| Name | par-scrape JSON |
| Version |
0.8.1
 JSON
JSON |
| download |
| home_page | None |
| Summary | A versatile web scraping tool with options for Selenium or Playwright, featuring OpenAI-powered data extraction and formatting. |
| upload_time | 2025-10-25 04:18:53 |
| maintainer | None |
| docs_url | None |
| author | None |
| requires_python | >=3.11 |
| license | MIT License
Copyright (c) 2024 Paul Robello
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. |
| keywords |
anthropic
data extraction
groq
llamacpp
ollama
openai
openrouter
playwright
selenium
web scraping
xai
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# PAR Scrape
[](https://pypi.org/project/par_scrape/)
[](https://pypi.org/project/par_scrape/)




PAR Scrape is a versatile web scraping tool with options for Selenium or Playwright, featuring AI-powered data extraction and formatting.
[](https://buymeacoffee.com/probello3)
## Screenshots
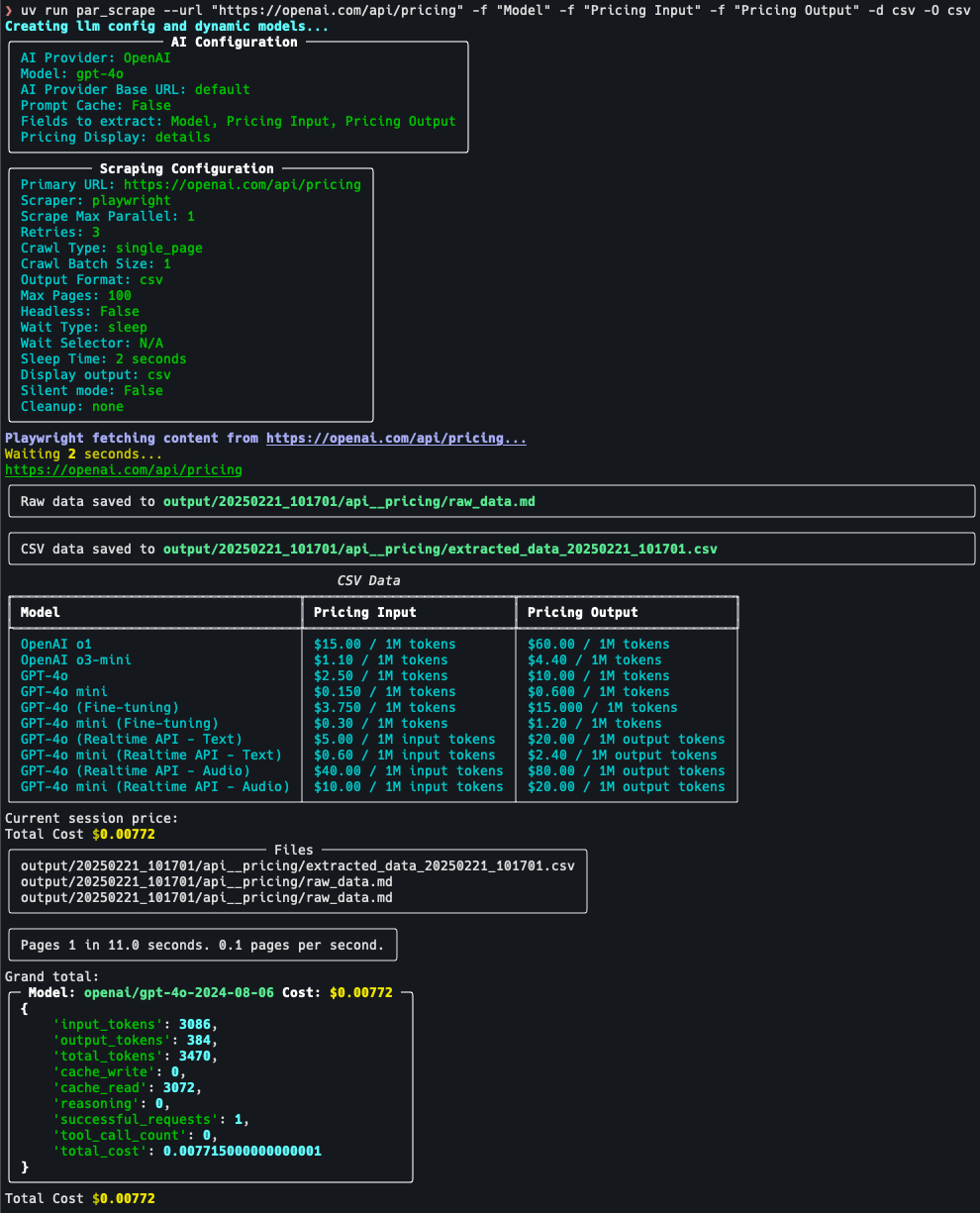
## Features
- Web scraping using Playwright or Selenium
- AI-powered data extraction and formatting
- Can be used to crawl and extract clean markdown without AI
- Supports multiple output formats (JSON, Excel, CSV, Markdown)
- Customizable field extraction
- Token usage and cost estimation
- Prompt cache for Anthropic provider
- Uses my [PAR AI Core](https://github.com/paulrobello/par_ai_core)
## Known Issues
- Selenium silent mode on windows still shows message about websocket. There is no simple way to get rid of this.
- Providers other than OpenAI are hit-and-miss depending on provider / model / data being extracted.
## Prompt Cache
- OpenAI will auto cache prompts that are over 1024 tokens.
- Anthropic will only cache prompts if you specify the --prompt-cache flag. Due to cache writes costing more only enable this if you intend to run multiple scrape jobs against the same url, also the cache will go stale within a couple of minutes so to reduce cost run your jobs as close together as possible.
## How it works
- Data is fetch from the site using either Selenium or Playwright
- HTML is converted to clean markdown
- If you specify an output format other than markdown then the following kicks in:
- A pydantic model is constructed from the fields you specify
- The markdown is sent to the AI provider with the pydantic model as the the required output
- The structured output is saved in the specified formats
- If crawling mode is enabled this process is repeated for each page in the queue until the specified max number of pages is reached
## Site Crawling
Crawling currently comes in 3 modes:
- Single page which is the default
- Single level which will crawl all links on the first page and add them to the queue. Links from any pages after the first are not added to the queue
- Domain which will crawl all links on all pages as long as they below to the same top level domain (TLD).
- Paginated will be added soon
Crawling progress is stored in a sqlite database and all pages are tagged with the run name which can be specified with the --run-name / -n flag.
You can resume a crawl by specifying the same run name again.
The options `--scrape-max-parallel` / `-P` can be used to increase the scraping speed by running multiple scrapes in parallel.
The options `--crawl-batch-size` / `-b` should be set at least as high as the scrape max parallel option to ensure that the queue is always full.
The options `--crawl-max-pages` / `-M` can be used to limit the total number of pages crawled in a single run.
## Prerequisites
To install PAR Scrape, make sure you have Python 3.11 or higher. Python 3.13 is the default and recommended version (supports Python 3.11-3.13).
### [uv](https://pypi.org/project/uv/) is recommended
#### Linux and Mac
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
#### Windows
```bash
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
## Installation
### Installation From Source
Then, follow these steps:
1. Clone the repository:
```bash
git clone https://github.com/paulrobello/par_scrape.git
cd par_scrape
```
2. Install the package dependencies using uv:
```bash
uv sync
```
### Installation From PyPI
To install PAR Scrape from PyPI, run any of the following commands:
```bash
uv tool install par_scrape
```
```bash
pipx install par_scrape
```
### Playwright Installation
To use playwright as a scraper, you must install it and its browsers using the following commands:
```bash
uv tool install playwright
playwright install chromium
```
## Usage
To use PAR Scrape, you can run it from the command line with various options. Here's a basic example:
Ensure you have the AI provider api key in your environment.
You can also store your api keys in the file `~/.par_scrape.env` as follows:
```shell
# AI API KEYS
OPENAI_API_KEY=
ANTHROPIC_API_KEY=
GROQ_API_KEY=
XAI_API_KEY=
GOOGLE_API_KEY=
MISTRAL_API_KEY=
GITHUB_TOKEN=
OPENROUTER_API_KEY=
DEEPSEEK_API_KEY=
# Used by Bedrock
AWS_PROFILE=
AWS_ACCESS_KEY_ID=
AWS_SECRET_ACCESS_KEY=
### Tracing (optional)
LANGCHAIN_TRACING_V2=false
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_API_KEY=
LANGCHAIN_PROJECT=par_scrape
```
### AI API KEYS
* ANTHROPIC_API_KEY is required for Anthropic. Get a key from https://console.anthropic.com/
* OPENAI_API_KEY is required for OpenAI. Get a key from https://platform.openai.com/account/api-keys
* GITHUB_TOKEN is required for GitHub Models. Get a free key from https://github.com/marketplace/models
* GOOGLE_API_KEY is required for Google Models. Get a free key from https://console.cloud.google.com
* XAI_API_KEY is required for XAI. Get a free key from https://x.ai/api
* GROQ_API_KEY is required for Groq. Get a free key from https://console.groq.com/
* MISTRAL_API_KEY is required for Mistral. Get a free key from https://console.mistral.ai/
* OPENROUTER_KEY is required for OpenRouter. Get a key from https://openrouter.ai/
* DEEPSEEK_API_KEY is required for Deepseek. Get a key from https://platform.deepseek.com/
* AWS_PROFILE or AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY are used for Bedrock authentication. The environment must
already be authenticated with AWS.
* No key required to use with Ollama, LlamaCpp, LiteLLM.
### Open AI Compatible Providers
If a specify provider is not listed but has an OpenAI compatible endpoint you can use the following combo of vars:
* PARAI_AI_PROVIDER=OpenAI
* PARAI_MODEL=Your selected model
* PARAI_AI_BASE_URL=The providers OpenAI endpoint URL
### Running from source
```bash
uv run par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" -f "Cache Price" --model gpt-4o-mini --display-output md
```
### Running if installed from PyPI
```bash
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" -f "Cache Price" --model gpt-4o-mini --display-output md
```
### Options
```
--url -u TEXT URL to scrape [default: https://openai.com/api/pricing/]
--output-format -O [md|json|csv|excel] Output format for the scraped data [default: md]
--fields -f TEXT Fields to extract from the webpage
[default: Model, Pricing Input, Pricing Output, Cache Price]
--scraper -s [selenium|playwright] Scraper to use: 'selenium' or 'playwright' [default: playwright]
--retries -r INTEGER Retry attempts for failed scrapes [default: 3]
--scrape-max-parallel -P INTEGER Max parallel fetch requests [default: 1]
--wait-type -w [none|pause|sleep|idle|selector|text] Method to use for page content load waiting [default: sleep]
--wait-selector -i TEXT Selector or text to use for page content load waiting. [default: None]
--headless -h Run in headless mode (for Selenium)
--sleep-time -t INTEGER Time to sleep before scrolling (in seconds) [default: 2]
--ai-provider -a [Ollama|LlamaCpp|OpenRouter|OpenAI|Gemini|Github|XAI|Anthropic|
Groq|Mistral|Deepseek|LiteLLM|Bedrock] AI provider to use for processing [default: OpenAI]
--model -m TEXT AI model to use for processing. If not specified, a default model will be used. [default: None]
--ai-base-url -b TEXT Override the base URL for the AI provider. [default: None]
--prompt-cache Enable prompt cache for Anthropic provider
--reasoning-effort [low|medium|high] Reasoning effort level to use for o1 and o3 models. [default: None]
--reasoning-budget INTEGER Maximum context size for reasoning. [default: None]
--display-output -d [none|plain|md|csv|json] Display output in terminal (md, csv, or json) [default: None]
--output-folder -o PATH Specify the location of the output folder [default: output]
--silent -q Run in silent mode, suppressing output
--run-name -n TEXT Specify a name for this run. Can be used to resume a crawl Defaults to YYYYmmdd_HHMMSS
--pricing -p [none|price|details] Enable pricing summary display [default: details]
--cleanup -c [none|before|after|both] How to handle cleanup of output folder [default: none]
--extraction-prompt -e PATH Path to the extraction prompt file [default: None]
--crawl-type -C [single_page|single_level|domain] Enable crawling mode [default: single_page]
--crawl-max-pages -M INTEGER Maximum number of pages to crawl this session [default: 100]
--crawl-batch-size -B INTEGER Maximum number of pages to load from the queue at once [default: 1]
--respect-rate-limits Whether to use domain-specific rate limiting [default: True]
--respect-robots Whether to respect robots.txt
--crawl-delay INTEGER Default delay in seconds between requests to the same domain [default: 1]
--version -v
--help Show this message and exit.
```
### Examples
* Basic usage with default options:
```bash
par_scrape --url "https://openai.com/api/pricing/" -f "Model" -f "Pricing Input" -f "Pricing Output" -O json -O csv --pricing details --display-output csv
```
* Using Playwright, displaying JSON output and waiting for text gpt-4o to be in page before continuing:
```bash
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --scraper playwright -O json -O csv -d json --pricing details -w text -i gpt-4o
```
* Specifying a custom model and output folder:
```bash
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --model gpt-4 --output-folder ./custom_output -O json -O csv --pricing details -w text -i gpt-4o
```
* Running in silent mode with a custom run name:
```bash
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --silent --run-name my_custom_run --pricing details -O json -O csv -w text -i gpt-4o
```
* Using the cleanup option to remove the output folder after scraping:
```bash
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --cleanup --pricing details -O json -O csv
```
* Using the pause option to wait for user input before scrolling:
```bash
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --pause --pricing details -O json -O csv
```
* Using Anthropic provider with prompt cache enabled and detailed pricing breakdown:
```bash
par_scrape -a Anthropic --prompt-cache -d csv -p details -f "Title" -f "Description" -f "Price" -f "Cache Price" -O json -O csv
```
* Crawling single level and only outputting markdown (No LLM or cost):
```bash
par_scrape --url "https://openai.com/api/pricing/" -O md --crawl-batch-size 5 --scrape-max-parallel 5 --crawl-type single_level
```
## Roadmap
- API Server
- More crawling options
- Paginated Listing crawling
## Whats New
- Version 0.8.1
- Updated dependencies (ruff 0.14.2, pyright 1.1.407)
- Ensured compatibility with Python 3.13 (now the default version)
- Maintains backward compatibility with Python 3.11 and 3.12
- Version 0.8.0
- Update deps and ci/cd workflows
- Version 0.7.1
- Updated par-ai-core and other deps
- Version 0.7.0
- Major overhaul and fixing of crawling features.
- added --respect-robots flag to check robots.txt before scraping
- added --respect-rate-limits to respect rate limits for domains
- added --reasoning-effort and --reasoning-budget for o1/o3 and Sonnet 3.7
- updated dependencies
- Version 0.6.1
- Updated ai-core
- Version 0.6.0
- Fixed bug where images were being striped from markdown output
- Now uses par_ai_core for url fetching and markdown conversion
- New Features:
- BREAKING CHANGES:
- New option to specify desired output formats `-O` which defaults to markdown only, which does not require AI
- BEHAVIOR CHANGES:
- Now retries 3 times on failed scrapes
- Basic site crawling
- Retry failed fetches
- HTTP authentication
- Proxy settings
- Updated system prompt for better results
- Version 0.5.1
- Update ai-core and dependencies
- Now supports Deepseek, XAI and LiteLLM
- Better pricing data
- Version 0.5.0
- Update ai-core and dependencies
- Now supports OpenRouter
- Version 0.4.9
- Updated to use new par-ai-core
- Now supports LlamaCPP and XAI Grok
- Better cost tracking
- Updated pricing data
- Better error handling
- Now supports Python 3.10
- Version 0.4.8:
- Added Anthropic prompt cache option.
- Version 0.4.7:
- BREAKING CHANGE: --pricing cli option now takes a string value of 'details', 'cost', or 'none'.
- Added pool of user agents that gets randomly pulled from.
- Updating pricing data.
- Pricing token capture and compute now much more accurate.
- Version 0.4.6:
- Minor bug fixes.
- Updating pricing data.
- Added support for Amazon Bedrock
- Removed some unnecessary dependencies.
- Code cleanup.
- Version 0.4.5:
- Added new option --wait-type that allows you to specify the type of wait to use such as pause, sleep, idle, text or selector.
- Removed --pause option as it is no longer needed with --wait-type option.
- Playwright scraping now honors the headless mode.
- Playwright is now the default scraper as it is much faster.
- Version 0.4.4:
- Better Playwright scraping.
- Version 0.4.3:
- Added option to override the base URL for the AI provider.
- Version 0.4.2:
- The url parameter can now point to a local rawData_*.md file for easier testing of different models without having to re-fetch the data.
- Added ability to specify file with extraction prompt.
- Tweaked extraction prompt to work with Groq and Anthropic. Google still does not work.
- Remove need for ~/.par-scrape-config.json
- Version 0.4.1:
- Minor bug fixes for pricing summary.
- Default model for google changed to "gemini-1.5-pro-exp-0827" which is free and usually works well.
- Version 0.4.0:
- Added support for Anthropic, Google, Groq, and Ollama. (Not well tested with any providers other than OpenAI)
- Add flag for displaying pricing summary. Defaults to False.
- Added pricing data for Anthropic.
- Better error handling for llm calls.
- Updated cleanup flag to handle both before and after cleanup. Removed --remove-output-folder flag.
- Version 0.3.1:
- Add pause and sleep-time options to control the browser and scraping delays.
- Default headless mode to False so you can interact with the browser.
- Version 0.3.0:
- Fixed location of config.json file.
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## Author
Paul Robello - probello@gmail.com
Raw data
{
"_id": null,
"home_page": null,
"name": "par-scrape",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.11",
"maintainer_email": "Paul Robello <probello@gmail.com>",
"keywords": "anthropic, data extraction, groq, llamacpp, ollama, openai, openrouter, playwright, selenium, web scraping, xai",
"author": null,
"author_email": "Paul Robello <probello@gmail.com>",
"download_url": "https://files.pythonhosted.org/packages/aa/8c/5c0ebac9896311ba04c7398e330edf8552f647729432c387d6f4e4062214/par_scrape-0.8.1.tar.gz",
"platform": null,
"description": "# PAR Scrape\n\n[](https://pypi.org/project/par_scrape/)\n[](https://pypi.org/project/par_scrape/) \n\n \n\n\n\n\nPAR Scrape is a versatile web scraping tool with options for Selenium or Playwright, featuring AI-powered data extraction and formatting.\n\n[](https://buymeacoffee.com/probello3)\n\n## Screenshots\n\n\n## Features\n\n- Web scraping using Playwright or Selenium\n- AI-powered data extraction and formatting\n- Can be used to crawl and extract clean markdown without AI\n- Supports multiple output formats (JSON, Excel, CSV, Markdown)\n- Customizable field extraction\n- Token usage and cost estimation\n- Prompt cache for Anthropic provider\n- Uses my [PAR AI Core](https://github.com/paulrobello/par_ai_core)\n\n\n## Known Issues\n- Selenium silent mode on windows still shows message about websocket. There is no simple way to get rid of this.\n- Providers other than OpenAI are hit-and-miss depending on provider / model / data being extracted.\n\n## Prompt Cache\n- OpenAI will auto cache prompts that are over 1024 tokens.\n- Anthropic will only cache prompts if you specify the --prompt-cache flag. Due to cache writes costing more only enable this if you intend to run multiple scrape jobs against the same url, also the cache will go stale within a couple of minutes so to reduce cost run your jobs as close together as possible.\n\n## How it works\n- Data is fetch from the site using either Selenium or Playwright\n- HTML is converted to clean markdown\n- If you specify an output format other than markdown then the following kicks in:\n - A pydantic model is constructed from the fields you specify\n - The markdown is sent to the AI provider with the pydantic model as the the required output\n - The structured output is saved in the specified formats\n- If crawling mode is enabled this process is repeated for each page in the queue until the specified max number of pages is reached\n\n## Site Crawling\n\nCrawling currently comes in 3 modes:\n- Single page which is the default\n- Single level which will crawl all links on the first page and add them to the queue. Links from any pages after the first are not added to the queue\n- Domain which will crawl all links on all pages as long as they below to the same top level domain (TLD).\n- Paginated will be added soon\n\nCrawling progress is stored in a sqlite database and all pages are tagged with the run name which can be specified with the --run-name / -n flag. \nYou can resume a crawl by specifying the same run name again. \nThe options `--scrape-max-parallel` / `-P` can be used to increase the scraping speed by running multiple scrapes in parallel. \nThe options `--crawl-batch-size` / `-b` should be set at least as high as the scrape max parallel option to ensure that the queue is always full.\nThe options `--crawl-max-pages` / `-M` can be used to limit the total number of pages crawled in a single run.\n\n## Prerequisites\n\nTo install PAR Scrape, make sure you have Python 3.11 or higher. Python 3.13 is the default and recommended version (supports Python 3.11-3.13).\n\n### [uv](https://pypi.org/project/uv/) is recommended\n\n#### Linux and Mac\n```bash\ncurl -LsSf https://astral.sh/uv/install.sh | sh\n```\n\n#### Windows\n```bash\npowershell -ExecutionPolicy ByPass -c \"irm https://astral.sh/uv/install.ps1 | iex\"\n```\n\n## Installation\n\n\n### Installation From Source\n\nThen, follow these steps:\n\n1. Clone the repository:\n ```bash\n git clone https://github.com/paulrobello/par_scrape.git\n cd par_scrape\n ```\n\n2. Install the package dependencies using uv:\n ```bash\n uv sync\n ```\n### Installation From PyPI\n\nTo install PAR Scrape from PyPI, run any of the following commands:\n\n```bash\nuv tool install par_scrape\n```\n\n```bash\npipx install par_scrape\n```\n### Playwright Installation\nTo use playwright as a scraper, you must install it and its browsers using the following commands:\n\n```bash\nuv tool install playwright\nplaywright install chromium\n```\n\n## Usage\n\nTo use PAR Scrape, you can run it from the command line with various options. Here's a basic example:\nEnsure you have the AI provider api key in your environment.\nYou can also store your api keys in the file `~/.par_scrape.env` as follows:\n```shell\n# AI API KEYS\nOPENAI_API_KEY=\nANTHROPIC_API_KEY=\nGROQ_API_KEY=\nXAI_API_KEY=\nGOOGLE_API_KEY=\nMISTRAL_API_KEY=\nGITHUB_TOKEN=\nOPENROUTER_API_KEY=\nDEEPSEEK_API_KEY=\n# Used by Bedrock\nAWS_PROFILE=\nAWS_ACCESS_KEY_ID=\nAWS_SECRET_ACCESS_KEY=\n\n\n\n### Tracing (optional)\nLANGCHAIN_TRACING_V2=false\nLANGCHAIN_ENDPOINT=https://api.smith.langchain.com\nLANGCHAIN_API_KEY=\nLANGCHAIN_PROJECT=par_scrape\n```\n\n### AI API KEYS\n\n* ANTHROPIC_API_KEY is required for Anthropic. Get a key from https://console.anthropic.com/\n* OPENAI_API_KEY is required for OpenAI. Get a key from https://platform.openai.com/account/api-keys\n* GITHUB_TOKEN is required for GitHub Models. Get a free key from https://github.com/marketplace/models\n* GOOGLE_API_KEY is required for Google Models. Get a free key from https://console.cloud.google.com\n* XAI_API_KEY is required for XAI. Get a free key from https://x.ai/api\n* GROQ_API_KEY is required for Groq. Get a free key from https://console.groq.com/\n* MISTRAL_API_KEY is required for Mistral. Get a free key from https://console.mistral.ai/\n* OPENROUTER_KEY is required for OpenRouter. Get a key from https://openrouter.ai/\n* DEEPSEEK_API_KEY is required for Deepseek. Get a key from https://platform.deepseek.com/\n* AWS_PROFILE or AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY are used for Bedrock authentication. The environment must\n already be authenticated with AWS.\n* No key required to use with Ollama, LlamaCpp, LiteLLM.\n\n\n### Open AI Compatible Providers\n\nIf a specify provider is not listed but has an OpenAI compatible endpoint you can use the following combo of vars:\n* PARAI_AI_PROVIDER=OpenAI\n* PARAI_MODEL=Your selected model\n* PARAI_AI_BASE_URL=The providers OpenAI endpoint URL\n\n### Running from source\n```bash\nuv run par_scrape --url \"https://openai.com/api/pricing/\" -f \"Title\" -f \"Description\" -f \"Price\" -f \"Cache Price\" --model gpt-4o-mini --display-output md\n```\n\n### Running if installed from PyPI\n```bash\npar_scrape --url \"https://openai.com/api/pricing/\" -f \"Title\" -f \"Description\" -f \"Price\" -f \"Cache Price\" --model gpt-4o-mini --display-output md\n```\n\n### Options\n```\n--url -u TEXT URL to scrape [default: https://openai.com/api/pricing/]\n--output-format -O [md|json|csv|excel] Output format for the scraped data [default: md]\n--fields -f TEXT Fields to extract from the webpage\n [default: Model, Pricing Input, Pricing Output, Cache Price]\n--scraper -s [selenium|playwright] Scraper to use: 'selenium' or 'playwright' [default: playwright]\n--retries -r INTEGER Retry attempts for failed scrapes [default: 3]\n--scrape-max-parallel -P INTEGER Max parallel fetch requests [default: 1]\n--wait-type -w [none|pause|sleep|idle|selector|text] Method to use for page content load waiting [default: sleep]\n--wait-selector -i TEXT Selector or text to use for page content load waiting. [default: None]\n--headless -h Run in headless mode (for Selenium)\n--sleep-time -t INTEGER Time to sleep before scrolling (in seconds) [default: 2]\n--ai-provider -a [Ollama|LlamaCpp|OpenRouter|OpenAI|Gemini|Github|XAI|Anthropic|\n Groq|Mistral|Deepseek|LiteLLM|Bedrock] AI provider to use for processing [default: OpenAI]\n--model -m TEXT AI model to use for processing. If not specified, a default model will be used. [default: None]\n--ai-base-url -b TEXT Override the base URL for the AI provider. [default: None]\n--prompt-cache Enable prompt cache for Anthropic provider\n--reasoning-effort [low|medium|high] Reasoning effort level to use for o1 and o3 models. [default: None]\n--reasoning-budget INTEGER Maximum context size for reasoning. [default: None]\n--display-output -d [none|plain|md|csv|json] Display output in terminal (md, csv, or json) [default: None]\n--output-folder -o PATH Specify the location of the output folder [default: output]\n--silent -q Run in silent mode, suppressing output\n--run-name -n TEXT Specify a name for this run. Can be used to resume a crawl Defaults to YYYYmmdd_HHMMSS\n--pricing -p [none|price|details] Enable pricing summary display [default: details]\n--cleanup -c [none|before|after|both] How to handle cleanup of output folder [default: none]\n--extraction-prompt -e PATH Path to the extraction prompt file [default: None]\n--crawl-type -C [single_page|single_level|domain] Enable crawling mode [default: single_page]\n--crawl-max-pages -M INTEGER Maximum number of pages to crawl this session [default: 100]\n--crawl-batch-size -B INTEGER Maximum number of pages to load from the queue at once [default: 1]\n--respect-rate-limits Whether to use domain-specific rate limiting [default: True]\n--respect-robots Whether to respect robots.txt\n--crawl-delay INTEGER Default delay in seconds between requests to the same domain [default: 1]\n--version -v\n--help Show this message and exit.\n```\n\n### Examples\n\n* Basic usage with default options:\n```bash\npar_scrape --url \"https://openai.com/api/pricing/\" -f \"Model\" -f \"Pricing Input\" -f \"Pricing Output\" -O json -O csv --pricing details --display-output csv\n```\n* Using Playwright, displaying JSON output and waiting for text gpt-4o to be in page before continuing:\n```bash\npar_scrape --url \"https://openai.com/api/pricing/\" -f \"Title\" -f \"Description\" -f \"Price\" --scraper playwright -O json -O csv -d json --pricing details -w text -i gpt-4o\n```\n* Specifying a custom model and output folder:\n```bash\npar_scrape --url \"https://openai.com/api/pricing/\" -f \"Title\" -f \"Description\" -f \"Price\" --model gpt-4 --output-folder ./custom_output -O json -O csv --pricing details -w text -i gpt-4o\n```\n* Running in silent mode with a custom run name:\n```bash\npar_scrape --url \"https://openai.com/api/pricing/\" -f \"Title\" -f \"Description\" -f \"Price\" --silent --run-name my_custom_run --pricing details -O json -O csv -w text -i gpt-4o\n```\n* Using the cleanup option to remove the output folder after scraping:\n```bash\npar_scrape --url \"https://openai.com/api/pricing/\" -f \"Title\" -f \"Description\" -f \"Price\" --cleanup --pricing details -O json -O csv\n```\n* Using the pause option to wait for user input before scrolling:\n```bash\npar_scrape --url \"https://openai.com/api/pricing/\" -f \"Title\" -f \"Description\" -f \"Price\" --pause --pricing details -O json -O csv\n```\n* Using Anthropic provider with prompt cache enabled and detailed pricing breakdown:\n```bash\npar_scrape -a Anthropic --prompt-cache -d csv -p details -f \"Title\" -f \"Description\" -f \"Price\" -f \"Cache Price\" -O json -O csv\n```\n\n* Crawling single level and only outputting markdown (No LLM or cost):\n```bash\npar_scrape --url \"https://openai.com/api/pricing/\" -O md --crawl-batch-size 5 --scrape-max-parallel 5 --crawl-type single_level\n```\n\n\n## Roadmap\n- API Server\n- More crawling options\n - Paginated Listing crawling\n\n\n## Whats New\n- Version 0.8.1\n - Updated dependencies (ruff 0.14.2, pyright 1.1.407)\n - Ensured compatibility with Python 3.13 (now the default version)\n - Maintains backward compatibility with Python 3.11 and 3.12\n- Version 0.8.0\n - Update deps and ci/cd workflows\n- Version 0.7.1\n - Updated par-ai-core and other deps\n- Version 0.7.0\n - Major overhaul and fixing of crawling features.\n - added --respect-robots flag to check robots.txt before scraping\n - added --respect-rate-limits to respect rate limits for domains\n - added --reasoning-effort and --reasoning-budget for o1/o3 and Sonnet 3.7\n - updated dependencies\n- Version 0.6.1\n - Updated ai-core\n- Version 0.6.0\n - Fixed bug where images were being striped from markdown output\n - Now uses par_ai_core for url fetching and markdown conversion\n - New Features:\n - BREAKING CHANGES:\n - New option to specify desired output formats `-O` which defaults to markdown only, which does not require AI\n - BEHAVIOR CHANGES:\n - Now retries 3 times on failed scrapes\n - Basic site crawling\n - Retry failed fetches\n - HTTP authentication\n - Proxy settings\n - Updated system prompt for better results\n- Version 0.5.1\n - Update ai-core and dependencies\n - Now supports Deepseek, XAI and LiteLLM\n - Better pricing data\n- Version 0.5.0\n - Update ai-core and dependencies\n - Now supports OpenRouter\n- Version 0.4.9\n - Updated to use new par-ai-core\n - Now supports LlamaCPP and XAI Grok\n - Better cost tracking\n - Updated pricing data\n - Better error handling\n - Now supports Python 3.10\n- Version 0.4.8:\n - Added Anthropic prompt cache option.\n- Version 0.4.7:\n - BREAKING CHANGE: --pricing cli option now takes a string value of 'details', 'cost', or 'none'.\n - Added pool of user agents that gets randomly pulled from.\n - Updating pricing data.\n - Pricing token capture and compute now much more accurate.\n- Version 0.4.6:\n - Minor bug fixes.\n - Updating pricing data.\n - Added support for Amazon Bedrock\n - Removed some unnecessary dependencies.\n - Code cleanup.\n- Version 0.4.5:\n - Added new option --wait-type that allows you to specify the type of wait to use such as pause, sleep, idle, text or selector.\n - Removed --pause option as it is no longer needed with --wait-type option.\n - Playwright scraping now honors the headless mode.\n - Playwright is now the default scraper as it is much faster.\n- Version 0.4.4:\n - Better Playwright scraping.\n- Version 0.4.3:\n - Added option to override the base URL for the AI provider.\n- Version 0.4.2:\n - The url parameter can now point to a local rawData_*.md file for easier testing of different models without having to re-fetch the data.\n - Added ability to specify file with extraction prompt.\n - Tweaked extraction prompt to work with Groq and Anthropic. Google still does not work.\n - Remove need for ~/.par-scrape-config.json\n- Version 0.4.1:\n - Minor bug fixes for pricing summary.\n - Default model for google changed to \"gemini-1.5-pro-exp-0827\" which is free and usually works well.\n- Version 0.4.0:\n - Added support for Anthropic, Google, Groq, and Ollama. (Not well tested with any providers other than OpenAI)\n - Add flag for displaying pricing summary. Defaults to False.\n - Added pricing data for Anthropic.\n - Better error handling for llm calls.\n - Updated cleanup flag to handle both before and after cleanup. Removed --remove-output-folder flag.\n- Version 0.3.1:\n - Add pause and sleep-time options to control the browser and scraping delays.\n - Default headless mode to False so you can interact with the browser.\n- Version 0.3.0:\n - Fixed location of config.json file.\n\n## Contributing\n\nContributions are welcome! Please feel free to submit a Pull Request.\n\n## License\n\nThis project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.\n\n## Author\n\nPaul Robello - probello@gmail.com\n",
"bugtrack_url": null,
"license": "MIT License\n \n Copyright (c) 2024 Paul Robello\n \n Permission is hereby granted, free of charge, to any person obtaining a copy\n of this software and associated documentation files (the \"Software\"), to deal\n in the Software without restriction, including without limitation the rights\n to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n copies of the Software, and to permit persons to whom the Software is\n furnished to do so, subject to the following conditions:\n \n The above copyright notice and this permission notice shall be included in all\n copies or substantial portions of the Software.\n \n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n SOFTWARE.",
"summary": "A versatile web scraping tool with options for Selenium or Playwright, featuring OpenAI-powered data extraction and formatting.",
"version": "0.8.1",
"project_urls": {
"Discussions": "https://github.com/paulrobello/par_scrape/discussions",
"Documentation": "https://github.com/paulrobello/par_scrape/blob/main/README.md",
"Homepage": "https://github.com/paulrobello/par_scrape",
"Issues": "https://github.com/paulrobello/par_scrape/issues",
"Repository": "https://github.com/paulrobello/par_scrape",
"Wiki": "https://github.com/paulrobello/par_scrape/wiki"
},
"split_keywords": [
"anthropic",
" data extraction",
" groq",
" llamacpp",
" ollama",
" openai",
" openrouter",
" playwright",
" selenium",
" web scraping",
" xai"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "95e4a51db5fc16ce06597606c23f14e861580abcf8d2e25d24ad33fd01556e8f",
"md5": "7c533b99f83674d0b1e40b0c4e6d61eb",
"sha256": "96c172fdc48785b7e2986101548128e085ed846b5ddeb10b0e30fc33d870dd43"
},
"downloads": -1,
"filename": "par_scrape-0.8.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "7c533b99f83674d0b1e40b0c4e6d61eb",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.11",
"size": 26341,
"upload_time": "2025-10-25T04:18:51",
"upload_time_iso_8601": "2025-10-25T04:18:51.588938Z",
"url": "https://files.pythonhosted.org/packages/95/e4/a51db5fc16ce06597606c23f14e861580abcf8d2e25d24ad33fd01556e8f/par_scrape-0.8.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "aa8c5c0ebac9896311ba04c7398e330edf8552f647729432c387d6f4e4062214",
"md5": "c4d949105c45fd588b420abce3998b40",
"sha256": "2fdbffc5322605a7fb1fdf98ddf66c910850e5f549206fbc4eba0109f9274d4c"
},
"downloads": -1,
"filename": "par_scrape-0.8.1.tar.gz",
"has_sig": false,
"md5_digest": "c4d949105c45fd588b420abce3998b40",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.11",
"size": 23772,
"upload_time": "2025-10-25T04:18:53",
"upload_time_iso_8601": "2025-10-25T04:18:53.095690Z",
"url": "https://files.pythonhosted.org/packages/aa/8c/5c0ebac9896311ba04c7398e330edf8552f647729432c387d6f4e4062214/par_scrape-0.8.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-10-25 04:18:53",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "paulrobello",
"github_project": "par_scrape",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "par-scrape"
}
