| Name | nomad-audio JSON |
| Version |
0.0.9
 JSON
JSON |
| download |
| home_page | |
| Summary | Perceptual similarity embeddings for non-matching reference audio quality assessment and speech enhancement |
| upload_time | 2023-10-09 13:36:35 |
| maintainer | |
| docs_url | None |
| author | |
| requires_python | >=3.9 |
| license | Copyright (c) 2018 The Python Packaging Authority Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. |
| keywords |
audio quality
speech enhancement
speech quality
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# NOMAD: Non-Matching Audio Distance
NOMAD is a perceptual similarity metric for non-matching reference speech quality assessment. NOMAD embeddings can be used to:
* Measuring quality with any clean reference e.g., both paired and unpaired speech
* As a loss function to improve speech enhancement models
## Table of contents
- [NOMAD: Non-Matching Audio Distance](#non-matching-audio-distance--nomad-)
* [Installation](#installation)
* [Using NOMAD similarity score](#using-nomad-similarity-score)
+ [Using NOMAD from the command line](#using-nomad-from-the-command-line)
+ [Using NOMAD inside Python](#using-nomad-inside-python)
* [Using NOMAD loss function](#using-nomad-loss-function)
+ [NOMAD loss weighting](#nomad-loss-weighting)
* [Training](#training)
+ [Package dependencies](#package-dependencies)
+ [Dataset generation](#dataset-generation)
+ [Training the model](#training-the-model)
* [Performance](#performance)
* [Paper and license](#paper-and-license)
## Installation
NOMAD is hosted on PyPi. It can be installed in your Python environment with the following command
```
pip install nomad_audio
```
The model works with 16 kHz sampling rate. If your wav files have different sampling rates, automatic downsampling or upsampling is performed to use correctly the model.
NOMAD was built with Python 3.9.16.
## Using NOMAD similarity score
Data wav files can be passed in 2 modes:
* In ```mode=='dir'```, you need to indicate two directories for the reference and the degraded .wav files.
* In ```mode=='csv```, you need to indicated two csv for the reference and the degraded .wav files.
Reference files can be any clean speech.
### Using NOMAD from the command line
To predict perceptual similarity of all .wav files between two directories:
```
python -m nomad_audio --mode dir --nmr /path/to/dir/non-matching-references --deg /path/to/dir/degraded
```
To predict perceptual similarity of all .wav files between two csv files:
```
python -m nomad_audio --mode csv --nmr /path/to/csv/non-matching-references --deg /path/to/csv/degraded
```
Both csv files should include a column ```filename``` with the absolute path for each wav file.
In both modes, the script will create two csv files in ```results-csv``` with date time format.
* ```DD-MM-YYYY_hh-mm-ss_nomad_avg.csv``` includes the average NOMAD scores with respect to all the references in ```nmr_path```
* ```DD-MM-YYYY_hh-mm-ss_nomad_scores.csv``` includes pairwise scores between the degraded speech samples in ```test_path``` and the references in ```nmr_path```
You can choose where to save the csv files by setting ```results_path```.
You can run this example using some .wav files that are provided in the repo:
```
python -m nomad_audio --mode dir --nmr_path data/nmr-data --test_path data/test-data
```
The resulting csv file ```DD-MM-YYYY_hh-mm-ss_nomad_avg.csv``` shows the mean computed using the 4 non-matching reference files:
```
Test File NOMAD
445-123860-0012_NOISE_15 1.587
6563-285357-0042_OPUS_64k 0.294
```
The other csv file ```DD-MM-YYYY_hh-mm-ss_nomad_scores.csv``` includes the pairwise scores between the degraded and the non-matching reference files:
```
Test File MJ60_10 FL67_01 FI53_04 MJ57_01
445-123860-0012_NOISE_15 1.627 1.534 1.629 1.561
6563-285357-0042_OPUS_64k 0.23 0.414 0.186 0.346
```
### Using NOMAD inside Python
You can import NOMAD as a module in Python. Here is an example:
```{python}
from nomad_audio import nomad
nmr_path = 'data/nmr-data'
test_path = 'data/test-data'
nomad_avg_scores, nomad_scores = nomad.predict('dir', nmr_path, test_path)
```
## Using NOMAD loss function
NOMAD has been evaluated as a loss function to improve speech enhancement models.
NOMAD loss can be used as a PyTorch loss function as follows:
```{python}
from nomad_audio import nomad
# Here is your training loop where you calculate your loss
loss = mse_loss(estimate, clean) + weight * nomad.forward(estimate, clean)
```
We provide a full example on how to use NOMAD loss for speech enhancement using a wave U-Net architecture, see ```src/nomad_audio/nomad_loss_test.py```.
In this example we show that using NOMAD as an auxiliary loss you can get quality improvement:
* MSE -> PESQ = 2.39
* MSE + NOMAD loss -> PESQ = 2.60
Steps to reproduce this experiment:
* Download Valentini speech enhancement dataset [here](https://datashare.ed.ac.uk/handle/10283/2791)
* In ```src/nomad_audio/se_config.yaml``` change the following parameters
* ```noisy_train_dir``` path to noisy_trainset_28spk_wav
* ```clean_train_dir``` path to clean_trainset_28spk_wav
* ```noisy_valid_dir``` path to noisy_validset_28spk_wav
* ```clean_valid_dir``` path to clean_validset_28spk_wav
* ```noisy_test_dir``` path to noisy_testset_wav
* ```clean_test_dir``` path to clean_testset_wav
Notice that the Valentini dataset does not explicitly provide a validation partition. We created one by using speech samples from speakers ```p286``` and ```p287``` from the training set.
See the paper for more details on speech enhancement results using the model DEMUCS and evaluated with subjective listening tests.
### NOMAD loss weighting
We recommend to tune the weight of the NOMAD loss. Paper results with the DEMUCS model has been done by setting the weight to `0.1`.
The U-Net model provided in this repo uses a weight equal to `0.001`.
## Training
### Package dependencies
After cloning the repo you can either pip install nomad_audio as above or install the required packages from ```requirements.txt```. If you install the pip package you will also have the additional nomad_audio module which is not needed to train NOMAD but only for usage.
### Dataset generation
NOMAD is trained on degraded samples from the Librispeech dataset.
[Download](https://zenodo.org/record/8380442/files/nomad_ls.tar.gz?download=1) the dataset to train the model.
In addition, we provide [instructions](data/nomad_dataset.md) to generate the dataset above. Notice that the process can be time-consuming, we recommend to download the dataset from the link.
### Training the model
The following steps are required to train the model:
1. Download wav2vec from this [link](https://dl.fbaipublicfiles.com/fairseq/wav2vec/wav2vec_small.pt) and save it into ```pt-models```. If you ran above ```pip install nomad_audio``` in your working directory you can skip this step.
2. Change the following parameters in ```src/config/train_triplet.yaml```
* ```root``` should be set to degraded Librispeech dataset path
3. From the working directory run:
```
python main.py --config_file train_triplet.yaml
```
This will generate a path in your working directory ```out-models/train-triplet/dd-mm-yyyy_hh-mm-ss``` that includes the best model and the configuration parameters used to train this model.
## Performance
We evaluated NOMAD for ranking degradation intensity, speech quality assessment, and as a loss function for speech enhancement.
See the paper for more details.
As clean non-matching references, we extracted 899 samples from the [TSP](https://www.mmsp.ece.mcgill.ca/Documents/Data/) speech database.
Here we show the scatter plot between NOMAD scores (computed with unpaired speech) and MOS quality labels. For each database we mapped NOMAD scores to MOS using a third order polynomial.
Notice that performances are reported without mapping in the paper.
#### [Genspeech](https://arxiv.org/abs/2102.10449)
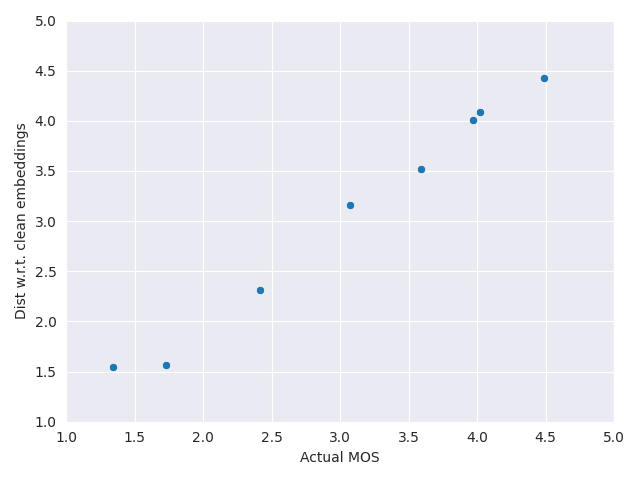
#### [P23 EXP1](https://www.itu.int/ITU-T/recommendations/rec.aspx?id=4415&lang=en)
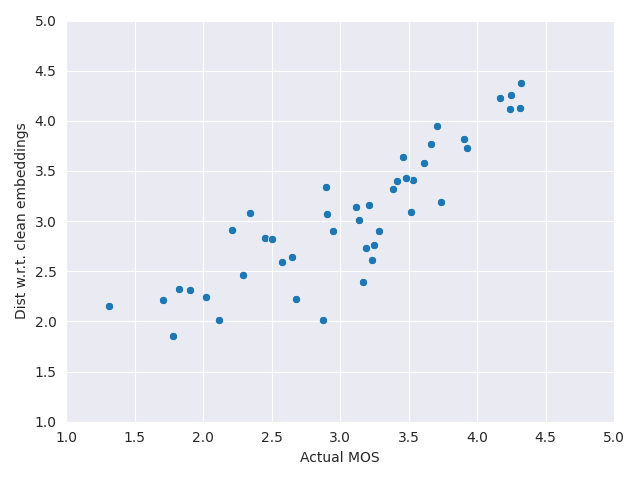
#### [P23 EXP3](https://www.itu.int/ITU-T/recommendations/rec.aspx?id=4415&lang=en)
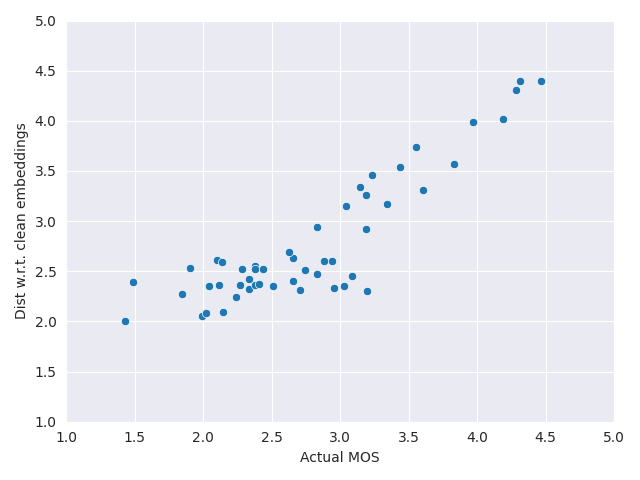
## Paper and license
If you use NOMAD or the training corpus for your research, please cite this [pre-print](https://arxiv.org/abs/2309.16284).
Ragano, A., Skoglund, J. and Hines, A., 2023. NOMAD: Unsupervised Learning of Perceptual Embeddings for Speech Enhancement and Non-matching Reference Audio Quality Assessment. arXiv preprint arXiv:2309.16284.
The NOMAD code is licensed under MIT license.
Copyright © 2023 Alessandro Ragano
Raw data
{
"_id": null,
"home_page": "",
"name": "nomad-audio",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.9",
"maintainer_email": "",
"keywords": "Audio quality,Speech enhancement,Speech quality",
"author": "",
"author_email": "Alessandro Ragano <alessandroragano@gmail.com>",
"download_url": "https://files.pythonhosted.org/packages/7a/f9/c4d30f5840a5ef8e7fb003b93d9bc9e2e8c0ce9c59550bd48ab04bb8a9fe/nomad_audio-0.0.9.tar.gz",
"platform": null,
"description": "# NOMAD: Non-Matching Audio Distance\n\nNOMAD is a perceptual similarity metric for non-matching reference speech quality assessment. NOMAD embeddings can be used to:\n* Measuring quality with any clean reference e.g., both paired and unpaired speech\n* As a loss function to improve speech enhancement models\n\n## Table of contents\n- [NOMAD: Non-Matching Audio Distance](#non-matching-audio-distance--nomad-)\n * [Installation](#installation)\n * [Using NOMAD similarity score](#using-nomad-similarity-score)\n + [Using NOMAD from the command line](#using-nomad-from-the-command-line)\n + [Using NOMAD inside Python](#using-nomad-inside-python)\n * [Using NOMAD loss function](#using-nomad-loss-function)\n + [NOMAD loss weighting](#nomad-loss-weighting)\n * [Training](#training)\n + [Package dependencies](#package-dependencies)\n + [Dataset generation](#dataset-generation)\n + [Training the model](#training-the-model)\n * [Performance](#performance)\n * [Paper and license](#paper-and-license)\n\n## Installation\nNOMAD is hosted on PyPi. It can be installed in your Python environment with the following command\n```\npip install nomad_audio\n```\n\nThe model works with 16 kHz sampling rate. If your wav files have different sampling rates, automatic downsampling or upsampling is performed to use correctly the model.\n\nNOMAD was built with Python 3.9.16.\n\n## Using NOMAD similarity score\nData wav files can be passed in 2 modes:\n* In ```mode=='dir'```, you need to indicate two directories for the reference and the degraded .wav files. \n* In ```mode=='csv```, you need to indicated two csv for the reference and the degraded .wav files.\n\nReference files can be any clean speech.\n\n### Using NOMAD from the command line\n\nTo predict perceptual similarity of all .wav files between two directories:\n```\npython -m nomad_audio --mode dir --nmr /path/to/dir/non-matching-references --deg /path/to/dir/degraded\n```\n\nTo predict perceptual similarity of all .wav files between two csv files:\n```\npython -m nomad_audio --mode csv --nmr /path/to/csv/non-matching-references --deg /path/to/csv/degraded\n```\n\nBoth csv files should include a column ```filename``` with the absolute path for each wav file.\n\n\nIn both modes, the script will create two csv files in ```results-csv``` with date time format. \n* ```DD-MM-YYYY_hh-mm-ss_nomad_avg.csv``` includes the average NOMAD scores with respect to all the references in ```nmr_path``` \n* ```DD-MM-YYYY_hh-mm-ss_nomad_scores.csv``` includes pairwise scores between the degraded speech samples in ```test_path``` and the references in ```nmr_path```\n\nYou can choose where to save the csv files by setting ```results_path```.\n\nYou can run this example using some .wav files that are provided in the repo:\n```\npython -m nomad_audio --mode dir --nmr_path data/nmr-data --test_path data/test-data\n```\n\nThe resulting csv file ```DD-MM-YYYY_hh-mm-ss_nomad_avg.csv``` shows the mean computed using the 4 non-matching reference files:\n```\nTest File NOMAD\n445-123860-0012_NOISE_15 1.587\n6563-285357-0042_OPUS_64k 0.294\n``` \n\nThe other csv file ```DD-MM-YYYY_hh-mm-ss_nomad_scores.csv``` includes the pairwise scores between the degraded and the non-matching reference files:\n```\nTest File MJ60_10 FL67_01 FI53_04 MJ57_01\n445-123860-0012_NOISE_15 1.627 1.534 1.629 1.561\n6563-285357-0042_OPUS_64k 0.23 0.414 0.186 0.346\n```\n\n### Using NOMAD inside Python\nYou can import NOMAD as a module in Python. Here is an example:\n\n```{python}\nfrom nomad_audio import nomad \n\nnmr_path = 'data/nmr-data'\ntest_path = 'data/test-data'\n\nnomad_avg_scores, nomad_scores = nomad.predict('dir', nmr_path, test_path)\n```\n\n## Using NOMAD loss function\nNOMAD has been evaluated as a loss function to improve speech enhancement models. \n\nNOMAD loss can be used as a PyTorch loss function as follows:\n```{python}\nfrom nomad_audio import nomad \n\n# Here is your training loop where you calculate your loss\nloss = mse_loss(estimate, clean) + weight * nomad.forward(estimate, clean)\n```\n\nWe provide a full example on how to use NOMAD loss for speech enhancement using a wave U-Net architecture, see ```src/nomad_audio/nomad_loss_test.py```.\nIn this example we show that using NOMAD as an auxiliary loss you can get quality improvement:\n* MSE -> PESQ = 2.39\n* MSE + NOMAD loss -> PESQ = 2.60\n\n\nSteps to reproduce this experiment:\n* Download Valentini speech enhancement dataset [here](https://datashare.ed.ac.uk/handle/10283/2791)\n* In ```src/nomad_audio/se_config.yaml``` change the following parameters\n * ```noisy_train_dir``` path to noisy_trainset_28spk_wav\n * ```clean_train_dir``` path to clean_trainset_28spk_wav\n * ```noisy_valid_dir``` path to noisy_validset_28spk_wav\n * ```clean_valid_dir``` path to clean_validset_28spk_wav\n * ```noisy_test_dir``` path to noisy_testset_wav\n * ```clean_test_dir``` path to clean_testset_wav\n\nNotice that the Valentini dataset does not explicitly provide a validation partition. We created one by using speech samples from speakers ```p286``` and ```p287``` from the training set.\n\nSee the paper for more details on speech enhancement results using the model DEMUCS and evaluated with subjective listening tests.\n\n### NOMAD loss weighting\nWe recommend to tune the weight of the NOMAD loss. Paper results with the DEMUCS model has been done by setting the weight to `0.1`. \nThe U-Net model provided in this repo uses a weight equal to `0.001`.\n\n\n## Training\n\n### Package dependencies\nAfter cloning the repo you can either pip install nomad_audio as above or install the required packages from ```requirements.txt```. If you install the pip package you will also have the additional nomad_audio module which is not needed to train NOMAD but only for usage.\n\n### Dataset generation\nNOMAD is trained on degraded samples from the Librispeech dataset.\n\n[Download](https://zenodo.org/record/8380442/files/nomad_ls.tar.gz?download=1) the dataset to train the model.\n\nIn addition, we provide [instructions](data/nomad_dataset.md) to generate the dataset above. Notice that the process can be time-consuming, we recommend to download the dataset from the link.\n\n### Training the model\nThe following steps are required to train the model:\n1. Download wav2vec from this [link](https://dl.fbaipublicfiles.com/fairseq/wav2vec/wav2vec_small.pt) and save it into ```pt-models```. If you ran above ```pip install nomad_audio``` in your working directory you can skip this step.\n2. Change the following parameters in ```src/config/train_triplet.yaml```\n * ```root``` should be set to degraded Librispeech dataset path\n3. From the working directory run: \n```\npython main.py --config_file train_triplet.yaml\n``` \n\nThis will generate a path in your working directory ```out-models/train-triplet/dd-mm-yyyy_hh-mm-ss``` that includes the best model and the configuration parameters used to train this model.\n\n\n## Performance\nWe evaluated NOMAD for ranking degradation intensity, speech quality assessment, and as a loss function for speech enhancement.\nSee the paper for more details. \nAs clean non-matching references, we extracted 899 samples from the [TSP](https://www.mmsp.ece.mcgill.ca/Documents/Data/) speech database.\n\nHere we show the scatter plot between NOMAD scores (computed with unpaired speech) and MOS quality labels. For each database we mapped NOMAD scores to MOS using a third order polynomial. \nNotice that performances are reported without mapping in the paper.\n\n#### [Genspeech](https://arxiv.org/abs/2102.10449)\n\n\n#### [P23 EXP1](https://www.itu.int/ITU-T/recommendations/rec.aspx?id=4415&lang=en)\n\n\n#### [P23 EXP3](https://www.itu.int/ITU-T/recommendations/rec.aspx?id=4415&lang=en)\n\n\n## Paper and license\nIf you use NOMAD or the training corpus for your research, please cite this [pre-print](https://arxiv.org/abs/2309.16284).\n\nRagano, A., Skoglund, J. and Hines, A., 2023. NOMAD: Unsupervised Learning of Perceptual Embeddings for Speech Enhancement and Non-matching Reference Audio Quality Assessment. arXiv preprint arXiv:2309.16284.\n\nThe NOMAD code is licensed under MIT license.\n\nCopyright \u00a9 2023 Alessandro Ragano",
"bugtrack_url": null,
"license": "Copyright (c) 2018 The Python Packaging Authority Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.",
"summary": "Perceptual similarity embeddings for non-matching reference audio quality assessment and speech enhancement",
"version": "0.0.9",
"project_urls": {
"Homepage": "https://github.com/alessandroragano/nomad"
},
"split_keywords": [
"audio quality",
"speech enhancement",
"speech quality"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "79c9842e1295fda9b9c8904f671ac4a22164ce20bced8d8553c3fde2998451b3",
"md5": "d7595411f1f316d97b943bb0594c75ee",
"sha256": "f1471acd58632708c53af52def044674b6678b3cebd68b30b1840588867e0f20"
},
"downloads": -1,
"filename": "nomad_audio-0.0.9-py3-none-any.whl",
"has_sig": false,
"md5_digest": "d7595411f1f316d97b943bb0594c75ee",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.9",
"size": 13837,
"upload_time": "2023-10-09T13:36:31",
"upload_time_iso_8601": "2023-10-09T13:36:31.805928Z",
"url": "https://files.pythonhosted.org/packages/79/c9/842e1295fda9b9c8904f671ac4a22164ce20bced8d8553c3fde2998451b3/nomad_audio-0.0.9-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "7af9c4d30f5840a5ef8e7fb003b93d9bc9e2e8c0ce9c59550bd48ab04bb8a9fe",
"md5": "e209c15b687c58c9a5739d459b965710",
"sha256": "69127b4a4bf8b492742ebe202aed0d41f1b1880ba007ef41b87690e7079d06e5"
},
"downloads": -1,
"filename": "nomad_audio-0.0.9.tar.gz",
"has_sig": false,
"md5_digest": "e209c15b687c58c9a5739d459b965710",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.9",
"size": 1908944,
"upload_time": "2023-10-09T13:36:35",
"upload_time_iso_8601": "2023-10-09T13:36:35.762126Z",
"url": "https://files.pythonhosted.org/packages/7a/f9/c4d30f5840a5ef8e7fb003b93d9bc9e2e8c0ce9c59550bd48ab04bb8a9fe/nomad_audio-0.0.9.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-10-09 13:36:35",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "alessandroragano",
"github_project": "nomad",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"requirements": [],
"lcname": "nomad-audio"
}
