## Parallel-pandas
[](https://pypi.org/project/parallel-pandas/)
[](https://pypi.org/project/parallel-pandas/)
[](https://pypi.org/project/parallel-pandas/)
Makes it easy to parallelize your calculations in pandas on all your CPUs.
## Installation
```python
pip install --upgrade parallel-pandas
```
## Quickstart
```python
import pandas as pd
import numpy as np
from parallel_pandas import ParallelPandas
#initialize parallel-pandas
ParallelPandas.initialize(n_cpu=16, split_factor=4, disable_pr_bar=True)
# create big DataFrame
df = pd.DataFrame(np.random.random((1_000_000, 100)))
# calculate multiple quantiles. Pandas only uses one core of CPU
%%timeit
res = df.quantile(q=[.25, .5, .95], axis=1)
```
`3.66 s ± 31.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)`
```python
#p_quantile is parallel analogue of quantile methods. Can use all cores of your CPU.
%%timeit
res = df.p_quantile(q=[.25, .5, .95], axis=1)
```
`679 ms ± 10.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)`
As you can see the `p_quantile` method is **5 times faster**!
## Usage
Under the hood, **parallel-pandas** works very simply. The Dataframe or Series is split into chunks along the first or second axis. Then these chunks are passed to a pool of processes or threads where the desired method is executed on each part. At the end, the parts are concatenated to get the final result.
When initializing parallel-pandas you can specify the following options:
1. `n_cpu` - the number of cores of your CPU that you want to use (default `None` - use all cores of CPU)
2. `split_factor` - Affects the number of chunks into which the DataFrame/Series is split according to the formula `chunks_number = split_factor*n_cpu` (default 1).
3. `show_vmem` - Shows a progress bar with available RAM (default `False`)
4. `disable_pr_bar` - Disable the progress bar for parallel tasks (default `False`)
For example
```python
import pandas as pd
import numpy as np
from parallel_pandas import ParallelPandas
#initialize parallel-pandas
ParallelPandas.initialize(n_cpu=16, split_factor=4, disable_pr_bar=False)
# create big DataFrame
df = pd.DataFrame(np.random.random((1_000_000, 100)))
```

During initialization, we specified `split_factor=4` and `n_cpu = 16`, so the DataFrame will be split into 64 chunks (in the case of the `describe` method, axis = 1) and the progress bar shows the progress for each chunk
You can parallelize any expression with pandas Dataframe. For example, let's do a z-score normalization of columns in a dataframe. Let's look at the execution time and memory consumption. Compare with synchronous execution and with Dask.DataFrame
```python
import pandas as pd
import numpy as np
from parallel_pandas import ParallelPandas
import dask.dataframe as dd
from time import monotonic
#initialize parallel-pandas
ParallelPandas.initialize(n_cpu=16, split_factor=8, disable_pr_bar=True)
# create big DataFrame
df = pd.DataFrame(np.random.random((1_000_000, 1000)))
# create dask DataFrame
ddf = dd.from_pandas(df, npartitions=128)
start = monotonic()
res=(df-df.mean())/df.std()
print(f'synchronous z-score normalization time took: {monotonic()-start:.1f} s.')
```
```python
synchronous z-score normalization time took: 21.7 s.
```
```python
#parallel-pandas
start = monotonic()
res=(df-df.p_mean())/df.p_std()
print(f'parallel z-score normalization time took: {monotonic()-start:.1f} s.')
```
```python
parallel z-score normalization time took: 11.7 s.
```
```python
#dask dataframe
start = monotonic()
res=((ddf-ddf.mean())/ddf.std()).compute()
print(f'dask parallel z-score normalization time took: {monotonic()-start:.1f} s.')
```
```python
dask parallel z-score normalization time took: 12.5 s.
```
Pay attention to memory consumption. `parallel-pandas` and `dask` use almost half as much RAM as `pandas`
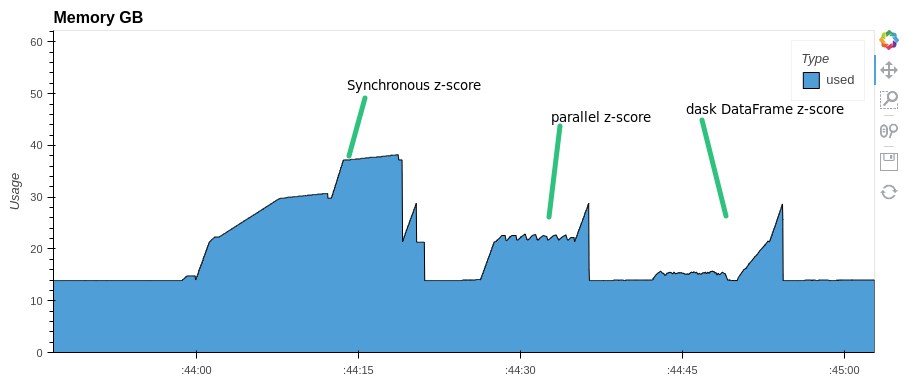
For some methods `parallel-pandas` is faster than `dask.DataFrame`:
```python
#dask
%%time
res = ddf.nunique().compute()
Wall time: 42.9 s
%%time
res = ddf.rolling(10).mean().compute()
Wall time: 19.1 s
#parallel-pandas
%%time
res = df.p_nunique()
Wall time: 12.9 s
%%time
res = df.rolling(10).p_mean()
Wall time: 12.5 s
```
## API
### Parallel counterparts for pandas Series methods
| methods | parallel analogue | executor |
|-------------------|---------------------|----------------------|
| pd.Series.apply() | pd.Series.p_apply() | threads / processes |
| pd.Series.map() | pd.Series.p_map() | threads / processes |
### Parallel counterparts for pandas SeriesGroupBy methods
| methods | parallel analogue | executor |
|--------------------------|----------------------------|-------------------------|
| pd.SeriesGroupBy.apply() | pd.SeriesGroupBy.p_apply() | threads / processes |
### Parallel counterparts for pandas Dataframe methods
| methods | parallel analogue | executor |
|----------------|-------------------|---------------------|
| df.mean() | df.p_mean() | threads |
| df.min() | df.p_min() | threads |
| df.max() | df.p_max() | threads |
| df.median() | df.p_max() | threads |
| df.kurt() | df.p_kurt() | threads |
| df.skew() | df.p_skew() | threads |
| df.sum() | df.p_sum() | threads |
| df.prod() | df.p_prod() | threads |
| df.var() | df.p_var() | threads |
| df.sem() | df.p_sem() | threads |
| df.std() | df.p_std() | threads |
| df.cummin() | df.p_cummin() | threads |
| df.cumsum() | df.p_cumsum() | threads |
| df.cummax() | df.p_cummax() | threads |
| df.cumprod() | df.p_cumprod() | threads |
| df.apply() | df.p_apply() | threads / processes |
| df.applymap() | df.p_applymap() | processes |
| df.replace() | df.p_replace() | threads |
| df.describe() | df.p_describe() | threads |
| df.nunique() | df.p_nunique() | threads / processes |
| df.mad() | df.p_mad() | threads |
| df.idxmin() | df.p_idxmin() | threads |
| df.idxmax() | df.p_idxmax() | threads |
| df.rank() | df.p_rank() | threads |
| df.mode() | df.p_mode() | threads/processes |
| df.agg() | df.p_agg() | threads/processes |
| df.aggregate() | df.p_aggregate() | threads/processes |
| df.quantile() | df.p_quantile() | threads/processes |
| df.corr() | df.p_corr() | threads/processes |
### Parallel counterparts for pandas DataframeGroupBy methods
| methods | parallel analogue | executor |
|--------------------------|----------------------------|----------------------|
| DataFrameGroupBy.apply() | DataFrameGroupBy.p_apply() | threads / processes |
### Parallel counterparts for pandas window methods
#### Rolling
| methods | parallel analogue | executor |
|------------------------------------|--------------------------------------|---------------------|
| pd.core.window.Rolling.apply() | pd.core.window.Rolling.p_apply() | threads / processes |
| pd.core.window.Rolling.min() | pd.core.window.Rolling.p_min() | threads / processes |
| pd.core.window.Rolling.max() | pd.core.window.Rolling.p_max() | threads / processes |
| pd.core.window.Rolling.mean() | pd.core.window.Rolling.p_mean() | threads / processes |
| pd.core.window.Rolling.sum() | pd.core.window.Rolling.p_sum() | threads / processes |
| pd.core.window.Rolling.var() | pd.core.window.Rolling.p_var() | threads / processes |
| pd.core.window.Rolling.sem() | pd.core.window.Rolling.p_sem() | threads / processes |
| pd.core.window.Rolling.skew() | pd.core.window.Rolling.p_skew() | threads / processes |
| pd.core.window.Rolling.kurt() | pd.core.window.Rolling.p_kurt() | threads / processes |
| pd.core.window.Rolling.median() | pd.core.window.Rolling.p_median() | threads / processes |
| pd.core.window.Rolling.quantile() | pd.core.window.Rolling.p_quantile() | threads / processes |
| pd.core.window.Rolling.rank() | pd.core.window.Rolling.p_rank() | threads / processes |
| pd.core.window.Rolling.agg() | pd.core.window.Rolling.p_agg() | threads / processes |
| pd.core.window.Rolling.aggregate() | pd.core.window.Rolling.p_aggregate() | threads / processes |
#### Window
| methods | parallel analogue | executor |
|-----------------------------------|-------------------------------------|---------------------|
| pd.core.window.Window.mean() | pd.core.window.Window.p_mean() | threads / processes |
| pd.core.window.Window.sum() | pd.core.window.Window.p_sum() | threads / processes |
| pd.core.window.Window.var() | pd.core.window.Window.p_var() | threads / processes |
| pd.core.window.Window.std() | pd.core.window.Window.p_std() | threads / processes |
#### RollingGroupby
| methods | parallel analogue | executor |
|-------------------------------------------|---------------------------------------------|---------------------|
| pd.core.window.RollingGroupby.apply() | pd.core.window.RollingGroupby.p_apply() | threads / processes |
| pd.core.window.RollingGroupby.min() | pd.core.window.RollingGroupby.p_min() | threads / processes |
| pd.core.window.RollingGroupby.max() | pd.core.window.RollingGroupby.p_max() | threads / processes |
| pd.core.window.RollingGroupby.mean() | pd.core.window.RollingGroupby.p_mean() | threads / processes |
| pd.core.window.RollingGroupby.sum() | pd.core.window.RollingGroupby.p_sum() | threads / processes |
| pd.core.window.RollingGroupby.var() | pd.core.window.RollingGroupby.p_var() | threads / processes |
| pd.core.window.RollingGroupby.sem() | pd.core.window.RollingGroupby.p_sem() | threads / processes |
| pd.core.window.RollingGroupby.skew() | pd.core.window.RollingGroupby.p_skew() | threads / processes |
| pd.core.window.RollingGroupby.kurt() | pd.core.window.RollingGroupby.p_kurt() | threads / processes |
| pd.core.window.RollingGroupby.median() | pd.core.window.RollingGroupby.p_median() | threads / processes |
| pd.core.window.RollingGroupby.quantile() | pd.core.window.RollingGroupby.p_quantile() | threads / processes |
| pd.core.window.RollingGroupby.rank() | pd.core.window.RollingGroupby.p_rank() | threads / processes |
| pd.core.window.RollingGroupby.agg() | pd.core.window.RollingGroupby.p_agg() | threads / processes |
| pd.core.window.RollingGroupby.aggregate() | pd.core.window.RollingGroupby.p_aggregate() | threads / processes |
#### Expanding
| methods | parallel analogue | executor |
|--------------------------------------|----------------------------------------|---------------------|
| pd.core.window.Expanding.apply() | pd.core.window.Expanding.p_apply() | threads / processes |
| pd.core.window.Expanding.min() | pd.core.window.Expanding.p_min() | threads / processes |
| pd.core.window.Expanding.max() | pd.core.window.Expanding.p_max() | threads / processes |
| pd.core.window.Expanding.mean() | pd.core.window.Expanding.p_mean() | threads / processes |
| pd.core.window.Expanding.sum() | pd.core.window.Expanding.p_sum() | threads / processes |
| pd.core.window.Expanding.var() | pd.core.window.Expanding.p_var() | threads / processes |
| pd.core.window.Expanding.sem() | pd.core.window.Expanding.p_sem() | threads / processes |
| pd.core.window.Expanding.skew() | pd.core.window.Expanding.p_skew() | threads / processes |
| pd.core.window.Expanding.kurt() | pd.core.window.Expanding.p_kurt() | threads / processes |
| pd.core.window.Expanding.median() | pd.core.window.Expanding.p_median() | threads / processes |
| pd.core.window.Expanding.quantile() | pd.core.window.Expanding.p_quantile() | threads / processes |
| pd.core.window.Expanding.rank() | pd.core.window.Expanding.p_rank() | threads / processes |
| pd.core.window.Expanding.agg() | pd.core.window.Expanding.p_agg() | threads / processes |
| pd.core.window.Expanding.aggregate() | pd.core.window.Expanding.p_aggregate() | threads / processes |
#### ExpandingGroupby
| methods | parallel analogue | executor |
|---------------------------------------------|-----------------------------------------------|---------------------|
| pd.core.window.ExpandingGroupby.apply() | pd.core.window.ExpandingGroupby.p_apply() | threads / processes |
| pd.core.window.ExpandingGroupby.min() | pd.core.window.ExpandingGroupby.p_min() | threads / processes |
| pd.core.window.ExpandingGroupby.max() | pd.core.window.ExpandingGroupby.p_max() | threads / processes |
| pd.core.window.ExpandingGroupby.mean() | pd.core.window.ExpandingGroupby.p_mean() | threads / processes |
| pd.core.window.ExpandingGroupby.sum() | pd.core.window.ExpandingGroupby.p_sum() | threads / processes |
| pd.core.window.ExpandingGroupby.var() | pd.core.window.ExpandingGroupby.p_var() | threads / processes |
| pd.core.window.ExpandingGroupby.sem() | pd.core.window.ExpandingGroupby.p_sem() | threads / processes |
| pd.core.window.ExpandingGroupby.skew() | pd.core.window.ExpandingGroupby.p_skew() | threads / processes |
| pd.core.window.ExpandingGroupby.kurt() | pd.core.window.ExpandingGroupby.p_kurt() | threads / processes |
| pd.core.window.ExpandingGroupby.median() | pd.core.window.ExpandingGroupby.p_median() | threads / processes |
| pd.core.window.ExpandingGroupby.quantile() | pd.core.window.ExpandingGroupby.p_quantile() | threads / processes |
| pd.core.window.ExpandingGroupby.rank() | pd.core.window.ExpandingGroupby.p_rank() | threads / processes |
| pd.core.window.ExpandingGroupby.agg() | pd.core.window.ExpandingGroupby.p_agg() | threads / processes |
| pd.core.window.ExpandingGroupby.aggregate() | pd.core.window.ExpandingGroupby.p_aggregate() | threads / processes |
### ExponentialMovingWindow
| methods | parallel analogue | executor |
|-----------------------------------------------|-------------------------------------------------|---------------------|
| pd.core.window.ExponentialMovingWindow.mean() | pd.core.window.ExponentialMovingWindow.p_mean() | threads / processes |
| pd.core.window.ExponentialMovingWindow.sum() | pd.core.window.ExponentialMovingWindow.p_sum() | threads / processes |
| pd.core.window.ExponentialMovingWindow.var() | pd.core.window.ExponentialMovingWindow.p_var() | threads / processes |
| pd.core.window.ExponentialMovingWindow.std() | pd.core.window.ExponentialMovingWindow.p_std() | threads / processes |
### ExponentialMovingWindowGroupby
| methods | parallel analogue | executor |
|------------------------------------------------------|--------------------------------------------------------|---------------------|
| pd.core.window.ExponentialMovingWindowGroupby.mean() | pd.core.window.ExponentialMovingWindowGroupby.p_mean() | threads / processes |
| pd.core.window.ExponentialMovingWindowGroupby.sum() | pd.core.window.ExponentialMovingWindowGroupby.p_sum() | threads / processes |
| pd.core.window.ExponentialMovingWindowGroupby.var() | pd.core.window.ExponentialMovingWindowGroupby.p_var() | threads / processes |
| pd.core.window.ExponentialMovingWindowGroupby.std() | pd.core.window.ExponentialMovingWindowGroupby.p_std() | threads / processes |
Raw data
{
"_id": null,
"home_page": "https://github.com/dubovikmaster/parallel-pandas",
"name": "parallel-pandas",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.7",
"maintainer_email": null,
"keywords": "parallel pandas, progress bar, parallel apply, parallel groupby, multiprocessing bar",
"author": "Dubovik Pavel",
"author_email": "geometryk@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/ab/0c/b32e50a5289aa18fd41086ad20557dca6a5ea16047887b24bb13d4383d69/parallel_pandas-0.6.5.tar.gz",
"platform": "any",
"description": "## Parallel-pandas\n\n[](https://pypi.org/project/parallel-pandas/)\n[](https://pypi.org/project/parallel-pandas/)\n[](https://pypi.org/project/parallel-pandas/)\n\n\nMakes it easy to parallelize your calculations in pandas on all your CPUs.\n\n## Installation\n\n```python\npip install --upgrade parallel-pandas\n```\n\n## Quickstart\n```python\nimport pandas as pd\nimport numpy as np\nfrom parallel_pandas import ParallelPandas\n\n#initialize parallel-pandas\nParallelPandas.initialize(n_cpu=16, split_factor=4, disable_pr_bar=True)\n\n# create big DataFrame\ndf = pd.DataFrame(np.random.random((1_000_000, 100)))\n\n# calculate multiple quantiles. Pandas only uses one core of CPU\n%%timeit\nres = df.quantile(q=[.25, .5, .95], axis=1)\n```\n`3.66 s \u00b1 31.6 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)`\n```python\n#p_quantile is parallel analogue of quantile methods. Can use all cores of your CPU.\n%%timeit\nres = df.p_quantile(q=[.25, .5, .95], axis=1)\n```\n`679 ms \u00b1 10.4 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)`\n\nAs you can see the `p_quantile` method is **5 times faster**!\n\n## Usage\n\nUnder the hood, **parallel-pandas** works very simply. The Dataframe or Series is split into chunks along the first or second axis. Then these chunks are passed to a pool of processes or threads where the desired method is executed on each part. At the end, the parts are concatenated to get the final result.\n\n\nWhen initializing parallel-pandas you can specify the following options:\n1. `n_cpu` - the number of cores of your CPU that you want to use (default `None` - use all cores of CPU)\n2. `split_factor` - Affects the number of chunks into which the DataFrame/Series is split according to the formula `chunks_number = split_factor*n_cpu` (default 1).\n3. `show_vmem` - Shows a progress bar with available RAM (default `False`)\n4. `disable_pr_bar` - Disable the progress bar for parallel tasks (default `False`)\n\nFor example\n\n```python\nimport pandas as pd\nimport numpy as np\nfrom parallel_pandas import ParallelPandas\n\n#initialize parallel-pandas\nParallelPandas.initialize(n_cpu=16, split_factor=4, disable_pr_bar=False)\n\n# create big DataFrame\ndf = pd.DataFrame(np.random.random((1_000_000, 100)))\n```\n\n\nDuring initialization, we specified `split_factor=4` and `n_cpu = 16`, so the DataFrame will be split into 64 chunks (in the case of the `describe` method, axis = 1) and the progress bar shows the progress for each chunk\n\nYou can parallelize any expression with pandas Dataframe. For example, let's do a z-score normalization of columns in a dataframe. Let's look at the execution time and memory consumption. Compare with synchronous execution and with Dask.DataFrame\n```python\nimport pandas as pd\nimport numpy as np\nfrom parallel_pandas import ParallelPandas\nimport dask.dataframe as dd\nfrom time import monotonic\n\n#initialize parallel-pandas\nParallelPandas.initialize(n_cpu=16, split_factor=8, disable_pr_bar=True)\n\n# create big DataFrame\ndf = pd.DataFrame(np.random.random((1_000_000, 1000)))\n\n# create dask DataFrame\nddf = dd.from_pandas(df, npartitions=128)\n\nstart = monotonic()\nres=(df-df.mean())/df.std()\nprint(f'synchronous z-score normalization time took: {monotonic()-start:.1f} s.')\n```\n```python\nsynchronous z-score normalization time took: 21.7 s.\n```\n```python\n#parallel-pandas\nstart = monotonic()\nres=(df-df.p_mean())/df.p_std()\nprint(f'parallel z-score normalization time took: {monotonic()-start:.1f} s.')\n```\n```python\nparallel z-score normalization time took: 11.7 s.\n```\n```python\n#dask dataframe\nstart = monotonic()\nres=((ddf-ddf.mean())/ddf.std()).compute()\nprint(f'dask parallel z-score normalization time took: {monotonic()-start:.1f} s.')\n```\n```python\ndask parallel z-score normalization time took: 12.5 s.\n```\n\nPay attention to memory consumption. `parallel-pandas` and `dask` use almost half as much RAM as `pandas`\n\n\n\nFor some methods `parallel-pandas` is faster than `dask.DataFrame`:\n```python\n#dask\n%%time\nres = ddf.nunique().compute()\nWall time: 42.9 s\n\n%%time\nres = ddf.rolling(10).mean().compute()\nWall time: 19.1 s\n\n#parallel-pandas\n%%time\nres = df.p_nunique()\nWall time: 12.9 s\n\n%%time\nres = df.rolling(10).p_mean()\nWall time: 12.5 s\n```\n\n## API\n\n### Parallel counterparts for pandas Series methods\n\n| methods | parallel analogue | executor |\n|-------------------|---------------------|----------------------|\n| pd.Series.apply() | pd.Series.p_apply() | threads / processes |\n| pd.Series.map() | pd.Series.p_map() | threads / processes |\n\n\n### Parallel counterparts for pandas SeriesGroupBy methods\n\n| methods | parallel analogue | executor |\n|--------------------------|----------------------------|-------------------------|\n| pd.SeriesGroupBy.apply() | pd.SeriesGroupBy.p_apply() | threads / processes |\n\n### Parallel counterparts for pandas Dataframe methods\n\n| methods | parallel analogue | executor |\n|----------------|-------------------|---------------------|\n| df.mean() | df.p_mean() | threads |\n| df.min() | df.p_min() | threads |\n| df.max() | df.p_max() | threads |\n| df.median() | df.p_max() | threads |\n| df.kurt() | df.p_kurt() | threads |\n| df.skew() | df.p_skew() | threads |\n| df.sum() | df.p_sum() | threads |\n| df.prod() | df.p_prod() | threads |\n| df.var() | df.p_var() | threads |\n| df.sem() | df.p_sem() | threads |\n| df.std() | df.p_std() | threads |\n| df.cummin() | df.p_cummin() | threads |\n| df.cumsum() | df.p_cumsum() | threads |\n| df.cummax() | df.p_cummax() | threads |\n| df.cumprod() | df.p_cumprod() | threads |\n| df.apply() | df.p_apply() | threads / processes |\n| df.applymap() | df.p_applymap() | processes |\n| df.replace() | df.p_replace() | threads |\n| df.describe() | df.p_describe() | threads |\n| df.nunique() | df.p_nunique() | threads / processes |\n| df.mad() | df.p_mad() | threads |\n| df.idxmin() | df.p_idxmin() | threads |\n| df.idxmax() | df.p_idxmax() | threads |\n| df.rank() | df.p_rank() | threads |\n| df.mode() | df.p_mode() | threads/processes |\n| df.agg() | df.p_agg() | threads/processes |\n| df.aggregate() | df.p_aggregate() | threads/processes |\n| df.quantile() | df.p_quantile() | threads/processes |\n| df.corr() | df.p_corr() | threads/processes |\n\n### Parallel counterparts for pandas DataframeGroupBy methods\n\n| methods | parallel analogue | executor |\n|--------------------------|----------------------------|----------------------|\n| DataFrameGroupBy.apply() | DataFrameGroupBy.p_apply() | threads / processes |\n\n### Parallel counterparts for pandas window methods\n\n#### Rolling\n\n| methods | parallel analogue | executor |\n|------------------------------------|--------------------------------------|---------------------|\n| pd.core.window.Rolling.apply() | pd.core.window.Rolling.p_apply() | threads / processes |\n| pd.core.window.Rolling.min() | pd.core.window.Rolling.p_min() | threads / processes |\n| pd.core.window.Rolling.max() | pd.core.window.Rolling.p_max() | threads / processes |\n| pd.core.window.Rolling.mean() | pd.core.window.Rolling.p_mean() | threads / processes |\n| pd.core.window.Rolling.sum() | pd.core.window.Rolling.p_sum() | threads / processes |\n| pd.core.window.Rolling.var() | pd.core.window.Rolling.p_var() | threads / processes |\n| pd.core.window.Rolling.sem() | pd.core.window.Rolling.p_sem() | threads / processes |\n| pd.core.window.Rolling.skew() | pd.core.window.Rolling.p_skew() | threads / processes |\n| pd.core.window.Rolling.kurt() | pd.core.window.Rolling.p_kurt() | threads / processes |\n| pd.core.window.Rolling.median() | pd.core.window.Rolling.p_median() | threads / processes |\n| pd.core.window.Rolling.quantile() | pd.core.window.Rolling.p_quantile() | threads / processes |\n| pd.core.window.Rolling.rank() | pd.core.window.Rolling.p_rank() | threads / processes |\n| pd.core.window.Rolling.agg() | pd.core.window.Rolling.p_agg() | threads / processes |\n| pd.core.window.Rolling.aggregate() | pd.core.window.Rolling.p_aggregate() | threads / processes |\n\n\n#### Window\n\n| methods | parallel analogue | executor |\n|-----------------------------------|-------------------------------------|---------------------|\n| pd.core.window.Window.mean() | pd.core.window.Window.p_mean() | threads / processes |\n| pd.core.window.Window.sum() | pd.core.window.Window.p_sum() | threads / processes |\n| pd.core.window.Window.var() | pd.core.window.Window.p_var() | threads / processes |\n| pd.core.window.Window.std() | pd.core.window.Window.p_std() | threads / processes |\n\n\n#### RollingGroupby\n\n| methods | parallel analogue | executor |\n|-------------------------------------------|---------------------------------------------|---------------------|\n| pd.core.window.RollingGroupby.apply() | pd.core.window.RollingGroupby.p_apply() | threads / processes |\n| pd.core.window.RollingGroupby.min() | pd.core.window.RollingGroupby.p_min() | threads / processes |\n| pd.core.window.RollingGroupby.max() | pd.core.window.RollingGroupby.p_max() | threads / processes |\n| pd.core.window.RollingGroupby.mean() | pd.core.window.RollingGroupby.p_mean() | threads / processes |\n| pd.core.window.RollingGroupby.sum() | pd.core.window.RollingGroupby.p_sum() | threads / processes |\n| pd.core.window.RollingGroupby.var() | pd.core.window.RollingGroupby.p_var() | threads / processes |\n| pd.core.window.RollingGroupby.sem() | pd.core.window.RollingGroupby.p_sem() | threads / processes |\n| pd.core.window.RollingGroupby.skew() | pd.core.window.RollingGroupby.p_skew() | threads / processes |\n| pd.core.window.RollingGroupby.kurt() | pd.core.window.RollingGroupby.p_kurt() | threads / processes |\n| pd.core.window.RollingGroupby.median() | pd.core.window.RollingGroupby.p_median() | threads / processes |\n| pd.core.window.RollingGroupby.quantile() | pd.core.window.RollingGroupby.p_quantile() | threads / processes |\n| pd.core.window.RollingGroupby.rank() | pd.core.window.RollingGroupby.p_rank() | threads / processes |\n| pd.core.window.RollingGroupby.agg() | pd.core.window.RollingGroupby.p_agg() | threads / processes |\n| pd.core.window.RollingGroupby.aggregate() | pd.core.window.RollingGroupby.p_aggregate() | threads / processes |\n\n#### Expanding\n\n| methods | parallel analogue | executor |\n|--------------------------------------|----------------------------------------|---------------------|\n| pd.core.window.Expanding.apply() | pd.core.window.Expanding.p_apply() | threads / processes |\n| pd.core.window.Expanding.min() | pd.core.window.Expanding.p_min() | threads / processes |\n| pd.core.window.Expanding.max() | pd.core.window.Expanding.p_max() | threads / processes |\n| pd.core.window.Expanding.mean() | pd.core.window.Expanding.p_mean() | threads / processes |\n| pd.core.window.Expanding.sum() | pd.core.window.Expanding.p_sum() | threads / processes |\n| pd.core.window.Expanding.var() | pd.core.window.Expanding.p_var() | threads / processes |\n| pd.core.window.Expanding.sem() | pd.core.window.Expanding.p_sem() | threads / processes |\n| pd.core.window.Expanding.skew() | pd.core.window.Expanding.p_skew() | threads / processes |\n| pd.core.window.Expanding.kurt() | pd.core.window.Expanding.p_kurt() | threads / processes |\n| pd.core.window.Expanding.median() | pd.core.window.Expanding.p_median() | threads / processes |\n| pd.core.window.Expanding.quantile() | pd.core.window.Expanding.p_quantile() | threads / processes |\n| pd.core.window.Expanding.rank() | pd.core.window.Expanding.p_rank() | threads / processes |\n| pd.core.window.Expanding.agg() | pd.core.window.Expanding.p_agg() | threads / processes |\n| pd.core.window.Expanding.aggregate() | pd.core.window.Expanding.p_aggregate() | threads / processes |\n\n\n#### ExpandingGroupby\n\n| methods | parallel analogue | executor |\n|---------------------------------------------|-----------------------------------------------|---------------------|\n| pd.core.window.ExpandingGroupby.apply() | pd.core.window.ExpandingGroupby.p_apply() | threads / processes |\n| pd.core.window.ExpandingGroupby.min() | pd.core.window.ExpandingGroupby.p_min() | threads / processes |\n| pd.core.window.ExpandingGroupby.max() | pd.core.window.ExpandingGroupby.p_max() | threads / processes |\n| pd.core.window.ExpandingGroupby.mean() | pd.core.window.ExpandingGroupby.p_mean() | threads / processes |\n| pd.core.window.ExpandingGroupby.sum() | pd.core.window.ExpandingGroupby.p_sum() | threads / processes |\n| pd.core.window.ExpandingGroupby.var() | pd.core.window.ExpandingGroupby.p_var() | threads / processes |\n| pd.core.window.ExpandingGroupby.sem() | pd.core.window.ExpandingGroupby.p_sem() | threads / processes |\n| pd.core.window.ExpandingGroupby.skew() | pd.core.window.ExpandingGroupby.p_skew() | threads / processes |\n| pd.core.window.ExpandingGroupby.kurt() | pd.core.window.ExpandingGroupby.p_kurt() | threads / processes |\n| pd.core.window.ExpandingGroupby.median() | pd.core.window.ExpandingGroupby.p_median() | threads / processes |\n| pd.core.window.ExpandingGroupby.quantile() | pd.core.window.ExpandingGroupby.p_quantile() | threads / processes |\n| pd.core.window.ExpandingGroupby.rank() | pd.core.window.ExpandingGroupby.p_rank() | threads / processes |\n| pd.core.window.ExpandingGroupby.agg() | pd.core.window.ExpandingGroupby.p_agg() | threads / processes |\n| pd.core.window.ExpandingGroupby.aggregate() | pd.core.window.ExpandingGroupby.p_aggregate() | threads / processes |\n\n### ExponentialMovingWindow\n\n| methods | parallel analogue | executor |\n|-----------------------------------------------|-------------------------------------------------|---------------------|\n| pd.core.window.ExponentialMovingWindow.mean() | pd.core.window.ExponentialMovingWindow.p_mean() | threads / processes |\n| pd.core.window.ExponentialMovingWindow.sum() | pd.core.window.ExponentialMovingWindow.p_sum() | threads / processes |\n| pd.core.window.ExponentialMovingWindow.var() | pd.core.window.ExponentialMovingWindow.p_var() | threads / processes |\n| pd.core.window.ExponentialMovingWindow.std() | pd.core.window.ExponentialMovingWindow.p_std() | threads / processes |\n\n### ExponentialMovingWindowGroupby\n\n| methods | parallel analogue | executor |\n|------------------------------------------------------|--------------------------------------------------------|---------------------|\n| pd.core.window.ExponentialMovingWindowGroupby.mean() | pd.core.window.ExponentialMovingWindowGroupby.p_mean() | threads / processes |\n| pd.core.window.ExponentialMovingWindowGroupby.sum() | pd.core.window.ExponentialMovingWindowGroupby.p_sum() | threads / processes |\n| pd.core.window.ExponentialMovingWindowGroupby.var() | pd.core.window.ExponentialMovingWindowGroupby.p_var() | threads / processes |\n| pd.core.window.ExponentialMovingWindowGroupby.std() | pd.core.window.ExponentialMovingWindowGroupby.p_std() | threads / processes |\n\n\n\n\n\n\n\n\n\n\n\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "Parallel processing on pandas with progress bars",
"version": "0.6.5",
"project_urls": {
"Homepage": "https://github.com/dubovikmaster/parallel-pandas"
},
"split_keywords": [
"parallel pandas",
" progress bar",
" parallel apply",
" parallel groupby",
" multiprocessing bar"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "3153c995e6aff89992c482430ead326a414d9a16da3724c54f3c432d3e76c5d3",
"md5": "7e2f49c28eb6104a1d2893ff58b23a86",
"sha256": "4c1a801f18e374cf874b3a71f03125b79cc00d510b07edb64af057d8b0932fb2"
},
"downloads": -1,
"filename": "parallel_pandas-0.6.5-py3-none-any.whl",
"has_sig": false,
"md5_digest": "7e2f49c28eb6104a1d2893ff58b23a86",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.7",
"size": 21556,
"upload_time": "2025-01-12T16:43:38",
"upload_time_iso_8601": "2025-01-12T16:43:38.699555Z",
"url": "https://files.pythonhosted.org/packages/31/53/c995e6aff89992c482430ead326a414d9a16da3724c54f3c432d3e76c5d3/parallel_pandas-0.6.5-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "ab0cb32e50a5289aa18fd41086ad20557dca6a5ea16047887b24bb13d4383d69",
"md5": "ab1b2ed13f22e3862f56c8638a0d5f6c",
"sha256": "0fdef095bddcac943eab5170a6a39f895ce80e0f07da6dacd16cd3f78c1ea3e1"
},
"downloads": -1,
"filename": "parallel_pandas-0.6.5.tar.gz",
"has_sig": false,
"md5_digest": "ab1b2ed13f22e3862f56c8638a0d5f6c",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.7",
"size": 21045,
"upload_time": "2025-01-12T16:43:40",
"upload_time_iso_8601": "2025-01-12T16:43:40.344173Z",
"url": "https://files.pythonhosted.org/packages/ab/0c/b32e50a5289aa18fd41086ad20557dca6a5ea16047887b24bb13d4383d69/parallel_pandas-0.6.5.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-01-12 16:43:40",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "dubovikmaster",
"github_project": "parallel-pandas",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"requirements": [
{
"name": "pandas",
"specs": [
[
">=",
"1.4.0"
]
]
},
{
"name": "dill",
"specs": [
[
">=",
"0.3.5.1"
]
]
},
{
"name": "tqdm",
"specs": [
[
">=",
"4.64.0"
]
]
},
{
"name": "psutil",
"specs": [
[
">=",
"5.9.1"
]
]
}
],
"lcname": "parallel-pandas"
}

