# Shantay
*Shantay* is a [permissively
licensed](https://github.com/apparebit/shantay/blob/boss/LICENSE), open-source,
Python-based command line tool for analyzing the European Commission's [DSA
transparency database](https://transparency.dsa.ec.europa.eu/). That database
collects the anonymized statements of reasons for online platforms' content
moderation decision. Even though the database is huge, almost 2 TB and growing,
*shantay* runs on consumer hardware. All you need is a USB drive, such as the 2
TB Samsung T7, that is large enough to store the full database and, for some
tasks, patience, as they may take a day, or two.
I've written [a blog post about my initial
impressions](https://apparebit.com/blog/2025/sashay-shantay) of the DSA
transparency database. Let's just say that, Brussels, we've got, uhm, problems
(plural)!
## 1. Getting Started
*Shantay*'s Python package is [distributed through
PyPI](https://pypi.org/project/shantay/). Hence, you can use a Python tool
runner such as [pipx](https://github.com/pypa/pipx) or
[uvx](https://docs.astral.sh/uv/guides/tools/) for executing *shantay* without
even installing it:
```bash
$ pipx shantay -h
```
or
```bash
$ uvx shantay -h
```
In either case, *shantay* will output its help message, which describes command
line options and tasks in detail. But to get you acquainted, here are some
choice examples.
The EU started operating the database on the 25th of September, 2023. To
download the daily releases for that year and determine their summary
statistics, execute:
```
$ uvx shantay --archive <directory> --last 2023-12-31 summarize
```
Except, you want to replace `<directory>` with the path to a directory suitable
for storing the complete database.
The previous command will run for quite a while, downloading and analyzing
release after release after release. Depending on your hardware, using more than
one process for downloading and analyzing the data may be faster. The following
invocation, for example, uses three worker processes for downloading and
analyzing data:
```
$ uvx shantay --archive <directory> --last 2023-12-31 --multiproc 3 summarize
```
Don't forget to replace `<directory>` with the actual path.
When running with parallel worker processes, *shantay*'s original process serves
as coordinator. Notably, it updates the status display on the console and writes
log entries to a file, by default `shantay.log` in the current working
directory.
Once *shantay* is done downloading and summarizing the daily releases for 2023,
you'll find a `db.parquet` file in the archive's root directory. It contains the
summary statistics at day-granularity. To visualize that same data, execute:
```
$ uvx shantay --archive <directory> visualize
```
Once finished, you'll find an
[`db.html`](https://apparebit.github.io/shantay/db.html) document with all
charts in the default staging directory `dsa-db-staging`. (The linked version
covers far more data.)
Alas, three months of data from the beginning of the DSA transparency database
aren't particularly satisfying. Shantay ships with a copy of the summary
statistics for the entire database. To visualize them, execute:
```
$ uvx shantay visualize
```
Now look at the [`db.html`](https://apparebit.github.io/shantay/db.html) again:
Much better!
## 2. Using Shantay
The `summarize` and `visualize` tasks cover almost all of Shantay's
functionality. Nonetheless, Shantay supports a few more tasks for fine-grained
control and data recovery. Here are all of them:
- **download** makes sure that daily distributions are locally available,
retrieving them as necessary. This task lets your prepare for future
`--offline` operation by downloading archives as expediently as possible and
not performing any other processing.
- **distill** extracts a category-specific subset from daily distributions. It
requires both the `--archive` and `--extract` directories. For a new extract
directory, it also requires a `--category`. That category and other metadata
are stored in `meta.json`.
- **recover** scans the `--extract` directory to validate the files and
restore (some of the) metadata in `meta.json`.
- **summarize** collects summary statistics either for the full database or a
category-specific subset, depending on whether `--archive` only (for the
full database) or both `--archive` and `--extract` (for a subset) are
specified. If you specify neither, Shantay materializes the builtin copy of
the summary statistics in staging.
- **info** prints helpful information about Shantay, key dependencies, the
Python runtime, and operating system, as well as the `--archive` and
`--extract` directories and their contents. If you specify neither, Shantay
prints information about the builtin copy of the summary statistics.
- **visualize** generates an HTML document that visualizes summary statistics.
`--archive` and `--extract` determine the scope of the visualization, just
as for `summarize`. If you specify neither, Shantay visualizes the builtin
copy of the summary statistics. In addition to generating an HTML report,
Shantay also saves all charts as SVG graphics.
Unless the `--offline` option is specified, the `distill` and `summarize` tasks
download daily distributions as needed.
Unless the date range is restricted with `--first` and `--last`, the `distill`
task also extracts category-specific data as needed. By default, the `--first`
date is 2023-09-25, the day the DSA transparency database became operational,
and the `--last` date is three days before today—one day to allow for the
Americas being a day behind Europe for several hours every day and another two
days to allow for some posting delay.
Summary statistics are stored in `db.parquet` for the full database and in a
file named after the category, such as `protection-of-minors.parquet`, for
category-specific data. The HTML documents follow the same naming convention.
Shantay's log distinguishes between `summarize-all`, `summarize-category`, and
`summarize-builtin` when identifying tasks. Furthermore, even when executing a
category-specific `summarize` task, Shantay's log distinguishes `distill` from
`summarize-category`. For multiprocessing, it schedules both tasks separately.
## 3. Organization of Storage
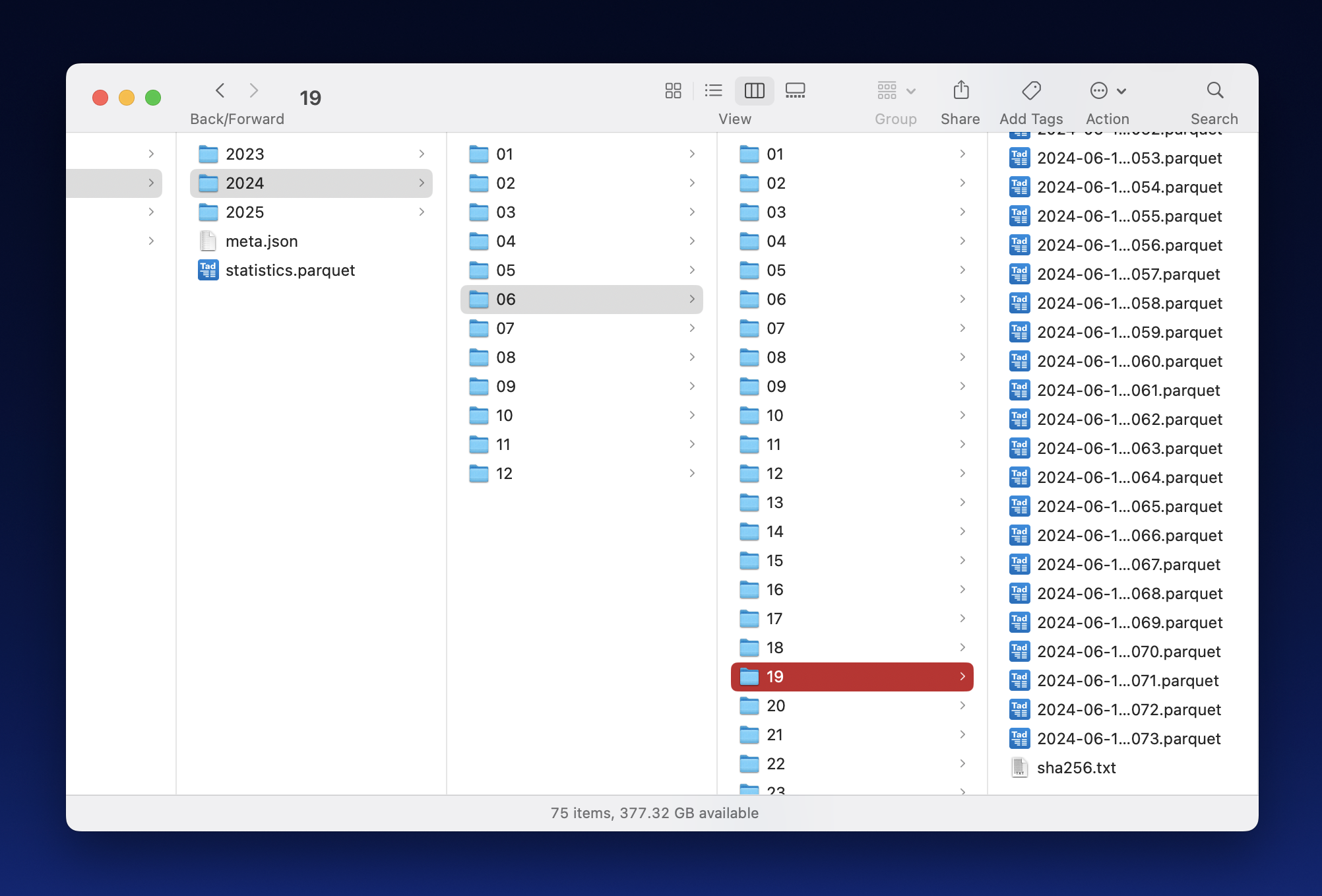
The screenshot below shows an example directory hierarchy under the `--extract`
root. It illustrates the directory levels discussed in 3.2 as well as the files
with digests and summary statistics discussed in 3.3.
### 3.1 Three Root Directories: Staging, Archive, Extract
*Shantay* distinguishes between three primary directories, `--staging` as
temporary storage, `--archive` for the original distributions, and `--extract`
for a category-specific subset:
- **Staging** stores data currently being processed, e.g., by uncompressing,
converting, and filtering it. You wouldn't be wrong if you called this
directory *temp* or *tmp* instead. This directory must be on a fast, local
file system; it should not be on an external disk, particularly not if the
disk is connected with USB.
- **Archive** stores the original, daily ZIP files and their SHA1 digests. It
is treated as append-only storage and holds the ground truth. This directory
must be on a large file system, e.g., 2 TB just about holds all data from
2023-09-25 into May 2025. This directory may be on an external drive (such
as the already mentioned T7).
- **Extract** stores parquet files with a (much) smaller subset of the
database. Like *archive*, *extract* is treated as append-only storage.
Unlike *archive*, which is unique, different runs of *shantay* may use
different *extract* directories representing different subsets of the
database.
### 3.2 Three Levels of Nested Directories: Year, Month, Day
Under the three root directories, *shantay* arranges files into a hierarchy of
directories, e.g., resulting in paths like
`2025/03/14/2025-03-14-00000.parquet`. The top level is named for years,
followed by two-digit months one level down, followed by two-digit days another
level down. Finally, daily archive files have their original names, whereas
files with category-specific data are named after the date and a zero-based
five-digit index (as illustrated earlier in this paragraph).
For the extract root, *shantay* maintains a per-day digest file named
`sha256.txt`. It contains the SHA-256 digests for every parquet file in the
directory: Each line contains one hexadecimal ASCII digest, a space,and the
file's name.
### 3.3 Summary Statistics
In addition to yearly directories, *shantay* also stores the following two files
inside root directories.
- A JSON file named after the category, e.g., `protection-of-minors.json`
contains an object with the `category` used for selecting the data extract
and some statistics about `releases`. `batch_count` must be the number of
daily data files and `sha256` must be the (recursive) digest of the digests
in the `sha256.txt` file.
- `db.parquet` contains the summary statistics about the full database.
Statistics for category-specific subsets are named after their categories.
Each file basically is a non-tidy, long data frame that uses up to seven
columns for identifying variables and up to four columns for identifying
values. While an encoding with fewer columns is eminently feasible, the
schema is optimized for being easy to work with (e.g., aggregations are
trivial) and compact to store (e.g., a column with mostly nulls requires
almost no space).
The individual columns are:
- `start_date` and `end_date` denote the date coverage of a row.
- `tag` is the category for filtered source data.
- `platform` is the online platform making the disclosures.
- `column` is the original transparency database column, with a few
virtual column names added.
- `entity` describes the metric contained in that row.
- `variant` captures values from the original database, encoded as a very
large enumeration.
- `text` does the same for transparency database columns with arbitrary
text.
- `count`, `min`, `mean`, and `max` contain the eponymous descriptive
statistics.
If `mean` contains a value, then `count` also contains a value, thus
enabling correct aggregation with a weighted average.
## 4. Big Data in the Small
Unlike most big data tools, Shantay is designed to run on consumer-level
hardware, e.g., a reasonably fast laptop or desktop with an external flash
drive, such as the Samsung T7, will do. In fact, that's my own setup: My primary
development machine is a four-year-old x86 iMac and all data is stored on a 2 TB
Samsung drive—though I'll have to upgrade to the next larger size soon enough.
Shantay targets consumer-level hardware because transparency as an
accountability mechanism mustn't be limited to people who have access to compute
clusters, whether locally or in the cloud. No, for a transparency database to be
effective, anyone with a reasonable computer should be able to do their own
analysis.
That seeming limitation also is a blessing in disguise. Notably, the [EU's
official tool](https://code.europa.eu/dsa/transparency-database/dsa-tdb) uses
the [Apache Spark engine](https://spark.apache.org), which has excellent
scalability but also very high resource requirements for every cluster node. In
other words, while the EU's tool does run on individual machines, it also runs
very slowly. In contrast, Shantay builds on the [Pola.rs](https://pola.rs) data
frame library, which is much simpler and faster when running on a single
computer. In addition, Shantay makes the most of available resources and
supports parallel execution across a (small) number of processes, which does
make a difference in my experience.
----
(C) 2025 by Robert Grimm. The Python source code in this repository has been
released as open source under the [Apache
2.0](https://github.com/apparebit/shantay/blob/boss/LICENSE) license.
Raw data
{
"_id": null,
"home_page": null,
"name": "shantay",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.12",
"maintainer_email": null,
"keywords": "batch processing, EU DSA, statement of reason",
"author": null,
"author_email": "Robert Grimm <rgrimm@alum.mit.edu>",
"download_url": "https://files.pythonhosted.org/packages/87/d3/51c52dc04c7f19afe71f608208f975c4bc6ffaf557de2d34f82fc8d1947b/shantay-0.5.0.tar.gz",
"platform": null,
"description": "# Shantay\n\n*Shantay* is a [permissively\nlicensed](https://github.com/apparebit/shantay/blob/boss/LICENSE), open-source,\nPython-based command line tool for analyzing the European Commission's [DSA\ntransparency database](https://transparency.dsa.ec.europa.eu/). That database\ncollects the anonymized statements of reasons for online platforms' content\nmoderation decision. Even though the database is huge, almost 2 TB and growing,\n*shantay* runs on consumer hardware. All you need is a USB drive, such as the 2\nTB Samsung T7, that is large enough to store the full database and, for some\ntasks, patience, as they may take a day, or two.\n\nI've written [a blog post about my initial\nimpressions](https://apparebit.com/blog/2025/sashay-shantay) of the DSA\ntransparency database. Let's just say that, Brussels, we've got, uhm, problems\n(plural)!\n\n\n## 1. Getting Started\n\n*Shantay*'s Python package is [distributed through\nPyPI](https://pypi.org/project/shantay/). Hence, you can use a Python tool\nrunner such as [pipx](https://github.com/pypa/pipx) or\n[uvx](https://docs.astral.sh/uv/guides/tools/) for executing *shantay* without\neven installing it:\n\n```bash\n$ pipx shantay -h\n```\nor\n```bash\n$ uvx shantay -h\n```\n\nIn either case, *shantay* will output its help message, which describes command\nline options and tasks in detail. But to get you acquainted, here are some\nchoice examples.\n\nThe EU started operating the database on the 25th of September, 2023. To\ndownload the daily releases for that year and determine their summary\nstatistics, execute:\n\n```\n$ uvx shantay --archive <directory> --last 2023-12-31 summarize\n```\n\nExcept, you want to replace `<directory>` with the path to a directory suitable\nfor storing the complete database.\n\nThe previous command will run for quite a while, downloading and analyzing\nrelease after release after release. Depending on your hardware, using more than\none process for downloading and analyzing the data may be faster. The following\ninvocation, for example, uses three worker processes for downloading and\nanalyzing data:\n\n```\n$ uvx shantay --archive <directory> --last 2023-12-31 --multiproc 3 summarize\n```\n\nDon't forget to replace `<directory>` with the actual path.\n\nWhen running with parallel worker processes, *shantay*'s original process serves\nas coordinator. Notably, it updates the status display on the console and writes\nlog entries to a file, by default `shantay.log` in the current working\ndirectory.\n\nOnce *shantay* is done downloading and summarizing the daily releases for 2023,\nyou'll find a `db.parquet` file in the archive's root directory. It contains the\nsummary statistics at day-granularity. To visualize that same data, execute:\n\n```\n$ uvx shantay --archive <directory> visualize\n```\n\nOnce finished, you'll find an\n[`db.html`](https://apparebit.github.io/shantay/db.html) document with all\ncharts in the default staging directory `dsa-db-staging`. (The linked version\ncovers far more data.)\n\nAlas, three months of data from the beginning of the DSA transparency database\naren't particularly satisfying. Shantay ships with a copy of the summary\nstatistics for the entire database. To visualize them, execute:\n\n```\n$ uvx shantay visualize\n```\n\nNow look at the [`db.html`](https://apparebit.github.io/shantay/db.html) again:\nMuch better!\n\n\n## 2. Using Shantay\n\nThe `summarize` and `visualize` tasks cover almost all of Shantay's\nfunctionality. Nonetheless, Shantay supports a few more tasks for fine-grained\ncontrol and data recovery. Here are all of them:\n\n - **download** makes sure that daily distributions are locally available,\n retrieving them as necessary. This task lets your prepare for future\n `--offline` operation by downloading archives as expediently as possible and\n not performing any other processing.\n\n - **distill** extracts a category-specific subset from daily distributions. It\n requires both the `--archive` and `--extract` directories. For a new extract\n directory, it also requires a `--category`. That category and other metadata\n are stored in `meta.json`.\n\n - **recover** scans the `--extract` directory to validate the files and\n restore (some of the) metadata in `meta.json`.\n\n - **summarize** collects summary statistics either for the full database or a\n category-specific subset, depending on whether `--archive` only (for the\n full database) or both `--archive` and `--extract` (for a subset) are\n specified. If you specify neither, Shantay materializes the builtin copy of\n the summary statistics in staging.\n\n - **info** prints helpful information about Shantay, key dependencies, the\n Python runtime, and operating system, as well as the `--archive` and\n `--extract` directories and their contents. If you specify neither, Shantay\n prints information about the builtin copy of the summary statistics.\n\n - **visualize** generates an HTML document that visualizes summary statistics.\n `--archive` and `--extract` determine the scope of the visualization, just\n as for `summarize`. If you specify neither, Shantay visualizes the builtin\n copy of the summary statistics. In addition to generating an HTML report,\n Shantay also saves all charts as SVG graphics.\n\nUnless the `--offline` option is specified, the `distill` and `summarize` tasks\ndownload daily distributions as needed.\n\nUnless the date range is restricted with `--first` and `--last`, the `distill`\ntask also extracts category-specific data as needed. By default, the `--first`\ndate is 2023-09-25, the day the DSA transparency database became operational,\nand the `--last` date is three days before today\u2014one day to allow for the\nAmericas being a day behind Europe for several hours every day and another two\ndays to allow for some posting delay.\n\nSummary statistics are stored in `db.parquet` for the full database and in a\nfile named after the category, such as `protection-of-minors.parquet`, for\ncategory-specific data. The HTML documents follow the same naming convention.\n\nShantay's log distinguishes between `summarize-all`, `summarize-category`, and\n`summarize-builtin` when identifying tasks. Furthermore, even when executing a\ncategory-specific `summarize` task, Shantay's log distinguishes `distill` from\n`summarize-category`. For multiprocessing, it schedules both tasks separately.\n\n\n## 3. Organization of Storage\n\nThe screenshot below shows an example directory hierarchy under the `--extract`\nroot. It illustrates the directory levels discussed in 3.2 as well as the files\nwith digests and summary statistics discussed in 3.3.\n\n\n\n\n### 3.1 Three Root Directories: Staging, Archive, Extract\n\n*Shantay* distinguishes between three primary directories, `--staging` as\ntemporary storage, `--archive` for the original distributions, and `--extract`\nfor a category-specific subset:\n\n - **Staging** stores data currently being processed, e.g., by uncompressing,\n converting, and filtering it. You wouldn't be wrong if you called this\n directory *temp* or *tmp* instead. This directory must be on a fast, local\n file system; it should not be on an external disk, particularly not if the\n disk is connected with USB.\n - **Archive** stores the original, daily ZIP files and their SHA1 digests. It\n is treated as append-only storage and holds the ground truth. This directory\n must be on a large file system, e.g., 2 TB just about holds all data from\n 2023-09-25 into May 2025. This directory may be on an external drive (such\n as the already mentioned T7).\n - **Extract** stores parquet files with a (much) smaller subset of the\n database. Like *archive*, *extract* is treated as append-only storage.\n Unlike *archive*, which is unique, different runs of *shantay* may use\n different *extract* directories representing different subsets of the\n database.\n\n\n### 3.2 Three Levels of Nested Directories: Year, Month, Day\n\nUnder the three root directories, *shantay* arranges files into a hierarchy of\ndirectories, e.g., resulting in paths like\n`2025/03/14/2025-03-14-00000.parquet`. The top level is named for years,\nfollowed by two-digit months one level down, followed by two-digit days another\nlevel down. Finally, daily archive files have their original names, whereas\nfiles with category-specific data are named after the date and a zero-based\nfive-digit index (as illustrated earlier in this paragraph).\n\nFor the extract root, *shantay* maintains a per-day digest file named\n`sha256.txt`. It contains the SHA-256 digests for every parquet file in the\ndirectory: Each line contains one hexadecimal ASCII digest, a space,and the\nfile's name.\n\n\n### 3.3 Summary Statistics\n\nIn addition to yearly directories, *shantay* also stores the following two files\ninside root directories.\n\n - A JSON file named after the category, e.g., `protection-of-minors.json`\n contains an object with the `category` used for selecting the data extract\n and some statistics about `releases`. `batch_count` must be the number of\n daily data files and `sha256` must be the (recursive) digest of the digests\n in the `sha256.txt` file.\n\n - `db.parquet` contains the summary statistics about the full database.\n Statistics for category-specific subsets are named after their categories.\n Each file basically is a non-tidy, long data frame that uses up to seven\n columns for identifying variables and up to four columns for identifying\n values. While an encoding with fewer columns is eminently feasible, the\n schema is optimized for being easy to work with (e.g., aggregations are\n trivial) and compact to store (e.g., a column with mostly nulls requires\n almost no space).\n\n The individual columns are:\n\n - `start_date` and `end_date` denote the date coverage of a row.\n - `tag` is the category for filtered source data.\n - `platform` is the online platform making the disclosures.\n - `column` is the original transparency database column, with a few\n virtual column names added.\n - `entity` describes the metric contained in that row.\n - `variant` captures values from the original database, encoded as a very\n large enumeration.\n - `text` does the same for transparency database columns with arbitrary\n text.\n - `count`, `min`, `mean`, and `max` contain the eponymous descriptive\n statistics.\n\n If `mean` contains a value, then `count` also contains a value, thus\n enabling correct aggregation with a weighted average.\n\n\n## 4. Big Data in the Small\n\nUnlike most big data tools, Shantay is designed to run on consumer-level\nhardware, e.g., a reasonably fast laptop or desktop with an external flash\ndrive, such as the Samsung T7, will do. In fact, that's my own setup: My primary\ndevelopment machine is a four-year-old x86 iMac and all data is stored on a 2 TB\nSamsung drive\u2014though I'll have to upgrade to the next larger size soon enough.\n\nShantay targets consumer-level hardware because transparency as an\naccountability mechanism mustn't be limited to people who have access to compute\nclusters, whether locally or in the cloud. No, for a transparency database to be\neffective, anyone with a reasonable computer should be able to do their own\nanalysis.\n\nThat seeming limitation also is a blessing in disguise. Notably, the [EU's\nofficial tool](https://code.europa.eu/dsa/transparency-database/dsa-tdb) uses\nthe [Apache Spark engine](https://spark.apache.org), which has excellent\nscalability but also very high resource requirements for every cluster node. In\nother words, while the EU's tool does run on individual machines, it also runs\nvery slowly. In contrast, Shantay builds on the [Pola.rs](https://pola.rs) data\nframe library, which is much simpler and faster when running on a single\ncomputer. In addition, Shantay makes the most of available resources and\nsupports parallel execution across a (small) number of processes, which does\nmake a difference in my experience.\n\n----\n\n(C) 2025 by Robert Grimm. The Python source code in this repository has been\nreleased as open source under the [Apache\n2.0](https://github.com/apparebit/shantay/blob/boss/LICENSE) license.\n",
"bugtrack_url": null,
"license": null,
"summary": "investigating the EU's DSA transparency database",
"version": "0.5.0",
"project_urls": {
"repository": "https://github.com/apparebit/shantay"
},
"split_keywords": [
"batch processing",
" eu dsa",
" statement of reason"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "f4c49d4cababf139119f066e4be66e2214635445616308e8f5bf494a2f24179e",
"md5": "731a0786ebd8f26beea32676e22a8270",
"sha256": "5ddc0c5744e41d978577c1cea0ea12ef96513603c8f8a311fdb03d4748d33b0b"
},
"downloads": -1,
"filename": "shantay-0.5.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "731a0786ebd8f26beea32676e22a8270",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.12",
"size": 5643507,
"upload_time": "2025-07-28T18:22:10",
"upload_time_iso_8601": "2025-07-28T18:22:10.468366Z",
"url": "https://files.pythonhosted.org/packages/f4/c4/9d4cababf139119f066e4be66e2214635445616308e8f5bf494a2f24179e/shantay-0.5.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "87d351c52dc04c7f19afe71f608208f975c4bc6ffaf557de2d34f82fc8d1947b",
"md5": "e23fdc620b531354d2e708df9f653500",
"sha256": "efc4fe80de55c0e21696f0498b02261c38960d40a256846dca172dd0b8da3561"
},
"downloads": -1,
"filename": "shantay-0.5.0.tar.gz",
"has_sig": false,
"md5_digest": "e23fdc620b531354d2e708df9f653500",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.12",
"size": 6478861,
"upload_time": "2025-07-28T18:22:13",
"upload_time_iso_8601": "2025-07-28T18:22:13.002414Z",
"url": "https://files.pythonhosted.org/packages/87/d3/51c52dc04c7f19afe71f608208f975c4bc6ffaf557de2d34f82fc8d1947b/shantay-0.5.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-07-28 18:22:13",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "apparebit",
"github_project": "shantay",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "shantay"
}

