| Name | mlpr JSON |
| Version |
0.1.19
 JSON
JSON |
| download |
| home_page | None |
| Summary | A library for machine learning pipeline and creation of reports. |
| upload_time | 2024-05-14 14:28:08 |
| maintainer | Manuel Ferreira Junior |
| docs_url | None |
| author | Manuel Ferreira Junior |
| requires_python | >=3.9 |
| license | None |
| keywords |
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# MLPR Library
<a href="https://www.buymeacoffee.com/manuelfjr" target="_blank"><img src="https://img.shields.io/badge/Buy_Me_A_Coffee-5F7FFF?style=for-the-badge&logo=buy-me-a-coffee&logoColor=black" target="_blank"></a>
<table>
<tr>
<th>Packages status</th>
<th>Downloads</th>
<th>Updates</th>
<th>Author</th>
</tr>
<tr>
<td>
<a href="https://pypi.org/project/mlpr/"><img src="https://img.shields.io/pypi/v/mlpr?color=blue" alt="PyPI version"></a>
<a href="https://pypi.org/project/mlpr/"><img src="https://img.shields.io/pypi/l/mlpr?color=blue" alt="License"></a>
<a href="https://pypi.org/project/mlpr/"><img src="https://img.shields.io/pypi/pyversions/mlpr" alt="PyPI - Python Version"></a>
<a href="https://pypi.org/project/mlpr/"><img src="https://img.shields.io/pypi/wheel/mlpr" alt="PyPI - Wheel"></a>
<a href="https://pypi.org/project/mlpr/"><img src="https://img.shields.io/pypi/status/mlpr" alt="PyPI - Status"></a>
</td>
<td>
<a href="https://pypi.org/project/mlpr/"><img src="https://img.shields.io/pypi/dm/mlpr?style=flat-square&color=darkgreen" alt="PyPI - Downloads"></a>
<a href="https://pypi.org/project/mlpr/"><img src="https://img.shields.io/pypi/dw/mlpr?style=flat-square&color=darkgreen" alt="PyPI - Downloads"></a>
<a href="https://pypi.org/project/mlpr/"><img src="https://img.shields.io/pypi/dd/mlpr?style=flat-square&color=darkgreen" alt="PyPI - Downloads"></a>
</td>
<td>
<a href="https://github.com/Manuelfjr/mlpr/commits"><img src="https://img.shields.io/github/last-commit/Manuelfjr/mlpr" alt="Last Commit"></a>
<a href="https://github.com/Manuelfjr/mlpr/issues"><img src="https://img.shields.io/github/issues-raw/Manuelfjr/mlpr" alt="Open Issues"></a>
<a href="https://github.com/Manuelfjr/mlpr/issues?q=is%3Aissue+is%3Aclosed"><img src="https://img.shields.io/github/issues-closed-raw/Manuelfjr/mlpr" alt="Closed Issues"></a>
<a href="https://github.com/Manuelfjr/mlpr/graphs/contributors"><img src="https://img.shields.io/github/contributors/Manuelfjr/mlpr" alt="Contributors"></a>
<a href="https://github.com/Manuelfjr/mlpr"><img src="https://img.shields.io/badge/docs-mlpr-blue?&logo" alt="Docs"></a>
</td>
<td>
<a href="https://github.com/Manuelfjr"><img src="https://img.shields.io/badge/author-manuelfjr-blue?&logo=github" alt="Author"></a>
<a href="https://github.com/Manuelfjr/mlpr/issues?q=is%3Aopen+is%3Aissue"><img src="https://badgen.net/github/open-issues/manuelfjr/mlpr" alt="Open Issues"></a>
<a href="https://github.com/Manuelfjr/mlpr/issues?q=is%3Aissue+is%3Aclosed"><img src="https://badgen.net/github/closed-issues/manuelfjr/mlpr" alt="Closed Issues"></a>
</td>
</tr>
</table>
<!-- [](https://pypi.org/project/mlpr/)
[](https://pypi.org/project/mlpr/)
[](https://pypi.org/project/mlpr/)
[](https://pypi.org/project/mlpr/)
[](https://pypi.org/project/mlpr/)
[](https://pypi.org/project/mlpr/)
[](https://pypi.org/project/mlpr/)
[](https://pypi.org/project/mlpr/)
[](https://github.com/Manuelfjr/mlpr/commits)
[](https://github.com/Manuelfjr/mlpr/issues)
[](https://github.com/Manuelfjr/mlpr/issues?q=is%3Aissue+is%3Aclosed)
[](https://github.com/Manuelfjr/mlpr/graphs/contributors)
[](https://github.com/Manuelfjr/birt-gd)
[](https://github.com/Manuelfjr)
[](https://github.com/Manuelfjr/mlpr/issues?q=is%3Aopen+is%3Aissue)
[](https://github.com/Manuelfjr/mlpr/issues?q=is%3Aissue+is%3Aclosed) -->
[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/regression_plots.png)
> :arrow_forward: **For use examples, click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks).**
This repository is a developing library named `MLPR` (Machine Learning Pipeline Report). It aims to facilitate the creation of machine learning models in various areas such as regression, forecasting, classification, and clustering. The library allows the user to perform tuning of these models, generate various types of plots for post-modeling analysis, and calculate various metrics.
In addition, `MLPR` allows the creation of metric reports using [`Jinja2`](https://pypi.org/project/Jinja2/), including the obtained graphs. The user can customize the report template according to their needs.
# Using the MLPR Library
The MLPR library is a powerful tool for machine learning and data analysis. Here's a brief guide on how to use it.
## Installation
Before you start, make sure you have installed the MLPR library. You can do this by running pip install mlpr.
```bash
pip install mlpr
```
<!-- # Regression
The example of how to use the module `mlpr.ml.regression` can be view in [`notebooks/regression/`](/notebooks/regression/) -->
# Table of contents
The library current support some features for Machine Learning, being:
**1. Regression**: Support for model selection using a Grid of params to model selection, calculating metrics and generating plots. This module support `spark` dataframe. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/regression/) for examples.
**2. Classification Metrics**: Support for classification metrics and give for the user the possibility to create your own metric. This module spport `spark` dataframe. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/classification/02.ml_metrics.ipynb) for examples.
**3. Tunning**: Support for supervisioned models tunning. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/tunning/) for examples.
**4. Classification uncertainty**: Support for uncertainty methods estimation. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/classification/01.ml_classification_examples.ipynb) for examples.
**5. Surrogates**: Support for training surrogates models, using a white box or less complex that can reproduce the black box behavior or a complex model. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/classification/03.ml_surrogates.ipynb) for examples.
**6. Tunning (Support for spark)**: Grid search and model selection using Spark framework for Python (`pyspark`).
# Tunning
Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/tunning/) for contents.
MLPR used for model selection.
## Importing the Library
First, import the necessary modules from the library:
```python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.base import BaseEstimator
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_blobs
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, cohen_kappa_score
from mlpr.ml.supervisioned.tunning.grid_search import GridSearch
from utils.reader import read_file_yaml
```
## Methods
Here we have a custom method for accuracy to use in model selection. Thus:
```python
def custom_accuracy_score(y_true: np.ndarray, y_pred: np.ndarray) -> float:
return accuracy_score(y_true, y_pred, normalize=False)
```
## Set parameters
```python
n_samples = 1000
centers = [(0, 0), (3, 4.5)]
n_features = 2
cluster_std = 1.3
random_state = 42
cv = 5
```
```python
np.random.seed(random_state)
```
```python
params_split: dict[str, float | int] = {
'test_size': 0.25,
'random_state': random_state
}
params_norm: dict[str, bool] = {'with_mean': True, 'with_std': True}
model_metrics: dict[str, Any] = {
'custom_accuracy': custom_accuracy_score,
'accuracy': accuracy_score,
'precision': precision_score,
'recall': recall_score,
'kappa': cohen_kappa_score,
'f1': f1_score,
}
```
## Loading the Data
Load your dataset. In this example, we're generating a dataset for classification using sklearn:
```python
X, y = make_blobs(
n_samples=n_samples,
centers=centers,
n_features=n_features,
cluster_std=cluster_std,
random_state=random_state
)
```
## Plot the dataset
```python
fig, ax = plt.subplots(1, 1, figsize=(14, 6))
ax.plot(X[:, 0][y == 0], X[:, 1][y == 0], "bs")
ax.plot(X[:, 0][y == 1], X[:, 1][y == 1], "g^")
ax.set_title("Dataset")
ax.set_frame_on(False)
ax.set_xticks([])
ax.set_yticks([])
fig.tight_layout()
```
[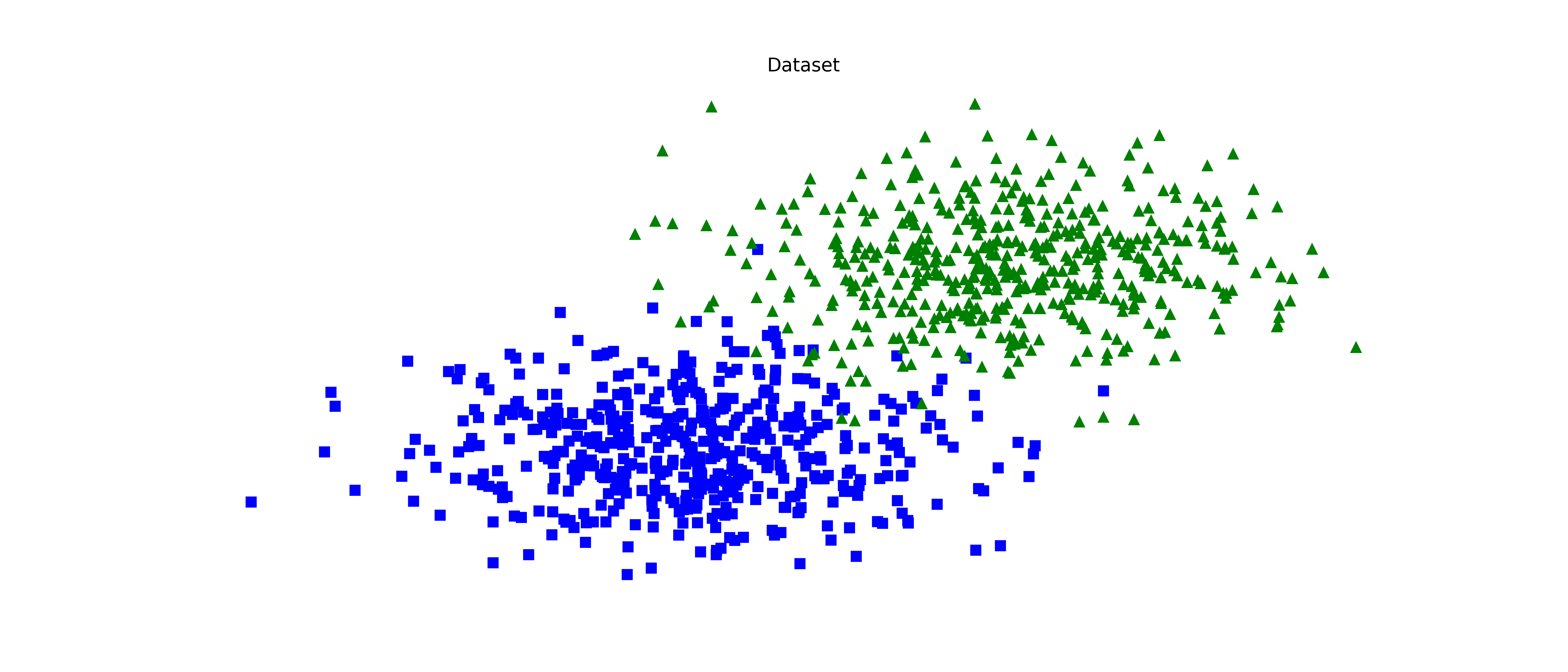](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/tunning_scatter.png)
## Cross-validtion
```python
models: dict[BaseEstimator, dict] = {
RandomForestClassifier: {
'n_estimators': [10, 50, 100, 200],
'max_depth': [None, 5, 10, 15],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'random_state': [random_state]
},
GradientBoostingClassifier: {
'n_estimators': [50, 100, 200],
'learning_rate': [0.1, 0.05, 0.01, 0.005],
'subsample': [0.5, 0.8, 1.0],
'random_state': [random_state]
},
LogisticRegression: {
'C': [0.01, 0.1, 1.0, 10.0],
'penalty': ['l1', 'l2'],
'solver': ['liblinear', 'saga'],
'random_state': [random_state]
},
GaussianNB: {
'var_smoothing': [1e-9, 1e-8, 1e-7, 1e-6, 1e-5]
},
KNeighborsClassifier: {
'n_neighbors': [3, 5, 7, 9],
'weights': ['uniform', 'distance'],
'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute']
},
SVC: {
'C': [0.01, 0.1, 1.0, 10.0],
'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],
'degree': [2, 3, 4],
'gamma': ['scale', 'auto'],
'random_state': [random_state]
},
DecisionTreeClassifier: {
'criterion': ['gini', 'entropy'],
'splitter': ['best', 'random'],
'max_depth': [None, 5, 10, 15],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'random_state': [random_state]
}
}
```
```python
grid_search = GridSearch(
X,
y,
params_split=params_split,
models_params=models,
normalize=True,
params_norm=params_norm,
scoring='accuracy',
metrics=model_metrics
)
grid_search.search(cv=cv, n_jobs=-1)
best_model, best_params = \
grid_search \
.get_best_model()
```
```python
results: pd.DataFrame = pd.DataFrame(grid_search._metrics).T
results
```
<table>
<tr>
<th></th>
<th>custom_accuracy</th>
<th>accuracy</th>
<th>precision</th>
<th>recall</th>
<th>kappa</th>
<th>f1</th>
</tr>
<tr>
<td>RandomForestClassifier</td>
<td>246.0</td>
<td>0.984</td>
<td>0.983607</td>
<td>0.983607</td>
<td>0.967982</td>
<td>0.983607</td>
</tr>
<tr>
<td>GradientBoostingClassifier</td>
<td>244.0</td>
<td>0.976</td>
<td>0.975410</td>
<td>0.975410</td>
<td>0.951972</td>
<td>0.975410</td>
</tr>
<tr>
<td>LogisticRegression</td>
<td>245.0</td>
<td>0.980</td>
<td>0.983471</td>
<td>0.975410</td>
<td>0.959969</td>
<td>0.979424</td>
</tr>
<tr>
<td>GaussianNB</td>
<td>244.0</td>
<td>0.976</td>
<td>0.975410</td>
<td>0.975410</td>
<td>0.951972</td>
<td>0.975410</td>
</tr>
<tr>
<td>KNeighborsClassifier</td>
<td>245.0</td>
<td>0.980</td>
<td>0.983471</td>
<td>0.975410</td>
<td>0.959969</td>
<td>0.979424</td>
</tr>
<tr>
<td>SVC</td>
<td>245.0</td>
<td>0.980</td>
<td>0.983471</td>
<td>0.975410</td>
<td>0.959969</td>
<td>0.979424</td>
</tr>
<tr>
<td>DecisionTreeClassifier</td>
<td>242.0</td>
<td>0.968</td>
<td>0.991379</td>
<td>0.942623</td>
<td>0.935889</td>
<td>0.966387</td>
</tr>
</table>
## Best model
Here we can see the distribution for the best classifier.
```python
fig, ax = plt.subplots(1, 2, figsize=(14, 6))
ax[0].plot(X[:, 0][y == 0], X[:, 1][y == 0], "bs")
ax[0].plot(X[:, 0][y == 1], X[:, 1][y == 1], "g^")
ax[0].set_title("Dataset")
ax[0].set_frame_on(False)
ax[0].set_xticks([])
ax[0].set_yticks([])
ax[1].plot(
grid_search.X_test[:, 0][grid_search.y_test == 0],
grid_search.X_test[:, 1][grid_search.y_test == 0],
"bs"
)
ax[1].plot(
grid_search.X_test[:, 0][grid_search.y_test == 1],
grid_search.X_test[:, 1][grid_search.y_test == 1],
"g^"
)
ax[1].set_title(grid_search.best_model.__class__.__name__)
ax[1].set_frame_on(False)
ax[1].set_xticks([])
ax[1].set_yticks([])
fig.tight_layout()
```
[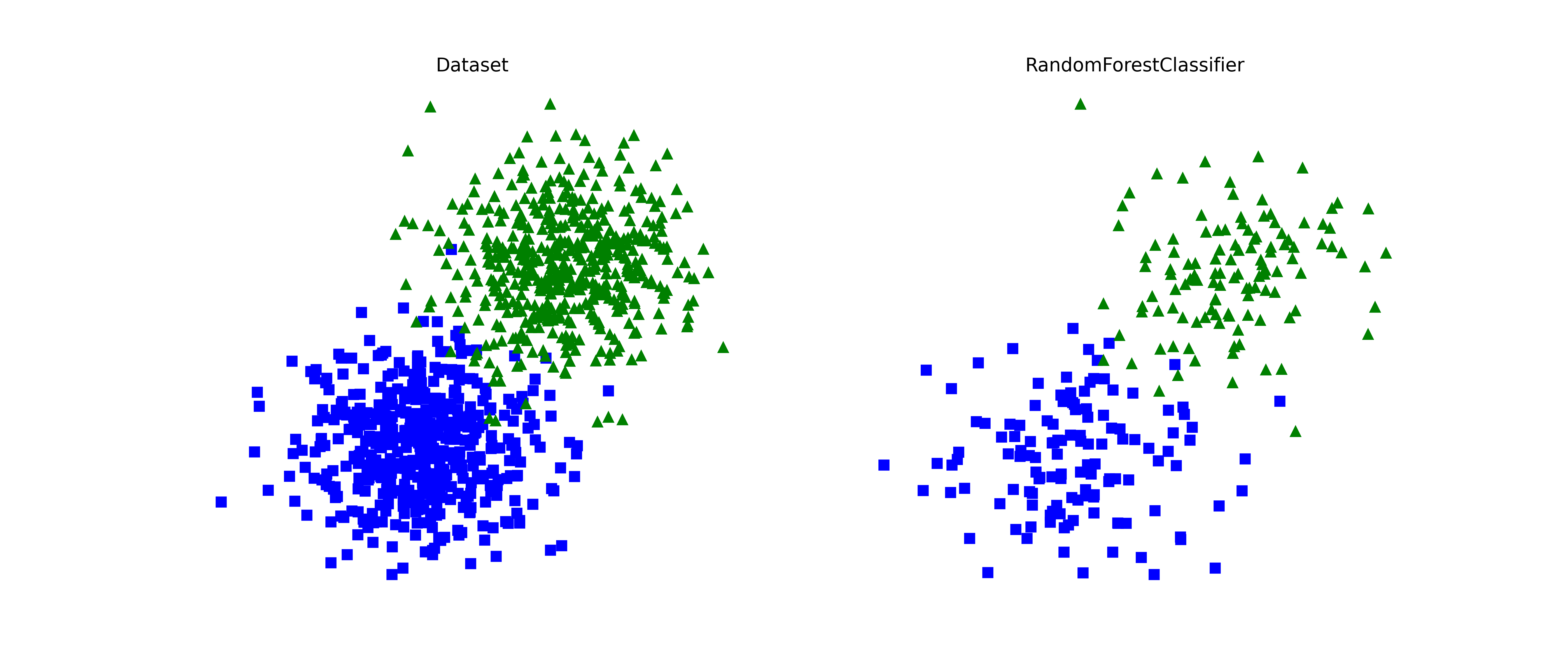](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/tunning_best_model.png)
# Classification: uncertainty estimation
Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/classification/) for contents.
How to use the module for uncertainty estimation in classification tasks.
## Importing the Library
First, import the necessary modules from the library:
```python
from typing import Dict
from functools import partial
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.base import BaseEstimator
from sklearn.datasets import make_blobs
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (accuracy_score, cohen_kappa_score, f1_score,
precision_score, recall_score)
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from mlpr.ml.supervisioned.classification.uncertainty import UncertaintyPlots
from mlpr.ml.supervisioned.classification.utils import calculate_probas
from mlpr.ml.supervisioned.tunning.grid_search import GridSearch
import warnings
warnings.filterwarnings("ignore")
```
## Parameters
Setting parameters for the experiments.
```python
random_state: int = 42
n_feats: int = 2
n_size: int = 1000
centers: list[tuple] = [
(0, 2),
(2, 0),
(5, 4.5)
]
n_class: int = len(centers)
cluster_std: list[float] = [1.4, 1.4, 0.8]
cv: int = 5
np.random.seed(random_state)
```
```python
params: dict[str, dict[str, Any]] = {
"n_samples": n_size,
"n_features": n_feats,
"centers": centers,
"cluster_std": cluster_std,
"random_state": random_state
}
```
```python
np.random.seed(random_state)
```
```python
params_split: dict[str, float | int] = {
'test_size': 0.25,
'random_state': random_state
}
params_norm: dict[str, bool] = {'with_mean': True, 'with_std': True}
model_metrics: dict[str, Any] = {
'custom_accuracy': partial(accuracy_score, normalize=False),
'accuracy': accuracy_score,
'precision': partial(precision_score, average='macro'),
'recall': partial(recall_score, average='macro'),
'kappa': cohen_kappa_score,
'f1': partial(f1_score, average='macro'),
}
```
## Load the dataset
Here we are generating a dataset for experiments, using blobs from scikit-learn.
```python
X, y = make_blobs(
**params
)
```
## Plot the dataset
Behavior of the dataset used in the experiment.
```python
markers = ['o', 'v', '^']
fig, ax = plt.subplots(1, 1, figsize=(14, 6))
colors = generate_colors("FF4B3E", "1C2127", len(np.unique(y)))
for i, k in enumerate(np.unique(y)):
ax.scatter(X[:, 0][y == k], X[:, 1][y == k], marker=markers[i % len(markers)], color=colors[i], label=f"c{i}")
ax.set_title("Dataset")
ax.set_frame_on(False)
ax.set_xticks([])
ax.set_yticks([])
for i, (center, color) in enumerate(zip(centers, colors)):
ax.scatter(
center[0],
center[1],
color="white",
linewidths=3,
marker="o",
edgecolor="black",
s=120,
label="center" if i == 0 else None
)
plt.legend()
fig.tight_layout()
```
[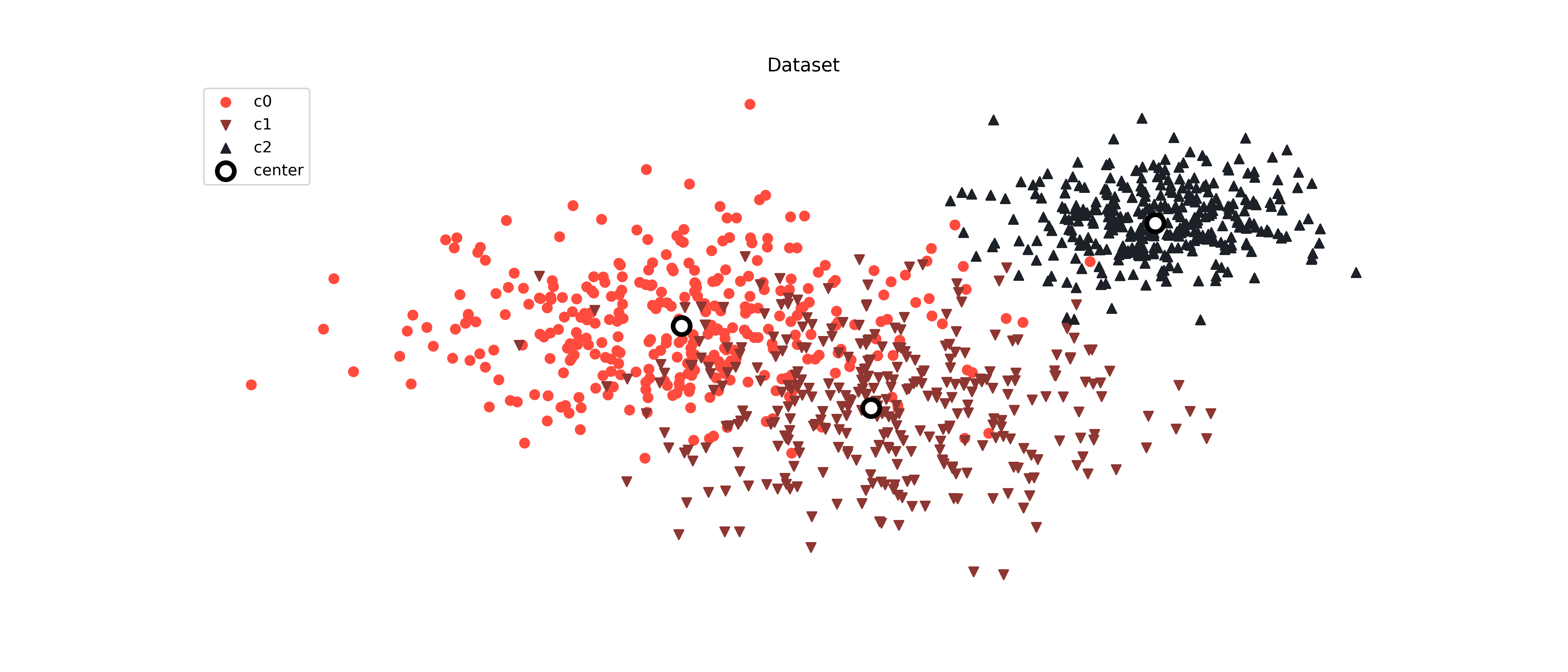](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/classification_scatter.png)
## Cross-validation
```python
models: dict[BaseEstimator, dict] = {
RandomForestClassifier: {
'n_estimators': [10, 50, 100, 200],
'max_depth': [None, 5, 10, 15],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'random_state': [random_state]
},
GradientBoostingClassifier: {
'n_estimators': [50, 100, 200],
'learning_rate': [0.1, 0.05, 0.01, 0.005],
'subsample': [0.5, 0.8, 1.0],
'random_state': [random_state]
},
LogisticRegression: {
'C': [0.01, 0.1, 1.0, 10.0],
'penalty': ['l1', 'l2'],
'solver': ['liblinear', 'saga'],
'random_state': [random_state],
'max_iter': [10000]
},
GaussianNB: {
'var_smoothing': [1e-9, 1e-8, 1e-7, 1e-6, 1e-5]
},
SVC: {
'C': [0.01, 0.1, 1.0, 10.0],
'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],
'degree': [2, 3, 4],
'gamma': ['scale', 'auto'],
'probability': [True],
'random_state': [random_state]
},
DecisionTreeClassifier: {
'criterion': ['gini', 'entropy'],
'splitter': ['best', 'random'],
'max_depth': [None, 5, 10, 15],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'random_state': [random_state]
}
}
```
```python
grid_search = GridSearch(
X,
y,
params_split=params_split,
models_params=models,
normalize=True,
params_norm=params_norm,
scoring='accuracy',
metrics=model_metrics
)
grid_search.search(cv=cv, n_jobs=-1)
best_model, best_params = \
grid_search \
.get_best_model()
```
```python
results: pd.DataFrame = pd.DataFrame(grid_search._metrics).T
results
```
<table>
<thead>
<tr>
<th></th>
<th>custom_accuracy</th>
<th>accuracy</th>
<th>precision</th>
<th>recall</th>
<th>kappa</th>
<th>f1</th>
</tr>
</thead>
<tbody>
<tr>
<td>RandomForestClassifier</td>
<td>222.0</td>
<td>0.888</td>
<td>0.883566</td>
<td>0.885902</td>
<td>0.831666</td>
<td>0.882724</td>
</tr>
<tr>
<td>GradientBoostingClassifier</td>
<td>221.0</td>
<td>0.884</td>
<td>0.878830</td>
<td>0.881207</td>
<td>0.825583</td>
<td>0.878421</td>
</tr>
<tr>
<td>LogisticRegression</td>
<td>230.0</td>
<td>0.920</td>
<td>0.915170</td>
<td>0.916987</td>
<td>0.879457</td>
<td>0.915662</td>
</tr>
<tr>
<td>GaussianNB</td>
<td>231.0</td>
<td>0.924</td>
<td>0.919375</td>
<td>0.921682</td>
<td>0.885539</td>
<td>0.920046</td>
</tr>
<tr>
<td>SVC</td>
<td>230.0</td>
<td>0.920</td>
<td>0.915170</td>
<td>0.916987</td>
<td>0.879457</td>
<td>0.915662</td>
</tr>
<tr>
<td>DecisionTreeClassifier</td>
<td>214.0</td>
<td>0.856</td>
<td>0.848155</td>
<td>0.845622</td>
<td>0.782325</td>
<td>0.846414</td>
</tr>
</tbody>
</table>
## Probabilities
Getting probabilities for uncertainty generation.
```python
probas = calculate_probas(grid_search.fitted, grid_search.X_train)
```
## Plot best model result
Plotting the result for best model.
```python
up = UncertaintyPlots()
```
```python
fig_un, ax_un = up.uncertainty(
model_names=[[best_model.__class__.__name__]],
probs={best_model.__class__.__name__: probas[best_model.__class__.__name__]},
X=grid_search.X_train,
figsize=(20, 6),
cmap='RdYlGn',
show_inline=True,
box_on=False
)
```
[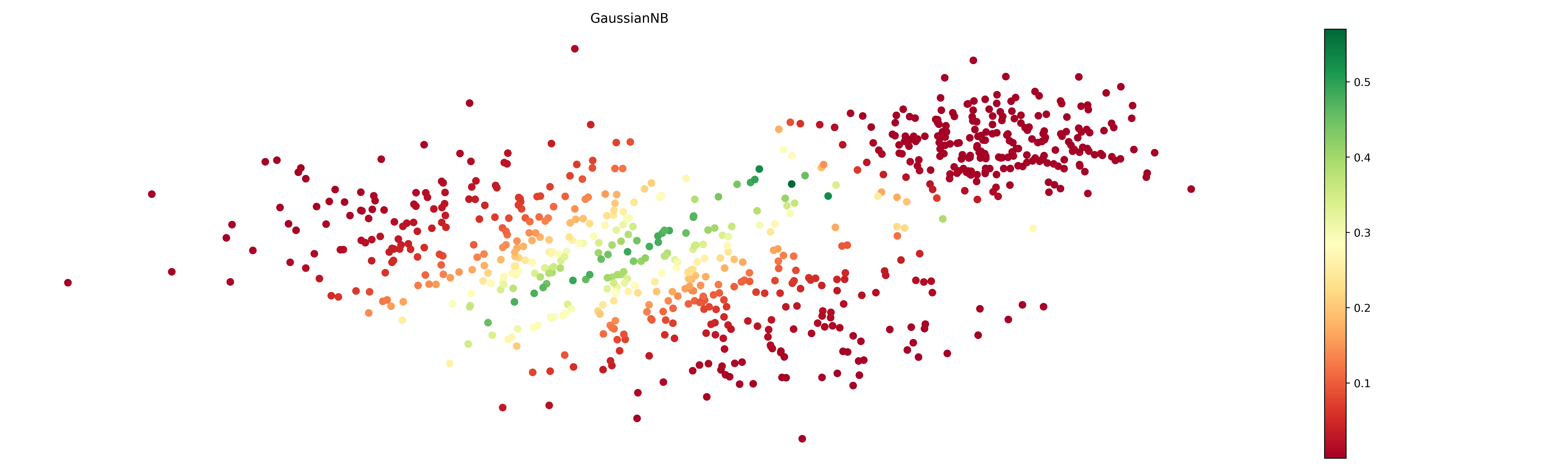](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/classification_uncertain_best.png)
## Plot overall of uncertainty
Plotting an overall of uncertainty estimated for the models.
```python
sorted_models = results.sort_values("accuracy", ascending=False).index.tolist()
pyramid = []
i = 0
for row in range(1, len(sorted_models)):
if i + row <= len(sorted_models):
pyramid.append(sorted_models[i:i+row])
i += row
else:
break
if i < len(sorted_models):
pyramid.append(sorted_models[i:])
if len(pyramid[-1]) < len(pyramid[-2]):
pyramid[-2].extend(pyramid[-1])
pyramid = pyramid[:-1]
```
```python
up = UncertaintyPlots()
```
```python
fig_un, ax_un = up.uncertainty(
model_names=pyramid,
probs=probas,
X=grid_search.X_train,
figsize=(20, 10),
show_inline=True,
cmap='RdYlGn',
box_on=False
)
```
[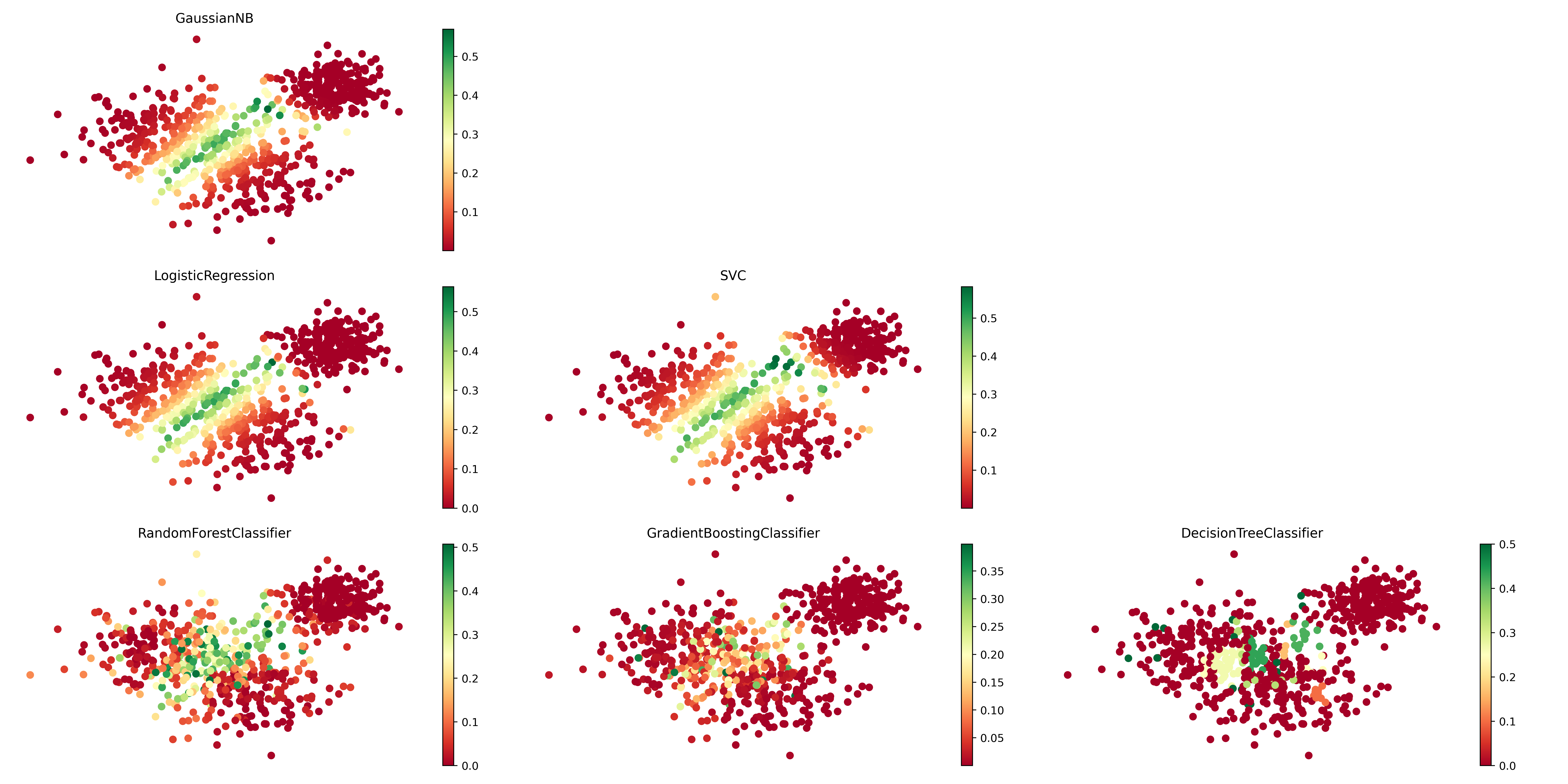](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/classification_uncertain_pyramid.png)
## Aleatory uncertainty and Epistemic uncertainty
```python
data_probas = pd.DataFrame(probas)
random: pd.Series = data_probas.mean(axis=1)
epistemic: pd.Series = data_probas.var(axis=1)
```
```python
up = UncertaintyPlots()
```
```python
fig_both, ax_both = up.uncertainty(
model_names=[["Random uncertainty", "Epistemic uncertainty"]],
probs={
"Random uncertainty": random,
"Epistemic uncertainty": epistemic
},
X=grid_search.X_train,
figsize=(20, 6),
cmap='RdYlGn',
show_inline=True,
box_on=False
)
```
[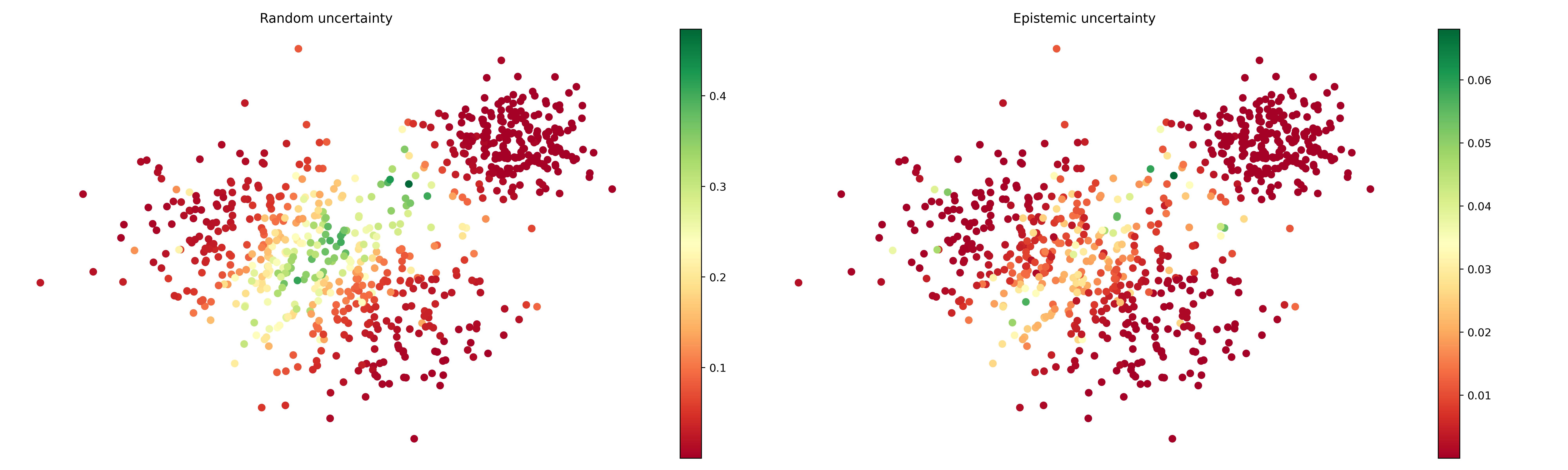](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/classification_uncertain_aleatory_epistemic.png)
# Regression
Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/regression/) for contents.
How to use the module for regression problems.
## Importing the Library
First, import the necessary modules from the library:
```python
from mlpr.ml.supervisioned.regression import metrics, plots
from mlpr.ml.supervisioned.tunning.grid_search import GridSearch
from mlpr.reports.create import ReportGenerator
```
## Loading the Data
Load your dataset. In this example, we're generating a dataset for regression using sklearn:
```python
n_feats = 11
n_instances = 1000
n_invert = 50
n_noise = 20
cv = 10
```
```python
X, y = make_regression(n_samples=n_instances, n_features=n_feats, noise=n_noise)
# introduce of noises
indices = np.random.choice(y.shape[0], size=n_invert, replace=False)
y[indices] = np.max(y) - y[indices]
data = pd.DataFrame(data=X, columns=[f'feature_{i}' for i in range(1, n_feats + 1)])
data['target'] = y
```
## Set the seed
Set the random seed for reproducibility
```python
n_seed = 42
np.random.seed(n_seed)
```
## Preparing the Data
Split your data into features ($X$) and target ($y$):
```python
X = data.drop("target", axis=1)
y = data["target"].values
```
## Model Training
Define the parameters for your models and use `GridSearch` to find the best model:
```python
models_params = {
Ridge: {
'alpha': [1.0, 10.0, 15., 20.],
'random_state': [n_seed]
},
Lasso: {
'alpha': [0.1, 1.0, 10.0],
'random_state': [n_seed]
},
SVR: {
'C': [0.1, 1.0, 10.0],
'kernel': ['linear', 'rbf']
},
RandomForestRegressor: {
'n_estimators': [10, 50, 100],
'max_depth': [None, 5, 10],
'random_state': [n_seed]
},
GradientBoostingRegressor: {
'n_estimators': [100, 200],
'learning_rate': [0.1, 0.05, 0.01],
'random_state': [n_seed]
},
XGBRegressor: {
'n_estimators': [100, 200],
'learning_rate': [0.1, 0.05, 0.01],
'random_state': [n_seed]
}
}
params_split: dict[str, float | int] = {
'test_size': 0.25,
'random_state': n_seed
}
params_norm: dict[str, bool] = {'with_mean': True, 'with_std': True}
grid_search = GridSearch(
X,
y,
params_split=params_split,
models_params=models_params,
normalize=True,
scoring='neg_mean_squared_error',
metrics={'neg_mean_squared_error': rmse},
params_norm=params_norm
)
grid_search.search(cv=5, n_jobs=-1)
best_model, best_params = \
grid_search \
.get_best_model()
```
## Making Predictions
Use the best model to make predictions:
```python
data_train = pd.DataFrame(
grid_search.X_train,
columns=X.columns
)
data_train["y_true"] = grid_search.y_train
data_train["y_pred"] = grid_search.best_model.predict(grid_search.X_train)
```
## Evaluating the Model
Calculate various metrics to evaluate the performance of the model:
```python
k = 3
```
```python
rm = metrics.RegressionMetrics(
data_train,
*["y_true", "y_pred"]
)
results = rm.calculate_metrics(
["mape", "rmse", "kolmogorov_smirnov", "confusion_matrix", "calculate_kappa"],
{
"mape": {},
"rmse": {},
"kolmogorov_smirnov": {},
"confusion_matrix": {"n_bins": k},
"calculate_kappa": {"n_bins": k}
}
)
```
## Results
The output it's a dictionary object with the calculated metrics, like this:
```
{'mape': 39.594540526956436,
'rmse': 54.09419440169204,
'kolmogorov_smirnov': (0.1510574018126888, 0.0010310446878578096),
'confusion_matrix': (array([[54, 57, 2, 0],
[16, 70, 21, 0],
[ 0, 37, 37, 3],
[ 0, 6, 25, 3]]),
{'precision': array([0.77142857, 0.41176471, 0.43529412, 0.5 ]),
'recall': array([0.47787611, 0.65420561, 0.48051948, 0.08823529]),
'f1_score': array([0.59016393, 0.50541516, 0.45679012, 0.15 ]),
'support': array([113, 107, 77, 34]),
'accuracy': 0.4954682779456193}),
'calculate_kappa': {0: {'confusion_matrix': array([[202, 16],
[ 59, 54]]),
'kappa_score': 0.4452885840055415,
'metrics': {'precision': array([0.77394636, 0.77142857]),
'recall': array([0.9266055 , 0.47787611]),
'f1_score': array([0.8434238 , 0.59016393]),
'support': array([218, 113]),
'accuracy': 0.7734138972809668}},
1: {'confusion_matrix': array([[124, 100],
[ 37, 70]]),
'kappa_score': 0.180085703437178,
'metrics': {'precision': array([0.77018634, 0.41176471]),
'recall': array([0.55357143, 0.65420561]),
'f1_score': array([0.64415584, 0.50541516]),
'support': array([224, 107]),
'accuracy': 0.5861027190332326}},
2: {'confusion_matrix': array([[206, 48],
[ 40, 37]]),
'kappa_score': 0.2813579394059016,
'metrics': {'precision': array([0.83739837, 0.43529412]),
'recall': array([0.81102362, 0.48051948]),
'f1_score': array([0.824 , 0.45679012]),
'support': array([254, 77]),
'accuracy': 0.7341389728096677}},
3: {'confusion_matrix': array([[294, 3],
[ 31, 3]]),
'kappa_score': 0.12297381546134645,
'metrics': {'precision': array([0.90461538, 0.5 ]),
'recall': array([0.98989899, 0.08823529]),
'f1_score': array([0.94533762, 0.15 ]),
'support': array([297, 34]),
'accuracy': 0.8972809667673716}}}}
```
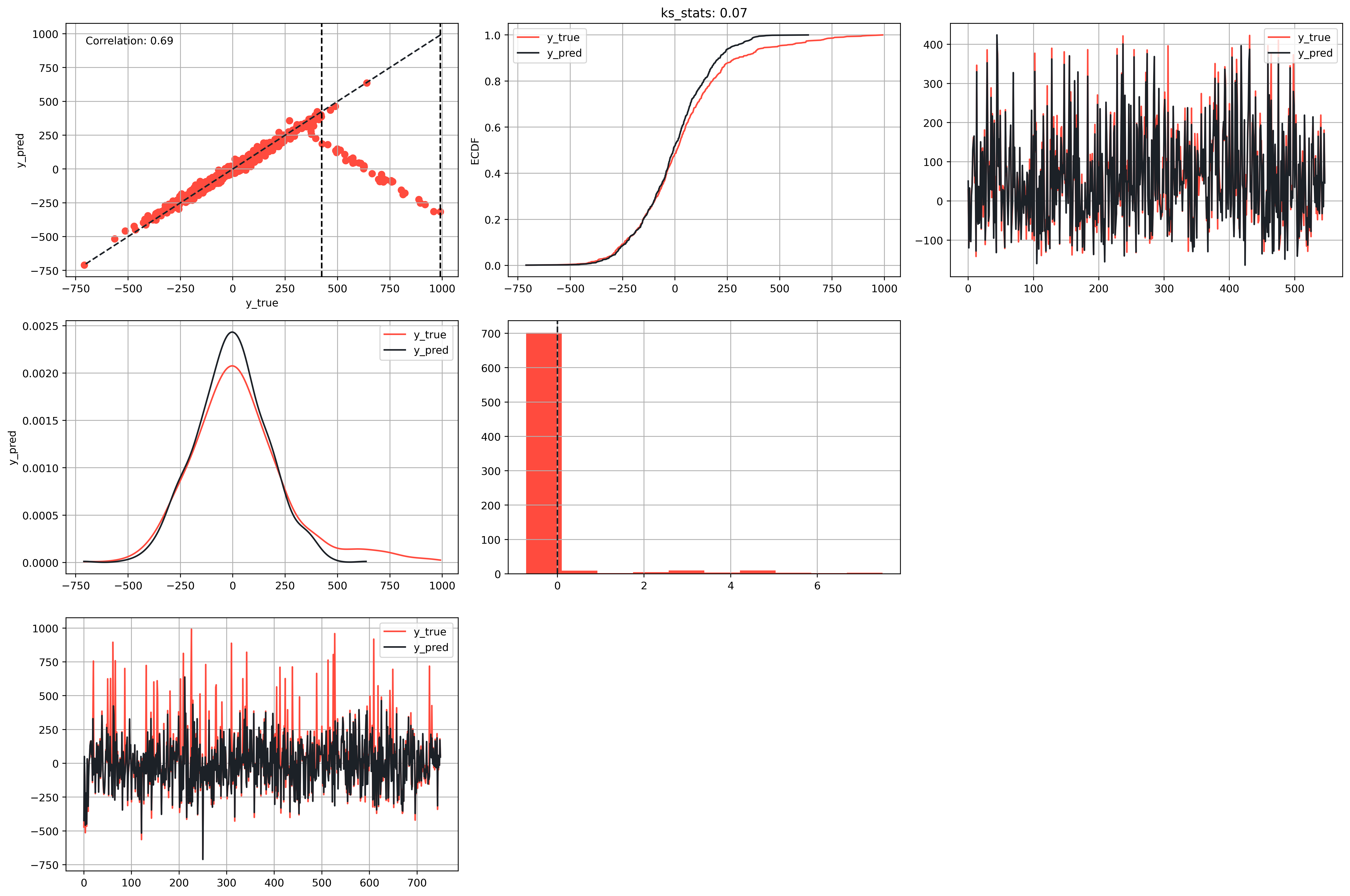
## Visualizing the Results
Plot the results using the `RegressionPlots` module:
```python
rp = \
plots \
.RegressionPlots(
data_train,
color_palette=["#FF4B3E", "#1C2127"]
)
```
```py
fig, axs = rp.grid_plot(
plot_functions=[
['graph11', 'graph12', 'graph13'],
['graph21', 'graph22'],
['graph23']
],
plot_args={
'graph11': {
"plot": "scatter",
"params": {
'y_true_col': 'y_true',
'y_pred_col': 'y_pred',
'linecolor': '#1C2127',
'worst_interval': True,
'metrics': rm.metrics["calculate_kappa"],
'class_interval': rm._class_intervals,
'method': 'recall',
'positive': True
}
},
'graph12': {
"plot": "plot_ecdf",
"params": {
'y_true_col': 'y_true',
'y_pred_col': 'y_pred'
}
},
'graph21': {
"plot": "plot_kde",
"params": {
'columns': ['y_true', 'y_pred']
}
},
'graph22': {
"plot": "plot_error_hist",
"params": {
'y_true_col': 'y_true',
'y_pred_col': 'y_pred',
'linecolor': '#1C2127'
}
},
'graph13': {
"plot": "plot_fitted",
"params": {
'y_true_col': 'y_true',
'y_pred_col': 'y_pred',
'condition': (
(
rm._worst_interval_kappa[0] <= data_train["y_true"]
) & (
data_train["y_true"] <= rm._worst_interval_kappa[1]
)
),
'sample_size': None
}
},
'graph23': {
"plot": "plot_fitted",
"params": {
'y_true_col': 'y_true',
'y_pred_col': 'y_pred',
'condition': None,
'sample_size': None
}
},
},
show_inline=True
)
```
[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/regression_plots.png)
## Reports
Here you can see the <a href="https://raw.githack.com/Manuelfjr/mlpr/develop/data/05_reports/report_model.html">report</a> output.
# Contact
Here you can find my contact information:
<div align="center">
<a href="https://github.com/Manuelfjr/mlpr">
<img src="https://avatars.githubusercontent.com/u/53409857?v=4" alt="Profile Image" width="200" height="200" style="border-radius: 50%;">
</a>
</div>
<br>
<div align="center">
<a href="https://manuelfjr.github.io"><img src="https://img.icons8.com/ios/30/000000/domain.png"/></a>
<a href="https://github.com/manuelfjr"><img src="https://img.icons8.com/ios/30/000000/github--v1.png"/></a>
<a href="https://www.instagram.com/manuelferreirajr/"><img src="https://img.icons8.com/ios/30/000000/instagram-new--v1.png"/></a>
<a href="https://www.linkedin.com/in/manuefjr/"><img src="https://img.icons8.com/ios/30/000000/linkedin.png"/></a>
<a href="mailto:ferreira.jr.ufpb@gmail.com"><img src="https://img.icons8.com/ios/30/000000/email.png"/></a>
</div>
# License
This project is licensed under the terms of the MIT license. For more details, see the [LICENSE](/LICENSE) file in the project's root directory.
Raw data
{
"_id": null,
"home_page": null,
"name": "mlpr",
"maintainer": "Manuel Ferreira Junior",
"docs_url": null,
"requires_python": ">=3.9",
"maintainer_email": "ferreira.jr.ufpb@gmail.com",
"keywords": null,
"author": "Manuel Ferreira Junior",
"author_email": "ferreira.jr.ufpb@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/58/f4/b05bafcdc7d635ea48b67cc8f239a5a67c17706252e62f50910af51e99b6/mlpr-0.1.19.tar.gz",
"platform": null,
"description": "# MLPR Library\n\n<a href=\"https://www.buymeacoffee.com/manuelfjr\" target=\"_blank\"><img src=\"https://img.shields.io/badge/Buy_Me_A_Coffee-5F7FFF?style=for-the-badge&logo=buy-me-a-coffee&logoColor=black\" target=\"_blank\"></a>\n\n<table>\n <tr>\n <th>Packages status</th>\n <th>Downloads</th>\n <th>Updates</th>\n <th>Author</th>\n </tr>\n <tr>\n <td>\n <a href=\"https://pypi.org/project/mlpr/\"><img src=\"https://img.shields.io/pypi/v/mlpr?color=blue\" alt=\"PyPI version\"></a>\n <a href=\"https://pypi.org/project/mlpr/\"><img src=\"https://img.shields.io/pypi/l/mlpr?color=blue\" alt=\"License\"></a>\n <a href=\"https://pypi.org/project/mlpr/\"><img src=\"https://img.shields.io/pypi/pyversions/mlpr\" alt=\"PyPI - Python Version\"></a>\n <a href=\"https://pypi.org/project/mlpr/\"><img src=\"https://img.shields.io/pypi/wheel/mlpr\" alt=\"PyPI - Wheel\"></a>\n <a href=\"https://pypi.org/project/mlpr/\"><img src=\"https://img.shields.io/pypi/status/mlpr\" alt=\"PyPI - Status\"></a>\n </td>\n <td>\n <a href=\"https://pypi.org/project/mlpr/\"><img src=\"https://img.shields.io/pypi/dm/mlpr?style=flat-square&color=darkgreen\" alt=\"PyPI - Downloads\"></a>\n <a href=\"https://pypi.org/project/mlpr/\"><img src=\"https://img.shields.io/pypi/dw/mlpr?style=flat-square&color=darkgreen\" alt=\"PyPI - Downloads\"></a>\n <a href=\"https://pypi.org/project/mlpr/\"><img src=\"https://img.shields.io/pypi/dd/mlpr?style=flat-square&color=darkgreen\" alt=\"PyPI - Downloads\"></a>\n </td>\n <td>\n <a href=\"https://github.com/Manuelfjr/mlpr/commits\"><img src=\"https://img.shields.io/github/last-commit/Manuelfjr/mlpr\" alt=\"Last Commit\"></a>\n <a href=\"https://github.com/Manuelfjr/mlpr/issues\"><img src=\"https://img.shields.io/github/issues-raw/Manuelfjr/mlpr\" alt=\"Open Issues\"></a>\n <a href=\"https://github.com/Manuelfjr/mlpr/issues?q=is%3Aissue+is%3Aclosed\"><img src=\"https://img.shields.io/github/issues-closed-raw/Manuelfjr/mlpr\" alt=\"Closed Issues\"></a>\n <a href=\"https://github.com/Manuelfjr/mlpr/graphs/contributors\"><img src=\"https://img.shields.io/github/contributors/Manuelfjr/mlpr\" alt=\"Contributors\"></a>\n <a href=\"https://github.com/Manuelfjr/mlpr\"><img src=\"https://img.shields.io/badge/docs-mlpr-blue?&logo\" alt=\"Docs\"></a>\n </td>\n <td>\n <a href=\"https://github.com/Manuelfjr\"><img src=\"https://img.shields.io/badge/author-manuelfjr-blue?&logo=github\" alt=\"Author\"></a>\n <a href=\"https://github.com/Manuelfjr/mlpr/issues?q=is%3Aopen+is%3Aissue\"><img src=\"https://badgen.net/github/open-issues/manuelfjr/mlpr\" alt=\"Open Issues\"></a>\n <a href=\"https://github.com/Manuelfjr/mlpr/issues?q=is%3Aissue+is%3Aclosed\"><img src=\"https://badgen.net/github/closed-issues/manuelfjr/mlpr\" alt=\"Closed Issues\"></a>\n </td>\n </tr>\n</table>\n\n<!-- [](https://pypi.org/project/mlpr/)\n[](https://pypi.org/project/mlpr/)\n[](https://pypi.org/project/mlpr/)\n[](https://pypi.org/project/mlpr/)\n[](https://pypi.org/project/mlpr/)\n\n[](https://pypi.org/project/mlpr/)\n[](https://pypi.org/project/mlpr/)\n[](https://pypi.org/project/mlpr/)\n\n[](https://github.com/Manuelfjr/mlpr/commits)\n[](https://github.com/Manuelfjr/mlpr/issues)\n[](https://github.com/Manuelfjr/mlpr/issues?q=is%3Aissue+is%3Aclosed)\n[](https://github.com/Manuelfjr/mlpr/graphs/contributors)\n[](https://github.com/Manuelfjr/birt-gd)\n\n[](https://github.com/Manuelfjr)\n[](https://github.com/Manuelfjr/mlpr/issues?q=is%3Aopen+is%3Aissue)\n[](https://github.com/Manuelfjr/mlpr/issues?q=is%3Aissue+is%3Aclosed) -->\n\n\n[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/regression_plots.png)\n\n> :arrow_forward: **For use examples, click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks).**\n\n\nThis repository is a developing library named `MLPR` (Machine Learning Pipeline Report). It aims to facilitate the creation of machine learning models in various areas such as regression, forecasting, classification, and clustering. The library allows the user to perform tuning of these models, generate various types of plots for post-modeling analysis, and calculate various metrics.\n\nIn addition, `MLPR` allows the creation of metric reports using [`Jinja2`](https://pypi.org/project/Jinja2/), including the obtained graphs. The user can customize the report template according to their needs.\n\n# Using the MLPR Library\nThe MLPR library is a powerful tool for machine learning and data analysis. Here's a brief guide on how to use it.\n\n## Installation\nBefore you start, make sure you have installed the MLPR library. You can do this by running pip install mlpr.\n\n\n```bash\npip install mlpr\n```\n\n<!-- # Regression\n\nThe example of how to use the module `mlpr.ml.regression` can be view in [`notebooks/regression/`](/notebooks/regression/) -->\n\n\n# Table of contents\n\nThe library current support some features for Machine Learning, being:\n\n**1. Regression**: Support for model selection using a Grid of params to model selection, calculating metrics and generating plots. This module support `spark` dataframe. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/regression/) for examples.\n\n**2. Classification Metrics**: Support for classification metrics and give for the user the possibility to create your own metric. This module spport `spark` dataframe. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/classification/02.ml_metrics.ipynb) for examples.\n\n**3. Tunning**: Support for supervisioned models tunning. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/tunning/) for examples.\n\n\n\n**4. Classification uncertainty**: Support for uncertainty methods estimation. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/classification/01.ml_classification_examples.ipynb) for examples.\n\n\n**5. Surrogates**: Support for training surrogates models, using a white box or less complex that can reproduce the black box behavior or a complex model. Click [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/classification/03.ml_surrogates.ipynb) for examples.\n\n**6. Tunning (Support for spark)**: Grid search and model selection using Spark framework for Python (`pyspark`).\n\n# Tunning\n\nClick [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/tunning/) for contents.\n\nMLPR used for model selection.\n\n## Importing the Library\nFirst, import the necessary modules from the library:\n\n```python\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nfrom sklearn.base import BaseEstimator\nfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.svm import SVC\nfrom sklearn.tree import DecisionTreeClassifier\n\nfrom sklearn.datasets import make_blobs\nfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, cohen_kappa_score\n\n\nfrom mlpr.ml.supervisioned.tunning.grid_search import GridSearch\nfrom utils.reader import read_file_yaml\n```\n\n## Methods\n\nHere we have a custom method for accuracy to use in model selection. Thus:\n\n```python\ndef custom_accuracy_score(y_true: np.ndarray, y_pred: np.ndarray) -> float:\n return accuracy_score(y_true, y_pred, normalize=False)\n```\n\n## Set parameters\n\n```python\nn_samples = 1000\ncenters = [(0, 0), (3, 4.5)]\nn_features = 2\ncluster_std = 1.3\nrandom_state = 42\ncv = 5\n```\n\n```python\nnp.random.seed(random_state)\n```\n\n```python\nparams_split: dict[str, float | int] = {\n 'test_size': 0.25,\n 'random_state': random_state\n}\nparams_norm: dict[str, bool] = {'with_mean': True, 'with_std': True}\nmodel_metrics: dict[str, Any] = {\n 'custom_accuracy': custom_accuracy_score,\n 'accuracy': accuracy_score,\n 'precision': precision_score,\n 'recall': recall_score,\n 'kappa': cohen_kappa_score,\n 'f1': f1_score,\n}\n```\n\n## Loading the Data\nLoad your dataset. In this example, we're generating a dataset for classification using sklearn:\n\n\n```python\nX, y = make_blobs(\n n_samples=n_samples,\n centers=centers,\n n_features=n_features,\n cluster_std=cluster_std,\n random_state=random_state\n)\n```\n\n## Plot the dataset\n\n```python\nfig, ax = plt.subplots(1, 1, figsize=(14, 6))\n\nax.plot(X[:, 0][y == 0], X[:, 1][y == 0], \"bs\")\nax.plot(X[:, 0][y == 1], X[:, 1][y == 1], \"g^\")\nax.set_title(\"Dataset\")\nax.set_frame_on(False)\nax.set_xticks([])\nax.set_yticks([])\nfig.tight_layout()\n```\n\n[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/tunning_scatter.png)\n\n## Cross-validtion\n\n```python\nmodels: dict[BaseEstimator, dict] = {\n RandomForestClassifier: {\n 'n_estimators': [10, 50, 100, 200],\n 'max_depth': [None, 5, 10, 15],\n 'min_samples_split': [2, 5, 10],\n 'min_samples_leaf': [1, 2, 4],\n 'random_state': [random_state]\n },\n GradientBoostingClassifier: {\n 'n_estimators': [50, 100, 200],\n 'learning_rate': [0.1, 0.05, 0.01, 0.005],\n 'subsample': [0.5, 0.8, 1.0],\n 'random_state': [random_state]\n },\n LogisticRegression: {\n 'C': [0.01, 0.1, 1.0, 10.0],\n 'penalty': ['l1', 'l2'],\n 'solver': ['liblinear', 'saga'],\n 'random_state': [random_state]\n },\n GaussianNB: {\n 'var_smoothing': [1e-9, 1e-8, 1e-7, 1e-6, 1e-5]\n },\n KNeighborsClassifier: {\n 'n_neighbors': [3, 5, 7, 9],\n 'weights': ['uniform', 'distance'],\n 'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute']\n },\n SVC: {\n 'C': [0.01, 0.1, 1.0, 10.0],\n 'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],\n 'degree': [2, 3, 4],\n 'gamma': ['scale', 'auto'],\n 'random_state': [random_state]\n },\n DecisionTreeClassifier: {\n 'criterion': ['gini', 'entropy'],\n 'splitter': ['best', 'random'],\n 'max_depth': [None, 5, 10, 15],\n 'min_samples_split': [2, 5, 10],\n 'min_samples_leaf': [1, 2, 4],\n 'random_state': [random_state]\n }\n}\n```\n\n```python\ngrid_search = GridSearch(\n X,\n y,\n params_split=params_split,\n models_params=models,\n normalize=True,\n params_norm=params_norm,\n scoring='accuracy',\n metrics=model_metrics\n)\ngrid_search.search(cv=cv, n_jobs=-1)\n\nbest_model, best_params = \\\n grid_search \\\n .get_best_model()\n```\n\n```python\nresults: pd.DataFrame = pd.DataFrame(grid_search._metrics).T\nresults\n```\n\n<table>\n <tr>\n <th></th>\n <th>custom_accuracy</th>\n <th>accuracy</th>\n <th>precision</th>\n <th>recall</th>\n <th>kappa</th>\n <th>f1</th>\n </tr>\n <tr>\n <td>RandomForestClassifier</td>\n <td>246.0</td>\n <td>0.984</td>\n <td>0.983607</td>\n <td>0.983607</td>\n <td>0.967982</td>\n <td>0.983607</td>\n </tr>\n <tr>\n <td>GradientBoostingClassifier</td>\n <td>244.0</td>\n <td>0.976</td>\n <td>0.975410</td>\n <td>0.975410</td>\n <td>0.951972</td>\n <td>0.975410</td>\n </tr>\n <tr>\n <td>LogisticRegression</td>\n <td>245.0</td>\n <td>0.980</td>\n <td>0.983471</td>\n <td>0.975410</td>\n <td>0.959969</td>\n <td>0.979424</td>\n </tr>\n <tr>\n <td>GaussianNB</td>\n <td>244.0</td>\n <td>0.976</td>\n <td>0.975410</td>\n <td>0.975410</td>\n <td>0.951972</td>\n <td>0.975410</td>\n </tr>\n <tr>\n <td>KNeighborsClassifier</td>\n <td>245.0</td>\n <td>0.980</td>\n <td>0.983471</td>\n <td>0.975410</td>\n <td>0.959969</td>\n <td>0.979424</td>\n </tr>\n <tr>\n <td>SVC</td>\n <td>245.0</td>\n <td>0.980</td>\n <td>0.983471</td>\n <td>0.975410</td>\n <td>0.959969</td>\n <td>0.979424</td>\n </tr>\n <tr>\n <td>DecisionTreeClassifier</td>\n <td>242.0</td>\n <td>0.968</td>\n <td>0.991379</td>\n <td>0.942623</td>\n <td>0.935889</td>\n <td>0.966387</td>\n </tr>\n</table>\n\n## Best model\nHere we can see the distribution for the best classifier.\n\n```python\nfig, ax = plt.subplots(1, 2, figsize=(14, 6))\n\nax[0].plot(X[:, 0][y == 0], X[:, 1][y == 0], \"bs\")\nax[0].plot(X[:, 0][y == 1], X[:, 1][y == 1], \"g^\")\nax[0].set_title(\"Dataset\")\nax[0].set_frame_on(False)\nax[0].set_xticks([])\nax[0].set_yticks([])\n\nax[1].plot(\n grid_search.X_test[:, 0][grid_search.y_test == 0],\n grid_search.X_test[:, 1][grid_search.y_test == 0],\n \"bs\"\n)\nax[1].plot(\n grid_search.X_test[:, 0][grid_search.y_test == 1],\n grid_search.X_test[:, 1][grid_search.y_test == 1],\n \"g^\"\n)\nax[1].set_title(grid_search.best_model.__class__.__name__)\nax[1].set_frame_on(False)\nax[1].set_xticks([])\nax[1].set_yticks([])\nfig.tight_layout()\n```\n\n[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/tunning_best_model.png)\n\n# Classification: uncertainty estimation\n\nClick [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/classification/) for contents.\n\nHow to use the module for uncertainty estimation in classification tasks.\n\n## Importing the Library\nFirst, import the necessary modules from the library:\n\n```python\nfrom typing import Dict\nfrom functools import partial\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nfrom sklearn.base import BaseEstimator\nfrom sklearn.datasets import make_blobs\nfrom sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import (accuracy_score, cohen_kappa_score, f1_score,\n precision_score, recall_score)\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.svm import SVC\nfrom sklearn.tree import DecisionTreeClassifier\n\nfrom mlpr.ml.supervisioned.classification.uncertainty import UncertaintyPlots\nfrom mlpr.ml.supervisioned.classification.utils import calculate_probas\nfrom mlpr.ml.supervisioned.tunning.grid_search import GridSearch\n\nimport warnings\nwarnings.filterwarnings(\"ignore\")\n```\n\n## Parameters\nSetting parameters for the experiments.\n\n```python\nrandom_state: int = 42\nn_feats: int = 2\nn_size: int = 1000\ncenters: list[tuple] = [\n (0, 2),\n (2, 0),\n (5, 4.5)\n]\nn_class: int = len(centers)\ncluster_std: list[float] = [1.4, 1.4, 0.8]\ncv: int = 5\nnp.random.seed(random_state)\n```\n\n```python\nparams: dict[str, dict[str, Any]] = {\n \"n_samples\": n_size,\n \"n_features\": n_feats,\n \"centers\": centers,\n \"cluster_std\": cluster_std,\n \"random_state\": random_state\n}\n```\n\n```python\nnp.random.seed(random_state)\n```\n\n```python\nparams_split: dict[str, float | int] = {\n 'test_size': 0.25,\n 'random_state': random_state\n}\nparams_norm: dict[str, bool] = {'with_mean': True, 'with_std': True}\n\nmodel_metrics: dict[str, Any] = {\n 'custom_accuracy': partial(accuracy_score, normalize=False),\n 'accuracy': accuracy_score,\n 'precision': partial(precision_score, average='macro'),\n 'recall': partial(recall_score, average='macro'),\n 'kappa': cohen_kappa_score,\n 'f1': partial(f1_score, average='macro'),\n}\n```\n\n## Load the dataset\n\nHere we are generating a dataset for experiments, using blobs from scikit-learn.\n\n```python\nX, y = make_blobs(\n **params\n)\n```\n\n## Plot the dataset\nBehavior of the dataset used in the experiment.\n\n```python\nmarkers = ['o', 'v', '^']\nfig, ax = plt.subplots(1, 1, figsize=(14, 6))\n\ncolors = generate_colors(\"FF4B3E\", \"1C2127\", len(np.unique(y)))\n\nfor i, k in enumerate(np.unique(y)):\n ax.scatter(X[:, 0][y == k], X[:, 1][y == k], marker=markers[i % len(markers)], color=colors[i], label=f\"c{i}\")\n\nax.set_title(\"Dataset\")\nax.set_frame_on(False)\nax.set_xticks([])\nax.set_yticks([])\nfor i, (center, color) in enumerate(zip(centers, colors)):\n ax.scatter(\n center[0],\n center[1],\n color=\"white\",\n linewidths=3,\n marker=\"o\",\n edgecolor=\"black\",\n s=120,\n label=\"center\" if i == 0 else None\n )\nplt.legend()\nfig.tight_layout()\n```\n\n[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/classification_scatter.png)\n\n\n## Cross-validation\n\n```python\nmodels: dict[BaseEstimator, dict] = {\n RandomForestClassifier: {\n 'n_estimators': [10, 50, 100, 200],\n 'max_depth': [None, 5, 10, 15],\n 'min_samples_split': [2, 5, 10],\n 'min_samples_leaf': [1, 2, 4],\n 'random_state': [random_state]\n },\n GradientBoostingClassifier: {\n 'n_estimators': [50, 100, 200],\n 'learning_rate': [0.1, 0.05, 0.01, 0.005],\n 'subsample': [0.5, 0.8, 1.0],\n 'random_state': [random_state]\n },\n LogisticRegression: {\n 'C': [0.01, 0.1, 1.0, 10.0],\n 'penalty': ['l1', 'l2'],\n 'solver': ['liblinear', 'saga'],\n 'random_state': [random_state],\n 'max_iter': [10000]\n },\n GaussianNB: {\n 'var_smoothing': [1e-9, 1e-8, 1e-7, 1e-6, 1e-5]\n },\n SVC: {\n 'C': [0.01, 0.1, 1.0, 10.0],\n 'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],\n 'degree': [2, 3, 4],\n 'gamma': ['scale', 'auto'],\n 'probability': [True],\n 'random_state': [random_state]\n },\n DecisionTreeClassifier: {\n 'criterion': ['gini', 'entropy'],\n 'splitter': ['best', 'random'],\n 'max_depth': [None, 5, 10, 15],\n 'min_samples_split': [2, 5, 10],\n 'min_samples_leaf': [1, 2, 4],\n 'random_state': [random_state]\n }\n}\n```\n\n```python\ngrid_search = GridSearch(\n X,\n y,\n params_split=params_split,\n models_params=models,\n normalize=True,\n params_norm=params_norm,\n scoring='accuracy',\n metrics=model_metrics\n)\ngrid_search.search(cv=cv, n_jobs=-1)\n\nbest_model, best_params = \\\n grid_search \\\n .get_best_model()\n```\n\n```python\nresults: pd.DataFrame = pd.DataFrame(grid_search._metrics).T\nresults\n```\n\n<table>\n <thead>\n <tr>\n <th></th>\n <th>custom_accuracy</th>\n <th>accuracy</th>\n <th>precision</th>\n <th>recall</th>\n <th>kappa</th>\n <th>f1</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <td>RandomForestClassifier</td>\n <td>222.0</td>\n <td>0.888</td>\n <td>0.883566</td>\n <td>0.885902</td>\n <td>0.831666</td>\n <td>0.882724</td>\n </tr>\n <tr>\n <td>GradientBoostingClassifier</td>\n <td>221.0</td>\n <td>0.884</td>\n <td>0.878830</td>\n <td>0.881207</td>\n <td>0.825583</td>\n <td>0.878421</td>\n </tr>\n <tr>\n <td>LogisticRegression</td>\n <td>230.0</td>\n <td>0.920</td>\n <td>0.915170</td>\n <td>0.916987</td>\n <td>0.879457</td>\n <td>0.915662</td>\n </tr>\n <tr>\n <td>GaussianNB</td>\n <td>231.0</td>\n <td>0.924</td>\n <td>0.919375</td>\n <td>0.921682</td>\n <td>0.885539</td>\n <td>0.920046</td>\n </tr>\n <tr>\n <td>SVC</td>\n <td>230.0</td>\n <td>0.920</td>\n <td>0.915170</td>\n <td>0.916987</td>\n <td>0.879457</td>\n <td>0.915662</td>\n </tr>\n <tr>\n <td>DecisionTreeClassifier</td>\n <td>214.0</td>\n <td>0.856</td>\n <td>0.848155</td>\n <td>0.845622</td>\n <td>0.782325</td>\n <td>0.846414</td>\n </tr>\n </tbody>\n</table>\n\n## Probabilities\n\nGetting probabilities for uncertainty generation.\n\n```python\nprobas = calculate_probas(grid_search.fitted, grid_search.X_train)\n```\n\n## Plot best model result\n\nPlotting the result for best model.\n\n```python\nup = UncertaintyPlots()\n```\n\n```python\nfig_un, ax_un = up.uncertainty(\n model_names=[[best_model.__class__.__name__]],\n probs={best_model.__class__.__name__: probas[best_model.__class__.__name__]},\n X=grid_search.X_train,\n figsize=(20, 6),\n cmap='RdYlGn',\n show_inline=True,\n box_on=False\n)\n```\n\n[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/classification_uncertain_best.png)\n\n\n\n## Plot overall of uncertainty\n\nPlotting an overall of uncertainty estimated for the models.\n\n```python\nsorted_models = results.sort_values(\"accuracy\", ascending=False).index.tolist()\n\npyramid = []\ni = 0\nfor row in range(1, len(sorted_models)):\n if i + row <= len(sorted_models):\n pyramid.append(sorted_models[i:i+row])\n i += row\n else:\n break\n\nif i < len(sorted_models):\n pyramid.append(sorted_models[i:])\n\nif len(pyramid[-1]) < len(pyramid[-2]):\n pyramid[-2].extend(pyramid[-1])\n pyramid = pyramid[:-1]\n```\n\n```python\nup = UncertaintyPlots()\n```\n\n```python\nfig_un, ax_un = up.uncertainty(\n model_names=pyramid,\n probs=probas,\n X=grid_search.X_train,\n figsize=(20, 10),\n show_inline=True,\n cmap='RdYlGn',\n box_on=False\n)\n```\n\n[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/classification_uncertain_pyramid.png)\n\n\n## Aleatory uncertainty and Epistemic uncertainty\n\n```python\ndata_probas = pd.DataFrame(probas)\nrandom: pd.Series = data_probas.mean(axis=1)\nepistemic: pd.Series = data_probas.var(axis=1)\n```\n\n```python\nup = UncertaintyPlots()\n```\n\n```python\nfig_both, ax_both = up.uncertainty(\n model_names=[[\"Random uncertainty\", \"Epistemic uncertainty\"]],\n probs={\n \"Random uncertainty\": random,\n \"Epistemic uncertainty\": epistemic\n },\n X=grid_search.X_train,\n figsize=(20, 6),\n cmap='RdYlGn',\n show_inline=True,\n box_on=False\n)\n```\n\n[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/classification_uncertain_aleatory_epistemic.png)\n\n# Regression\n\nClick [here](https://github.com/Manuelfjr/mlpr/tree/develop/notebooks/supervisioned/regression/) for contents.\n\nHow to use the module for regression problems.\n\n## Importing the Library\nFirst, import the necessary modules from the library:\n\n```python\nfrom mlpr.ml.supervisioned.regression import metrics, plots\nfrom mlpr.ml.supervisioned.tunning.grid_search import GridSearch\nfrom mlpr.reports.create import ReportGenerator\n```\n\n## Loading the Data\nLoad your dataset. In this example, we're generating a dataset for regression using sklearn:\n\n```python\nn_feats = 11\nn_instances = 1000\nn_invert = 50\nn_noise = 20\ncv = 10\n```\n\n```python\nX, y = make_regression(n_samples=n_instances, n_features=n_feats, noise=n_noise)\n\n# introduce of noises\nindices = np.random.choice(y.shape[0], size=n_invert, replace=False)\ny[indices] = np.max(y) - y[indices]\n\ndata = pd.DataFrame(data=X, columns=[f'feature_{i}' for i in range(1, n_feats + 1)])\ndata['target'] = y\n```\n\n## Set the seed\nSet the random seed for reproducibility\n\n```python\nn_seed = 42\nnp.random.seed(n_seed)\n```\n\n## Preparing the Data\nSplit your data into features ($X$) and target ($y$):\n\n```python\nX = data.drop(\"target\", axis=1)\ny = data[\"target\"].values\n```\n## Model Training\nDefine the parameters for your models and use `GridSearch` to find the best model:\n\n```python\nmodels_params = {\n Ridge: {\n 'alpha': [1.0, 10.0, 15., 20.],\n 'random_state': [n_seed]\n },\n Lasso: {\n 'alpha': [0.1, 1.0, 10.0],\n 'random_state': [n_seed]\n },\n SVR: {\n 'C': [0.1, 1.0, 10.0],\n 'kernel': ['linear', 'rbf']\n },\n RandomForestRegressor: {\n 'n_estimators': [10, 50, 100],\n 'max_depth': [None, 5, 10],\n 'random_state': [n_seed]\n },\n GradientBoostingRegressor: {\n 'n_estimators': [100, 200],\n 'learning_rate': [0.1, 0.05, 0.01],\n 'random_state': [n_seed]\n },\n XGBRegressor: {\n 'n_estimators': [100, 200],\n 'learning_rate': [0.1, 0.05, 0.01],\n 'random_state': [n_seed]\n }\n}\n\nparams_split: dict[str, float | int] = {\n 'test_size': 0.25,\n 'random_state': n_seed\n}\nparams_norm: dict[str, bool] = {'with_mean': True, 'with_std': True}\n\ngrid_search = GridSearch(\n X,\n y,\n params_split=params_split,\n models_params=models_params,\n normalize=True,\n scoring='neg_mean_squared_error',\n metrics={'neg_mean_squared_error': rmse},\n params_norm=params_norm\n)\ngrid_search.search(cv=5, n_jobs=-1)\n\nbest_model, best_params = \\\n grid_search \\\n .get_best_model()\n\n```\n\n\n## Making Predictions\nUse the best model to make predictions:\n\n```python\ndata_train = pd.DataFrame(\n grid_search.X_train,\n columns=X.columns\n)\ndata_train[\"y_true\"] = grid_search.y_train\ndata_train[\"y_pred\"] = grid_search.best_model.predict(grid_search.X_train)\n```\n\n## Evaluating the Model\nCalculate various metrics to evaluate the performance of the model:\n\n```python\nk = 3\n```\n\n```python\nrm = metrics.RegressionMetrics(\n data_train,\n *[\"y_true\", \"y_pred\"]\n)\nresults = rm.calculate_metrics(\n [\"mape\", \"rmse\", \"kolmogorov_smirnov\", \"confusion_matrix\", \"calculate_kappa\"],\n {\n \"mape\": {},\n \"rmse\": {},\n \"kolmogorov_smirnov\": {},\n \"confusion_matrix\": {\"n_bins\": k},\n \"calculate_kappa\": {\"n_bins\": k}\n }\n)\n```\n\n## Results\n\nThe output it's a dictionary object with the calculated metrics, like this:\n\n```\n{'mape': 39.594540526956436,\n 'rmse': 54.09419440169204,\n 'kolmogorov_smirnov': (0.1510574018126888, 0.0010310446878578096),\n 'confusion_matrix': (array([[54, 57, 2, 0],\n [16, 70, 21, 0],\n [ 0, 37, 37, 3],\n [ 0, 6, 25, 3]]),\n {'precision': array([0.77142857, 0.41176471, 0.43529412, 0.5 ]),\n 'recall': array([0.47787611, 0.65420561, 0.48051948, 0.08823529]),\n 'f1_score': array([0.59016393, 0.50541516, 0.45679012, 0.15 ]),\n 'support': array([113, 107, 77, 34]),\n 'accuracy': 0.4954682779456193}),\n 'calculate_kappa': {0: {'confusion_matrix': array([[202, 16],\n [ 59, 54]]),\n 'kappa_score': 0.4452885840055415,\n 'metrics': {'precision': array([0.77394636, 0.77142857]),\n 'recall': array([0.9266055 , 0.47787611]),\n 'f1_score': array([0.8434238 , 0.59016393]),\n 'support': array([218, 113]),\n 'accuracy': 0.7734138972809668}},\n 1: {'confusion_matrix': array([[124, 100],\n [ 37, 70]]),\n 'kappa_score': 0.180085703437178,\n 'metrics': {'precision': array([0.77018634, 0.41176471]),\n 'recall': array([0.55357143, 0.65420561]),\n 'f1_score': array([0.64415584, 0.50541516]),\n 'support': array([224, 107]),\n 'accuracy': 0.5861027190332326}},\n 2: {'confusion_matrix': array([[206, 48],\n [ 40, 37]]),\n 'kappa_score': 0.2813579394059016,\n 'metrics': {'precision': array([0.83739837, 0.43529412]),\n 'recall': array([0.81102362, 0.48051948]),\n 'f1_score': array([0.824 , 0.45679012]),\n 'support': array([254, 77]),\n 'accuracy': 0.7341389728096677}},\n 3: {'confusion_matrix': array([[294, 3],\n [ 31, 3]]),\n 'kappa_score': 0.12297381546134645,\n 'metrics': {'precision': array([0.90461538, 0.5 ]),\n 'recall': array([0.98989899, 0.08823529]),\n 'f1_score': array([0.94533762, 0.15 ]),\n 'support': array([297, 34]),\n 'accuracy': 0.8972809667673716}}}}\n```\n\n\n\n## Visualizing the Results\nPlot the results using the `RegressionPlots` module:\n\n```python\nrp = \\\n plots \\\n .RegressionPlots(\n data_train,\n color_palette=[\"#FF4B3E\", \"#1C2127\"]\n )\n```\n\n```py\nfig, axs = rp.grid_plot(\n plot_functions=[\n ['graph11', 'graph12', 'graph13'],\n ['graph21', 'graph22'],\n ['graph23']\n ],\n plot_args={\n 'graph11': {\n \"plot\": \"scatter\",\n \"params\": {\n 'y_true_col': 'y_true',\n 'y_pred_col': 'y_pred',\n 'linecolor': '#1C2127',\n 'worst_interval': True,\n 'metrics': rm.metrics[\"calculate_kappa\"],\n 'class_interval': rm._class_intervals,\n 'method': 'recall',\n 'positive': True\n }\n },\n 'graph12': {\n \"plot\": \"plot_ecdf\",\n \"params\": {\n 'y_true_col': 'y_true',\n 'y_pred_col': 'y_pred'\n }\n },\n 'graph21': {\n \"plot\": \"plot_kde\",\n \"params\": {\n 'columns': ['y_true', 'y_pred']\n }\n },\n 'graph22': {\n \"plot\": \"plot_error_hist\",\n \"params\": {\n 'y_true_col': 'y_true',\n 'y_pred_col': 'y_pred',\n 'linecolor': '#1C2127'\n }\n },\n 'graph13': {\n \"plot\": \"plot_fitted\",\n \"params\": {\n 'y_true_col': 'y_true',\n 'y_pred_col': 'y_pred',\n 'condition': (\n (\n rm._worst_interval_kappa[0] <= data_train[\"y_true\"]\n ) & (\n data_train[\"y_true\"] <= rm._worst_interval_kappa[1]\n )\n ),\n 'sample_size': None\n }\n },\n 'graph23': {\n \"plot\": \"plot_fitted\",\n \"params\": {\n 'y_true_col': 'y_true',\n 'y_pred_col': 'y_pred',\n 'condition': None,\n 'sample_size': None\n }\n },\n },\n show_inline=True\n)\n```\n\n[](https://raw.githack.com/Manuelfjr/mlpr/develop/assets/regression_plots.png)\n\n\n## Reports\n\nHere you can see the <a href=\"https://raw.githack.com/Manuelfjr/mlpr/develop/data/05_reports/report_model.html\">report</a> output.\n\n# Contact\n\nHere you can find my contact information:\n\n<div align=\"center\">\n <a href=\"https://github.com/Manuelfjr/mlpr\">\n <img src=\"https://avatars.githubusercontent.com/u/53409857?v=4\" alt=\"Profile Image\" width=\"200\" height=\"200\" style=\"border-radius: 50%;\">\n </a>\n</div>\n\n<br>\n\n<div align=\"center\">\n<a href=\"https://manuelfjr.github.io\"><img src=\"https://img.icons8.com/ios/30/000000/domain.png\"/></a>\n<a href=\"https://github.com/manuelfjr\"><img src=\"https://img.icons8.com/ios/30/000000/github--v1.png\"/></a>\n<a href=\"https://www.instagram.com/manuelferreirajr/\"><img src=\"https://img.icons8.com/ios/30/000000/instagram-new--v1.png\"/></a>\n<a href=\"https://www.linkedin.com/in/manuefjr/\"><img src=\"https://img.icons8.com/ios/30/000000/linkedin.png\"/></a>\n<a href=\"mailto:ferreira.jr.ufpb@gmail.com\"><img src=\"https://img.icons8.com/ios/30/000000/email.png\"/></a>\n</div>\n\n# License\n\nThis project is licensed under the terms of the MIT license. For more details, see the [LICENSE](/LICENSE) file in the project's root directory.",
"bugtrack_url": null,
"license": null,
"summary": "A library for machine learning pipeline and creation of reports.",
"version": "0.1.19",
"project_urls": {
"changelog": "https://github.com/Manuelfjr/mlpr/tree/develop/CHANGELOG.md",
"homepage": "https://github.com/Manuelfjr/mlpr/tree/develop",
"issues": "https://github.com/Manuelfjr/mlpr/issues",
"repository": "https://github.com/Manuelfjr/mlpr.git",
"source": "https://github.com/Manuelfjr/mlpr",
"tracker": "https://github.com/Manuelfjr/mlpr/tree/develop/issues"
},
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "8f0b99e7b268879dea2bd435da874f8afcf06b7b660826d1052650d7b5ab58a1",
"md5": "cd25d36de0e39f103abbd7272b216a6f",
"sha256": "56c6b6f64b57a6d26c558afa6d7b7e51feb64c09c0de05e20a49d670eeca1070"
},
"downloads": -1,
"filename": "mlpr-0.1.19-py3-none-any.whl",
"has_sig": false,
"md5_digest": "cd25d36de0e39f103abbd7272b216a6f",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.9",
"size": 39124,
"upload_time": "2024-05-14T14:28:06",
"upload_time_iso_8601": "2024-05-14T14:28:06.031052Z",
"url": "https://files.pythonhosted.org/packages/8f/0b/99e7b268879dea2bd435da874f8afcf06b7b660826d1052650d7b5ab58a1/mlpr-0.1.19-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "58f4b05bafcdc7d635ea48b67cc8f239a5a67c17706252e62f50910af51e99b6",
"md5": "3aee9ea8de8e045a054e780d873e3053",
"sha256": "90747d1406fbf78f16337c70917891bd01cba32f8924890d855e1c3f9995b203"
},
"downloads": -1,
"filename": "mlpr-0.1.19.tar.gz",
"has_sig": false,
"md5_digest": "3aee9ea8de8e045a054e780d873e3053",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.9",
"size": 33359,
"upload_time": "2024-05-14T14:28:08",
"upload_time_iso_8601": "2024-05-14T14:28:08.041953Z",
"url": "https://files.pythonhosted.org/packages/58/f4/b05bafcdc7d635ea48b67cc8f239a5a67c17706252e62f50910af51e99b6/mlpr-0.1.19.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-05-14 14:28:08",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "Manuelfjr",
"github_project": "mlpr",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "mlpr"
}
