# Rule Set 3
> Python package to predict the activity of CRISPR sgRNA sequences using Rule Set 3
## Install
You can install the latest release of rs3 from pypi using
`pip install rs3`
For mac users you may also have to brew install the OpenMP library
`brew install libomp`
or install lightgbm without Openmp
`pip install lightgbm --install-option=--nomp`
See the [LightGBM documentation](https://github.com/microsoft/LightGBM/tree/master/python-package)
for more information
## Documentation
You can see the complete documentation for Rule Set 3 [here](https://gpp-rnd.github.io/rs3/).
## Quick Start
### Sequence based model
To calculate Rule Set 3 (sequence) scores, import the predict_seq function from the seq module.
```
from rs3.seq import predict_seq
```
You can store the 30mer context sequences you want to predict as a list.
```
context_seqs = ['GACGAAAGCGACAACGCGTTCATCCGGGCA', 'AGAAAACACTAGCATCCCCACCCGCGGACT']
```
You can specify the
[Hsu2013](https://www.nature.com/articles/nbt.2647) or
[Chen2013](https://www.sciencedirect.com/science/article/pii/S0092867413015316?via%3Dihub)
as the tracrRNA to score with.
We generally find any tracrRNA that does not have a T in the fifth position is better predicted with the Chen2013 input.
```
predict_seq(context_seqs, sequence_tracr='Hsu2013')
```
Calculating sequence-based features
100%|██████████| 2/2 [00:00<00:00, 15.04it/s]
array([-0.90030944, 1.11451622])
### Target based model
To get target scores, which use features at the endogenous target site to make predictions,
you must build or load feature matrices for the amino acid sequences, conservation scores, and protein domains.
As an example, we'll calculate target scores for 250 sgRNAs in the GeckoV2 library.
```
import pandas as pd
from rs3.predicttarg import predict_target
from rs3.targetfeat import (add_target_columns,
get_aa_subseq_df,
get_protein_domain_features,
get_conservation_features)
```
```
design_df = pd.read_table('test_data/sgrna-designs.txt')
design_df.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Input</th>
<th>Quota</th>
<th>Target Taxon</th>
<th>Target Gene ID</th>
<th>Target Gene Symbol</th>
<th>Target Transcript</th>
<th>Target Reference Coords</th>
<th>Target Alias</th>
<th>CRISPR Mechanism</th>
<th>Target Domain</th>
<th>...</th>
<th>On-Target Rank Weight</th>
<th>Off-Target Rank Weight</th>
<th>Combined Rank</th>
<th>Preselected As</th>
<th>Matching Active Arrayed Oligos</th>
<th>Matching Arrayed Constructs</th>
<th>Pools Containing Matching Construct</th>
<th>Pick Order</th>
<th>Picking Round</th>
<th>Picking Notes</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>1.0</td>
<td>7</td>
<td>GCAGATACAAGAGCAACTGA</td>
<td>NaN</td>
<td>BRDN0004619103</td>
<td>NaN</td>
<td>1</td>
<td>0</td>
<td>Preselected</td>
</tr>
<tr>
<th>1</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>1.0</td>
<td>48</td>
<td>AAAACTGGCACGACCATCGC</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>2</td>
<td>0</td>
<td>Preselected</td>
</tr>
<tr>
<th>2</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>1.0</td>
<td>7</td>
<td>AAAAGATTTGCGCACCCAAG</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>1</td>
<td>0</td>
<td>Preselected</td>
</tr>
<tr>
<th>3</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>1.0</td>
<td>8</td>
<td>CTTTGACCCAGACATAATGG</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>2</td>
<td>0</td>
<td>Preselected</td>
</tr>
<tr>
<th>4</th>
<td>TOP1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198900</td>
<td>TOP1</td>
<td>ENST00000361337.3</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>1.0</td>
<td>1</td>
<td>NaN</td>
<td>NaN</td>
<td>BRDN0001486452</td>
<td>NaN</td>
<td>2</td>
<td>1</td>
<td>NaN</td>
</tr>
</tbody>
</table>
<p>5 rows × 60 columns</p>
</div>
Throughout the analysis we will be using a core set of ID columns to merge the feature matrices. These ID columns
should uniquely identify an sgRNA and its target site.
```
id_cols = ['sgRNA Context Sequence', 'Target Cut Length', 'Target Transcript', 'Orientation']
```
#### Amino acid sequence input
To calculate the amino acid sequence matrix, you must first load the complete sequence from ensembl using the
`build_transcript_aa_seq_df`. See the documentation for the `predicttarg` module for an example of how to
use this function.
In this example we will use amino acid sequences that have been precalculated using the `write_transcript_data`
function in the `targetdata` module. Check out the documentation for this module for more information on
how to use this function.
We use pyarrow to read the written transcript data.
The stored transcripts are indexed by their Ensembl ID without the version number identifier.
To get this shortened version of the Ensembl ID use the `add_target_columns` function from the `targetfeat` module.
This function adds the 'Transcript Base' column as well as a column indicating the amino acid index ('AA Index')
of the cut site. The 'AA Index' column will be used for merging with the amino acid translations.
```
design_targ_df = add_target_columns(design_df)
design_targ_df.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Input</th>
<th>Quota</th>
<th>Target Taxon</th>
<th>Target Gene ID</th>
<th>Target Gene Symbol</th>
<th>Target Transcript</th>
<th>Target Reference Coords</th>
<th>Target Alias</th>
<th>CRISPR Mechanism</th>
<th>Target Domain</th>
<th>...</th>
<th>Combined Rank</th>
<th>Preselected As</th>
<th>Matching Active Arrayed Oligos</th>
<th>Matching Arrayed Constructs</th>
<th>Pools Containing Matching Construct</th>
<th>Pick Order</th>
<th>Picking Round</th>
<th>Picking Notes</th>
<th>AA Index</th>
<th>Transcript Base</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>7</td>
<td>GCAGATACAAGAGCAACTGA</td>
<td>NaN</td>
<td>BRDN0004619103</td>
<td>NaN</td>
<td>1</td>
<td>0</td>
<td>Preselected</td>
<td>64</td>
<td>ENST00000259457</td>
</tr>
<tr>
<th>1</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>48</td>
<td>AAAACTGGCACGACCATCGC</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>2</td>
<td>0</td>
<td>Preselected</td>
<td>46</td>
<td>ENST00000259457</td>
</tr>
<tr>
<th>2</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>7</td>
<td>AAAAGATTTGCGCACCCAAG</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>1</td>
<td>0</td>
<td>Preselected</td>
<td>106</td>
<td>ENST00000394249</td>
</tr>
<tr>
<th>3</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>8</td>
<td>CTTTGACCCAGACATAATGG</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>2</td>
<td>0</td>
<td>Preselected</td>
<td>263</td>
<td>ENST00000394249</td>
</tr>
<tr>
<th>4</th>
<td>TOP1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198900</td>
<td>TOP1</td>
<td>ENST00000361337.3</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1</td>
<td>NaN</td>
<td>NaN</td>
<td>BRDN0001486452</td>
<td>NaN</td>
<td>2</td>
<td>1</td>
<td>NaN</td>
<td>140</td>
<td>ENST00000361337</td>
</tr>
</tbody>
</table>
<p>5 rows × 62 columns</p>
</div>
```
transcript_bases = design_targ_df['Transcript Base'].unique()
transcript_bases[0:5]
```
array(['ENST00000259457', 'ENST00000394249', 'ENST00000361337',
'ENST00000368328', 'ENST00000610426'], dtype=object)
```
aa_seq_df = pd.read_parquet('test_data/target_data/aa_seqs.pq', engine='pyarrow',
filters=[[('Transcript Base', 'in', transcript_bases)]])
aa_seq_df.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Target Transcript</th>
<th>Target Total Length</th>
<th>Transcript Base</th>
<th>version</th>
<th>seq</th>
<th>molecule</th>
<th>desc</th>
<th>id</th>
<th>AA len</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>ENST00000259457.8</td>
<td>834</td>
<td>ENST00000259457</td>
<td>3</td>
<td>MAAVSVYAPPVGGFSFDNCRRNAVLEADFAKRGYKLPKVRKTGTTI...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000259457</td>
<td>277</td>
</tr>
<tr>
<th>1</th>
<td>ENST00000394249.8</td>
<td>1863</td>
<td>ENST00000394249</td>
<td>3</td>
<td>MRRSEVLAEESIVCLQKALNHLREIWELIGIPEDQRLQRTEVVKKH...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000377793</td>
<td>620</td>
</tr>
<tr>
<th>2</th>
<td>ENST00000361337.3</td>
<td>2298</td>
<td>ENST00000361337</td>
<td>2</td>
<td>MSGDHLHNDSQIEADFRLNDSHKHKDKHKDREHRHKEHKKEKDREK...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000354522</td>
<td>765</td>
</tr>
<tr>
<th>3</th>
<td>ENST00000368328.5</td>
<td>267</td>
<td>ENST00000368328</td>
<td>4</td>
<td>MALSTIVSQRKQIKRKAPRGFLKRVFKRKKPQLRLEKSGDLLVHLN...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000357311</td>
<td>88</td>
</tr>
<tr>
<th>4</th>
<td>ENST00000610426.5</td>
<td>783</td>
<td>ENST00000610426</td>
<td>1</td>
<td>MPQNEYIELHRKRYGYRLDYHEKKRKKESREAHERSKKAKKMIGLK...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000483484</td>
<td>260</td>
</tr>
</tbody>
</table>
</div>
From the complete transcript translations, we extract an amino acid subsequence as input to our model. The subsequence
is centered around the amino acid encoded by the nucleotide preceding the cut site in the direction of transcription.
This is the nucleotide that corresponds to the 'Target Cut Length' in a CRISPick design file.
We take 16 amino acids on either side of the cut site for a total sequence length of 33.
The `get_aa_subseq_df` from the `targetfeat` module will calculate these subsequences
from the complete amino acid sequences.
```
aa_subseq_df = get_aa_subseq_df(sg_designs=design_targ_df, aa_seq_df=aa_seq_df, width=16,
id_cols=id_cols)
aa_subseq_df.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Target Transcript</th>
<th>Target Total Length</th>
<th>Transcript Base</th>
<th>version</th>
<th>seq</th>
<th>molecule</th>
<th>desc</th>
<th>id</th>
<th>AA len</th>
<th>Target Cut Length</th>
<th>Orientation</th>
<th>sgRNA Context Sequence</th>
<th>AA Index</th>
<th>extended_seq</th>
<th>AA 0-Indexed</th>
<th>AA 0-Indexed padded</th>
<th>seq_start</th>
<th>seq_end</th>
<th>AA Subsequence</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>ENST00000259457.8</td>
<td>834</td>
<td>ENST00000259457</td>
<td>3</td>
<td>MAAVSVYAPPVGGFSFDNCRRNAVLEADFAKRGYKLPKVRKTGTTI...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000259457</td>
<td>277</td>
<td>191</td>
<td>sense</td>
<td>TGGAGCAGATACAAGAGCAACTGAAGGGAT</td>
<td>64</td>
<td>-----------------MAAVSVYAPPVGGFSFDNCRRNAVLEADF...</td>
<td>63</td>
<td>80</td>
<td>64</td>
<td>96</td>
<td>GVVYKDGIVLGADTRATEGMVVADKNCSKIHFI</td>
</tr>
<tr>
<th>1</th>
<td>ENST00000259457.8</td>
<td>834</td>
<td>ENST00000259457</td>
<td>3</td>
<td>MAAVSVYAPPVGGFSFDNCRRNAVLEADFAKRGYKLPKVRKTGTTI...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000259457</td>
<td>277</td>
<td>137</td>
<td>sense</td>
<td>CCGGAAAACTGGCACGACCATCGCTGGGGT</td>
<td>46</td>
<td>-----------------MAAVSVYAPPVGGFSFDNCRRNAVLEADF...</td>
<td>45</td>
<td>62</td>
<td>46</td>
<td>78</td>
<td>AKRGYKLPKVRKTGTTIAGVVYKDGIVLGADTR</td>
</tr>
<tr>
<th>2</th>
<td>ENST00000394249.8</td>
<td>1863</td>
<td>ENST00000394249</td>
<td>3</td>
<td>MRRSEVLAEESIVCLQKALNHLREIWELIGIPEDQRLQRTEVVKKH...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000377793</td>
<td>620</td>
<td>316</td>
<td>sense</td>
<td>TAGAAAAAGATTTGCGCACCCAAGTGGAAT</td>
<td>106</td>
<td>-----------------MRRSEVLAEESIVCLQKALNHLREIWELI...</td>
<td>105</td>
<td>122</td>
<td>106</td>
<td>138</td>
<td>EEGETTILQLEKDLRTQVELMRKQKKERKQELK</td>
</tr>
<tr>
<th>3</th>
<td>ENST00000394249.8</td>
<td>1863</td>
<td>ENST00000394249</td>
<td>3</td>
<td>MRRSEVLAEESIVCLQKALNHLREIWELIGIPEDQRLQRTEVVKKH...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000377793</td>
<td>620</td>
<td>787</td>
<td>antisense</td>
<td>TGGCCTTTGACCCAGACATAATGGTGGCCA</td>
<td>263</td>
<td>-----------------MRRSEVLAEESIVCLQKALNHLREIWELI...</td>
<td>262</td>
<td>279</td>
<td>263</td>
<td>295</td>
<td>WDRLQIPEEEREAVATIMSGSKAKVRKALQLEV</td>
</tr>
<tr>
<th>4</th>
<td>ENST00000361337.3</td>
<td>2298</td>
<td>ENST00000361337</td>
<td>2</td>
<td>MSGDHLHNDSQIEADFRLNDSHKHKDKHKDREHRHKEHKKEKDREK...</td>
<td>protein</td>
<td>None</td>
<td>ENSP00000354522</td>
<td>765</td>
<td>420</td>
<td>antisense</td>
<td>AAATACTCACTCATCCTCATCTCGAGGTCT</td>
<td>140</td>
<td>-----------------MSGDHLHNDSQIEADFRLNDSHKHKDKHK...</td>
<td>139</td>
<td>156</td>
<td>140</td>
<td>172</td>
<td>GYFVPPKEDIKPLKRPRDEDDADYKPKKIKTED</td>
</tr>
</tbody>
</table>
</div>
#### Lite Scores
You now have all the information you need to calculate "lite" Target Scores, which are less data intensive than complete
target scores, with the `predict_target` function from the `predicttarg` module.
```
lite_predictions = predict_target(design_df=design_df,
aa_subseq_df=aa_subseq_df)
design_df['Target Score Lite'] = lite_predictions
design_df.head()
```
/opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
/opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Input</th>
<th>Quota</th>
<th>Target Taxon</th>
<th>Target Gene ID</th>
<th>Target Gene Symbol</th>
<th>Target Transcript</th>
<th>Target Reference Coords</th>
<th>Target Alias</th>
<th>CRISPR Mechanism</th>
<th>Target Domain</th>
<th>...</th>
<th>Off-Target Rank Weight</th>
<th>Combined Rank</th>
<th>Preselected As</th>
<th>Matching Active Arrayed Oligos</th>
<th>Matching Arrayed Constructs</th>
<th>Pools Containing Matching Construct</th>
<th>Pick Order</th>
<th>Picking Round</th>
<th>Picking Notes</th>
<th>Target Score Lite</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>7</td>
<td>GCAGATACAAGAGCAACTGA</td>
<td>NaN</td>
<td>BRDN0004619103</td>
<td>NaN</td>
<td>1</td>
<td>0</td>
<td>Preselected</td>
<td>0.012467</td>
</tr>
<tr>
<th>1</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>48</td>
<td>AAAACTGGCACGACCATCGC</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>2</td>
<td>0</td>
<td>Preselected</td>
<td>0.048338</td>
</tr>
<tr>
<th>2</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>7</td>
<td>AAAAGATTTGCGCACCCAAG</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>1</td>
<td>0</td>
<td>Preselected</td>
<td>-0.129234</td>
</tr>
<tr>
<th>3</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>8</td>
<td>CTTTGACCCAGACATAATGG</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>2</td>
<td>0</td>
<td>Preselected</td>
<td>0.061647</td>
</tr>
<tr>
<th>4</th>
<td>TOP1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198900</td>
<td>TOP1</td>
<td>ENST00000361337.3</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1.0</td>
<td>1</td>
<td>NaN</td>
<td>NaN</td>
<td>BRDN0001486452</td>
<td>NaN</td>
<td>2</td>
<td>1</td>
<td>NaN</td>
<td>-0.009100</td>
</tr>
</tbody>
</table>
<p>5 rows × 61 columns</p>
</div>
If you would like to calculate full target scores then follow the sections below.
#### Protein domain input
To calculate full target scores you will also need inputs for protein domains and conservation.
The protein domain input should have 16 binary columns for 16 different protein domain sources in addition to the
`id_cols`. The protein domain sources are 'Pfam', 'PANTHER', 'HAMAP', 'SuperFamily', 'TIGRfam', 'ncoils', 'Gene3D',
'Prosite_patterns', 'Seg', 'SignalP', 'TMHMM', 'MobiDBLite', 'PIRSF', 'PRINTS', 'Smart', 'Prosite_profiles'.
These columns should be kept in order when inputting for scoring.
In this example we will load the protein domain information from a parquet file, which was written
using `write_transcript_data` function in the `targetdata` module. You can also query transcript data on the fly,
by using the `build_translation_overlap_df` function. See the documentation for the `predicttarg` module for more
information on how to do this.
```
domain_df = pd.read_parquet('test_data/target_data/protein_domains.pq', engine='pyarrow',
filters=[[('Transcript Base', 'in', transcript_bases)]])
domain_df.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>type</th>
<th>cigar_string</th>
<th>id</th>
<th>hit_end</th>
<th>feature_type</th>
<th>description</th>
<th>seq_region_name</th>
<th>end</th>
<th>hit_start</th>
<th>translation_id</th>
<th>interpro</th>
<th>hseqname</th>
<th>Transcript Base</th>
<th>align_type</th>
<th>start</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>Pfam</td>
<td></td>
<td>PF12465</td>
<td>36</td>
<td>protein_feature</td>
<td>Proteasome beta subunit, C-terminal</td>
<td>ENSP00000259457</td>
<td>271</td>
<td>1</td>
<td>976188</td>
<td>IPR024689</td>
<td>PF12465</td>
<td>ENST00000259457</td>
<td>None</td>
<td>235</td>
</tr>
<tr>
<th>1</th>
<td>Pfam</td>
<td></td>
<td>PF00227</td>
<td>190</td>
<td>protein_feature</td>
<td>Proteasome, subunit alpha/beta</td>
<td>ENSP00000259457</td>
<td>221</td>
<td>2</td>
<td>976188</td>
<td>IPR001353</td>
<td>PF00227</td>
<td>ENST00000259457</td>
<td>None</td>
<td>41</td>
</tr>
<tr>
<th>2</th>
<td>PRINTS</td>
<td></td>
<td>PR00141</td>
<td>0</td>
<td>protein_feature</td>
<td>Peptidase T1A, proteasome beta-subunit</td>
<td>ENSP00000259457</td>
<td>66</td>
<td>0</td>
<td>976188</td>
<td>IPR000243</td>
<td>PR00141</td>
<td>ENST00000259457</td>
<td>None</td>
<td>51</td>
</tr>
<tr>
<th>3</th>
<td>PRINTS</td>
<td></td>
<td>PR00141</td>
<td>0</td>
<td>protein_feature</td>
<td>Peptidase T1A, proteasome beta-subunit</td>
<td>ENSP00000259457</td>
<td>182</td>
<td>0</td>
<td>976188</td>
<td>IPR000243</td>
<td>PR00141</td>
<td>ENST00000259457</td>
<td>None</td>
<td>171</td>
</tr>
<tr>
<th>4</th>
<td>PRINTS</td>
<td></td>
<td>PR00141</td>
<td>0</td>
<td>protein_feature</td>
<td>Peptidase T1A, proteasome beta-subunit</td>
<td>ENSP00000259457</td>
<td>193</td>
<td>0</td>
<td>976188</td>
<td>IPR000243</td>
<td>PR00141</td>
<td>ENST00000259457</td>
<td>None</td>
<td>182</td>
</tr>
</tbody>
</table>
</div>
Now to transform the `domain_df` into a wide form for model input, we use the `get_protein_domain_features` function
from the `targetfeat` module.
```
domain_feature_df = get_protein_domain_features(design_targ_df, domain_df, id_cols=id_cols)
domain_feature_df.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>sgRNA Context Sequence</th>
<th>Target Cut Length</th>
<th>Target Transcript</th>
<th>Orientation</th>
<th>Pfam</th>
<th>PANTHER</th>
<th>HAMAP</th>
<th>SuperFamily</th>
<th>TIGRfam</th>
<th>ncoils</th>
<th>Gene3D</th>
<th>Prosite_patterns</th>
<th>Seg</th>
<th>SignalP</th>
<th>TMHMM</th>
<th>MobiDBLite</th>
<th>PIRSF</th>
<th>PRINTS</th>
<th>Smart</th>
<th>Prosite_profiles</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>AAAAGAATGATGAAAAGACACCACAGGGAG</td>
<td>244</td>
<td>ENST00000610426.5</td>
<td>sense</td>
<td>1</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
</tr>
<tr>
<th>1</th>
<td>AAAAGAGCCATGAATCTAAACATCAGGAAT</td>
<td>640</td>
<td>ENST00000223073.6</td>
<td>sense</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
</tr>
<tr>
<th>2</th>
<td>AAAAGCGCCAAATGGCCCGAGAATTGGGAG</td>
<td>709</td>
<td>ENST00000331923.9</td>
<td>sense</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
</tr>
<tr>
<th>3</th>
<td>AAACAGAAAAAGTTAAAATCACCAAGGTGT</td>
<td>496</td>
<td>ENST00000283882.4</td>
<td>sense</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
</tr>
<tr>
<th>4</th>
<td>AAACAGATGGAAGATGCTTACCGGGGGACC</td>
<td>132</td>
<td>ENST00000393047.8</td>
<td>sense</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
</tr>
</tbody>
</table>
</div>
For input into the `predict_target` function, the `domain_feature_df` should have the `id_cols` as well as
columns for each of the 16 protein domain features.
#### Conservation input
Finally, for the full target model you need to calculate conservation features.
The conservation features represent conservation across evolutionary time at the sgRNA cut site and are quantified
using PhyloP scores. These scores are available for download by the UCSC genome browser
for [hg38](https://hgdownload.soe.ucsc.edu/goldenPath/hg38/database/) (phyloP100way),
and [mm39](https://hgdownload.soe.ucsc.edu/goldenPath/mm39/database/) (phyloP35way).
Within this package we query conservation scores using the UCSC genome browser's
[REST API](http://genome.ucsc.edu/goldenPath/help/api.html).
To get conservation scores, you can use the `build_conservation_df` function from the `targetdata` module.
Here we load conservation scores, which were written to parquet using the `write_conservation_data` function from the
`targetdata` module.
```
conservation_df = pd.read_parquet('test_data/target_data/conservation.pq', engine='pyarrow',
filters=[[('Transcript Base', 'in', transcript_bases)]])
conservation_df.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>exon_id</th>
<th>genomic position</th>
<th>conservation</th>
<th>Transcript Base</th>
<th>target position</th>
<th>chromosome</th>
<th>genome</th>
<th>translation length</th>
<th>Target Transcript</th>
<th>Strand of Target</th>
<th>Target Total Length</th>
<th>ranked_conservation</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>ENSE00001866322</td>
<td>124415425.0</td>
<td>6.46189</td>
<td>ENST00000259457</td>
<td>1</td>
<td>9</td>
<td>hg38</td>
<td>277</td>
<td>ENST00000259457.8</td>
<td>-</td>
<td>834</td>
<td>0.639089</td>
</tr>
<tr>
<th>1</th>
<td>ENSE00001866322</td>
<td>124415424.0</td>
<td>7.48071</td>
<td>ENST00000259457</td>
<td>2</td>
<td>9</td>
<td>hg38</td>
<td>277</td>
<td>ENST00000259457.8</td>
<td>-</td>
<td>834</td>
<td>0.686451</td>
</tr>
<tr>
<th>2</th>
<td>ENSE00001866322</td>
<td>124415423.0</td>
<td>6.36001</td>
<td>ENST00000259457</td>
<td>3</td>
<td>9</td>
<td>hg38</td>
<td>277</td>
<td>ENST00000259457.8</td>
<td>-</td>
<td>834</td>
<td>0.622902</td>
</tr>
<tr>
<th>3</th>
<td>ENSE00001866322</td>
<td>124415422.0</td>
<td>6.36001</td>
<td>ENST00000259457</td>
<td>4</td>
<td>9</td>
<td>hg38</td>
<td>277</td>
<td>ENST00000259457.8</td>
<td>-</td>
<td>834</td>
<td>0.622902</td>
</tr>
<tr>
<th>4</th>
<td>ENSE00001866322</td>
<td>124415421.0</td>
<td>8.09200</td>
<td>ENST00000259457</td>
<td>5</td>
<td>9</td>
<td>hg38</td>
<td>277</td>
<td>ENST00000259457.8</td>
<td>-</td>
<td>834</td>
<td>0.870504</td>
</tr>
</tbody>
</table>
</div>
We normalize conservation scores to a within-gene percent rank, in the 'ranked_conservation' column,
in order to make scores comparable across genes and genomes. Note that a rank of 0 indicates the
least conserved nucleotide and a rank of 1 indicates the most conserved.
To featurize the conservation scores, we average across a window of 4 and 32 nucleotides
centered around the nucleotide preceding the cut site in the direction of transcription.
Note that this nucleotide is the 2nd nucleotide in the window of 4 and the 16th nucleotide in the window of 32.
We use the `get_conservation_features` function from the `targetfeat` module to get these features from the
`conservation_df`.
For the `predict_targ` function, we need the `id_cols` and the columns 'cons_4' and 'cons_32' in the
`conservation_feature_df`.
```
conservation_feature_df = get_conservation_features(design_targ_df, conservation_df,
small_width=2, large_width=16,
conservation_column='ranked_conservation',
id_cols=id_cols)
conservation_feature_df
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>sgRNA Context Sequence</th>
<th>Target Cut Length</th>
<th>Target Transcript</th>
<th>Orientation</th>
<th>cons_4</th>
<th>cons_32</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>AAAAGAATGATGAAAAGACACCACAGGGAG</td>
<td>244</td>
<td>ENST00000610426.5</td>
<td>sense</td>
<td>0.218231</td>
<td>0.408844</td>
</tr>
<tr>
<th>1</th>
<td>AAAAGAGCCATGAATCTAAACATCAGGAAT</td>
<td>640</td>
<td>ENST00000223073.6</td>
<td>sense</td>
<td>0.129825</td>
<td>0.278180</td>
</tr>
<tr>
<th>2</th>
<td>AAAAGCGCCAAATGGCCCGAGAATTGGGAG</td>
<td>709</td>
<td>ENST00000331923.9</td>
<td>sense</td>
<td>0.470906</td>
<td>0.532305</td>
</tr>
<tr>
<th>3</th>
<td>AAACAGAAAAAGTTAAAATCACCAAGGTGT</td>
<td>496</td>
<td>ENST00000283882.4</td>
<td>sense</td>
<td>0.580556</td>
<td>0.602708</td>
</tr>
<tr>
<th>4</th>
<td>AAACAGATGGAAGATGCTTACCGGGGGACC</td>
<td>132</td>
<td>ENST00000393047.8</td>
<td>sense</td>
<td>0.283447</td>
<td>0.414293</td>
</tr>
<tr>
<th>...</th>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
</tr>
<tr>
<th>395</th>
<td>TTTGATTGCATTAAGGTTGGACTCTGGATT</td>
<td>246</td>
<td>ENST00000249269.9</td>
<td>sense</td>
<td>0.580612</td>
<td>0.618707</td>
</tr>
<tr>
<th>396</th>
<td>TTTGCCCACAGCTCCAAAGCATCGCGGAGA</td>
<td>130</td>
<td>ENST00000227618.8</td>
<td>sense</td>
<td>0.323770</td>
<td>0.416368</td>
</tr>
<tr>
<th>397</th>
<td>TTTTACAGTGCGATGTATGATGTATGGCTT</td>
<td>119</td>
<td>ENST00000338366.6</td>
<td>sense</td>
<td>0.788000</td>
<td>0.537417</td>
</tr>
<tr>
<th>398</th>
<td>TTTTGGATCTCGTAGTGATTCAAGAGGGAA</td>
<td>233</td>
<td>ENST00000629496.3</td>
<td>sense</td>
<td>0.239630</td>
<td>0.347615</td>
</tr>
<tr>
<th>399</th>
<td>TTTTTGTTACTACAGGTTCGCTGCTGGGAA</td>
<td>201</td>
<td>ENST00000395840.6</td>
<td>sense</td>
<td>0.693767</td>
<td>0.639044</td>
</tr>
</tbody>
</table>
<p>400 rows × 6 columns</p>
</div>
#### Full Target Scores
In order to calculate Target Scores you must input the feature matrices and design_df to the `predict_target`
function from the `predicttarg` module.
```
target_predictions = predict_target(design_df=design_df,
aa_subseq_df=aa_subseq_df,
domain_feature_df=domain_feature_df,
conservation_feature_df=conservation_feature_df,
id_cols=id_cols)
design_df['Target Score'] = target_predictions
design_df.head()
```
/opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
/opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Input</th>
<th>Quota</th>
<th>Target Taxon</th>
<th>Target Gene ID</th>
<th>Target Gene Symbol</th>
<th>Target Transcript</th>
<th>Target Reference Coords</th>
<th>Target Alias</th>
<th>CRISPR Mechanism</th>
<th>Target Domain</th>
<th>...</th>
<th>Combined Rank</th>
<th>Preselected As</th>
<th>Matching Active Arrayed Oligos</th>
<th>Matching Arrayed Constructs</th>
<th>Pools Containing Matching Construct</th>
<th>Pick Order</th>
<th>Picking Round</th>
<th>Picking Notes</th>
<th>Target Score Lite</th>
<th>Target Score</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>7</td>
<td>GCAGATACAAGAGCAACTGA</td>
<td>NaN</td>
<td>BRDN0004619103</td>
<td>NaN</td>
<td>1</td>
<td>0</td>
<td>Preselected</td>
<td>0.012467</td>
<td>0.152037</td>
</tr>
<tr>
<th>1</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>48</td>
<td>AAAACTGGCACGACCATCGC</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>2</td>
<td>0</td>
<td>Preselected</td>
<td>0.048338</td>
<td>0.064880</td>
</tr>
<tr>
<th>2</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>7</td>
<td>AAAAGATTTGCGCACCCAAG</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>1</td>
<td>0</td>
<td>Preselected</td>
<td>-0.129234</td>
<td>-0.063012</td>
</tr>
<tr>
<th>3</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>8</td>
<td>CTTTGACCCAGACATAATGG</td>
<td>NaN</td>
<td>NaN</td>
<td>NaN</td>
<td>2</td>
<td>0</td>
<td>Preselected</td>
<td>0.061647</td>
<td>-0.126357</td>
</tr>
<tr>
<th>4</th>
<td>TOP1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198900</td>
<td>TOP1</td>
<td>ENST00000361337.3</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1</td>
<td>NaN</td>
<td>NaN</td>
<td>BRDN0001486452</td>
<td>NaN</td>
<td>2</td>
<td>1</td>
<td>NaN</td>
<td>-0.009100</td>
<td>-0.234410</td>
</tr>
</tbody>
</table>
<p>5 rows × 62 columns</p>
</div>
Target Scores can be added directly to the sequence scores for your final Rule Set 3 predictions.
### Predict Function
If you don't want to generate the target matrices themselves, you can use the `predict` function from
the `predict` module.
```
from rs3.predict import predict
import matplotlib.pyplot as plt
import gpplot
import seaborn as sns
```
#### Preloaded data
In this first example with the `predict` function, we calculate predictions for GeckoV2 sgRNAs.
In this example the amino acid sequences, protein domains and conservation scores were prequeried using the
`write_transcript_data` and `write_conservation_data` functions from the targetdata module.
Pre-querying these data can be helpful for large scale design runs.
You can also use the `predict` function without pre-querying and calculate
scores on the fly. You can see an example of this in the next section.
The `predict` function allows for parallel computation
for querying databases (`n_jobs_min`) and featurizing sgRNAs (`n_jobs_max`).
We recommend keeping `n_jobs_min` set to 1 or 2, as the APIs limit the amount of queries per hour.
```
design_df = pd.read_table('test_data/sgrna-designs.txt')
import multiprocessing
max_n_jobs = multiprocessing.cpu_count()
```
```
scored_designs = predict(design_df, tracr=['Hsu2013', 'Chen2013'], target=True,
n_jobs_min=2, n_jobs_max=max_n_jobs,
aa_seq_file='./test_data/target_data/aa_seqs.pq',
domain_file='./test_data/target_data/protein_domains.pq',
conservatin_file='./test_data/target_data/conservation.pq',
lite=False)
scored_designs.head()
```
Calculating sequence-based features
100%|██████████| 400/400 [00:05<00:00, 68.98it/s]
Calculating sequence-based features
100%|██████████| 400/400 [00:01<00:00, 229.85it/s]
/opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
/opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Input</th>
<th>Quota</th>
<th>Target Taxon</th>
<th>Target Gene ID</th>
<th>Target Gene Symbol</th>
<th>Target Transcript</th>
<th>Target Reference Coords</th>
<th>Target Alias</th>
<th>CRISPR Mechanism</th>
<th>Target Domain</th>
<th>...</th>
<th>Picking Round</th>
<th>Picking Notes</th>
<th>RS3 Sequence Score (Hsu2013 tracr)</th>
<th>RS3 Sequence Score (Chen2013 tracr)</th>
<th>AA Index</th>
<th>Transcript Base</th>
<th>Missing conservation information</th>
<th>Target Score</th>
<th>RS3 Sequence (Hsu2013 tracr) + Target Score</th>
<th>RS3 Sequence (Chen2013 tracr) + Target Score</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>0.787640</td>
<td>0.559345</td>
<td>64</td>
<td>ENST00000259457</td>
<td>False</td>
<td>0.152037</td>
<td>0.939676</td>
<td>0.711381</td>
</tr>
<tr>
<th>1</th>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>PSMB7</td>
<td>ENST00000259457.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>-0.294126</td>
<td>-0.181437</td>
<td>46</td>
<td>ENST00000259457</td>
<td>False</td>
<td>0.064880</td>
<td>-0.229246</td>
<td>-0.116557</td>
</tr>
<tr>
<th>2</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>-0.043418</td>
<td>-0.220434</td>
<td>106</td>
<td>ENST00000394249</td>
<td>False</td>
<td>-0.063012</td>
<td>-0.106429</td>
<td>-0.283446</td>
</tr>
<tr>
<th>3</th>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>PRC1</td>
<td>ENST00000394249.8</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>0.759256</td>
<td>0.453469</td>
<td>263</td>
<td>ENST00000394249</td>
<td>False</td>
<td>-0.126357</td>
<td>0.632899</td>
<td>0.327112</td>
</tr>
<tr>
<th>4</th>
<td>TOP1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198900</td>
<td>TOP1</td>
<td>ENST00000361337.3</td>
<td>NaN</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>...</td>
<td>1</td>
<td>NaN</td>
<td>0.424001</td>
<td>-0.197035</td>
<td>140</td>
<td>ENST00000361337</td>
<td>False</td>
<td>-0.234410</td>
<td>0.189591</td>
<td>-0.431445</td>
</tr>
</tbody>
</table>
<p>5 rows × 68 columns</p>
</div>
Here are the details for the keyword arguments of the above function
* `tracr` - tracr to calculate scores for. If a list is supplied instead of a string, scores will be calculated for both tracrs
* `target` - boolean indicating whether to calculate target scores
* `n_jobs_min`, `n_jobs_max` - number of cpus to use for parallel computation
* `aa_seq_file`, `domain_file`, `conservatin_file` - precalculated parquet files. Optional inputs as these features can also be calculated on the fly
* `lite` - boolean indicating whether to calculate lite target scores
By listing both tracrRNAs `tracr=['Hsu2013', 'Chen2013']` and setting `target=True`,
we calculate 5 unique scores: one sequence score for each tracr, the target score,
and the sequence scores plus the target score.
We can compare these predictions against the observed activity from GeckoV2
```
gecko_activity = pd.read_csv('test_data/Aguirre2016_activity.csv')
gecko_activity.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>sgRNA Sequence</th>
<th>sgRNA Context Sequence</th>
<th>Target Gene Symbol</th>
<th>Target Cut %</th>
<th>avg_mean_centered_neg_lfc</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>AAAAAACTTACCCCTTTGAC</td>
<td>AAAAAAAAAACTTACCCCTTTGACTGGCCA</td>
<td>CPSF6</td>
<td>22.2</td>
<td>-1.139819</td>
</tr>
<tr>
<th>1</th>
<td>AAAAACATTATCATTGAGCC</td>
<td>TGGCAAAAACATTATCATTGAGCCTGGATT</td>
<td>SKA3</td>
<td>62.3</td>
<td>-0.793055</td>
</tr>
<tr>
<th>2</th>
<td>AAAAAGAGATTGTCAAATCA</td>
<td>TATGAAAAAGAGATTGTCAAATCAAGGTAG</td>
<td>AQR</td>
<td>3.8</td>
<td>0.946453</td>
</tr>
<tr>
<th>3</th>
<td>AAAAAGCATCTCTAGAAATA</td>
<td>TTCAAAAAAGCATCTCTAGAAATATGGTCC</td>
<td>ZNHIT6</td>
<td>61.7</td>
<td>-0.429590</td>
</tr>
<tr>
<th>4</th>
<td>AAAAAGCGAGATACCCGAAA</td>
<td>AAAAAAAAAGCGAGATACCCGAAAAGGCAG</td>
<td>ABCF1</td>
<td>9.4</td>
<td>0.734196</td>
</tr>
</tbody>
</table>
</div>
```
gecko_activity_scores = (gecko_activity.merge(scored_designs,
how='inner',
on=['sgRNA Sequence', 'sgRNA Context Sequence',
'Target Gene Symbol', 'Target Cut %']))
gecko_activity_scores.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>sgRNA Sequence</th>
<th>sgRNA Context Sequence</th>
<th>Target Gene Symbol</th>
<th>Target Cut %</th>
<th>avg_mean_centered_neg_lfc</th>
<th>Input</th>
<th>Quota</th>
<th>Target Taxon</th>
<th>Target Gene ID</th>
<th>Target Transcript</th>
<th>...</th>
<th>Picking Round</th>
<th>Picking Notes</th>
<th>RS3 Sequence Score (Hsu2013 tracr)</th>
<th>RS3 Sequence Score (Chen2013 tracr)</th>
<th>AA Index</th>
<th>Transcript Base</th>
<th>Missing conservation information</th>
<th>Target Score</th>
<th>RS3 Sequence (Hsu2013 tracr) + Target Score</th>
<th>RS3 Sequence (Chen2013 tracr) + Target Score</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>AAAACTGGCACGACCATCGC</td>
<td>CCGGAAAACTGGCACGACCATCGCTGGGGT</td>
<td>PSMB7</td>
<td>16.4</td>
<td>-1.052943</td>
<td>PSMB7</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000136930</td>
<td>ENST00000259457.8</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>-0.294126</td>
<td>-0.181437</td>
<td>46</td>
<td>ENST00000259457</td>
<td>False</td>
<td>0.064880</td>
<td>-0.229246</td>
<td>-0.116557</td>
</tr>
<tr>
<th>1</th>
<td>AAAAGATTTGCGCACCCAAG</td>
<td>TAGAAAAAGATTTGCGCACCCAAGTGGAAT</td>
<td>PRC1</td>
<td>17.0</td>
<td>0.028674</td>
<td>PRC1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198901</td>
<td>ENST00000394249.8</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>-0.043418</td>
<td>-0.220434</td>
<td>106</td>
<td>ENST00000394249</td>
<td>False</td>
<td>-0.063012</td>
<td>-0.106429</td>
<td>-0.283446</td>
</tr>
<tr>
<th>2</th>
<td>AAAAGTCCAAGCATAGCAAC</td>
<td>CGGGAAAAGTCCAAGCATAGCAACAGGTAA</td>
<td>TOP1</td>
<td>6.5</td>
<td>0.195309</td>
<td>TOP1</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000198900</td>
<td>ENST00000361337.3</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>-0.294127</td>
<td>-0.022951</td>
<td>50</td>
<td>ENST00000361337</td>
<td>False</td>
<td>-0.354708</td>
<td>-0.648835</td>
<td>-0.377659</td>
</tr>
<tr>
<th>3</th>
<td>AAAGAAGCCTCAACTTCGTC</td>
<td>AGCGAAAGAAGCCTCAACTTCGTCTGGAGA</td>
<td>CENPW</td>
<td>37.5</td>
<td>-1.338209</td>
<td>CENPW</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000203760</td>
<td>ENST00000368328.5</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>-0.667399</td>
<td>-0.308794</td>
<td>34</td>
<td>ENST00000368328</td>
<td>False</td>
<td>0.129285</td>
<td>-0.538114</td>
<td>-0.179509</td>
</tr>
<tr>
<th>4</th>
<td>AAAGTGTGCTTTGTTGGAGA</td>
<td>TACTAAAGTGTGCTTTGTTGGAGATGGCTT</td>
<td>NSA2</td>
<td>60.0</td>
<td>-0.175219</td>
<td>NSA2</td>
<td>2</td>
<td>9606</td>
<td>ENSG00000164346</td>
<td>ENST00000610426.5</td>
<td>...</td>
<td>0</td>
<td>Preselected</td>
<td>-0.402220</td>
<td>-0.622492</td>
<td>157</td>
<td>ENST00000610426</td>
<td>False</td>
<td>-0.113577</td>
<td>-0.515797</td>
<td>-0.736069</td>
</tr>
</tbody>
</table>
<p>5 rows × 69 columns</p>
</div>
Since GeckoV2 was screened with the tracrRNA from Hsu et al. 2013, we'll use these scores sequence scores a part of our final prediction.
```
plt.subplots(figsize=(4,4))
gpplot.point_densityplot(gecko_activity_scores, y='avg_mean_centered_neg_lfc',
x='RS3 Sequence (Hsu2013 tracr) + Target Score')
gpplot.add_correlation(gecko_activity_scores, y='avg_mean_centered_neg_lfc',
x='RS3 Sequence (Hsu2013 tracr) + Target Score')
sns.despine()
```
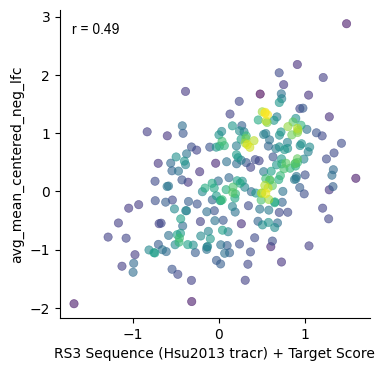
#### Predictions on the fly
You can also make predictions without pre-querying the target data. Here
we use example designs for BCL2L1, MCL1 and EEF2.
```
design_df = pd.read_table('test_data/sgrna-designs_BCL2L1_MCL1_EEF2.txt')
```
```
scored_designs = predict(design_df,
tracr=['Hsu2013', 'Chen2013'], target=True,
n_jobs_min=2, n_jobs_max=8,
lite=False)
scored_designs
```
Calculating sequence-based features
100%|██████████| 849/849 [00:06<00:00, 137.86it/s]
Calculating sequence-based features
100%|██████████| 849/849 [00:02<00:00, 321.44it/s]
Getting amino acid sequences
100%|██████████| 1/1 [00:00<00:00, 1.77it/s]
Getting protein domains
100%|██████████| 3/3 [00:00<00:00, 899.29it/s]
Getting conservation
100%|██████████| 3/3 [00:00<00:00, 10.67it/s]
/opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
/opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.
warnings.warn(
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>Input</th>
<th>Quota</th>
<th>Target Taxon</th>
<th>Target Gene ID</th>
<th>Target Gene Symbol</th>
<th>Target Transcript</th>
<th>Target Alias</th>
<th>CRISPR Mechanism</th>
<th>Target Domain</th>
<th>Reference Sequence</th>
<th>...</th>
<th>Picking Round</th>
<th>Picking Notes</th>
<th>RS3 Sequence Score (Hsu2013 tracr)</th>
<th>RS3 Sequence Score (Chen2013 tracr)</th>
<th>AA Index</th>
<th>Transcript Base</th>
<th>Missing conservation information</th>
<th>Target Score</th>
<th>RS3 Sequence (Hsu2013 tracr) + Target Score</th>
<th>RS3 Sequence (Chen2013 tracr) + Target Score</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>EEF2</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000167658</td>
<td>EEF2</td>
<td>ENST00000309311.7</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000019.10</td>
<td>...</td>
<td>NaN</td>
<td>Outside Target Window: 5-65%</td>
<td>0.907809</td>
<td>0.769956</td>
<td>666</td>
<td>ENST00000309311</td>
<td>False</td>
<td>-0.115549</td>
<td>0.792261</td>
<td>0.654408</td>
</tr>
<tr>
<th>1</th>
<td>EEF2</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000167658</td>
<td>EEF2</td>
<td>ENST00000309311.7</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000019.10</td>
<td>...</td>
<td>NaN</td>
<td>BsmBI:CGTCTC; Outside Target Window: 5-65%</td>
<td>0.171870</td>
<td>0.040419</td>
<td>581</td>
<td>ENST00000309311</td>
<td>False</td>
<td>-0.017643</td>
<td>0.154226</td>
<td>0.022776</td>
</tr>
<tr>
<th>2</th>
<td>EEF2</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000167658</td>
<td>EEF2</td>
<td>ENST00000309311.7</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000019.10</td>
<td>...</td>
<td>1.0</td>
<td>NaN</td>
<td>1.393513</td>
<td>0.577732</td>
<td>107</td>
<td>ENST00000309311</td>
<td>False</td>
<td>0.172910</td>
<td>1.566422</td>
<td>0.750642</td>
</tr>
<tr>
<th>3</th>
<td>EEF2</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000167658</td>
<td>EEF2</td>
<td>ENST00000309311.7</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000019.10</td>
<td>...</td>
<td>1.0</td>
<td>NaN</td>
<td>0.904446</td>
<td>0.008390</td>
<td>406</td>
<td>ENST00000309311</td>
<td>False</td>
<td>0.121034</td>
<td>1.025480</td>
<td>0.129424</td>
</tr>
<tr>
<th>4</th>
<td>EEF2</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000167658</td>
<td>EEF2</td>
<td>ENST00000309311.7</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000019.10</td>
<td>...</td>
<td>1.0</td>
<td>NaN</td>
<td>0.831087</td>
<td>0.361594</td>
<td>546</td>
<td>ENST00000309311</td>
<td>False</td>
<td>0.036041</td>
<td>0.867128</td>
<td>0.397635</td>
</tr>
<tr>
<th>...</th>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>...</td>
</tr>
<tr>
<th>844</th>
<td>MCL1</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000143384</td>
<td>MCL1</td>
<td>ENST00000369026.3</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000001.11</td>
<td>...</td>
<td>NaN</td>
<td>Off-target Match Bin I matches > 3; Spacing Vi...</td>
<td>-0.792918</td>
<td>-0.663881</td>
<td>52</td>
<td>ENST00000369026</td>
<td>False</td>
<td>-0.299583</td>
<td>-1.092501</td>
<td>-0.963464</td>
</tr>
<tr>
<th>845</th>
<td>MCL1</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000143384</td>
<td>MCL1</td>
<td>ENST00000369026.3</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000001.11</td>
<td>...</td>
<td>NaN</td>
<td>Outside Target Window: 5-65%; poly(T):TTTT</td>
<td>-1.920374</td>
<td>-1.819985</td>
<td>5</td>
<td>ENST00000369026</td>
<td>False</td>
<td>-0.003507</td>
<td>-1.923881</td>
<td>-1.823491</td>
</tr>
<tr>
<th>846</th>
<td>MCL1</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000143384</td>
<td>MCL1</td>
<td>ENST00000369026.3</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000001.11</td>
<td>...</td>
<td>NaN</td>
<td>Spacing Violation: Too close to earlier pick a...</td>
<td>-1.101303</td>
<td>-1.295640</td>
<td>24</td>
<td>ENST00000369026</td>
<td>False</td>
<td>-0.285485</td>
<td>-1.386788</td>
<td>-1.581125</td>
</tr>
<tr>
<th>847</th>
<td>MCL1</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000143384</td>
<td>MCL1</td>
<td>ENST00000369026.3</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000001.11</td>
<td>...</td>
<td>NaN</td>
<td>Spacing Violation: Too close to earlier pick a...</td>
<td>-0.617431</td>
<td>-0.621436</td>
<td>30</td>
<td>ENST00000369026</td>
<td>False</td>
<td>-0.312348</td>
<td>-0.929779</td>
<td>-0.933784</td>
</tr>
<tr>
<th>848</th>
<td>MCL1</td>
<td>5</td>
<td>9606</td>
<td>ENSG00000143384</td>
<td>MCL1</td>
<td>ENST00000369026.3</td>
<td>NaN</td>
<td>CRISPRko</td>
<td>CDS</td>
<td>NC_000001.11</td>
<td>...</td>
<td>NaN</td>
<td>On-Target Efficacy Score < 0.2; Spacing Violat...</td>
<td>-0.586811</td>
<td>-0.664130</td>
<td>30</td>
<td>ENST00000369026</td>
<td>False</td>
<td>-0.312348</td>
<td>-0.899159</td>
<td>-0.976478</td>
</tr>
</tbody>
</table>
<p>849 rows × 61 columns</p>
</div>
We see that the predict function is querying the target data in addition
to making predictions.
Raw data
{
"_id": null,
"home_page": "https://github.com/gpp-rnd/rs3/tree/master/",
"name": "rs3",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.7",
"maintainer_email": "",
"keywords": "rs3,CRISPR,sgrna",
"author": "Peter Deweirdt",
"author_email": "petedeweirdt@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/fa/3e/4256ab2115f99e85677403f82cf6cdec6f6bda86359dd202f0b7568263d8/rs3-0.0.16.tar.gz",
"platform": null,
"description": "# Rule Set 3\n> Python package to predict the activity of CRISPR sgRNA sequences using Rule Set 3\n\n\n## Install\n\nYou can install the latest release of rs3 from pypi using\n\n`pip install rs3`\n\nFor mac users you may also have to brew install the OpenMP library\n\n`brew install libomp`\n\nor install lightgbm without Openmp\n\n`pip install lightgbm --install-option=--nomp`\n\nSee the [LightGBM documentation](https://github.com/microsoft/LightGBM/tree/master/python-package)\nfor more information\n\n## Documentation\n\nYou can see the complete documentation for Rule Set 3 [here](https://gpp-rnd.github.io/rs3/).\n\n## Quick Start\n\n### Sequence based model\n\nTo calculate Rule Set 3 (sequence) scores, import the predict_seq function from the seq module.\n\n```\nfrom rs3.seq import predict_seq\n```\n\nYou can store the 30mer context sequences you want to predict as a list.\n\n```\ncontext_seqs = ['GACGAAAGCGACAACGCGTTCATCCGGGCA', 'AGAAAACACTAGCATCCCCACCCGCGGACT']\n```\n\nYou can specify the\n[Hsu2013](https://www.nature.com/articles/nbt.2647) or\n[Chen2013](https://www.sciencedirect.com/science/article/pii/S0092867413015316?via%3Dihub)\nas the tracrRNA to score with.\nWe generally find any tracrRNA that does not have a T in the fifth position is better predicted with the Chen2013 input.\n\n```\npredict_seq(context_seqs, sequence_tracr='Hsu2013')\n```\n\n Calculating sequence-based features\n\n\n 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 2/2 [00:00<00:00, 15.04it/s]\n\n\n\n\n\n array([-0.90030944, 1.11451622])\n\n\n\n### Target based model\n\nTo get target scores, which use features at the endogenous target site to make predictions,\nyou must build or load feature matrices for the amino acid sequences, conservation scores, and protein domains.\n\nAs an example, we'll calculate target scores for 250 sgRNAs in the GeckoV2 library.\n\n```\nimport pandas as pd\nfrom rs3.predicttarg import predict_target\nfrom rs3.targetfeat import (add_target_columns,\n get_aa_subseq_df,\n get_protein_domain_features,\n get_conservation_features)\n```\n\n```\ndesign_df = pd.read_table('test_data/sgrna-designs.txt')\ndesign_df.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Input</th>\n <th>Quota</th>\n <th>Target Taxon</th>\n <th>Target Gene ID</th>\n <th>Target Gene Symbol</th>\n <th>Target Transcript</th>\n <th>Target Reference Coords</th>\n <th>Target Alias</th>\n <th>CRISPR Mechanism</th>\n <th>Target Domain</th>\n <th>...</th>\n <th>On-Target Rank Weight</th>\n <th>Off-Target Rank Weight</th>\n <th>Combined Rank</th>\n <th>Preselected As</th>\n <th>Matching Active Arrayed Oligos</th>\n <th>Matching Arrayed Constructs</th>\n <th>Pools Containing Matching Construct</th>\n <th>Pick Order</th>\n <th>Picking Round</th>\n <th>Picking Notes</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>1.0</td>\n <td>7</td>\n <td>GCAGATACAAGAGCAACTGA</td>\n <td>NaN</td>\n <td>BRDN0004619103</td>\n <td>NaN</td>\n <td>1</td>\n <td>0</td>\n <td>Preselected</td>\n </tr>\n <tr>\n <th>1</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>1.0</td>\n <td>48</td>\n <td>AAAACTGGCACGACCATCGC</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>2</td>\n <td>0</td>\n <td>Preselected</td>\n </tr>\n <tr>\n <th>2</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>1.0</td>\n <td>7</td>\n <td>AAAAGATTTGCGCACCCAAG</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>1</td>\n <td>0</td>\n <td>Preselected</td>\n </tr>\n <tr>\n <th>3</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>1.0</td>\n <td>8</td>\n <td>CTTTGACCCAGACATAATGG</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>2</td>\n <td>0</td>\n <td>Preselected</td>\n </tr>\n <tr>\n <th>4</th>\n <td>TOP1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198900</td>\n <td>TOP1</td>\n <td>ENST00000361337.3</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>1.0</td>\n <td>1</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>BRDN0001486452</td>\n <td>NaN</td>\n <td>2</td>\n <td>1</td>\n <td>NaN</td>\n </tr>\n </tbody>\n</table>\n<p>5 rows \u00d7 60 columns</p>\n</div>\n\n\n\nThroughout the analysis we will be using a core set of ID columns to merge the feature matrices. These ID columns\nshould uniquely identify an sgRNA and its target site.\n\n```\nid_cols = ['sgRNA Context Sequence', 'Target Cut Length', 'Target Transcript', 'Orientation']\n```\n\n#### Amino acid sequence input\n\nTo calculate the amino acid sequence matrix, you must first load the complete sequence from ensembl using the\n`build_transcript_aa_seq_df`. See the documentation for the `predicttarg` module for an example of how to\nuse this function.\n\nIn this example we will use amino acid sequences that have been precalculated using the `write_transcript_data`\nfunction in the `targetdata` module. Check out the documentation for this module for more information on\nhow to use this function.\n\nWe use pyarrow to read the written transcript data.\nThe stored transcripts are indexed by their Ensembl ID without the version number identifier.\nTo get this shortened version of the Ensembl ID use the `add_target_columns` function from the `targetfeat` module.\nThis function adds the 'Transcript Base' column as well as a column indicating the amino acid index ('AA Index')\nof the cut site. The 'AA Index' column will be used for merging with the amino acid translations.\n\n```\ndesign_targ_df = add_target_columns(design_df)\ndesign_targ_df.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Input</th>\n <th>Quota</th>\n <th>Target Taxon</th>\n <th>Target Gene ID</th>\n <th>Target Gene Symbol</th>\n <th>Target Transcript</th>\n <th>Target Reference Coords</th>\n <th>Target Alias</th>\n <th>CRISPR Mechanism</th>\n <th>Target Domain</th>\n <th>...</th>\n <th>Combined Rank</th>\n <th>Preselected As</th>\n <th>Matching Active Arrayed Oligos</th>\n <th>Matching Arrayed Constructs</th>\n <th>Pools Containing Matching Construct</th>\n <th>Pick Order</th>\n <th>Picking Round</th>\n <th>Picking Notes</th>\n <th>AA Index</th>\n <th>Transcript Base</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>7</td>\n <td>GCAGATACAAGAGCAACTGA</td>\n <td>NaN</td>\n <td>BRDN0004619103</td>\n <td>NaN</td>\n <td>1</td>\n <td>0</td>\n <td>Preselected</td>\n <td>64</td>\n <td>ENST00000259457</td>\n </tr>\n <tr>\n <th>1</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>48</td>\n <td>AAAACTGGCACGACCATCGC</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>2</td>\n <td>0</td>\n <td>Preselected</td>\n <td>46</td>\n <td>ENST00000259457</td>\n </tr>\n <tr>\n <th>2</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>7</td>\n <td>AAAAGATTTGCGCACCCAAG</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>1</td>\n <td>0</td>\n <td>Preselected</td>\n <td>106</td>\n <td>ENST00000394249</td>\n </tr>\n <tr>\n <th>3</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>8</td>\n <td>CTTTGACCCAGACATAATGG</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>2</td>\n <td>0</td>\n <td>Preselected</td>\n <td>263</td>\n <td>ENST00000394249</td>\n </tr>\n <tr>\n <th>4</th>\n <td>TOP1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198900</td>\n <td>TOP1</td>\n <td>ENST00000361337.3</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>BRDN0001486452</td>\n <td>NaN</td>\n <td>2</td>\n <td>1</td>\n <td>NaN</td>\n <td>140</td>\n <td>ENST00000361337</td>\n </tr>\n </tbody>\n</table>\n<p>5 rows \u00d7 62 columns</p>\n</div>\n\n\n\n```\ntranscript_bases = design_targ_df['Transcript Base'].unique()\ntranscript_bases[0:5]\n```\n\n\n\n\n array(['ENST00000259457', 'ENST00000394249', 'ENST00000361337',\n 'ENST00000368328', 'ENST00000610426'], dtype=object)\n\n\n\n```\naa_seq_df = pd.read_parquet('test_data/target_data/aa_seqs.pq', engine='pyarrow',\n filters=[[('Transcript Base', 'in', transcript_bases)]])\naa_seq_df.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Target Transcript</th>\n <th>Target Total Length</th>\n <th>Transcript Base</th>\n <th>version</th>\n <th>seq</th>\n <th>molecule</th>\n <th>desc</th>\n <th>id</th>\n <th>AA len</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>ENST00000259457.8</td>\n <td>834</td>\n <td>ENST00000259457</td>\n <td>3</td>\n <td>MAAVSVYAPPVGGFSFDNCRRNAVLEADFAKRGYKLPKVRKTGTTI...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000259457</td>\n <td>277</td>\n </tr>\n <tr>\n <th>1</th>\n <td>ENST00000394249.8</td>\n <td>1863</td>\n <td>ENST00000394249</td>\n <td>3</td>\n <td>MRRSEVLAEESIVCLQKALNHLREIWELIGIPEDQRLQRTEVVKKH...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000377793</td>\n <td>620</td>\n </tr>\n <tr>\n <th>2</th>\n <td>ENST00000361337.3</td>\n <td>2298</td>\n <td>ENST00000361337</td>\n <td>2</td>\n <td>MSGDHLHNDSQIEADFRLNDSHKHKDKHKDREHRHKEHKKEKDREK...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000354522</td>\n <td>765</td>\n </tr>\n <tr>\n <th>3</th>\n <td>ENST00000368328.5</td>\n <td>267</td>\n <td>ENST00000368328</td>\n <td>4</td>\n <td>MALSTIVSQRKQIKRKAPRGFLKRVFKRKKPQLRLEKSGDLLVHLN...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000357311</td>\n <td>88</td>\n </tr>\n <tr>\n <th>4</th>\n <td>ENST00000610426.5</td>\n <td>783</td>\n <td>ENST00000610426</td>\n <td>1</td>\n <td>MPQNEYIELHRKRYGYRLDYHEKKRKKESREAHERSKKAKKMIGLK...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000483484</td>\n <td>260</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\nFrom the complete transcript translations, we extract an amino acid subsequence as input to our model. The subsequence\nis centered around the amino acid encoded by the nucleotide preceding the cut site in the direction of transcription.\nThis is the nucleotide that corresponds to the 'Target Cut Length' in a CRISPick design file.\nWe take 16 amino acids on either side of the cut site for a total sequence length of 33.\n\nThe `get_aa_subseq_df` from the `targetfeat` module will calculate these subsequences\nfrom the complete amino acid sequences.\n\n```\n\naa_subseq_df = get_aa_subseq_df(sg_designs=design_targ_df, aa_seq_df=aa_seq_df, width=16,\n id_cols=id_cols)\naa_subseq_df.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Target Transcript</th>\n <th>Target Total Length</th>\n <th>Transcript Base</th>\n <th>version</th>\n <th>seq</th>\n <th>molecule</th>\n <th>desc</th>\n <th>id</th>\n <th>AA len</th>\n <th>Target Cut Length</th>\n <th>Orientation</th>\n <th>sgRNA Context Sequence</th>\n <th>AA Index</th>\n <th>extended_seq</th>\n <th>AA 0-Indexed</th>\n <th>AA 0-Indexed padded</th>\n <th>seq_start</th>\n <th>seq_end</th>\n <th>AA Subsequence</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>ENST00000259457.8</td>\n <td>834</td>\n <td>ENST00000259457</td>\n <td>3</td>\n <td>MAAVSVYAPPVGGFSFDNCRRNAVLEADFAKRGYKLPKVRKTGTTI...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000259457</td>\n <td>277</td>\n <td>191</td>\n <td>sense</td>\n <td>TGGAGCAGATACAAGAGCAACTGAAGGGAT</td>\n <td>64</td>\n <td>-----------------MAAVSVYAPPVGGFSFDNCRRNAVLEADF...</td>\n <td>63</td>\n <td>80</td>\n <td>64</td>\n <td>96</td>\n <td>GVVYKDGIVLGADTRATEGMVVADKNCSKIHFI</td>\n </tr>\n <tr>\n <th>1</th>\n <td>ENST00000259457.8</td>\n <td>834</td>\n <td>ENST00000259457</td>\n <td>3</td>\n <td>MAAVSVYAPPVGGFSFDNCRRNAVLEADFAKRGYKLPKVRKTGTTI...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000259457</td>\n <td>277</td>\n <td>137</td>\n <td>sense</td>\n <td>CCGGAAAACTGGCACGACCATCGCTGGGGT</td>\n <td>46</td>\n <td>-----------------MAAVSVYAPPVGGFSFDNCRRNAVLEADF...</td>\n <td>45</td>\n <td>62</td>\n <td>46</td>\n <td>78</td>\n <td>AKRGYKLPKVRKTGTTIAGVVYKDGIVLGADTR</td>\n </tr>\n <tr>\n <th>2</th>\n <td>ENST00000394249.8</td>\n <td>1863</td>\n <td>ENST00000394249</td>\n <td>3</td>\n <td>MRRSEVLAEESIVCLQKALNHLREIWELIGIPEDQRLQRTEVVKKH...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000377793</td>\n <td>620</td>\n <td>316</td>\n <td>sense</td>\n <td>TAGAAAAAGATTTGCGCACCCAAGTGGAAT</td>\n <td>106</td>\n <td>-----------------MRRSEVLAEESIVCLQKALNHLREIWELI...</td>\n <td>105</td>\n <td>122</td>\n <td>106</td>\n <td>138</td>\n <td>EEGETTILQLEKDLRTQVELMRKQKKERKQELK</td>\n </tr>\n <tr>\n <th>3</th>\n <td>ENST00000394249.8</td>\n <td>1863</td>\n <td>ENST00000394249</td>\n <td>3</td>\n <td>MRRSEVLAEESIVCLQKALNHLREIWELIGIPEDQRLQRTEVVKKH...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000377793</td>\n <td>620</td>\n <td>787</td>\n <td>antisense</td>\n <td>TGGCCTTTGACCCAGACATAATGGTGGCCA</td>\n <td>263</td>\n <td>-----------------MRRSEVLAEESIVCLQKALNHLREIWELI...</td>\n <td>262</td>\n <td>279</td>\n <td>263</td>\n <td>295</td>\n <td>WDRLQIPEEEREAVATIMSGSKAKVRKALQLEV</td>\n </tr>\n <tr>\n <th>4</th>\n <td>ENST00000361337.3</td>\n <td>2298</td>\n <td>ENST00000361337</td>\n <td>2</td>\n <td>MSGDHLHNDSQIEADFRLNDSHKHKDKHKDREHRHKEHKKEKDREK...</td>\n <td>protein</td>\n <td>None</td>\n <td>ENSP00000354522</td>\n <td>765</td>\n <td>420</td>\n <td>antisense</td>\n <td>AAATACTCACTCATCCTCATCTCGAGGTCT</td>\n <td>140</td>\n <td>-----------------MSGDHLHNDSQIEADFRLNDSHKHKDKHK...</td>\n <td>139</td>\n <td>156</td>\n <td>140</td>\n <td>172</td>\n <td>GYFVPPKEDIKPLKRPRDEDDADYKPKKIKTED</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\n#### Lite Scores\n\nYou now have all the information you need to calculate \"lite\" Target Scores, which are less data intensive than complete\ntarget scores, with the `predict_target` function from the `predicttarg` module.\n\n```\nlite_predictions = predict_target(design_df=design_df,\n aa_subseq_df=aa_subseq_df)\ndesign_df['Target Score Lite'] = lite_predictions\ndesign_df.head()\n```\n\n /opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.\n warnings.warn(\n /opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.\n warnings.warn(\n\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Input</th>\n <th>Quota</th>\n <th>Target Taxon</th>\n <th>Target Gene ID</th>\n <th>Target Gene Symbol</th>\n <th>Target Transcript</th>\n <th>Target Reference Coords</th>\n <th>Target Alias</th>\n <th>CRISPR Mechanism</th>\n <th>Target Domain</th>\n <th>...</th>\n <th>Off-Target Rank Weight</th>\n <th>Combined Rank</th>\n <th>Preselected As</th>\n <th>Matching Active Arrayed Oligos</th>\n <th>Matching Arrayed Constructs</th>\n <th>Pools Containing Matching Construct</th>\n <th>Pick Order</th>\n <th>Picking Round</th>\n <th>Picking Notes</th>\n <th>Target Score Lite</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>7</td>\n <td>GCAGATACAAGAGCAACTGA</td>\n <td>NaN</td>\n <td>BRDN0004619103</td>\n <td>NaN</td>\n <td>1</td>\n <td>0</td>\n <td>Preselected</td>\n <td>0.012467</td>\n </tr>\n <tr>\n <th>1</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>48</td>\n <td>AAAACTGGCACGACCATCGC</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>2</td>\n <td>0</td>\n <td>Preselected</td>\n <td>0.048338</td>\n </tr>\n <tr>\n <th>2</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>7</td>\n <td>AAAAGATTTGCGCACCCAAG</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>1</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.129234</td>\n </tr>\n <tr>\n <th>3</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>8</td>\n <td>CTTTGACCCAGACATAATGG</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>2</td>\n <td>0</td>\n <td>Preselected</td>\n <td>0.061647</td>\n </tr>\n <tr>\n <th>4</th>\n <td>TOP1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198900</td>\n <td>TOP1</td>\n <td>ENST00000361337.3</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1.0</td>\n <td>1</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>BRDN0001486452</td>\n <td>NaN</td>\n <td>2</td>\n <td>1</td>\n <td>NaN</td>\n <td>-0.009100</td>\n </tr>\n </tbody>\n</table>\n<p>5 rows \u00d7 61 columns</p>\n</div>\n\n\n\nIf you would like to calculate full target scores then follow the sections below.\n\n#### Protein domain input\n\nTo calculate full target scores you will also need inputs for protein domains and conservation.\n\nThe protein domain input should have 16 binary columns for 16 different protein domain sources in addition to the\n`id_cols`. The protein domain sources are 'Pfam', 'PANTHER', 'HAMAP', 'SuperFamily', 'TIGRfam', 'ncoils', 'Gene3D',\n'Prosite_patterns', 'Seg', 'SignalP', 'TMHMM', 'MobiDBLite', 'PIRSF', 'PRINTS', 'Smart', 'Prosite_profiles'.\nThese columns should be kept in order when inputting for scoring.\n\nIn this example we will load the protein domain information from a parquet file, which was written\nusing `write_transcript_data` function in the `targetdata` module. You can also query transcript data on the fly,\nby using the `build_translation_overlap_df` function. See the documentation for the `predicttarg` module for more\ninformation on how to do this.\n\n```\ndomain_df = pd.read_parquet('test_data/target_data/protein_domains.pq', engine='pyarrow',\n filters=[[('Transcript Base', 'in', transcript_bases)]])\ndomain_df.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>type</th>\n <th>cigar_string</th>\n <th>id</th>\n <th>hit_end</th>\n <th>feature_type</th>\n <th>description</th>\n <th>seq_region_name</th>\n <th>end</th>\n <th>hit_start</th>\n <th>translation_id</th>\n <th>interpro</th>\n <th>hseqname</th>\n <th>Transcript Base</th>\n <th>align_type</th>\n <th>start</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>Pfam</td>\n <td></td>\n <td>PF12465</td>\n <td>36</td>\n <td>protein_feature</td>\n <td>Proteasome beta subunit, C-terminal</td>\n <td>ENSP00000259457</td>\n <td>271</td>\n <td>1</td>\n <td>976188</td>\n <td>IPR024689</td>\n <td>PF12465</td>\n <td>ENST00000259457</td>\n <td>None</td>\n <td>235</td>\n </tr>\n <tr>\n <th>1</th>\n <td>Pfam</td>\n <td></td>\n <td>PF00227</td>\n <td>190</td>\n <td>protein_feature</td>\n <td>Proteasome, subunit alpha/beta</td>\n <td>ENSP00000259457</td>\n <td>221</td>\n <td>2</td>\n <td>976188</td>\n <td>IPR001353</td>\n <td>PF00227</td>\n <td>ENST00000259457</td>\n <td>None</td>\n <td>41</td>\n </tr>\n <tr>\n <th>2</th>\n <td>PRINTS</td>\n <td></td>\n <td>PR00141</td>\n <td>0</td>\n <td>protein_feature</td>\n <td>Peptidase T1A, proteasome beta-subunit</td>\n <td>ENSP00000259457</td>\n <td>66</td>\n <td>0</td>\n <td>976188</td>\n <td>IPR000243</td>\n <td>PR00141</td>\n <td>ENST00000259457</td>\n <td>None</td>\n <td>51</td>\n </tr>\n <tr>\n <th>3</th>\n <td>PRINTS</td>\n <td></td>\n <td>PR00141</td>\n <td>0</td>\n <td>protein_feature</td>\n <td>Peptidase T1A, proteasome beta-subunit</td>\n <td>ENSP00000259457</td>\n <td>182</td>\n <td>0</td>\n <td>976188</td>\n <td>IPR000243</td>\n <td>PR00141</td>\n <td>ENST00000259457</td>\n <td>None</td>\n <td>171</td>\n </tr>\n <tr>\n <th>4</th>\n <td>PRINTS</td>\n <td></td>\n <td>PR00141</td>\n <td>0</td>\n <td>protein_feature</td>\n <td>Peptidase T1A, proteasome beta-subunit</td>\n <td>ENSP00000259457</td>\n <td>193</td>\n <td>0</td>\n <td>976188</td>\n <td>IPR000243</td>\n <td>PR00141</td>\n <td>ENST00000259457</td>\n <td>None</td>\n <td>182</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\nNow to transform the `domain_df` into a wide form for model input, we use the `get_protein_domain_features` function\nfrom the `targetfeat` module.\n\n```\ndomain_feature_df = get_protein_domain_features(design_targ_df, domain_df, id_cols=id_cols)\ndomain_feature_df.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>sgRNA Context Sequence</th>\n <th>Target Cut Length</th>\n <th>Target Transcript</th>\n <th>Orientation</th>\n <th>Pfam</th>\n <th>PANTHER</th>\n <th>HAMAP</th>\n <th>SuperFamily</th>\n <th>TIGRfam</th>\n <th>ncoils</th>\n <th>Gene3D</th>\n <th>Prosite_patterns</th>\n <th>Seg</th>\n <th>SignalP</th>\n <th>TMHMM</th>\n <th>MobiDBLite</th>\n <th>PIRSF</th>\n <th>PRINTS</th>\n <th>Smart</th>\n <th>Prosite_profiles</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>AAAAGAATGATGAAAAGACACCACAGGGAG</td>\n <td>244</td>\n <td>ENST00000610426.5</td>\n <td>sense</td>\n <td>1</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n </tr>\n <tr>\n <th>1</th>\n <td>AAAAGAGCCATGAATCTAAACATCAGGAAT</td>\n <td>640</td>\n <td>ENST00000223073.6</td>\n <td>sense</td>\n <td>0</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n </tr>\n <tr>\n <th>2</th>\n <td>AAAAGCGCCAAATGGCCCGAGAATTGGGAG</td>\n <td>709</td>\n <td>ENST00000331923.9</td>\n <td>sense</td>\n <td>0</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n </tr>\n <tr>\n <th>3</th>\n <td>AAACAGAAAAAGTTAAAATCACCAAGGTGT</td>\n <td>496</td>\n <td>ENST00000283882.4</td>\n <td>sense</td>\n <td>0</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n </tr>\n <tr>\n <th>4</th>\n <td>AAACAGATGGAAGATGCTTACCGGGGGACC</td>\n <td>132</td>\n <td>ENST00000393047.8</td>\n <td>sense</td>\n <td>0</td>\n <td>1</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n <td>0</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\nFor input into the `predict_target` function, the `domain_feature_df` should have the `id_cols` as well as\ncolumns for each of the 16 protein domain features.\n\n#### Conservation input\n\nFinally, for the full target model you need to calculate conservation features.\nThe conservation features represent conservation across evolutionary time at the sgRNA cut site and are quantified\nusing PhyloP scores. These scores are available for download by the UCSC genome browser\nfor [hg38](https://hgdownload.soe.ucsc.edu/goldenPath/hg38/database/) (phyloP100way),\nand [mm39](https://hgdownload.soe.ucsc.edu/goldenPath/mm39/database/) (phyloP35way).\n\nWithin this package we query conservation scores using the UCSC genome browser's\n[REST API](http://genome.ucsc.edu/goldenPath/help/api.html).\nTo get conservation scores, you can use the `build_conservation_df` function from the `targetdata` module.\nHere we load conservation scores, which were written to parquet using the `write_conservation_data` function from the\n`targetdata` module.\n\n```\nconservation_df = pd.read_parquet('test_data/target_data/conservation.pq', engine='pyarrow',\n filters=[[('Transcript Base', 'in', transcript_bases)]])\nconservation_df.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>exon_id</th>\n <th>genomic position</th>\n <th>conservation</th>\n <th>Transcript Base</th>\n <th>target position</th>\n <th>chromosome</th>\n <th>genome</th>\n <th>translation length</th>\n <th>Target Transcript</th>\n <th>Strand of Target</th>\n <th>Target Total Length</th>\n <th>ranked_conservation</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>ENSE00001866322</td>\n <td>124415425.0</td>\n <td>6.46189</td>\n <td>ENST00000259457</td>\n <td>1</td>\n <td>9</td>\n <td>hg38</td>\n <td>277</td>\n <td>ENST00000259457.8</td>\n <td>-</td>\n <td>834</td>\n <td>0.639089</td>\n </tr>\n <tr>\n <th>1</th>\n <td>ENSE00001866322</td>\n <td>124415424.0</td>\n <td>7.48071</td>\n <td>ENST00000259457</td>\n <td>2</td>\n <td>9</td>\n <td>hg38</td>\n <td>277</td>\n <td>ENST00000259457.8</td>\n <td>-</td>\n <td>834</td>\n <td>0.686451</td>\n </tr>\n <tr>\n <th>2</th>\n <td>ENSE00001866322</td>\n <td>124415423.0</td>\n <td>6.36001</td>\n <td>ENST00000259457</td>\n <td>3</td>\n <td>9</td>\n <td>hg38</td>\n <td>277</td>\n <td>ENST00000259457.8</td>\n <td>-</td>\n <td>834</td>\n <td>0.622902</td>\n </tr>\n <tr>\n <th>3</th>\n <td>ENSE00001866322</td>\n <td>124415422.0</td>\n <td>6.36001</td>\n <td>ENST00000259457</td>\n <td>4</td>\n <td>9</td>\n <td>hg38</td>\n <td>277</td>\n <td>ENST00000259457.8</td>\n <td>-</td>\n <td>834</td>\n <td>0.622902</td>\n </tr>\n <tr>\n <th>4</th>\n <td>ENSE00001866322</td>\n <td>124415421.0</td>\n <td>8.09200</td>\n <td>ENST00000259457</td>\n <td>5</td>\n <td>9</td>\n <td>hg38</td>\n <td>277</td>\n <td>ENST00000259457.8</td>\n <td>-</td>\n <td>834</td>\n <td>0.870504</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\nWe normalize conservation scores to a within-gene percent rank, in the 'ranked_conservation' column,\nin order to make scores comparable across genes and genomes. Note that a rank of 0 indicates the\nleast conserved nucleotide and a rank of 1 indicates the most conserved.\n\nTo featurize the conservation scores, we average across a window of 4 and 32 nucleotides\ncentered around the nucleotide preceding the cut site in the direction of transcription.\nNote that this nucleotide is the 2nd nucleotide in the window of 4 and the 16th nucleotide in the window of 32.\n\nWe use the `get_conservation_features` function from the `targetfeat` module to get these features from the\n`conservation_df`.\n\nFor the `predict_targ` function, we need the `id_cols` and the columns 'cons_4' and 'cons_32' in the\n`conservation_feature_df`.\n\n```\nconservation_feature_df = get_conservation_features(design_targ_df, conservation_df,\n small_width=2, large_width=16,\n conservation_column='ranked_conservation',\n id_cols=id_cols)\nconservation_feature_df\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>sgRNA Context Sequence</th>\n <th>Target Cut Length</th>\n <th>Target Transcript</th>\n <th>Orientation</th>\n <th>cons_4</th>\n <th>cons_32</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>AAAAGAATGATGAAAAGACACCACAGGGAG</td>\n <td>244</td>\n <td>ENST00000610426.5</td>\n <td>sense</td>\n <td>0.218231</td>\n <td>0.408844</td>\n </tr>\n <tr>\n <th>1</th>\n <td>AAAAGAGCCATGAATCTAAACATCAGGAAT</td>\n <td>640</td>\n <td>ENST00000223073.6</td>\n <td>sense</td>\n <td>0.129825</td>\n <td>0.278180</td>\n </tr>\n <tr>\n <th>2</th>\n <td>AAAAGCGCCAAATGGCCCGAGAATTGGGAG</td>\n <td>709</td>\n <td>ENST00000331923.9</td>\n <td>sense</td>\n <td>0.470906</td>\n <td>0.532305</td>\n </tr>\n <tr>\n <th>3</th>\n <td>AAACAGAAAAAGTTAAAATCACCAAGGTGT</td>\n <td>496</td>\n <td>ENST00000283882.4</td>\n <td>sense</td>\n <td>0.580556</td>\n <td>0.602708</td>\n </tr>\n <tr>\n <th>4</th>\n <td>AAACAGATGGAAGATGCTTACCGGGGGACC</td>\n <td>132</td>\n <td>ENST00000393047.8</td>\n <td>sense</td>\n <td>0.283447</td>\n <td>0.414293</td>\n </tr>\n <tr>\n <th>...</th>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n </tr>\n <tr>\n <th>395</th>\n <td>TTTGATTGCATTAAGGTTGGACTCTGGATT</td>\n <td>246</td>\n <td>ENST00000249269.9</td>\n <td>sense</td>\n <td>0.580612</td>\n <td>0.618707</td>\n </tr>\n <tr>\n <th>396</th>\n <td>TTTGCCCACAGCTCCAAAGCATCGCGGAGA</td>\n <td>130</td>\n <td>ENST00000227618.8</td>\n <td>sense</td>\n <td>0.323770</td>\n <td>0.416368</td>\n </tr>\n <tr>\n <th>397</th>\n <td>TTTTACAGTGCGATGTATGATGTATGGCTT</td>\n <td>119</td>\n <td>ENST00000338366.6</td>\n <td>sense</td>\n <td>0.788000</td>\n <td>0.537417</td>\n </tr>\n <tr>\n <th>398</th>\n <td>TTTTGGATCTCGTAGTGATTCAAGAGGGAA</td>\n <td>233</td>\n <td>ENST00000629496.3</td>\n <td>sense</td>\n <td>0.239630</td>\n <td>0.347615</td>\n </tr>\n <tr>\n <th>399</th>\n <td>TTTTTGTTACTACAGGTTCGCTGCTGGGAA</td>\n <td>201</td>\n <td>ENST00000395840.6</td>\n <td>sense</td>\n <td>0.693767</td>\n <td>0.639044</td>\n </tr>\n </tbody>\n</table>\n<p>400 rows \u00d7 6 columns</p>\n</div>\n\n\n\n#### Full Target Scores\n\nIn order to calculate Target Scores you must input the feature matrices and design_df to the `predict_target`\nfunction from the `predicttarg` module.\n\n```\ntarget_predictions = predict_target(design_df=design_df,\n aa_subseq_df=aa_subseq_df,\n domain_feature_df=domain_feature_df,\n conservation_feature_df=conservation_feature_df,\n id_cols=id_cols)\ndesign_df['Target Score'] = target_predictions\ndesign_df.head()\n```\n\n /opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.\n warnings.warn(\n /opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.\n warnings.warn(\n\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Input</th>\n <th>Quota</th>\n <th>Target Taxon</th>\n <th>Target Gene ID</th>\n <th>Target Gene Symbol</th>\n <th>Target Transcript</th>\n <th>Target Reference Coords</th>\n <th>Target Alias</th>\n <th>CRISPR Mechanism</th>\n <th>Target Domain</th>\n <th>...</th>\n <th>Combined Rank</th>\n <th>Preselected As</th>\n <th>Matching Active Arrayed Oligos</th>\n <th>Matching Arrayed Constructs</th>\n <th>Pools Containing Matching Construct</th>\n <th>Pick Order</th>\n <th>Picking Round</th>\n <th>Picking Notes</th>\n <th>Target Score Lite</th>\n <th>Target Score</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>7</td>\n <td>GCAGATACAAGAGCAACTGA</td>\n <td>NaN</td>\n <td>BRDN0004619103</td>\n <td>NaN</td>\n <td>1</td>\n <td>0</td>\n <td>Preselected</td>\n <td>0.012467</td>\n <td>0.152037</td>\n </tr>\n <tr>\n <th>1</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>48</td>\n <td>AAAACTGGCACGACCATCGC</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>2</td>\n <td>0</td>\n <td>Preselected</td>\n <td>0.048338</td>\n <td>0.064880</td>\n </tr>\n <tr>\n <th>2</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>7</td>\n <td>AAAAGATTTGCGCACCCAAG</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>1</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.129234</td>\n <td>-0.063012</td>\n </tr>\n <tr>\n <th>3</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>8</td>\n <td>CTTTGACCCAGACATAATGG</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>2</td>\n <td>0</td>\n <td>Preselected</td>\n <td>0.061647</td>\n <td>-0.126357</td>\n </tr>\n <tr>\n <th>4</th>\n <td>TOP1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198900</td>\n <td>TOP1</td>\n <td>ENST00000361337.3</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>BRDN0001486452</td>\n <td>NaN</td>\n <td>2</td>\n <td>1</td>\n <td>NaN</td>\n <td>-0.009100</td>\n <td>-0.234410</td>\n </tr>\n </tbody>\n</table>\n<p>5 rows \u00d7 62 columns</p>\n</div>\n\n\n\nTarget Scores can be added directly to the sequence scores for your final Rule Set 3 predictions.\n\n### Predict Function\n\nIf you don't want to generate the target matrices themselves, you can use the `predict` function from\nthe `predict` module.\n\n```\nfrom rs3.predict import predict\nimport matplotlib.pyplot as plt\nimport gpplot\nimport seaborn as sns\n```\n\n#### Preloaded data\n\nIn this first example with the `predict` function, we calculate predictions for GeckoV2 sgRNAs.\n\nIn this example the amino acid sequences, protein domains and conservation scores were prequeried using the\n`write_transcript_data` and `write_conservation_data` functions from the targetdata module.\nPre-querying these data can be helpful for large scale design runs.\n\nYou can also use the `predict` function without pre-querying and calculate\nscores on the fly. You can see an example of this in the next section.\n\nThe `predict` function allows for parallel computation\nfor querying databases (`n_jobs_min`) and featurizing sgRNAs (`n_jobs_max`).\nWe recommend keeping `n_jobs_min` set to 1 or 2, as the APIs limit the amount of queries per hour.\n\n```\ndesign_df = pd.read_table('test_data/sgrna-designs.txt')\nimport multiprocessing\nmax_n_jobs = multiprocessing.cpu_count()\n```\n\n```\nscored_designs = predict(design_df, tracr=['Hsu2013', 'Chen2013'], target=True,\n n_jobs_min=2, n_jobs_max=max_n_jobs,\n aa_seq_file='./test_data/target_data/aa_seqs.pq',\n domain_file='./test_data/target_data/protein_domains.pq',\n conservatin_file='./test_data/target_data/conservation.pq',\n lite=False)\nscored_designs.head()\n```\n\n Calculating sequence-based features\n\n\n 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 400/400 [00:05<00:00, 68.98it/s] \n\n\n Calculating sequence-based features\n\n\n 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 400/400 [00:01<00:00, 229.85it/s]\n /opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.\n warnings.warn(\n /opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.\n warnings.warn(\n\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Input</th>\n <th>Quota</th>\n <th>Target Taxon</th>\n <th>Target Gene ID</th>\n <th>Target Gene Symbol</th>\n <th>Target Transcript</th>\n <th>Target Reference Coords</th>\n <th>Target Alias</th>\n <th>CRISPR Mechanism</th>\n <th>Target Domain</th>\n <th>...</th>\n <th>Picking Round</th>\n <th>Picking Notes</th>\n <th>RS3 Sequence Score (Hsu2013 tracr)</th>\n <th>RS3 Sequence Score (Chen2013 tracr)</th>\n <th>AA Index</th>\n <th>Transcript Base</th>\n <th>Missing conservation information</th>\n <th>Target Score</th>\n <th>RS3 Sequence (Hsu2013 tracr) + Target Score</th>\n <th>RS3 Sequence (Chen2013 tracr) + Target Score</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>0.787640</td>\n <td>0.559345</td>\n <td>64</td>\n <td>ENST00000259457</td>\n <td>False</td>\n <td>0.152037</td>\n <td>0.939676</td>\n <td>0.711381</td>\n </tr>\n <tr>\n <th>1</th>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>PSMB7</td>\n <td>ENST00000259457.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.294126</td>\n <td>-0.181437</td>\n <td>46</td>\n <td>ENST00000259457</td>\n <td>False</td>\n <td>0.064880</td>\n <td>-0.229246</td>\n <td>-0.116557</td>\n </tr>\n <tr>\n <th>2</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.043418</td>\n <td>-0.220434</td>\n <td>106</td>\n <td>ENST00000394249</td>\n <td>False</td>\n <td>-0.063012</td>\n <td>-0.106429</td>\n <td>-0.283446</td>\n </tr>\n <tr>\n <th>3</th>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>PRC1</td>\n <td>ENST00000394249.8</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>0.759256</td>\n <td>0.453469</td>\n <td>263</td>\n <td>ENST00000394249</td>\n <td>False</td>\n <td>-0.126357</td>\n <td>0.632899</td>\n <td>0.327112</td>\n </tr>\n <tr>\n <th>4</th>\n <td>TOP1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198900</td>\n <td>TOP1</td>\n <td>ENST00000361337.3</td>\n <td>NaN</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>...</td>\n <td>1</td>\n <td>NaN</td>\n <td>0.424001</td>\n <td>-0.197035</td>\n <td>140</td>\n <td>ENST00000361337</td>\n <td>False</td>\n <td>-0.234410</td>\n <td>0.189591</td>\n <td>-0.431445</td>\n </tr>\n </tbody>\n</table>\n<p>5 rows \u00d7 68 columns</p>\n</div>\n\n\n\nHere are the details for the keyword arguments of the above function\n\n* `tracr` - tracr to calculate scores for. If a list is supplied instead of a string, scores will be calculated for both tracrs\n* `target` - boolean indicating whether to calculate target scores\n* `n_jobs_min`, `n_jobs_max` - number of cpus to use for parallel computation\n* `aa_seq_file`, `domain_file`, `conservatin_file` - precalculated parquet files. Optional inputs as these features can also be calculated on the fly\n* `lite` - boolean indicating whether to calculate lite target scores\n\nBy listing both tracrRNAs `tracr=['Hsu2013', 'Chen2013']` and setting `target=True`,\nwe calculate 5 unique scores: one sequence score for each tracr, the target score,\nand the sequence scores plus the target score.\n\nWe can compare these predictions against the observed activity from GeckoV2\n\n```\ngecko_activity = pd.read_csv('test_data/Aguirre2016_activity.csv')\ngecko_activity.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>sgRNA Sequence</th>\n <th>sgRNA Context Sequence</th>\n <th>Target Gene Symbol</th>\n <th>Target Cut %</th>\n <th>avg_mean_centered_neg_lfc</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>AAAAAACTTACCCCTTTGAC</td>\n <td>AAAAAAAAAACTTACCCCTTTGACTGGCCA</td>\n <td>CPSF6</td>\n <td>22.2</td>\n <td>-1.139819</td>\n </tr>\n <tr>\n <th>1</th>\n <td>AAAAACATTATCATTGAGCC</td>\n <td>TGGCAAAAACATTATCATTGAGCCTGGATT</td>\n <td>SKA3</td>\n <td>62.3</td>\n <td>-0.793055</td>\n </tr>\n <tr>\n <th>2</th>\n <td>AAAAAGAGATTGTCAAATCA</td>\n <td>TATGAAAAAGAGATTGTCAAATCAAGGTAG</td>\n <td>AQR</td>\n <td>3.8</td>\n <td>0.946453</td>\n </tr>\n <tr>\n <th>3</th>\n <td>AAAAAGCATCTCTAGAAATA</td>\n <td>TTCAAAAAAGCATCTCTAGAAATATGGTCC</td>\n <td>ZNHIT6</td>\n <td>61.7</td>\n <td>-0.429590</td>\n </tr>\n <tr>\n <th>4</th>\n <td>AAAAAGCGAGATACCCGAAA</td>\n <td>AAAAAAAAAGCGAGATACCCGAAAAGGCAG</td>\n <td>ABCF1</td>\n <td>9.4</td>\n <td>0.734196</td>\n </tr>\n </tbody>\n</table>\n</div>\n\n\n\n```\ngecko_activity_scores = (gecko_activity.merge(scored_designs,\n how='inner',\n on=['sgRNA Sequence', 'sgRNA Context Sequence',\n 'Target Gene Symbol', 'Target Cut %']))\ngecko_activity_scores.head()\n```\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>sgRNA Sequence</th>\n <th>sgRNA Context Sequence</th>\n <th>Target Gene Symbol</th>\n <th>Target Cut %</th>\n <th>avg_mean_centered_neg_lfc</th>\n <th>Input</th>\n <th>Quota</th>\n <th>Target Taxon</th>\n <th>Target Gene ID</th>\n <th>Target Transcript</th>\n <th>...</th>\n <th>Picking Round</th>\n <th>Picking Notes</th>\n <th>RS3 Sequence Score (Hsu2013 tracr)</th>\n <th>RS3 Sequence Score (Chen2013 tracr)</th>\n <th>AA Index</th>\n <th>Transcript Base</th>\n <th>Missing conservation information</th>\n <th>Target Score</th>\n <th>RS3 Sequence (Hsu2013 tracr) + Target Score</th>\n <th>RS3 Sequence (Chen2013 tracr) + Target Score</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>AAAACTGGCACGACCATCGC</td>\n <td>CCGGAAAACTGGCACGACCATCGCTGGGGT</td>\n <td>PSMB7</td>\n <td>16.4</td>\n <td>-1.052943</td>\n <td>PSMB7</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000136930</td>\n <td>ENST00000259457.8</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.294126</td>\n <td>-0.181437</td>\n <td>46</td>\n <td>ENST00000259457</td>\n <td>False</td>\n <td>0.064880</td>\n <td>-0.229246</td>\n <td>-0.116557</td>\n </tr>\n <tr>\n <th>1</th>\n <td>AAAAGATTTGCGCACCCAAG</td>\n <td>TAGAAAAAGATTTGCGCACCCAAGTGGAAT</td>\n <td>PRC1</td>\n <td>17.0</td>\n <td>0.028674</td>\n <td>PRC1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198901</td>\n <td>ENST00000394249.8</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.043418</td>\n <td>-0.220434</td>\n <td>106</td>\n <td>ENST00000394249</td>\n <td>False</td>\n <td>-0.063012</td>\n <td>-0.106429</td>\n <td>-0.283446</td>\n </tr>\n <tr>\n <th>2</th>\n <td>AAAAGTCCAAGCATAGCAAC</td>\n <td>CGGGAAAAGTCCAAGCATAGCAACAGGTAA</td>\n <td>TOP1</td>\n <td>6.5</td>\n <td>0.195309</td>\n <td>TOP1</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000198900</td>\n <td>ENST00000361337.3</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.294127</td>\n <td>-0.022951</td>\n <td>50</td>\n <td>ENST00000361337</td>\n <td>False</td>\n <td>-0.354708</td>\n <td>-0.648835</td>\n <td>-0.377659</td>\n </tr>\n <tr>\n <th>3</th>\n <td>AAAGAAGCCTCAACTTCGTC</td>\n <td>AGCGAAAGAAGCCTCAACTTCGTCTGGAGA</td>\n <td>CENPW</td>\n <td>37.5</td>\n <td>-1.338209</td>\n <td>CENPW</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000203760</td>\n <td>ENST00000368328.5</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.667399</td>\n <td>-0.308794</td>\n <td>34</td>\n <td>ENST00000368328</td>\n <td>False</td>\n <td>0.129285</td>\n <td>-0.538114</td>\n <td>-0.179509</td>\n </tr>\n <tr>\n <th>4</th>\n <td>AAAGTGTGCTTTGTTGGAGA</td>\n <td>TACTAAAGTGTGCTTTGTTGGAGATGGCTT</td>\n <td>NSA2</td>\n <td>60.0</td>\n <td>-0.175219</td>\n <td>NSA2</td>\n <td>2</td>\n <td>9606</td>\n <td>ENSG00000164346</td>\n <td>ENST00000610426.5</td>\n <td>...</td>\n <td>0</td>\n <td>Preselected</td>\n <td>-0.402220</td>\n <td>-0.622492</td>\n <td>157</td>\n <td>ENST00000610426</td>\n <td>False</td>\n <td>-0.113577</td>\n <td>-0.515797</td>\n <td>-0.736069</td>\n </tr>\n </tbody>\n</table>\n<p>5 rows \u00d7 69 columns</p>\n</div>\n\n\n\nSince GeckoV2 was screened with the tracrRNA from Hsu et al. 2013, we'll use these scores sequence scores a part of our final prediction.\n\n```\nplt.subplots(figsize=(4,4))\ngpplot.point_densityplot(gecko_activity_scores, y='avg_mean_centered_neg_lfc',\n x='RS3 Sequence (Hsu2013 tracr) + Target Score')\ngpplot.add_correlation(gecko_activity_scores, y='avg_mean_centered_neg_lfc',\n x='RS3 Sequence (Hsu2013 tracr) + Target Score')\nsns.despine()\n```\n\n\n \n\n \n\n\n#### Predictions on the fly\n\nYou can also make predictions without pre-querying the target data. Here\nwe use example designs for BCL2L1, MCL1 and EEF2.\n\n```\ndesign_df = pd.read_table('test_data/sgrna-designs_BCL2L1_MCL1_EEF2.txt')\n```\n\n```\nscored_designs = predict(design_df,\n tracr=['Hsu2013', 'Chen2013'], target=True,\n n_jobs_min=2, n_jobs_max=8,\n lite=False)\nscored_designs\n```\n\n Calculating sequence-based features\n\n\n 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 849/849 [00:06<00:00, 137.86it/s]\n\n\n Calculating sequence-based features\n\n\n 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 849/849 [00:02<00:00, 321.44it/s]\n\n\n Getting amino acid sequences\n\n\n 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 1/1 [00:00<00:00, 1.77it/s]\n\n\n Getting protein domains\n\n\n 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 3/3 [00:00<00:00, 899.29it/s]\n\n\n Getting conservation\n\n\n 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 3/3 [00:00<00:00, 10.67it/s]\n /opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.\n warnings.warn(\n /opt/anaconda3/envs/rs3/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.dev0 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.\n warnings.warn(\n\n\n\n\n\n<div>\n<style scoped>\n .dataframe tbody tr th:only-of-type {\n vertical-align: middle;\n }\n\n .dataframe tbody tr th {\n vertical-align: top;\n }\n\n .dataframe thead th {\n text-align: right;\n }\n</style>\n<table border=\"1\" class=\"dataframe\">\n <thead>\n <tr style=\"text-align: right;\">\n <th></th>\n <th>Input</th>\n <th>Quota</th>\n <th>Target Taxon</th>\n <th>Target Gene ID</th>\n <th>Target Gene Symbol</th>\n <th>Target Transcript</th>\n <th>Target Alias</th>\n <th>CRISPR Mechanism</th>\n <th>Target Domain</th>\n <th>Reference Sequence</th>\n <th>...</th>\n <th>Picking Round</th>\n <th>Picking Notes</th>\n <th>RS3 Sequence Score (Hsu2013 tracr)</th>\n <th>RS3 Sequence Score (Chen2013 tracr)</th>\n <th>AA Index</th>\n <th>Transcript Base</th>\n <th>Missing conservation information</th>\n <th>Target Score</th>\n <th>RS3 Sequence (Hsu2013 tracr) + Target Score</th>\n <th>RS3 Sequence (Chen2013 tracr) + Target Score</th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <th>0</th>\n <td>EEF2</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000167658</td>\n <td>EEF2</td>\n <td>ENST00000309311.7</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000019.10</td>\n <td>...</td>\n <td>NaN</td>\n <td>Outside Target Window: 5-65%</td>\n <td>0.907809</td>\n <td>0.769956</td>\n <td>666</td>\n <td>ENST00000309311</td>\n <td>False</td>\n <td>-0.115549</td>\n <td>0.792261</td>\n <td>0.654408</td>\n </tr>\n <tr>\n <th>1</th>\n <td>EEF2</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000167658</td>\n <td>EEF2</td>\n <td>ENST00000309311.7</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000019.10</td>\n <td>...</td>\n <td>NaN</td>\n <td>BsmBI:CGTCTC; Outside Target Window: 5-65%</td>\n <td>0.171870</td>\n <td>0.040419</td>\n <td>581</td>\n <td>ENST00000309311</td>\n <td>False</td>\n <td>-0.017643</td>\n <td>0.154226</td>\n <td>0.022776</td>\n </tr>\n <tr>\n <th>2</th>\n <td>EEF2</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000167658</td>\n <td>EEF2</td>\n <td>ENST00000309311.7</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000019.10</td>\n <td>...</td>\n <td>1.0</td>\n <td>NaN</td>\n <td>1.393513</td>\n <td>0.577732</td>\n <td>107</td>\n <td>ENST00000309311</td>\n <td>False</td>\n <td>0.172910</td>\n <td>1.566422</td>\n <td>0.750642</td>\n </tr>\n <tr>\n <th>3</th>\n <td>EEF2</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000167658</td>\n <td>EEF2</td>\n <td>ENST00000309311.7</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000019.10</td>\n <td>...</td>\n <td>1.0</td>\n <td>NaN</td>\n <td>0.904446</td>\n <td>0.008390</td>\n <td>406</td>\n <td>ENST00000309311</td>\n <td>False</td>\n <td>0.121034</td>\n <td>1.025480</td>\n <td>0.129424</td>\n </tr>\n <tr>\n <th>4</th>\n <td>EEF2</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000167658</td>\n <td>EEF2</td>\n <td>ENST00000309311.7</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000019.10</td>\n <td>...</td>\n <td>1.0</td>\n <td>NaN</td>\n <td>0.831087</td>\n <td>0.361594</td>\n <td>546</td>\n <td>ENST00000309311</td>\n <td>False</td>\n <td>0.036041</td>\n <td>0.867128</td>\n <td>0.397635</td>\n </tr>\n <tr>\n <th>...</th>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n <td>...</td>\n </tr>\n <tr>\n <th>844</th>\n <td>MCL1</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000143384</td>\n <td>MCL1</td>\n <td>ENST00000369026.3</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000001.11</td>\n <td>...</td>\n <td>NaN</td>\n <td>Off-target Match Bin I matches > 3; Spacing Vi...</td>\n <td>-0.792918</td>\n <td>-0.663881</td>\n <td>52</td>\n <td>ENST00000369026</td>\n <td>False</td>\n <td>-0.299583</td>\n <td>-1.092501</td>\n <td>-0.963464</td>\n </tr>\n <tr>\n <th>845</th>\n <td>MCL1</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000143384</td>\n <td>MCL1</td>\n <td>ENST00000369026.3</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000001.11</td>\n <td>...</td>\n <td>NaN</td>\n <td>Outside Target Window: 5-65%; poly(T):TTTT</td>\n <td>-1.920374</td>\n <td>-1.819985</td>\n <td>5</td>\n <td>ENST00000369026</td>\n <td>False</td>\n <td>-0.003507</td>\n <td>-1.923881</td>\n <td>-1.823491</td>\n </tr>\n <tr>\n <th>846</th>\n <td>MCL1</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000143384</td>\n <td>MCL1</td>\n <td>ENST00000369026.3</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000001.11</td>\n <td>...</td>\n <td>NaN</td>\n <td>Spacing Violation: Too close to earlier pick a...</td>\n <td>-1.101303</td>\n <td>-1.295640</td>\n <td>24</td>\n <td>ENST00000369026</td>\n <td>False</td>\n <td>-0.285485</td>\n <td>-1.386788</td>\n <td>-1.581125</td>\n </tr>\n <tr>\n <th>847</th>\n <td>MCL1</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000143384</td>\n <td>MCL1</td>\n <td>ENST00000369026.3</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000001.11</td>\n <td>...</td>\n <td>NaN</td>\n <td>Spacing Violation: Too close to earlier pick a...</td>\n <td>-0.617431</td>\n <td>-0.621436</td>\n <td>30</td>\n <td>ENST00000369026</td>\n <td>False</td>\n <td>-0.312348</td>\n <td>-0.929779</td>\n <td>-0.933784</td>\n </tr>\n <tr>\n <th>848</th>\n <td>MCL1</td>\n <td>5</td>\n <td>9606</td>\n <td>ENSG00000143384</td>\n <td>MCL1</td>\n <td>ENST00000369026.3</td>\n <td>NaN</td>\n <td>CRISPRko</td>\n <td>CDS</td>\n <td>NC_000001.11</td>\n <td>...</td>\n <td>NaN</td>\n <td>On-Target Efficacy Score < 0.2; Spacing Violat...</td>\n <td>-0.586811</td>\n <td>-0.664130</td>\n <td>30</td>\n <td>ENST00000369026</td>\n <td>False</td>\n <td>-0.312348</td>\n <td>-0.899159</td>\n <td>-0.976478</td>\n </tr>\n </tbody>\n</table>\n<p>849 rows \u00d7 61 columns</p>\n</div>\n\n\n\nWe see that the predict function is querying the target data in addition\nto making predictions.\n\n\n",
"bugtrack_url": null,
"license": "Apache Software License 2.0",
"summary": "Predict the activity of CRISPR sgRNAs",
"version": "0.0.16",
"project_urls": {
"Homepage": "https://github.com/gpp-rnd/rs3/tree/master/"
},
"split_keywords": [
"rs3",
"crispr",
"sgrna"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "e79a5fc75d9b71819043b7d7cb50cc2b452b010bdace346f691ef840511889ea",
"md5": "610f0000fa76253e57bd5c8d7fd47cd4",
"sha256": "e769bb40f148a086a2c01937eddc513f3339ac8be0191075e328d8a1e0f1e66d"
},
"downloads": -1,
"filename": "rs3-0.0.16-py3-none-any.whl",
"has_sig": false,
"md5_digest": "610f0000fa76253e57bd5c8d7fd47cd4",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.7",
"size": 6160272,
"upload_time": "2024-02-24T17:06:21",
"upload_time_iso_8601": "2024-02-24T17:06:21.701964Z",
"url": "https://files.pythonhosted.org/packages/e7/9a/5fc75d9b71819043b7d7cb50cc2b452b010bdace346f691ef840511889ea/rs3-0.0.16-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "fa3e4256ab2115f99e85677403f82cf6cdec6f6bda86359dd202f0b7568263d8",
"md5": "2bad105f28d0878774250bcc9f2aea9b",
"sha256": "06591b4bade00f18ece00a0a7e853fddcfe0ba07093e6f43872b4afe1ac88233"
},
"downloads": -1,
"filename": "rs3-0.0.16.tar.gz",
"has_sig": false,
"md5_digest": "2bad105f28d0878774250bcc9f2aea9b",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.7",
"size": 6121364,
"upload_time": "2024-02-24T17:06:28",
"upload_time_iso_8601": "2024-02-24T17:06:28.507233Z",
"url": "https://files.pythonhosted.org/packages/fa/3e/4256ab2115f99e85677403f82cf6cdec6f6bda86359dd202f0b7568263d8/rs3-0.0.16.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-02-24 17:06:28",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "gpp-rnd",
"github_project": "rs3",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "rs3"
}

