# pyscrapeTrain
Python script for downloading all tracks from a traktrain.com url.
It functions as a TrakTrain downloader to mp3.
Similar functionality to defunct scrapeTrainV2 but written in Python. (I wrote this from scratch as I don't have any experience with Ruby).
# Setup
First install the pip package
```bash
pip install pyscrapetrain
```
# How to use:
Simplest use-case:
```bash
pyscrapetrain <traktrain-url>
```
For example:
```bash
pyscrapetrain https://traktrain.com/waifu
```
Tracks are downloaded to a `pyscrapeTrain/artist` folder in your home directory.
## Changing folder
To change download folder use the `-d` flag:
```bash
python pyscrapetrain.py <traktrain-url> -d /path/to/folder
```
Which will create a `pyscrapeTrain/artist` folder under the path specified.
For example:
```bash
pyscrapetrain https://traktrain.com/waifu -d /Users/user/Documents
```
Will create the following folder `/Users/user/Documents/pyscrapeTrain/waifu`.
## Adding custom album
You might want to listen to the playlist of tracks you just downloaded
so the script supports a custom album ID3 tag to allow you to sort in your media library.
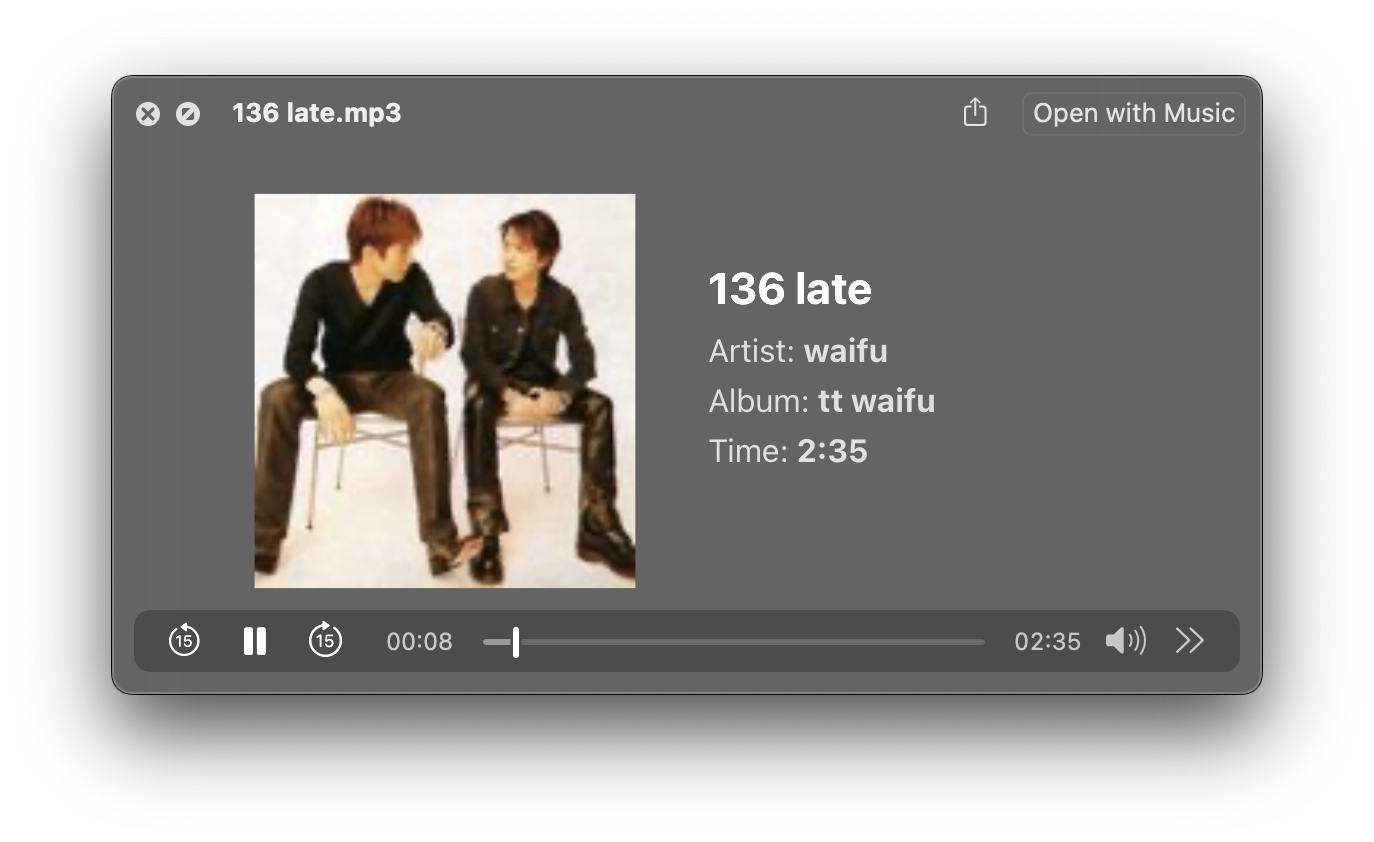
Use the `-a` tag to assign a custom album name.
For example:
```bash
pyscrapetrain https://traktrain.com/waifu -a "tt waifu"
```
Which gives:
## Supplying a list of URLs
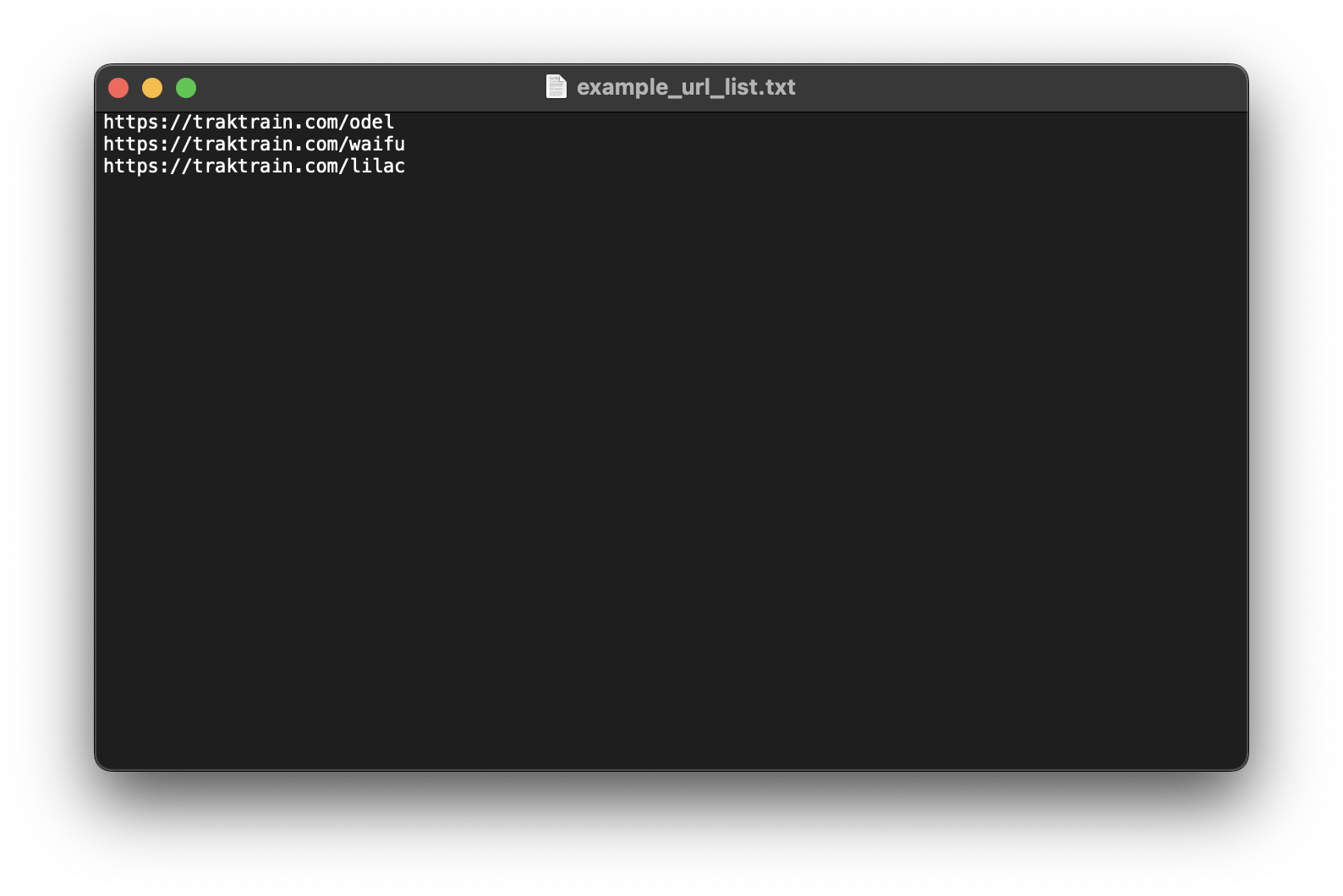
If you want to scrape multiple traktrain pages then you can point a .txt file
with each url you want to scrape on a new line.
For this use-case simply specify the filepath instead of a url.
For example:
```bash
pyscrapetrain example_url_list.txt
```
Example list of urls:
Raw data
{
"_id": null,
"home_page": "https://github.com/tim-morriss/pyscrapeTrain",
"name": "pyscrapetrain",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": "",
"keywords": "traktrain,scrapeTrain",
"author": "Tim Morriss",
"author_email": "",
"download_url": "https://files.pythonhosted.org/packages/b1/a5/9883c83fc9abff16d8d6801390f84398bf6e25e49fb98f45b8e6e5cfddb6/pyscrapetrain-0.1.1.tar.gz",
"platform": null,
"description": "# pyscrapeTrain\n\nPython script for downloading all tracks from a traktrain.com url. \nIt functions as a TrakTrain downloader to mp3.\n\nSimilar functionality to defunct scrapeTrainV2 but written in Python. (I wrote this from scratch as I don't have any experience with Ruby).\n\n# Setup\nFirst install the pip package\n```bash\npip install pyscrapetrain\n```\n\n# How to use:\nSimplest use-case:\n```bash\npyscrapetrain <traktrain-url>\n```\n\nFor example: \n```bash\npyscrapetrain https://traktrain.com/waifu\n```\n\nTracks are downloaded to a `pyscrapeTrain/artist` folder in your home directory. \n## Changing folder\nTo change download folder use the `-d` flag:\n```bash\npython pyscrapetrain.py <traktrain-url> -d /path/to/folder\n```\n\nWhich will create a `pyscrapeTrain/artist` folder under the path specified.\nFor example:\n```bash\npyscrapetrain https://traktrain.com/waifu -d /Users/user/Documents\n```\nWill create the following folder `/Users/user/Documents/pyscrapeTrain/waifu`.\n\n## Adding custom album\nYou might want to listen to the playlist of tracks you just downloaded \nso the script supports a custom album ID3 tag to allow you to sort in your media library.\n\nUse the `-a` tag to assign a custom album name.\n\nFor example:\n```bash\npyscrapetrain https://traktrain.com/waifu -a \"tt waifu\"\n```\n\nWhich gives:\n\n\n## Supplying a list of URLs\n\nIf you want to scrape multiple traktrain pages then you can point a .txt file \nwith each url you want to scrape on a new line.\n\nFor this use-case simply specify the filepath instead of a url.\n\nFor example:\n```bash\npyscrapetrain example_url_list.txt\n```\n\nExample list of urls:\n\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "CLI for downloading TrakTrain tracks",
"version": "0.1.1",
"project_urls": {
"Download": "https://github.com/tim-morriss/pyscrapeTrain/archive/refs/tags/v0.1.1.tar.gz",
"Homepage": "https://github.com/tim-morriss/pyscrapeTrain"
},
"split_keywords": [
"traktrain",
"scrapetrain"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "b1a59883c83fc9abff16d8d6801390f84398bf6e25e49fb98f45b8e6e5cfddb6",
"md5": "f40666dc137645875a091fb82acd8b39",
"sha256": "af75b3377bec68f98f1cc3ea6000f63c85629e88fb33a96e32ba0122be45ee11"
},
"downloads": -1,
"filename": "pyscrapetrain-0.1.1.tar.gz",
"has_sig": false,
"md5_digest": "f40666dc137645875a091fb82acd8b39",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 6761,
"upload_time": "2023-10-18T17:47:18",
"upload_time_iso_8601": "2023-10-18T17:47:18.908518Z",
"url": "https://files.pythonhosted.org/packages/b1/a5/9883c83fc9abff16d8d6801390f84398bf6e25e49fb98f45b8e6e5cfddb6/pyscrapetrain-0.1.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-10-18 17:47:18",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "tim-morriss",
"github_project": "pyscrapeTrain",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"requirements": [
{
"name": "beautifulsoup4",
"specs": []
},
{
"name": "halo",
"specs": []
},
{
"name": "mutagen",
"specs": []
},
{
"name": "requests",
"specs": []
},
{
"name": "simple-chalk",
"specs": []
},
{
"name": "tqdm",
"specs": []
}
],
"lcname": "pyscrapetrain"
}

