# MMKit-Features: Multimodal Feature Extraction Toolkit
Traditional knowledge graphs (KGs) are usually comprised of entities, relationships, and attributes. However, they are not designed to effectively store or represent multimodal data. This limitation prevents them from capturing and integrating information from different modes of data, such as text, images, and audio, in a meaningful and holistic way.
The `MMKit-Features` project proposes a multimodal architecture to build multimodal knowledge graphs with flexible multimodal feature extraction and dynamic multimodal concept generation.
## Project Goal
- To extract, store, and fuse various multimodal features from multimodal datasets efficiently;
- To achieve generative adversarial network(GAN)-based multimodal knowledge representation dynamically in multimodal knowledge graphs;
- To provide a common deep learning-based architecture to enhance multimodal knowledge reasoning in real life.
## Installation
You can install this toolkit using our [PyPi](https://pypi.org/project/mmkit-features/) package.
```
pip install mmkit-features
```
## Design Science Framework
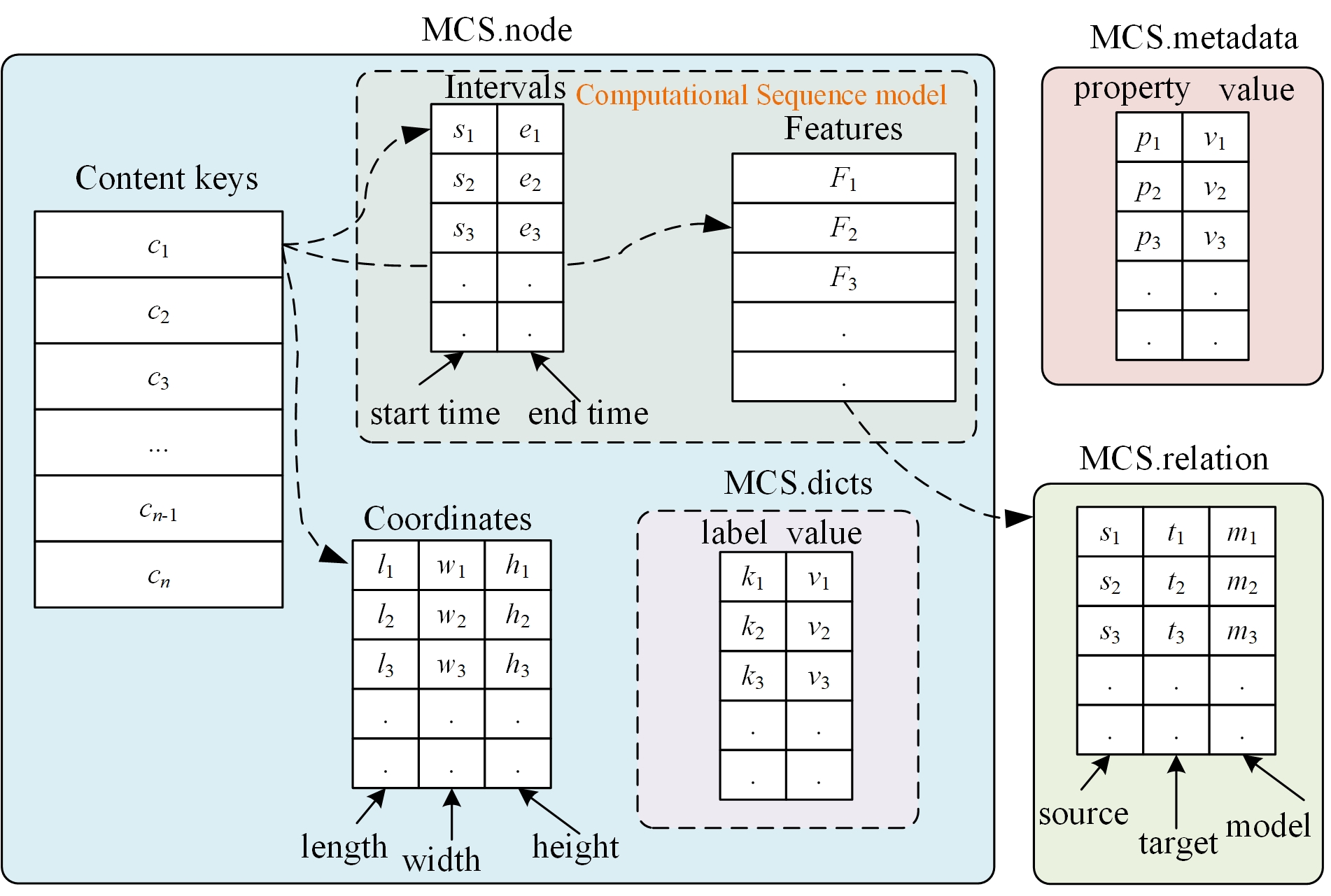
Figure 1: Multimodal Computational Sequence
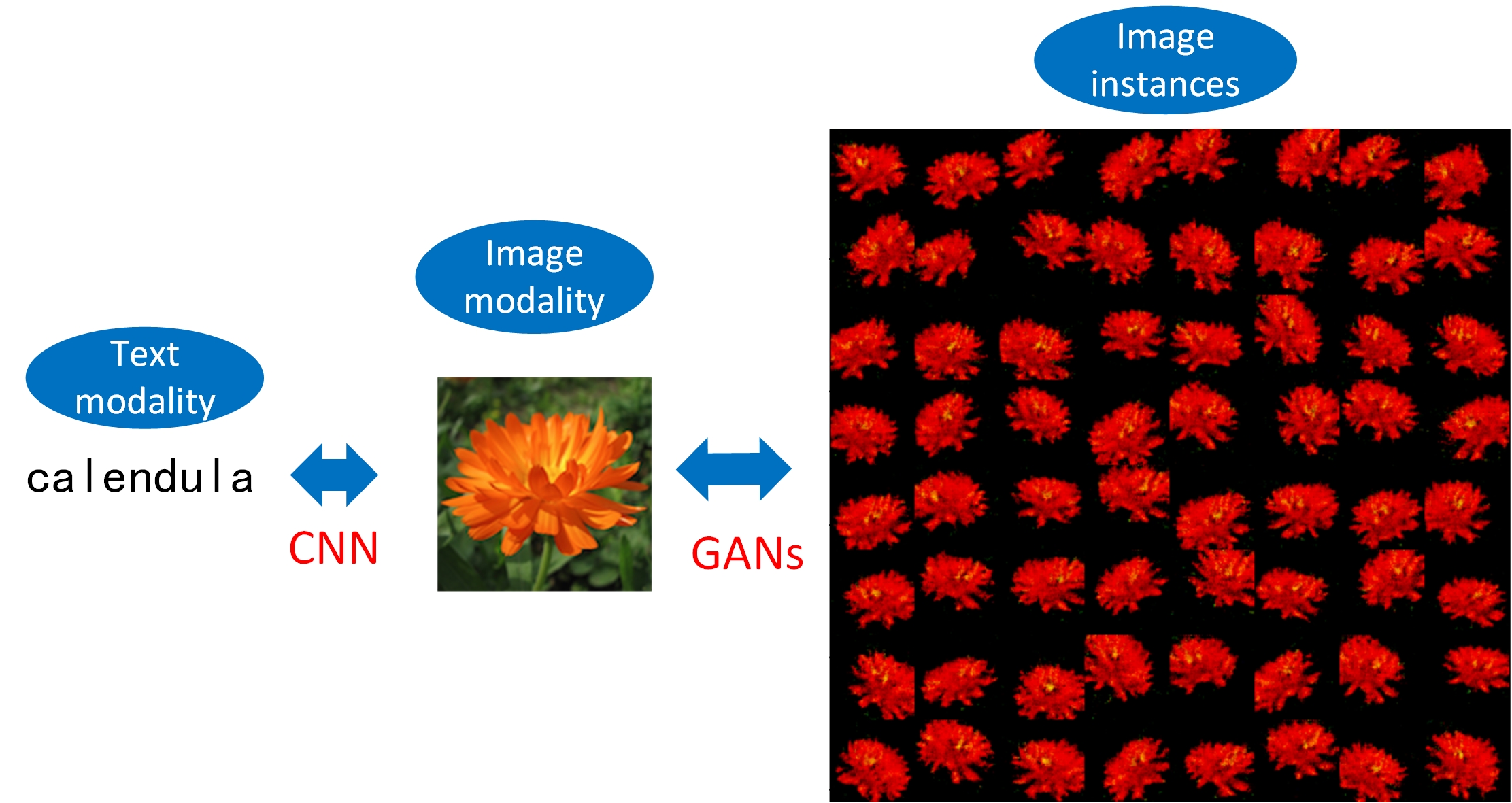
Figure 2: GAN-based Multimodal Concept Generation
## Modalities
1. Text/Language modality
2. Image modality
3. Video modality
4. Audio modality
5. Cross-modality among above
## Usage
A toy example showing how to build a multimodal feature (MMF) library is here:
```python
from mmkfeatures.fusion.mm_features_lib import MMFeaturesLib
from mmkfeatures.fusion.mm_features_node import MMFeaturesNode
import numpy as np
if __name__ == "__main__":
# 1. create an empty multimodal features library with root and dataset names
feature_lib = MMFeaturesLib(root_name="test features",dataset_name = "test_features")
# 2. set short names for each dimension for convenience
feature_lib.set_features_name(["feature1","feature2","feature3"])
# 3. set a list of content IDs
content_ids = ["content1","content2","content3"]
# 4. according to IDs, assign a group of features with interval to corresponding content ID
features_dict = {}
for id in content_ids:
mmf_node = MMFeaturesNode(id)
mmf_node.set_item("name",str(id))
mmf_node.set_item("features",np.array([[1,2,3]]))
mmf_node.set_item("intervals",np.array([[0,1]]))
features_dict[id] = mmf_node
# 5. set the library's data
feature_lib.set_data(features_dict)
# 6. save the features to disk for future use
feature_lib.save_data("test6_feature.csd")
# 7. check structure of lib file with the format of h5py
feature_lib.show_structure("test6_feature.csd")
# 8. have a glance of features content within the dataset
feature_lib.show_sample_data("test6_feature.csd")
# 9. Finally, we construct a simple multimodal knowledge base.
```
Further instructions on the toolkit refers to [here](https://github.com/dhchenx/mmkit-features/tree/main/doc).
## Applications
Here are some examples of using our work in real life with codes and documents.
### 1. Multimodal Features Extractors
- [Text Features Extraction](doc/text_features_extraction.md)
- [Speech Features Extraction](doc/speech_features_extraction.md)
- [Image Features Extractoin](doc/image_features_extraction.md)
- [Video Features Extraction](doc/video_features_extraction.md)
- [Transformer-based Features Extraction](src/mmkfeatures/transformer/README.md)
### 2. Multimodal Feature Library (MMFLib)
- [Basic Computational Sequence](doc/simple_computational_seq_use.md)
- [Core use of MMFLib](doc/multimodal_features_library.md)
### 3. Multimodal Knowledge Bases
- [Multimodal Birds Feature Library](doc/example_bird_library.md)
- [Multimodal Disease Coding Feature Library](doc/example_icd11_library.md)
- [Multimodal ROCO Feature Library](examples/roco_lib/step1_create_lib_roco.py)
### 4. Multimodal Indexing and Querying
- [Brute Force Indexing](examples/birds_features_lib/step3_use_index.py)
- [Inverted Indexing](examples/birds_features_lib/step3_use_index.py)
- [Positional Indexing](examples/birds_features_lib/step3_use_index.py)
- [Multimodal Indexing and querying](examples/birds_features_lib/evaluate/)
## Credits
The project includes some source codes from various open-source contributors. Here is a list of their contributions.
1. [A2Zadeh/CMU-MultimodalSDK](https://github.com/A2Zadeh/CMU-MultimodalSDK)
2. [aishoot/Speech_Feature_Extraction](https://github.com/aishoot/Speech_Feature_Extraction)
3. [antoine77340/video_feature_extractor](https://github.com/antoine77340/video_feature_extractor)
4. [jgoodman8/py-image-features-extractor](https://github.com/jgoodman8/py-image-features-extractor)
5. [v-iashin/Video Features](https://v-iashin.github.io/video_features/)
## License
The `mmkit-features` project is provided by [Donghua Chen](https://github.com/dhchenx) with MIT license.
## Citation
Please cite our project if the project is used in your research.
Chen, D. (2023). MMKit-Features: Multimodal Features Extraction Toolkit (Version 0.0.2) [Computer software]
Raw data
{
"_id": null,
"home_page": "https://github.com/dhchenx/mmkit-features",
"name": "mmkit-features",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.6, <4",
"maintainer_email": "",
"keywords": "multimodal features,multimodal data,knowledge base",
"author": "Donghua Chen",
"author_email": "douglaschan@126.com",
"download_url": "https://files.pythonhosted.org/packages/2e/3f/67a9ac82cf3d09643f2d82151c1fb2e4ae66b70914dcaf4c469dc712b17f/mmkit-features-0.0.1a4.tar.gz",
"platform": null,
"description": "# MMKit-Features: Multimodal Feature Extraction Toolkit\n\nTraditional knowledge graphs (KGs) are usually comprised of entities, relationships, and attributes. However, they are not designed to effectively store or represent multimodal data. This limitation prevents them from capturing and integrating information from different modes of data, such as text, images, and audio, in a meaningful and holistic way.\n\nThe `MMKit-Features` project proposes a multimodal architecture to build multimodal knowledge graphs with flexible multimodal feature extraction and dynamic multimodal concept generation. \n\n## Project Goal\n- To extract, store, and fuse various multimodal features from multimodal datasets efficiently;\n- To achieve generative adversarial network(GAN)-based multimodal knowledge representation dynamically in multimodal knowledge graphs;\n- To provide a common deep learning-based architecture to enhance multimodal knowledge reasoning in real life. \n\n## Installation\n\nYou can install this toolkit using our [PyPi](https://pypi.org/project/mmkit-features/) package. \n\n```\n pip install mmkit-features\n```\n\n## Design Science Framework\n\n\n\nFigure 1: Multimodal Computational Sequence\n\n\n\nFigure 2: GAN-based Multimodal Concept Generation\n\n## Modalities\n\n1. Text/Language modality\n2. Image modality\n3. Video modality\n4. Audio modality\n5. Cross-modality among above\n\n## Usage\nA toy example showing how to build a multimodal feature (MMF) library is here:\n\n```python\nfrom mmkfeatures.fusion.mm_features_lib import MMFeaturesLib\nfrom mmkfeatures.fusion.mm_features_node import MMFeaturesNode\nimport numpy as np\nif __name__ == \"__main__\":\n # 1. create an empty multimodal features library with root and dataset names\n feature_lib = MMFeaturesLib(root_name=\"test features\",dataset_name = \"test_features\")\n # 2. set short names for each dimension for convenience\n feature_lib.set_features_name([\"feature1\",\"feature2\",\"feature3\"])\n # 3. set a list of content IDs\n content_ids = [\"content1\",\"content2\",\"content3\"]\n # 4. according to IDs, assign a group of features with interval to corresponding content ID\n features_dict = {}\n for id in content_ids:\n mmf_node = MMFeaturesNode(id)\n mmf_node.set_item(\"name\",str(id))\n mmf_node.set_item(\"features\",np.array([[1,2,3]]))\n mmf_node.set_item(\"intervals\",np.array([[0,1]]))\n features_dict[id] = mmf_node\n # 5. set the library's data\n feature_lib.set_data(features_dict)\n # 6. save the features to disk for future use\n feature_lib.save_data(\"test6_feature.csd\")\n # 7. check structure of lib file with the format of h5py\n feature_lib.show_structure(\"test6_feature.csd\")\n # 8. have a glance of features content within the dataset\n feature_lib.show_sample_data(\"test6_feature.csd\")\n # 9. Finally, we construct a simple multimodal knowledge base. \n```\n\nFurther instructions on the toolkit refers to [here](https://github.com/dhchenx/mmkit-features/tree/main/doc). \n\n\n## Applications\n\nHere are some examples of using our work in real life with codes and documents. \n\n### 1. Multimodal Features Extractors\n\n- [Text Features Extraction](doc/text_features_extraction.md)\n- [Speech Features Extraction](doc/speech_features_extraction.md)\n- [Image Features Extractoin](doc/image_features_extraction.md)\n- [Video Features Extraction](doc/video_features_extraction.md)\n- [Transformer-based Features Extraction](src/mmkfeatures/transformer/README.md)\n\n### 2. Multimodal Feature Library (MMFLib)\n\n- [Basic Computational Sequence](doc/simple_computational_seq_use.md)\n- [Core use of MMFLib](doc/multimodal_features_library.md)\n\n### 3. Multimodal Knowledge Bases\n\n- [Multimodal Birds Feature Library](doc/example_bird_library.md)\n- [Multimodal Disease Coding Feature Library](doc/example_icd11_library.md)\n- [Multimodal ROCO Feature Library](examples/roco_lib/step1_create_lib_roco.py)\n\n### 4. Multimodal Indexing and Querying\n\n- [Brute Force Indexing](examples/birds_features_lib/step3_use_index.py)\n- [Inverted Indexing](examples/birds_features_lib/step3_use_index.py)\n- [Positional Indexing](examples/birds_features_lib/step3_use_index.py)\n- [Multimodal Indexing and querying](examples/birds_features_lib/evaluate/)\n\n## Credits\n\nThe project includes some source codes from various open-source contributors. Here is a list of their contributions. \n\n1. [A2Zadeh/CMU-MultimodalSDK](https://github.com/A2Zadeh/CMU-MultimodalSDK)\n2. [aishoot/Speech_Feature_Extraction](https://github.com/aishoot/Speech_Feature_Extraction)\n3. [antoine77340/video_feature_extractor](https://github.com/antoine77340/video_feature_extractor)\n4. [jgoodman8/py-image-features-extractor](https://github.com/jgoodman8/py-image-features-extractor)\n5. [v-iashin/Video Features](https://v-iashin.github.io/video_features/)\n\n## License\n\nThe `mmkit-features` project is provided by [Donghua Chen](https://github.com/dhchenx) with MIT license. \n\n## Citation\n\nPlease cite our project if the project is used in your research. \n\nChen, D. (2023). MMKit-Features: Multimodal Features Extraction Toolkit (Version 0.0.2) [Computer software]\n\n\n\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "A multimodal architecture to build multimodal knowledge graphs with flexible multimodal feature extraction and dynamic multimodal concept generation.",
"version": "0.0.1a4",
"project_urls": {
"Bug Reports": "https://github.com/dhchenx/mmkit-features/issues",
"Homepage": "https://github.com/dhchenx/mmkit-features",
"Source": "https://github.com/dhchenx/mmkit-features"
},
"split_keywords": [
"multimodal features",
"multimodal data",
"knowledge base"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "f5f4a8187704e18a8ee928aa55c3ea672556e73a56d98343e71bef1285766aac",
"md5": "c2ff91f366c63867ff384dd2616a69ce",
"sha256": "452f53f5eecd81ec5980e49fda180dbe330990228fa1573f92e84eb96167cb5a"
},
"downloads": -1,
"filename": "mmkit_features-0.0.1a4-py3-none-any.whl",
"has_sig": false,
"md5_digest": "c2ff91f366c63867ff384dd2616a69ce",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.6, <4",
"size": 145303,
"upload_time": "2023-05-13T02:33:16",
"upload_time_iso_8601": "2023-05-13T02:33:16.750585Z",
"url": "https://files.pythonhosted.org/packages/f5/f4/a8187704e18a8ee928aa55c3ea672556e73a56d98343e71bef1285766aac/mmkit_features-0.0.1a4-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "2e3f67a9ac82cf3d09643f2d82151c1fb2e4ae66b70914dcaf4c469dc712b17f",
"md5": "1014f5bf615e3d294ce16b14b740ed98",
"sha256": "470cbf12d6ccf99c2717ddf57d3824f4b095b95ade69323636a538e5d58e2eda"
},
"downloads": -1,
"filename": "mmkit-features-0.0.1a4.tar.gz",
"has_sig": false,
"md5_digest": "1014f5bf615e3d294ce16b14b740ed98",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.6, <4",
"size": 112706,
"upload_time": "2023-05-13T02:33:18",
"upload_time_iso_8601": "2023-05-13T02:33:18.795878Z",
"url": "https://files.pythonhosted.org/packages/2e/3f/67a9ac82cf3d09643f2d82151c1fb2e4ae66b70914dcaf4c469dc712b17f/mmkit-features-0.0.1a4.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-05-13 02:33:18",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "dhchenx",
"github_project": "mmkit-features",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "mmkit-features"
}

