# syntax-parser-prototype
<a href="https://pypi.org/project/syntax-parser-prototype/" target="_blank" style="position: absolute;top: 22px; right: 62px;color: #db54d9; z-index:100;">
<img src="https://pypi.org/static/images/logo-small.8998e9d1.svg" alt="pypi.org/wsqlite3" style="height: 24px;">
</a>
**spp** provides a generic schema implementation for syntax parsers whose
structure and behavior can be defined flexibly and complexly using derived objects.
**spp** also provides some advanced interfaces and parameterizations to meet complex syntax definition requirements.
```commandline
pip install syntax-parser-prototype --upgrade
pip install syntax-parser-prototype[debug] --upgrade
```
## Quick Start
The main entry points for the phrase configuration are the methods `Phrase.starts` and `Phrase.ends`.
Their return value tells the parser whether a phrase starts and, if so, where and in what context.
The structural logic of a syntax is realized by assigning phrases objects to other phrases objects as
under phrases.
<details>
<summary>
demos/quickstart/main.py (<a href="https://github.com/srccircumflex/syntax-parser-prototype/blob/master/demos/quickstart/main.py">source</a>)
</summary>
```python
# Represents a simplified method for parsing python syntax.
# The following paragraph is to be parsed:
# foo = 42
# baz = not f'{foo + 42 is foo} \' bar'
import keyword
import re
from src.syntax_parser_prototype import *
from src.syntax_parser_prototype.features.tokenize import *
# simple string definition
class StringPhrase(Phrase):
id = "string"
# token typing
class NodeToken(NodeToken):
id = "string-start-quotes"
class Token(Token):
id = "string-content"
TDefaultToken = Token
class EndToken(EndToken):
id = "string-end-quotes"
# backslash escape handling
class MaskPhrase(Phrase):
id = "mask"
def starts(self, stream: Stream):
if m := re.search("\\\\.", stream.unparsed):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ prevents closure
return MaskToken(m.start(), m.end())
# could also be implemented as a stand-alone token or
# independent phrase if the pattern is to be tokenized separately
else:
return None
PH_MASK = MaskPhrase()
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# creates the logic during initialization
self.add_subs(self.PH_MASK)
def starts(self, stream: Stream):
# searches for quotation marks and possible prefix and saves the quotation mark type
# switches to a different phase configuration if the f-string pattern is found
if m := re.search("(f?)(['\"])", stream.unparsed, re.IGNORECASE):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
if prefix := m.group(1):
switchto = PH_FSTRING
else:
switchto = self
return self.NodeToken(m.start(), m.end(), SwitchTo(switchto), quotes=m.group(2))
else:
return None
def ends(self, stream: Stream):
# searches for the saved quotation mark type
if m := re.search(stream.node.extras.quotes, stream.unparsed):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
return self.EndToken(m.start(), m.end())
else:
return None
# modified string definition for f-string pattern
class FstringPhrase(StringPhrase):
id = "fstring"
# format content handling
class FstringFormatContentPhrase(Phrase):
id = "fstring-format-content"
# token typing
class NodeToken(NodeToken):
id = "fstring-format-content-open"
class EndToken(EndToken):
id = "fstring-format-content-close"
def starts(self, stream: Stream):
if m := re.search("\\{", stream.unparsed):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
return self.NodeToken(m.start(), m.end())
else:
return None
def ends(self, stream: Stream):
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
if m := re.search("}", stream.unparsed):
return self.EndToken(m.start(), m.end())
else:
return None
PH_FSTRING_FORMAT_CONTENT = FstringFormatContentPhrase()
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# creates the logic during initialization
self.add_subs(self.PH_FSTRING_FORMAT_CONTENT)
NUMBER42 = list()
# simple word definition
class WordPhrase(Phrase):
id = "word"
# token typing
class KeywordToken(Token):
id = "keyword"
class VariableToken(Token):
id = "variable"
class NumberToken(Token):
id = "number"
class WordNode(NodeToken):
id = "word"
def atConfirmed(self) -> None:
assert not self.inner
def atFeaturized(self) -> None:
# collect 42 during the parsing process
if self.inner[0].content == "42":
NUMBER42.append(self[0])
def starts(self, stream: Stream):
if m := re.search("\\w+", stream.unparsed):
# foo = 42
# ↑ ↑
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ ↑ ↑ ↑ ↑ ↑
return self.WordNode(
m.start(),
m.end(),
# forwards the content to tokenize
RTokenize(len(m.group()))
)
# could also be implemented as a stand-alone token,
# but this way saves conditional queries if the token is not prioritized
else:
return None
def tokenize(self, stream: TokenizeStream):
token = stream.eat_remain()
if token in keyword.kwlist:
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ ↑
return self.KeywordToken
elif re.match("^\\d+$", token):
# foo = 42
# ↑
# baz = not f'{foo + 42 is foo} \' bar'
# ↑
return self.NumberToken
else:
# foo = 42
# ↑
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ ↑ ↑
return self.VariableToken
def ends(self, stream: Stream):
# end the phrase immediately without content after the start process
# foo = 42
# ↑ ↑
# baz = not f'{foo + 42 is foo} \' bar'
# ↑ ↑ ↑ ↑ ↑ ↑
return super().ends(stream) # return InstantEndToken()
MAIN = Root()
PH_STRING = StringPhrase()
PH_FSTRING = FstringPhrase()
PH_WORD = WordPhrase()
# MAIN SETUP
# - configure the logic at the top level
MAIN.add_subs(PH_STRING, PH_WORD)
# - recursive reference to the logic of the top level
PH_FSTRING.PH_FSTRING_FORMAT_CONTENT.add_subs(MAIN.__sub_phrases__)
if __name__ == "__main__":
from demos.quickstart import template
with open(template.__file__) as f:
# foo = 42
# baz = not f'{foo + 42 is foo} \' bar'
#
content = f.read()
# parse the content
result = MAIN.parse_string(content)
if PROCESS_RESULT := True:
# some result processing
assert content == result.tokenReader.branch.content
token = result.tokenIndex.get_token_at_coord(1, 19)
assert token.content == "42"
assert token.column_end == 21
assert token.data_end == 30
assert token.node.phrase.id == "word"
assert token.next.next.next.next.content == "is"
assert token.node.node[0].tokenReader.inner.content == "foo"
assert isinstance(result, NodeToken)
for inner_token in result:
if isinstance(inner_token, NodeToken):
assert isinstance(inner_token.inner, list)
assert isinstance(inner_token.end, EndToken)
else:
assert not hasattr(inner_token, "inner")
assert isinstance(result.end, EndToken) and isinstance(result.end, EOF)
assert len(NUMBER42) == 2
if DEBUG := True:
# visualisation
print(*(f"std. repr: {t} {t!r}" for t in NUMBER42), sep="\n")
from src.syntax_parser_prototype import debug
print(*(f"debug repr: {t} {t!r}" for t in NUMBER42), sep="\n")
debug.html_server.token_css[WordPhrase.KeywordToken] = "font-weight: bold;"
debug.html_server.token_css[WordPhrase.NumberToken] = "color: blue; border-bottom: 1px dotted blue;"
debug.html_server.token_css[StringPhrase.NodeToken] = "color: green;"
debug.html_server.token_css[StringPhrase.Token] = "color: green;"
debug.html_server.token_css[StringPhrase.EndToken] = "color: green;"
debug.html_server.token_css[FstringPhrase.FstringFormatContentPhrase.NodeToken] = "color: orange;"
debug.html_server.token_css[FstringPhrase.FstringFormatContentPhrase.EndToken] = "color: orange;"
debug.html_server(result)
```
</details>
## Concept
### General
#### Configuration Overview
The basic parser behavior is defined by
1. the structure definition in the form of assignments of phrases to phrases as sub- or suffix phrases
and assignments of root subphrases to `Root`;
2. the return values of `Phrase.starts()` and `Phrase.ends()`.
##### Advanced Features
1. `Phrase.tokenize()` (hook)
2. `[...]Token.atConfirmed()` (hook)
3. `[...]Token.atFeaturized()` (hook)
4. `[...]Token(..., features: LStrip | RTokenize | SwitchTo | SwitchPh | ForwardTo)` (advanced behavior control)
#### Parser Behavior
The entries for starting the parsing process are `Root.parse_rows()` and `Root.parse_string()`,
which return a `RootNode` object as the result.
The parser processes entered data _row_[^1] by row:
> The more detailed definition of a _row_ can be left to the user (`Root.parse_rows()`).
> The line break characters are **NOT** automatically interpreted at the end of a row
> and must therefore be included in the transferred data.
>
> In `Root.parse_string()`, lines are defined by line break characters by default.
##### Phrases Start and End Values
Within a process iteration, ``starts()`` of sub-phrases and the ``ends()`` of the currently active phrase are queried
for the unparsed part of the current _row_[^1] (defined from viewpoint (a cursor) to the end of the _row_[^1]).
The methods must return a token object that matches the context as a positive value (otherwise ``None``).
- Valid node tokens from `Phrase.starts()` are:
- `NodeToken`
- `MaskNodeToken`
- `InstantNodeToken`
- Valid _standalone_[^2] tokens from `Phrase.starts()` are:
- `Token`
- `InstandToken`
- `MaskToken`
> _Standalone tokens_ are token types that do not trigger a phrase change and are assigned directly to the parent phrase.
- Valid end tokens from `Phrase.ends()` are:
- `EndToken`
- `InstandEndToken`
##### Token Priority
The order in which phrases are assigned as sub-phrases is irrelevant;
the internal order in which the methods of several sub-phrases are queried is random
and in most cases is executed across the board for all potential sub-phrases.
Therefore - and to differentiate from `EndToken`'s - positive return values (`tokens`) must be
differentiated to find the one that should actually be processed next.
The project talks about token _priority_[^3]:
1. `InstandToken`'s have the highest priority. These would
1. as `InstandEndToken` from `Phrase.ends()` prevent the search for starts
and close the phrase immediately at the defined point.
2. as `InstandNodeToken` or `InstandToken` as a _standalone_[^2] Token from `Phrase.starts()`,
immediately interrupt the search for further starts and process this token directly.
2. Tokens with the smallest `at` parameter (the start position relative to the viewpoint of the stream)
have the second-highest priority.
3. The third-highest priority is given to so-called _null tokens_[^4].
> _Null tokens_ are tokens for which no
content is defined. _null tokens_ that are returned for the position directly at the viewpoint (`at=0`)
are only permitted as `EndTokens`, as otherwise the parser might get stuck in an infinite loop.
An exception to this is the extended feature configuration with `ForwardTo`,
where only one of the tokens has to advance the stream.
4. Finally, the Token with the longest content has the highest priority.
##### Value Domains and Tokenization
The domain of values within a phrase defined by `starts()` and `ends()` is referred to as a branch and can be nested
by sub- or suffix phrases. The domain at phrase level is then separated by the `NodeToken`'s of these phrases.
By default, the parser parses this domain _row_[^1] by _row_[^1] as single tokens. The `Phrase.tokenize()` hook is
available for selective token typing.
Therefore, before processing a Node, End or _standalone_[^2] Token or at the end of a _row_[^1],
the remaining content is automatically assigned to the (still) active node/phrase.
### Token Types
#### Control Tokens
Control tokens are returned as positive values of the configured phrase methods
for controlling the parser and — except the `Mask[Node]Token`'s — are present in the result.
In general, all tokens must be configured with the definition of `at <int>` and `to <int>`.
These values tell the parser in which area of the currently unparsed _row_[^1] part the content for
the token is located.
Except the `Mask[Node]Token`'s, all control tokens can be equipped with extended
features that can significantly influence the parsing process.
In addition, free keyword parameters can be transferred to `[...]NodeToken`'s,
which are assigned to the `extras` attribute in the node.
##### class Token
(_standard type_) Simple text content token and base type for all other tokens.
Tokens of this type must be returned by ``Phrase.tokenize``
or can represent a _standalone_[^2] token via ``Phrase.starts``.
These are stored as a value in the `inner` attribute of the parent node.
##### class NodeToken(Token)
(_standard type_) Represents the beginning of a phrase as a token and
contains subordinate tokens and the end token.
`Phrase.starts()` must return tokens of this type when a complex phrase starts.
These are stored as a value in the `inner` attribute of the parent node.
##### class EndToken(Token)
(_standard type_) Represents the end of a phrase.
`Phrase.ends()` must return tokens of this type when a complex phrase ends.
These are stored as a value as the `end` attribute of the parent node.
##### class MaskToken(Token)
(_special type_) Special _standalone_[^2] token type that can be returned by `Phrase.starts()`.
Instead of the start of this phrase, the content is then assigned to the parent node.
This token type will never be present in the result.
**Note**: If `Phrase.start()` returns a `MaskToken`, sub-/suffix-phrases of this Phrase are **NOT** evaluated.
##### class MaskNodeToken(MaskToken, NodeToken)
(_special type_) Special node token type that can be returned by `Phrase.starts()`.
Starts a masking phrase whose content is assigned to the parent node.
This token type will never be present in the result.
**Note**: If `Phrase.start()` returns a `MaskToken`, sub-/suffix-phrases of this Phrase are **NOT** evaluated.
##### class InstantToken(Token)
(_special type_) Special _standalone_[^2] token type that can be returned by `Phrase.starts()`.
Prevents comparison of _priority_[^3] with other tokens and accepts the token directly.
##### class InstantEndToken(InstantToken, EndToken)
(_special type_) Special end token type that can be returned by `Phrase.ends()`.
Prevents comparison of _priority_[^3] with other tokens and accepts the token directly.
##### class InstantNodeToken(InstantToken, NodeToken)
(_special type_) Special node token type that can be returned by `Phrase.starts()`.
Prevents comparison of _priority_[^3] with other tokens and accepts the token directly.
#### Internal Token Types
Internal token types are automatically assigned during the process.
##### class OpenEndToken(Token)
Represents the non-end of a phrase.
This type is set to `NodeToken.end` by default until an `EndToken` replaces it
or remains in the result if none was found until the end.
Acts as an interface to the last seen token of the phrase for duck typing.
##### class RootNode(NodeToken)
Represents the root of the parsed input and contains all other tokens
(has no content but is a valid token to represent the result root).
##### class OToken(Token)
Represents an inner token for the root phrase when no user-defined phrase is active.
##### class OEOF(OpenEndToken)
Represents the non-end of the parsed input, set to `RootNode.end`.
This type is set by default until the `EOF` replaces it at the end of the process
(will never be included in the result).
##### class EOF(EndToken)
Represents the end of the parsed input, set to `RootNode.end`
(has no content but is a valid token to be included in the result).
## Visualization Tools
The debug module ([source](https://github.com/srccircumflex/syntax-parser-prototype/blob/master/src/syntax_parser_prototype/debug.py)) provides some support for visualization.
All necessary packages can be installed separately:
```commandline
pip install syntax-parser-prototype[debug] --upgrade
```
### Overview
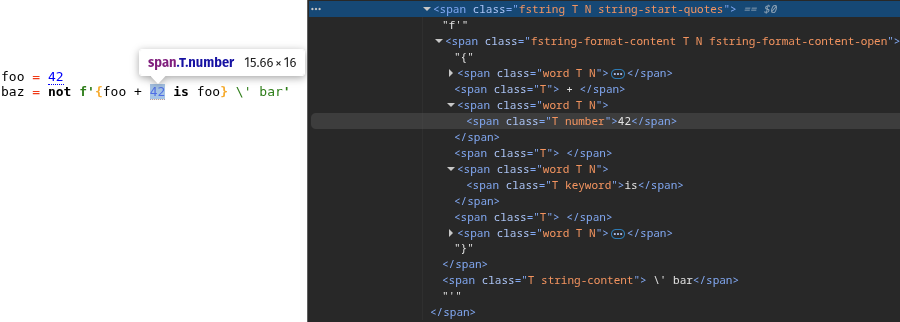
#### HTML Server
```python
from src.syntax_parser_prototype import debug
debug.html_server(result)
```
#### Structure Graph App
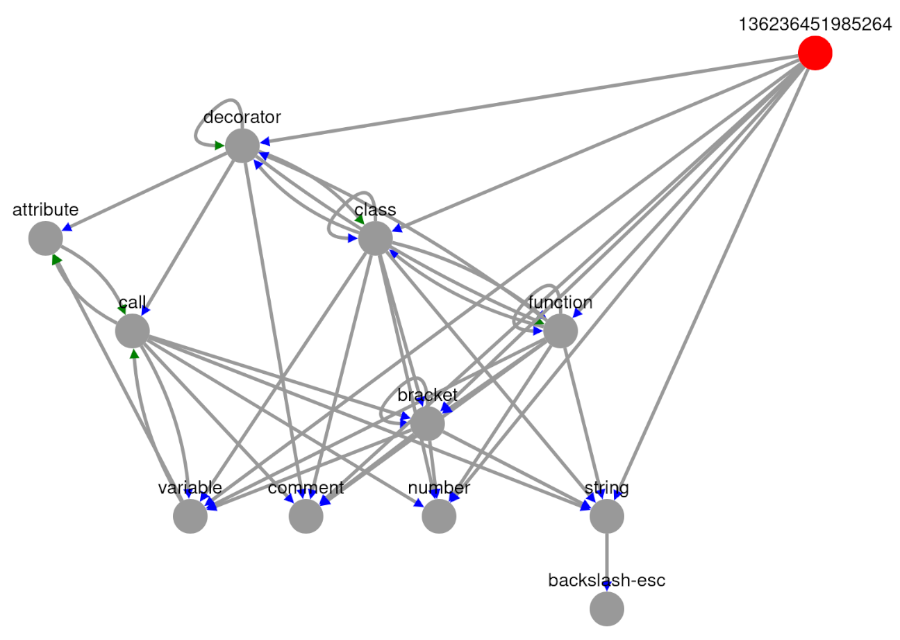
```python
from src.syntax_parser_prototype import debug
debug.structure_graph_app(MAIN)
```
#### Pretty XML
```python
from src.syntax_parser_prototype import debug
print(debug.pretty_xml(result))
```
```xml
<?xml version="1.0" ?>
<R phrase="130192620364736" coord="0 0:0">
<word phrase="word" coord="0 0:0">
<variable coord="0 0:3">foo</variable>
<iE coord="0 3:3"/>
</word>
<o coord="0 3:6"> = </o>
<word phrase="word" coord="0 6:6">
<number coord="0 6:8">42</number>
<iE coord="0 8:8"/>
</word>
<o coord="0 8:9">
</o>
<word phrase="word" coord="1 0:0">
<variable coord="1 0:3">baz</variable>
<iE coord="1 3:3"/>
</word>
<o coord="1 3:6"> = </o>
<word phrase="word" coord="1 6:6">
<keyword coord="1 6:9">not</keyword>
<iE coord="1 9:9"/>
</word>
<o coord="1 9:10"> </o>
<string-start-quotes phrase="fstring" coord="1 10:12">
f'
<fstring-format-content-open phrase="fstring-format-content" coord="1 12:13">
{
<word phrase="word" coord="1 13:13">
<variable coord="1 13:16">foo</variable>
<iE coord="1 16:16"/>
</word>
<T coord="1 16:19"> + </T>
<word phrase="word" coord="1 19:19">
<number coord="1 19:21">42</number>
<iE coord="1 21:21"/>
</word>
<T coord="1 21:22"> </T>
<word phrase="word" coord="1 22:22">
<keyword coord="1 22:24">is</keyword>
<iE coord="1 24:24"/>
</word>
<T coord="1 24:25"> </T>
<word phrase="word" coord="1 25:25">
<variable coord="1 25:28">foo</variable>
<iE coord="1 28:28"/>
</word>
<fstring-format-content-close coord="1 28:29">}</fstring-format-content-close>
</fstring-format-content-open>
<string-content coord="1 32:39"> \' bar</string-content>
<string-end-quotes coord="1 36:37">'</string-end-quotes>
</string-start-quotes>
<o coord="1 37:38">
</o>
<EOF coord="1 38:38"/>
</R>
```
## Change Log
### 3.0 — major release
- added `node` shortcut in `TokenizeStream`
- added less restrictive type hints in `Phrase` and `Root` generics
- added support for `Phrase` and `Node` type hints for `Stream`'s and `Token`'s
via `Generic[TV_PHRASE, TV_NODE_TOKEN]` to ensure stronger type binding between
phrase implementations and token/node types
(Application example in a `Phrase.starts` method definition:
```python
def starts(self, stream: streams.Stream[MyPhrase, MyNode1 | MyNode2]):
stream.node.my_attribute
stream.node.phrase.my_attribute
...
```
- fixed `OpenEndToken` interface
- added/fixed unpacking in `Phrase.add_suffixes()`
### 3.0a3 — fix type hint
- 3.0a3 fixes a type hint error in `Phrase.tokenize()`
### 3.0a2 — security update
- 3.0a2 closes a gap in the protection against infinite loops
> With the configuration of the extended feature `ForwardTo` to an `EndToken`,
the parser would not have recognized if it did not advance.
### 3.0a1 — initial pre-release
- Version 3 differs fundamentally from its predecessors
[^1]: A row is not necessarily a line as it is generally understood.
[^2]: Standalone tokens are token types that do not trigger a phrase change and are assigned directly to the parent phrase.
[^3]: `InstandEndToken` < `InstandNodeToken` < `InstandToken` < smallest `at` < _Null tokens_ < longest `content`
[^4]: Null tokens are tokens for which no content is defined.
Null tokens that are returned for the position directly at the viewpoint (`at=0`) are only permitted as `EndTokens`.
Raw data
{
"_id": null,
"home_page": null,
"name": "syntax-parser-prototype",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.10",
"maintainer_email": null,
"keywords": "syntax, parser, prototype, compiler, framework",
"author": null,
"author_email": "\"Adrian F. Hoefflin\" <srccircumflex@outlook.com>",
"download_url": "https://files.pythonhosted.org/packages/5e/15/2d5b0bd7dc53568afc08c1ddb674d4b23162f054124d56c305382d58c97f/syntax_parser_prototype-3.0.tar.gz",
"platform": null,
"description": "# syntax-parser-prototype\n\n<a href=\"https://pypi.org/project/syntax-parser-prototype/\" target=\"_blank\" style=\"position: absolute;top: 22px; right: 62px;color: #db54d9; z-index:100;\">\n<img src=\"https://pypi.org/static/images/logo-small.8998e9d1.svg\" alt=\"pypi.org/wsqlite3\" style=\"height: 24px;\">\n</a>\n\n**spp** provides a generic schema implementation for syntax parsers whose \nstructure and behavior can be defined flexibly and complexly using derived objects.\n\n**spp** also provides some advanced interfaces and parameterizations to meet complex syntax definition requirements.\n\n```commandline\npip install syntax-parser-prototype --upgrade\npip install syntax-parser-prototype[debug] --upgrade\n```\n\n\n## Quick Start\n\nThe main entry points for the phrase configuration are the methods `Phrase.starts` and `Phrase.ends`.\nTheir return value tells the parser whether a phrase starts and, if so, where and in what context.\n\nThe structural logic of a syntax is realized by assigning phrases objects to other phrases objects as \nunder phrases.\n\n<details>\n <summary>\n demos/quickstart/main.py (<a href=\"https://github.com/srccircumflex/syntax-parser-prototype/blob/master/demos/quickstart/main.py\">source</a>)\n </summary>\n\n```python\n# Represents a simplified method for parsing python syntax.\n# The following paragraph is to be parsed:\n# foo = 42\n# baz = not f'{foo + 42 is foo} \\' bar'\n\nimport keyword\nimport re\n\nfrom src.syntax_parser_prototype import *\nfrom src.syntax_parser_prototype.features.tokenize import *\n\n\n# simple string definition\nclass StringPhrase(Phrase):\n id = \"string\"\n\n # token typing\n class NodeToken(NodeToken):\n id = \"string-start-quotes\"\n\n class Token(Token):\n id = \"string-content\"\n\n TDefaultToken = Token\n\n class EndToken(EndToken):\n id = \"string-end-quotes\"\n\n # backslash escape handling\n class MaskPhrase(Phrase):\n id = \"mask\"\n\n def starts(self, stream: Stream):\n if m := re.search(\"\\\\\\\\.\", stream.unparsed):\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191 prevents closure\n return MaskToken(m.start(), m.end())\n # could also be implemented as a stand-alone token or \n # independent phrase if the pattern is to be tokenized separately\n else:\n return None\n\n PH_MASK = MaskPhrase()\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n # creates the logic during initialization\n self.add_subs(self.PH_MASK)\n\n def starts(self, stream: Stream):\n # searches for quotation marks and possible prefix and saves the quotation mark type\n # switches to a different phase configuration if the f-string pattern is found\n if m := re.search(\"(f?)(['\\\"])\", stream.unparsed, re.IGNORECASE):\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191\n if prefix := m.group(1):\n switchto = PH_FSTRING\n else:\n switchto = self\n return self.NodeToken(m.start(), m.end(), SwitchTo(switchto), quotes=m.group(2))\n else:\n return None\n\n def ends(self, stream: Stream):\n # searches for the saved quotation mark type\n if m := re.search(stream.node.extras.quotes, stream.unparsed):\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191\n return self.EndToken(m.start(), m.end())\n else:\n return None\n\n\n# modified string definition for f-string pattern\nclass FstringPhrase(StringPhrase):\n id = \"fstring\"\n\n # format content handling\n class FstringFormatContentPhrase(Phrase):\n id = \"fstring-format-content\"\n\n # token typing\n class NodeToken(NodeToken):\n id = \"fstring-format-content-open\"\n\n class EndToken(EndToken):\n id = \"fstring-format-content-close\"\n\n def starts(self, stream: Stream):\n if m := re.search(\"\\\\{\", stream.unparsed):\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191\n return self.NodeToken(m.start(), m.end())\n else:\n return None\n\n def ends(self, stream: Stream):\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191\n if m := re.search(\"}\", stream.unparsed):\n return self.EndToken(m.start(), m.end())\n else:\n return None\n\n PH_FSTRING_FORMAT_CONTENT = FstringFormatContentPhrase()\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n # creates the logic during initialization\n self.add_subs(self.PH_FSTRING_FORMAT_CONTENT)\n\n\nNUMBER42 = list()\n\n\n# simple word definition\nclass WordPhrase(Phrase):\n id = \"word\"\n\n # token typing\n class KeywordToken(Token):\n id = \"keyword\"\n\n class VariableToken(Token):\n id = \"variable\"\n\n class NumberToken(Token):\n id = \"number\"\n\n class WordNode(NodeToken):\n id = \"word\"\n\n def atConfirmed(self) -> None:\n assert not self.inner\n\n def atFeaturized(self) -> None:\n # collect 42 during the parsing process\n if self.inner[0].content == \"42\":\n NUMBER42.append(self[0])\n\n def starts(self, stream: Stream):\n if m := re.search(\"\\\\w+\", stream.unparsed):\n # foo = 42\n # \u2191 \u2191\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191 \u2191 \u2191 \u2191 \u2191 \u2191\n return self.WordNode(\n m.start(),\n m.end(),\n # forwards the content to tokenize\n RTokenize(len(m.group()))\n )\n # could also be implemented as a stand-alone token, \n # but this way saves conditional queries if the token is not prioritized\n else:\n return None\n\n def tokenize(self, stream: TokenizeStream):\n token = stream.eat_remain()\n if token in keyword.kwlist:\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191 \u2191\n return self.KeywordToken\n elif re.match(\"^\\\\d+$\", token):\n # foo = 42\n # \u2191\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191\n return self.NumberToken\n else:\n # foo = 42\n # \u2191\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191 \u2191 \u2191\n return self.VariableToken\n\n def ends(self, stream: Stream):\n # end the phrase immediately without content after the start process\n # foo = 42\n # \u2191 \u2191\n # baz = not f'{foo + 42 is foo} \\' bar'\n # \u2191 \u2191 \u2191 \u2191 \u2191 \u2191\n return super().ends(stream) # return InstantEndToken()\n\n\nMAIN = Root()\nPH_STRING = StringPhrase()\nPH_FSTRING = FstringPhrase()\nPH_WORD = WordPhrase()\n\n# MAIN SETUP\n# - configure the logic at the top level\nMAIN.add_subs(PH_STRING, PH_WORD)\n# - recursive reference to the logic of the top level\nPH_FSTRING.PH_FSTRING_FORMAT_CONTENT.add_subs(MAIN.__sub_phrases__)\n\nif __name__ == \"__main__\":\n from demos.quickstart import template\n\n with open(template.__file__) as f:\n # foo = 42\n # baz = not f'{foo + 42 is foo} \\' bar'\n #\n content = f.read()\n\n # parse the content\n result = MAIN.parse_string(content)\n\n if PROCESS_RESULT := True:\n # some result processing\n assert content == result.tokenReader.branch.content\n token = result.tokenIndex.get_token_at_coord(1, 19)\n assert token.content == \"42\"\n assert token.column_end == 21\n assert token.data_end == 30\n assert token.node.phrase.id == \"word\"\n assert token.next.next.next.next.content == \"is\"\n assert token.node.node[0].tokenReader.inner.content == \"foo\"\n\n assert isinstance(result, NodeToken)\n for inner_token in result:\n if isinstance(inner_token, NodeToken):\n assert isinstance(inner_token.inner, list)\n assert isinstance(inner_token.end, EndToken)\n else:\n assert not hasattr(inner_token, \"inner\")\n assert isinstance(result.end, EndToken) and isinstance(result.end, EOF)\n\n assert len(NUMBER42) == 2\n\n if DEBUG := True:\n # visualisation\n print(*(f\"std. repr: {t} {t!r}\" for t in NUMBER42), sep=\"\\n\")\n\n from src.syntax_parser_prototype import debug\n\n print(*(f\"debug repr: {t} {t!r}\" for t in NUMBER42), sep=\"\\n\")\n\n debug.html_server.token_css[WordPhrase.KeywordToken] = \"font-weight: bold;\"\n debug.html_server.token_css[WordPhrase.NumberToken] = \"color: blue; border-bottom: 1px dotted blue;\"\n debug.html_server.token_css[StringPhrase.NodeToken] = \"color: green;\"\n debug.html_server.token_css[StringPhrase.Token] = \"color: green;\"\n debug.html_server.token_css[StringPhrase.EndToken] = \"color: green;\"\n debug.html_server.token_css[FstringPhrase.FstringFormatContentPhrase.NodeToken] = \"color: orange;\"\n debug.html_server.token_css[FstringPhrase.FstringFormatContentPhrase.EndToken] = \"color: orange;\"\n\n debug.html_server(result)\n```\n\n</details>\n\n\n## Concept\n\n### General\n\n#### Configuration Overview\n\nThe basic parser behavior is defined by\n1. the structure definition in the form of assignments of phrases to phrases as sub- or suffix phrases \nand assignments of root subphrases to `Root`;\n2. the return values of `Phrase.starts()` and `Phrase.ends()`.\n\n\n##### Advanced Features\n\n1. `Phrase.tokenize()` (hook)\n2. `[...]Token.atConfirmed()` (hook)\n3. `[...]Token.atFeaturized()` (hook)\n4. `[...]Token(..., features: LStrip | RTokenize | SwitchTo | SwitchPh | ForwardTo)` (advanced behavior control)\n\n\n#### Parser Behavior\n\nThe entries for starting the parsing process are `Root.parse_rows()` and `Root.parse_string()`,\nwhich return a `RootNode` object as the result.\n\nThe parser processes entered data _row_[^1] by row:\n> The more detailed definition of a _row_ can be left to the user (`Root.parse_rows()`). \n> The line break characters are **NOT** automatically interpreted at the end of a row \n> and must therefore be included in the transferred data.\n>\n> In `Root.parse_string()`, lines are defined by line break characters by default.\n\n\n##### Phrases Start and End Values\n\nWithin a process iteration, ``starts()`` of sub-phrases and the ``ends()`` of the currently active phrase are queried \nfor the unparsed part of the current _row_[^1] (defined from viewpoint (a cursor) to the end of the _row_[^1]). \nThe methods must return a token object that matches the context as a positive value (otherwise ``None``).\n\n- Valid node tokens from `Phrase.starts()` are:\n - `NodeToken`\n - `MaskNodeToken`\n - `InstantNodeToken`\n- Valid _standalone_[^2] tokens from `Phrase.starts()` are:\n - `Token`\n - `InstandToken`\n - `MaskToken`\n > _Standalone tokens_ are token types that do not trigger a phrase change and are assigned directly to the parent phrase.\n- Valid end tokens from `Phrase.ends()` are:\n - `EndToken`\n - `InstandEndToken`\n\n\n##### Token Priority\n\nThe order in which phrases are assigned as sub-phrases is irrelevant; \nthe internal order in which the methods of several sub-phrases are queried is random \nand in most cases is executed across the board for all potential sub-phrases. \nTherefore - and to differentiate from `EndToken`'s - positive return values (`tokens`) must be \ndifferentiated to find the one that should actually be processed next. \n\nThe project talks about token _priority_[^3]:\n\n1. `InstandToken`'s have the highest priority. These would \n 1. as `InstandEndToken` from `Phrase.ends()` prevent the search for starts \n and close the phrase immediately at the defined point.\n 2. as `InstandNodeToken` or `InstandToken` as a _standalone_[^2] Token from `Phrase.starts()`,\n immediately interrupt the search for further starts and process this token directly.\n2. Tokens with the smallest `at` parameter (the start position relative to the viewpoint of the stream)\nhave the second-highest priority.\n3. The third-highest priority is given to so-called _null tokens_[^4]. \n > _Null tokens_ are tokens for which no \ncontent is defined. _null tokens_ that are returned for the position directly at the viewpoint (`at=0`) \nare only permitted as `EndTokens`, as otherwise the parser might get stuck in an infinite loop.\nAn exception to this is the extended feature configuration with `ForwardTo`, \nwhere only one of the tokens has to advance the stream.\n4. Finally, the Token with the longest content has the highest priority.\n\n\n##### Value Domains and Tokenization\n\nThe domain of values within a phrase defined by `starts()` and `ends()` is referred to as a branch and can be nested \nby sub- or suffix phrases. The domain at phrase level is then separated by the `NodeToken`'s of these phrases.\nBy default, the parser parses this domain _row_[^1] by _row_[^1] as single tokens. The `Phrase.tokenize()` hook is \navailable for selective token typing.\nTherefore, before processing a Node, End or _standalone_[^2] Token or at the end of a _row_[^1], \nthe remaining content is automatically assigned to the (still) active node/phrase.\n\n\n\n### Token Types\n\n#### Control Tokens\n\nControl tokens are returned as positive values of the configured phrase methods \nfor controlling the parser and \u2014 except the `Mask[Node]Token`'s \u2014 are present in the result.\nIn general, all tokens must be configured with the definition of `at <int>` and `to <int>`. \nThese values tell the parser in which area of the currently unparsed _row_[^1] part the content for \nthe token is located.\n\nExcept the `Mask[Node]Token`'s, all control tokens can be equipped with extended \nfeatures that can significantly influence the parsing process.\n\nIn addition, free keyword parameters can be transferred to `[...]NodeToken`'s, \nwhich are assigned to the `extras` attribute in the node.\n\n##### class Token\n(_standard type_) Simple text content token and base type for all other tokens.\n\nTokens of this type must be returned by ``Phrase.tokenize``\nor can represent a _standalone_[^2] token via ``Phrase.starts``.\nThese are stored as a value in the `inner` attribute of the parent node.\n\n\n##### class NodeToken(Token)\n(_standard type_) Represents the beginning of a phrase as a token and\ncontains subordinate tokens and the end token.\n\n`Phrase.starts()` must return tokens of this type when a complex phrase starts.\nThese are stored as a value in the `inner` attribute of the parent node.\n\n\n##### class EndToken(Token)\n(_standard type_) Represents the end of a phrase.\n\n`Phrase.ends()` must return tokens of this type when a complex phrase ends.\nThese are stored as a value as the `end` attribute of the parent node.\n\n\n##### class MaskToken(Token)\n(_special type_) Special _standalone_[^2] token type that can be returned by `Phrase.starts()`.\n\nInstead of the start of this phrase, the content is then assigned to the parent node.\nThis token type will never be present in the result.\n\n**Note**: If `Phrase.start()` returns a `MaskToken`, sub-/suffix-phrases of this Phrase are **NOT** evaluated.\n\n\n##### class MaskNodeToken(MaskToken, NodeToken)\n(_special type_) Special node token type that can be returned by `Phrase.starts()`.\n\nStarts a masking phrase whose content is assigned to the parent node.\nThis token type will never be present in the result.\n\n**Note**: If `Phrase.start()` returns a `MaskToken`, sub-/suffix-phrases of this Phrase are **NOT** evaluated.\n\n\n##### class InstantToken(Token)\n(_special type_) Special _standalone_[^2] token type that can be returned by `Phrase.starts()`.\n\nPrevents comparison of _priority_[^3] with other tokens and accepts the token directly.\n\n\n##### class InstantEndToken(InstantToken, EndToken)\n(_special type_) Special end token type that can be returned by `Phrase.ends()`.\n\nPrevents comparison of _priority_[^3] with other tokens and accepts the token directly.\n\n\n##### class InstantNodeToken(InstantToken, NodeToken)\n(_special type_) Special node token type that can be returned by `Phrase.starts()`.\n\nPrevents comparison of _priority_[^3] with other tokens and accepts the token directly.\n\n\n\n#### Internal Token Types\n\nInternal token types are automatically assigned during the process.\n\n##### class OpenEndToken(Token)\nRepresents the non-end of a phrase.\n\nThis type is set to `NodeToken.end` by default until an `EndToken` replaces it\nor remains in the result if none was found until the end.\nActs as an interface to the last seen token of the phrase for duck typing.\n\n##### class RootNode(NodeToken)\nRepresents the root of the parsed input and contains all other tokens\n(has no content but is a valid token to represent the result root).\n\n##### class OToken(Token)\nRepresents an inner token for the root phrase when no user-defined phrase is active.\n\n##### class OEOF(OpenEndToken)\nRepresents the non-end of the parsed input, set to `RootNode.end`.\n\nThis type is set by default until the `EOF` replaces it at the end of the process\n(will never be included in the result).\n\n##### class EOF(EndToken)\nRepresents the end of the parsed input, set to `RootNode.end`\n(has no content but is a valid token to be included in the result).\n\n\n## Visualization Tools\n\nThe debug module ([source](https://github.com/srccircumflex/syntax-parser-prototype/blob/master/src/syntax_parser_prototype/debug.py)) provides some support for visualization. \nAll necessary packages can be installed separately:\n\n```commandline\npip install syntax-parser-prototype[debug] --upgrade\n```\n\n### Overview\n\n\n#### HTML Server\n\n```python\nfrom src.syntax_parser_prototype import debug\ndebug.html_server(result)\n```\n\n\n\n\n#### Structure Graph App\n\n```python\nfrom src.syntax_parser_prototype import debug\ndebug.structure_graph_app(MAIN)\n```\n\n\n\n#### Pretty XML\n\n```python\nfrom src.syntax_parser_prototype import debug\nprint(debug.pretty_xml(result))\n```\n\n```xml\n<?xml version=\"1.0\" ?>\n<R phrase=\"130192620364736\" coord=\"0 0:0\">\n\t<word phrase=\"word\" coord=\"0 0:0\">\n\t\t<variable coord=\"0 0:3\">foo</variable>\n\t\t<iE coord=\"0 3:3\"/>\n\t</word>\n\t<o coord=\"0 3:6\"> = </o>\n\t<word phrase=\"word\" coord=\"0 6:6\">\n\t\t<number coord=\"0 6:8\">42</number>\n\t\t<iE coord=\"0 8:8\"/>\n\t</word>\n\t<o coord=\"0 8:9\">\n</o>\n\t<word phrase=\"word\" coord=\"1 0:0\">\n\t\t<variable coord=\"1 0:3\">baz</variable>\n\t\t<iE coord=\"1 3:3\"/>\n\t</word>\n\t<o coord=\"1 3:6\"> = </o>\n\t<word phrase=\"word\" coord=\"1 6:6\">\n\t\t<keyword coord=\"1 6:9\">not</keyword>\n\t\t<iE coord=\"1 9:9\"/>\n\t</word>\n\t<o coord=\"1 9:10\"> </o>\n\t<string-start-quotes phrase=\"fstring\" coord=\"1 10:12\">\n\t\tf'\n\t\t<fstring-format-content-open phrase=\"fstring-format-content\" coord=\"1 12:13\">\n\t\t\t{\n\t\t\t<word phrase=\"word\" coord=\"1 13:13\">\n\t\t\t\t<variable coord=\"1 13:16\">foo</variable>\n\t\t\t\t<iE coord=\"1 16:16\"/>\n\t\t\t</word>\n\t\t\t<T coord=\"1 16:19\"> + </T>\n\t\t\t<word phrase=\"word\" coord=\"1 19:19\">\n\t\t\t\t<number coord=\"1 19:21\">42</number>\n\t\t\t\t<iE coord=\"1 21:21\"/>\n\t\t\t</word>\n\t\t\t<T coord=\"1 21:22\"> </T>\n\t\t\t<word phrase=\"word\" coord=\"1 22:22\">\n\t\t\t\t<keyword coord=\"1 22:24\">is</keyword>\n\t\t\t\t<iE coord=\"1 24:24\"/>\n\t\t\t</word>\n\t\t\t<T coord=\"1 24:25\"> </T>\n\t\t\t<word phrase=\"word\" coord=\"1 25:25\">\n\t\t\t\t<variable coord=\"1 25:28\">foo</variable>\n\t\t\t\t<iE coord=\"1 28:28\"/>\n\t\t\t</word>\n\t\t\t<fstring-format-content-close coord=\"1 28:29\">}</fstring-format-content-close>\n\t\t</fstring-format-content-open>\n\t\t<string-content coord=\"1 32:39\"> \\' bar</string-content>\n\t\t<string-end-quotes coord=\"1 36:37\">'</string-end-quotes>\n\t</string-start-quotes>\n\t<o coord=\"1 37:38\">\n</o>\n\t<EOF coord=\"1 38:38\"/>\n</R>\n```\n\n\n## Change Log\n\n### 3.0 \u2014 major release\n- added `node` shortcut in `TokenizeStream`\n- added less restrictive type hints in `Phrase` and `Root` generics\n- added support for `Phrase` and `Node` type hints for `Stream`'s and `Token`'s\nvia `Generic[TV_PHRASE, TV_NODE_TOKEN]` to ensure stronger type binding between \nphrase implementations and token/node types\n\n (Application example in a `Phrase.starts` method definition:\n ```python\n def starts(self, stream: streams.Stream[MyPhrase, MyNode1 | MyNode2]):\n stream.node.my_attribute\n stream.node.phrase.my_attribute\n ...\n ```\n\n- fixed `OpenEndToken` interface\n- added/fixed unpacking in `Phrase.add_suffixes()`\n\n\n### 3.0a3 \u2014 fix type hint\n- 3.0a3 fixes a type hint error in `Phrase.tokenize()`\n\n### 3.0a2 \u2014 security update\n- 3.0a2 closes a gap in the protection against infinite loops \n> With the configuration of the extended feature `ForwardTo` to an `EndToken`, \nthe parser would not have recognized if it did not advance.\n\n### 3.0a1 \u2014 initial pre-release\n- Version 3 differs fundamentally from its predecessors\n\n\n\n[^1]: A row is not necessarily a line as it is generally understood.\n[^2]: Standalone tokens are token types that do not trigger a phrase change and are assigned directly to the parent phrase.\n[^3]: `InstandEndToken` < `InstandNodeToken` < `InstandToken` < smallest `at` < _Null tokens_ < longest `content`\n[^4]: Null tokens are tokens for which no content is defined. \nNull tokens that are returned for the position directly at the viewpoint (`at=0`) are only permitted as `EndTokens`.\n",
"bugtrack_url": null,
"license": "MIT License",
"summary": "prototype of a sytaxparser",
"version": "3.0",
"project_urls": {
"Homepage": "https://github.com/srccircumflex/syntax-parser-prototype"
},
"split_keywords": [
"syntax",
" parser",
" prototype",
" compiler",
" framework"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "e212a99c2b3806f468c0924ebfea9413aef7b18673fe0dd7bede17c1b58ba9ba",
"md5": "e98e78f22206732b57d20defe71d8078",
"sha256": "49088a704d5d242ddf13176df67a137d57bd37579461981746814635129d91dd"
},
"downloads": -1,
"filename": "syntax_parser_prototype-3.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "e98e78f22206732b57d20defe71d8078",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.10",
"size": 33802,
"upload_time": "2025-10-11T15:01:16",
"upload_time_iso_8601": "2025-10-11T15:01:16.473796Z",
"url": "https://files.pythonhosted.org/packages/e2/12/a99c2b3806f468c0924ebfea9413aef7b18673fe0dd7bede17c1b58ba9ba/syntax_parser_prototype-3.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "5e152d5b0bd7dc53568afc08c1ddb674d4b23162f054124d56c305382d58c97f",
"md5": "d837b45952e6a7110ff1d02f30a6f520",
"sha256": "484b91a97a1923c3aa67d4f644f14509488b74ff8c279a46fd29a2d4a3fb194d"
},
"downloads": -1,
"filename": "syntax_parser_prototype-3.0.tar.gz",
"has_sig": false,
"md5_digest": "d837b45952e6a7110ff1d02f30a6f520",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.10",
"size": 35970,
"upload_time": "2025-10-11T15:01:18",
"upload_time_iso_8601": "2025-10-11T15:01:18.316198Z",
"url": "https://files.pythonhosted.org/packages/5e/15/2d5b0bd7dc53568afc08c1ddb674d4b23162f054124d56c305382d58c97f/syntax_parser_prototype-3.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-10-11 15:01:18",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "srccircumflex",
"github_project": "syntax-parser-prototype",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "syntax-parser-prototype"
}

