# scaleup-optimizers
`scaleup-optimizers` is a Python library for parameter optimization using a transfer learning algorithm. It integrates a Bayesian optimization technique to handle models of both small-scale and large-scale systems.
## Problem Statement
Training and optimizing a large-scale system presents several challenges:
- Computational Cost: Direct parameter optimization on a large system is extremely expensive in terms of both required time and cost.
- Limited Trails: Due to resource constraints, we can only perform a small number of optimization trials on a large system.
The scaleup optimization problem is to efficiently optimize a large-scale system within a small number of optimization trails by using a model of a small-scale system.
## Description
This library is designed to help you efficiently optimize parameters of a large scale system using Bayesian Optimization technique. It provides tools for working with both small-scale (e.g., experimental) and large-scale (e.g., production) systems, the large-scale leverages optimization history from small-scale.
## Architecture
The library consists of two main components:
### 1. SmallScaleOptimizer
- Performs initial Bayesian optimization on a smaller version of the model (Experiment System)
- Minimizes the objective function through multiple iterations
- Collects optimization history (best_params, X_iters, Y_iters) to inform the second stage
- Uses Small Scale Gaussian Process with acquisition functions
### 2. LargeScaleOptimizer
- Leverages optimization history from SmallScaleOptimizer
- Incorporates transfer learning to warm-start the optimization process
- Efficiently explores promising regions of the hyperparameter space
- Uses Large Scale Gaussian Process with acquisition functions
### Parameters
#### SmallScaleOptimizer
`objective_function`: callable function of Small Model to be optimized. Should take a list of parameters as input and return a scalar value to be minimized.
`search_space`: list of skopt.space objects. List defining the parameter search space using skopt space objects.
`acq_func` : str, default='EI'. The acquisition function to use for selecting next points. Options ('EI', 'PI', 'UCB')
`n_steps` : int, default=10. Number of optimization steps to perform after initialization.
`n_initial_points` : int, default=1. Number of random points to evaluate before starting the optimization. Only used if `X_init` and `Y_init` are not provided.
`X_init` : array-like, shape (n_small_samples, n_dimensions) optional. Initial parameter combinations.
`Y_init` : list, optional. Objective function values for initial points. Required to provide `X_init`.
#### LargeScaleOptimizer
`objective_function`: callable function of Large Model to be optimized. Should take a list of parameters (the numbers of parameter must be the same as Small Model) as input and return a scalar value to be minimized.
`search_space`: list of skopt.space objects. List defining the parameter search space using skopt space objects. (Use the same space for both Model).
`best_params`: list. Best parameters found from Small Model optimization runs. Used to initialize the transfer learning process. These parameters should be in the same format and order as defined in the search space.
`X_iters_small` : array-like, shape (n_small_samples, n_dimensions). A subset of Small Model optimization iterations' parameters. These represent the most relevant or important points from previous optimization runs. Used to warm start the Large Model optimization.
`Y_iters_small` : list, shape (n_small_samples). Objective function values corresponding to X_iters_small. These are the evaluation results from Small Model optimization runs.
`gp` and `gpL`: You can specify the alpha (numerical stability) and kernel length scale or bounds using SmallScaleGaussianProcess and LargeScaleGaussianProcess.
```python
from scaleup_bo.surrogate_models import SmallScaleGaussianProcess, LargeScaleGaussianProcess
gp = SmallScaleGaussianProcess(kernel=RBF(1.0, (1e-5, 100)), alpha=0.1)
gpL = LargeScaleGaussianProcess(kernel=RBF(0.5, (1e-3, 10)), alpha=0.01)
```
You can see the example in the Getting Started Section.
## Installation
### scaleup-optimizer requires
- `numpy>=1.21.0`
- `scipy>=1.10.0`
- `scikit-optimize>=0.8.1`
- `matplotlib>=3.4.0`
### Install via pip
You can install the library from PyPI or your local environment:
#### From PyPI
```bash
pip install scaleup-optimizers
```
## Getting Started
### Define the Experiment Model and decide on parameters to optimize then define objective function to minimize.
#### Load Dataset
```python
import numpy as np
import torch
import torch.nn as nn
import torchvision.datasets as datasets
from torch.utils.data import Subset
from torch.utils.data import DataLoader,random_split
import torchvision.transforms as transforms
data_transform = transforms.ToTensor()
train_dataset = datasets.FashionMNIST(root="datasets", train=True, transform=data_transform, download=True)
test_dataset = datasets.FashionMNIST(root="datasets", train=False, transform=data_transform, download=True)
# Calculate 5% of the datasets
test_subset_size = int(0.05 * len(test_dataset))
test_subset, _ = random_split(test_dataset, [test_subset_size, len(test_dataset) - test_subset_size])
train_data_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_data_loader = DataLoader(test_subset, batch_size=64, shuffle=True)
test_data_loader_L = DataLoader(test_dataset, batch_size=64, shuffle=True)
```
#### Define Experiment Model
```python
class ModelS(nn.Module):
def __init__(self, dropout_rate=0.2, conv_kernel_size=3, pool_kernel_size=2):
super(ModelS, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=conv_kernel_size, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=pool_kernel_size),
self.merge_channels(64, 32),
)
self._compute_linear_input_size()
self.classifier = nn.Sequential(
nn.Dropout(dropout_rate),
nn.Linear(self.linear_input_size, 10),
nn.LogSoftmax(dim=1),
)
def merge_channels(self, in_channels, out_channels):
assert in_channels == 2 * out_channels, "in_channels should be twice out_channels"
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1),
)
def _compute_linear_input_size(self):
with torch.no_grad():
dummy_input = torch.zeros(1, 1, 28, 28)
features_output = self.features(dummy_input)
num_channels, height, width = features_output.size()[1:]
self.linear_input_size = num_channels * height * width
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
nll_loss = nn.NLLLoss()
# Select the device on which to perform the calculation.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Transfer the model to the device that will perform the calculation.
model = ModelS().to(device)
# Create an Optimizer.
optim = torch.optim.Adam(model.parameters())
def train(model, device, data_loader, optim):
model.train()
total_loss = 0
total_correct = 0
for data, target in data_loader:
# Transfer the data and labels to the device performing the calculation.
data, target = data.to(device), target.to(device)
# Sequential propagation.
output = model(data)
loss = nll_loss(output, target)
total_loss += float(loss)
# Reverse propagation or backpropagation
optim.zero_grad()
loss.backward()
# Update parameters.
optim.step()
# The class with the highest probability is the predictive label.
pred_target = output.argmax(dim=1)
total_correct += int((pred_target == target).sum())
avg_loss = total_loss / len(data_loader.dataset)
accuracy = total_correct / len(data_loader.dataset)
return avg_loss, accuracy
def test(model, device, data_loader):
model.eval()
with torch.no_grad():
total_loss = 0
total_correct = 0
for data, target in data_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = nll_loss(output, target)
total_loss += float(loss)
pred_target = output.argmax(dim=1)
total_correct += int((pred_target == target).sum())
avg_loss = total_loss / len(data_loader.dataset)
accuracy = total_correct / len(data_loader.dataset)
return avg_loss, accuracy
```
#### Define Objective Function
```python
def objective_function_S(params):
dropout_rate, learning_rate, conv_kernel_size, pool_kernel_size = params
conv_kernel_size = int(conv_kernel_size)
pool_kernel_size = int(pool_kernel_size)
model = ModelS(dropout_rate=dropout_rate, conv_kernel_size=conv_kernel_size, pool_kernel_size=pool_kernel_size).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
n_epochs = 20
patience = 5
min_val_loss = float('inf')
epochs_no_improve = 0
for epoch in range(n_epochs):
train_loss, train_accuracy = train(model, device, train_data_loader, optimizer)
val_loss, val_accuracy = test(model, device, test_data_loader)
# Check if validation loss has improved
if val_loss < min_val_loss:
min_val_loss = val_loss
epochs_no_improve = 0
else:
epochs_no_improve += 1
if epochs_no_improve >= patience:
print(f"Early stopping at epoch {epoch+1}")
break
return min_val_loss
```
#### Define bound of search space (Unified for both Experiment and Production System)
```python
# List of hyperparameters to optimize.
# For each hyperparameter, we specify:
# - The bounds within which values will be selected.
# - The corresponding parameter name as recognized by scikit-learn.
# - The sampling distribution to guide value selection.
# For instance, the learning rate uses a 'log-uniform' distribution.
from skopt.space import Real, Integer, Categorical
search_space = [
Real(0.1, 1, name='dropout_rate'),
Real(0.0001, 10, name='learning_rate', prior='log-uniform'),
Integer(1, 10, name='conv_kernel_size'),
Integer(1, 3, name='pool_kernel_size'),
]
```
#### Optimize Experiment System Over 10 Iteration
```python
from scaleup_bo import SmallScaleOptimizer
small_optimizer = SmallScaleOptimizer(objective_function_S, search_space, n_steps=10, n_initial_points=1)
# Collect history from SmallScaleOptimizer
best_params_s = small_optimizer.best_params
best_hyperparameters = dict(zip(['dropout_rate', 'learning_rate', 'conv_kernel_size', 'pool_kernel_size'], best_params_s))
print("Best Hyperparameter of Small Model: ", best_hyperparameters)
X_iters_small = small_optimizer.X_iters
print('X_iters_small: ', X_iters_small)
Y_iters_small = small_optimizer.Y_iters
print('Y_iters_small: ', Y_iters_small)
```
#### Output
```bash
Best Hyperparameter of Small Model: {'dropout_rate': 0.3002150723, 'learning_rate': 0.0007667914, 'conv_kernel_size': 6, 'pool_kernel_size': 3}
X_iters_small: array([[0.7803350320816986, 9.083817128074404, 4, 3],
[0.1, 0.0001, 10, 5],
[0.2757733648, 0.0369179854, 2, 4],
[0.2364062706, 0.0002389496, 3, 3],
[0.9509629778, 0.0134669852, 3, 5],
[0.6484239182, 0.1599534102, 2, 5],
[0.9573643447, 0.4342609034, 6, 5],
[0.4850212168, 0.1077820534, 4, 4],
[0.3002150723, 0.0007667914, 6, 3],
[0.4913776109, 0.0010069987, 5, 3],
[0.3353326913, 0.0079244646, 7, 4]])
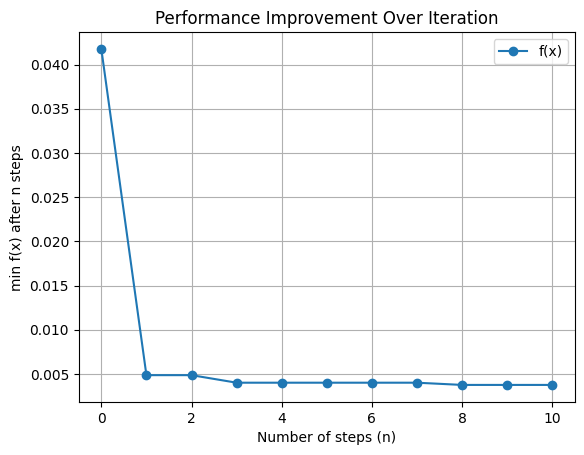
Y_iters_small: array([0.0417628 , 0.00486325, 0.00528098, 0.00400994, 0.00927958,
0.01945705, 0.03691163, 0.00989952, 0.00375851, 0.00390017,
0.0042957 ])
```
#### Plot Performance
```python
from scaleup_bo.plots import plot_performance
plot_performance(small_optimizer)
```
#### Plot Evaluation
```bash
from scaleup_bo.plots import custom_plot_evaluation
custom_plot_evaluation(small_optimizer)
```

### Define the Production Model to optimize and the parameters are the same as Experiment System then define objective function to minimize using history leverage from Experiment System
#### Define Production Model
```python
class ModelL(nn.Module):
def __init__(self, dropout_rate=0.2, conv_kernel_size=1, pool_kernel_size=2):
super(ModelL, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=conv_kernel_size, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=pool_kernel_size, stride=2),
nn.Conv2d(32, 64, kernel_size=conv_kernel_size, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=pool_kernel_size, stride=2),
)
self._compute_linear_input_size()
self.classifier = nn.Sequential(
nn.Dropout(dropout_rate),
nn.Linear(self.linear_input_size, 128),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(128, 10),
nn.LogSoftmax(dim=1),
)
def _compute_linear_input_size(self):
with torch.no_grad():
dummy_input = torch.zeros(1, 1, 28, 28)
features_output = self.features(dummy_input)
num_channels, height, width = features_output.size()[1:]
self.linear_input_size = num_channels * height * width
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# Transfer the model to the device that will perform the calculation.
modelL = ModelL().to(device)
# Create an Optimizer for ModelL
optimL = torch.optim.Adam(modelL.parameters())
```
#### Define Objective Function
```python
def objective_function_L(params):
dropout_rate, learning_rate, conv_kernel_size, pool_kernel_size = params
conv_kernel_size = int(conv_kernel_size)
pool_kernel_size = int(pool_kernel_size)
modelL = ModelL(dropout_rate=dropout_rate, conv_kernel_size=conv_kernel_size, pool_kernel_size=pool_kernel_size).to(device)
optimizer = torch.optim.Adam(modelL.parameters(), lr=learning_rate)
n_epochs = 30
patience = 5
min_val_loss = float('inf')
epochs_no_improve = 0
for epoch in range(n_epochs):
train_loss, train_accuracy = train(modelL, device, train_data_loader, optimizer)
val_loss, val_accuracy = test(modelL, device, test_data_loader_L)
# Check if validation loss has improved
if val_loss < min_val_loss:
min_val_loss = val_loss
epochs_no_improve = 0
else:
epochs_no_improve += 1
if epochs_no_improve >= patience:
print(f"Early stopping at epoch {epoch+1}")
break
return min_val_loss
```
#### Optimize Production System Over 10 Iteration
```python
from scaleup_bo import LargeScaleOptimizer
large_optimizer = LargeScaleOptimizer(objective_function_L, search_space, best_params=best_params_s, X_iters_small=X_iters_small, Y_iters_small=Y_iters_small, n_steps=10)
best_params_l = large_optimizer.best_params
best_hyperparameters_l = dict(zip(['dropout_rate', 'learning_rate', 'conv_kernel_size', 'pool_kernel_size'], best_params_s))
print("Best Hyperparameter of Large Model: ", best_hyperparameters_l)
best_score_l = large_optimizer.best_score
print("Best score of Large Model: ", best_score_l)
```
#### Output
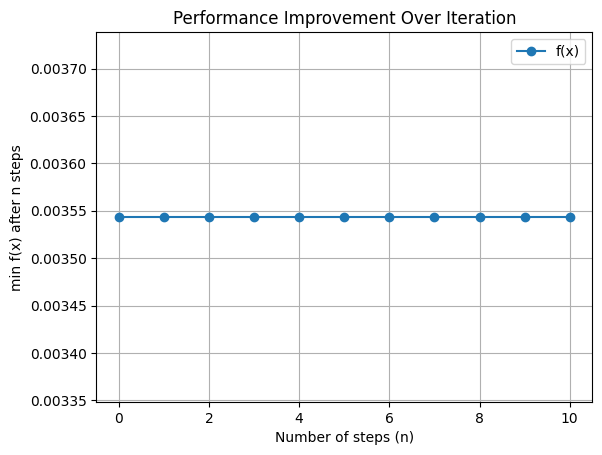
```bash
Best Hyperparameter of Large Model: {'dropout_rate': 0.300215072, 'learning_rate': 0.0007667914, 'conv_kernel_size': 6, 'pool_kernel_size': 3}
Best score of Large Model: 0.0035434851370751857
```
#### Plot Performance
```python
from scaleup_bo.plots import plot_performance
plot_performance(large_optimizer)
```
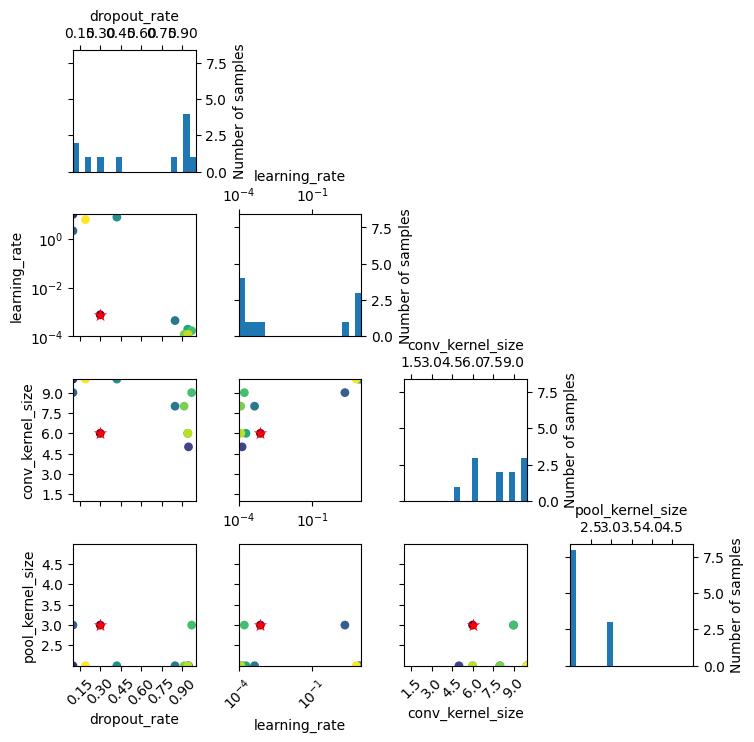
#### Plot Evaluation
```python
from scaleup_bo.plots import custom_plot_evaluation
custom_plot_evaluation(large_optimizer)
```
Raw data
{
"_id": null,
"home_page": "https://gitlab.bird-initiative-dev.com/bird-initiative/scaleup-optimizer",
"name": "scaleup-optimizers",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.6",
"maintainer_email": null,
"keywords": "machine learning, hyperparameter optimization, scale up algorithm",
"author": "Bird Initiative",
"author_email": "develop@bird-initiative.com",
"download_url": "https://files.pythonhosted.org/packages/01/53/5ab721e7bfb7ba17662b0536aec45ce90200fb566572f5a0cf8ed138c3af/scaleup_optimizers-1.0.6.tar.gz",
"platform": null,
"description": "# scaleup-optimizers\n\n`scaleup-optimizers` is a Python library for parameter optimization using a transfer learning algorithm. It integrates a Bayesian optimization technique to handle models of both small-scale and large-scale systems.\n\n## Problem Statement\n\nTraining and optimizing a large-scale system presents several challenges:\n\n- Computational Cost: Direct parameter optimization on a large system is extremely expensive in terms of both required time and cost.\n- Limited Trails: Due to resource constraints, we can only perform a small number of optimization trials on a large system.\n\nThe scaleup optimization problem is to efficiently optimize a large-scale system within a small number of optimization trails by using a model of a small-scale system.\n\n## Description\n\nThis library is designed to help you efficiently optimize parameters of a large scale system using Bayesian Optimization technique. It provides tools for working with both small-scale (e.g., experimental) and large-scale (e.g., production) systems, the large-scale leverages optimization history from small-scale.\n\n## Architecture\n\nThe library consists of two main components:\n\n### 1. SmallScaleOptimizer\n\n- Performs initial Bayesian optimization on a smaller version of the model (Experiment System)\n- Minimizes the objective function through multiple iterations\n- Collects optimization history (best_params, X_iters, Y_iters) to inform the second stage\n- Uses Small Scale Gaussian Process with acquisition functions\n\n### 2. LargeScaleOptimizer\n\n- Leverages optimization history from SmallScaleOptimizer\n- Incorporates transfer learning to warm-start the optimization process\n- Efficiently explores promising regions of the hyperparameter space\n- Uses Large Scale Gaussian Process with acquisition functions\n\n### Parameters\n\n#### SmallScaleOptimizer\n\n`objective_function`: callable function of Small Model to be optimized. Should take a list of parameters as input and return a scalar value to be minimized.\n\n`search_space`: list of skopt.space objects. List defining the parameter search space using skopt space objects.\n\n`acq_func` : str, default='EI'. The acquisition function to use for selecting next points. Options ('EI', 'PI', 'UCB')\n\n`n_steps` : int, default=10. Number of optimization steps to perform after initialization.\n\n`n_initial_points` : int, default=1. Number of random points to evaluate before starting the optimization. Only used if `X_init` and `Y_init` are not provided.\n\n`X_init` : array-like, shape (n_small_samples, n_dimensions) optional. Initial parameter combinations.\n\n`Y_init` : list, optional. Objective function values for initial points. Required to provide `X_init`.\n\n#### LargeScaleOptimizer\n\n`objective_function`: callable function of Large Model to be optimized. Should take a list of parameters (the numbers of parameter must be the same as Small Model) as input and return a scalar value to be minimized.\n\n`search_space`: list of skopt.space objects. List defining the parameter search space using skopt space objects. (Use the same space for both Model).\n\n`best_params`: list. Best parameters found from Small Model optimization runs. Used to initialize the transfer learning process. These parameters should be in the same format and order as defined in the search space.\n\n`X_iters_small` : array-like, shape (n_small_samples, n_dimensions). A subset of Small Model optimization iterations' parameters. These represent the most relevant or important points from previous optimization runs. Used to warm start the Large Model optimization.\n\n`Y_iters_small` : list, shape (n_small_samples). Objective function values corresponding to X_iters_small. These are the evaluation results from Small Model optimization runs.\n\n`gp` and `gpL`: You can specify the alpha (numerical stability) and kernel length scale or bounds using SmallScaleGaussianProcess and LargeScaleGaussianProcess.\n\n```python\nfrom scaleup_bo.surrogate_models import SmallScaleGaussianProcess, LargeScaleGaussianProcess\n\ngp = SmallScaleGaussianProcess(kernel=RBF(1.0, (1e-5, 100)), alpha=0.1)\ngpL = LargeScaleGaussianProcess(kernel=RBF(0.5, (1e-3, 10)), alpha=0.01)\n```\n\nYou can see the example in the Getting Started Section.\n\n## Installation\n\n### scaleup-optimizer requires\n\n- `numpy>=1.21.0`\n- `scipy>=1.10.0`\n- `scikit-optimize>=0.8.1`\n- `matplotlib>=3.4.0`\n\n### Install via pip\n\nYou can install the library from PyPI or your local environment:\n\n#### From PyPI\n\n```bash\npip install scaleup-optimizers\n\n```\n\n## Getting Started\n\n### Define the Experiment Model and decide on parameters to optimize then define objective function to minimize.\n\n#### Load Dataset\n\n```python\nimport numpy as np\nimport torch\nimport torch.nn as nn\nimport torchvision.datasets as datasets\nfrom torch.utils.data import Subset\nfrom torch.utils.data import DataLoader,random_split\nimport torchvision.transforms as transforms\n\ndata_transform = transforms.ToTensor()\n\ntrain_dataset = datasets.FashionMNIST(root=\"datasets\", train=True, transform=data_transform, download=True)\ntest_dataset = datasets.FashionMNIST(root=\"datasets\", train=False, transform=data_transform, download=True)\n\n# Calculate 5% of the datasets\ntest_subset_size = int(0.05 * len(test_dataset))\ntest_subset, _ = random_split(test_dataset, [test_subset_size, len(test_dataset) - test_subset_size])\n\ntrain_data_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)\ntest_data_loader = DataLoader(test_subset, batch_size=64, shuffle=True)\ntest_data_loader_L = DataLoader(test_dataset, batch_size=64, shuffle=True)\n```\n\n#### Define Experiment Model\n\n```python\nclass ModelS(nn.Module):\n def __init__(self, dropout_rate=0.2, conv_kernel_size=3, pool_kernel_size=2):\n super(ModelS, self).__init__()\n self.features = nn.Sequential(\n nn.Conv2d(1, 64, kernel_size=conv_kernel_size, stride=1, padding=1),\n nn.ReLU(),\n nn.MaxPool2d(kernel_size=pool_kernel_size),\n self.merge_channels(64, 32),\n )\n\n self._compute_linear_input_size()\n\n self.classifier = nn.Sequential(\n nn.Dropout(dropout_rate),\n nn.Linear(self.linear_input_size, 10),\n nn.LogSoftmax(dim=1),\n )\n\n def merge_channels(self, in_channels, out_channels):\n assert in_channels == 2 * out_channels, \"in_channels should be twice out_channels\"\n return nn.Sequential(\n nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1),\n )\n\n def _compute_linear_input_size(self):\n with torch.no_grad():\n dummy_input = torch.zeros(1, 1, 28, 28)\n features_output = self.features(dummy_input)\n num_channels, height, width = features_output.size()[1:]\n self.linear_input_size = num_channels * height * width\n\n def forward(self, x):\n x = self.features(x)\n x = torch.flatten(x, 1)\n x = self.classifier(x)\n return x\n\nnll_loss = nn.NLLLoss()\n\n# Select the device on which to perform the calculation.\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n\n# Transfer the model to the device that will perform the calculation.\nmodel = ModelS().to(device)\n# Create an Optimizer.\noptim = torch.optim.Adam(model.parameters())\n\ndef train(model, device, data_loader, optim):\n model.train()\n\n total_loss = 0\n total_correct = 0\n for data, target in data_loader:\n # Transfer the data and labels to the device performing the calculation.\n data, target = data.to(device), target.to(device)\n\n # Sequential propagation.\n output = model(data)\n\n loss = nll_loss(output, target)\n total_loss += float(loss)\n\n # Reverse propagation or backpropagation\n optim.zero_grad()\n loss.backward()\n\n # Update parameters.\n optim.step()\n\n # The class with the highest probability is the predictive label.\n pred_target = output.argmax(dim=1)\n\n total_correct += int((pred_target == target).sum())\n\n avg_loss = total_loss / len(data_loader.dataset)\n accuracy = total_correct / len(data_loader.dataset)\n\n return avg_loss, accuracy\n\ndef test(model, device, data_loader):\n model.eval()\n\n with torch.no_grad():\n total_loss = 0\n total_correct = 0\n for data, target in data_loader:\n data, target = data.to(device), target.to(device)\n\n output = model(data)\n\n loss = nll_loss(output, target)\n total_loss += float(loss)\n\n pred_target = output.argmax(dim=1)\n\n total_correct += int((pred_target == target).sum())\n\n avg_loss = total_loss / len(data_loader.dataset)\n accuracy = total_correct / len(data_loader.dataset)\n\n return avg_loss, accuracy\n```\n\n#### Define Objective Function\n\n```python\ndef objective_function_S(params):\n dropout_rate, learning_rate, conv_kernel_size, pool_kernel_size = params\n\n conv_kernel_size = int(conv_kernel_size)\n pool_kernel_size = int(pool_kernel_size)\n\n model = ModelS(dropout_rate=dropout_rate, conv_kernel_size=conv_kernel_size, pool_kernel_size=pool_kernel_size).to(device)\n optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)\n\n n_epochs = 20\n patience = 5\n min_val_loss = float('inf')\n epochs_no_improve = 0\n\n for epoch in range(n_epochs):\n train_loss, train_accuracy = train(model, device, train_data_loader, optimizer)\n val_loss, val_accuracy = test(model, device, test_data_loader)\n\n # Check if validation loss has improved\n if val_loss < min_val_loss:\n min_val_loss = val_loss\n epochs_no_improve = 0\n else:\n epochs_no_improve += 1\n\n if epochs_no_improve >= patience:\n print(f\"Early stopping at epoch {epoch+1}\")\n break\n\n return min_val_loss\n```\n\n#### Define bound of search space (Unified for both Experiment and Production System)\n\n```python\n# List of hyperparameters to optimize.\n# For each hyperparameter, we specify:\n# - The bounds within which values will be selected.\n# - The corresponding parameter name as recognized by scikit-learn.\n# - The sampling distribution to guide value selection.\n# For instance, the learning rate uses a 'log-uniform' distribution.\n\nfrom skopt.space import Real, Integer, Categorical\n\nsearch_space = [\n Real(0.1, 1, name='dropout_rate'),\n Real(0.0001, 10, name='learning_rate', prior='log-uniform'),\n\n Integer(1, 10, name='conv_kernel_size'),\n Integer(1, 3, name='pool_kernel_size'),\n]\n```\n\n#### Optimize Experiment System Over 10 Iteration\n\n```python\nfrom scaleup_bo import SmallScaleOptimizer\n\nsmall_optimizer = SmallScaleOptimizer(objective_function_S, search_space, n_steps=10, n_initial_points=1)\n\n# Collect history from SmallScaleOptimizer\nbest_params_s = small_optimizer.best_params\nbest_hyperparameters = dict(zip(['dropout_rate', 'learning_rate', 'conv_kernel_size', 'pool_kernel_size'], best_params_s))\nprint(\"Best Hyperparameter of Small Model: \", best_hyperparameters)\n\nX_iters_small = small_optimizer.X_iters\nprint('X_iters_small: ', X_iters_small)\n\nY_iters_small = small_optimizer.Y_iters\nprint('Y_iters_small: ', Y_iters_small)\n\n```\n\n#### Output\n```bash\nBest Hyperparameter of Small Model: {'dropout_rate': 0.3002150723, 'learning_rate': 0.0007667914, 'conv_kernel_size': 6, 'pool_kernel_size': 3}\n\nX_iters_small: array([[0.7803350320816986, 9.083817128074404, 4, 3],\n [0.1, 0.0001, 10, 5],\n [0.2757733648, 0.0369179854, 2, 4],\n [0.2364062706, 0.0002389496, 3, 3],\n [0.9509629778, 0.0134669852, 3, 5],\n [0.6484239182, 0.1599534102, 2, 5],\n [0.9573643447, 0.4342609034, 6, 5],\n [0.4850212168, 0.1077820534, 4, 4],\n [0.3002150723, 0.0007667914, 6, 3],\n [0.4913776109, 0.0010069987, 5, 3],\n [0.3353326913, 0.0079244646, 7, 4]])\n\nY_iters_small: array([0.0417628 , 0.00486325, 0.00528098, 0.00400994, 0.00927958,\n 0.01945705, 0.03691163, 0.00989952, 0.00375851, 0.00390017,\n 0.0042957 ])\n```\n\n#### Plot Performance\n```python\nfrom scaleup_bo.plots import plot_performance\n\nplot_performance(small_optimizer)\n```\n\n\n#### Plot Evaluation \n```bash\nfrom scaleup_bo.plots import custom_plot_evaluation\n\ncustom_plot_evaluation(small_optimizer)\n```\n\n\n### Define the Production Model to optimize and the parameters are the same as Experiment System then define objective function to minimize using history leverage from Experiment System\n\n#### Define Production Model\n\n```python\nclass ModelL(nn.Module):\n def __init__(self, dropout_rate=0.2, conv_kernel_size=1, pool_kernel_size=2):\n super(ModelL, self).__init__()\n self.features = nn.Sequential(\n nn.Conv2d(1, 32, kernel_size=conv_kernel_size, padding=1),\n nn.ReLU(),\n nn.MaxPool2d(kernel_size=pool_kernel_size, stride=2),\n nn.Conv2d(32, 64, kernel_size=conv_kernel_size, padding=1),\n nn.ReLU(),\n nn.MaxPool2d(kernel_size=pool_kernel_size, stride=2),\n )\n\n self._compute_linear_input_size()\n\n self.classifier = nn.Sequential(\n nn.Dropout(dropout_rate),\n nn.Linear(self.linear_input_size, 128),\n nn.ReLU(),\n nn.Dropout(dropout_rate),\n nn.Linear(128, 10),\n nn.LogSoftmax(dim=1),\n )\n\n def _compute_linear_input_size(self):\n with torch.no_grad():\n dummy_input = torch.zeros(1, 1, 28, 28)\n features_output = self.features(dummy_input)\n num_channels, height, width = features_output.size()[1:]\n self.linear_input_size = num_channels * height * width\n\n def forward(self, x):\n x = self.features(x)\n x = torch.flatten(x, 1)\n x = self.classifier(x)\n return x\n\n# Transfer the model to the device that will perform the calculation.\nmodelL = ModelL().to(device)\n\n# Create an Optimizer for ModelL\noptimL = torch.optim.Adam(modelL.parameters())\n\n```\n\n#### Define Objective Function\n\n```python\n\ndef objective_function_L(params):\n dropout_rate, learning_rate, conv_kernel_size, pool_kernel_size = params\n\n conv_kernel_size = int(conv_kernel_size)\n pool_kernel_size = int(pool_kernel_size)\n\n modelL = ModelL(dropout_rate=dropout_rate, conv_kernel_size=conv_kernel_size, pool_kernel_size=pool_kernel_size).to(device)\n optimizer = torch.optim.Adam(modelL.parameters(), lr=learning_rate)\n\n n_epochs = 30\n patience = 5\n min_val_loss = float('inf')\n epochs_no_improve = 0\n\n for epoch in range(n_epochs):\n train_loss, train_accuracy = train(modelL, device, train_data_loader, optimizer)\n val_loss, val_accuracy = test(modelL, device, test_data_loader_L)\n\n # Check if validation loss has improved\n if val_loss < min_val_loss:\n min_val_loss = val_loss\n epochs_no_improve = 0\n else:\n epochs_no_improve += 1\n\n if epochs_no_improve >= patience:\n print(f\"Early stopping at epoch {epoch+1}\")\n break\n\n return min_val_loss\n```\n\n#### Optimize Production System Over 10 Iteration\n\n```python\nfrom scaleup_bo import LargeScaleOptimizer\n\nlarge_optimizer = LargeScaleOptimizer(objective_function_L, search_space, best_params=best_params_s, X_iters_small=X_iters_small, Y_iters_small=Y_iters_small, n_steps=10)\n\nbest_params_l = large_optimizer.best_params\nbest_hyperparameters_l = dict(zip(['dropout_rate', 'learning_rate', 'conv_kernel_size', 'pool_kernel_size'], best_params_s))\nprint(\"Best Hyperparameter of Large Model: \", best_hyperparameters_l)\n\nbest_score_l = large_optimizer.best_score\nprint(\"Best score of Large Model: \", best_score_l)\n```\n\n#### Output\n```bash\nBest Hyperparameter of Large Model: {'dropout_rate': 0.300215072, 'learning_rate': 0.0007667914, 'conv_kernel_size': 6, 'pool_kernel_size': 3}\n\nBest score of Large Model: 0.0035434851370751857\n```\n\n#### Plot Performance\n```python\nfrom scaleup_bo.plots import plot_performance\n\nplot_performance(large_optimizer)\n```\n\n\n#### Plot Evaluation \n```python\nfrom scaleup_bo.plots import custom_plot_evaluation\n\ncustom_plot_evaluation(large_optimizer)\n```\n\n",
"bugtrack_url": null,
"license": null,
"summary": "This library is use to optimize hyperparameter of machine learning with scale up algorithm",
"version": "1.0.6",
"project_urls": {
"Homepage": "https://gitlab.bird-initiative-dev.com/bird-initiative/scaleup-optimizer"
},
"split_keywords": [
"machine learning",
" hyperparameter optimization",
" scale up algorithm"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "55ff618754f3ee82554e0a28942f5a27be8848da3fda62beafd03dfc859e2b4a",
"md5": "e26b1b680cdb7466f46b0a85e5a93c8c",
"sha256": "bc5066f7de7189a6fc38f605970ec5e158f128e6c07f773ac12caa113d609199"
},
"downloads": -1,
"filename": "scaleup_optimizers-1.0.6-py3-none-any.whl",
"has_sig": false,
"md5_digest": "e26b1b680cdb7466f46b0a85e5a93c8c",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.6",
"size": 35593,
"upload_time": "2024-11-20T04:12:13",
"upload_time_iso_8601": "2024-11-20T04:12:13.498372Z",
"url": "https://files.pythonhosted.org/packages/55/ff/618754f3ee82554e0a28942f5a27be8848da3fda62beafd03dfc859e2b4a/scaleup_optimizers-1.0.6-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "01535ab721e7bfb7ba17662b0536aec45ce90200fb566572f5a0cf8ed138c3af",
"md5": "7e3458367f2e7b79dcad2a0d9dd535a9",
"sha256": "124e5d79e8ca30f57c6077b85fbfa27bfc1d644d373be66a656f3dc8d015c666"
},
"downloads": -1,
"filename": "scaleup_optimizers-1.0.6.tar.gz",
"has_sig": false,
"md5_digest": "7e3458367f2e7b79dcad2a0d9dd535a9",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.6",
"size": 27443,
"upload_time": "2024-11-20T04:12:15",
"upload_time_iso_8601": "2024-11-20T04:12:15.778994Z",
"url": "https://files.pythonhosted.org/packages/01/53/5ab721e7bfb7ba17662b0536aec45ce90200fb566572f5a0cf8ed138c3af/scaleup_optimizers-1.0.6.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-11-20 04:12:15",
"github": false,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"lcname": "scaleup-optimizers"
}
