br>• Confusion Matrix (with colored overlays) | • Residual analysis (residuals vs predicted, with 95% prediction interval)<br>• Prediction error plot (actual vs predicted, with perfect prediction line and error bands) |
<br>
#### Classification Models
#### Regression Models
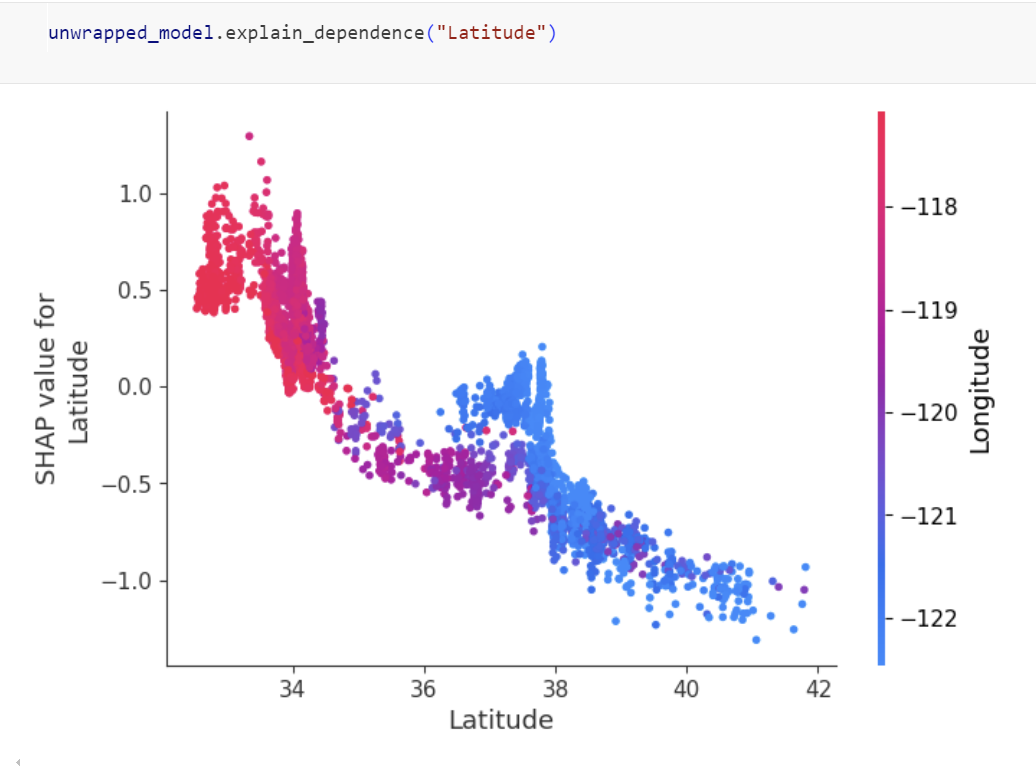
### Explainable ML
One liner to create global and local explanation based on SHAP that will work across various classification and regression algorithms.
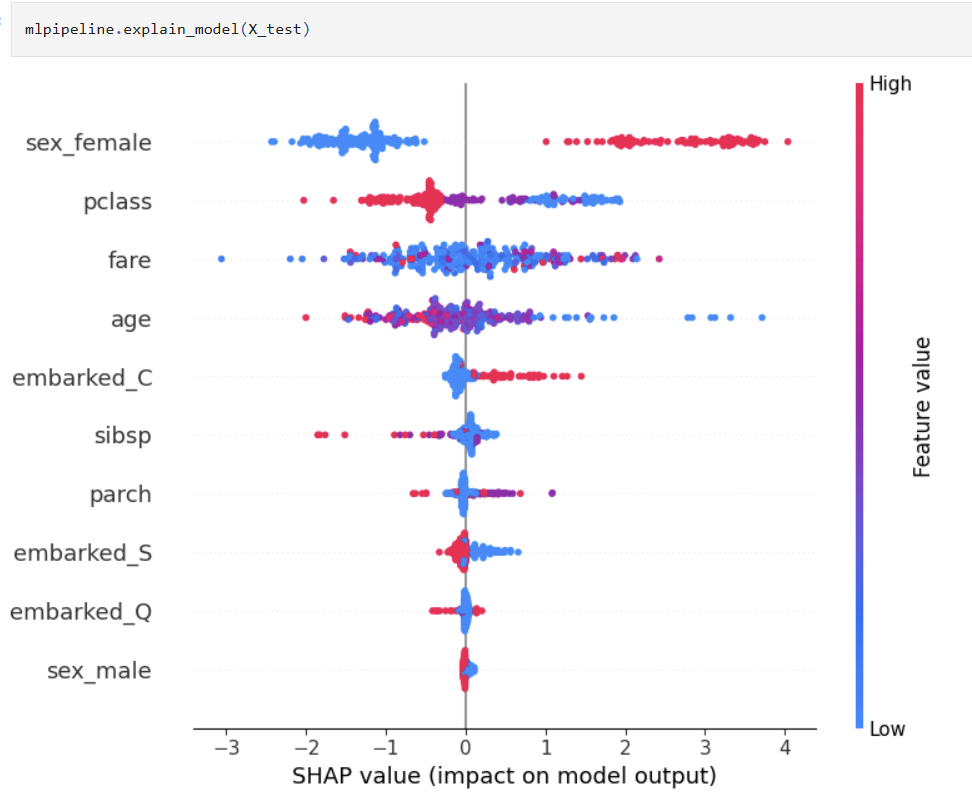
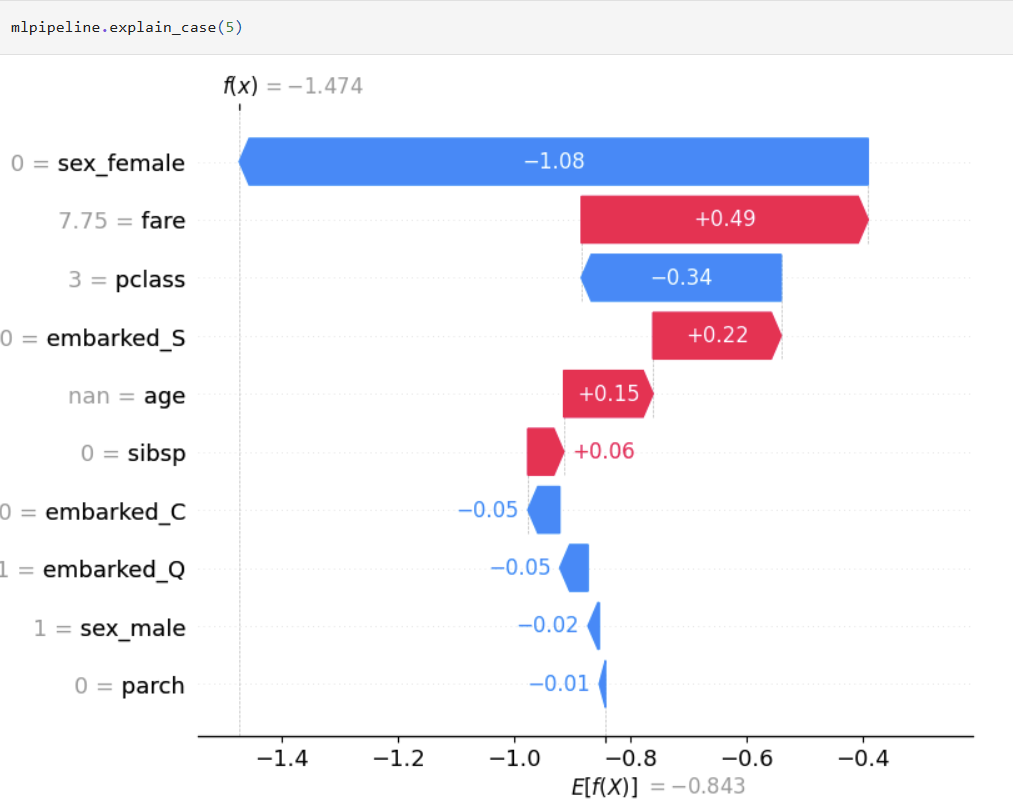
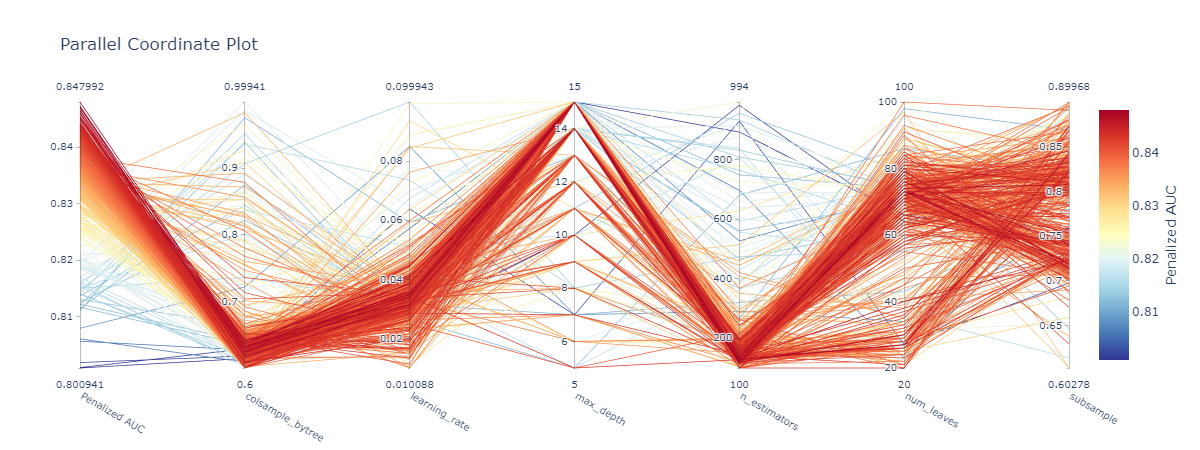
### Hyperparameter Optimization
`mlarena` offers iterative hyperparameter tuning with cross-validation for robust results and parallel coordinates visualization for search space diagnostics. See [2.advanced_usage.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/2.advanced_usage.ipynb) for more.
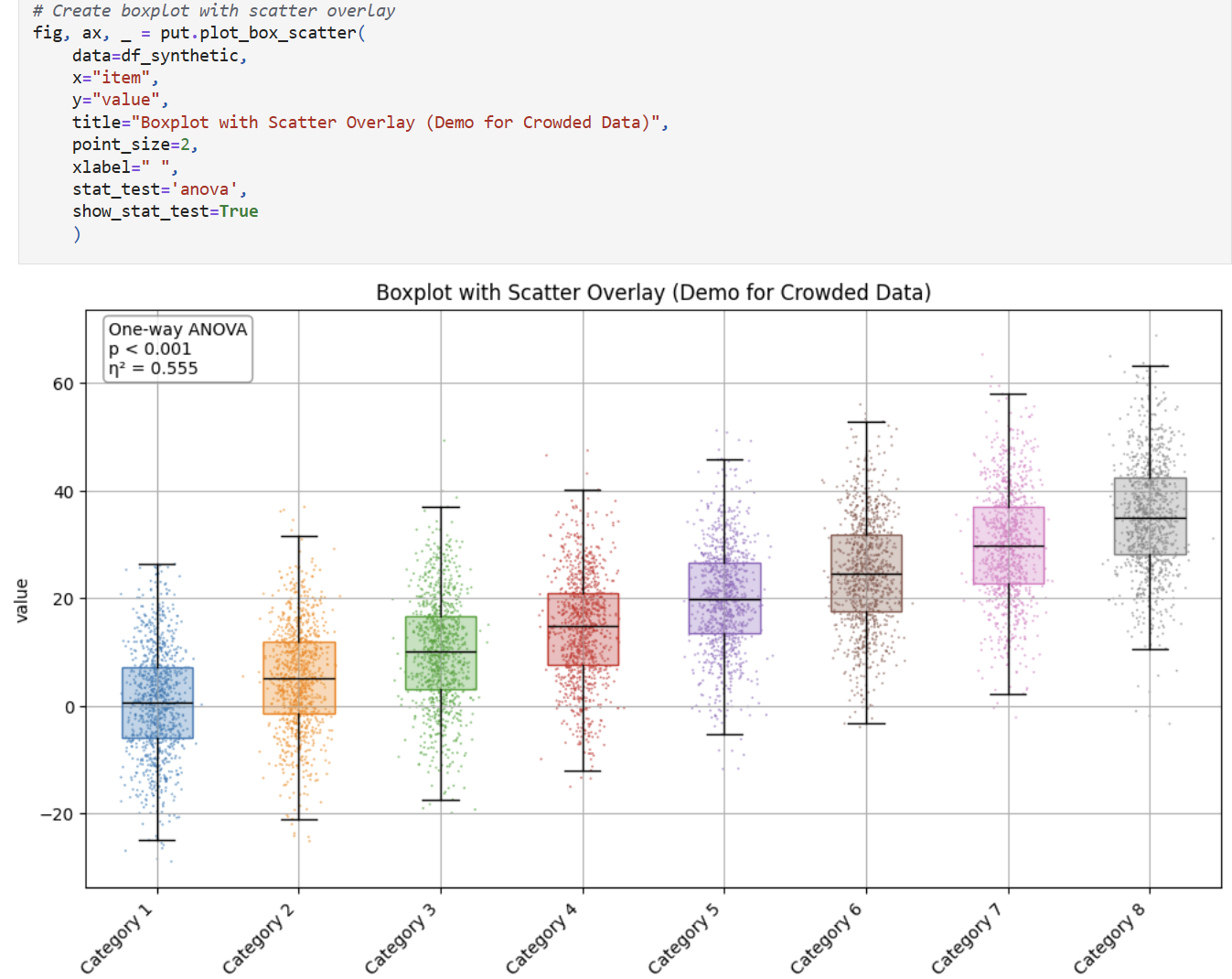
### Plotting Utility Functions
`mlarena` offers handy utility visualizations for data exploration. Pls see [3.utils_plot.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_plot.ipynb) for more.
#### `plot_box_scatter` for comparing numerical distributions across categories with optional statistical testing
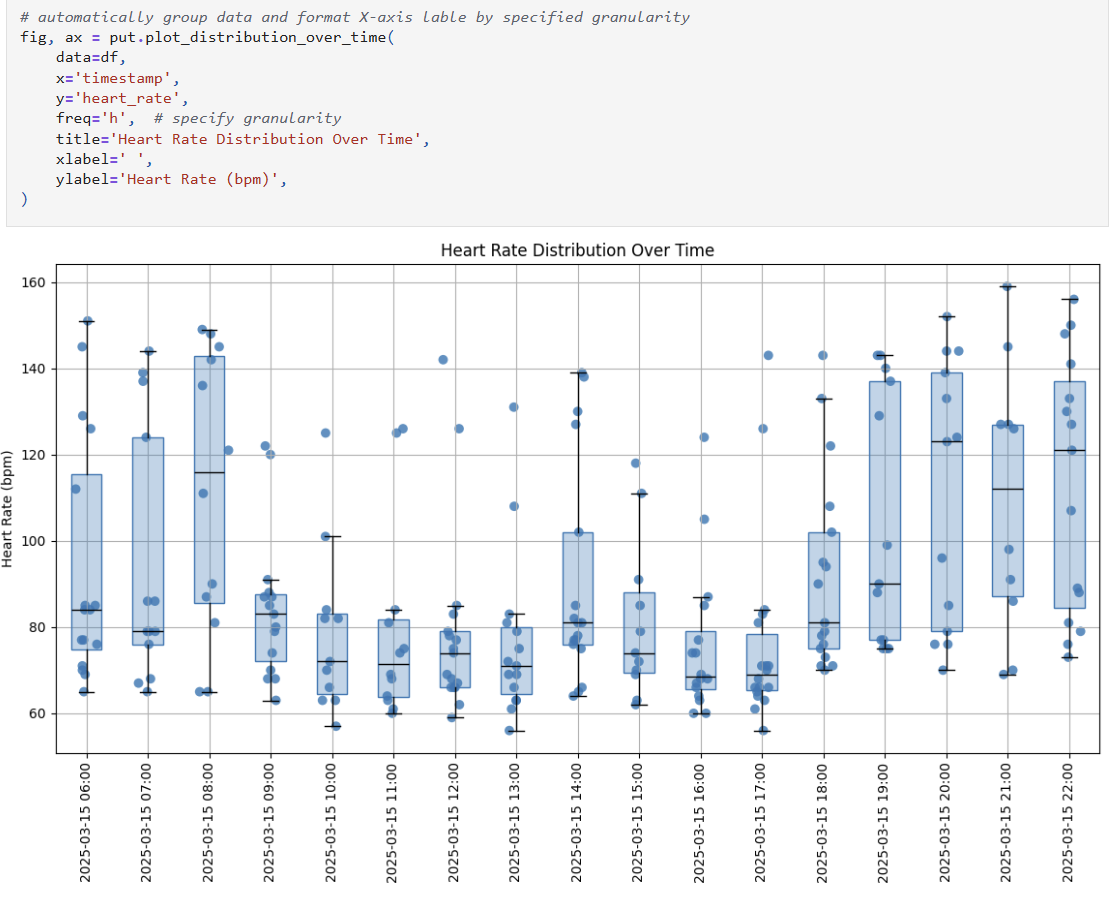
#### `plot_distribution_over_time` for comparing numerical distributions over time
#### `plot_distribution_over_time` color points using `point_hue`
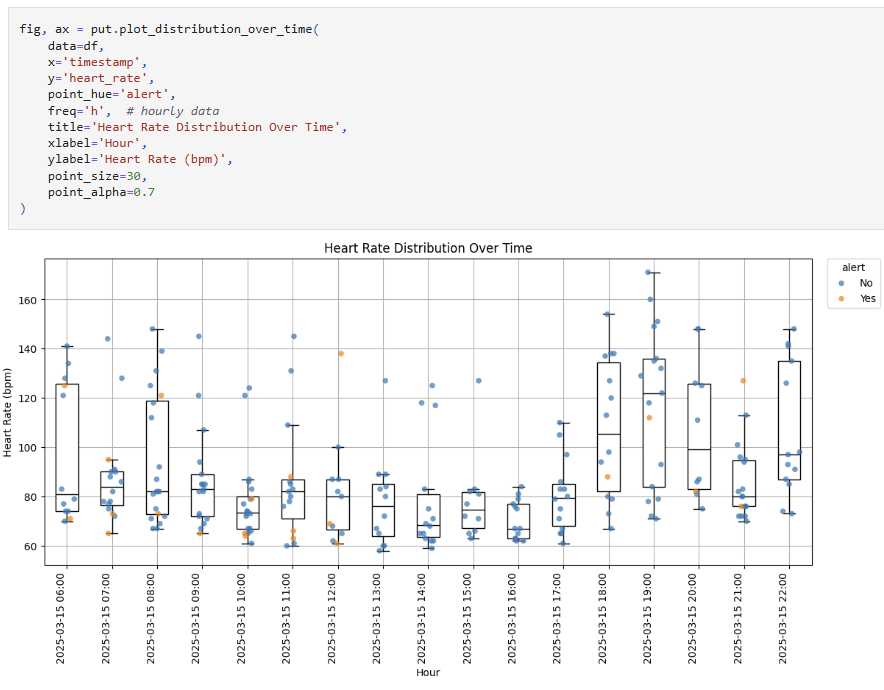
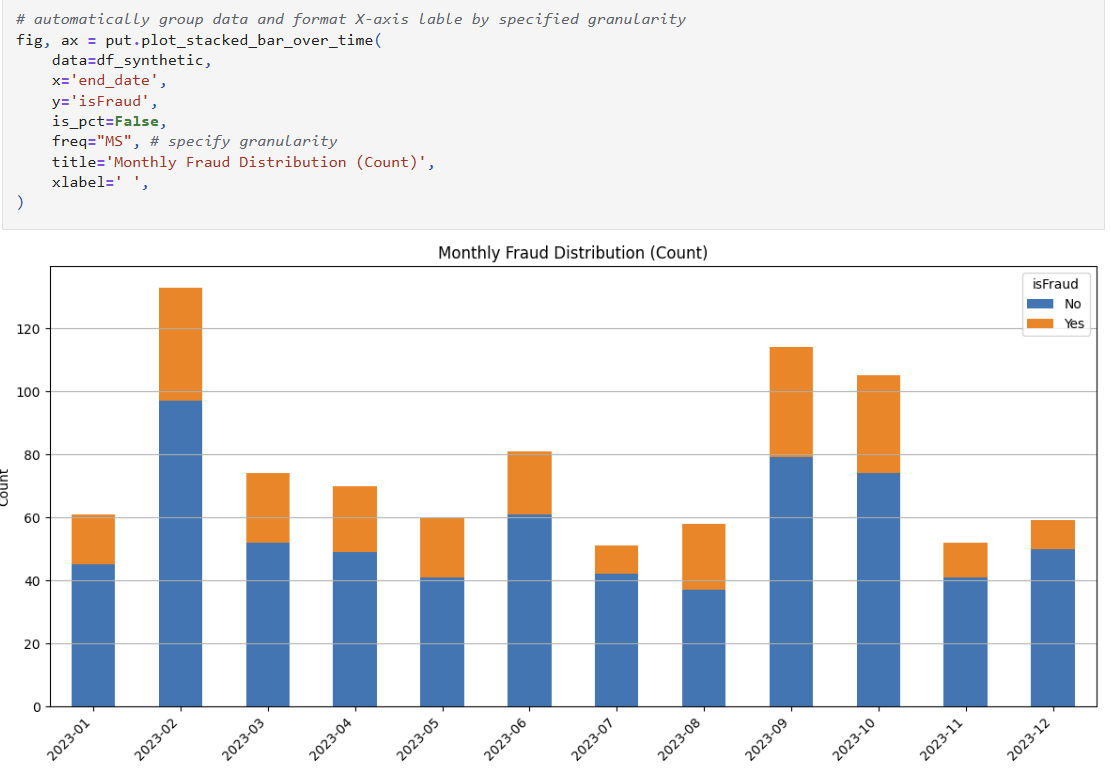
#### `plot_stacked_bar_over_time` for comparing categorical distributions over time
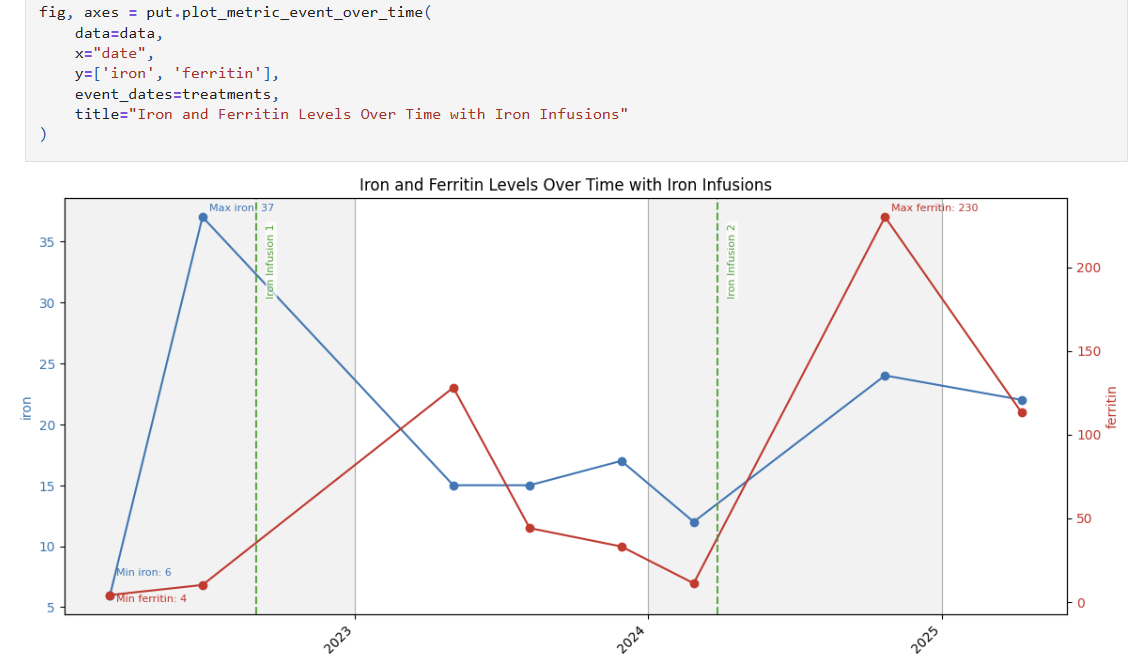
#### `plot_metric_event_over_time` for timeseries trends and events
### Data Utilities
Some handy utilities for data validation, cleaning and manipulations. Pls see [3.utils_data.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_data.ipynb) for more.
#### `is_primary_key`

## Features
**Algorithm Agnostic ML Pipeline**
- Unified interface for any scikit-learn compatible model
- Consistent workflow across classification and regression tasks
- Automated report generation with comprehensive metrics and visuals
- Built on `mlflow.pyfunc` for seamless MLOps integration
- Automated experiment tracking of parameters, metrics, and models
- Simplified handoff from experimentation to production via the MLflow framework
**Intelligent Preprocessing**
- Streamlined feature preprocessing with smart defaults and minimal code
- Automatic feature analysis with data-driven encoding recommendations
- Integrated target encoding with visualization for optimal smoothing selection
- Feature filtering based on information theory metrics (mutual information)
- Intelligent feature name sanitization to prevent pipeline failure
- Handles the full preprocessing pipeline from missing values to feature encoding
- Seamless integration with scikit-learn and MLflow for production deployment
**Model Optimization**
- Efficient hyperparameter tuning with Optuna's TPE sampler
- Smart early stopping with patient pruning to save computation resources
- Configurable early stopping parameter
- Startup trials before pruning begins
- Warmup steps per trial
- Cross-validation with variance penalty to prevent overfitting
- Parallel coordinates visualization for search history tracking and parameter space diagnostics
- Automated threshold optimization with business-focused F-beta scoring
- Cross-validation or bootstrap methods
- Configurable beta parameter for precision/recall trade-off
- Confidence intervals for bootstrap method
- Flexible metric selection for optimization
- Classification: AUC (default), F1, accuracy, log_loss, MCC
- Regression: RMSE (default), MAE, median_ae, SMAPE, NRMSE (mean/std/IQR)
**Performance Analysis**
- Comprehensive metric tracking
- Classification: AUC, F1, Fbeta, precision, recall, accuracy, log_loss, MCC, positive_rate, base_rate
- Regression: RMSE, MAE, median_ae, R2, adjusted R2, MAPE, SMAPE, NRMSE (mean/std/IQR), improvement over mean/median baselines
- Performance visualization
- Classification:
- Metrics vs Threshold plot (precision, recall, F-beta)
- ROC curve with AUC score
- Confusion matrix with color-coded cells
- Regression:
- Residual analysis with 95% prediction intervals
- Prediction error plot with perfect prediction line and error bands
- Model interpretability
- Global feature importance
- Local prediction explanations
**Utils**
- Advanced plotting utilities
- Distribution analysis
- `plot_box_scatter`: Box plots with scatter overlay and statistical testing
- Optional point coloring by category
- Built-in statistical tests (ANOVA, Welch, Kruskal)
- Customizable point jittering and transparency
- Time series visualization
- `plot_metric_event_over_time`: Track metrics with event annotations
- Support for dual y-axes
- Automatic date formatting based on time range
- Customizable event markers and labels
- Min/max value annotations
- `plot_distribution_over_time`: Track distributions over time
- Box plots with scatter overlay for each time period
- Optional point coloring by category
- Flexible time aggregation (hourly/daily/monthly/yearly)
- Summary statistics for each period
- `plot_stacked_bar_over_time`: Track categorical distributions
- Percentage or count-based stacking
- Flexible time aggregation
- Custom category labeling
- Automatic legend and color management
- Categorical analysis
- `plot_stacked_bar`: Stacked bar charts with statistical testing
- Built-in chi-square and G-tests
- Percentage or count-based visualization
- Custom category labeling
- Statistical analysis utilities
- Group comparison tools
- `compare_groups`: Statistical testing across groups with visualization
- `add_stratified_groups`: Create balanced groups with stratification
- `optimize_stratification_strategy`: Find optimal stratification columns
- Power analysis and sample size calculation
- `power_analysis_numeric`: Power calculation for t-tests
- `power_analysis_proportion`: Power calculation for proportion tests
- `sample_size_numeric`: Required sample size for numeric outcomes
- `sample_size_proportion`: Required sample size for proportion tests
- `numeric_effectsize`: Cohen's d effect size calculation
- Data manipulation tools
- Standardized dollar amount cleaning for financial analysis
- Value counts with percentage calculation for categorical analysis
- Smart date column transformation with flexible format handling
- Schema and data quality utilities
- Primary key validation with detailed diagnostics
- Alphabetically sorted schema display
- Safe column selection with case sensitivity options
- Automatic removal of fully null columns
- Complete Duplicate Management Workflow: "Discover → Investigate → Resolve":
- Use `is_primary_key` to discover the existance of duplication issues
- Use `find_duplicates` to analyze duplicate patterns
- Use `deduplicate_by_rank` to intelligently resolve duplicates with business logic
- I/O utilities
- `save_object`: Store Python objects to disk with customizable options
- Support for pickle and joblib backends
- Optional date stamping in filenames
- Compression support for joblib backend
- `load_object`: Retrieve Python objects with automatic backend detection
- Seamless loading regardless of storage format
- Direct compatibility with paths returned by `save_object`
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## License
This project is licensed under the MIT License - see the LICENSE file for details.
Raw data
{
"_id": null,
"home_page": "https://github.com/MenaWANG/mlarena",
"name": "mlarena",
"maintainer": null,
"docs_url": null,
"requires_python": "<3.13,>=3.10",
"maintainer_email": null,
"keywords": "machine-learning, data-science, preprocessing, pipeline",
"author": "Mena Wang",
"author_email": "ningwang25@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/74/7f/5498b8b33d310be8b4449514ded0bf9c48f3c0382095e6258ef90b59ccee/mlarena-0.4.5.tar.gz",
"platform": null,
"description": "# MLArena\n\n[](https://www.python.org/downloads/)\n[](https://pypi.org/project/mlarena/)\n[](https://opensource.org/licenses/MIT)\n[](https://pytest.org/)\n[](https://github.com/psf/black)\n[](https://pycqa.github.io/isort/)\n[](https://github.com/MenaWANG/mlarena/actions/workflows/mlarena.yml)\n\n\n`mlarena` is an algorithm-agnostic machine learning toolkit for streamlined model training, diagnostics, and optimization. Implemented as a custom `mlflow.pyfunc` model, it ensures seamless integration with the MLflow ecosystem for robust experiment tracking, model versioning, and framework-agnostic deployment.\n\nIt blends smart automation that embeds ML best practices with comprehensive tools for expert-level customization and diagnostics. This unique combination fills the gap between manual ML development and fully automated AutoML platforms. Moreover, it comes with a suite of practical utilities for data analysis and visualizations - see our [comparison with AutoML platforms](https://github.com/MenaWANG/mlarena/blob/master/docs/comparision-autoML.md) to determine which approach best fits your needs.\n\n## Publications\n\nRead about the concepts and methodologies behind MLArena through these articles:\n\n1. [Algorithm-Agnostic Model Building with MLflow](https://medium.com/data-science/algorithm-agnostic-model-building-with-mlflow-b106a5a29535?source=friends_link&sk=a43a376c46116970cd983420cfd68afe) - Published in Towards Data Science\n > A foundational guide demonstrating how to build algorithm-agnostic ML pipelines using mlflow.pyfunc. The article explores creating generic model wrappers, encapsulating preprocessing logic, and leveraging MLflow's unified model representation for seamless algorithm transitions.\n\n2. [Explainable Generic ML Pipeline with MLflow](https://medium.com/data-science/explainable-generic-ml-pipeline-with-mlflow-2494ca1b3f96?source=friends_link&sk=ebe917c37719516a5b5170efc1bd0b32) - Published in Towards Data Science\n > An advanced implementation guide that extends the generic ML pipeline with more sophisticated preprocessing and SHAP-based model explanations. The article demonstrates how to build a production-ready pipeline that supports both classification and regression tasks, handles feature preprocessing, and provides interpretable model insights while maintaining algorithm agnosticism.\n \nFor quick guide over the package \n\n3. [Build Algorithm-Agnostic ML Pipelines in a Breeze](https://contributor.insightmediagroup.io/build-algorithm-agnostic-ml-pipelines-in-a-breeze/) - Published in Towards Data Science\n\n > This article discussed some key challenges in algorithm-agnostic ML Pipeline building and demonstractes how MLarena can help to address them. Although more functionalities have been added after the publication of the article on 7 July 2025, it is nonetheless a good overview of MLarena's core functionalies and a good quick guide for starting with the package. \n\nOn specific functionalities\n\n4. [Help Your Model Learn the True Signal](https://towardsdatascience.com/help-your-model-learn-the-true-signal/)\n\n > This article explores the challenges of investigating data points that disproportionately disrupt a model's ability to learn the dominant signal. By leveraging an algorithm-agnostic approach inspired by Cook's Distance, it provides a method to effectively identify and diagnose these disruptive data points, ensuring that models capture stable, generalizable patterns. This technique is implemented as a helper function `calculate_cooks_d_like_influence` in the MLarena package, and is compatiable with any sklearn style ML algorithms.\n\n## Installation\n\nThe package is undergoing rapid development at the moment (pls see [CHANGELOG](https://github.com/MenaWANG/mlarena/blob/master/CHANGELOG.md) for details), it is therefore highly recommended to install with specific versions. For example\n\n```bash\n%pip install mlarena==0.4.5\n```\n\nIf you are using the package in [Databricks ML Cluster with DBR runtime >= 16.0](https://learn.microsoft.com/en-us/azure/databricks/release-notes/runtime/16.0ml), you can install without dependencies like below:\n\n```bash\n%pip install mlarena==0.4.5 --no-deps\n```\nIf you are using earlier DBR runtimes, simply install `optuna` in addition like below. Note: As of 2025-04-26, `optuna` is recommended by Databricks, while `hyperopt` will be [removed from Databricks ML Runtime](https://docs.databricks.com/aws/en/machine-learning/automl-hyperparam-tuning/).\n\n```bash\n%pip install mlarena==0.4.5 --no-deps\n%pip install optuna==3.6.1\n```\n\n## Usage Example\n\n* For quick start with a basic example, see [1.basic_usage.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/1.basic_usage.ipynb). \n* For more advanced examples on model optimization, see [2.advanced_usage.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/2.advanced_usage.ipynb). \n* For visualization utilities, see [3.utils_plot.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_plot.ipynb).\n* For data cleaning and manipulation utilities, see [3.utils_data.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_data.ipynb).\n* For statistical analysis utilities, see [3.utils_stats.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_stats.ipynb).\n* For input/output utilities, see [3.utils_io.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_io.ipynb)\n* For handling common challenges in machine learning, see [4.ml_discussions.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/4.ml_discussions.ipynb).\n\n## Visual Examples:\n\n### Quick Start\nTrain and evaluate models quickly with `mlarena`'s default preprocessing pipeline, comprehensive reporting, and model explainability. The framework handles the complexities behind the scenes, allowing you to focus on insights rather than boilerplate code. See [1.basic_usage.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/1.basic_usage.ipynb) for complete examples.\n<br>\n\n| Category | Classification Metrics & Plots | Regression Metrics & Plots |\n|-------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|\n| Metrics | **Evaluation Parameters**<br>\u2022 Threshold (classification cutoff)<br>\u2022 Beta (F-beta weight parameter)<br><br>**Core Performance Metrics**<br>\u2022 Accuracy (overall correct predictions)<br>\u2022 Precision (true positives / predicted positives)<br>\u2022 Recall (true positives / actual positives)<br>\u2022 F1 Score (harmonic mean of Precision & Recall)<br>\u2022 F\u03b2 Score (weighted harmonic mean, if \u03b2 \u2260 1)<br>\u2022 MCC (Matthews Correlation Coefficient)<br>\u2022 AUC (ranking quality)<br>\u2022 Log Loss (confidence-weighted error)<br><br>**Prediction Distribution**<br>\u2022 Positive Rate (fraction of positive predictions)<br>\u2022 Base Rate (actual positive class rate) | **Error Metrics**<br>\u2022 RMSE (Root Mean Squared Error)<br>\u2022 MAE (Mean Absolute Error)<br>\u2022 Median Absolute Error<br>\u2022 NRMSE (Normalized RMSE as % of) <ul style=\"margin-top:0;margin-bottom:0;\"><li>mean</li><li>std</li><li>IQR</li></ul>\u2022 MAPE (Mean Absolute Percentage Error, excl. zeros)<br>\u2022 SMAPE (Symmetric Mean Absolute Percentage Error)<br><br>**Goodness of Fit**<br>\u2022 R\u00b2 (Coefficient of Determination)<br>\u2022 Adjusted R\u00b2<br><br>**Improvement over Baseline**<br>\u2022 RMSE Improvement over Mean Baseline (%)<br>\u2022 RMSE Improvement over Median Baseline (%) |\n| Plots | \u2022 Metrics vs Threshold (Precision, Recall, F\u03b2, with vertical threshold line)<br>\u2022 ROC Curve<br>\u2022 Confusion Matrix (with colored overlays) | \u2022 Residual analysis (residuals vs predicted, with 95% prediction interval)<br>\u2022 Prediction error plot (actual vs predicted, with perfect prediction line and error bands) |\n<br>\n\n#### Classification Models\n\n \n\n#### Regression Models\n\n \n\n### Explainable ML\nOne liner to create global and local explanation based on SHAP that will work across various classification and regression algorithms. \n\n \n\n \n\n \n\n### Hyperparameter Optimization\n`mlarena` offers iterative hyperparameter tuning with cross-validation for robust results and parallel coordinates visualization for search space diagnostics. See [2.advanced_usage.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/2.advanced_usage.ipynb) for more.\n\n\n\n### Plotting Utility Functions \n\n`mlarena` offers handy utility visualizations for data exploration. Pls see [3.utils_plot.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_plot.ipynb) for more.\n\n#### `plot_box_scatter` for comparing numerical distributions across categories with optional statistical testing\n\n\n#### `plot_distribution_over_time` for comparing numerical distributions over time\n\n\n#### `plot_distribution_over_time` color points using `point_hue`\n\n\n#### `plot_stacked_bar_over_time` for comparing categorical distributions over time\n\n\n#### `plot_metric_event_over_time` for timeseries trends and events\n\n\n### Data Utilities\n\nSome handy utilities for data validation, cleaning and manipulations. Pls see [3.utils_data.ipynb](https://github.com/MenaWANG/mlarena/blob/master/examples/3.utils_data.ipynb) for more. \n\n#### `is_primary_key`\n\n\n\n## Features\n\n**Algorithm Agnostic ML Pipeline**\n- Unified interface for any scikit-learn compatible model\n- Consistent workflow across classification and regression tasks\n- Automated report generation with comprehensive metrics and visuals\n- Built on `mlflow.pyfunc` for seamless MLOps integration\n- Automated experiment tracking of parameters, metrics, and models\n- Simplified handoff from experimentation to production via the MLflow framework\n\n**Intelligent Preprocessing**\n- Streamlined feature preprocessing with smart defaults and minimal code\n- Automatic feature analysis with data-driven encoding recommendations \n- Integrated target encoding with visualization for optimal smoothing selection\n- Feature filtering based on information theory metrics (mutual information)\n- Intelligent feature name sanitization to prevent pipeline failure\n- Handles the full preprocessing pipeline from missing values to feature encoding\n- Seamless integration with scikit-learn and MLflow for production deployment\n\n\n**Model Optimization**\n- Efficient hyperparameter tuning with Optuna's TPE sampler\n- Smart early stopping with patient pruning to save computation resources\n - Configurable early stopping parameter\n - Startup trials before pruning begins\n - Warmup steps per trial\n- Cross-validation with variance penalty to prevent overfitting\n- Parallel coordinates visualization for search history tracking and parameter space diagnostics\n- Automated threshold optimization with business-focused F-beta scoring\n - Cross-validation or bootstrap methods\n - Configurable beta parameter for precision/recall trade-off\n - Confidence intervals for bootstrap method\n- Flexible metric selection for optimization\n - Classification: AUC (default), F1, accuracy, log_loss, MCC\n - Regression: RMSE (default), MAE, median_ae, SMAPE, NRMSE (mean/std/IQR)\n\n**Performance Analysis**\n- Comprehensive metric tracking\n - Classification: AUC, F1, Fbeta, precision, recall, accuracy, log_loss, MCC, positive_rate, base_rate\n - Regression: RMSE, MAE, median_ae, R2, adjusted R2, MAPE, SMAPE, NRMSE (mean/std/IQR), improvement over mean/median baselines\n- Performance visualization\n - Classification: \n - Metrics vs Threshold plot (precision, recall, F-beta)\n - ROC curve with AUC score\n - Confusion matrix with color-coded cells\n - Regression:\n - Residual analysis with 95% prediction intervals\n - Prediction error plot with perfect prediction line and error bands\n- Model interpretability\n - Global feature importance\n - Local prediction explanations\n\n**Utils**\n- Advanced plotting utilities\n - Distribution analysis\n - `plot_box_scatter`: Box plots with scatter overlay and statistical testing\n - Optional point coloring by category\n - Built-in statistical tests (ANOVA, Welch, Kruskal)\n - Customizable point jittering and transparency\n - Time series visualization\n - `plot_metric_event_over_time`: Track metrics with event annotations\n - Support for dual y-axes\n - Automatic date formatting based on time range\n - Customizable event markers and labels\n - Min/max value annotations\n - `plot_distribution_over_time`: Track distributions over time\n - Box plots with scatter overlay for each time period\n - Optional point coloring by category\n - Flexible time aggregation (hourly/daily/monthly/yearly)\n - Summary statistics for each period\n - `plot_stacked_bar_over_time`: Track categorical distributions\n - Percentage or count-based stacking\n - Flexible time aggregation\n - Custom category labeling\n - Automatic legend and color management\n - Categorical analysis\n - `plot_stacked_bar`: Stacked bar charts with statistical testing\n - Built-in chi-square and G-tests\n - Percentage or count-based visualization\n - Custom category labeling\n- Statistical analysis utilities\n - Group comparison tools\n - `compare_groups`: Statistical testing across groups with visualization\n - `add_stratified_groups`: Create balanced groups with stratification\n - `optimize_stratification_strategy`: Find optimal stratification columns\n - Power analysis and sample size calculation\n - `power_analysis_numeric`: Power calculation for t-tests\n - `power_analysis_proportion`: Power calculation for proportion tests\n - `sample_size_numeric`: Required sample size for numeric outcomes\n - `sample_size_proportion`: Required sample size for proportion tests\n - `numeric_effectsize`: Cohen's d effect size calculation\n- Data manipulation tools\n - Standardized dollar amount cleaning for financial analysis\n - Value counts with percentage calculation for categorical analysis\n - Smart date column transformation with flexible format handling\n - Schema and data quality utilities\n - Primary key validation with detailed diagnostics\n - Alphabetically sorted schema display\n - Safe column selection with case sensitivity options\n - Automatic removal of fully null columns\n - Complete Duplicate Management Workflow: \"Discover \u2192 Investigate \u2192 Resolve\":\n - Use `is_primary_key` to discover the existance of duplication issues\n - Use `find_duplicates` to analyze duplicate patterns\n - Use `deduplicate_by_rank` to intelligently resolve duplicates with business logic\n- I/O utilities\n - `save_object`: Store Python objects to disk with customizable options\n - Support for pickle and joblib backends\n - Optional date stamping in filenames\n - Compression support for joblib backend\n - `load_object`: Retrieve Python objects with automatic backend detection\n - Seamless loading regardless of storage format\n - Direct compatibility with paths returned by `save_object`\n\n## Contributing\n\nContributions are welcome! Please feel free to submit a Pull Request.\n\n## License\n\nThis project is licensed under the MIT License - see the LICENSE file for details. \n",
"bugtrack_url": null,
"license": "MIT",
"summary": "An algorithm-agnostic machine learning toolkit for model training, diagnostics and optimization",
"version": "0.4.5",
"project_urls": {
"Homepage": "https://github.com/MenaWANG/mlarena",
"Repository": "https://github.com/MenaWANG/mlarena"
},
"split_keywords": [
"machine-learning",
" data-science",
" preprocessing",
" pipeline"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "ba11d1b96a6c738fd40de887150c11caed2c8eb0bc97716f24881c13400bbbaa",
"md5": "025667e10f35e21b5265f3def95f4c87",
"sha256": "c8329175bd73df4297e49f258bf73641e4f213227561acbac7be16dc4d1f2402"
},
"downloads": -1,
"filename": "mlarena-0.4.5-py3-none-any.whl",
"has_sig": false,
"md5_digest": "025667e10f35e21b5265f3def95f4c87",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": "<3.13,>=3.10",
"size": 74036,
"upload_time": "2025-08-24T12:08:17",
"upload_time_iso_8601": "2025-08-24T12:08:17.554438Z",
"url": "https://files.pythonhosted.org/packages/ba/11/d1b96a6c738fd40de887150c11caed2c8eb0bc97716f24881c13400bbbaa/mlarena-0.4.5-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "747f5498b8b33d310be8b4449514ded0bf9c48f3c0382095e6258ef90b59ccee",
"md5": "657da95bde8a926074f7691053257b6c",
"sha256": "7efdcc47b4196bc9356dfe9a5eb73ebd48a03649122cbc38cb38d1dd26e27c4d"
},
"downloads": -1,
"filename": "mlarena-0.4.5.tar.gz",
"has_sig": false,
"md5_digest": "657da95bde8a926074f7691053257b6c",
"packagetype": "sdist",
"python_version": "source",
"requires_python": "<3.13,>=3.10",
"size": 75303,
"upload_time": "2025-08-24T12:08:18",
"upload_time_iso_8601": "2025-08-24T12:08:18.832556Z",
"url": "https://files.pythonhosted.org/packages/74/7f/5498b8b33d310be8b4449514ded0bf9c48f3c0382095e6258ef90b59ccee/mlarena-0.4.5.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-08-24 12:08:18",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "MenaWANG",
"github_project": "mlarena",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "mlarena"
}

