| Name | supertriplets JSON |
| Version |
1.0.6
 JSON
JSON |
| download |
| home_page | |
| Summary | Torch Multimodal Supervised Triplet Learning Toolbox |
| upload_time | 2023-09-25 21:12:47 |
| maintainer | |
| docs_url | None |
| author | |
| requires_python | >=3.8 |
| license | MIT License Copyright (c) 2023 Gabriel Tardochi Salles Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. |
| keywords |
data-science
contrastive-learning
triplet-learning
online-triplet-learning
natural-language-processing
computer-vision
artificial-intelligence
machine-learning
deep-learning
transformers
nlp
cv
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
<!--- BADGES: START --->




<!--- BADGES: END --->
# SuperTriplets
SuperTriplets is a toolbox for supervised online hard triplet learning, currently supporting different kinds of data: text, image, and even text + image (multimodal).
It doesn't try to automate the training and evaluation loop for you. Instead, it provides useful PyTorch-based utilities you can couple to your existing code, making the process as easy as performing other everyday supervised learning tasks, such as classification and regression.
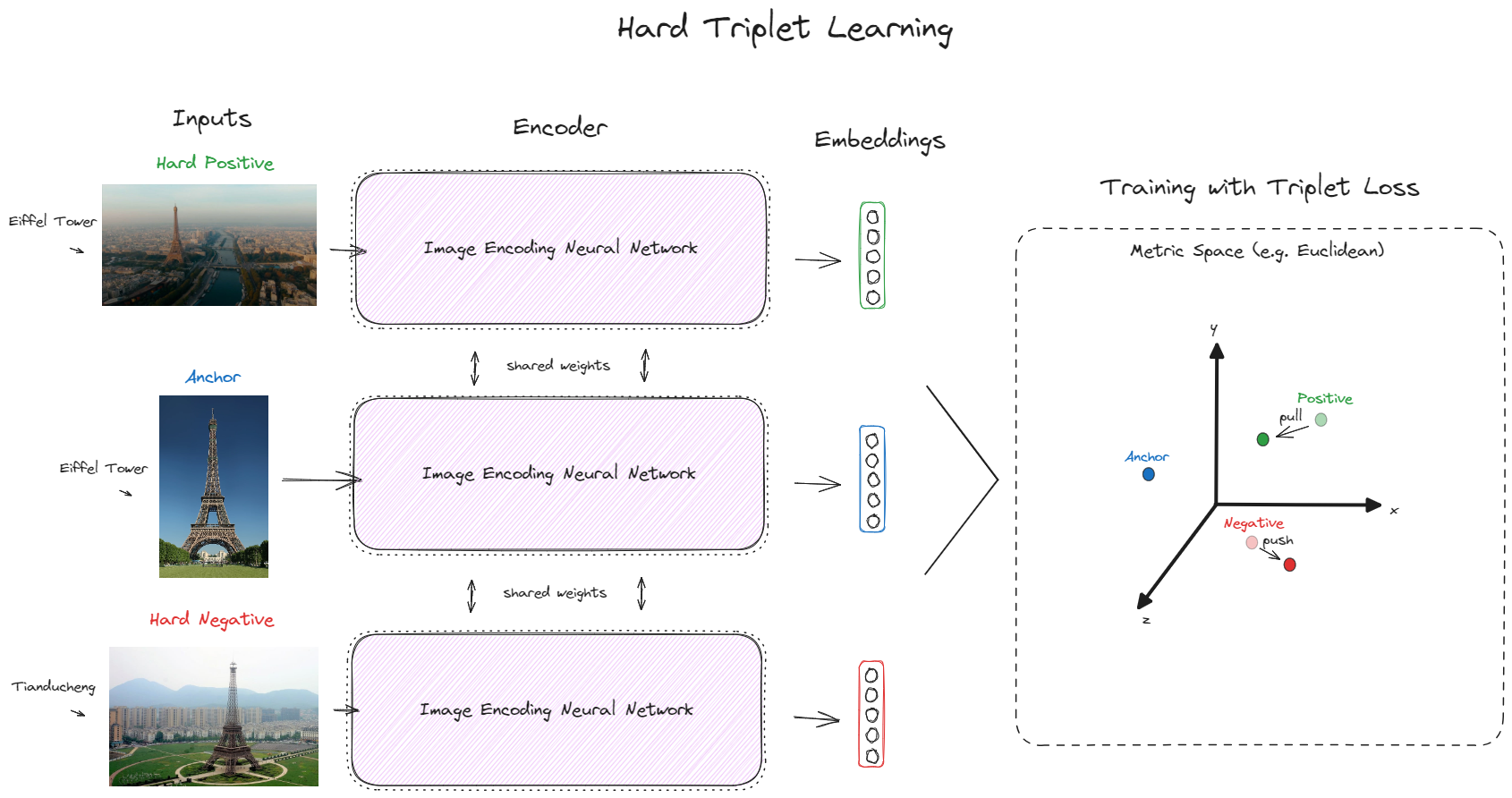
## Installation and Supported Versions
SuperTriplets is available on [PyPI](https://pypi.org/project/supertriplets/):
```console
$ pip install supertriplets
```
SuperTriplets officially supports Python 3.8+.
## Quick Start
### Training
Update your model weights with batch hard triplet losses over label balanced batches:
```python
import torch
from supertriplets.dataset import OnlineTripletsDataset
from supertriplets.distance import EuclideanDistance
from supertriplets.loss import BatchHardTripletLoss
from supertriplets.sample import TextImageSample
# ... omitted code to load the pandas.Dataframe `train_df`
device = 'cuda:0' if torch.cuda.is_available() else 'cpu' # always use cuda if available
# SuperTriplets provides very basic `sample` classes to store and manipulate datapoints
train_examples = [
TextImageSample(text=text, image_path=image_path, label=label)
for text, image_path, label in zip(train_df['text'], train_df['image_path'], train_df['label'])
]
def my_sample_loading_func(text, image_path, label, *args, **kwargs):
# ... implement your own preprocessing logic: e.g. tokenization, augmentations, tensor creation, etc
# this usually contains similar logic to what you would use inside a torch.utils.data.Dataset `__get_item__` method
# the only requirement is that it should at least have a few parameters named like its `sample` class attributes
loaded_sample = {"text_input": prep_text, "image_input": prep_image, "label": prep_label}
return loaded_sample
# subclass of torch.utils.data.IterableDataset
# it loops over examples to make sure each batch has the same number of
# samples per label and every sample is seen once per epoch
train_dataset = OnlineTripletsDataset(
examples=train_examples,
in_batch_num_samples_per_label=2, # labels with less than this will be discarded
batch_size=32, # multiple of `in_batch_num_samples_per_label`
sample_loading_func=my_sample_loading_func,
sample_loading_kwargs={} # you could add parameters to `my_sample_loading_func` and pass them here
)
# simple torch.utils.data.DataLoader, should match `batch_size` with `train_dataset`
train_dataloader = DataLoader(dataset=train_dataset, batch_size=32, num_workers=0, drop_last=True)
# SuperTriplets implement a variety of batch hard triplet losses and distances
criterion = BatchHardTripletLoss(distance=EuclideanDistance(squared=False), margin=5)
model = # init your torch model
optimizer = # init your torch optimizer
num_epochs = # define the number of training epochs
# basic training loop
for epoch in range(1, num_epochs + 1):
for batch in train_dataloader:
data = batch["samples"] # batch preprocessing result of `train_dataset.sample_loading_func`
labels = move_tensors_to_device(obj=data.pop("label"), device=device) # helper to move tensors within lists and dicts recursively between devices
inputs = move_tensors_to_device(obj=data, device=device)
optimizer.zero_grad()
embeddings = model(**inputs)
loss = criterion(embeddings=embeddings, labels=labels) # finds and uses the batch hardest triplets to update gradients
loss.backward()
optimizer.step()
```
### Evaluation
Mine hard triplets with pretrained models to construct your static testing dataset:
```python
import torch
from supertriplets.sample import TextImageSample
from supertriplets.encoder import PretrainedSampleEncoder
from supertriplets.evaluate import HardTripletsMiner
from supertriplets.dataset import StaticTripletsDataset
# ... omitted code to load the pandas.Dataframe `test_df`
device = 'cuda:0' if torch.cuda.is_available() else 'cpu' # always use cuda if available
# SuperTriplets provides very basic `sample` classes to store and manipulate datapoints
test_examples = [
TextImageSample(text=text, image_path=image_path, label=label)
for text, image_path, label in zip(test_df['text'], test_df['image_path'], test_df['label'])
]
# Leverage general purpose pretrained models per language and data format or bring your own `test_embeddings`
pretrained_encoder = PretrainedSampleEncoder(modality="text_english-image")
test_embeddings = pretrained_encoder.encode(examples=test_examples, device=device, batch_size=32)
# Index `test_examples` using `test_embeddings` and perform nearest neighbor search to sample hard positives and hard negatives
hard_triplet_miner = HardTripletsMiner(use_gpu_powered_index_if_available=True)
test_anchors, test_positives, test_negatives = hard_triplet_miner.mine(
examples=test_examples, embeddings=test_embeddings, normalize_l2=True, sample_from_topk_hardest=10
)
def my_sample_loading_func(text, image_path, label, *args, **kwargs):
# ... implement your own preprocessing logic: e.g. tokenization, augmentations, tensor creation, etc
# this usually contains similar logic to what you would use inside a torch.utils.data.Dataset `__get_item__` method
# the only requirement is that it should at least have a few parameters named like its `sample` class attributes
loaded_sample = {"text_input": prep_text, "image_input": prep_image, "label": prep_label}
return loaded_sample
# just another subclass of torch.utils.data.Dataset
test_dataset = StaticTripletsDataset(
anchor_examples=test_anchor_examples,
positive_examples=test_positive_examples,
negative_examples=test_negative_examples,
sample_loading_func=my_sample_loading_func,
sample_loading_kwargs={} # you could add parameters to `my_sample_loading_func` and pass them here
)
```
Easily create a good baseline with pretrained models and utilities to measure model accuracies on triplets using a diverse set of distance measurements:
```python
from torch.utils.data import DataLoader
from tqdm import tqdm
from supertriplets.evaluate import TripletEmbeddingsEvaluator
from supertriplets.models import load_pretrained_model
from supertriplets.utils import move_tensors_to_device
model = load_pretrained_model(model_name="CLIPViTB32EnglishEncoder") # see the list of pretrained models or bring your own model
model.to(device)
model.eval()
# very basic torch.utils.data.DataLoader to loop through the `test_dataset`
test_dataloader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False, num_workers=0, drop_last=False)
# bring your own logic to calculate embeddings
def get_triplet_embeddings(dataloader, model, device):
model.eval()
embeddings = {"anchors": [], "positives": [], "negatives": []}
with torch.no_grad():
for batch in tqdm(dataloader, total=len(dataloader)):
# a batch contains the preprocessing result for anchors, positives and negatives samples
for input_type in ["anchors", "positives", "negatives"]:
inputs = {k: v for k, v in batch[input_type].items() if k != "label"}
inputs = move_tensors_to_device(obj=inputs, device=device) # helper to move tensors within lists and dicts recursively between devices
batch_embeddings = model(**inputs).cpu()
embeddings[input_type].append(batch_embeddings)
embeddings = {k: torch.cat(v, dim=0).numpy() for k, v in embeddings.items()}
return embeddings
# evaluate any model encodings accuracy on existing triplets
# accuracy is the percentage of triplets where dist(a, p) < dist(a, n)
triplet_embeddings_evaluator = TripletEmbeddingsEvaluator(
calculate_by_cosine=True, calculate_by_manhattan=True, calculate_by_euclidean=True
)
test_triplet_embeddings = get_triplet_embeddings(dataloader=test_dataloader, model=model, device=device)
# `test_baseline_accuracies` is a dict of accuracies calculated using chosen distance measures
test_baseline_accuracies = triplet_embeddings_evaluator.evaluate(
embeddings_anchors=test_triplet_embeddings["anchors"],
embeddings_positives=test_triplet_embeddings["positives"],
embeddings_negatives=test_triplet_embeddings["negatives"],
)
# ... continue using `triplet_embeddings_evaluator` within your evaluation loops
```
## Local Development
Make sure you have python3, python3-venv and make installed.
Create a virtual environment with an editable installation of SuperTriplets and development specific dependencies by running:
```console
$ make install
```
Activate `.venv`:
```console
$ source .venv/bin/activate
```
Now you can make changes and test them with pytest.
Testing without a GPU:
```console
$ python -m pytest -k "not test_tinymmimdb_convergence"
```
With a GPU:
```console
$ python -m pytest
```
## Changelog
See [CHANGELOG.md](https://github.com/gabrieltardochi/supertriplets/blob/main/CHANGELOG.md) for news on all SuperTriplets versions.
## License
See [LICENSE](https://github.com/gabrieltardochi/supertriplets/blob/main/LICENSE.txt) for the current license.
Raw data
{
"_id": null,
"home_page": "",
"name": "supertriplets",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": "Gabriel Tardochi Salles <ga.tardochisalles@gmail.com>",
"keywords": "data-science,contrastive-learning,triplet-learning,online-triplet-learning,natural-language-processing,computer-vision,artificial-intelligence,machine-learning,deep-learning,transformers,nlp,cv",
"author": "",
"author_email": "Gabriel Tardochi Salles <ga.tardochisalles@gmail.com>",
"download_url": "https://files.pythonhosted.org/packages/4c/69/71637f6b979aeb6610a0f3756937281879ccf96621b0886b4cfe0287a68f/supertriplets-1.0.6.tar.gz",
"platform": null,
"description": "<!--- BADGES: START --->\n\n\n\n\n<!--- BADGES: END --->\n# SuperTriplets\nSuperTriplets is a toolbox for supervised online hard triplet learning, currently supporting different kinds of data: text, image, and even text + image (multimodal). \nIt doesn't try to automate the training and evaluation loop for you. Instead, it provides useful PyTorch-based utilities you can couple to your existing code, making the process as easy as performing other everyday supervised learning tasks, such as classification and regression. \n\n## Installation and Supported Versions\nSuperTriplets is available on [PyPI](https://pypi.org/project/supertriplets/):\n```console\n$ pip install supertriplets\n```\nSuperTriplets officially supports Python 3.8+.\n## Quick Start\n### Training\nUpdate your model weights with batch hard triplet losses over label balanced batches:\n```python\nimport torch\n\nfrom supertriplets.dataset import OnlineTripletsDataset\nfrom supertriplets.distance import EuclideanDistance\nfrom supertriplets.loss import BatchHardTripletLoss\nfrom supertriplets.sample import TextImageSample\n\n# ... omitted code to load the pandas.Dataframe `train_df`\n\ndevice = 'cuda:0' if torch.cuda.is_available() else 'cpu' # always use cuda if available\n\n# SuperTriplets provides very basic `sample` classes to store and manipulate datapoints\ntrain_examples = [\n TextImageSample(text=text, image_path=image_path, label=label)\n for text, image_path, label in zip(train_df['text'], train_df['image_path'], train_df['label'])\n]\n\ndef my_sample_loading_func(text, image_path, label, *args, **kwargs):\n # ... implement your own preprocessing logic: e.g. tokenization, augmentations, tensor creation, etc\n # this usually contains similar logic to what you would use inside a torch.utils.data.Dataset `__get_item__` method\n # the only requirement is that it should at least have a few parameters named like its `sample` class attributes\n loaded_sample = {\"text_input\": prep_text, \"image_input\": prep_image, \"label\": prep_label}\n return loaded_sample\n\n# subclass of torch.utils.data.IterableDataset\n# it loops over examples to make sure each batch has the same number of\n# samples per label and every sample is seen once per epoch\ntrain_dataset = OnlineTripletsDataset(\n examples=train_examples,\n in_batch_num_samples_per_label=2, # labels with less than this will be discarded\n batch_size=32, # multiple of `in_batch_num_samples_per_label`\n sample_loading_func=my_sample_loading_func,\n sample_loading_kwargs={} # you could add parameters to `my_sample_loading_func` and pass them here\n)\n\n# simple torch.utils.data.DataLoader, should match `batch_size` with `train_dataset`\ntrain_dataloader = DataLoader(dataset=train_dataset, batch_size=32, num_workers=0, drop_last=True)\n\n# SuperTriplets implement a variety of batch hard triplet losses and distances\ncriterion = BatchHardTripletLoss(distance=EuclideanDistance(squared=False), margin=5)\n\nmodel = # init your torch model\noptimizer = # init your torch optimizer\nnum_epochs = # define the number of training epochs\n\n# basic training loop\nfor epoch in range(1, num_epochs + 1):\n for batch in train_dataloader:\n data = batch[\"samples\"] # batch preprocessing result of `train_dataset.sample_loading_func`\n labels = move_tensors_to_device(obj=data.pop(\"label\"), device=device) # helper to move tensors within lists and dicts recursively between devices\n inputs = move_tensors_to_device(obj=data, device=device)\n\n optimizer.zero_grad()\n\n embeddings = model(**inputs)\n loss = criterion(embeddings=embeddings, labels=labels) # finds and uses the batch hardest triplets to update gradients\n\n loss.backward()\n optimizer.step()\n```\n### Evaluation\nMine hard triplets with pretrained models to construct your static testing dataset:\n```python\nimport torch\n\nfrom supertriplets.sample import TextImageSample\nfrom supertriplets.encoder import PretrainedSampleEncoder\nfrom supertriplets.evaluate import HardTripletsMiner\nfrom supertriplets.dataset import StaticTripletsDataset\n\n# ... omitted code to load the pandas.Dataframe `test_df`\n\ndevice = 'cuda:0' if torch.cuda.is_available() else 'cpu' # always use cuda if available\n\n# SuperTriplets provides very basic `sample` classes to store and manipulate datapoints\ntest_examples = [\n TextImageSample(text=text, image_path=image_path, label=label)\n for text, image_path, label in zip(test_df['text'], test_df['image_path'], test_df['label'])\n]\n\n# Leverage general purpose pretrained models per language and data format or bring your own `test_embeddings`\npretrained_encoder = PretrainedSampleEncoder(modality=\"text_english-image\")\ntest_embeddings = pretrained_encoder.encode(examples=test_examples, device=device, batch_size=32)\n\n# Index `test_examples` using `test_embeddings` and perform nearest neighbor search to sample hard positives and hard negatives\nhard_triplet_miner = HardTripletsMiner(use_gpu_powered_index_if_available=True)\ntest_anchors, test_positives, test_negatives = hard_triplet_miner.mine(\n examples=test_examples, embeddings=test_embeddings, normalize_l2=True, sample_from_topk_hardest=10\n)\n\ndef my_sample_loading_func(text, image_path, label, *args, **kwargs):\n # ... implement your own preprocessing logic: e.g. tokenization, augmentations, tensor creation, etc\n # this usually contains similar logic to what you would use inside a torch.utils.data.Dataset `__get_item__` method\n # the only requirement is that it should at least have a few parameters named like its `sample` class attributes\n loaded_sample = {\"text_input\": prep_text, \"image_input\": prep_image, \"label\": prep_label}\n return loaded_sample\n\n# just another subclass of torch.utils.data.Dataset\ntest_dataset = StaticTripletsDataset(\n anchor_examples=test_anchor_examples,\n positive_examples=test_positive_examples,\n negative_examples=test_negative_examples,\n sample_loading_func=my_sample_loading_func,\n sample_loading_kwargs={} # you could add parameters to `my_sample_loading_func` and pass them here\n)\n```\nEasily create a good baseline with pretrained models and utilities to measure model accuracies on triplets using a diverse set of distance measurements:\n```python\nfrom torch.utils.data import DataLoader\nfrom tqdm import tqdm\n\nfrom supertriplets.evaluate import TripletEmbeddingsEvaluator\nfrom supertriplets.models import load_pretrained_model\nfrom supertriplets.utils import move_tensors_to_device\n\n\nmodel = load_pretrained_model(model_name=\"CLIPViTB32EnglishEncoder\") # see the list of pretrained models or bring your own model\nmodel.to(device)\nmodel.eval()\n\n# very basic torch.utils.data.DataLoader to loop through the `test_dataset`\ntest_dataloader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False, num_workers=0, drop_last=False)\n\n# bring your own logic to calculate embeddings\ndef get_triplet_embeddings(dataloader, model, device):\n model.eval()\n embeddings = {\"anchors\": [], \"positives\": [], \"negatives\": []}\n with torch.no_grad():\n for batch in tqdm(dataloader, total=len(dataloader)):\n # a batch contains the preprocessing result for anchors, positives and negatives samples\n for input_type in [\"anchors\", \"positives\", \"negatives\"]:\n inputs = {k: v for k, v in batch[input_type].items() if k != \"label\"}\n inputs = move_tensors_to_device(obj=inputs, device=device) # helper to move tensors within lists and dicts recursively between devices\n batch_embeddings = model(**inputs).cpu()\n embeddings[input_type].append(batch_embeddings)\n embeddings = {k: torch.cat(v, dim=0).numpy() for k, v in embeddings.items()}\n return embeddings\n\n# evaluate any model encodings accuracy on existing triplets\n# accuracy is the percentage of triplets where dist(a, p) < dist(a, n)\ntriplet_embeddings_evaluator = TripletEmbeddingsEvaluator(\n calculate_by_cosine=True, calculate_by_manhattan=True, calculate_by_euclidean=True\n)\n\ntest_triplet_embeddings = get_triplet_embeddings(dataloader=test_dataloader, model=model, device=device)\n\n# `test_baseline_accuracies` is a dict of accuracies calculated using chosen distance measures\ntest_baseline_accuracies = triplet_embeddings_evaluator.evaluate(\n embeddings_anchors=test_triplet_embeddings[\"anchors\"],\n embeddings_positives=test_triplet_embeddings[\"positives\"],\n embeddings_negatives=test_triplet_embeddings[\"negatives\"],\n)\n# ... continue using `triplet_embeddings_evaluator` within your evaluation loops\n```\n## Local Development\nMake sure you have python3, python3-venv and make installed. \nCreate a virtual environment with an editable installation of SuperTriplets and development specific dependencies by running:\n```console\n$ make install\n```\nActivate `.venv`:\n```console\n$ source .venv/bin/activate\n```\nNow you can make changes and test them with pytest. \nTesting without a GPU:\n```console\n$ python -m pytest -k \"not test_tinymmimdb_convergence\"\n```\nWith a GPU:\n```console\n$ python -m pytest\n```\n## Changelog\nSee [CHANGELOG.md](https://github.com/gabrieltardochi/supertriplets/blob/main/CHANGELOG.md) for news on all SuperTriplets versions.\n## License\nSee [LICENSE](https://github.com/gabrieltardochi/supertriplets/blob/main/LICENSE.txt) for the current license.\n",
"bugtrack_url": null,
"license": "MIT License Copyright (c) 2023 Gabriel Tardochi Salles Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. ",
"summary": "Torch Multimodal Supervised Triplet Learning Toolbox",
"version": "1.0.6",
"project_urls": {
"Changelog": "https://github.com/gabrieltardochi/supertriplets/blob/main/CHANGELOG.md",
"Homepage": "https://github.com/gabrieltardochi/supertriplets",
"Repository": "https://github.com/gabrieltardochi/supertriplets"
},
"split_keywords": [
"data-science",
"contrastive-learning",
"triplet-learning",
"online-triplet-learning",
"natural-language-processing",
"computer-vision",
"artificial-intelligence",
"machine-learning",
"deep-learning",
"transformers",
"nlp",
"cv"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "9907ba3d7fd8dc729d1c70544a864a1800f1583ce8f099d7adc8e85f35b664d6",
"md5": "9425ac1c42d8300d63ab78f61e1e5961",
"sha256": "10a2f82eb1e1eb8c2dd99fea576af59f8c908275df72da1d8c6cecdeb9685145"
},
"downloads": -1,
"filename": "supertriplets-1.0.6-py3-none-any.whl",
"has_sig": false,
"md5_digest": "9425ac1c42d8300d63ab78f61e1e5961",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.8",
"size": 22123,
"upload_time": "2023-09-25T21:12:45",
"upload_time_iso_8601": "2023-09-25T21:12:45.230775Z",
"url": "https://files.pythonhosted.org/packages/99/07/ba3d7fd8dc729d1c70544a864a1800f1583ce8f099d7adc8e85f35b664d6/supertriplets-1.0.6-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "4c6971637f6b979aeb6610a0f3756937281879ccf96621b0886b4cfe0287a68f",
"md5": "544417c323f8a4acded6153b8489452d",
"sha256": "f75cf993c20667fbc81880ae260e5e1e528723727d457b3612d88c4532a7cf4a"
},
"downloads": -1,
"filename": "supertriplets-1.0.6.tar.gz",
"has_sig": false,
"md5_digest": "544417c323f8a4acded6153b8489452d",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 21570,
"upload_time": "2023-09-25T21:12:47",
"upload_time_iso_8601": "2023-09-25T21:12:47.751685Z",
"url": "https://files.pythonhosted.org/packages/4c/69/71637f6b979aeb6610a0f3756937281879ccf96621b0886b4cfe0287a68f/supertriplets-1.0.6.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-09-25 21:12:47",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "gabrieltardochi",
"github_project": "supertriplets",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "supertriplets"
}
