# Biblioteca de ML (_Machine Learning_) - Prodest
A finalidade desta biblioteca é prover interfaces e funções que dão suporte ao provisionamento de modelos de ML na Stack
de ML do Prodest.
Acesse a [documentação da lib](https://prodest.github.io/mllibprodest)!
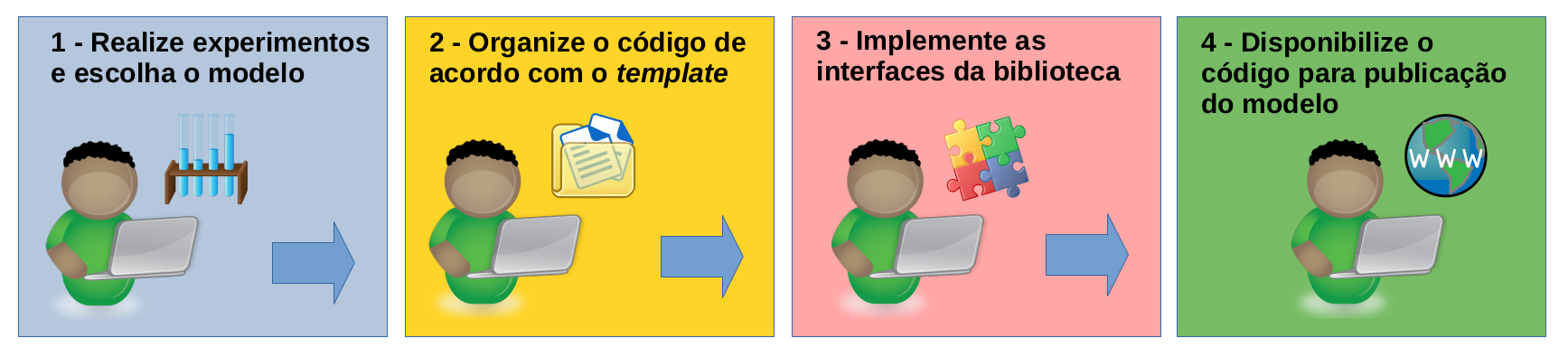
_Workflow_ básico para construção, disponibilização e publicação de modelos:
## Pré-requisitos
- **Python >= 3.11.** Instruções: [Linux (Geralmente já vem instalado por padrão)](https://python.org.br/instalacao-linux) ou [Windows](https://www.python.org/downloads/windows).
- **Git.** Instruções: [Linux](https://git-scm.com/download/linux) ou [Windows](https://git-scm.com/download/win).
- **Venv.** Gerenciador de ambiente virtual Python adotado no tutorial. Instruções: [Linux e Windows (escolha o sistema na página)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment).
Ou qualquer outro gerenciador de ambiente Python que preferir.
## 1. Realize experimentos e escolha o modelo
Esta é uma das etapas iniciais de um projeto para o desenvolvimento de um modelo de _Machine Learning_. Neste momento é
necessário entender o problema a ser resolvido; levantar requisitos; obter e tratar os dados, etc. Também é nessa etapa
que se verifica a viabilidade (ou não) da construção de um modelo.
Neste passo você tem **total liberdade** para construir o seu modelo e realizar os experimentos que quiser. Entretanto,
é importante que os resultados e artefatos gerados pelos experimentos, desde já, sejam registrados para facilitar a
comparação dos resultados obtidos e a publicação do modelo. Esta lib utiliza o
[MLflow](https://github.com/mlflow/mlflow) como plataforma para registro dos experimentos/modelos (no contexto da lib, o
MLflow é chamado de _Provider_).
Apesar do registro dos experimentos ser importante, deixar de registrá-los agora **não** vai impedir que você construa o
seu modelo!
Você tem duas opções:
- Seguir com a construção do modelo e execução dos experimentos e, caso chegue à conclusão de que o modelo é viável,
ajustar o código para realizar o registro; ou
- Fazer uma pausa e entender primeiro como registrar seus experimentos no MLflow e já construir o código com a lógica
necessária para isso.
Independente da opção escolhida, haverá necessidade de, agora ou depois, aprender (caso não saiba) como registrar os
experimentos do modelo no MLflow.
Para alcançar esse objetivo, leia a [documentação oficial do MLflow](https://mlflow.org/docs/latest/index.html).
Segue abaixo, um exemplo simples de como utilizar o MLflow para registrar os experimentos de um modelo construído com o [scikit-learn](https://scikit-learn.org).
```python
import os
import mlflow.sklearn # Importa o sklearn através do MLflow
import pickle # Para gerar um artefato de exemplo
# Obs.: Utilize as duas linhas abaixo, exatamente como apresentadas, para configurar o
# parâmetro 'Tracking URI' do MLflow nos seus códigos de testes. Dessa forma, quando subir
# para produção não haverá necessidade de modificá-las, pois lá o parâmetro 'Tracking URI'
# será obtido diretamente através da variável de ambiente 'MLFLOW_TRACKING_URI'.
if os.environ.get('MLFLOW_TRACKING_URI') is None:
mlflow.set_tracking_uri('sqlite:///teste_mlflow.db')
# Configura o experimento (se não existir, cria)
mlflow.set_experiment(experiment_name="Teste_sklearn")
# Inicia uma execução do experimento (um experimento pode possuir várias execuções)
mlflow.start_run(run_name="t1", description="teste 1")
# Registra algumas informações adicionais no experimento (coloque as informações que julgar
# necessárias, no formato dict)
tags = {"Projeto": "Teste", "team": "ML", "util": "Informação útil"}
mlflow.set_tags(tags)
# Inicia o registro dos logs da execução do sklearn
mlflow.sklearn.autolog()
# TODO: Inclua aqui a lógica para fazer o fit do modelo
'''Exemplo de modelo, somente para o propósito de testes!'''
# Adaptado de https://scikit-learn.org/stable/modules/tree.html#classification
import matplotlib
import numpy as np
from sklearn import tree
X = np.array([[0, 0], [1, 1]])
Y = np.array([0, 1]).reshape(-1)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
'''Fim do exemplo de modelo.'''
'''
Salva um artefato de seu interesse no MLflow (podem ser arquivos em diversos formatos: txt,
pkl, png, jpeg, etc.). Exemplos de artefatos: gráficos, objetos persistidos com pickle,
enfim, tudo que for relevante e/ou necessário para que o modelo funcione e/ou para análise
das execuções.
'''
# Cria um aterfato de teste no formato pickle (obs.: todas as classes da lib tem os métodos
# 'convert_artifact_to_pickle' e 'convert_artifact_to_object' para auxiliar na persistência
# dos artefatos)
artefato = {"t": 1}
caminho_artefato = "artefato.pkl"
with open(caminho_artefato, 'wb') as arq:
pickle.dump(artefato, arq)
# Salva o artefato criado
mlflow.log_artifact(caminho_artefato)
# Finaliza o experimento
mlflow.end_run()
print("\nTeste finalizado!\n")
```
Se você quiser testar um registro de experimento através do código acima, faça o seguinte:
- Crie uma pasta para testes;
- Copie e cole o código acima em um editor de texto simples e salve com o nome 'testeml.py' dentro da pasta criada;
- Abra um prompt de comando ou terminal e entre na pasta criada;
- Crie e ative um ambiente virtual Python, conforme instruções: [Linux e Windows (escolha o sistema na página)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment);
- Atualize o pip e o setuptools;
- Instale os pacotes mlflow, sklearn, matplotlib e numpy;
```bash
pip install --upgrade pip setuptools
```
```bash
pip install mlflow==3.1.1 scikit-learn==1.7.0 matplotlib==3.10.3 numpy==2.3.1
```
- Rode o teste (ignore as mensagens do tipo 'INFO' de criação do banco de dados);
```bash
python testeml.py
```
Cabe observar que: depois de rodar o código de teste, foi criada uma pasta chamada '**mlruns**', dentro da pasta de
testes, que serve para armazenar os artefatos gerados pelo código e que são apresentados na interface do MLflow.
Abaixo segue uma listagem do conteúdo gerado pelo código de teste (obs.: essa parte do caminho vai ser diferente de
acordo com cada experimento/execução realizados: '1/1a67156e63444d6e886fab7c8459bb8b'. O conteúdo da pasta também será
diferente de acordo com cada modelo).
```bash
(env) user:/teste/mlruns/1/1a67156e63444d6e886fab7c8459bb8b/artifacts$ dir
artefato.pkl estimator.html model training_confusion_matrix.png training_precision_recall_curve.png training_roc_curve.png
```
Dentro da pasta criada para testes também foi gerado um arquivo chamado '**teste_mlflow.db**', que é um pequeno banco
de dados [SQlite](https://www.sqlite.org), que serve para armazenar os modelos que foram registrados.
- Inicie o servidor do MLflow;
Perceba que a pasta '**mlruns**' e o arquivo '**teste_mlflow.db**' são passados como parâmetros na hora de iniciar o
servidor, para que o experimento de teste possa ser visualizado. Portanto, é **mandatório** sempre iniciar o servidor do
MLflow **de dentro da pasta** onde se encontra o código que fará o registro dos artefatos e dos experimentos/modelos.
**DICA**: Abra um outro prompt de comando ou terminal diferente; entre na pasta onde se encontra o código para registro
dos experimentos/modelo; **ative** o ambiente virtual criado anteriormente; execute o comando para iniciar o servidor do MLflow de dentro desta pasta. Pois assim, você
conseguirá rodar o código e já observar os resultados sem ter que parar o servidor para liberar o prompt ou terminal.
```bash
mlflow server --backend-store-uri sqlite:///teste_mlflow.db --host 0.0.0.0 -p 5000 --default-artifact-root mlruns
```
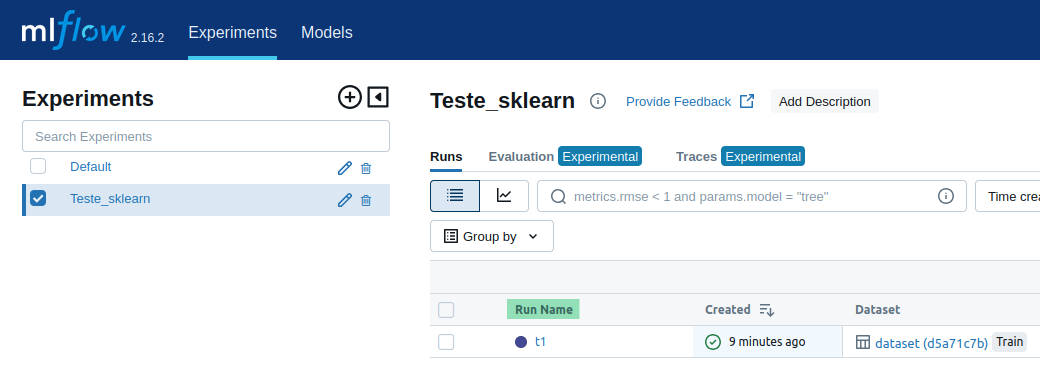
- Verifique se o experimento foi criado. Acesse o MLFlow: [http://localhost:5000](http://localhost:5000) e procure
pelo experimento/execução '**Teste_sklearn**' na seção **Experiments** (se o experimento não estiver listado, verifique
se o servidor foi iniciado de dentro da pasta correta);
- Clique na execução do experimento que se encontra na coluna '**Run Name**' (destaque em verde);
- Verifique se os artefatos foram gravados;
- Finalize o servidor do MLflow. Faça 'CTRL+c' no prompt de comando ou terminal onde ele foi iniciado;
- Apague a pasta criada para realização dos testes.
**NOTA**: Existem vários outros _frameworks_ suportados: TensorFlow, Keras, Pytorch, etc. (veja a lista completa para
Python em [MLflow Python API](https://mlflow.org/docs/latest/python_api/index.html)), inclusive é possível registrar
modelos que **não são suportados nativamente** pelo MLflow utilizando a função
[mlflow.pyfunc](https://mlflow.org/docs/latest/python_api/mlflow.pyfunc.html).
**ATENÇÃO**: Sua interação direta com o MLflow será somente para registro dos experimentos/modelo. Essa interação é
essencial porque dá liberdade ao desenvolvedor para escolher o _framework_ que achar mais adequado para construção
do seu modelo. A lib disponibiliza funções para obtenção do modelo registrado e dos seus artefatos, além de
outras funções relacionadas à carga de _datasets_. Leia a documentação das interfaces, classes e funções da lib para
mais detalhes.
### Antes de ir para os próximos passos...
Quando você já tiver realizado vários experimentos utilizando o MLflow e decidido por colocar o modelo em produção,
será preciso registrar o modelo treinado para que o mesmo seja carregado e usado na construção dos _workers_, conforme
descrito no passo 3. Siga as instruções abaixo para registrar o modelo:
- Caso o servidor do MLflow não esteja rodando, entre na pasta onde o **script que salvará o experimento** (código
desenvolvido para criação do modelo) se encontra;
- Ative o ambiente virtual Python criado para rodar os experimentos, ou se preferir, crie um novo. Instruções: [Linux e Windows (escolha o sistema na página)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment);
- Inicie o servidor do MLflow;
```bash
mlflow server --backend-store-uri sqlite:///teste_mlflow.db --host 0.0.0.0 -p 5000 --default-artifact-root mlruns
```
- Acesse o MLflow ([http://localhost:5000](http://localhost:5000)) e clique no experimento que foi criado por você (se
o experimento não estiver listado, verifique se o servidor do MLflow foi iniciado de dentro da pasta correta);
- Clique no link (que está na coluna **'Models'**) para a rodada do experimento que deseja registrar;
- Clique no botão **'Register Model'** e escolha a opção **'Create New Model'**;
- Dê um nome para o modelo e clique em **'Register'**;
- Na barra superior clique em **'Models'**;
- Clique no link para a última versão do modelo que está em **'Latest Version'**;
- Na opção **'Aliases'**, clique em **'Add'**;
- Digite **_production_** e clique em **'Save aliases'**.
Quando for testar a implementação dos _workers_ (passo 3), lembre de deixar o servidor do MLflow rodando para que seja
possível carregar o modelo.
## 2. Organize o código de acordo com o _template_
Uma vez que o modelo foi desenvolvido e testado, agora é o momento de iniciar as tratativas para publicá-lo na _stack_ de ML do
Prodest. Porém, antes, é oportuno mostrar como o modelo será integrado à _stack_. Esta integração se dará através de
componentes denominados _workers_, cuja codificação é de responsabilidade de quem está construindo o modelo. Na
ilustração abaixo é possível observar que os _workers_ são acessados pelos componentes de apoio da _stack_ para
permitir a publicação dos modelos. Caso seja necessário, uma mesma stack poderá publicar mais de um modelo.
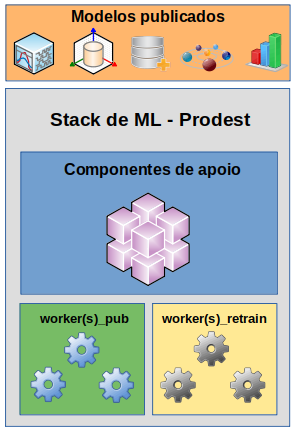
Existem dois tipos de _workers_:
- **worker_pub**: Fornece os métodos necessários para publicação do modelo.
- **worker_retrain**: Responsável pela avaliação do desempenho do modelo e retreinamento, se for preciso.
Para que o modelo possa ser publicado, é imprescindível que a organização do código seja conforme especificado na pasta
'**templates**' (esta pasta vem junto com repositório da lib).
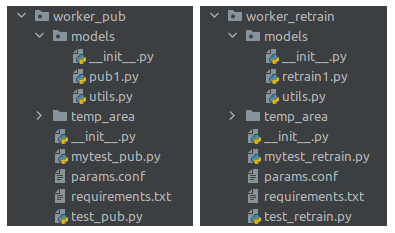
As regras são simples mas precisam ser seguidas, caso contrário a publicação do modelo falhará.
- Os nomes das pastas '**worker_pub**' e '**worker_retrain**' não podem ser alterados;
- Os nomes dos scripts padrões contidos nestas pastas não podem ser alterados;
- (Opcional, mas recomendável). Separe as funções utilitárias para o funcionamento dos _workers_ nos arquivos '**utils.py**';
- Gere um arquivo de _requirements_ para cada um dos _workers_ **separadamente**. Dica: Use um ambiente virtual Python
separado para cada _worker_, instale os pacotes requeridos para o funcionamento deles e no final gere um arquivo
'**requirements.txt**' para cada _worker_;
- Não importe código de fora destas pastas. Se os dois _workers_ precisarem de uma mesma função, faça uma cópia desta em
cada pasta (o arquivo 'utils.py' pode ajudar a organizar estas funções!);
- Cuide para que os importes funcionem corretamente, dentro de cada pasta, **sem precisar** configurar a variável de
ambiente PYTHONPATH;
- Utilize a pasta '**temp_area**' para salvar e ler os arquivos temporários que forem criados.
**NOTA**: Os scripts '**mytest_pub.py**' e '**mytest_retrain.py**' podem ser utilizados por você para criação de testes
personalizados, para isso basta implementar a função '**test**' em cada um deles. Já os scripts '**test_pub.py**' e
'**test_retrain.py**' podem ser usados para testar se algumas premissas foram atendidas, através de testes padrões
da lib e a execução automática dos testes personalizados que foram implementados pelo usuário. No passo 3 é mostrado
como rodar os scripts '**test_pub.py**' e '**test_retrain.py**'.
Caso queira, você pode criar pastas ou arquivos de apoio dentro das pastas dos _workers_ para organizar seu código,
desde que não modique a localização dos arquivos especificada pelos _templates_.
Para obter e utilizar a pasta com os _templates_:
- Clone o repositório da lib;
```bash
git clone https://github.com/prodest/mllibprodest.git
```
- Entre na pasta gerada no processo de clonagem do repositório e copie o conteúdo da pasta '**templates**' para outro local
de sua preferência (não trabalhe na pasta do repositório).
- **Organize o código responsável pelo treino do modelo**. Copie todos os _scripts_ que são utilizados para treinar o modelo
para a pasta '**training_model**' (**não** incluir a pasta '**env**' nem arquivos desnecessários) e altere o _script_
'**train.py**' para que ele chame o _script_ principal do modelo, ou, se preferir, apague o _script_ 'train.py' e
renomeie o _script_ principal do modelo para 'train.py'.
- Gere o arquivo de _requirements_ para o código do modelo e coloque-o dentro da pasta '**training_model**'.
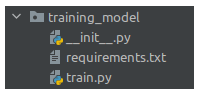
**NOTA**: Não altere o nome da pasta '**training_model**' nem do _script_ '**train.py**'. Estruture o código para que
não haja necessidade de criar a variável de ambiente PYTHONPATH para fazer os 'imports' do código do modelo.
## 3. Implemente as interfaces da biblioteca
Antes de iniciar a implementação das interfaces, é importante criar um ambiente virtual Python **separadamente** para cada
_worker_. Dessa forma você conseguirá gerar os arquivos de _requirements_ sem maiores problemas. Siga as instruções abaixo:
**Para o worker_pub**:
- Abra um prompt de comando ou terminal;
- Entre na pasta para onde você copiou o conteúdo da pasta '**templates**';
- Entre na pasta '**worker_pub**', crie e ative um ambiente virtual Python, conforme instruções: [Linux e Windows (escolha o sistema na página)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment);
- Atualize o pip e o setuptools;
- Instale a lib para o worker_pub;
```bash
pip install --upgrade pip setuptools
pip install mllibprodest
```
- Feche o prompt de comando ou terminal.
**Para o worker_retrain**:
- Abra **outro** prompt de comando ou terminal (**Não** aproveite o anterior de forma alguma, pois dará errado!);
- Entre na pasta para onde você copiou o conteúdo da pasta '**templates**';
- Entre na pasta '**worker_retrain**', crie e ative **outro** ambiente virtual Python;
- Atualize o pip e o setuptools;
- Instale a lib para o worker_retrain;
```bash
pip install --upgrade pip setuptools
pip install mllibprodest
```
- Feche o prompt de comando ou terminal.
Pronto. Agora você tem um ambiente virtual Python para cada _worker_. Quando for utilizar uma IDE ou editor de código
para implementar as interfaces, configure para que eles utilizem os ambientes virtuais criados para os respectivos
_workers_. Dessa forma, à medida que você for produzindo o código e necessitar de instalar pacotes, esses serão
instalados nos ambientes virtuais criados. Quando terminar a implementação, basta você gerar os arquivos de
_requirements_ com base no ambiente virtual de cada _worker_ separadamente. Acredite, isso vai te ajudar bastante!
Outro ponto importante antes de implementar as interfaces é saber que: para publicar o modelo será necessário a criação
de três artefatos obrigatórios, inclusive seguindo o mesmo nome (_case sensitive_). Estes artefatos devem ser
dicionários (dict) salvos com o [Pickle](https://docs.python.org/3/library/pickle.html) (utilize a função
'convert_artifact_to_pickle' quando estiver implementando as interfaces):
- **TrainingParams.pkl**: Deve conter os parâmetros que você escolheu utilizar no treinamento do modelo. Não há
necessidade de colocar os parâmetros nos quais você manteve os valores _default_. Você pode colocar outros parâmetros,
criados por você, necessários para que o modelo funcione. Coloque o nome
do parâmetro como nome da chave e o valor do parâmetro como valor da chave. Ex. baseado no _DecisionTreeClassifier_:
{'criterion': 'entropy', 'max_depth': '20', 'random_state': '77', 'meu_parametro_personalizado': 'teste'}.
- **TrainingDatasetsNames.pkl**: Deve conter os tipos de datasets e os nomes dos respectivos arquivos utilizados no
treinamento do modelo. Exemplo: {'features': 'nome_arquivo_features', 'targets': 'nome_arquivo_targets'}.
- **BaselineMetrics.pkl**: Deve conter as métricas que você achar relevantes para decidir se o modelo precisa ser
retreinado. Por exemplo, você poderia definir a métrica acurácia mínima e caso o modelo que estiver em produção, ao ser
avaliado, não estiver atingindo o valor dessa métrica, será um indicativo de que ele precisa ser retreinado. Outro exemplo
claro da necessidade de retreinamento é quando um modelo de classificação é treinado para predizer um conjunto de _labels_
e por um motivo qualquer surgem novos _labels_. Nesse caso, o modelo não saberá predizer estes _labels_ e necessitará
ser retreinado em um dataset atualizado com os novos _labels_. Exemplo: {'acuracia_minima': 0.94,
'labels_presentes_no_treino': ['gato', 'cachorro']}.
**NOTA**: Estes artefatos deverão ser criados pelo script utilizado para registro dos experimentos no processo de
treinamento do modelo e salvos através da função '**mlflow.log_artifact**', no momento da realização dos experimentos. Os
artefatos salvos junto com o modelo devem ser utilizados na implementação das funcionalidades das interfaces no momento
da construção dos _workers_. A única maneira de obter parâmetros e informações acerca do modelo registrado será por
intermédio destes artefatos. Por favor, não persista nada localmente, pois os _workers_ não trocarão mensagens nem
compartilharão acesso à dados entre si.
Para implementar as interfaces e construir os _workers_ basta editar os _templates_ conforme abaixo:
**REGRAS**: Implemente todos os métodos solicitados respeitando os tipos dos parâmetros e de retorno. Não troque os
nomes dos parâmetros.
**worker_pub**:
- Abra o arquivo '**pub1.py**', que se encontra na pasta '**worker_pub/models**', e implemente os métodos da interface
**ModelPublicationInterfaceCLF** através da classe **ModeloCLF**. Leia os comentários, eles te guiarão na implementação.
- Abra o arquivo '**params.conf**', que se encontra na pasta '**worker_pub**', e informe os parâmetros dos modelos.
Leia os comentários, eles te guiarão na configuração.
**worker_retrain**:
- Abra o arquivo '**retrain1.py**', que se encontra na pasta '**worker_retrain/models**', e implemente os métodos da interface
**ModelPublicationInterfaceRETRAIN** através da classe **ModeloRETRAIN**. Leia os comentários, eles te guiarão na
implementação.
- Abra o arquivo '**params.conf**', que se encontra na pasta '**worker_retrain**', e informe os parâmetros dos modelos.
Leia os comentários, eles te guiarão na configuração.
**NOTA**: É possível publicar um ou mais modelos utilizando uma mesma **Stack**. Para isso, basta fazer as devidas
configurações de cada um dos modelos nos arquivos '**params.conf**' constantes nas pastas **worker_pub** e **worker_retrain**.
A lib disponibiliza vários métodos úteis que auxiliarão na implementação das interfaces.
Todos os métodos estão documentados via [docstrings](https://peps.python.org/pep-0257/) que, geralmente, são
renderizadas pelas IDEs ou editores de código facilitando a leitura da documentação. Veja alguns métodos úteis disponíveis:
- **make_log** - Criação do arquivo para geração de logs.
- **load_datasets** - Carga de datasets.
- **load_model** - Carga de modelos salvos.
- **load_production_params**, **load_production_datasets_names**, **load_production_baseline** - Carga das informações
dos modelos publicados, salvas através dos artefatos obrigatórios.
- **convert_artifact_to_pickle** - Conversão de um artefato para o formato pickle.
- **convert_artifact_to_object** - Conversão de um artefato que está no formato pickle para o objeto de origem.
Explore a [documentação](https://prodest.github.io/mllibprodest) para saber das possibilidades de uso da lib.
### Teste o código produzido!
O repositório da lib disponibiliza os scripts '**test_pub.py**' e '**test_retrain.py**' para realização de testes para
verificar se alguns requisitos solicitados estão sendo atendidos. Também é possível criar testes personalizados através da
implementação da função '**test**' que se encontra nos scripts '**mytest_pub.py**' e '**mytest_retrain.py**'. Todos
estes scripts estão nas pastas **worker_pub** e **worker_retrain**.
Para testar o seu código siga as instruções abaixo:
- Caso o servidor do MLflow não esteja rodando, entre na pasta onde o código/script para registro dos experimentos/modelo
se encontra; ative o ambiente virtual Python, instruções: [Linux e Windows (escolha o sistema na página)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment),
e inicie o servidor do MLflow:
```bash
mlflow server --backend-store-uri sqlite:///teste_mlflow.db --host 0.0.0.0 -p 5000 --default-artifact-root mlruns
```
- Obtenha o caminho completo da pasta '**mlruns**' (ela é criada dentro da pasta onde o script para geração dos
experimentos/modelo foi executado);
- Se for testar o _worker_ pub, entre na pasta '**worker_pub**' e execute o comando abaixo. Lembre-se de informar o
caminho completo da pasta '**mlruns**' através do parâmetro '**--mlruns_path**';
```bash
python test_pub.py --mlruns_path="caminho completo para a pasta mlruns"
```
- Se for testar o _worker_ retrain, entre na pasta '**worker_retrain**' e execute o comando abaixo. Lembre-se de
informar o caminho completo da pasta '**mlruns**' através do parâmetro '**--mlruns_path**';
```bash
python test_retrain.py --mlruns_path="caminho completo para a pasta mlruns"
```
Leia atentamente as mensagens e caso exista alguma inconsistência no teste, atenda ao que for solicitado pelo script.
## 4. Disponibilize o código para publicação do modelo
Antes de enviar os códigos, certifique-se que eles estão funcionando de acordo com as regras estabelecidas e que os
arquivos com os _requirements_ foram gerados corretamente. Se ocorrer algum erro que impeça a publicação, entraremos
em contato para informar o ocorrido e fornecer as informações sobre o erro.
**DICA:** **Não** é obrigatório, porém se você quiser testar o modelo implementado, antes de disponibilizá-lo para
publicação; clone o repositório da [Stack de ML do Prodest](https://github.com/prodest/prodest-ml-stack)
(versão standalone) e siga as instruções para fazer o _deploy_ da Stack e o teste do seu modelo utilizando ela.
Para disponibilizar o modelo para publicação:
- Crie uma pasta chamada '**publicar**';
- Copie as pastas '**worker_pub**', '**worker_retrain**' e '**training_model**' para a pasta '**publicar**'
(**não** incluir a pasta
'**env**', que é do ambiente virtual Python, nem a pasta '**temp_area**', que é utilizada para guardar arquivos
temporários) ;
- Compacte a pasta '**publicar**' utilizando o formato '.zip';
- Envie o arquivo '**publicar.zip**' para o Prodest, conforme alinhamento prévio realizado em reunião ou qualquer
outro meio de contato.
Raw data
{
"_id": null,
"home_page": "https://github.com/prodest/mllibprodest",
"name": "mllibprodest",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.11",
"maintainer_email": null,
"keywords": "Prodest, ML, lib, stack",
"author": "Instituto de Tecnologia da Informa\u00e7\u00e3o e Comunica\u00e7\u00e3o do Esp\u00edrito Santo (PRODEST)",
"author_email": "\"Instituto de Tecnologia da Informa\u00e7\u00e3o e Comunica\u00e7\u00e3o do Esp\u00edrito Santo (PRODEST)\" <prodest@prodest.es.gov.br>",
"download_url": "https://files.pythonhosted.org/packages/a8/d6/8a993e38d2828c7ca11b97689f508a74393a235d58edf36af90abcdb934a/mllibprodest-1.8.9.tar.gz",
"platform": null,
"description": "# Biblioteca de ML (_Machine Learning_) - Prodest\n\nA finalidade desta biblioteca \u00e9 prover interfaces e fun\u00e7\u00f5es que d\u00e3o suporte ao provisionamento de modelos de ML na Stack\nde ML do Prodest.\n\nAcesse a [documenta\u00e7\u00e3o da lib](https://prodest.github.io/mllibprodest)!\n\n_Workflow_ b\u00e1sico para constru\u00e7\u00e3o, disponibiliza\u00e7\u00e3o e publica\u00e7\u00e3o de modelos:\n\n\n\n## Pr\u00e9-requisitos\n\n- **Python >= 3.11.** Instru\u00e7\u00f5es: [Linux (Geralmente j\u00e1 vem instalado por padr\u00e3o)](https://python.org.br/instalacao-linux) ou [Windows](https://www.python.org/downloads/windows).\n- **Git.** Instru\u00e7\u00f5es: [Linux](https://git-scm.com/download/linux) ou [Windows](https://git-scm.com/download/win).\n- **Venv.** Gerenciador de ambiente virtual Python adotado no tutorial. Instru\u00e7\u00f5es: [Linux e Windows (escolha o sistema na p\u00e1gina)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment).\n Ou qualquer outro gerenciador de ambiente Python que preferir.\n\n## 1. Realize experimentos e escolha o modelo\n\nEsta \u00e9 uma das etapas iniciais de um projeto para o desenvolvimento de um modelo de _Machine Learning_. Neste momento \u00e9\nnecess\u00e1rio entender o problema a ser resolvido; levantar requisitos; obter e tratar os dados, etc. Tamb\u00e9m \u00e9 nessa etapa\nque se verifica a viabilidade (ou n\u00e3o) da constru\u00e7\u00e3o de um modelo.\n\nNeste passo voc\u00ea tem **total liberdade** para construir o seu modelo e realizar os experimentos que quiser. Entretanto,\n\u00e9 importante que os resultados e artefatos gerados pelos experimentos, desde j\u00e1, sejam registrados para facilitar a\ncompara\u00e7\u00e3o dos resultados obtidos e a publica\u00e7\u00e3o do modelo. Esta lib utiliza o\n[MLflow](https://github.com/mlflow/mlflow) como plataforma para registro dos experimentos/modelos (no contexto da lib, o\nMLflow \u00e9 chamado de _Provider_).\n\nApesar do registro dos experimentos ser importante, deixar de registr\u00e1-los agora **n\u00e3o** vai impedir que voc\u00ea construa o\nseu modelo!\n\nVoc\u00ea tem duas op\u00e7\u00f5es:\n\n- Seguir com a constru\u00e7\u00e3o do modelo e execu\u00e7\u00e3o dos experimentos e, caso chegue \u00e0 conclus\u00e3o de que o modelo \u00e9 vi\u00e1vel,\n ajustar o c\u00f3digo para realizar o registro; ou\n\n- Fazer uma pausa e entender primeiro como registrar seus experimentos no MLflow e j\u00e1 construir o c\u00f3digo com a l\u00f3gica\n necess\u00e1ria para isso.\n\nIndependente da op\u00e7\u00e3o escolhida, haver\u00e1 necessidade de, agora ou depois, aprender (caso n\u00e3o saiba) como registrar os\nexperimentos do modelo no MLflow.\nPara alcan\u00e7ar esse objetivo, leia a [documenta\u00e7\u00e3o oficial do MLflow](https://mlflow.org/docs/latest/index.html).\n\nSegue abaixo, um exemplo simples de como utilizar o MLflow para registrar os experimentos de um modelo constru\u00eddo com o [scikit-learn](https://scikit-learn.org).\n\n```python\nimport os\nimport mlflow.sklearn # Importa o sklearn atrav\u00e9s do MLflow\nimport pickle # Para gerar um artefato de exemplo\n\n# Obs.: Utilize as duas linhas abaixo, exatamente como apresentadas, para configurar o\n# par\u00e2metro 'Tracking URI' do MLflow nos seus c\u00f3digos de testes. Dessa forma, quando subir\n# para produ\u00e7\u00e3o n\u00e3o haver\u00e1 necessidade de modific\u00e1-las, pois l\u00e1 o par\u00e2metro 'Tracking URI'\n# ser\u00e1 obtido diretamente atrav\u00e9s da vari\u00e1vel de ambiente 'MLFLOW_TRACKING_URI'.\nif os.environ.get('MLFLOW_TRACKING_URI') is None:\n mlflow.set_tracking_uri('sqlite:///teste_mlflow.db')\n\n# Configura o experimento (se n\u00e3o existir, cria)\nmlflow.set_experiment(experiment_name=\"Teste_sklearn\")\n\n# Inicia uma execu\u00e7\u00e3o do experimento (um experimento pode possuir v\u00e1rias execu\u00e7\u00f5es)\nmlflow.start_run(run_name=\"t1\", description=\"teste 1\")\n\n# Registra algumas informa\u00e7\u00f5es adicionais no experimento (coloque as informa\u00e7\u00f5es que julgar\n# necess\u00e1rias, no formato dict)\ntags = {\"Projeto\": \"Teste\", \"team\": \"ML\", \"util\": \"Informa\u00e7\u00e3o \u00fatil\"}\nmlflow.set_tags(tags)\n\n# Inicia o registro dos logs da execu\u00e7\u00e3o do sklearn\nmlflow.sklearn.autolog()\n\n# TODO: Inclua aqui a l\u00f3gica para fazer o fit do modelo\n\n'''Exemplo de modelo, somente para o prop\u00f3sito de testes!'''\n# Adaptado de https://scikit-learn.org/stable/modules/tree.html#classification\nimport matplotlib\nimport numpy as np\nfrom sklearn import tree\nX = np.array([[0, 0], [1, 1]])\nY = np.array([0, 1]).reshape(-1)\nclf = tree.DecisionTreeClassifier()\nclf = clf.fit(X, Y)\n'''Fim do exemplo de modelo.'''\n\n'''\nSalva um artefato de seu interesse no MLflow (podem ser arquivos em diversos formatos: txt,\npkl, png, jpeg, etc.). Exemplos de artefatos: gr\u00e1ficos, objetos persistidos com pickle,\nenfim, tudo que for relevante e/ou necess\u00e1rio para que o modelo funcione e/ou para an\u00e1lise\ndas execu\u00e7\u00f5es.\n'''\n# Cria um aterfato de teste no formato pickle (obs.: todas as classes da lib tem os m\u00e9todos\n# 'convert_artifact_to_pickle' e 'convert_artifact_to_object' para auxiliar na persist\u00eancia\n# dos artefatos)\nartefato = {\"t\": 1}\ncaminho_artefato = \"artefato.pkl\"\nwith open(caminho_artefato, 'wb') as arq:\n pickle.dump(artefato, arq)\n\n# Salva o artefato criado\nmlflow.log_artifact(caminho_artefato)\n\n# Finaliza o experimento\nmlflow.end_run()\n\nprint(\"\\nTeste finalizado!\\n\")\n```\n\nSe voc\u00ea quiser testar um registro de experimento atrav\u00e9s do c\u00f3digo acima, fa\u00e7a o seguinte:\n\n- Crie uma pasta para testes;\n- Copie e cole o c\u00f3digo acima em um editor de texto simples e salve com o nome 'testeml.py' dentro da pasta criada;\n- Abra um prompt de comando ou terminal e entre na pasta criada;\n- Crie e ative um ambiente virtual Python, conforme instru\u00e7\u00f5es: [Linux e Windows (escolha o sistema na p\u00e1gina)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment);\n- Atualize o pip e o setuptools;\n- Instale os pacotes mlflow, sklearn, matplotlib e numpy;\n\n```bash\npip install --upgrade pip setuptools\n```\n\n```bash\npip install mlflow==3.1.1 scikit-learn==1.7.0 matplotlib==3.10.3 numpy==2.3.1\n```\n\n- Rode o teste (ignore as mensagens do tipo 'INFO' de cria\u00e7\u00e3o do banco de dados);\n\n```bash\npython testeml.py\n```\n\nCabe observar que: depois de rodar o c\u00f3digo de teste, foi criada uma pasta chamada '**mlruns**', dentro da pasta de\ntestes, que serve para armazenar os artefatos gerados pelo c\u00f3digo e que s\u00e3o apresentados na interface do MLflow.\nAbaixo segue uma listagem do conte\u00fado gerado pelo c\u00f3digo de teste (obs.: essa parte do caminho vai ser diferente de\nacordo com cada experimento/execu\u00e7\u00e3o realizados: '1/1a67156e63444d6e886fab7c8459bb8b'. O conte\u00fado da pasta tamb\u00e9m ser\u00e1\ndiferente de acordo com cada modelo).\n\n```bash\n(env) user:/teste/mlruns/1/1a67156e63444d6e886fab7c8459bb8b/artifacts$ dir\nartefato.pkl estimator.html model training_confusion_matrix.png training_precision_recall_curve.png training_roc_curve.png\n```\n\nDentro da pasta criada para testes tamb\u00e9m foi gerado um arquivo chamado '**teste_mlflow.db**', que \u00e9 um pequeno banco\nde dados [SQlite](https://www.sqlite.org), que serve para armazenar os modelos que foram registrados.\n\n- Inicie o servidor do MLflow;\n\nPerceba que a pasta '**mlruns**' e o arquivo '**teste_mlflow.db**' s\u00e3o passados como par\u00e2metros na hora de iniciar o\nservidor, para que o experimento de teste possa ser visualizado. Portanto, \u00e9 **mandat\u00f3rio** sempre iniciar o servidor do\nMLflow **de dentro da pasta** onde se encontra o c\u00f3digo que far\u00e1 o registro dos artefatos e dos experimentos/modelos.\n\n**DICA**: Abra um outro prompt de comando ou terminal diferente; entre na pasta onde se encontra o c\u00f3digo para registro\ndos experimentos/modelo; **ative** o ambiente virtual criado anteriormente; execute o comando para iniciar o servidor do MLflow de dentro desta pasta. Pois assim, voc\u00ea\nconseguir\u00e1 rodar o c\u00f3digo e j\u00e1 observar os resultados sem ter que parar o servidor para liberar o prompt ou terminal.\n\n```bash\nmlflow server --backend-store-uri sqlite:///teste_mlflow.db --host 0.0.0.0 -p 5000 --default-artifact-root mlruns\n```\n\n- Verifique se o experimento foi criado. Acesse o MLFlow: [http://localhost:5000](http://localhost:5000) e procure\n pelo experimento/execu\u00e7\u00e3o '**Teste_sklearn**' na se\u00e7\u00e3o **Experiments** (se o experimento n\u00e3o estiver listado, verifique\n se o servidor foi iniciado de dentro da pasta correta);\n\n- Clique na execu\u00e7\u00e3o do experimento que se encontra na coluna '**Run Name**' (destaque em verde);\n\n\n\n- Verifique se os artefatos foram gravados;\n\n\n\n- Finalize o servidor do MLflow. Fa\u00e7a 'CTRL+c' no prompt de comando ou terminal onde ele foi iniciado;\n- Apague a pasta criada para realiza\u00e7\u00e3o dos testes.\n\n**NOTA**: Existem v\u00e1rios outros _frameworks_ suportados: TensorFlow, Keras, Pytorch, etc. (veja a lista completa para\nPython em [MLflow Python API](https://mlflow.org/docs/latest/python_api/index.html)), inclusive \u00e9 poss\u00edvel registrar\nmodelos que **n\u00e3o s\u00e3o suportados nativamente** pelo MLflow utilizando a fun\u00e7\u00e3o\n[mlflow.pyfunc](https://mlflow.org/docs/latest/python_api/mlflow.pyfunc.html).\n\n**ATEN\u00c7\u00c3O**: Sua intera\u00e7\u00e3o direta com o MLflow ser\u00e1 somente para registro dos experimentos/modelo. Essa intera\u00e7\u00e3o \u00e9\nessencial porque d\u00e1 liberdade ao desenvolvedor para escolher o _framework_ que achar mais adequado para constru\u00e7\u00e3o\ndo seu modelo. A lib disponibiliza fun\u00e7\u00f5es para obten\u00e7\u00e3o do modelo registrado e dos seus artefatos, al\u00e9m de\noutras fun\u00e7\u00f5es relacionadas \u00e0 carga de _datasets_. Leia a documenta\u00e7\u00e3o das interfaces, classes e fun\u00e7\u00f5es da lib para\nmais detalhes.\n\n### Antes de ir para os pr\u00f3ximos passos...\n\nQuando voc\u00ea j\u00e1 tiver realizado v\u00e1rios experimentos utilizando o MLflow e decidido por colocar o modelo em produ\u00e7\u00e3o,\nser\u00e1 preciso registrar o modelo treinado para que o mesmo seja carregado e usado na constru\u00e7\u00e3o dos _workers_, conforme\ndescrito no passo 3. Siga as instru\u00e7\u00f5es abaixo para registrar o modelo:\n\n- Caso o servidor do MLflow n\u00e3o esteja rodando, entre na pasta onde o **script que salvar\u00e1 o experimento** (c\u00f3digo\n desenvolvido para cria\u00e7\u00e3o do modelo) se encontra;\n- Ative o ambiente virtual Python criado para rodar os experimentos, ou se preferir, crie um novo. Instru\u00e7\u00f5es: [Linux e Windows (escolha o sistema na p\u00e1gina)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment);\n- Inicie o servidor do MLflow;\n\n```bash\nmlflow server --backend-store-uri sqlite:///teste_mlflow.db --host 0.0.0.0 -p 5000 --default-artifact-root mlruns\n```\n\n- Acesse o MLflow ([http://localhost:5000](http://localhost:5000)) e clique no experimento que foi criado por voc\u00ea (se\n o experimento n\u00e3o estiver listado, verifique se o servidor do MLflow foi iniciado de dentro da pasta correta);\n- Clique no link (que est\u00e1 na coluna **'Models'**) para a rodada do experimento que deseja registrar;\n- Clique no bot\u00e3o **'Register Model'** e escolha a op\u00e7\u00e3o **'Create New Model'**;\n- D\u00ea um nome para o modelo e clique em **'Register'**;\n- Na barra superior clique em **'Models'**;\n- Clique no link para a \u00faltima vers\u00e3o do modelo que est\u00e1 em **'Latest Version'**;\n- Na op\u00e7\u00e3o **'Aliases'**, clique em **'Add'**;\n- Digite **_production_** e clique em **'Save aliases'**.\n\nQuando for testar a implementa\u00e7\u00e3o dos _workers_ (passo 3), lembre de deixar o servidor do MLflow rodando para que seja\nposs\u00edvel carregar o modelo.\n\n## 2. Organize o c\u00f3digo de acordo com o _template_\n\nUma vez que o modelo foi desenvolvido e testado, agora \u00e9 o momento de iniciar as tratativas para public\u00e1-lo na _stack_ de ML do\nProdest. Por\u00e9m, antes, \u00e9 oportuno mostrar como o modelo ser\u00e1 integrado \u00e0 _stack_. Esta integra\u00e7\u00e3o se dar\u00e1 atrav\u00e9s de\ncomponentes denominados _workers_, cuja codifica\u00e7\u00e3o \u00e9 de responsabilidade de quem est\u00e1 construindo o modelo. Na\nilustra\u00e7\u00e3o abaixo \u00e9 poss\u00edvel observar que os _workers_ s\u00e3o acessados pelos componentes de apoio da _stack_ para\npermitir a publica\u00e7\u00e3o dos modelos. Caso seja necess\u00e1rio, uma mesma stack poder\u00e1 publicar mais de um modelo.\n\n\n\nExistem dois tipos de _workers_:\n\n- **worker_pub**: Fornece os m\u00e9todos necess\u00e1rios para publica\u00e7\u00e3o do modelo.\n- **worker_retrain**: Respons\u00e1vel pela avalia\u00e7\u00e3o do desempenho do modelo e retreinamento, se for preciso.\n\nPara que o modelo possa ser publicado, \u00e9 imprescind\u00edvel que a organiza\u00e7\u00e3o do c\u00f3digo seja conforme especificado na pasta\n'**templates**' (esta pasta vem junto com reposit\u00f3rio da lib).\n\n\n\nAs regras s\u00e3o simples mas precisam ser seguidas, caso contr\u00e1rio a publica\u00e7\u00e3o do modelo falhar\u00e1.\n\n- Os nomes das pastas '**worker_pub**' e '**worker_retrain**' n\u00e3o podem ser alterados;\n- Os nomes dos scripts padr\u00f5es contidos nestas pastas n\u00e3o podem ser alterados;\n- (Opcional, mas recomend\u00e1vel). Separe as fun\u00e7\u00f5es utilit\u00e1rias para o funcionamento dos _workers_ nos arquivos '**utils.py**';\n- Gere um arquivo de _requirements_ para cada um dos _workers_ **separadamente**. Dica: Use um ambiente virtual Python\n separado para cada _worker_, instale os pacotes requeridos para o funcionamento deles e no final gere um arquivo\n '**requirements.txt**' para cada _worker_;\n- N\u00e3o importe c\u00f3digo de fora destas pastas. Se os dois _workers_ precisarem de uma mesma fun\u00e7\u00e3o, fa\u00e7a uma c\u00f3pia desta em\n cada pasta (o arquivo 'utils.py' pode ajudar a organizar estas fun\u00e7\u00f5es!);\n- Cuide para que os importes funcionem corretamente, dentro de cada pasta, **sem precisar** configurar a vari\u00e1vel de\n ambiente PYTHONPATH;\n- Utilize a pasta '**temp_area**' para salvar e ler os arquivos tempor\u00e1rios que forem criados.\n\n**NOTA**: Os scripts '**mytest_pub.py**' e '**mytest_retrain.py**' podem ser utilizados por voc\u00ea para cria\u00e7\u00e3o de testes\npersonalizados, para isso basta implementar a fun\u00e7\u00e3o '**test**' em cada um deles. J\u00e1 os scripts '**test_pub.py**' e\n'**test_retrain.py**' podem ser usados para testar se algumas premissas foram atendidas, atrav\u00e9s de testes padr\u00f5es\nda lib e a execu\u00e7\u00e3o autom\u00e1tica dos testes personalizados que foram implementados pelo usu\u00e1rio. No passo 3 \u00e9 mostrado\ncomo rodar os scripts '**test_pub.py**' e '**test_retrain.py**'.\n\nCaso queira, voc\u00ea pode criar pastas ou arquivos de apoio dentro das pastas dos _workers_ para organizar seu c\u00f3digo,\ndesde que n\u00e3o modique a localiza\u00e7\u00e3o dos arquivos especificada pelos _templates_.\n\nPara obter e utilizar a pasta com os _templates_:\n\n- Clone o reposit\u00f3rio da lib;\n\n```bash\ngit clone https://github.com/prodest/mllibprodest.git\n```\n\n- Entre na pasta gerada no processo de clonagem do reposit\u00f3rio e copie o conte\u00fado da pasta '**templates**' para outro local\n de sua prefer\u00eancia (n\u00e3o trabalhe na pasta do reposit\u00f3rio).\n\n- **Organize o c\u00f3digo respons\u00e1vel pelo treino do modelo**. Copie todos os _scripts_ que s\u00e3o utilizados para treinar o modelo\n para a pasta '**training_model**' (**n\u00e3o** incluir a pasta '**env**' nem arquivos desnecess\u00e1rios) e altere o _script_\n '**train.py**' para que ele chame o _script_ principal do modelo, ou, se preferir, apague o _script_ 'train.py' e\n renomeie o _script_ principal do modelo para 'train.py'.\n\n- Gere o arquivo de _requirements_ para o c\u00f3digo do modelo e coloque-o dentro da pasta '**training_model**'.\n\n\n\n**NOTA**: N\u00e3o altere o nome da pasta '**training_model**' nem do _script_ '**train.py**'. Estruture o c\u00f3digo para que\nn\u00e3o haja necessidade de criar a vari\u00e1vel de ambiente PYTHONPATH para fazer os 'imports' do c\u00f3digo do modelo.\n\n## 3. Implemente as interfaces da biblioteca\n\nAntes de iniciar a implementa\u00e7\u00e3o das interfaces, \u00e9 importante criar um ambiente virtual Python **separadamente** para cada\n_worker_. Dessa forma voc\u00ea conseguir\u00e1 gerar os arquivos de _requirements_ sem maiores problemas. Siga as instru\u00e7\u00f5es abaixo:\n\n**Para o worker_pub**:\n\n- Abra um prompt de comando ou terminal;\n- Entre na pasta para onde voc\u00ea copiou o conte\u00fado da pasta '**templates**';\n- Entre na pasta '**worker_pub**', crie e ative um ambiente virtual Python, conforme instru\u00e7\u00f5es: [Linux e Windows (escolha o sistema na p\u00e1gina)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment);\n- Atualize o pip e o setuptools;\n- Instale a lib para o worker_pub;\n\n```bash\npip install --upgrade pip setuptools\npip install mllibprodest\n```\n\n- Feche o prompt de comando ou terminal.\n\n**Para o worker_retrain**:\n\n- Abra **outro** prompt de comando ou terminal (**N\u00e3o** aproveite o anterior de forma alguma, pois dar\u00e1 errado!);\n- Entre na pasta para onde voc\u00ea copiou o conte\u00fado da pasta '**templates**';\n- Entre na pasta '**worker_retrain**', crie e ative **outro** ambiente virtual Python;\n- Atualize o pip e o setuptools;\n- Instale a lib para o worker_retrain;\n\n```bash\npip install --upgrade pip setuptools\npip install mllibprodest\n```\n\n- Feche o prompt de comando ou terminal.\n\nPronto. Agora voc\u00ea tem um ambiente virtual Python para cada _worker_. Quando for utilizar uma IDE ou editor de c\u00f3digo\npara implementar as interfaces, configure para que eles utilizem os ambientes virtuais criados para os respectivos\n_workers_. Dessa forma, \u00e0 medida que voc\u00ea for produzindo o c\u00f3digo e necessitar de instalar pacotes, esses ser\u00e3o\ninstalados nos ambientes virtuais criados. Quando terminar a implementa\u00e7\u00e3o, basta voc\u00ea gerar os arquivos de\n_requirements_ com base no ambiente virtual de cada _worker_ separadamente. Acredite, isso vai te ajudar bastante!\n\nOutro ponto importante antes de implementar as interfaces \u00e9 saber que: para publicar o modelo ser\u00e1 necess\u00e1rio a cria\u00e7\u00e3o\nde tr\u00eas artefatos obrigat\u00f3rios, inclusive seguindo o mesmo nome (_case sensitive_). Estes artefatos devem ser\ndicion\u00e1rios (dict) salvos com o [Pickle](https://docs.python.org/3/library/pickle.html) (utilize a fun\u00e7\u00e3o\n'convert_artifact_to_pickle' quando estiver implementando as interfaces):\n\n- **TrainingParams.pkl**: Deve conter os par\u00e2metros que voc\u00ea escolheu utilizar no treinamento do modelo. N\u00e3o h\u00e1\n necessidade de colocar os par\u00e2metros nos quais voc\u00ea manteve os valores _default_. Voc\u00ea pode colocar outros par\u00e2metros,\n criados por voc\u00ea, necess\u00e1rios para que o modelo funcione. Coloque o nome\n do par\u00e2metro como nome da chave e o valor do par\u00e2metro como valor da chave. Ex. baseado no _DecisionTreeClassifier_:\n {'criterion': 'entropy', 'max_depth': '20', 'random_state': '77', 'meu_parametro_personalizado': 'teste'}.\n\n- **TrainingDatasetsNames.pkl**: Deve conter os tipos de datasets e os nomes dos respectivos arquivos utilizados no\n treinamento do modelo. Exemplo: {'features': 'nome_arquivo_features', 'targets': 'nome_arquivo_targets'}.\n\n- **BaselineMetrics.pkl**: Deve conter as m\u00e9tricas que voc\u00ea achar relevantes para decidir se o modelo precisa ser\n retreinado. Por exemplo, voc\u00ea poderia definir a m\u00e9trica acur\u00e1cia m\u00ednima e caso o modelo que estiver em produ\u00e7\u00e3o, ao ser\n avaliado, n\u00e3o estiver atingindo o valor dessa m\u00e9trica, ser\u00e1 um indicativo de que ele precisa ser retreinado. Outro exemplo\n claro da necessidade de retreinamento \u00e9 quando um modelo de classifica\u00e7\u00e3o \u00e9 treinado para predizer um conjunto de _labels_\n e por um motivo qualquer surgem novos _labels_. Nesse caso, o modelo n\u00e3o saber\u00e1 predizer estes _labels_ e necessitar\u00e1\n ser retreinado em um dataset atualizado com os novos _labels_. Exemplo: {'acuracia_minima': 0.94,\n 'labels_presentes_no_treino': ['gato', 'cachorro']}.\n\n**NOTA**: Estes artefatos dever\u00e3o ser criados pelo script utilizado para registro dos experimentos no processo de\ntreinamento do modelo e salvos atrav\u00e9s da fun\u00e7\u00e3o '**mlflow.log_artifact**', no momento da realiza\u00e7\u00e3o dos experimentos. Os\nartefatos salvos junto com o modelo devem ser utilizados na implementa\u00e7\u00e3o das funcionalidades das interfaces no momento\nda constru\u00e7\u00e3o dos _workers_. A \u00fanica maneira de obter par\u00e2metros e informa\u00e7\u00f5es acerca do modelo registrado ser\u00e1 por\ninterm\u00e9dio destes artefatos. Por favor, n\u00e3o persista nada localmente, pois os _workers_ n\u00e3o trocar\u00e3o mensagens nem\ncompartilhar\u00e3o acesso \u00e0 dados entre si.\n\nPara implementar as interfaces e construir os _workers_ basta editar os _templates_ conforme abaixo:\n\n**REGRAS**: Implemente todos os m\u00e9todos solicitados respeitando os tipos dos par\u00e2metros e de retorno. N\u00e3o troque os\nnomes dos par\u00e2metros.\n\n**worker_pub**:\n\n- Abra o arquivo '**pub1.py**', que se encontra na pasta '**worker_pub/models**', e implemente os m\u00e9todos da interface\n **ModelPublicationInterfaceCLF** atrav\u00e9s da classe **ModeloCLF**. Leia os coment\u00e1rios, eles te guiar\u00e3o na implementa\u00e7\u00e3o.\n\n- Abra o arquivo '**params.conf**', que se encontra na pasta '**worker_pub**', e informe os par\u00e2metros dos modelos.\n Leia os coment\u00e1rios, eles te guiar\u00e3o na configura\u00e7\u00e3o.\n\n**worker_retrain**:\n\n- Abra o arquivo '**retrain1.py**', que se encontra na pasta '**worker_retrain/models**', e implemente os m\u00e9todos da interface\n **ModelPublicationInterfaceRETRAIN** atrav\u00e9s da classe **ModeloRETRAIN**. Leia os coment\u00e1rios, eles te guiar\u00e3o na\n implementa\u00e7\u00e3o.\n\n- Abra o arquivo '**params.conf**', que se encontra na pasta '**worker_retrain**', e informe os par\u00e2metros dos modelos.\n Leia os coment\u00e1rios, eles te guiar\u00e3o na configura\u00e7\u00e3o.\n\n**NOTA**: \u00c9 poss\u00edvel publicar um ou mais modelos utilizando uma mesma **Stack**. Para isso, basta fazer as devidas\nconfigura\u00e7\u00f5es de cada um dos modelos nos arquivos '**params.conf**' constantes nas pastas **worker_pub** e **worker_retrain**.\n\nA lib disponibiliza v\u00e1rios m\u00e9todos \u00fateis que auxiliar\u00e3o na implementa\u00e7\u00e3o das interfaces.\nTodos os m\u00e9todos est\u00e3o documentados via [docstrings](https://peps.python.org/pep-0257/) que, geralmente, s\u00e3o\nrenderizadas pelas IDEs ou editores de c\u00f3digo facilitando a leitura da documenta\u00e7\u00e3o. Veja alguns m\u00e9todos \u00fateis dispon\u00edveis:\n\n- **make_log** - Cria\u00e7\u00e3o do arquivo para gera\u00e7\u00e3o de logs.\n- **load_datasets** - Carga de datasets.\n- **load_model** - Carga de modelos salvos.\n- **load_production_params**, **load_production_datasets_names**, **load_production_baseline** - Carga das informa\u00e7\u00f5es\n dos modelos publicados, salvas atrav\u00e9s dos artefatos obrigat\u00f3rios.\n- **convert_artifact_to_pickle** - Convers\u00e3o de um artefato para o formato pickle.\n- **convert_artifact_to_object** - Convers\u00e3o de um artefato que est\u00e1 no formato pickle para o objeto de origem.\n\nExplore a [documenta\u00e7\u00e3o](https://prodest.github.io/mllibprodest) para saber das possibilidades de uso da lib.\n\n### Teste o c\u00f3digo produzido!\n\nO reposit\u00f3rio da lib disponibiliza os scripts '**test_pub.py**' e '**test_retrain.py**' para realiza\u00e7\u00e3o de testes para\nverificar se alguns requisitos solicitados est\u00e3o sendo atendidos. Tamb\u00e9m \u00e9 poss\u00edvel criar testes personalizados atrav\u00e9s da\nimplementa\u00e7\u00e3o da fun\u00e7\u00e3o '**test**' que se encontra nos scripts '**mytest_pub.py**' e '**mytest_retrain.py**'. Todos\nestes scripts est\u00e3o nas pastas **worker_pub** e **worker_retrain**.\n\nPara testar o seu c\u00f3digo siga as instru\u00e7\u00f5es abaixo:\n\n- Caso o servidor do MLflow n\u00e3o esteja rodando, entre na pasta onde o c\u00f3digo/script para registro dos experimentos/modelo\n se encontra; ative o ambiente virtual Python, instru\u00e7\u00f5es: [Linux e Windows (escolha o sistema na p\u00e1gina)](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/#creating-a-virtual-environment),\n e inicie o servidor do MLflow:\n\n```bash\nmlflow server --backend-store-uri sqlite:///teste_mlflow.db --host 0.0.0.0 -p 5000 --default-artifact-root mlruns\n```\n\n- Obtenha o caminho completo da pasta '**mlruns**' (ela \u00e9 criada dentro da pasta onde o script para gera\u00e7\u00e3o dos\n experimentos/modelo foi executado);\n\n- Se for testar o _worker_ pub, entre na pasta '**worker_pub**' e execute o comando abaixo. Lembre-se de informar o\n caminho completo da pasta '**mlruns**' atrav\u00e9s do par\u00e2metro '**--mlruns_path**';\n\n```bash\npython test_pub.py --mlruns_path=\"caminho completo para a pasta mlruns\"\n```\n\n- Se for testar o _worker_ retrain, entre na pasta '**worker_retrain**' e execute o comando abaixo. Lembre-se de\n informar o caminho completo da pasta '**mlruns**' atrav\u00e9s do par\u00e2metro '**--mlruns_path**';\n\n```bash\npython test_retrain.py --mlruns_path=\"caminho completo para a pasta mlruns\"\n```\n\nLeia atentamente as mensagens e caso exista alguma inconsist\u00eancia no teste, atenda ao que for solicitado pelo script.\n\n## 4. Disponibilize o c\u00f3digo para publica\u00e7\u00e3o do modelo\n\nAntes de enviar os c\u00f3digos, certifique-se que eles est\u00e3o funcionando de acordo com as regras estabelecidas e que os\narquivos com os _requirements_ foram gerados corretamente. Se ocorrer algum erro que impe\u00e7a a publica\u00e7\u00e3o, entraremos\nem contato para informar o ocorrido e fornecer as informa\u00e7\u00f5es sobre o erro.\n\n**DICA:** **N\u00e3o** \u00e9 obrigat\u00f3rio, por\u00e9m se voc\u00ea quiser testar o modelo implementado, antes de disponibiliz\u00e1-lo para\npublica\u00e7\u00e3o; clone o reposit\u00f3rio da [Stack de ML do Prodest](https://github.com/prodest/prodest-ml-stack)\n(vers\u00e3o standalone) e siga as instru\u00e7\u00f5es para fazer o _deploy_ da Stack e o teste do seu modelo utilizando ela.\n\nPara disponibilizar o modelo para publica\u00e7\u00e3o:\n\n- Crie uma pasta chamada '**publicar**';\n- Copie as pastas '**worker_pub**', '**worker_retrain**' e '**training_model**' para a pasta '**publicar**'\n (**n\u00e3o** incluir a pasta\n '**env**', que \u00e9 do ambiente virtual Python, nem a pasta '**temp_area**', que \u00e9 utilizada para guardar arquivos\n tempor\u00e1rios) ;\n- Compacte a pasta '**publicar**' utilizando o formato '.zip';\n- Envie o arquivo '**publicar.zip**' para o Prodest, conforme alinhamento pr\u00e9vio realizado em reuni\u00e3o ou qualquer\n outro meio de contato.\n",
"bugtrack_url": null,
"license": null,
"summary": "Biblioteca de Machine Learning (ML) do Prodest.",
"version": "1.8.9",
"project_urls": {
"Bug Tracker": "https://github.com/prodest/mllibprodest/issues",
"Documentation": "https://prodest.github.io/mllibprodest",
"Homepage": "https://github.com/prodest/mllibprodest"
},
"split_keywords": [
"prodest",
" ml",
" lib",
" stack"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "1c8a47d4f07d04152700fd367b6078ae9b7967d06974726a4882331bdc18c75d",
"md5": "dd7b9855e9ff9ca8db1c3f6f5705a5ed",
"sha256": "8d12c42b0dea7a64909b9b69a504027c8559840140b88f0546bf24924de4b8e4"
},
"downloads": -1,
"filename": "mllibprodest-1.8.9-py3-none-any.whl",
"has_sig": false,
"md5_digest": "dd7b9855e9ff9ca8db1c3f6f5705a5ed",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.11",
"size": 44485,
"upload_time": "2025-07-11T23:39:30",
"upload_time_iso_8601": "2025-07-11T23:39:30.775381Z",
"url": "https://files.pythonhosted.org/packages/1c/8a/47d4f07d04152700fd367b6078ae9b7967d06974726a4882331bdc18c75d/mllibprodest-1.8.9-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "a8d68a993e38d2828c7ca11b97689f508a74393a235d58edf36af90abcdb934a",
"md5": "e6b82d70f9f54fbea8a8602dca61221d",
"sha256": "08602d0919d591cbb8793b6dc9ec5ba50e1f262ddd5b42d07108a4b932e2ca55"
},
"downloads": -1,
"filename": "mllibprodest-1.8.9.tar.gz",
"has_sig": false,
"md5_digest": "e6b82d70f9f54fbea8a8602dca61221d",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.11",
"size": 46793,
"upload_time": "2025-07-11T23:39:32",
"upload_time_iso_8601": "2025-07-11T23:39:32.435094Z",
"url": "https://files.pythonhosted.org/packages/a8/d6/8a993e38d2828c7ca11b97689f508a74393a235d58edf36af90abcdb934a/mllibprodest-1.8.9.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-07-11 23:39:32",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "prodest",
"github_project": "mllibprodest",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "mllibprodest"
}

")