# RWKV Tokenizer
[](https://github.com/cahya-wirawan/rwkv-tokenizer/actions/)
[](https://pypi.org/project/pyrwkv-tokenizer/)
[](https://pypi.org/project/pyrwkv-tokenizer/)
[](https://github.com/cahya-wirawan/rwkv-tokenizer/blob/main/LICENSE.txt)
A fast RWKV Tokenizer written in Rust that supports the World Tokenizer used by the
[RWKV](https://github.com/BlinkDL/RWKV-LM) v5 and v6 models.
## Installation
Install the rwkv-tokenizer python module:
```
$ pip install pyrwkv-tokenizer
```
## Usage
```
>>> import pyrwkv_tokenizer
>>> tokenizer = pyrwkv_tokenizer.RWKVTokenizer()
>>> tokenizer.encode("Today is a beautiful day. 今天是美好的一天。")
[33520, 4600, 332, 59219, 21509, 47, 33, 10381, 11639, 13091, 15597, 11685, 14734, 10250, 11639, 10080]
>>> tokenizer.decode([33520, 4600, 332, 59219, 21509, 47, 33, 10381, 11639, 13091, 15597, 11685, 14734, 10250, 11639, 10080])
'Today is a beautiful day. 今天是美好的一天。'
```
## Performance and Validity Test
We compared the encoding results of the Rust RWKV Tokenizer and the original tokenizer using
the English Wikipedia and Chinese poetries datasets. Both results are identical. The Rust RWKV Tokenizer also
passes [the original tokenizer's unit test](https://github.com/BlinkDL/ChatRWKV/blob/main/tokenizer/rwkv_tokenizer.py).
The following steps describe how to do the unit test:
```
$ pip install pytest pyrwkv-tokenizer
$ git clone https://github.com/cahya-wirawan/rwkv-tokenizer.git
$ cd rwkv-tokenizer
$ pytest
```
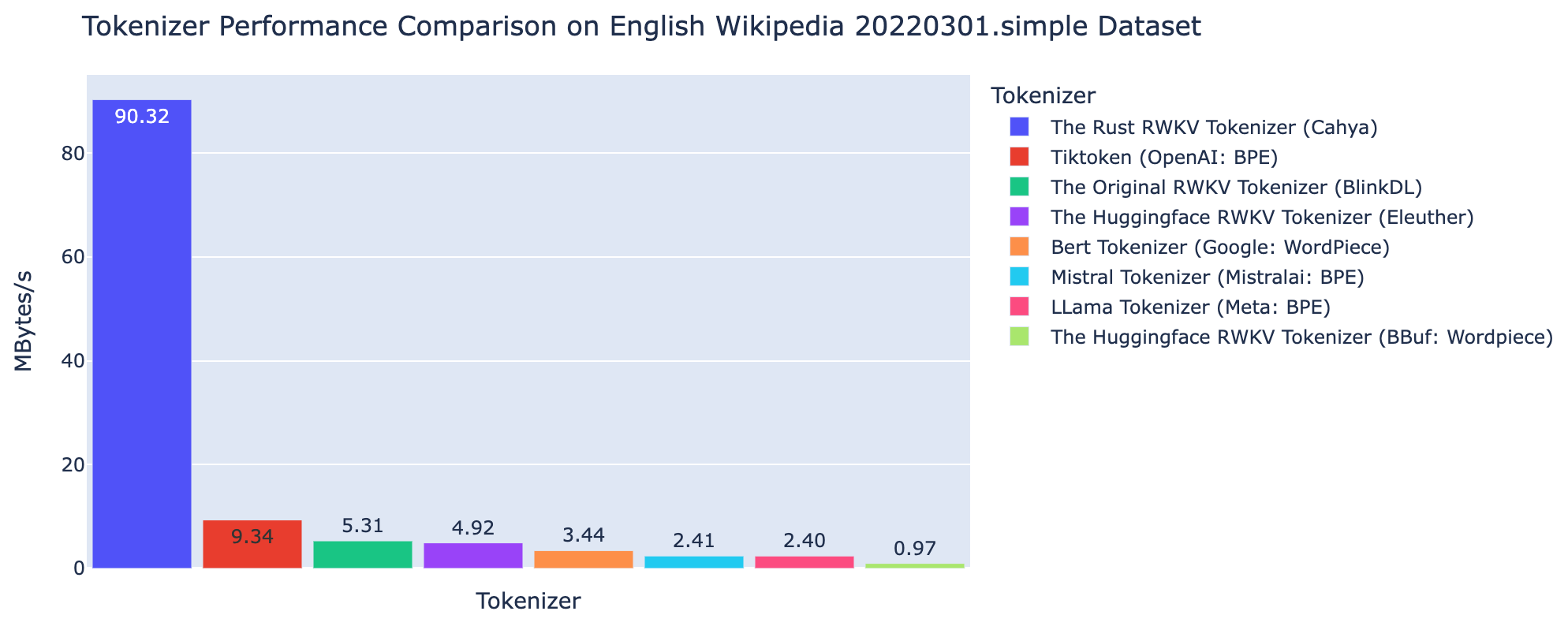
We did a performance comparison on [the simple English Wikipedia dataset 20220301.en](https://huggingface.co/datasets/legacy-datasets/wikipedia) among following tokenizer:
- The original RWKV tokenizer (BlinkDL)
- Huggingface implementaion of RWKV tokenizer
- Huggingface LLama tokenizer
- Huggingface Mistral tokenizer
- Bert tokenizer
- OpenAI Tiktoken
- The Rust RWKV tokenizer
The comparison is done using this [jupyter notebook](https://github.com/cahya-wirawan/rwkv-tokenizer/blob/main/tools/rwkv_tokenizers.ipynb) in a M2 Mac mini. The Rust RWKV
tokenizer is around 17x faster than the original tokenizer and 9.6x faster than OpenAI Tiktoken.
## Changelog
- Version 0.9.1
- Added utf8 error handling to decoder
- Version 0.9.0
- Added multithreading for the function encode_batch()
- Added batch/multithreading comparison
- Version 0.3.0
- Fixed the issue where some characters were not encoded correctly
*This tokenizer is my very first Rust program, so it might still have many bugs and silly codes :-)*
Raw data
{
"_id": null,
"home_page": null,
"name": "rwkv-tokenizer",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": null,
"keywords": "LLM, RWKV, Language Model",
"author": "Cahya Wirawan <cahya.wirawan@gmail.com>",
"author_email": "Cahya Wirawan <cahya.wirawan@gmail.com>",
"download_url": "https://files.pythonhosted.org/packages/88/0b/55f681f8936d9c14057d9fb005eb0ddb1133d5ebae770bd07c24742546ff/rwkv_tokenizer-0.11.0.tar.gz",
"platform": null,
"description": "# RWKV Tokenizer\n\n[](https://github.com/cahya-wirawan/rwkv-tokenizer/actions/)\n[](https://pypi.org/project/pyrwkv-tokenizer/)\n[](https://pypi.org/project/pyrwkv-tokenizer/)\n[](https://github.com/cahya-wirawan/rwkv-tokenizer/blob/main/LICENSE.txt)\n\n\nA fast RWKV Tokenizer written in Rust that supports the World Tokenizer used by the \n[RWKV](https://github.com/BlinkDL/RWKV-LM) v5 and v6 models.\n\n## Installation\nInstall the rwkv-tokenizer python module:\n```\n$ pip install pyrwkv-tokenizer\n```\n## Usage\n```\n>>> import pyrwkv_tokenizer\n>>> tokenizer = pyrwkv_tokenizer.RWKVTokenizer()\n>>> tokenizer.encode(\"Today is a beautiful day. \u4eca\u5929\u662f\u7f8e\u597d\u7684\u4e00\u5929\u3002\")\n[33520, 4600, 332, 59219, 21509, 47, 33, 10381, 11639, 13091, 15597, 11685, 14734, 10250, 11639, 10080]\n>>> tokenizer.decode([33520, 4600, 332, 59219, 21509, 47, 33, 10381, 11639, 13091, 15597, 11685, 14734, 10250, 11639, 10080])\n'Today is a beautiful day. \u4eca\u5929\u662f\u7f8e\u597d\u7684\u4e00\u5929\u3002'\n\n```\n\n## Performance and Validity Test\n\nWe compared the encoding results of the Rust RWKV Tokenizer and the original tokenizer using\nthe English Wikipedia and Chinese poetries datasets. Both results are identical. The Rust RWKV Tokenizer also \npasses [the original tokenizer's unit test](https://github.com/BlinkDL/ChatRWKV/blob/main/tokenizer/rwkv_tokenizer.py). \nThe following steps describe how to do the unit test:\n```\n$ pip install pytest pyrwkv-tokenizer\n$ git clone https://github.com/cahya-wirawan/rwkv-tokenizer.git\n$ cd rwkv-tokenizer\n$ pytest\n```\n\nWe did a performance comparison on [the simple English Wikipedia dataset 20220301.en](https://huggingface.co/datasets/legacy-datasets/wikipedia) among following tokenizer:\n- The original RWKV tokenizer (BlinkDL)\n- Huggingface implementaion of RWKV tokenizer\n- Huggingface LLama tokenizer\n- Huggingface Mistral tokenizer\n- Bert tokenizer\n- OpenAI Tiktoken\n- The Rust RWKV tokenizer\n\nThe comparison is done using this [jupyter notebook](https://github.com/cahya-wirawan/rwkv-tokenizer/blob/main/tools/rwkv_tokenizers.ipynb) in a M2 Mac mini. The Rust RWKV \ntokenizer is around 17x faster than the original tokenizer and 9.6x faster than OpenAI Tiktoken.\n\n\n\n## Changelog\n- Version 0.9.1\n - Added utf8 error handling to decoder\n- Version 0.9.0\n - Added multithreading for the function encode_batch()\n - Added batch/multithreading comparison\n- Version 0.3.0\n - Fixed the issue where some characters were not encoded correctly\n\n*This tokenizer is my very first Rust program, so it might still have many bugs and silly codes :-)*\n\n\n",
"bugtrack_url": null,
"license": "Apache-2.0",
"summary": "RWKV Tokenizer",
"version": "0.11.0",
"project_urls": {
"changelog": "https://github.com/cahya-wirawan/rwkv-tokenizer/blob/master/CHANGELOG.md",
"documentation": "https://github.com/cahya-wirawan/rwkv-tokenizer",
"homepage": "https://github.com/cahya-wirawan/rwkv-tokenizer",
"repository": "https://github.com/cahya-wirawan/rwkv-tokenizer"
},
"split_keywords": [
"llm",
" rwkv",
" language model"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "b6b491aae96592264fdf8b1f6c037300cbe06a2a20edca8057bedf2f5f54c013",
"md5": "f40047a65190dbba9d024ab1f4e0e11d",
"sha256": "169fad1e69f45150d754242d5a8e7b2e1516653841c450a1f7e922db0098965a"
},
"downloads": -1,
"filename": "rwkv_tokenizer-0.11.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl",
"has_sig": false,
"md5_digest": "f40047a65190dbba9d024ab1f4e0e11d",
"packagetype": "bdist_wheel",
"python_version": "cp310",
"requires_python": ">=3.8",
"size": 1410400,
"upload_time": "2025-07-16T09:53:46",
"upload_time_iso_8601": "2025-07-16T09:53:46.114212Z",
"url": "https://files.pythonhosted.org/packages/b6/b4/91aae96592264fdf8b1f6c037300cbe06a2a20edca8057bedf2f5f54c013/rwkv_tokenizer-0.11.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "880b55f681f8936d9c14057d9fb005eb0ddb1133d5ebae770bd07c24742546ff",
"md5": "ef2c1975168a198b8b5c27cd82b99002",
"sha256": "3ee4861c4613908ab00c66caa952873d2d92108749e0edb60755b5885cbf82e7"
},
"downloads": -1,
"filename": "rwkv_tokenizer-0.11.0.tar.gz",
"has_sig": false,
"md5_digest": "ef2c1975168a198b8b5c27cd82b99002",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 806070,
"upload_time": "2025-07-16T09:53:48",
"upload_time_iso_8601": "2025-07-16T09:53:48.591425Z",
"url": "https://files.pythonhosted.org/packages/88/0b/55f681f8936d9c14057d9fb005eb0ddb1133d5ebae770bd07c24742546ff/rwkv_tokenizer-0.11.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-07-16 09:53:48",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "cahya-wirawan",
"github_project": "rwkv-tokenizer",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "rwkv-tokenizer"
}

