# trendfilter:
Trend filtering is about building a model for a 1D function
(could be a time series) that has some nice properties such as
smoothness or sparse changes in slopes (piecewise linear). It can
also incorporate other features such as seasonality and can be
made very robust to outliers and other data corruption features.
Here's a visual example

The objective to be minimized is, in our case, Huber loss with
regularization on 1st and 2nd derivative plus some constraints.
Can be either L1 or L2 norms for regularization.
This library provides a flexible and powerful python function to
do trend filtering and is built on top of the
convex optimization library cvxpy.
Trend filtering is very useful on typical data science problems we
that we commonly run into in the business world. These types of
data series are typically not very large and low signal-to-noise. An
example might be monthly sales of one type of product.
Unlike high signal-to-noise data, that is
often treated with other time-series techniques, thee main desire
is finding the most recent trend and extrapolating forward a bit. The
biggest problem is data quality issues. So we want to do this as
robustly as possible. It's also quite useful when we want to include
the data corruption as part of the model and extract it at the same
time instead of requiring a pre-processing step with some arbitrary
rules.
This is what this technique is best utilized for.
Larger, richer data sets (e.g. medical EKG data) with thousands
or millions of points, low noise and no outliers, might be
better approached with other techniques that focus most of all on
extracting the full complexity of the signal from a small amount of
noise.
# Install
pip install trendfilter
or clone the repo.
# Examples:
Contruct some x, y data where there is noise as well as few
outliers. See
[test file](https://github.com/dave31415/trendfilter/blob/master/test/test_tf.py)
for prep_data code and plotting code.
First build the base model with no regularization. This is essentially
just an overly complex way of constructing an interpolation function.
```
from trendfilter import trend_filter, get_example_data, plot_model
x, y_noisy = get_example_data()
result = trend_filter(x, y_noisy)
title = 'Base model, no regularization'
plot_model(result, title=title)
```

This has no real use by itself. It's just saying the model is the
same as the data points.
You'll always want to give it some key-words to
apply some kind of regularization or constraint so that the model
is not simply the same as the noisy data.
Let's do something more useful. Don't do any regularization yet. Just
force the model to be monotonically increasing. So basically, it
is looking for the model which has minimal Huber loss but is
constrained to be monotonically increasing.
We use Huber loss because it is robust to outliers while still
looking like quadratic loss for small values.
```
result = trend_filter(x, y_noisy, monotonic=True)
plot_model(result, show_extrap=True, extrap_max=3)
```
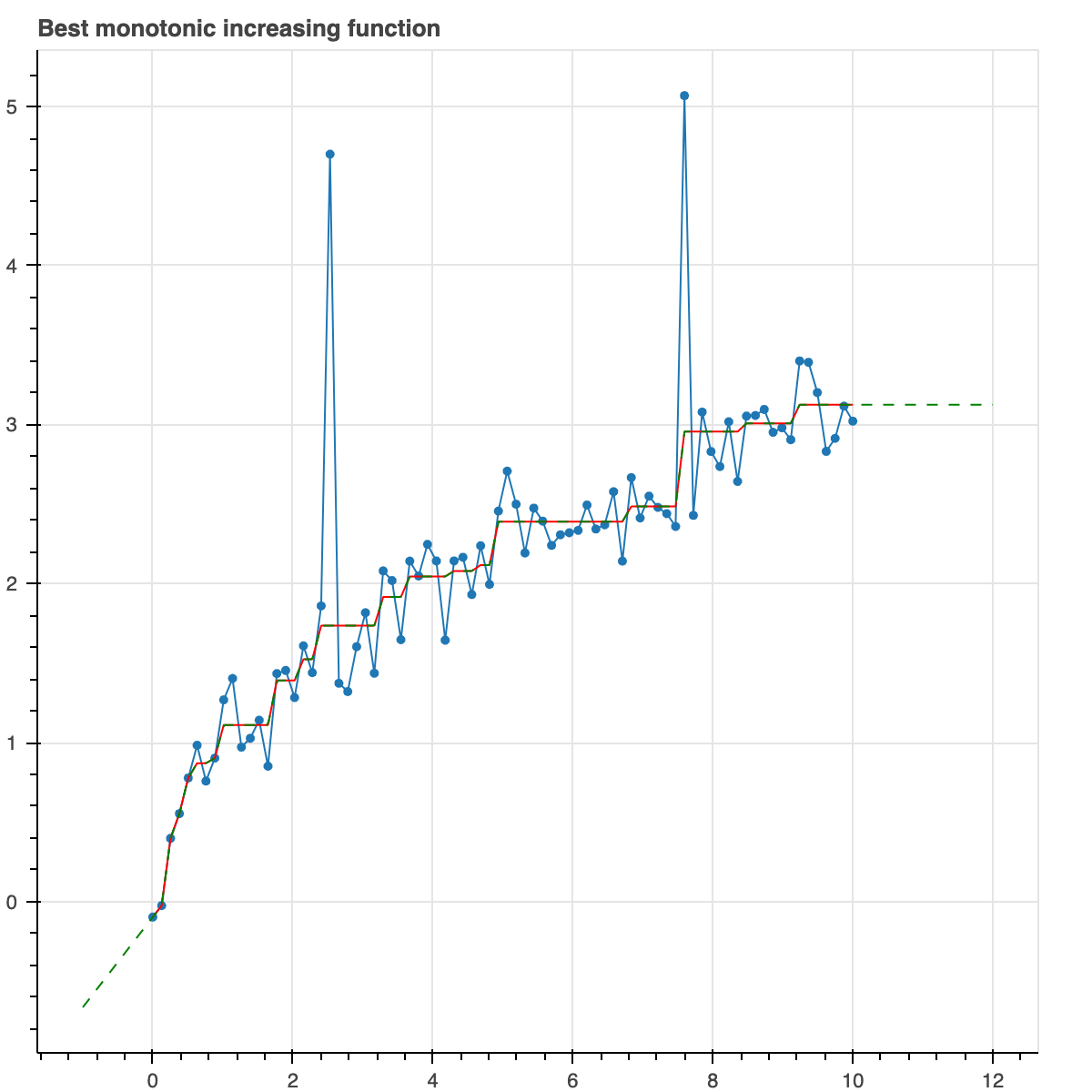
The green line, by the way, just shows that the function can be extrapolated
which is a very useful thing, for example, if you want to make predictions
about the future.
Ok, now let's do an L1 trend filter model. So we are going to
penalize any non-zero second derivative with an L1 norm. As we
probably know, L1 norms induce sparseness. So the second dervative at
most of the points will be exactly zero but will probably be non-zero
at a few of them. Thus, we expect piecewise linear trends that
occasionally have sudden slope changes.
```
result = trend_filter(x, y_noisy, l_norm=1, alpha_2=0.2)
plot_model(result, show_extrap=True, extrap_max=3)
```

Let's do the same thing but enforce it to be monotonic.
```
result = trend_filter(x, y_noisy, l_norm=1, alpha_2=0.2, monotonic=True)
plot_model(result, show_extrap=True, extrap_max=3)
```

Now let's increase the regularization parameter to give a higher
penalty to slope changes. It results in longer trends. Fewer slope
changes. Overall, less complexity.
```
result = trend_filter(x, y_noisy, l_norm=1, alpha_2=2.0)
plot_model(result, show_extrap=True, extrap_max=3)
```

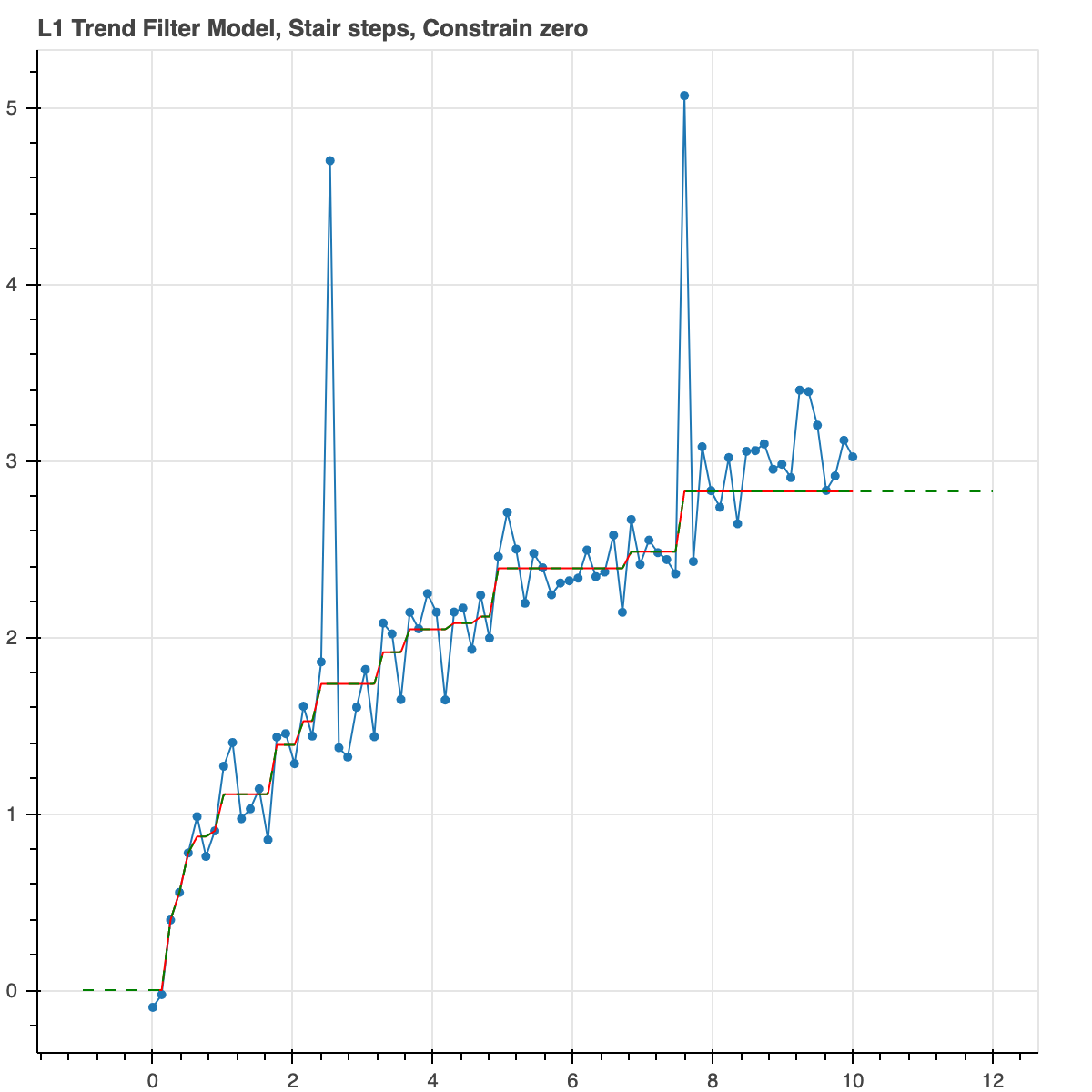
Did you like the stair steps? Let's do that again. But now
we will not force it to be monotonic. We are going to put an
L1 norm on the first derivative. This produces a similar
output but it could actually decrease if the data actually
did so. Let's also constrain the curve to go through the origin,
(0,0).
```
result = trend_filter(x, y_noisy, l_norm=1, alpha_1=1.0, constrain_zero=True)
plot_model(result, show_extrap=True, extrap_max=3)
```
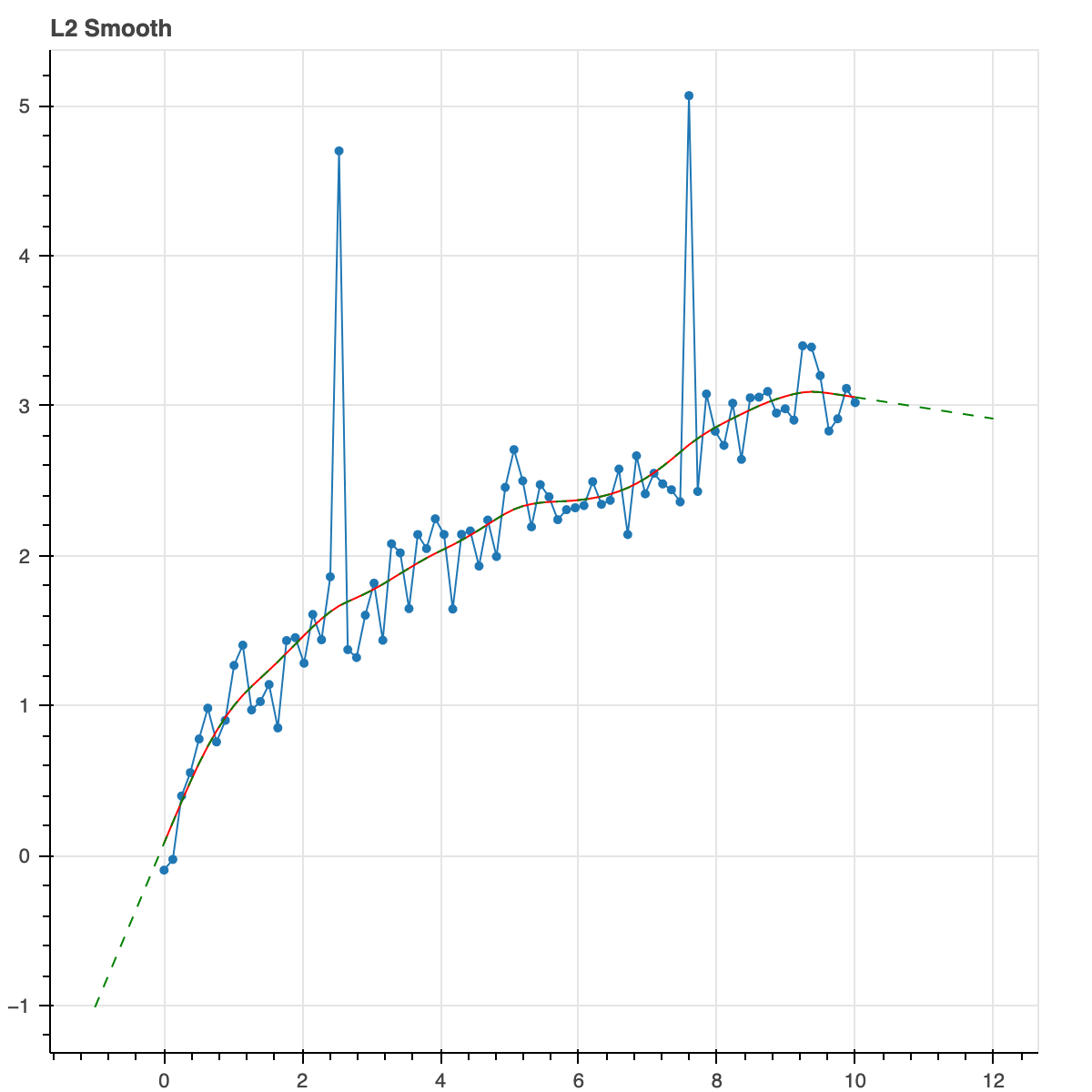
Let's do L2 norms for regularization on the second
derivative. L2 norms don't care very much about small values.
They don't force them all the way to zero to create sparse
solution. They care more about big values. This results is a
smooth continuous curve. This is a nice way of doing robust
smoothing.
```
result = trend_filter(x, y_noisy, l_norm=2, alpha_2=2.0)
plot_model(result, show_extrap=True, extrap_max=3)
```
Here is the full function signature.
```
def trend_filter(x, y, y_err=None, alpha_1=0.0,
alpha_2=0.0, l_norm=2,
constrain_zero=False, monotonic=False,
positive=False,
linear_deviations=None):
```
So you see there are alpha key-words for regularization parameters.
The number n, tells you the derivative is being penalized.
You can use any, all or none of them. The key-word
l_norm gives you the choice of 1 or 2. Monotonic and
constrain_zero, we've explained already. positive forces the
base model to be positive. linear_deviations will be explained in a bit.
The data structure returned by trend_filter is a dictionary with various
pieces of information about the model. The most import are
'y_fit' which is an array of best fit model values corresponding to
each point x. The 'function' element is a function mapping any x to the
model value, including points outside the initial range. These external
points will be extrapolated linearly. In the case that the data is a
time-series, this function can provide forecasts for the future.
We didn't discuss y_err. That's the uncertainty on y. The
default is 1. The Huber loss is actually applied to (data-model)/y_err.
So, you can weight points differently if you have a good reason to,
such as knowing the actual error values or knowing that some points
are dubious or if some points are known exactly. That would be the limit
as y_err goes towards zero and it will make the curve go through those
points.
All in all, these keywords give you a huge amount of freedom in
what you want your model to look like.
# Linear model deviations and seasonality:
Any time series library should include ways of modeling seasonality and
this one does as well. In fact, it includes something more general which is
the ability to add in any linear features to the model.
This linearity preserves convexity and so we can still use
convex optimization.
By linear deviation we means any addition to the model that is a specified
matrix multiplied by a variable vector. That variable vector can be solved
for as well.
To do this you create a data structure called linear deviations
```
linear_deviation = {'mapping': lambda x: int(x) % 12,
'name': 'seasonal_term',
'n_vars': 12,
'alpha': 0.1}
```
This assumes the matrix above is an assignment matrix. You can also create
a matrix yourself and include that as 'matrix' instead of 'mapping'.
This provides a mapping from x to some set of integer indices. You tell
it there are 12 of them. One for each month of the year. We can give it a
name 'seasonal_term' and a regularization parameter. Evidently, we are
going to use this on a monthly time series.
Now just call it like this.
```
linear_deviations = [linear_deviation]
result = trend_filter(x, y_noisy, l_norm=1, alpha_2=4.0, linear_deviations=linear_deviations)
```
Note that you input it as a list if linear deviations. You can include
multiple. Perhaps for example, you have one that marks months for which
the kids are in school or months where there was a convention
in town.
Let's see it in action.
We've created another data set with some seasonal pattern added.
This is how it looks when the model is run without seasonality.
```
from trendfilter import get_example_data_seasonal()
x, y_noisy = get_example_data_seasonal()
result = trend_filter(x, y_noisy, l_norm=1, alpha_2=4.0)
plot_model(result, show_extrap=True, extrap_max=40)
```
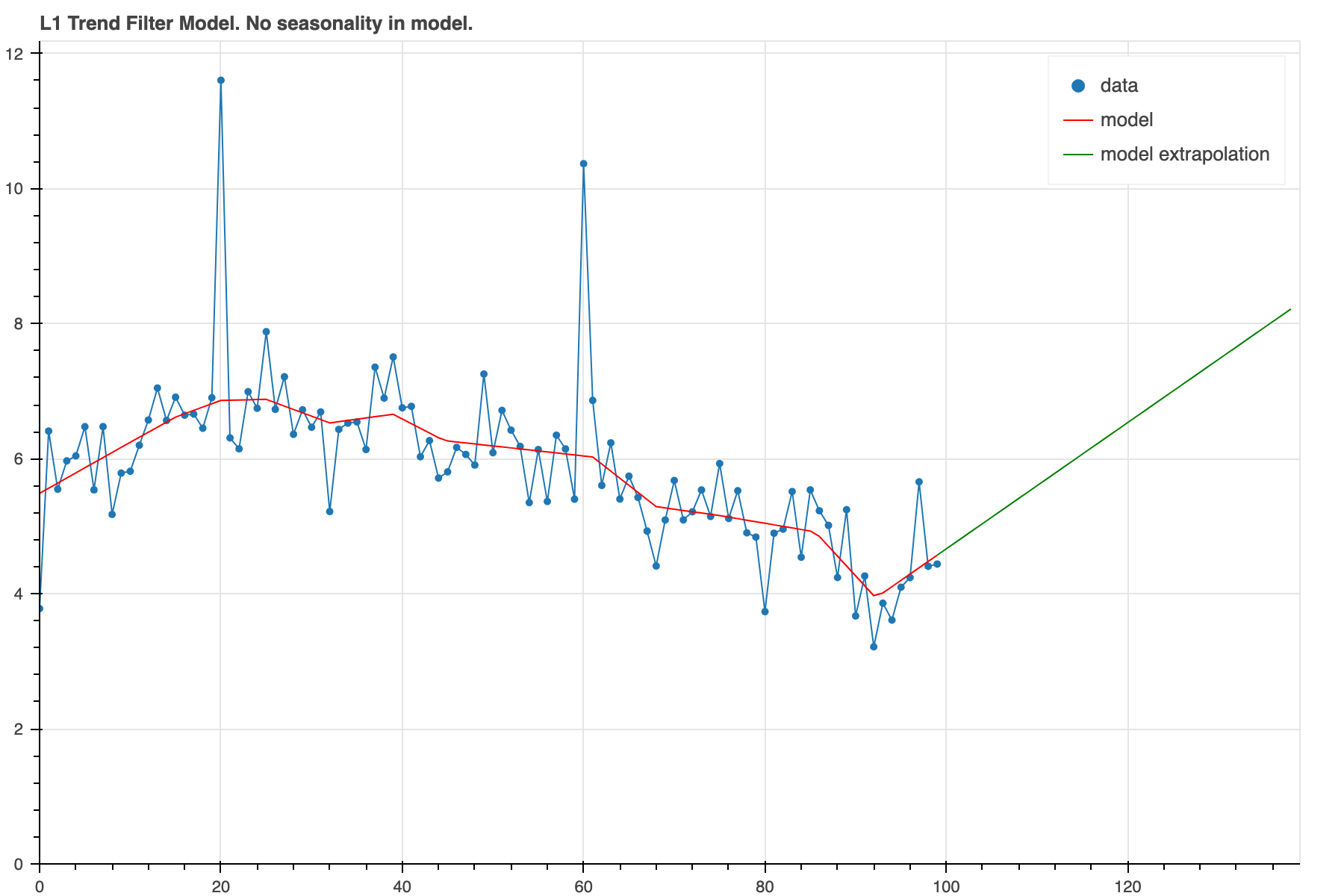
In this case the model is just trying to model all the wiggles
with a changing trend. This doesn't produce a very
convincing looking forecast. We can improve that some and iron
out the wiggles by using a higher alpha_2.
But if we notice there is some periodicity to it, we can
actually model it using the structure we created above.
```
result = trend_filter(x, y_noisy, l_norm=1, alpha_2=4.0, linear_deviations=linear_deviations)
plot_model(result, show_extrap=True, extrap_max=40, show_base=True)
```
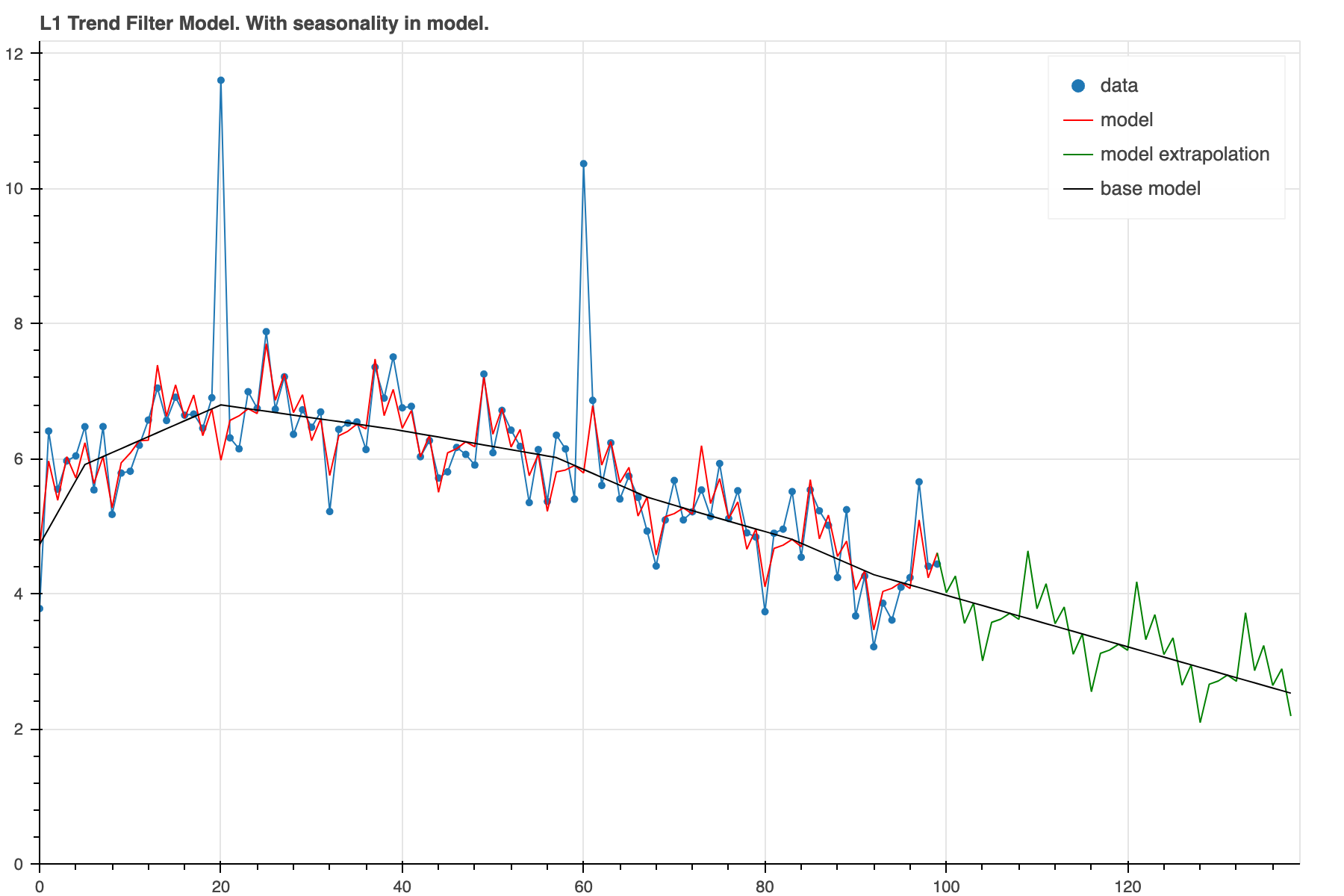
Now, we can see that there is indeed a prominant seasonal
pattern on top of a rather smooth base model. The forecast
now will include that same seasonal pattern which should
lead to a more accurate forecast.
The 'alpha' regularization determines the amount of evidence required
to make use of the seasonal component. For a larger alpha and the same
pattern here, it will take more cycles before it will overcome the barrier.
At this point the total objective is lower than trying to model the
wiggles with slope changes or tolerating a difference between model and
data.
First pypi version April 12, 2021
0.1.4
Added more examples with more documentation and plots in the Readme
0.1.5
Mostly a refactor but changed API slightly.
0.2.0
Includes seasonality and linear deviations.
0.2.1
Switched to ECOS solver
0.3.0
Switched to Claribel solver which is the new built in solver
Inputs now converted to numpy arrays so list inputs should work
0.3.2 Fixing PyPi to show plots, use full URLs
Raw data
{
"_id": null,
"home_page": "https://github.com/dave31415/trendfilter",
"name": "trendfilter",
"maintainer": null,
"docs_url": null,
"requires_python": null,
"maintainer_email": null,
"keywords": "cvxpy, trendfilter",
"author": "David Johnston",
"author_email": "dave31415@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/8c/a3/46b22c6f81de6afb14f44ac454e06edc74a6d876930c970a3290c54b8f1b/trendfilter-0.3.2.tar.gz",
"platform": null,
"description": "# trendfilter: \n\nTrend filtering is about building a model for a 1D function\n(could be a time series) that has some nice properties such as \nsmoothness or sparse changes in slopes (piecewise linear). It can\nalso incorporate other features such as seasonality and can be \nmade very robust to outliers and other data corruption features.\n\nHere's a visual example\n\n\n\n\nThe objective to be minimized is, in our case, Huber loss with\nregularization on 1st and 2nd derivative plus some constraints. \nCan be either L1 or L2 norms for regularization.\n\nThis library provides a flexible and powerful python function to \ndo trend filtering and is built on top of the \nconvex optimization library cvxpy.\n\nTrend filtering is very useful on typical data science problems we\nthat we commonly run into in the business world. These types of \ndata series are typically not very large and low signal-to-noise. An\nexample might be monthly sales of one type of product. \n\nUnlike high signal-to-noise data, that is \noften treated with other time-series techniques, thee main desire\nis finding the most recent trend and extrapolating forward a bit. The\nbiggest problem is data quality issues. So we want to do this as \nrobustly as possible. It's also quite useful when we want to include\nthe data corruption as part of the model and extract it at the same \ntime instead of requiring a pre-processing step with some arbitrary \nrules.\n\nThis is what this technique is best utilized for.\nLarger, richer data sets (e.g. medical EKG data) with thousands \nor millions of points, low noise and no outliers, might be\nbetter approached with other techniques that focus most of all on \nextracting the full complexity of the signal from a small amount of\nnoise.\n\n# Install\n\npip install trendfilter\n\nor clone the repo. \n\n# Examples:\n\nContruct some x, y data where there is noise as well as few \noutliers. See \n[test file](https://github.com/dave31415/trendfilter/blob/master/test/test_tf.py)\nfor prep_data code and plotting code.\n\nFirst build the base model with no regularization. This is essentially\njust an overly complex way of constructing an interpolation function. \n\n```\nfrom trendfilter import trend_filter, get_example_data, plot_model\n\nx, y_noisy = get_example_data()\nresult = trend_filter(x, y_noisy)\ntitle = 'Base model, no regularization'\nplot_model(result, title=title)\n```\n\n\n\nThis has no real use by itself. It's just saying the model is the\nsame as the data points.\n\nYou'll always want to give it some key-words to\napply some kind of regularization or constraint so that the model\nis not simply the same as the noisy data.\n\nLet's do something more useful. Don't do any regularization yet. Just\nforce the model to be monotonically increasing. So basically, it \nis looking for the model which has minimal Huber loss but is \nconstrained to be monotonically increasing. \n\nWe use Huber loss because it is robust to outliers while still\nlooking like quadratic loss for small values.\n\n```\nresult = trend_filter(x, y_noisy, monotonic=True)\nplot_model(result, show_extrap=True, extrap_max=3)\n```\n\n\n\nThe green line, by the way, just shows that the function can be extrapolated \nwhich is a very useful thing, for example, if you want to make predictions\nabout the future.\n\nOk, now let's do an L1 trend filter model. So we are going to \npenalize any non-zero second derivative with an L1 norm. As we \nprobably know, L1 norms induce sparseness. So the second dervative at \nmost of the points will be exactly zero but will probably be non-zero\nat a few of them. Thus, we expect piecewise linear trends that \noccasionally have sudden slope changes.\n\n```\nresult = trend_filter(x, y_noisy, l_norm=1, alpha_2=0.2)\nplot_model(result, show_extrap=True, extrap_max=3)\n```\n\n\n\nLet's do the same thing but enforce it to be monotonic.\n\n```\nresult = trend_filter(x, y_noisy, l_norm=1, alpha_2=0.2, monotonic=True)\nplot_model(result, show_extrap=True, extrap_max=3)\n```\n\n\n\n\nNow let's increase the regularization parameter to give a higher\npenalty to slope changes. It results in longer trends. Fewer slope\nchanges. Overall, less complexity.\n\n```\nresult = trend_filter(x, y_noisy, l_norm=1, alpha_2=2.0)\nplot_model(result, show_extrap=True, extrap_max=3)\n```\n\n\n\n\nDid you like the stair steps? Let's do that again. But now\nwe will not force it to be monotonic. We are going to put an\nL1 norm on the first derivative. This produces a similar \noutput but it could actually decrease if the data actually\ndid so. Let's also constrain the curve to go through the origin, \n(0,0).\n\n```\nresult = trend_filter(x, y_noisy, l_norm=1, alpha_1=1.0, constrain_zero=True)\nplot_model(result, show_extrap=True, extrap_max=3)\n```\n\n\n\n\nLet's do L2 norms for regularization on the second \nderivative. L2 norms don't care very much about small values. \nThey don't force them all the way to zero to create sparse \nsolution. They care more about big values. This results is a \nsmooth continuous curve. This is a nice way of doing robust \nsmoothing. \n\n```\nresult = trend_filter(x, y_noisy, l_norm=2, alpha_2=2.0)\nplot_model(result, show_extrap=True, extrap_max=3)\n```\n\n\n\n\nHere is the full function signature.\n\n```\ndef trend_filter(x, y, y_err=None, alpha_1=0.0,\n alpha_2=0.0, l_norm=2,\n constrain_zero=False, monotonic=False,\n positive=False,\n linear_deviations=None):\n```\n\nSo you see there are alpha key-words for regularization parameters. \nThe number n, tells you the derivative is being penalized.\nYou can use any, all or none of them. The key-word\nl_norm gives you the choice of 1 or 2. Monotonic and \nconstrain_zero, we've explained already. positive forces the \nbase model to be positive. linear_deviations will be explained in a bit.\n\nThe data structure returned by trend_filter is a dictionary with various\npieces of information about the model. The most import are \n'y_fit' which is an array of best fit model values corresponding to \neach point x. The 'function' element is a function mapping any x to the\nmodel value, including points outside the initial range. These external \npoints will be extrapolated linearly. In the case that the data is a \ntime-series, this function can provide forecasts for the future.\n\nWe didn't discuss y_err. That's the uncertainty on y. The\ndefault is 1. The Huber loss is actually applied to (data-model)/y_err.\nSo, you can weight points differently if you have a good reason to,\nsuch as knowing the actual error values or knowing that some points \nare dubious or if some points are known exactly. That would be the limit\nas y_err goes towards zero and it will make the curve go through those\npoints.\n\nAll in all, these keywords give you a huge amount of freedom in\nwhat you want your model to look like.\n\n# Linear model deviations and seasonality:\n\nAny time series library should include ways of modeling seasonality and \nthis one does as well. In fact, it includes something more general which is\nthe ability to add in any linear features to the model. \nThis linearity preserves convexity and so we can still use \nconvex optimization. \nBy linear deviation we means any addition to the model that is a specified\nmatrix multiplied by a variable vector. That variable vector can be solved\nfor as well. \n\nTo do this you create a data structure called linear deviations\n\n```\nlinear_deviation = {'mapping': lambda x: int(x) % 12,\n 'name': 'seasonal_term',\n 'n_vars': 12,\n 'alpha': 0.1}\n```\n\nThis assumes the matrix above is an assignment matrix. You can also create\na matrix yourself and include that as 'matrix' instead of 'mapping'. \n\nThis provides a mapping from x to some set of integer indices. You tell\nit there are 12 of them. One for each month of the year. We can give it a \nname 'seasonal_term' and a regularization parameter. Evidently, we are\ngoing to use this on a monthly time series. \n\nNow just call it like this.\n\n```\nlinear_deviations = [linear_deviation]\nresult = trend_filter(x, y_noisy, l_norm=1, alpha_2=4.0, linear_deviations=linear_deviations)\n```\n\nNote that you input it as a list if linear deviations. You can include\nmultiple. Perhaps for example, you have one that marks months for which\nthe kids are in school or months where there was a convention \nin town.\n\nLet's see it in action.\n\nWe've created another data set with some seasonal pattern added.\nThis is how it looks when the model is run without seasonality.\n\n```\nfrom trendfilter import get_example_data_seasonal()\n\nx, y_noisy = get_example_data_seasonal()\nresult = trend_filter(x, y_noisy, l_norm=1, alpha_2=4.0)\nplot_model(result, show_extrap=True, extrap_max=40)\n```\n\n\n\nIn this case the model is just trying to model all the wiggles\nwith a changing trend. This doesn't produce a very \nconvincing looking forecast. We can improve that some and iron\nout the wiggles by using a higher alpha_2.\n\nBut if we notice there is some periodicity to it, we can \nactually model it using the structure we created above.\n\n```\nresult = trend_filter(x, y_noisy, l_norm=1, alpha_2=4.0, linear_deviations=linear_deviations)\nplot_model(result, show_extrap=True, extrap_max=40, show_base=True)\n```\n\n\n\nNow, we can see that there is indeed a prominant seasonal\npattern on top of a rather smooth base model. The forecast \nnow will include that same seasonal pattern which should \nlead to a more accurate forecast.\n\nThe 'alpha' regularization determines the amount of evidence required\nto make use of the seasonal component. For a larger alpha and the same \npattern here, it will take more cycles before it will overcome the barrier.\nAt this point the total objective is lower than trying to model the \nwiggles with slope changes or tolerating a difference between model and \ndata.\n\n\nFirst pypi version April 12, 2021\n\n0.1.4 \nAdded more examples with more documentation and plots in the Readme\n\n0.1.5\nMostly a refactor but changed API slightly.\n\n0.2.0\nIncludes seasonality and linear deviations.\n\n0.2.1\nSwitched to ECOS solver\n\n0.3.0 \nSwitched to Claribel solver which is the new built in solver\nInputs now converted to numpy arrays so list inputs should work\n\n0.3.2 Fixing PyPi to show plots, use full URLs\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "Useful trendfilter algorithm",
"version": "0.3.2",
"project_urls": {
"Download": "https://pypi.org/project/trendfilter/",
"Homepage": "https://github.com/dave31415/trendfilter"
},
"split_keywords": [
"cvxpy",
" trendfilter"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "370a463337a8dfae672d718959701d748ed431e5345b63e33927c194811711c6",
"md5": "2875a88b4083cb9840f2f4c7b46c6f65",
"sha256": "a56bffd2f8852f272384bf32c1b8fe00154d95ed7965d226359e9a981a332548"
},
"downloads": -1,
"filename": "trendfilter-0.3.2-py3-none-any.whl",
"has_sig": false,
"md5_digest": "2875a88b4083cb9840f2f4c7b46c6f65",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": null,
"size": 12991,
"upload_time": "2024-08-21T18:02:49",
"upload_time_iso_8601": "2024-08-21T18:02:49.409868Z",
"url": "https://files.pythonhosted.org/packages/37/0a/463337a8dfae672d718959701d748ed431e5345b63e33927c194811711c6/trendfilter-0.3.2-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "8ca346b22c6f81de6afb14f44ac454e06edc74a6d876930c970a3290c54b8f1b",
"md5": "45af0ccdfa5d3e3013975cf5ab0ccb22",
"sha256": "91b21d9767f63aa3d4767e910d2ae8eff5562379fcad659a8022595b0de29eed"
},
"downloads": -1,
"filename": "trendfilter-0.3.2.tar.gz",
"has_sig": false,
"md5_digest": "45af0ccdfa5d3e3013975cf5ab0ccb22",
"packagetype": "sdist",
"python_version": "source",
"requires_python": null,
"size": 16022,
"upload_time": "2024-08-21T18:02:50",
"upload_time_iso_8601": "2024-08-21T18:02:50.876022Z",
"url": "https://files.pythonhosted.org/packages/8c/a3/46b22c6f81de6afb14f44ac454e06edc74a6d876930c970a3290c54b8f1b/trendfilter-0.3.2.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-08-21 18:02:50",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "dave31415",
"github_project": "trendfilter",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"requirements": [],
"lcname": "trendfilter"
}

