# Streams Explorer
> Explore Apache Kafka data pipelines in Kubernetes.
> **Note**
> We are participating in the annual Hacktoberfest. If you're looking to contribute, please see our [open issues](https://github.com/bakdata/streams-explorer/issues?q=is%3Aissue+is%3Aopen+sort%3Aupdated-desc+label%3Ahacktoberfest) and use the [standalone installation](#standalone) for development.
## Contents
- [Streams Explorer](#streams-explorer)
- [Features](#features)
- [Overview](#overview)
- [Installation](#installation)
- [Docker Compose](#docker-compose)
- [Deploying to Kubernetes cluster](#deploying-to-kubernetes-cluster)
- [Standalone](#standalone)
- [Backend](#backend)
- [Frontend](#frontend)
- [Configuration](#configuration)
- [Kafka](#kafka)
- [Kafka Connect](#kafka-connect)
- [Kubernetes](#kubernetes)
- [Schema Registry / Karapace](#schema-registry--karapace)
- [Prometheus](#prometheus)
- [AKHQ](#akhq)
- [Redpanda Console](#redpanda-console)
- [Grafana](#grafana)
- [Kibana](#kibana)
- [Elasticsearch](#elasticsearch)
- [Plugins](#plugins)
- [Demo pipeline](#demo-pipeline)
- [Plugin customization](#plugin-customization)
## Features
- Visualization of streaming applications, topics, and connectors
- Monitor all or individual pipelines from multiple namespaces
- Inspection of Avro schema from schema registry
- Integration with [streams-bootstrap](https://github.com/bakdata/streams-bootstrap) and [faust-bootstrap](https://github.com/bakdata/faust-bootstrap), or custom streaming app config parsing from Kubernetes deployments using plugins
- Real-time metrics from Prometheus (consumer lag & read rate, replicas, topic size, messages in & out per second, connector tasks)
- Linking to external services for logging and analysis, such as Kibana, Grafana, Loki, AKHQ, Redpanda Console, and Elasticsearch
- Customizable through Python plugins
## Overview
Visit our introduction [blogpost](https://medium.com/bakdata/exploring-data-pipelines-in-apache-kafka-with-streams-explorer-8337dd11fdad) for a complete overview and demo of Streams Explorer.
## Installation
> **Prerequisites**
> Access to a Kubernetes cluster, where streaming apps and services are deployed.
### Docker Compose
1. Forward the ports to Prometheus. (Kafka Connect, Schema Registry, and other integrations are optional)
2. Start the container
```sh
docker compose up
```
Once the container is started visit <http://localhost:8080>
### Deploying to Kubernetes cluster
1. Add the Helm chart repository
```sh
helm repo add streams-explorer https://bakdata.github.io/streams-explorer
```
2. Install
```sh
helm upgrade --install --values helm-chart/values.yaml streams-explorer streams-explorer/streams-explorer
```
### Standalone
#### Backend
1. Install dependencies using [Poetry](https://python-poetry.org)
```sh
poetry install
```
2. Forward the ports to Prometheus. (Kafka Connect, Schema Registry, and other integrations are optional)
3. Configure the backend in [settings.yaml](backend/settings.yaml).
4. Start the backend server
```sh
poetry run start
```
#### Frontend
1. Install dependencies
```sh
npm ci
```
2. Start the frontend server
```sh
npm run build && npm run prod
```
Visit <http://localhost:3000>
## Configuration
Depending on your type of installation set the configuration for the backend server in this file:
- **Docker Compose**: [docker-compose.yaml](docker-compose.yaml)
- **Kubernetes**: [helm-chart/values.yaml](helm-chart/values.yaml)
- **standalone**: [backend/settings.yaml](backend/settings.yaml)
In the [helm-chart/values.yaml](helm-chart/values.yaml) configuration is done either through the `config` section using double underscore notation, e.g. `K8S__consumer_group_annotation: consumerGroup` or the content of [backend/settings.yaml](backend/settings.yaml) can be pasted under the `settings` section. Alternatively all configuration options can be written as environment variables using double underscore notation and the prefix `SE`, e.g. `SE_K8S__deployment__cluster=false`.
The following configuration options are available:
#### General
- `graph.update_interval` Render the graph every x seconds (int, **required**, default: `30`)
- `graph.layout_arguments` Arguments passed to graphviz layout (string, **required**, default: `-Grankdir=LR -Gnodesep=0.8 -Gpad=10`)
- `graph.pipeline_distance` Increase/decrease vertical space between pipeline graphs by X pixels (int, **required**, default: `500`)
- `graph.resolve.input_pattern_topics.all` If true topics that match (extra) input pattern(s) are connected to the streaming app in the graph containing all pipelines (bool, **required**, default: `false`)
- `graph.resolve.input_pattern_topics.pipelines` If true topics that match (extra) input pattern(s) are connected to the streaming app in pipeline graphs (bool, **required**, default: `false`)
#### Kafka
- `kafka.enable` Enable Kafka (bool, default: `false`)
- `kafka.config` librdkafka configuration properties ([reference](https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md)) (dict, default: `{"bootstrap.servers": "localhost:9092"}`)
- `kafka.displayed_information` Configuration options of Kafka topics displayed in the frontend (list of dict)
- `kafka.topic_names_cache.ttl` Cache for retrieving all topic names (used when input topic patterns are resolved) (int, default: `3600`)
#### Kafka Connect
- `kafkaconnect.url` URL of Kafka Connect server (string, default: None)
- `kafkaconnect.update_interval` Fetch connectors every x seconds (int, default: `300`)
- `kafkaconnect.displayed_information` Configuration options of Kafka connectors displayed in the frontend (list of dict)
#### Kubernetes
- `k8s.deployment.cluster` Whether streams-explorer is deployed to Kubernetes cluster (bool, **required**, default: `false`)
- `k8s.deployment.context` Name of cluster (string, optional if running in cluster, default: `kubernetes-cluster`)
- `k8s.deployment.namespaces` Kubernetes namespaces (list of string, **required**, default: `['kubernetes-namespace']`)
- `k8s.containers.ignore` Name of containers that should be ignored/hidden (list of string, default: `['prometheus-jmx-exporter']`)
- `k8s.displayed_information` Details of pod that should be displayed (list of dict, default: `[{'name': 'Labels', 'key': 'metadata.labels'}]`)
- `k8s.labels` Labels used to set attributes of nodes (list of string, **required**, default: `['pipeline']`)
- `k8s.pipeline.label` Attribute of nodes the pipeline name should be extracted from (string, **required**, default: `pipeline`)
- `k8s.consumer_group_annotation` Annotation the consumer group name should be extracted from (string, **required**, default: `consumerGroup`)
#### Schema Registry / Karapace
- `schemaregistry.url` URL of Confluent Schema Registry or Karapace (string, default: None)
#### Prometheus
- `prometheus.url` URL of Prometheus (string, **required**, default: `http://localhost:9090`)
The following exporters are required to collect Kafka metrics for Prometheus:
- [Kafka Exporter](https://github.com/danielqsj/kafka_exporter)
- [Kafka Lag Exporter](https://github.com/lightbend/kafka-lag-exporter)
- [Kafka Connect Exporter](https://github.com/wakeful/kafka_connect_exporter)
#### AKHQ
- `akhq.enable` Enable AKHQ (bool, default: `false`)
- `akhq.url` URL of AKHQ (string, default: `http://localhost:8080`)
- `akhq.cluster` Name of cluster (string, default: `kubernetes-cluster`)
- `akhq.connect` Name of connect (string, default: None)
#### Redpanda Console
Redpanda Console can be used instead of AKHQ. (mutually exclusive)
- `redpanda_console.enable` Enable Redpanda Console (bool, default: `false`)
- `redpanda_console.url` URL of Redpanda Console (string, default: `http://localhost:8080`)
#### Grafana
- `grafana.enable` Enable Grafana (bool, default: `false`)
- `grafana.url` URL of Grafana (string, default: `http://localhost:3000`)
- `grafana.dashboards.topics` Path to topics dashboard (string), sample dashboards for topics and consumer groups are included in the [`./grafana`](https://github.com/bakdata/streams-explorer/tree/main/grafana) subfolder
- `grafana.dashboards.consumergroups` Path to consumer groups dashboard (string)
#### Kibana
- `kibanalogs.enable` Enable Kibana logs (bool, default: `false`)
- `kibanalogs.url` URL of Kibana logs (string, default: `http://localhost:5601`)
#### Loki
Loki can be used instead of Kibana. (mutually exclusive)
- `loki.enable` Enable Loki logs (bool, default: `false`)
- `loki.url` URL of Loki logs (string, default: `http://localhost:3000`)
#### Elasticsearch
for Kafka Connect Elasticsearch connector
- `esindex.url` URL of Elasticsearch index (string, default: `http://localhost:5601/app/kibana#/dev_tools/console`)
#### Plugins
- `plugins.path` Path to folder containing plugins relative to backend (string, **required**, default: `./plugins`)
- `plugins.extractors.default` Whether to load default extractors (bool, **required**, default: `true`)
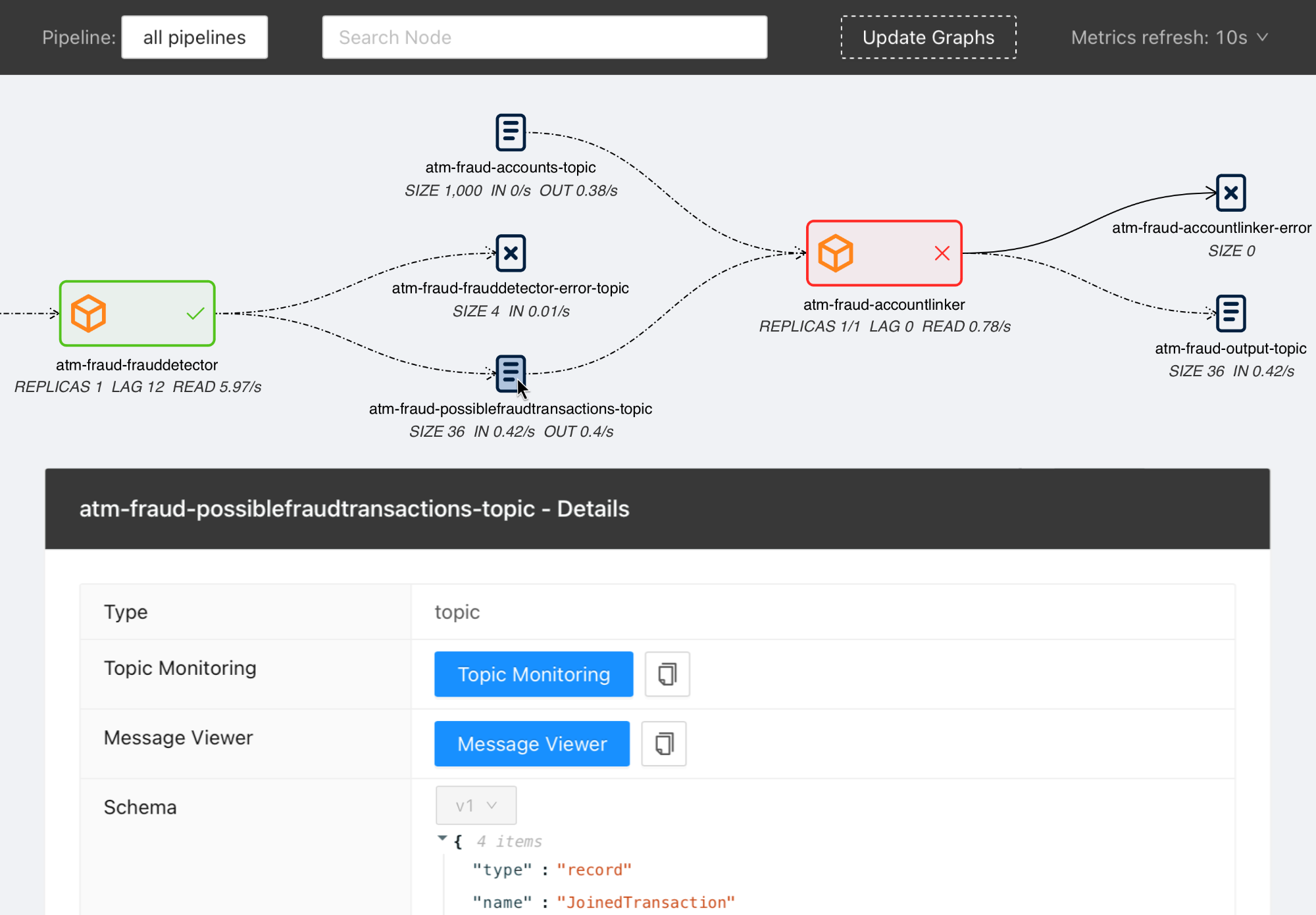
## Demo pipeline

[ATM Fraud detection with streams-bootstrap](https://github.com/bakdata/pipeline-atm-fraud)
## Plugin customization
It is possible to create your own config parser, linker, metric provider, and extractors in Python by implementing the `K8sConfigParser`, `LinkingService`, `MetricProvider`, or `Extractor` classes. This way you can customize it to your specific setup and services. As an example we provide the [`DefaultLinker`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/defaultlinker.py) as `LinkingService`. The default [`MetricProvider`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/services/metric_providers.py) supports Prometheus. Furthermore the following default `Extractor` plugins are included:
- [`ElasticsearchSink`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/extractor/default/elasticsearch_sink.py)
- [`JdbcSink`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/extractor/default/jdbc_sink.py)
- [`S3Sink`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/extractor/default/s3_sink.py)
- [`GenericSink`/`GenericSource`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/extractor/default/generic.py)
If your streaming application deployments are configured through environment variables, following the schema of [streams-bootstrap](https://github.com/bakdata/streams-bootstrap) or [faust-bootstrap](https://github.com/bakdata/faust-bootstrap), the Streams Explorer works out-of-the-box with the default deployment parser.
For streams-bootstrap deployments configured through CLI arguments a separate parser can be loaded by creating a Python file (e.g. `config_parser.py`) in the plugins folder with the following import statement:
```python
from streams_explorer.core.k8s_config_parser import StreamsBootstrapArgsParser
```
For other setups a custom config parser plugin can be created by inheriting from the [`K8sConfigParser`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/k8s_config_parser.py) class and implementing the `parse` method. In this example we're retrieving the streaming app configurations from an external REST API. In order for a deployment to be indentified as streaming app, input and output topics are required.
```python
import httpx
from streams_explorer.core.k8s_config_parser import K8sConfigParser
from streams_explorer.models.k8s import K8sConfig
class CustomConfigParser(K8sConfigParser):
def get_name(self) -> str:
name = self.k8s_app.metadata.name
if not name:
raise TypeError(f"Name is required for {self.k8s_app.class_name}")
return name
def parse(self) -> K8sConfig:
"""Retrieve app config from REST endpoint."""
name = self.get_name()
data = httpx.get(f"url/config/{name}").json()
return K8sConfig(**data)
```
Raw data
{
"_id": null,
"home_page": "https://github.com/bakdata/streams-explorer",
"name": "streams-explorer",
"maintainer": null,
"docs_url": null,
"requires_python": "<4.0,>=3.10",
"maintainer_email": null,
"keywords": "kafka, kubernetes, stream-processing, monitoring, pipelines",
"author": "bakdata",
"author_email": null,
"download_url": "https://files.pythonhosted.org/packages/6a/ac/d0c421f173460c802f075886fe71a7ab111463fdf15cc9fe2bc14ace566f/streams_explorer-2.4.0.tar.gz",
"platform": null,
"description": "# Streams Explorer\n\n> Explore Apache Kafka data pipelines in Kubernetes.\n\n\n\n> **Note**\n> We are participating in the annual Hacktoberfest. If you're looking to contribute, please see our [open issues](https://github.com/bakdata/streams-explorer/issues?q=is%3Aissue+is%3Aopen+sort%3Aupdated-desc+label%3Ahacktoberfest) and use the [standalone installation](#standalone) for development.\n\n## Contents\n\n- [Streams Explorer](#streams-explorer)\n - [Features](#features)\n - [Overview](#overview)\n - [Installation](#installation)\n - [Docker Compose](#docker-compose)\n - [Deploying to Kubernetes cluster](#deploying-to-kubernetes-cluster)\n - [Standalone](#standalone)\n - [Backend](#backend)\n - [Frontend](#frontend)\n - [Configuration](#configuration)\n - [Kafka](#kafka)\n - [Kafka Connect](#kafka-connect)\n - [Kubernetes](#kubernetes)\n - [Schema Registry / Karapace](#schema-registry--karapace)\n - [Prometheus](#prometheus)\n - [AKHQ](#akhq)\n - [Redpanda Console](#redpanda-console)\n - [Grafana](#grafana)\n - [Kibana](#kibana)\n - [Elasticsearch](#elasticsearch)\n - [Plugins](#plugins)\n - [Demo pipeline](#demo-pipeline)\n - [Plugin customization](#plugin-customization)\n\n## Features\n\n- Visualization of streaming applications, topics, and connectors\n- Monitor all or individual pipelines from multiple namespaces\n- Inspection of Avro schema from schema registry\n- Integration with [streams-bootstrap](https://github.com/bakdata/streams-bootstrap) and [faust-bootstrap](https://github.com/bakdata/faust-bootstrap), or custom streaming app config parsing from Kubernetes deployments using plugins\n- Real-time metrics from Prometheus (consumer lag & read rate, replicas, topic size, messages in & out per second, connector tasks)\n- Linking to external services for logging and analysis, such as Kibana, Grafana, Loki, AKHQ, Redpanda Console, and Elasticsearch\n- Customizable through Python plugins\n\n## Overview\n\nVisit our introduction [blogpost](https://medium.com/bakdata/exploring-data-pipelines-in-apache-kafka-with-streams-explorer-8337dd11fdad) for a complete overview and demo of Streams Explorer.\n\n## Installation\n\n> **Prerequisites**\n> Access to a Kubernetes cluster, where streaming apps and services are deployed.\n\n### Docker Compose\n\n1. Forward the ports to Prometheus. (Kafka Connect, Schema Registry, and other integrations are optional)\n2. Start the container\n\n```sh\ndocker compose up\n```\n\nOnce the container is started visit <http://localhost:8080>\n\n### Deploying to Kubernetes cluster\n\n1. Add the Helm chart repository\n\n```sh\nhelm repo add streams-explorer https://bakdata.github.io/streams-explorer\n```\n\n2. Install\n\n```sh\nhelm upgrade --install --values helm-chart/values.yaml streams-explorer streams-explorer/streams-explorer\n```\n\n### Standalone\n\n#### Backend\n\n1. Install dependencies using [Poetry](https://python-poetry.org)\n\n```sh\npoetry install\n```\n\n2. Forward the ports to Prometheus. (Kafka Connect, Schema Registry, and other integrations are optional)\n3. Configure the backend in [settings.yaml](backend/settings.yaml).\n4. Start the backend server\n\n```sh\npoetry run start\n```\n\n#### Frontend\n\n1. Install dependencies\n\n```sh\nnpm ci\n```\n\n2. Start the frontend server\n\n```sh\nnpm run build && npm run prod\n```\n\nVisit <http://localhost:3000>\n\n## Configuration\n\nDepending on your type of installation set the configuration for the backend server in this file:\n\n- **Docker Compose**: [docker-compose.yaml](docker-compose.yaml)\n- **Kubernetes**: [helm-chart/values.yaml](helm-chart/values.yaml)\n- **standalone**: [backend/settings.yaml](backend/settings.yaml)\n\nIn the [helm-chart/values.yaml](helm-chart/values.yaml) configuration is done either through the `config` section using double underscore notation, e.g. `K8S__consumer_group_annotation: consumerGroup` or the content of [backend/settings.yaml](backend/settings.yaml) can be pasted under the `settings` section. Alternatively all configuration options can be written as environment variables using double underscore notation and the prefix `SE`, e.g. `SE_K8S__deployment__cluster=false`.\n\nThe following configuration options are available:\n\n#### General\n\n- `graph.update_interval` Render the graph every x seconds (int, **required**, default: `30`)\n- `graph.layout_arguments` Arguments passed to graphviz layout (string, **required**, default: `-Grankdir=LR -Gnodesep=0.8 -Gpad=10`)\n- `graph.pipeline_distance` Increase/decrease vertical space between pipeline graphs by X pixels (int, **required**, default: `500`)\n- `graph.resolve.input_pattern_topics.all` If true topics that match (extra) input pattern(s) are connected to the streaming app in the graph containing all pipelines (bool, **required**, default: `false`)\n- `graph.resolve.input_pattern_topics.pipelines` If true topics that match (extra) input pattern(s) are connected to the streaming app in pipeline graphs (bool, **required**, default: `false`)\n\n#### Kafka\n\n- `kafka.enable` Enable Kafka (bool, default: `false`)\n- `kafka.config` librdkafka configuration properties ([reference](https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md)) (dict, default: `{\"bootstrap.servers\": \"localhost:9092\"}`)\n- `kafka.displayed_information` Configuration options of Kafka topics displayed in the frontend (list of dict)\n- `kafka.topic_names_cache.ttl` Cache for retrieving all topic names (used when input topic patterns are resolved) (int, default: `3600`)\n\n#### Kafka Connect\n\n- `kafkaconnect.url` URL of Kafka Connect server (string, default: None)\n- `kafkaconnect.update_interval` Fetch connectors every x seconds (int, default: `300`)\n- `kafkaconnect.displayed_information` Configuration options of Kafka connectors displayed in the frontend (list of dict)\n\n#### Kubernetes\n\n- `k8s.deployment.cluster` Whether streams-explorer is deployed to Kubernetes cluster (bool, **required**, default: `false`)\n- `k8s.deployment.context` Name of cluster (string, optional if running in cluster, default: `kubernetes-cluster`)\n- `k8s.deployment.namespaces` Kubernetes namespaces (list of string, **required**, default: `['kubernetes-namespace']`)\n- `k8s.containers.ignore` Name of containers that should be ignored/hidden (list of string, default: `['prometheus-jmx-exporter']`)\n- `k8s.displayed_information` Details of pod that should be displayed (list of dict, default: `[{'name': 'Labels', 'key': 'metadata.labels'}]`)\n- `k8s.labels` Labels used to set attributes of nodes (list of string, **required**, default: `['pipeline']`)\n- `k8s.pipeline.label` Attribute of nodes the pipeline name should be extracted from (string, **required**, default: `pipeline`)\n- `k8s.consumer_group_annotation` Annotation the consumer group name should be extracted from (string, **required**, default: `consumerGroup`)\n\n#### Schema Registry / Karapace\n\n- `schemaregistry.url` URL of Confluent Schema Registry or Karapace (string, default: None)\n\n#### Prometheus\n\n- `prometheus.url` URL of Prometheus (string, **required**, default: `http://localhost:9090`)\n\nThe following exporters are required to collect Kafka metrics for Prometheus:\n\n- [Kafka Exporter](https://github.com/danielqsj/kafka_exporter)\n- [Kafka Lag Exporter](https://github.com/lightbend/kafka-lag-exporter)\n- [Kafka Connect Exporter](https://github.com/wakeful/kafka_connect_exporter)\n\n#### AKHQ\n\n- `akhq.enable` Enable AKHQ (bool, default: `false`)\n- `akhq.url` URL of AKHQ (string, default: `http://localhost:8080`)\n- `akhq.cluster` Name of cluster (string, default: `kubernetes-cluster`)\n- `akhq.connect` Name of connect (string, default: None)\n\n#### Redpanda Console\n\nRedpanda Console can be used instead of AKHQ. (mutually exclusive)\n\n- `redpanda_console.enable` Enable Redpanda Console (bool, default: `false`)\n- `redpanda_console.url` URL of Redpanda Console (string, default: `http://localhost:8080`)\n\n#### Grafana\n\n- `grafana.enable` Enable Grafana (bool, default: `false`)\n- `grafana.url` URL of Grafana (string, default: `http://localhost:3000`)\n- `grafana.dashboards.topics` Path to topics dashboard (string), sample dashboards for topics and consumer groups are included in the [`./grafana`](https://github.com/bakdata/streams-explorer/tree/main/grafana) subfolder\n- `grafana.dashboards.consumergroups` Path to consumer groups dashboard (string)\n\n#### Kibana\n\n- `kibanalogs.enable` Enable Kibana logs (bool, default: `false`)\n- `kibanalogs.url` URL of Kibana logs (string, default: `http://localhost:5601`)\n\n#### Loki\n\nLoki can be used instead of Kibana. (mutually exclusive)\n\n- `loki.enable` Enable Loki logs (bool, default: `false`)\n- `loki.url` URL of Loki logs (string, default: `http://localhost:3000`)\n\n#### Elasticsearch\n\nfor Kafka Connect Elasticsearch connector\n\n- `esindex.url` URL of Elasticsearch index (string, default: `http://localhost:5601/app/kibana#/dev_tools/console`)\n\n#### Plugins\n\n- `plugins.path` Path to folder containing plugins relative to backend (string, **required**, default: `./plugins`)\n- `plugins.extractors.default` Whether to load default extractors (bool, **required**, default: `true`)\n\n## Demo pipeline\n\n\n\n[ATM Fraud detection with streams-bootstrap](https://github.com/bakdata/pipeline-atm-fraud)\n\n## Plugin customization\n\nIt is possible to create your own config parser, linker, metric provider, and extractors in Python by implementing the `K8sConfigParser`, `LinkingService`, `MetricProvider`, or `Extractor` classes. This way you can customize it to your specific setup and services. As an example we provide the [`DefaultLinker`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/defaultlinker.py) as `LinkingService`. The default [`MetricProvider`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/services/metric_providers.py) supports Prometheus. Furthermore the following default `Extractor` plugins are included:\n\n- [`ElasticsearchSink`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/extractor/default/elasticsearch_sink.py)\n- [`JdbcSink`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/extractor/default/jdbc_sink.py)\n- [`S3Sink`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/extractor/default/s3_sink.py)\n- [`GenericSink`/`GenericSource`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/extractor/default/generic.py)\n\nIf your streaming application deployments are configured through environment variables, following the schema of [streams-bootstrap](https://github.com/bakdata/streams-bootstrap) or [faust-bootstrap](https://github.com/bakdata/faust-bootstrap), the Streams Explorer works out-of-the-box with the default deployment parser.\nFor streams-bootstrap deployments configured through CLI arguments a separate parser can be loaded by creating a Python file (e.g. `config_parser.py`) in the plugins folder with the following import statement:\n\n```python\nfrom streams_explorer.core.k8s_config_parser import StreamsBootstrapArgsParser\n```\n\nFor other setups a custom config parser plugin can be created by inheriting from the [`K8sConfigParser`](https://github.com/bakdata/streams-explorer/blob/main/backend/streams_explorer/core/k8s_config_parser.py) class and implementing the `parse` method. In this example we're retrieving the streaming app configurations from an external REST API. In order for a deployment to be indentified as streaming app, input and output topics are required.\n\n```python\nimport httpx\n\nfrom streams_explorer.core.k8s_config_parser import K8sConfigParser\nfrom streams_explorer.models.k8s import K8sConfig\n\n\nclass CustomConfigParser(K8sConfigParser):\n def get_name(self) -> str:\n name = self.k8s_app.metadata.name\n if not name:\n raise TypeError(f\"Name is required for {self.k8s_app.class_name}\")\n return name\n\n def parse(self) -> K8sConfig:\n \"\"\"Retrieve app config from REST endpoint.\"\"\"\n name = self.get_name()\n data = httpx.get(f\"url/config/{name}\").json()\n return K8sConfig(**data)\n```\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "Explore Data Pipelines in Apache Kafka.",
"version": "2.4.0",
"project_urls": {
"Bug Tracker": "https://github.com/bakdata/streams-explorer/issues",
"Homepage": "https://github.com/bakdata/streams-explorer",
"Repository": "https://github.com/bakdata/streams-explorer"
},
"split_keywords": [
"kafka",
" kubernetes",
" stream-processing",
" monitoring",
" pipelines"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "204b441750fa33b489cb57cf6f437a356efe470ba7bc951d1560d0ba951309f3",
"md5": "37c1d21a156e2b1bbfefc7276a793228",
"sha256": "d15bd8675cc49ba2dc53da0e0cbf20b06c324a07fc77141c6ddbe552ae869246"
},
"downloads": -1,
"filename": "streams_explorer-2.4.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "37c1d21a156e2b1bbfefc7276a793228",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": "<4.0,>=3.10",
"size": 47125,
"upload_time": "2024-09-18T15:37:37",
"upload_time_iso_8601": "2024-09-18T15:37:37.039272Z",
"url": "https://files.pythonhosted.org/packages/20/4b/441750fa33b489cb57cf6f437a356efe470ba7bc951d1560d0ba951309f3/streams_explorer-2.4.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "6aacd0c421f173460c802f075886fe71a7ab111463fdf15cc9fe2bc14ace566f",
"md5": "7fdf5c7773fe6066e7dd1cf08ab60486",
"sha256": "34a8e0d116c8ebaee91040fc8cb35576e8ec02616139dbc9b0e664347a803f1c"
},
"downloads": -1,
"filename": "streams_explorer-2.4.0.tar.gz",
"has_sig": false,
"md5_digest": "7fdf5c7773fe6066e7dd1cf08ab60486",
"packagetype": "sdist",
"python_version": "source",
"requires_python": "<4.0,>=3.10",
"size": 34585,
"upload_time": "2024-09-18T15:37:38",
"upload_time_iso_8601": "2024-09-18T15:37:38.418911Z",
"url": "https://files.pythonhosted.org/packages/6a/ac/d0c421f173460c802f075886fe71a7ab111463fdf15cc9fe2bc14ace566f/streams_explorer-2.4.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-09-18 15:37:38",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "bakdata",
"github_project": "streams-explorer",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "streams-explorer"
}

