| Name | torch-optimi JSON |
| Version |
0.3.1
 JSON
JSON |
| download |
| home_page | None |
| Summary | Fast, Modern, & Low Precision PyTorch Optimizers |
| upload_time | 2025-07-25 21:18:41 |
| maintainer | None |
| docs_url | None |
| author | Benjamin Warner |
| requires_python | >=3.10 |
| license | MIT License Copyright (c) 2023 Benjamin Warner Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. |
| keywords |
optimizers
pytorch
deep learning
ai
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# optimī
### Fast, Modern, and Low Precision PyTorch Optimizers
[](https://pypi.org/project/torch-optimi/)
[](https://pypi.org/project/torch-optimi/)
[](https://pepy.tech/projects/torch-optimi)
[](https://optimi.benjaminwarner.dev)
optimi enables accurate low precision training via Kahan summation, integrates gradient release and optimizer accumulation for additional memory efficiency, supports fully decoupled weight decay, and features fast implementations of modern optimizers.
## Low Precision Training with Kahan Summation
optimi optimizers can match the performance of mixed precision when [training in pure BFloat16 by using Kahan summation](https://optimi.benjaminwarner.dev/kahan_summation).
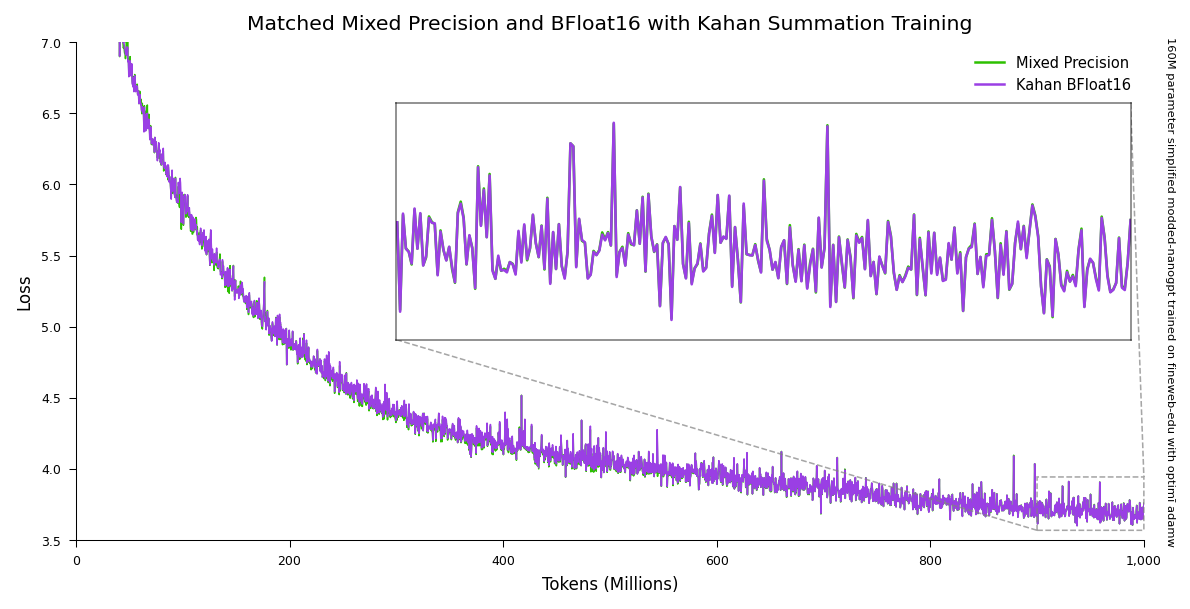
Training in BFloat16 with Kahan summation can reduce non-activation training memory usage by [37 to 45 percent](https://optimi.benjaminwarner.dev/kahan_summation/#memory-savings) when using an Adam optimizer. BFloat16 training can increase single GPU [training speed up to 10 percent](https://optimi.benjaminwarner.dev/kahan_summation/#training-speedup) at the same batch size.
## Fast Triton Implementations
optimi's fused [Triton optimizers](https://optimi.benjaminwarner.dev/triton) are faster than PyTorch's fused Cuda optimizers, and nearly as fast as compiled optimizers without any hassle.
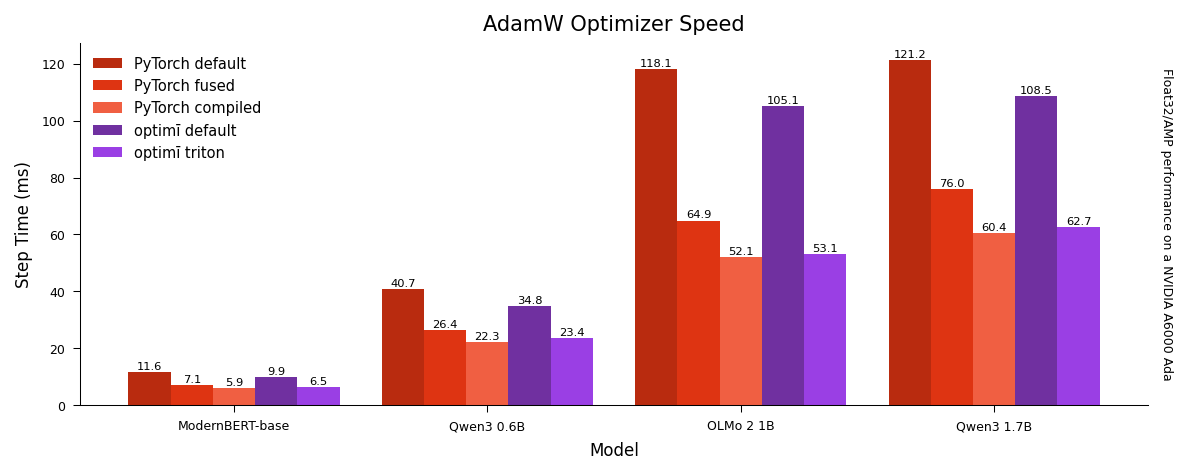
optimi's Triton backend supports modern NVIDIA (Ampere or newer), AMD, and Intel GPUs, and is enabled by default for all optimizers.
## Fully Decoupled Weight Decay
In addition to supporting PyTorch-style decoupled weight decay, optimi optimizers also support [fully decoupled weight decay](https://optimi.benjaminwarner.dev/fully_decoupled_weight_decay).
Fully decoupled weight decay decouples weight decay from the learning rate, more accurately following [*Decoupled Weight Decay Regularization*](https://arxiv.org/abs/1711.05101). This can help simplify hyperparameter tuning as the optimal weight decay is no longer tied to the learning rate.
## Gradient Release: Fused Backward and Optimizer Step
optimi optimizers can perform the [optimization step layer-by-layer during the backward pass](https://optimi.benjaminwarner.dev/gradient_release), immediately freeing gradient memory.
Unlike the current PyTorch implementation, optimi’s gradient release optimizers are a drop-in replacement for standard optimizers and seamlessly work with exisiting hyperparmeter schedulers.
## Optimizer Accumulation: Gradient Release and Accumulation
optimi optimizers can approximate gradient accumulation with gradient release by [accumulating gradients into the optimizer states](https://optimi.benjaminwarner.dev/optimizer_accumulation).
## Documentation
<https://optimi.benjaminwarner.dev>
## Optimizers
optimi implements the following optimizers:
- [Adam](https://optimi.benjaminwarner.dev/optimizers/adam)
- [AdamW](https://optimi.benjaminwarner.dev/optimizers/adamw)
- [Adan](https://optimi.benjaminwarner.dev/optimizers/adan)
- [Lion](https://optimi.benjaminwarner.dev/optimizers/lion)
- [RAdam](https://optimi.benjaminwarner.dev/optimizers/radam)
- [Ranger](https://optimi.benjaminwarner.dev/optimizers/ranger)
- [SGD](https://optimi.benjaminwarner.dev/optimizers/sgd)
- [StableAdamW](https://optimi.benjaminwarner.dev/optimizers/stableadamw)
## Install
optimi is available to install from pypi.
```bash
pip install torch-optimi
```
## Usage
To use an optimi optimizer with Kahan summation and fully decoupled weight decay:
```python
import torch
from torch import nn
from optimi import AdamW
# create or cast model in low precision (bfloat16)
model = nn.Linear(20, 1, dtype=torch.bfloat16)
# initialize any optimi optimizer with parameters & fully decoupled weight decay
# Kahan summation is automatically enabled since model & inputs are bfloat16
opt = AdamW(model.parameters(), lr=1e-3, weight_decay=1e-5, decouple_lr=True)
# forward and backward, casting input to bfloat16 if needed
loss = model(torch.randn(20, dtype=torch.bfloat16))
loss.backward()
# optimizer step
opt.step()
opt.zero_grad()
```
To use with PyTorch-style weight decay with float32 or mixed precision:
```python
# create model
model = nn.Linear(20, 1)
# initialize any optimi optimizer with parameters
opt = AdamW(model.parameters(), lr=1e-3, weight_decay=1e-2)
```
To use with gradient release:
```python
# initialize any optimi optimizer with `gradient_release=True`
# and call `prepare_for_gradient_release` on model and optimizer
opt = AdamW(model.parameters(), lr=1e-3, gradient_release=True)
prepare_for_gradient_release(model, opt)
# setup a learning rate scheduler like normal
scheduler = CosineAnnealingLR(opt, ...)
# calling backward on the model will peform the optimzier step
loss = model(torch.randn(20, dtype=torch.bfloat16))
loss.backward()
# optimizer step and zero_grad are no longer needed, and will
# harmlessly no-op if called by an existing training framework
# opt.step()
# opt.zero_grad()
# step the learning rate scheduler like normal
scheduler.step()
# optionally remove gradient release hooks when done training
remove_gradient_release(model)
```
To use with optimizer accumulation:
```python
# initialize any optimi optimizer with `gradient_release=True`
# and call `prepare_for_gradient_release` on model and optimizer
opt = AdamW(model.parameters(), lr=1e-3, gradient_release=True)
prepare_for_gradient_release(model, opt)
# update model parameters every four steps after accumulating
# gradients directly into the optimizer states
accumulation_steps = 4
# setup a learning rate scheduler for gradient accumulation
scheduler = CosineAnnealingLR(opt, ...)
# use existing PyTorch dataloader
for idx, batch in enumerate(dataloader):
# `optimizer_accumulation=True` accumulates gradients into
# optimizer states. set `optimizer_accumulation=False` to
# update parameters by performing a full gradient release step
opt.optimizer_accumulation = (idx+1) % accumulation_steps != 0
# calling backward on the model will peform the optimizer step
# either accumulating gradients or updating model parameters
loss = model(batch)
loss.backward()
# optimizer step and zero_grad are no longer needed, and will
# harmlessly no-op if called by an existing training framework
# opt.step()
# opt.zero_grad()
# step the learning rate scheduler after accumulating gradients
if not opt.optimizer_accumulation:
scheduler.step()
# optionally remove gradient release hooks when done training
remove_gradient_release(model)
```
## Differences from PyTorch
optimi optimizers do not support compilation, differentiation, complex numbers, or have capturable versions.
optimi Adam optimizers do not support AMSGrad and SGD does not support Nesterov momentum. Optimizers which debias updates (Adam optimizers and Adan) calculate the debias term per parameter group, not per parameter.
Raw data
{
"_id": null,
"home_page": null,
"name": "torch-optimi",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.10",
"maintainer_email": null,
"keywords": "Optimizers, PyTorch, Deep Learning, AI",
"author": "Benjamin Warner",
"author_email": "Benjamin Warner <me@benjaminwarner.dev>",
"download_url": "https://files.pythonhosted.org/packages/9e/e9/8e3ff53b37daf78926afd91ee4eb9c26fa76c545cdccb2c27b31fb6d3583/torch_optimi-0.3.1.tar.gz",
"platform": null,
"description": "# optim\u012b\n\n### Fast, Modern, and Low Precision PyTorch Optimizers\n\n[](https://pypi.org/project/torch-optimi/)\n[](https://pypi.org/project/torch-optimi/)\n[](https://pepy.tech/projects/torch-optimi)\n[](https://optimi.benjaminwarner.dev)\n\noptimi enables accurate low precision training via Kahan summation, integrates gradient release and optimizer accumulation for additional memory efficiency, supports fully decoupled weight decay, and features fast implementations of modern optimizers.\n\n## Low Precision Training with Kahan Summation\n\noptimi optimizers can match the performance of mixed precision when [training in pure BFloat16 by using Kahan summation](https://optimi.benjaminwarner.dev/kahan_summation).\n\n\n\nTraining in BFloat16 with Kahan summation can reduce non-activation training memory usage by [37 to 45 percent](https://optimi.benjaminwarner.dev/kahan_summation/#memory-savings) when using an Adam optimizer. BFloat16 training can increase single GPU [training speed up to 10 percent](https://optimi.benjaminwarner.dev/kahan_summation/#training-speedup) at the same batch size.\n\n## Fast Triton Implementations\n\noptimi's fused [Triton optimizers](https://optimi.benjaminwarner.dev/triton) are faster than PyTorch's fused Cuda optimizers, and nearly as fast as compiled optimizers without any hassle.\n\n\n\noptimi's Triton backend supports modern NVIDIA (Ampere or newer), AMD, and Intel GPUs, and is enabled by default for all optimizers.\n\n## Fully Decoupled Weight Decay\n\nIn addition to supporting PyTorch-style decoupled weight decay, optimi optimizers also support [fully decoupled weight decay](https://optimi.benjaminwarner.dev/fully_decoupled_weight_decay).\n\nFully decoupled weight decay decouples weight decay from the learning rate, more accurately following [*Decoupled Weight Decay Regularization*](https://arxiv.org/abs/1711.05101). This can help simplify hyperparameter tuning as the optimal weight decay is no longer tied to the learning rate.\n\n## Gradient Release: Fused Backward and Optimizer Step\n\noptimi optimizers can perform the [optimization step layer-by-layer during the backward pass](https://optimi.benjaminwarner.dev/gradient_release), immediately freeing gradient memory.\n\nUnlike the current PyTorch implementation, optimi\u2019s gradient release optimizers are a drop-in replacement for standard optimizers and seamlessly work with exisiting hyperparmeter schedulers.\n\n## Optimizer Accumulation: Gradient Release and Accumulation\n\noptimi optimizers can approximate gradient accumulation with gradient release by [accumulating gradients into the optimizer states](https://optimi.benjaminwarner.dev/optimizer_accumulation).\n\n## Documentation\n\n<https://optimi.benjaminwarner.dev>\n\n## Optimizers\n\noptimi implements the following optimizers:\n- [Adam](https://optimi.benjaminwarner.dev/optimizers/adam)\n- [AdamW](https://optimi.benjaminwarner.dev/optimizers/adamw)\n- [Adan](https://optimi.benjaminwarner.dev/optimizers/adan)\n- [Lion](https://optimi.benjaminwarner.dev/optimizers/lion)\n- [RAdam](https://optimi.benjaminwarner.dev/optimizers/radam)\n- [Ranger](https://optimi.benjaminwarner.dev/optimizers/ranger)\n- [SGD](https://optimi.benjaminwarner.dev/optimizers/sgd)\n- [StableAdamW](https://optimi.benjaminwarner.dev/optimizers/stableadamw)\n\n## Install\n\noptimi is available to install from pypi.\n\n```bash\npip install torch-optimi\n```\n\n## Usage\n\nTo use an optimi optimizer with Kahan summation and fully decoupled weight decay:\n\n```python\nimport torch\nfrom torch import nn\nfrom optimi import AdamW\n\n# create or cast model in low precision (bfloat16)\nmodel = nn.Linear(20, 1, dtype=torch.bfloat16)\n\n# initialize any optimi optimizer with parameters & fully decoupled weight decay\n# Kahan summation is automatically enabled since model & inputs are bfloat16\nopt = AdamW(model.parameters(), lr=1e-3, weight_decay=1e-5, decouple_lr=True)\n\n# forward and backward, casting input to bfloat16 if needed\nloss = model(torch.randn(20, dtype=torch.bfloat16))\nloss.backward()\n\n# optimizer step\nopt.step()\nopt.zero_grad()\n```\n\nTo use with PyTorch-style weight decay with float32 or mixed precision:\n\n```python\n# create model\nmodel = nn.Linear(20, 1)\n\n# initialize any optimi optimizer with parameters\nopt = AdamW(model.parameters(), lr=1e-3, weight_decay=1e-2)\n```\n\nTo use with gradient release:\n\n```python\n# initialize any optimi optimizer with `gradient_release=True`\n# and call `prepare_for_gradient_release` on model and optimizer\nopt = AdamW(model.parameters(), lr=1e-3, gradient_release=True)\nprepare_for_gradient_release(model, opt)\n\n# setup a learning rate scheduler like normal\nscheduler = CosineAnnealingLR(opt, ...)\n\n# calling backward on the model will peform the optimzier step\nloss = model(torch.randn(20, dtype=torch.bfloat16))\nloss.backward()\n\n# optimizer step and zero_grad are no longer needed, and will\n# harmlessly no-op if called by an existing training framework\n# opt.step()\n# opt.zero_grad()\n\n# step the learning rate scheduler like normal\nscheduler.step()\n\n# optionally remove gradient release hooks when done training\nremove_gradient_release(model)\n```\n\nTo use with optimizer accumulation:\n\n```python\n# initialize any optimi optimizer with `gradient_release=True`\n# and call `prepare_for_gradient_release` on model and optimizer\nopt = AdamW(model.parameters(), lr=1e-3, gradient_release=True)\nprepare_for_gradient_release(model, opt)\n\n# update model parameters every four steps after accumulating\n# gradients directly into the optimizer states\naccumulation_steps = 4\n\n# setup a learning rate scheduler for gradient accumulation\nscheduler = CosineAnnealingLR(opt, ...)\n\n# use existing PyTorch dataloader\nfor idx, batch in enumerate(dataloader):\n # `optimizer_accumulation=True` accumulates gradients into\n # optimizer states. set `optimizer_accumulation=False` to\n # update parameters by performing a full gradient release step\n opt.optimizer_accumulation = (idx+1) % accumulation_steps != 0\n\n # calling backward on the model will peform the optimizer step\n # either accumulating gradients or updating model parameters\n loss = model(batch)\n loss.backward()\n\n # optimizer step and zero_grad are no longer needed, and will\n # harmlessly no-op if called by an existing training framework\n # opt.step()\n # opt.zero_grad()\n\n # step the learning rate scheduler after accumulating gradients\n if not opt.optimizer_accumulation:\n scheduler.step()\n\n# optionally remove gradient release hooks when done training\nremove_gradient_release(model)\n```\n\n## Differences from PyTorch\n\noptimi optimizers do not support compilation, differentiation, complex numbers, or have capturable versions.\n\noptimi Adam optimizers do not support AMSGrad and SGD does not support Nesterov momentum. Optimizers which debias updates (Adam optimizers and Adan) calculate the debias term per parameter group, not per parameter.\n",
"bugtrack_url": null,
"license": "MIT License Copyright (c) 2023 Benjamin Warner Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.",
"summary": "Fast, Modern, & Low Precision PyTorch Optimizers",
"version": "0.3.1",
"project_urls": {
"Bug Reports": "https://github.com/warner-benjamin/optimi/issues",
"Homepage": "https://optimi.benjaminwarner.dev",
"Source": "https://github.com/warner-benjamin/optimi"
},
"split_keywords": [
"optimizers",
" pytorch",
" deep learning",
" ai"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "6057f43262d46c906fba337a739481308466cb486cf91e3027061951c12b6cdd",
"md5": "e36b4955d99479f39c87ecc85452c075",
"sha256": "913ef7afb757ced56d5da4d5011db4da3f191925d976efac27a7f3ee1cfe2c1a"
},
"downloads": -1,
"filename": "torch_optimi-0.3.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "e36b4955d99479f39c87ecc85452c075",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.10",
"size": 49216,
"upload_time": "2025-07-25T21:18:40",
"upload_time_iso_8601": "2025-07-25T21:18:40.085374Z",
"url": "https://files.pythonhosted.org/packages/60/57/f43262d46c906fba337a739481308466cb486cf91e3027061951c12b6cdd/torch_optimi-0.3.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "9ee98e3ff53b37daf78926afd91ee4eb9c26fa76c545cdccb2c27b31fb6d3583",
"md5": "11038da5f272f7d2e046827228dd4491",
"sha256": "1694adff82647a433b266025beced12bb2ba635735e2c367de93b9069645f435"
},
"downloads": -1,
"filename": "torch_optimi-0.3.1.tar.gz",
"has_sig": false,
"md5_digest": "11038da5f272f7d2e046827228dd4491",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.10",
"size": 24697,
"upload_time": "2025-07-25T21:18:41",
"upload_time_iso_8601": "2025-07-25T21:18:41.237498Z",
"url": "https://files.pythonhosted.org/packages/9e/e9/8e3ff53b37daf78926afd91ee4eb9c26fa76c545cdccb2c27b31fb6d3583/torch_optimi-0.3.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-07-25 21:18:41",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "warner-benjamin",
"github_project": "optimi",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "torch-optimi"
}
