| Name | spaceavocado-x12 JSON |
| Version |
1.0.1
 JSON
JSON |
| download |
| home_page | |
| Summary | Simple X12 files parser. |
| upload_time | 2023-03-16 03:21:18 |
| maintainer | |
| docs_url | None |
| author | |
| requires_python | >=3.7 |
| license | Copyright (c) 2023, David Horak (info@davidhorak.com) Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. |
| keywords |
x12
parser
schema
|
| VCS |
|
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# Space Avocado X12 Parser
A simple X12 file parser, allowing to parse X12 loops and segment based on schema.
*Credit: Inspired by [Maven Central X12 Parser](https://github.com/ryanco/x12-parser).*
> X12 is a message formatting standard used with Electronic Data Interchange (EDI) documents for trading partners to share electronic business documents in an agreed-upon and standard format. It is the most common EDI standard used in the United States.
**X12 Document List**: https://en.wikipedia.org/wiki/X12_Document_List
**X12 Schematic:**
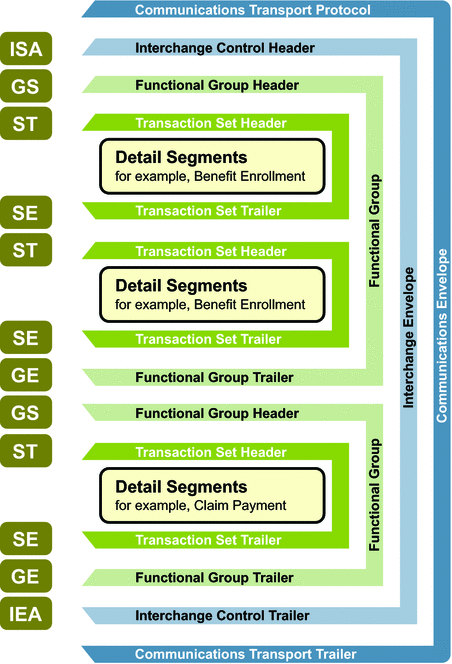
See more details at https://x12.org/.
---
**Table of Content**
- [Space Avocado X12 Parser](#space-avocado-x12-parser)
- [Installation](#installation)
- [How to use](#how-to-use)
- [1. Define a schema for the x12 file to be parsed.](#1-define-a-schema-for-the-x12-file-to-be-parsed)
- [Loop/Segment Matcher Predicate](#loopsegment-matcher-predicate)
- [Loop schema could be decorated with segment schemas](#loop-schema-could-be-decorated-with-segment-schemas)
- [2. Parse](#2-parse)
- [Loop Operations](#loop-operations)
- [Segment Operations](#segment-operations)
- [3. Optional: Analyze parsed loop.](#3-optional-analyze-parsed-loop)
- [Contributing](#contributing)
- [License](#license)
---
## Installation
You can install the **Space Avocado X12 Parser** from [PyPI](https://pypi.org/project/spaceavocado-x12/):
python -m pip install spaceavocado-x12
The reader is supported on Python 3.7 and above.
## How to use
### 1. Define a schema for the x12 file to be parsed.
```py
from x12.schema.schema import Schema, Usage, by_segment, by_segment_element
def schema() -> Schema:
x12 = Schema('X12')
isa = x12.add_child('ISA', Usage.REQUIRED, by_segment('ISA'))
gs = isa.add_child('GS', Usage.REQUIRED, by_segment('GS'))
st = gs.add_child('ST', Usage.REQUIRED, by_segment_element('ST', 1, ['835']))
st.add_child('1000A', Usage.REQUIRED, by_segment_element('N1', 1, ['PR']))
st.add_child('1000B', Usage.REQUIRED, by_segment_element('N1', 1, ['PE']))
mm = st.add_child('2000', Usage.REQUIRED, by_segment('LX'))
mmc = mm.add_child('2100', Usage.REQUIRED, by_segment('CLP'))
mmc.add_child('2110', Usage.REQUIRED, by_segment('SVC'))
gs.add_child('SE', Usage.REQUIRED, by_segment('SE'))
isa.add_child('GE', Usage.REQUIRED, by_segment('GE'))
x12.add_child('IEA', Usage.REQUIRED, by_segment('IEA'))
return x12
```
To see the structure of the schema: ```print(schema())```.
```
+--X12
| +--ISA
| | +--GS
| | | +--ST
| | | | +--1000A
| | | | +--1000B
| | | | +--2000
| | | | | +--2100
| | | | | | +--2110
| | | +--SE
| | +--GE
| +--IEA
```
The above is an example of true nested structure of x12 835 document schema but schema could be defied in any, i.e. you can get flat structure if needed, e.g.:
```py
from x12.schema.schema import Schema, Usage, by_segment, by_segment_element
def schema() -> Schema:
x12 = Schema('X12')
x12.add_child('1000A', Usage.REQUIRED, by_segment_element('N1', 1, ['PR']))
x12.add_child('1000B', Usage.REQUIRED, by_segment_element('N1', 1, ['PE']))
x12.add_child('2000', Usage.REQUIRED, by_segment('LX'))
x12.add_child('2100', Usage.REQUIRED, by_segment('CLP'))
x12.add_child('2110', Usage.REQUIRED, by_segment('SVC'))
return x12
```
```
+--X12
| +--1000A
| +--1000B
| +--2000
| +--2100
| +--2110
```
#### Loop/Segment Matcher Predicate
There are 2 build-in predicates, for the most commonly used situations:
**by_segment**
- Used to determine a **loop** by **segment ID**.
- E.g.: ```by_segment('LX')``` matches this segment ```LX*DATA_1*DATA_N~```.
**by_segment_element**
- Used to determine a **loop** by **segment ID** and **element value(s)** at given **element index**.
- In many situations loop could start with the same segment id but differing the element values.
- E.g.: ```by_segment_element('N1', 1, ['PR', 'PE'])``` matches this segment ```N1*PR*DATA_N~``` or ```N1*PE*DATA_N~``` but not ```N1*QE*DATA_N~```.
A custom predicate function could be used:
- ```x12.add_child('2000', Usage.REQUIRED, lambda tokens: tokens[0] == "LX")```.
- The above is an equivalent of ```x12.add_child('2000', Usage.REQUIRED, by_segment('LX'))```.
#### Loop schema could be decorated with segment schemas
This is useful of [Analyze parsed loop](#3-optional-analyze-parsed-loop).
Example:
```py
from x12.schema.schema import Segment
gs.add_child('ST', Usage.REQUIRED, by_segment_element('ST', 1, ['835'])).with_segments(
Segment('ST', Usage.REQUIRED, by_segment('ST')),
Segment('BPR', Usage.REQUIRED, by_segment('BPR')),
Segment('TRN', Usage.REQUIRED, by_segment('TRN')),
Segment('REF', Usage.REQUIRED, by_segment('REF')),
Segment('DTM', Usage.REQUIRED, by_segment('DTM'))
)
```
- Uses the same Usage and predicates as **Loop** schema.
- The segment schemas are in sequential order of anticipated segments within the given loop.
### 2. Parse
```py
from x12.schema.schema import Schema, Usage
from x12.parser.parse import parse
# Real schema here
schema = Schema("X12")
loop = parse(filepath_to_x12_file, schema)
```
**Note**: if the x12 file does use the standard segment, element and composite separators, you can provide custom definition:
```py
from x12.parser.context import Context
loop = parse(filepath_to_x12_file, schema, Context("~", "*", ":"))
```
#### Loop Operations
**Serialization:**
Loop could be serialized to:
- XML: ```loop.to_xml()```
- original x12 format ```str(loop)```
- Debug view: ```loop.to_debug()```. This provides visual distinction for loops and segments.
**Find Child Loops:**
```py
# find loop by loop schema name
# Non recursive, search only within loop's direct children loops
loops = loop.find_loops("ST")
# Recursive, find loops anywhere in the downstream tree structure.
loops = loop.find_loops("NM1", True)
```
**Find Segments:**
```py
# find segment by segment ID
# Non recursive, search only within loop's segments
segments = loop.find_segments("ST")
# Recursive, find segments anywhere in the downstream tree structure.
segments = loop.find_segments("NM1", True)
```
**Other operations:**
- To access loop parent: ```loop.parent```
- Direct access to children loops: ```loop.loops```
- Direct access to segments: ```loop.segments```
#### Segment Operations
**Serialization:**
Segment could be serialized to:
- XML: ```segment.to_xml()```
- original x12 format ```str(segment)```
- Debug view: ```segment.to_debug()```. This provides visual distinction for segments.

**Access segment elements**
```segment.elements```
### 3. Optional: Analyze parsed loop.
This is an optional step to analyze the parsed document to see missing and unexpected loops/segments based on the schema.
```py
from x12.schema.schema import Schema, Usage
from x12.parser.parse import parse
from x12.parser.analyze import analyze
# Real schema here
schema = Schema("X12")
loop = parse(filepath_to_x12_file, schema)
print(analyze(loop))
```
**Example:**

- Red indicates missing loops / segments.
- Yellow indicates unexpected segments.
---
## Contributing
See [contributing.md](https://github.com/spaceavocado/x12/blob/master/contributing.md).
## License
Space Avocado X12 Parser is released under the MIT license. See [LICENSE.md]([LICENSE.md](https://github.com/spaceavocado/x12/blob/master/LICENSE.md)).
Raw data
{
"_id": null,
"home_page": "",
"name": "spaceavocado-x12",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.7",
"maintainer_email": "",
"keywords": "x12,parser,schema",
"author": "",
"author_email": "David Horak <info@davidhorak.com>",
"download_url": "https://files.pythonhosted.org/packages/be/83/28e3c52124f1fa330cf1e73304ee27d47a1565a3cb1c5786088b0947f684/spaceavocado-x12-1.0.1.tar.gz",
"platform": null,
"description": "# Space Avocado X12 Parser\r\nA simple X12 file parser, allowing to parse X12 loops and segment based on schema.\r\n\r\n*Credit: Inspired by [Maven Central X12 Parser](https://github.com/ryanco/x12-parser).*\r\n\r\n> X12 is a message formatting standard used with Electronic Data Interchange (EDI) documents for trading partners to share electronic business documents in an agreed-upon and standard format. It is the most common EDI standard used in the United States.\r\n\r\n**X12 Document List**: https://en.wikipedia.org/wiki/X12_Document_List\r\n\r\n**X12 Schematic:**\r\n\r\n\r\n\r\nSee more details at https://x12.org/.\r\n\r\n---\r\n\r\n**Table of Content**\r\n- [Space Avocado X12 Parser](#space-avocado-x12-parser)\r\n - [Installation](#installation)\r\n - [How to use](#how-to-use)\r\n - [1. Define a schema for the x12 file to be parsed.](#1-define-a-schema-for-the-x12-file-to-be-parsed)\r\n - [Loop/Segment Matcher Predicate](#loopsegment-matcher-predicate)\r\n - [Loop schema could be decorated with segment schemas](#loop-schema-could-be-decorated-with-segment-schemas)\r\n - [2. Parse](#2-parse)\r\n - [Loop Operations](#loop-operations)\r\n - [Segment Operations](#segment-operations)\r\n - [3. Optional: Analyze parsed loop.](#3-optional-analyze-parsed-loop)\r\n - [Contributing](#contributing)\r\n - [License](#license)\r\n\r\n---\r\n\r\n## Installation\r\n\r\nYou can install the **Space Avocado X12 Parser** from [PyPI](https://pypi.org/project/spaceavocado-x12/):\r\n\r\n python -m pip install spaceavocado-x12\r\n\r\nThe reader is supported on Python 3.7 and above.\r\n\r\n## How to use\r\n\r\n### 1. Define a schema for the x12 file to be parsed.\r\n\r\n```py\r\nfrom x12.schema.schema import Schema, Usage, by_segment, by_segment_element\r\n\r\ndef schema() -> Schema:\r\n x12 = Schema('X12')\r\n isa = x12.add_child('ISA', Usage.REQUIRED, by_segment('ISA'))\r\n gs = isa.add_child('GS', Usage.REQUIRED, by_segment('GS'))\r\n st = gs.add_child('ST', Usage.REQUIRED, by_segment_element('ST', 1, ['835']))\r\n\r\n st.add_child('1000A', Usage.REQUIRED, by_segment_element('N1', 1, ['PR']))\r\n st.add_child('1000B', Usage.REQUIRED, by_segment_element('N1', 1, ['PE']))\r\n\r\n mm = st.add_child('2000', Usage.REQUIRED, by_segment('LX'))\r\n mmc = mm.add_child('2100', Usage.REQUIRED, by_segment('CLP'))\r\n mmc.add_child('2110', Usage.REQUIRED, by_segment('SVC'))\r\n\r\n gs.add_child('SE', Usage.REQUIRED, by_segment('SE'))\r\n isa.add_child('GE', Usage.REQUIRED, by_segment('GE'))\r\n x12.add_child('IEA', Usage.REQUIRED, by_segment('IEA'))\r\n\r\n return x12\r\n```\r\n\r\nTo see the structure of the schema: ```print(schema())```.\r\n\r\n```\r\n+--X12\r\n| +--ISA\r\n| | +--GS\r\n| | | +--ST\r\n| | | | +--1000A\r\n| | | | +--1000B\r\n| | | | +--2000\r\n| | | | | +--2100\r\n| | | | | | +--2110\r\n| | | +--SE\r\n| | +--GE\r\n| +--IEA\r\n```\r\n\r\nThe above is an example of true nested structure of x12 835 document schema but schema could be defied in any, i.e. you can get flat structure if needed, e.g.:\r\n\r\n```py\r\nfrom x12.schema.schema import Schema, Usage, by_segment, by_segment_element\r\n\r\ndef schema() -> Schema:\r\n x12 = Schema('X12')\r\n\r\n x12.add_child('1000A', Usage.REQUIRED, by_segment_element('N1', 1, ['PR']))\r\n x12.add_child('1000B', Usage.REQUIRED, by_segment_element('N1', 1, ['PE']))\r\n\r\n x12.add_child('2000', Usage.REQUIRED, by_segment('LX'))\r\n x12.add_child('2100', Usage.REQUIRED, by_segment('CLP'))\r\n x12.add_child('2110', Usage.REQUIRED, by_segment('SVC'))\r\n\r\n return x12\r\n```\r\n\r\n```\r\n+--X12\r\n| +--1000A\r\n| +--1000B\r\n| +--2000\r\n| +--2100\r\n| +--2110\r\n```\r\n\r\n#### Loop/Segment Matcher Predicate\r\nThere are 2 build-in predicates, for the most commonly used situations:\r\n\r\n**by_segment**\r\n- Used to determine a **loop** by **segment ID**.\r\n- E.g.: ```by_segment('LX')``` matches this segment ```LX*DATA_1*DATA_N~```.\r\n\r\n**by_segment_element**\r\n- Used to determine a **loop** by **segment ID** and **element value(s)** at given **element index**.\r\n- In many situations loop could start with the same segment id but differing the element values.\r\n- E.g.: ```by_segment_element('N1', 1, ['PR', 'PE'])``` matches this segment ```N1*PR*DATA_N~``` or ```N1*PE*DATA_N~``` but not ```N1*QE*DATA_N~```.\r\n\r\nA custom predicate function could be used:\r\n- ```x12.add_child('2000', Usage.REQUIRED, lambda tokens: tokens[0] == \"LX\")```.\r\n- The above is an equivalent of ```x12.add_child('2000', Usage.REQUIRED, by_segment('LX'))```.\r\n\r\n#### Loop schema could be decorated with segment schemas\r\nThis is useful of [Analyze parsed loop](#3-optional-analyze-parsed-loop).\r\n\r\nExample:\r\n```py\r\nfrom x12.schema.schema import Segment\r\n\r\ngs.add_child('ST', Usage.REQUIRED, by_segment_element('ST', 1, ['835'])).with_segments(\r\n Segment('ST', Usage.REQUIRED, by_segment('ST')),\r\n Segment('BPR', Usage.REQUIRED, by_segment('BPR')),\r\n Segment('TRN', Usage.REQUIRED, by_segment('TRN')),\r\n Segment('REF', Usage.REQUIRED, by_segment('REF')),\r\n Segment('DTM', Usage.REQUIRED, by_segment('DTM'))\r\n)\r\n```\r\n- Uses the same Usage and predicates as **Loop** schema.\r\n- The segment schemas are in sequential order of anticipated segments within the given loop.\r\n\r\n\r\n### 2. Parse\r\n\r\n```py\r\nfrom x12.schema.schema import Schema, Usage\r\nfrom x12.parser.parse import parse\r\n\r\n# Real schema here\r\nschema = Schema(\"X12\")\r\n\r\nloop = parse(filepath_to_x12_file, schema)\r\n```\r\n\r\n**Note**: if the x12 file does use the standard segment, element and composite separators, you can provide custom definition:\r\n\r\n```py\r\nfrom x12.parser.context import Context\r\n\r\nloop = parse(filepath_to_x12_file, schema, Context(\"~\", \"*\", \":\"))\r\n```\r\n\r\n#### Loop Operations\r\n\r\n**Serialization:**\r\nLoop could be serialized to:\r\n- XML: ```loop.to_xml()```\r\n- original x12 format ```str(loop)```\r\n- Debug view: ```loop.to_debug()```. This provides visual distinction for loops and segments.\r\n \r\n\r\n**Find Child Loops:**\r\n```py\r\n# find loop by loop schema name\r\n\r\n# Non recursive, search only within loop's direct children loops\r\nloops = loop.find_loops(\"ST\")\r\n\r\n# Recursive, find loops anywhere in the downstream tree structure.\r\nloops = loop.find_loops(\"NM1\", True)\r\n```\r\n\r\n**Find Segments:**\r\n```py\r\n# find segment by segment ID\r\n\r\n# Non recursive, search only within loop's segments\r\nsegments = loop.find_segments(\"ST\")\r\n\r\n# Recursive, find segments anywhere in the downstream tree structure.\r\nsegments = loop.find_segments(\"NM1\", True)\r\n```\r\n\r\n**Other operations:**\r\n- To access loop parent: ```loop.parent```\r\n- Direct access to children loops: ```loop.loops```\r\n- Direct access to segments: ```loop.segments```\r\n\r\n#### Segment Operations\r\n\r\n**Serialization:**\r\nSegment could be serialized to:\r\n- XML: ```segment.to_xml()```\r\n- original x12 format ```str(segment)```\r\n- Debug view: ```segment.to_debug()```. This provides visual distinction for segments.\r\n \r\n\r\n**Access segment elements**\r\n```segment.elements```\r\n\r\n### 3. Optional: Analyze parsed loop.\r\nThis is an optional step to analyze the parsed document to see missing and unexpected loops/segments based on the schema.\r\n\r\n```py\r\nfrom x12.schema.schema import Schema, Usage\r\nfrom x12.parser.parse import parse\r\nfrom x12.parser.analyze import analyze\r\n\r\n# Real schema here\r\nschema = Schema(\"X12\")\r\n\r\nloop = parse(filepath_to_x12_file, schema)\r\n\r\nprint(analyze(loop))\r\n```\r\n\r\n**Example:**\r\n\r\n\r\n- Red indicates missing loops / segments.\r\n- Yellow indicates unexpected segments.\r\n\r\n\r\n---\r\n\r\n## Contributing\r\n\r\nSee [contributing.md](https://github.com/spaceavocado/x12/blob/master/contributing.md).\r\n\r\n## License\r\n\r\nSpace Avocado X12 Parser is released under the MIT license. See [LICENSE.md]([LICENSE.md](https://github.com/spaceavocado/x12/blob/master/LICENSE.md)).\r\n\r\n",
"bugtrack_url": null,
"license": "Copyright (c) 2023, David Horak (info@davidhorak.com) Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.",
"summary": "Simple X12 files parser.",
"version": "1.0.1",
"split_keywords": [
"x12",
"parser",
"schema"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "f347bf972266e2352b076574ca26cf055f012c58c6e7dc3dd334356ba9bfb121",
"md5": "a0e90b6fb4831fad652f3f8726e951d2",
"sha256": "d149419e3af40f0027b652b65772cf079b1e7d7e5468df3e91d77d2ac111d9f3"
},
"downloads": -1,
"filename": "spaceavocado_x12-1.0.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "a0e90b6fb4831fad652f3f8726e951d2",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.7",
"size": 11858,
"upload_time": "2023-03-16T03:21:14",
"upload_time_iso_8601": "2023-03-16T03:21:14.237003Z",
"url": "https://files.pythonhosted.org/packages/f3/47/bf972266e2352b076574ca26cf055f012c58c6e7dc3dd334356ba9bfb121/spaceavocado_x12-1.0.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "be8328e3c52124f1fa330cf1e73304ee27d47a1565a3cb1c5786088b0947f684",
"md5": "3aa13445545281dffd6855397ade3358",
"sha256": "82276e0c4517007535288ec8fc0d720e8377a3856d731dbff3d1d61adf96b42b"
},
"downloads": -1,
"filename": "spaceavocado-x12-1.0.1.tar.gz",
"has_sig": false,
"md5_digest": "3aa13445545281dffd6855397ade3358",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.7",
"size": 12532,
"upload_time": "2023-03-16T03:21:18",
"upload_time_iso_8601": "2023-03-16T03:21:18.269508Z",
"url": "https://files.pythonhosted.org/packages/be/83/28e3c52124f1fa330cf1e73304ee27d47a1565a3cb1c5786088b0947f684/spaceavocado-x12-1.0.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-03-16 03:21:18",
"github": false,
"gitlab": false,
"bitbucket": false,
"lcname": "spaceavocado-x12"
}
