| Name | omnipy JSON |
| Version |
0.20.0
 JSON
JSON |
| download |
| home_page | https://fairtracks.net/fair/#fair-07-transformation |
| Summary | Omnipy is a high level Python library for type-driven data wrangling and scalable workflow orchestration (under development) |
| upload_time | 2025-01-06 23:08:25 |
| maintainer | Sveinung Gundersen |
| docs_url | None |
| author | Sveinung Gundersen |
| requires_python | <3.13,>=3.10 |
| license | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2023 Omnipy contributors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
| keywords |
data wrangling
metadata
workflows
etl
research data
prefect
pydantic
fair
ontologies
json
tabular
type-driven
orchestration
data models
universal
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
<style>
h1 {
display: none;
}
</style>

Omnipy is a high level Python library for type-driven data wrangling and scalable workflow
orchestration.
## Updates
- **June 22, 2024:** We're not very good at writing updates. Expect a larger update soon on an important
and potentially groundbreaking new feature of Omnipy: the capability of model objects to automatically
mimic behaviour of the modelled class – with the addition of snapshots and rollbacks.
So e.g. `Model[list[int]]()` is not just a run-time typesafe parser that continuously makes sure that the
elements in the list are, in fact, integers; the object can also be operated as a list using e.g.
`.append()`, `.insert()` and concatenation with the `+` operator; and furthermore: if you append an
unparseable element, say `"abc"` instead of `"123"`, it will roll back the contents to the previously
validated snapshot!
- **Feb 3, 2023:** Documentation of the Omnipy API is still sparse. However, for examples of running
code, please check out the [omnipy-examples repo](https://github.com/fairtracks/omnipy_examples).
- **Dec 22, 2022:** Omnipy is the new name of the Python package formerly known as uniFAIR.
_We are very grateful to Dr. Jamin Chen, who gracefully transferred ownership of the (mostly
unused) "omnipy" name in PyPI to us!__
## Generic functionality
_(NOTE: Read the
section [Transformation on the FAIRtracks.net website](https://fairtracks.net/fair/#fair-07-transformation)
for a more detailed and better formatted version of the following description!)_
Omnipy is designed primarily to simplify development and deployment of (meta)data transformation
processes in the context of FAIRification and data brokering efforts. However, the functionality is
very generic and can also be used to support research data (and metadata) transformations in a range
of fields and contexts beyond life science, including day-to-day research scenarios:
## Data wrangling in day-to-day research
Researchers in life science and other data-centric fields
often need to extract, manipulate and integrate data and/or metadata from different sources, such as
repositories, databases or flat files. Much research time is spent on trivial and not-so-trivial
details of such ["data wrangling"](https://en.wikipedia.org/wiki/Data_wrangling):
- reformat data structures
- clean up errors
- remove duplicate data
- map and integrate dataset fields
- etc.
General software for data wrangling and analysis, such as [Pandas](https://pandas.pydata.org/),
[R](https://www.r-project.org/) or [Frictionless](https://frictionlessdata.io/), are useful, but
researchers still regularly end up with hard-to-reuse scripts, often with manual steps.
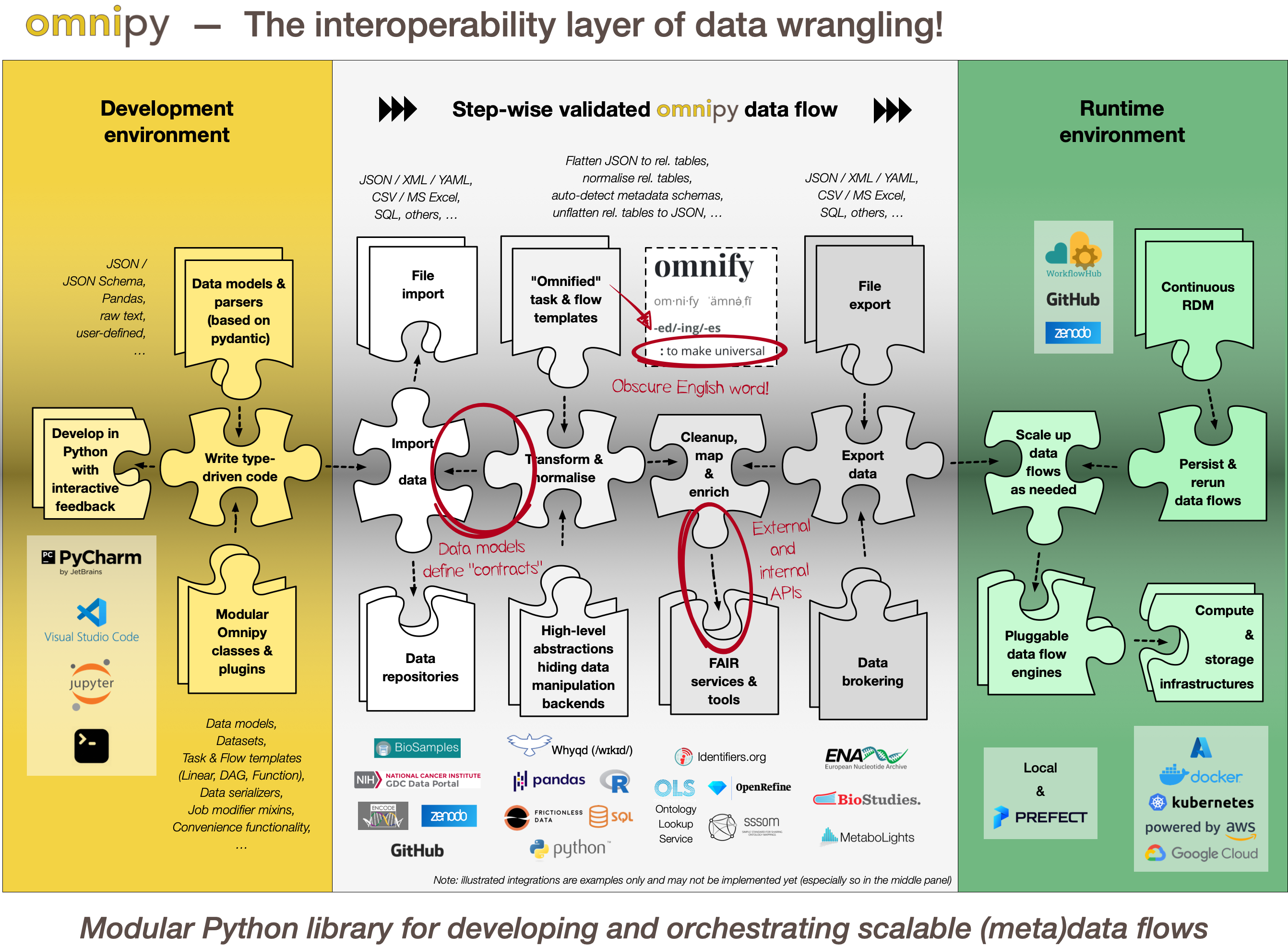
## Step-wise data model transformations
With the Omnipy Python package, researchers can import (meta)data in almost any shape or form:
_nested JSON; tabular
(relational) data; binary streams; or other data structures_. Through a step-by-step process, data
is continuously parsed and reshaped according to a series of data model transformations.
## "Parse, don't validate"
Omnipy follows the principles of "Type-driven design" (read
_Technical note #2: "Parse, don't validate"_ on the
[FAIRtracks.net website](https://fairtracks.net/fair/#fair-07-transformation) for more info). It
makes use of cutting-edge [Python type hints](https://peps.python.org/pep-0484/) and the popular
[pydantic](https://pydantic-docs.helpmanual.io/) package to "pour" data into precisely defined data
models that can range from very general (e.g. _"any kind of JSON data", "any kind of tabular data"_,
etc.) to very specific (e.g. _"follow the FAIRtracks JSON Schema for track files with the extra
restriction of only allowing BigBED files"_).
## Data types as contracts
Omnipy _tasks_ (single steps) or _flows_ (workflows) are defined as
transformations from specific _input_ data models to specific _output_ data models.
[pydantic](https://pydantic-docs.helpmanual.io/)-based parsing guarantees that the input and output
data always follows the data models (i.e. data types). Thus, the data models defines "contracts"
that simplifies reuse of tasks and flows in a _mix-and-match_ fashion.
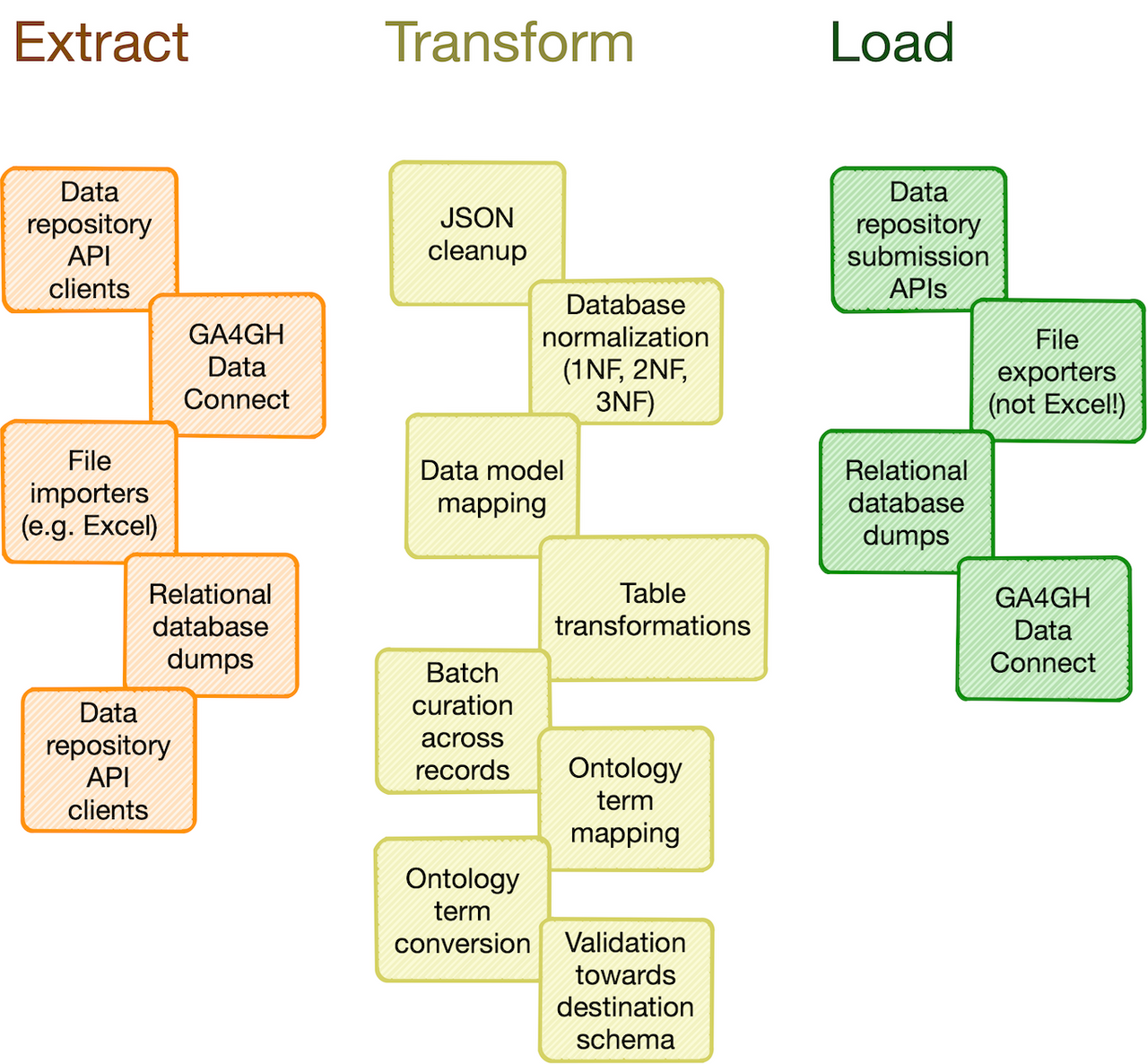
## Catalog of common processing steps
Omnipy is built from the ground up to be modular. We aim
to provide a catalog of commonly useful functionality ranging from:
- data import from REST API endpoints, common flat file formats, database dumps, etc.
- flattening of complex, nested JSON structures
- standardization of relational tabular data (i.e. removing redundancy)
- mapping of tabular data between schemas
- lookup and mapping of ontology terms
- semi-automatic data cleaning (through e.g. [Open Refine](https://openrefine.org/))
- support for common data manipulation software and libraries, such as
[Pandas](https://pandas.pydata.org/), [R](https://www.r-project.org/),
[Frictionless](https://frictionlessdata.io/), etc.
In particular, we will provide a _FAIRtracks_ module that contains data models and processing steps
to transform metadata to follow the [FAIRtracks standard](/standards/#standards-01-fairtracks).
## Refine and apply templates
An Omnipy module typically consists of a set of generic _task_ and
_flow templates_ with related data models, (de)serializers, and utility functions. The user can then
pick task and flow templates from this extensible, modular catalog, further refine them in the
context of a custom, use case-specific flow, and apply them to the desired compute engine to carry
out the transformations needed to wrangle data into the required shape.
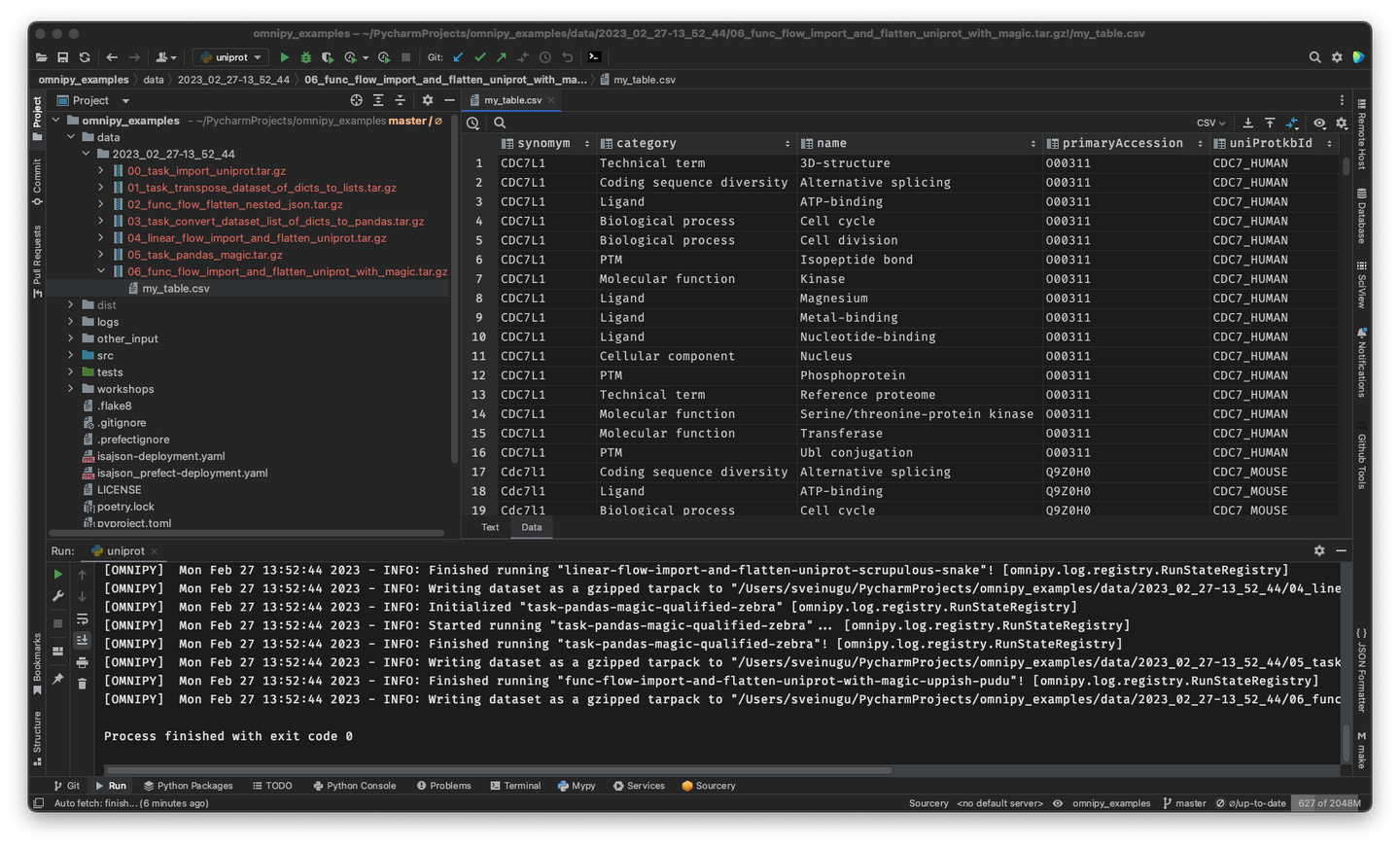
## Rerun only when needed
When piecing together a custom flow in Omnipy, the user has persistent
access to the state of the data at every step of the process. Persistent intermediate data allows
for caching of tasks based on the input data and parameters. Hence, if the input data and parameters
of a task does not change between runs, the task is not rerun. This is particularly useful for
importing from REST API endpoints, as a flow can be continuously rerun without taxing the remote
server; data import will only carried out in the initial iteration or when the REST API signals that
the data has changed.
## Scale up with external compute resources
In the case of large datasets, the researcher can set
up a flow based on a representative sample of the full dataset, in a size that is suited for running
locally on, say, a laptop. Once the flow has produced the correct output on the sample data, the
operation can be seamlessly scaled up to the full dataset and sent off in
[software containers](https://www.docker.com/resources/what-container/) to run on external compute
resources, using e.g. [Kubernetes](https://kubernetes.io/). Such offloaded flows
can be easily monitored using a web GUI.
## Industry-standard ETL backbone
Offloading of flows to external compute resources is provided by
the integration of Omnipy with a workflow engine based on the [Prefect](https://www.prefect.io/)
Python package. Prefect is an industry-leading platform for dataflow automation and orchestration
that brings a [series of powerful features](https://www.prefect.io/opensource/) to Omnipy:
- Predefined integrations with a range of compute infrastructure solutions
- Predefined integration with various services to support extraction, transformation, and loading
(ETL) of data and metadata
- Code as workflow ("If Python can write it, Prefect can run it")
- Dynamic workflows: no predefined Direct Acyclic Graphs (DAGs) needed!
- Command line and web GUI-based visibility and control of jobs
- Trigger jobs from external events such as GitHub commits, file uploads, etc.
- Define continuously running workflows that still respond to external events
- Run tasks concurrently through support for asynchronous tasks
## Pluggable workflow engines
It is also possible to integrate Omnipy with other workflow
backends by implementing new workflow engine plugins. This is relatively easy to do, as the core
architecture of Omnipy allows the user to easily switch the workflow engine at runtime. Omnipy
supports both traditional DAG-based and the more _avant garde_ code-based definition of flows. Two
workflow engines are currently supported: _local_ and _prefect_.
Raw data
{
"_id": null,
"home_page": "https://fairtracks.net/fair/#fair-07-transformation",
"name": "omnipy",
"maintainer": "Sveinung Gundersen",
"docs_url": null,
"requires_python": "<3.13,>=3.10",
"maintainer_email": null,
"keywords": "data wrangling, metadata, workflows, etl, research data, prefect, pydantic, FAIR, ontologies, JSON, tabular, type-driven, orchestration, data models, universal",
"author": "Sveinung Gundersen",
"author_email": null,
"download_url": "https://files.pythonhosted.org/packages/cf/81/c344b7691797ab8d469e862edfd89b3b714b06d59d44e5a81f2afcb4a160/omnipy-0.20.0.tar.gz",
"platform": null,
"description": "<style>\n h1 {\n display: none;\n }\n</style>\n\n\nOmnipy is a high level Python library for type-driven data wrangling and scalable workflow\norchestration.\n\n\n\n## Updates\n\n- **June 22, 2024:** We're not very good at writing updates. Expect a larger update soon on an important \n and potentially groundbreaking new feature of Omnipy: the capability of model objects to automatically \n mimic behaviour of the modelled class \u2013 with the addition of snapshots and rollbacks.\n So e.g. `Model[list[int]]()` is not just a run-time typesafe parser that continuously makes sure that the \n elements in the list are, in fact, integers; the object can also be operated as a list using e.g. \n `.append()`, `.insert()` and concatenation with the `+` operator; and furthermore: if you append an\n unparseable element, say `\"abc\"` instead of `\"123\"`, it will roll back the contents to the previously \n validated snapshot!\n- **Feb 3, 2023:** Documentation of the Omnipy API is still sparse. However, for examples of running\n code, please check out the [omnipy-examples repo](https://github.com/fairtracks/omnipy_examples).\n- **Dec 22, 2022:** Omnipy is the new name of the Python package formerly known as uniFAIR.\n _We are very grateful to Dr. Jamin Chen, who gracefully transferred ownership of the (mostly \n unused) \"omnipy\" name in PyPI to us!__\n\n## Generic functionality\n\n_(NOTE: Read the\nsection [Transformation on the FAIRtracks.net website](https://fairtracks.net/fair/#fair-07-transformation)\nfor a more detailed and better formatted version of the following description!)_\n\nOmnipy is designed primarily to simplify development and deployment of (meta)data transformation\nprocesses in the context of FAIRification and data brokering efforts. However, the functionality is\nvery generic and can also be used to support research data (and metadata) transformations in a range\nof fields and contexts beyond life science, including day-to-day research scenarios:\n\n## Data wrangling in day-to-day research\n\nResearchers in life science and other data-centric fields\noften need to extract, manipulate and integrate data and/or metadata from different sources, such as\nrepositories, databases or flat files. Much research time is spent on trivial and not-so-trivial\ndetails of such [\"data wrangling\"](https://en.wikipedia.org/wiki/Data_wrangling):\n\n- reformat data structures\n- clean up errors\n- remove duplicate data\n- map and integrate dataset fields\n- etc.\n\nGeneral software for data wrangling and analysis, such as [Pandas](https://pandas.pydata.org/),\n[R](https://www.r-project.org/) or [Frictionless](https://frictionlessdata.io/), are useful, but\nresearchers still regularly end up with hard-to-reuse scripts, often with manual steps.\n\n## Step-wise data model transformations\n\nWith the Omnipy Python package, researchers can import (meta)data in almost any shape or form:\n_nested JSON; tabular\n(relational) data; binary streams; or other data structures_. Through a step-by-step process, data\nis continuously parsed and reshaped according to a series of data model transformations.\n\n## \"Parse, don't validate\"\n\nOmnipy follows the principles of \"Type-driven design\" (read\n_Technical note #2: \"Parse, don't validate\"_ on the\n[FAIRtracks.net website](https://fairtracks.net/fair/#fair-07-transformation) for more info). It\nmakes use of cutting-edge [Python type hints](https://peps.python.org/pep-0484/) and the popular\n[pydantic](https://pydantic-docs.helpmanual.io/) package to \"pour\" data into precisely defined data\nmodels that can range from very general (e.g. _\"any kind of JSON data\", \"any kind of tabular data\"_,\netc.) to very specific (e.g. _\"follow the FAIRtracks JSON Schema for track files with the extra\nrestriction of only allowing BigBED files\"_).\n\n## Data types as contracts\n\nOmnipy _tasks_ (single steps) or _flows_ (workflows) are defined as\ntransformations from specific _input_ data models to specific _output_ data models.\n[pydantic](https://pydantic-docs.helpmanual.io/)-based parsing guarantees that the input and output\ndata always follows the data models (i.e. data types). Thus, the data models defines \"contracts\"\nthat simplifies reuse of tasks and flows in a _mix-and-match_ fashion.\n\n## Catalog of common processing steps\n\nOmnipy is built from the ground up to be modular. We aim\nto provide a catalog of commonly useful functionality ranging from:\n\n- data import from REST API endpoints, common flat file formats, database dumps, etc.\n- flattening of complex, nested JSON structures\n- standardization of relational tabular data (i.e. removing redundancy)\n- mapping of tabular data between schemas\n- lookup and mapping of ontology terms\n- semi-automatic data cleaning (through e.g. [Open Refine](https://openrefine.org/))\n- support for common data manipulation software and libraries, such as\n [Pandas](https://pandas.pydata.org/), [R](https://www.r-project.org/),\n [Frictionless](https://frictionlessdata.io/), etc.\n\nIn particular, we will provide a _FAIRtracks_ module that contains data models and processing steps\nto transform metadata to follow the [FAIRtracks standard](/standards/#standards-01-fairtracks).\n\n\n\n## Refine and apply templates\n\nAn Omnipy module typically consists of a set of generic _task_ and\n_flow templates_ with related data models, (de)serializers, and utility functions. The user can then\npick task and flow templates from this extensible, modular catalog, further refine them in the\ncontext of a custom, use case-specific flow, and apply them to the desired compute engine to carry\nout the transformations needed to wrangle data into the required shape.\n\n## Rerun only when needed\n\nWhen piecing together a custom flow in Omnipy, the user has persistent\naccess to the state of the data at every step of the process. Persistent intermediate data allows\nfor caching of tasks based on the input data and parameters. Hence, if the input data and parameters\nof a task does not change between runs, the task is not rerun. This is particularly useful for\nimporting from REST API endpoints, as a flow can be continuously rerun without taxing the remote\nserver; data import will only carried out in the initial iteration or when the REST API signals that\nthe data has changed.\n\n## Scale up with external compute resources\n\nIn the case of large datasets, the researcher can set\nup a flow based on a representative sample of the full dataset, in a size that is suited for running\nlocally on, say, a laptop. Once the flow has produced the correct output on the sample data, the\noperation can be seamlessly scaled up to the full dataset and sent off in\n[software containers](https://www.docker.com/resources/what-container/) to run on external compute\nresources, using e.g. [Kubernetes](https://kubernetes.io/). Such offloaded flows\ncan be easily monitored using a web GUI.\n\n\n\n## Industry-standard ETL backbone\n\nOffloading of flows to external compute resources is provided by\nthe integration of Omnipy with a workflow engine based on the [Prefect](https://www.prefect.io/)\nPython package. Prefect is an industry-leading platform for dataflow automation and orchestration\nthat brings a [series of powerful features](https://www.prefect.io/opensource/) to Omnipy:\n\n- Predefined integrations with a range of compute infrastructure solutions\n- Predefined integration with various services to support extraction, transformation, and loading\n (ETL) of data and metadata\n- Code as workflow (\"If Python can write it, Prefect can run it\")\n- Dynamic workflows: no predefined Direct Acyclic Graphs (DAGs) needed!\n- Command line and web GUI-based visibility and control of jobs\n- Trigger jobs from external events such as GitHub commits, file uploads, etc.\n- Define continuously running workflows that still respond to external events\n- Run tasks concurrently through support for asynchronous tasks\n\n\n\n## Pluggable workflow engines\n\nIt is also possible to integrate Omnipy with other workflow\nbackends by implementing new workflow engine plugins. This is relatively easy to do, as the core\narchitecture of Omnipy allows the user to easily switch the workflow engine at runtime. Omnipy\nsupports both traditional DAG-based and the more _avant garde_ code-based definition of flows. Two\nworkflow engines are currently supported: _local_ and _prefect_.\n",
"bugtrack_url": null,
"license": " Apache License\n Version 2.0, January 2004\n http://www.apache.org/licenses/\n\n TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION\n\n 1. Definitions.\n\n \"License\" shall mean the terms and conditions for use, reproduction,\n and distribution as defined by Sections 1 through 9 of this document.\n\n \"Licensor\" shall mean the copyright owner or entity authorized by\n the copyright owner that is granting the License.\n\n \"Legal Entity\" shall mean the union of the acting entity and all\n other entities that control, are controlled by, or are under common\n control with that entity. For the purposes of this definition,\n \"control\" means (i) the power, direct or indirect, to cause the\n direction or management of such entity, whether by contract or\n otherwise, or (ii) ownership of fifty percent (50%) or more of the\n outstanding shares, or (iii) beneficial ownership of such entity.\n\n \"You\" (or \"Your\") shall mean an individual or Legal Entity\n exercising permissions granted by this License.\n\n \"Source\" form shall mean the preferred form for making modifications,\n including but not limited to software source code, documentation\n source, and configuration files.\n\n \"Object\" form shall mean any form resulting from mechanical\n transformation or translation of a Source form, including but\n not limited to compiled object code, generated documentation,\n and conversions to other media types.\n\n \"Work\" shall mean the work of authorship, whether in Source or\n Object form, made available under the License, as indicated by a\n copyright notice that is included in or attached to the work\n (an example is provided in the Appendix below).\n\n \"Derivative Works\" shall mean any work, whether in Source or Object\n form, that is based on (or derived from) the Work and for which the\n editorial revisions, annotations, elaborations, or other modifications\n represent, as a whole, an original work of authorship. For the purposes\n of this License, Derivative Works shall not include works that remain\n separable from, or merely link (or bind by name) to the interfaces of,\n the Work and Derivative Works thereof.\n\n \"Contribution\" shall mean any work of authorship, including\n the original version of the Work and any modifications or additions\n to that Work or Derivative Works thereof, that is intentionally\n submitted to Licensor for inclusion in the Work by the copyright owner\n or by an individual or Legal Entity authorized to submit on behalf of\n the copyright owner. For the purposes of this definition, \"submitted\"\n means any form of electronic, verbal, or written communication sent\n to the Licensor or its representatives, including but not limited to\n communication on electronic mailing lists, source code control systems,\n and issue tracking systems that are managed by, or on behalf of, the\n Licensor for the purpose of discussing and improving the Work, but\n excluding communication that is conspicuously marked or otherwise\n designated in writing by the copyright owner as \"Not a Contribution.\"\n\n \"Contributor\" shall mean Licensor and any individual or Legal Entity\n on behalf of whom a Contribution has been received by Licensor and\n subsequently incorporated within the Work.\n\n 2. Grant of Copyright License. Subject to the terms and conditions of\n this License, each Contributor hereby grants to You a perpetual,\n worldwide, non-exclusive, no-charge, royalty-free, irrevocable\n copyright license to reproduce, prepare Derivative Works of,\n publicly display, publicly perform, sublicense, and distribute the\n Work and such Derivative Works in Source or Object form.\n\n 3. Grant of Patent License. Subject to the terms and conditions of\n this License, each Contributor hereby grants to You a perpetual,\n worldwide, non-exclusive, no-charge, royalty-free, irrevocable\n (except as stated in this section) patent license to make, have made,\n use, offer to sell, sell, import, and otherwise transfer the Work,\n where such license applies only to those patent claims licensable\n by such Contributor that are necessarily infringed by their\n Contribution(s) alone or by combination of their Contribution(s)\n with the Work to which such Contribution(s) was submitted. If You\n institute patent litigation against any entity (including a\n cross-claim or counterclaim in a lawsuit) alleging that the Work\n or a Contribution incorporated within the Work constitutes direct\n or contributory patent infringement, then any patent licenses\n granted to You under this License for that Work shall terminate\n as of the date such litigation is filed.\n\n 4. Redistribution. You may reproduce and distribute copies of the\n Work or Derivative Works thereof in any medium, with or without\n modifications, and in Source or Object form, provided that You\n meet the following conditions:\n\n (a) You must give any other recipients of the Work or\n Derivative Works a copy of this License; and\n\n (b) You must cause any modified files to carry prominent notices\n stating that You changed the files; and\n\n (c) You must retain, in the Source form of any Derivative Works\n that You distribute, all copyright, patent, trademark, and\n attribution notices from the Source form of the Work,\n excluding those notices that do not pertain to any part of\n the Derivative Works; and\n\n (d) If the Work includes a \"NOTICE\" text file as part of its\n distribution, then any Derivative Works that You distribute must\n include a readable copy of the attribution notices contained\n within such NOTICE file, excluding those notices that do not\n pertain to any part of the Derivative Works, in at least one\n of the following places: within a NOTICE text file distributed\n as part of the Derivative Works; within the Source form or\n documentation, if provided along with the Derivative Works; or,\n within a display generated by the Derivative Works, if and\n wherever such third-party notices normally appear. The contents\n of the NOTICE file are for informational purposes only and\n do not modify the License. You may add Your own attribution\n notices within Derivative Works that You distribute, alongside\n or as an addendum to the NOTICE text from the Work, provided\n that such additional attribution notices cannot be construed\n as modifying the License.\n\n You may add Your own copyright statement to Your modifications and\n may provide additional or different license terms and conditions\n for use, reproduction, or distribution of Your modifications, or\n for any such Derivative Works as a whole, provided Your use,\n reproduction, and distribution of the Work otherwise complies with\n the conditions stated in this License.\n\n 5. Submission of Contributions. Unless You explicitly state otherwise,\n any Contribution intentionally submitted for inclusion in the Work\n by You to the Licensor shall be under the terms and conditions of\n this License, without any additional terms or conditions.\n Notwithstanding the above, nothing herein shall supersede or modify\n the terms of any separate license agreement you may have executed\n with Licensor regarding such Contributions.\n\n 6. Trademarks. This License does not grant permission to use the trade\n names, trademarks, service marks, or product names of the Licensor,\n except as required for reasonable and customary use in describing the\n origin of the Work and reproducing the content of the NOTICE file.\n\n 7. Disclaimer of Warranty. Unless required by applicable law or\n agreed to in writing, Licensor provides the Work (and each\n Contributor provides its Contributions) on an \"AS IS\" BASIS,\n WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n implied, including, without limitation, any warranties or conditions\n of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A\n PARTICULAR PURPOSE. You are solely responsible for determining the\n appropriateness of using or redistributing the Work and assume any\n risks associated with Your exercise of permissions under this License.\n\n 8. Limitation of Liability. In no event and under no legal theory,\n whether in tort (including negligence), contract, or otherwise,\n unless required by applicable law (such as deliberate and grossly\n negligent acts) or agreed to in writing, shall any Contributor be\n liable to You for damages, including any direct, indirect, special,\n incidental, or consequential damages of any character arising as a\n result of this License or out of the use or inability to use the\n Work (including but not limited to damages for loss of goodwill,\n work stoppage, computer failure or malfunction, or any and all\n other commercial damages or losses), even if such Contributor\n has been advised of the possibility of such damages.\n\n 9. Accepting Warranty or Additional Liability. While redistributing\n the Work or Derivative Works thereof, You may choose to offer,\n and charge a fee for, acceptance of support, warranty, indemnity,\n or other liability obligations and/or rights consistent with this\n License. However, in accepting such obligations, You may act only\n on Your own behalf and on Your sole responsibility, not on behalf\n of any other Contributor, and only if You agree to indemnify,\n defend, and hold each Contributor harmless for any liability\n incurred by, or claims asserted against, such Contributor by reason\n of your accepting any such warranty or additional liability.\n\n END OF TERMS AND CONDITIONS\n\n APPENDIX: How to apply the Apache License to your work.\n\n To apply the Apache License to your work, attach the following\n boilerplate notice, with the fields enclosed by brackets \"[]\"\n replaced with your own identifying information. (Don't include\n the brackets!) The text should be enclosed in the appropriate\n comment syntax for the file format. We also recommend that a\n file or class name and description of purpose be included on the\n same \"printed page\" as the copyright notice for easier\n identification within third-party archives.\n\n Copyright 2023 Omnipy contributors\n\n Licensed under the Apache License, Version 2.0 (the \"License\");\n you may not use this file except in compliance with the License.\n You may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\n Unless required by applicable law or agreed to in writing, software\n distributed under the License is distributed on an \"AS IS\" BASIS,\n WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n See the License for the specific language governing permissions and\n limitations under the License.\n",
"summary": "Omnipy is a high level Python library for type-driven data wrangling and scalable workflow orchestration (under development)",
"version": "0.20.0",
"project_urls": {
"Documentation": "http://omnipy.readthedocs.io/",
"Homepage": "https://fairtracks.net/fair/#fair-07-transformation",
"releasenotes": "https://omnipy.readthedocs.io/en/latest/release_notes/",
"source": "http://github.com/fairtracks/omnipy"
},
"split_keywords": [
"data wrangling",
" metadata",
" workflows",
" etl",
" research data",
" prefect",
" pydantic",
" fair",
" ontologies",
" json",
" tabular",
" type-driven",
" orchestration",
" data models",
" universal"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "4cbaea802220efd8626949a0730adb0a026b3dafafb9a7364cc1d46e61539e04",
"md5": "79cefea0a6bd0b0f1d423b42e9a9510c",
"sha256": "1846d46a66667ce66c6dffb44b981218162d5c8c66ff595df5f393a73d152040"
},
"downloads": -1,
"filename": "omnipy-0.20.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "79cefea0a6bd0b0f1d423b42e9a9510c",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": "<3.13,>=3.10",
"size": 172996,
"upload_time": "2025-01-06T23:08:22",
"upload_time_iso_8601": "2025-01-06T23:08:22.800828Z",
"url": "https://files.pythonhosted.org/packages/4c/ba/ea802220efd8626949a0730adb0a026b3dafafb9a7364cc1d46e61539e04/omnipy-0.20.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "cf81c344b7691797ab8d469e862edfd89b3b714b06d59d44e5a81f2afcb4a160",
"md5": "e1238706defe4ca74f7ca17db5aebe1a",
"sha256": "ff131458830c809983ed89eaff5832a515616611221d7595c7f4d82fe2e915c5"
},
"downloads": -1,
"filename": "omnipy-0.20.0.tar.gz",
"has_sig": false,
"md5_digest": "e1238706defe4ca74f7ca17db5aebe1a",
"packagetype": "sdist",
"python_version": "source",
"requires_python": "<3.13,>=3.10",
"size": 121131,
"upload_time": "2025-01-06T23:08:25",
"upload_time_iso_8601": "2025-01-06T23:08:25.970952Z",
"url": "https://files.pythonhosted.org/packages/cf/81/c344b7691797ab8d469e862edfd89b3b714b06d59d44e5a81f2afcb4a160/omnipy-0.20.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-01-06 23:08:25",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "fairtracks",
"github_project": "omnipy",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "omnipy"
}
