[](https://pypi.org/project/unidic2ud/)
# UniDic2UD
Tokenizer, POS-tagger, lemmatizer, and dependency-parser for modern and contemporary Japanese, working on [Universal Dependencies](https://universaldependencies.org/format.html).
## Basic usage
```py
>>> import unidic2ud
>>> nlp=unidic2ud.load("kindai")
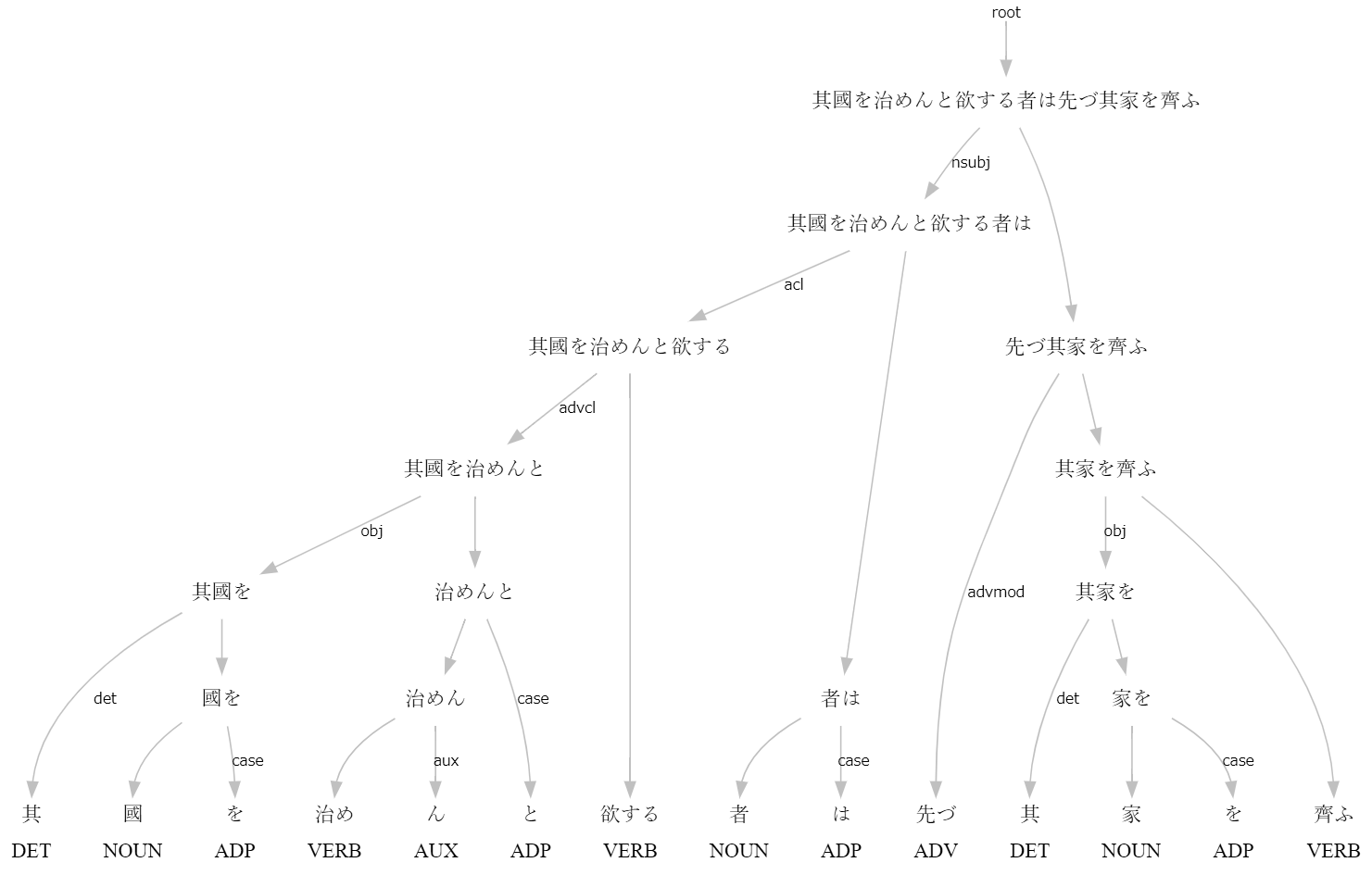
>>> s=nlp("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(s)
# text = 其國を治めんと欲する者は先づ其家を齊ふ
1 其 其の DET 連体詞 _ 2 det _ SpaceAfter=No|Translit=ソノ
2 國 国 NOUN 名詞-普通名詞-一般 _ 4 obj _ SpaceAfter=No|Translit=クニ
3 を を ADP 助詞-格助詞 _ 2 case _ SpaceAfter=No|Translit=ヲ
4 治め 収める VERB 動詞-一般 _ 7 advcl _ SpaceAfter=No|Translit=オサメ
5 ん む AUX 助動詞 _ 4 aux _ SpaceAfter=No|Translit=ン
6 と と ADP 助詞-格助詞 _ 4 case _ SpaceAfter=No|Translit=ト
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
8 者 者 NOUN 名詞-普通名詞-一般 _ 14 nsubj _ SpaceAfter=No|Translit=モノ
9 は は ADP 助詞-係助詞 _ 8 case _ SpaceAfter=No|Translit=ハ
10 先づ 先ず ADV 副詞 _ 14 advmod _ SpaceAfter=No|Translit=マヅ
11 其 其の DET 連体詞 _ 12 det _ SpaceAfter=No|Translit=ソノ
12 家 家 NOUN 名詞-普通名詞-一般 _ 14 obj _ SpaceAfter=No|Translit=ウチ
13 を を ADP 助詞-格助詞 _ 12 case _ SpaceAfter=No|Translit=ヲ
14 齊ふ 整える VERB 動詞-一般 _ 0 root _ SpaceAfter=No|Translit=トトノフ
>>> t=s[7]
>>> print(t.id,t.form,t.lemma,t.upos,t.xpos,t.feats,t.head.id,t.deprel,t.deps,t.misc)
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
>>> print(s.to_tree())
其 <══╗ det(決定詞)
國 ═╗═╝<╗ obj(目的語)
を <╝ ║ case(格表示)
治め ═╗═╗═╝<╗ advcl(連用修飾節)
ん <╝ ║ ║ aux(動詞補助成分)
と <══╝ ║ case(格表示)
欲する ═══════╝<╗ acl(連体修飾節)
者 ═╗═══════╝<╗ nsubj(主語)
は <╝ ║ case(格表示)
先づ <══════╗ ║ advmod(連用修飾語)
其 <══╗ ║ ║ det(決定詞)
家 ═╗═╝<╗ ║ ║ obj(目的語)
を <╝ ║ ║ ║ case(格表示)
齊ふ ═════╝═╝═══╝ root(親)
>>> f=open("trial.svg","w")
>>> f.write(s.to_svg())
>>> f.close()
```

`unidic2ud.load(UniDic,UDPipe)` loads a natural language processor pipeline, which uses `UniDic` for tokenizer POS-tagger and lemmatizer, then uses `UDPipe` for dependency-parser. The default `UDPipe` is `UDPipe="japanese-modern"`. Available `UniDic` options are:
* `UniDic="gendai"`: Use [現代書き言葉UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_bccwj).
* `UniDic="spoken"`: Use [現代話し言葉UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_csj).
* `UniDic="novel"`: Use [近現代口語小説UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_novel).
* `UniDic="qkana"`: Use [旧仮名口語UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_qkana).
* `UniDic="kindai"`: Use [近代文語UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_kindai).
* `UniDic="kinsei"`: Use [近世江戸口語UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_kinsei-edo).
* `UniDic="kyogen"`: Use [中世口語UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_chusei-kougo).
* `UniDic="wakan"`: Use [中世文語UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_chusei-bungo).
* `UniDic="wabun"`: Use [中古和文UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_wabun).
* `UniDic="manyo"`: Use [上代語UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_jodai).
* `UniDic=None`: Use `UDPipe` for tokenizer, POS-tagger, lemmatizer, and dependency-parser.
`unidic2ud.UniDic2UDEntry.to_tree()` has an option `to_tree(BoxDrawingWidth=2)` for old terminals, whose Box Drawing characters are "fullwidth".
You can simply use `unidic2ud` on the command line:
```sh
echo 其國を治めんと欲する者は先づ其家を齊ふ | unidic2ud -U kindai
```
## CaboCha emulator usage
```py
>>> import unidic2ud.cabocha as CaboCha
>>> c=CaboCha.Parser("kindai")
>>> s=c.parse("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(s.toString(CaboCha.FORMAT_TREE_LATTICE))
其-D
國を-D
治めんと-D
欲する-D
者は-------D
先づ-----D
其-D |
家を-D
齊ふ
EOS
* 0 1D 0/0 0.000000
其 連体詞,*,*,*,*,*,其の,ソノ,*,DET O 1<-det-2
* 1 2D 0/1 0.000000
國 名詞,普通名詞,一般,*,*,*,国,クニ,*,NOUN O 2<-obj-4
を 助詞,格助詞,*,*,*,*,を,ヲ,*,ADP O 3<-case-2
* 2 3D 0/1 0.000000
治め 動詞,一般,*,*,*,*,収める,オサメ,*,VERB O 4<-advcl-7
ん 助動詞,*,*,*,*,*,む,ン,*,AUX O 5<-aux-4
と 助詞,格助詞,*,*,*,*,と,ト,*,ADP O 6<-case-4
* 3 4D 0/0 0.000000
欲する 動詞,一般,*,*,*,*,欲する,ホッスル,*,VERB O 7<-acl-8
* 4 8D 0/1 0.000000
者 名詞,普通名詞,一般,*,*,*,者,モノ,*,NOUN O 8<-nsubj-14
は 助詞,係助詞,*,*,*,*,は,ハ,*,ADP O 9<-case-8
* 5 8D 0/0 0.000000
先づ 副詞,*,*,*,*,*,先ず,マヅ,*,ADV O 10<-advmod-14
* 6 7D 0/0 0.000000
其 連体詞,*,*,*,*,*,其の,ソノ,*,DET O 11<-det-12
* 7 8D 0/1 0.000000
家 名詞,普通名詞,一般,*,*,*,家,ウチ,*,NOUN O 12<-obj-14
を 助詞,格助詞,*,*,*,*,を,ヲ,*,ADP O 13<-case-12
* 8 -1D 0/0 0.000000
齊ふ 動詞,一般,*,*,*,*,整える,トトノフ,*,VERB O 14<-root
EOS
>>> for c in [s.chunk(i) for i in range(s.chunk_size())]:
... if c.link>=0:
... print(c,"->",s.chunk(c.link))
...
其 -> 國を
國を -> 治めんと
治めんと -> 欲する
欲する -> 者は
者は -> 齊ふ
先づ -> 齊ふ
其 -> 家を
家を -> 齊ふ
```
`CaboCha.Parser(UniDic)` is an alias for `unidic2ud.load(UniDic,UDPipe="japanese-modern")`, and its default is `UniDic=None`. `CaboCha.Tree.toString(format)` has five available formats:
* `CaboCha.FORMAT_TREE`: tree (numbered as 0)
* `CaboCha.FORMAT_LATTICE`: lattice (numbered as 1)
* `CaboCha.FORMAT_TREE_LATTICE`: tree + lattice (numbered as 2)
* `CaboCha.FORMAT_XML`: XML (numbered as 3)
* `CaboCha.FORMAT_CONLL`: Universal Dependencies CoNLL-U (numbered as 4)
You can simply use `udcabocha` on the command line:
```sh
echo 其國を治めんと欲する者は先づ其家を齊ふ | udcabocha -U kindai -f 2
```
`-U UniDic` specifies `UniDic`. `-f format` specifies the output format in 0 to 4 above (default is `-f 0`) and in 5 to 8 below:
* `-f 5`: `to_tree()`
* `-f 6`: `to_tree(BoxDrawingWidth=2)`
* `-f 7`: `to_svg()`
* `-f 8`: [raw DOT](https://graphviz.readthedocs.io/en/stable/manual.html#using-raw-dot) graph through [Immediate Catena Analysis](https://koichiyasuoka.github.io/deplacy/#deplacydot)
Try [notebook](https://colab.research.google.com/github/KoichiYasuoka/UniDic2UD/blob/master/udcabocha.ipynb) for Google Colaboratory.
## Usage via spaCy
If you have already installed [spaCy](https://pypi.org/project/spacy/) 2.1.0 or later, you can use `UniDic` via spaCy Language pipeline.
```py
>>> import unidic2ud.spacy
>>> nlp=unidic2ud.spacy.load("kindai")
>>> d=nlp("其國を治めんと欲する者は先づ其家を齊ふ")
>>> print(unidic2ud.spacy.to_conllu(d))
# text = 其國を治めんと欲する者は先づ其家を齊ふ
1 其 其の DET 連体詞 _ 2 det _ SpaceAfter=No|Translit=ソノ
2 國 国 NOUN 名詞-普通名詞-一般 _ 4 obj _ SpaceAfter=No|Translit=クニ
3 を を ADP 助詞-格助詞 _ 2 case _ SpaceAfter=No|Translit=ヲ
4 治め 収める VERB 動詞-一般 _ 7 advcl _ SpaceAfter=No|Translit=オサメ
5 ん む AUX 助動詞 _ 4 aux _ SpaceAfter=No|Translit=ン
6 と と ADP 助詞-格助詞 _ 4 case _ SpaceAfter=No|Translit=ト
7 欲する 欲する VERB 動詞-一般 _ 8 acl _ SpaceAfter=No|Translit=ホッスル
8 者 者 NOUN 名詞-普通名詞-一般 _ 14 nsubj _ SpaceAfter=No|Translit=モノ
9 は は ADP 助詞-係助詞 _ 8 case _ SpaceAfter=No|Translit=ハ
10 先づ 先ず ADV 副詞 _ 14 advmod _ SpaceAfter=No|Translit=マヅ
11 其 其の DET 連体詞 _ 12 det _ SpaceAfter=No|Translit=ソノ
12 家 家 NOUN 名詞-普通名詞-一般 _ 14 obj _ SpaceAfter=No|Translit=ウチ
13 を を ADP 助詞-格助詞 _ 12 case _ SpaceAfter=No|Translit=ヲ
14 齊ふ 整える VERB 動詞-一般 _ 0 root _ SpaceAfter=No|Translit=トトノフ
>>> t=d[6]
>>> print(t.i+1,t.orth_,t.lemma_,t.pos_,t.tag_,t.head.i+1,t.dep_,t.whitespace_,t.norm_)
7 欲する 欲する VERB 動詞-一般 8 acl ホッスル
>>> from deplacy.deprelja import deprelja
>>> for b in unidic2ud.spacy.bunsetu_spans(d):
... for t in b.lefts:
... print(unidic2ud.spacy.bunsetu_span(t),"->",b,"("+deprelja[t.dep_]+")")
...
其 -> 國を (決定詞)
國を -> 治めんと (目的語)
治めんと -> 欲する (連用修飾節)
欲する -> 者は (連体修飾節)
其 -> 家を (決定詞)
者は -> 齊ふ (主語)
先づ -> 齊ふ (連用修飾語)
家を -> 齊ふ (目的語)
```
`unidic2ud.spacy.load(UniDic,parser)` loads a spaCy pipeline, which uses `UniDic` for tokenizer POS-tagger and lemmatizer (as shown above), then uses `parser` for dependency-parser. The default `parser` is `parser="japanese-modern"` and available options are:
* `parser="ja_core_news_sm"`: Use [spaCy Japanese model](https://spacy.io/models/ja) (small).
* `parser="ja_core_news_md"`: Use spaCy Japanese model (middle).
* `parser="ja_core_news_lg"`: Use spaCy Japanese model (large).
* `parser="ja_ginza"`: Use [GiNZA](https://github.com/megagonlabs/ginza).
* `parser="japanese-gsd"`: Use [UDPipe Japanese model](http://hdl.handle.net/11234/1-3131).
* `parser="stanza_ja"`: Use [Stanza Japanese model](https://stanfordnlp.github.io/stanza/available_models.html).
## Installation for Linux
Tar-ball is available for Linux, and is installed by default when you use `pip`:
```sh
pip install unidic2ud
```
By default installation, `UniDic` is invoked through Web APIs. If you want to invoke them locally and faster, you can download `UniDic` which you use just as follows:
```sh
python -m unidic2ud download kindai
python -m unidic2ud dictlist
```
Licenses of dictionaries and models are: GPL/LGPL/BSD for `gendai` and `spoken`; CC BY-NC-SA 4.0 for others.
## Installation for Cygwin
Make sure to get `gcc-g++` `python37-pip` `python37-devel` packages, and then:
```sh
pip3.7 install unidic2ud
```
Use `python3.7` command in [Cygwin](https://www.cygwin.com/install.html) instead of `python`.
## Installation for Jupyter Notebook (Google Colaboratory)
```py
!pip install unidic2ud
```
## Benchmarks
Results of [舞姬/雪國/荒野より-Benchmarks](https://colab.research.google.com/github/KoichiYasuoka/UniDic2UD/blob/master/benchmark/benchmark.ipynb)
|[舞姬](https://github.com/KoichiYasuoka/UniDic2UD/blob/master/benchmark/maihime-benchmark.tar.gz)|LAS|MLAS|BLEX|
|---------------|-----|-----|-----|
|UniDic="kindai"|81.13|70.37|77.78|
|UniDic="qkana" |79.25|70.37|77.78|
|UniDic="kinsei"|72.22|60.71|64.29|
|[雪國](https://github.com/KoichiYasuoka/UniDic2UD/blob/master/benchmark/yukiguni-benchmark.tar.gz)|LAS|MLAS|BLEX|
|---------------|-----|-----|-----|
|UniDic="qkana" |89.29|85.71|81.63|
|UniDic="kinsei"|89.29|85.71|77.55|
|UniDic="kindai"|84.96|81.63|77.55|
|[荒野より](https://github.com/KoichiYasuoka/UniDic2UD/blob/master/benchmark/koyayori-benchmark.tar.gz)|LAS|MLAS|BLEX|
|---------------|-----|-----|-----|
|UniDic="kindai"|76.44|61.54|53.85|
|UniDic="qkana" |75.39|61.54|53.85|
|UniDic="kinsei"|71.88|58.97|51.28|
## Author
Koichi Yasuoka (安岡孝一)
## References
* 安岡孝一: [形態素解析部の付け替えによる近代日本語(旧字旧仮名)の係り受け解析](http://hdl.handle.net/2433/254677), 情報処理学会研究報告, Vol.2020-CH-124「人文科学とコンピュータ」, No.3 (2020年9月5日), pp.1-8.
* 安岡孝一: [漢日英Universal Dependencies平行コーパスとその差異](http://hdl.handle.net/2433/245218), 人文科学とコンピュータシンポジウム「じんもんこん2019」論文集 (2019年12月), pp.43-50.
Raw data
{
"_id": null,
"home_page": "https://github.com/KoichiYasuoka/UniDic2UD",
"name": "unidic2ud",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.6",
"maintainer_email": null,
"keywords": "unidic udpipe mecab nlp",
"author": "Koichi Yasuoka",
"author_email": "yasuoka@kanji.zinbun.kyoto-u.ac.jp",
"download_url": "https://files.pythonhosted.org/packages/35/29/521a8b83a86559333dfaf70bc81957a1e846e06f89971d83c3d18931fd27/unidic2ud-3.0.5.tar.gz",
"platform": null,
"description": "[](https://pypi.org/project/unidic2ud/)\n\n# UniDic2UD\n\nTokenizer, POS-tagger, lemmatizer, and dependency-parser for modern and contemporary Japanese, working on [Universal Dependencies](https://universaldependencies.org/format.html).\n\n## Basic usage\n\n```py\n>>> import unidic2ud\n>>> nlp=unidic2ud.load(\"kindai\")\n>>> s=nlp(\"\u5176\u570b\u3092\u6cbb\u3081\u3093\u3068\u6b32\u3059\u308b\u8005\u306f\u5148\u3065\u5176\u5bb6\u3092\u9f4a\u3075\")\n>>> print(s)\n# text = \u5176\u570b\u3092\u6cbb\u3081\u3093\u3068\u6b32\u3059\u308b\u8005\u306f\u5148\u3065\u5176\u5bb6\u3092\u9f4a\u3075\n1\t\u5176\t\u5176\u306e\tDET\t\u9023\u4f53\u8a5e\t_\t2\tdet\t_\tSpaceAfter=No|Translit=\u30bd\u30ce\n2\t\u570b\t\u56fd\tNOUN\t\u540d\u8a5e-\u666e\u901a\u540d\u8a5e-\u4e00\u822c\t_\t4\tobj\t_\tSpaceAfter=No|Translit=\u30af\u30cb\n3\t\u3092\t\u3092\tADP\t\u52a9\u8a5e-\u683c\u52a9\u8a5e\t_\t2\tcase\t_\tSpaceAfter=No|Translit=\u30f2\n4\t\u6cbb\u3081\t\u53ce\u3081\u308b\tVERB\t\u52d5\u8a5e-\u4e00\u822c\t_\t7\tadvcl\t_\tSpaceAfter=No|Translit=\u30aa\u30b5\u30e1\n5\t\u3093\t\u3080\tAUX\t\u52a9\u52d5\u8a5e\t_\t4\taux\t_\tSpaceAfter=No|Translit=\u30f3\n6\t\u3068\t\u3068\tADP\t\u52a9\u8a5e-\u683c\u52a9\u8a5e\t_\t4\tcase\t_\tSpaceAfter=No|Translit=\u30c8\n7\t\u6b32\u3059\u308b\t\u6b32\u3059\u308b\tVERB\t\u52d5\u8a5e-\u4e00\u822c\t_\t8\tacl\t_\tSpaceAfter=No|Translit=\u30db\u30c3\u30b9\u30eb\n8\t\u8005\t\u8005\tNOUN\t\u540d\u8a5e-\u666e\u901a\u540d\u8a5e-\u4e00\u822c\t_\t14\tnsubj\t_\tSpaceAfter=No|Translit=\u30e2\u30ce\n9\t\u306f\t\u306f\tADP\t\u52a9\u8a5e-\u4fc2\u52a9\u8a5e\t_\t8\tcase\t_\tSpaceAfter=No|Translit=\u30cf\n10\t\u5148\u3065\t\u5148\u305a\tADV\t\u526f\u8a5e\t_\t14\tadvmod\t_\tSpaceAfter=No|Translit=\u30de\u30c5\n11\t\u5176\t\u5176\u306e\tDET\t\u9023\u4f53\u8a5e\t_\t12\tdet\t_\tSpaceAfter=No|Translit=\u30bd\u30ce\n12\t\u5bb6\t\u5bb6\tNOUN\t\u540d\u8a5e-\u666e\u901a\u540d\u8a5e-\u4e00\u822c\t_\t14\tobj\t_\tSpaceAfter=No|Translit=\u30a6\u30c1\n13\t\u3092\t\u3092\tADP\t\u52a9\u8a5e-\u683c\u52a9\u8a5e\t_\t12\tcase\t_\tSpaceAfter=No|Translit=\u30f2\n14\t\u9f4a\u3075\t\u6574\u3048\u308b\tVERB\t\u52d5\u8a5e-\u4e00\u822c\t_\t0\troot\t_\tSpaceAfter=No|Translit=\u30c8\u30c8\u30ce\u30d5\n\n>>> t=s[7]\n>>> print(t.id,t.form,t.lemma,t.upos,t.xpos,t.feats,t.head.id,t.deprel,t.deps,t.misc)\n7 \u6b32\u3059\u308b \u6b32\u3059\u308b VERB \u52d5\u8a5e-\u4e00\u822c _ 8 acl _ SpaceAfter=No|Translit=\u30db\u30c3\u30b9\u30eb\n\n>>> print(s.to_tree())\n \u5176 <\u2550\u2550\u2557 det(\u6c7a\u5b9a\u8a5e)\n \u570b \u2550\u2557\u2550\u255d<\u2557 obj(\u76ee\u7684\u8a9e)\n \u3092 <\u255d \u2551 case(\u683c\u8868\u793a)\n \u6cbb\u3081 \u2550\u2557\u2550\u2557\u2550\u255d<\u2557 advcl(\u9023\u7528\u4fee\u98fe\u7bc0)\n \u3093 <\u255d \u2551 \u2551 aux(\u52d5\u8a5e\u88dc\u52a9\u6210\u5206)\n \u3068 <\u2550\u2550\u255d \u2551 case(\u683c\u8868\u793a)\n\u6b32\u3059\u308b \u2550\u2550\u2550\u2550\u2550\u2550\u2550\u255d<\u2557 acl(\u9023\u4f53\u4fee\u98fe\u7bc0)\n \u8005 \u2550\u2557\u2550\u2550\u2550\u2550\u2550\u2550\u2550\u255d<\u2557 nsubj(\u4e3b\u8a9e)\n \u306f <\u255d \u2551 case(\u683c\u8868\u793a)\n \u5148\u3065 <\u2550\u2550\u2550\u2550\u2550\u2550\u2557 \u2551 advmod(\u9023\u7528\u4fee\u98fe\u8a9e)\n \u5176 <\u2550\u2550\u2557 \u2551 \u2551 det(\u6c7a\u5b9a\u8a5e)\n \u5bb6 \u2550\u2557\u2550\u255d<\u2557 \u2551 \u2551 obj(\u76ee\u7684\u8a9e)\n \u3092 <\u255d \u2551 \u2551 \u2551 case(\u683c\u8868\u793a)\n \u9f4a\u3075 \u2550\u2550\u2550\u2550\u2550\u255d\u2550\u255d\u2550\u2550\u2550\u255d root(\u89aa)\n\n>>> f=open(\"trial.svg\",\"w\")\n>>> f.write(s.to_svg())\n>>> f.close()\n```\n\n\n`unidic2ud.load(UniDic,UDPipe)` loads a natural language processor pipeline, which uses `UniDic` for tokenizer POS-tagger and lemmatizer, then uses `UDPipe` for dependency-parser. The default `UDPipe` is `UDPipe=\"japanese-modern\"`. Available `UniDic` options are:\n\n* `UniDic=\"gendai\"`: Use [\u73fe\u4ee3\u66f8\u304d\u8a00\u8449UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_bccwj).\n* `UniDic=\"spoken\"`: Use [\u73fe\u4ee3\u8a71\u3057\u8a00\u8449UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_csj).\n* `UniDic=\"novel\"`: Use [\u8fd1\u73fe\u4ee3\u53e3\u8a9e\u5c0f\u8aacUniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_novel).\n* `UniDic=\"qkana\"`: Use [\u65e7\u4eee\u540d\u53e3\u8a9eUniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_qkana).\n* `UniDic=\"kindai\"`: Use [\u8fd1\u4ee3\u6587\u8a9eUniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_kindai).\n* `UniDic=\"kinsei\"`: Use [\u8fd1\u4e16\u6c5f\u6238\u53e3\u8a9eUniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_kinsei-edo).\n* `UniDic=\"kyogen\"`: Use [\u4e2d\u4e16\u53e3\u8a9eUniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_chusei-kougo).\n* `UniDic=\"wakan\"`: Use [\u4e2d\u4e16\u6587\u8a9eUniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_chusei-bungo).\n* `UniDic=\"wabun\"`: Use [\u4e2d\u53e4\u548c\u6587UniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_wabun).\n* `UniDic=\"manyo\"`: Use [\u4e0a\u4ee3\u8a9eUniDic](https://clrd.ninjal.ac.jp/unidic/download_all.html#unidic_jodai).\n* `UniDic=None`: Use `UDPipe` for tokenizer, POS-tagger, lemmatizer, and dependency-parser.\n\n`unidic2ud.UniDic2UDEntry.to_tree()` has an option `to_tree(BoxDrawingWidth=2)` for old terminals, whose Box Drawing characters are \"fullwidth\".\n\nYou can simply use `unidic2ud` on the command line:\n```sh\necho \u5176\u570b\u3092\u6cbb\u3081\u3093\u3068\u6b32\u3059\u308b\u8005\u306f\u5148\u3065\u5176\u5bb6\u3092\u9f4a\u3075 | unidic2ud -U kindai\n```\n\n## CaboCha emulator usage\n\n```py\n>>> import unidic2ud.cabocha as CaboCha\n>>> c=CaboCha.Parser(\"kindai\")\n>>> s=c.parse(\"\u5176\u570b\u3092\u6cbb\u3081\u3093\u3068\u6b32\u3059\u308b\u8005\u306f\u5148\u3065\u5176\u5bb6\u3092\u9f4a\u3075\")\n>>> print(s.toString(CaboCha.FORMAT_TREE_LATTICE))\n \u5176-D\n \u570b\u3092-D\n\u6cbb\u3081\u3093\u3068-D\n \u6b32\u3059\u308b-D\n \u8005\u306f-------D\n \u5148\u3065-----D\n \u5176-D |\n \u5bb6\u3092-D\n \u9f4a\u3075\nEOS\n* 0 1D 0/0 0.000000\n\u5176\t\u9023\u4f53\u8a5e,*,*,*,*,*,\u5176\u306e,\u30bd\u30ce,*,DET\tO\t1<-det-2\n* 1 2D 0/1 0.000000\n\u570b\t\u540d\u8a5e,\u666e\u901a\u540d\u8a5e,\u4e00\u822c,*,*,*,\u56fd,\u30af\u30cb,*,NOUN\tO\t2<-obj-4\n\u3092\t\u52a9\u8a5e,\u683c\u52a9\u8a5e,*,*,*,*,\u3092,\u30f2,*,ADP\tO\t3<-case-2\n* 2 3D 0/1 0.000000\n\u6cbb\u3081\t\u52d5\u8a5e,\u4e00\u822c,*,*,*,*,\u53ce\u3081\u308b,\u30aa\u30b5\u30e1,*,VERB\tO\t4<-advcl-7\n\u3093\t\u52a9\u52d5\u8a5e,*,*,*,*,*,\u3080,\u30f3,*,AUX\tO\t5<-aux-4\n\u3068\t\u52a9\u8a5e,\u683c\u52a9\u8a5e,*,*,*,*,\u3068,\u30c8,*,ADP\tO\t6<-case-4\n* 3 4D 0/0 0.000000\n\u6b32\u3059\u308b\t\u52d5\u8a5e,\u4e00\u822c,*,*,*,*,\u6b32\u3059\u308b,\u30db\u30c3\u30b9\u30eb,*,VERB\tO\t7<-acl-8\n* 4 8D 0/1 0.000000\n\u8005\t\u540d\u8a5e,\u666e\u901a\u540d\u8a5e,\u4e00\u822c,*,*,*,\u8005,\u30e2\u30ce,*,NOUN\tO\t8<-nsubj-14\n\u306f\t\u52a9\u8a5e,\u4fc2\u52a9\u8a5e,*,*,*,*,\u306f,\u30cf,*,ADP\tO\t9<-case-8\n* 5 8D 0/0 0.000000\n\u5148\u3065\t\u526f\u8a5e,*,*,*,*,*,\u5148\u305a,\u30de\u30c5,*,ADV\tO\t10<-advmod-14\n* 6 7D 0/0 0.000000\n\u5176\t\u9023\u4f53\u8a5e,*,*,*,*,*,\u5176\u306e,\u30bd\u30ce,*,DET\tO\t11<-det-12\n* 7 8D 0/1 0.000000\n\u5bb6\t\u540d\u8a5e,\u666e\u901a\u540d\u8a5e,\u4e00\u822c,*,*,*,\u5bb6,\u30a6\u30c1,*,NOUN\tO\t12<-obj-14\n\u3092\t\u52a9\u8a5e,\u683c\u52a9\u8a5e,*,*,*,*,\u3092,\u30f2,*,ADP\tO\t13<-case-12\n* 8 -1D 0/0 0.000000\n\u9f4a\u3075\t\u52d5\u8a5e,\u4e00\u822c,*,*,*,*,\u6574\u3048\u308b,\u30c8\u30c8\u30ce\u30d5,*,VERB\tO\t14<-root\nEOS\n>>> for c in [s.chunk(i) for i in range(s.chunk_size())]:\n... if c.link>=0:\n... print(c,\"->\",s.chunk(c.link))\n...\n\u5176 -> \u570b\u3092\n\u570b\u3092 -> \u6cbb\u3081\u3093\u3068\n\u6cbb\u3081\u3093\u3068 -> \u6b32\u3059\u308b\n\u6b32\u3059\u308b -> \u8005\u306f\n\u8005\u306f -> \u9f4a\u3075\n\u5148\u3065 -> \u9f4a\u3075\n\u5176 -> \u5bb6\u3092\n\u5bb6\u3092 -> \u9f4a\u3075\n```\n`CaboCha.Parser(UniDic)` is an alias for `unidic2ud.load(UniDic,UDPipe=\"japanese-modern\")`, and its default is `UniDic=None`. `CaboCha.Tree.toString(format)` has five available formats:\n* `CaboCha.FORMAT_TREE`: tree (numbered as 0)\n* `CaboCha.FORMAT_LATTICE`: lattice (numbered as 1)\n* `CaboCha.FORMAT_TREE_LATTICE`: tree + lattice (numbered as 2)\n* `CaboCha.FORMAT_XML`: XML (numbered as 3)\n* `CaboCha.FORMAT_CONLL`: Universal Dependencies CoNLL-U (numbered as 4)\n\nYou can simply use `udcabocha` on the command line:\n```sh\necho \u5176\u570b\u3092\u6cbb\u3081\u3093\u3068\u6b32\u3059\u308b\u8005\u306f\u5148\u3065\u5176\u5bb6\u3092\u9f4a\u3075 | udcabocha -U kindai -f 2\n```\n`-U UniDic` specifies `UniDic`. `-f format` specifies the output format in 0 to 4 above (default is `-f 0`) and in 5 to 8 below:\n* `-f 5`: `to_tree()`\n* `-f 6`: `to_tree(BoxDrawingWidth=2)`\n* `-f 7`: `to_svg()`\n* `-f 8`: [raw DOT](https://graphviz.readthedocs.io/en/stable/manual.html#using-raw-dot) graph through [Immediate Catena Analysis](https://koichiyasuoka.github.io/deplacy/#deplacydot)\n\n\n\nTry [notebook](https://colab.research.google.com/github/KoichiYasuoka/UniDic2UD/blob/master/udcabocha.ipynb) for Google Colaboratory.\n\n## Usage via spaCy\n\nIf you have already installed [spaCy](https://pypi.org/project/spacy/) 2.1.0 or later, you can use `UniDic` via spaCy Language pipeline.\n\n```py\n>>> import unidic2ud.spacy\n>>> nlp=unidic2ud.spacy.load(\"kindai\")\n>>> d=nlp(\"\u5176\u570b\u3092\u6cbb\u3081\u3093\u3068\u6b32\u3059\u308b\u8005\u306f\u5148\u3065\u5176\u5bb6\u3092\u9f4a\u3075\")\n>>> print(unidic2ud.spacy.to_conllu(d))\n# text = \u5176\u570b\u3092\u6cbb\u3081\u3093\u3068\u6b32\u3059\u308b\u8005\u306f\u5148\u3065\u5176\u5bb6\u3092\u9f4a\u3075\n1\t\u5176\t\u5176\u306e\tDET\t\u9023\u4f53\u8a5e\t_\t2\tdet\t_\tSpaceAfter=No|Translit=\u30bd\u30ce\n2\t\u570b\t\u56fd\tNOUN\t\u540d\u8a5e-\u666e\u901a\u540d\u8a5e-\u4e00\u822c\t_\t4\tobj\t_\tSpaceAfter=No|Translit=\u30af\u30cb\n3\t\u3092\t\u3092\tADP\t\u52a9\u8a5e-\u683c\u52a9\u8a5e\t_\t2\tcase\t_\tSpaceAfter=No|Translit=\u30f2\n4\t\u6cbb\u3081\t\u53ce\u3081\u308b\tVERB\t\u52d5\u8a5e-\u4e00\u822c\t_\t7\tadvcl\t_\tSpaceAfter=No|Translit=\u30aa\u30b5\u30e1\n5\t\u3093\t\u3080\tAUX\t\u52a9\u52d5\u8a5e\t_\t4\taux\t_\tSpaceAfter=No|Translit=\u30f3\n6\t\u3068\t\u3068\tADP\t\u52a9\u8a5e-\u683c\u52a9\u8a5e\t_\t4\tcase\t_\tSpaceAfter=No|Translit=\u30c8\n7\t\u6b32\u3059\u308b\t\u6b32\u3059\u308b\tVERB\t\u52d5\u8a5e-\u4e00\u822c\t_\t8\tacl\t_\tSpaceAfter=No|Translit=\u30db\u30c3\u30b9\u30eb\n8\t\u8005\t\u8005\tNOUN\t\u540d\u8a5e-\u666e\u901a\u540d\u8a5e-\u4e00\u822c\t_\t14\tnsubj\t_\tSpaceAfter=No|Translit=\u30e2\u30ce\n9\t\u306f\t\u306f\tADP\t\u52a9\u8a5e-\u4fc2\u52a9\u8a5e\t_\t8\tcase\t_\tSpaceAfter=No|Translit=\u30cf\n10\t\u5148\u3065\t\u5148\u305a\tADV\t\u526f\u8a5e\t_\t14\tadvmod\t_\tSpaceAfter=No|Translit=\u30de\u30c5\n11\t\u5176\t\u5176\u306e\tDET\t\u9023\u4f53\u8a5e\t_\t12\tdet\t_\tSpaceAfter=No|Translit=\u30bd\u30ce\n12\t\u5bb6\t\u5bb6\tNOUN\t\u540d\u8a5e-\u666e\u901a\u540d\u8a5e-\u4e00\u822c\t_\t14\tobj\t_\tSpaceAfter=No|Translit=\u30a6\u30c1\n13\t\u3092\t\u3092\tADP\t\u52a9\u8a5e-\u683c\u52a9\u8a5e\t_\t12\tcase\t_\tSpaceAfter=No|Translit=\u30f2\n14\t\u9f4a\u3075\t\u6574\u3048\u308b\tVERB\t\u52d5\u8a5e-\u4e00\u822c\t_\t0\troot\t_\tSpaceAfter=No|Translit=\u30c8\u30c8\u30ce\u30d5\n\n>>> t=d[6]\n>>> print(t.i+1,t.orth_,t.lemma_,t.pos_,t.tag_,t.head.i+1,t.dep_,t.whitespace_,t.norm_)\n7 \u6b32\u3059\u308b \u6b32\u3059\u308b VERB \u52d5\u8a5e-\u4e00\u822c 8 acl \u30db\u30c3\u30b9\u30eb\n\n>>> from deplacy.deprelja import deprelja\n>>> for b in unidic2ud.spacy.bunsetu_spans(d):\n... for t in b.lefts:\n... print(unidic2ud.spacy.bunsetu_span(t),\"->\",b,\"(\"+deprelja[t.dep_]+\")\")\n...\n\u5176 -> \u570b\u3092 (\u6c7a\u5b9a\u8a5e)\n\u570b\u3092 -> \u6cbb\u3081\u3093\u3068 (\u76ee\u7684\u8a9e)\n\u6cbb\u3081\u3093\u3068 -> \u6b32\u3059\u308b (\u9023\u7528\u4fee\u98fe\u7bc0)\n\u6b32\u3059\u308b -> \u8005\u306f (\u9023\u4f53\u4fee\u98fe\u7bc0)\n\u5176 -> \u5bb6\u3092 (\u6c7a\u5b9a\u8a5e)\n\u8005\u306f -> \u9f4a\u3075 (\u4e3b\u8a9e)\n\u5148\u3065 -> \u9f4a\u3075 (\u9023\u7528\u4fee\u98fe\u8a9e)\n\u5bb6\u3092 -> \u9f4a\u3075 (\u76ee\u7684\u8a9e)\n```\n\n`unidic2ud.spacy.load(UniDic,parser)` loads a spaCy pipeline, which uses `UniDic` for tokenizer POS-tagger and lemmatizer (as shown above), then uses `parser` for dependency-parser. The default `parser` is `parser=\"japanese-modern\"` and available options are:\n\n* `parser=\"ja_core_news_sm\"`: Use [spaCy Japanese model](https://spacy.io/models/ja) (small).\n* `parser=\"ja_core_news_md\"`: Use spaCy Japanese model (middle).\n* `parser=\"ja_core_news_lg\"`: Use spaCy Japanese model (large).\n* `parser=\"ja_ginza\"`: Use [GiNZA](https://github.com/megagonlabs/ginza).\n* `parser=\"japanese-gsd\"`: Use [UDPipe Japanese model](http://hdl.handle.net/11234/1-3131).\n* `parser=\"stanza_ja\"`: Use [Stanza Japanese model](https://stanfordnlp.github.io/stanza/available_models.html).\n\n## Installation for Linux\n\nTar-ball is available for Linux, and is installed by default when you use `pip`:\n```sh\npip install unidic2ud\n```\n\nBy default installation, `UniDic` is invoked through Web APIs. If you want to invoke them locally and faster, you can download `UniDic` which you use just as follows:\n```sh\npython -m unidic2ud download kindai\npython -m unidic2ud dictlist\n```\nLicenses of dictionaries and models are: GPL/LGPL/BSD for `gendai` and `spoken`; CC BY-NC-SA 4.0 for others.\n\n## Installation for Cygwin\n\nMake sure to get `gcc-g++` `python37-pip` `python37-devel` packages, and then:\n```sh\npip3.7 install unidic2ud\n```\nUse `python3.7` command in [Cygwin](https://www.cygwin.com/install.html) instead of `python`.\n\n## Installation for Jupyter Notebook (Google Colaboratory)\n\n```py\n!pip install unidic2ud\n```\n## Benchmarks\n\nResults of [\u821e\u59ec/\u96ea\u570b/\u8352\u91ce\u3088\u308a-Benchmarks](https://colab.research.google.com/github/KoichiYasuoka/UniDic2UD/blob/master/benchmark/benchmark.ipynb)\n\n|[\u821e\u59ec](https://github.com/KoichiYasuoka/UniDic2UD/blob/master/benchmark/maihime-benchmark.tar.gz)|LAS|MLAS|BLEX|\n|---------------|-----|-----|-----|\n|UniDic=\"kindai\"|81.13|70.37|77.78|\n|UniDic=\"qkana\" |79.25|70.37|77.78|\n|UniDic=\"kinsei\"|72.22|60.71|64.29|\n\n|[\u96ea\u570b](https://github.com/KoichiYasuoka/UniDic2UD/blob/master/benchmark/yukiguni-benchmark.tar.gz)|LAS|MLAS|BLEX|\n|---------------|-----|-----|-----|\n|UniDic=\"qkana\" |89.29|85.71|81.63|\n|UniDic=\"kinsei\"|89.29|85.71|77.55|\n|UniDic=\"kindai\"|84.96|81.63|77.55|\n\n|[\u8352\u91ce\u3088\u308a](https://github.com/KoichiYasuoka/UniDic2UD/blob/master/benchmark/koyayori-benchmark.tar.gz)|LAS|MLAS|BLEX|\n|---------------|-----|-----|-----|\n|UniDic=\"kindai\"|76.44|61.54|53.85|\n|UniDic=\"qkana\" |75.39|61.54|53.85|\n|UniDic=\"kinsei\"|71.88|58.97|51.28|\n\n## Author\n\nKoichi Yasuoka (\u5b89\u5ca1\u5b5d\u4e00)\n\n## References\n\n* \u5b89\u5ca1\u5b5d\u4e00: [\u5f62\u614b\u7d20\u89e3\u6790\u90e8\u306e\u4ed8\u3051\u66ff\u3048\u306b\u3088\u308b\u8fd1\u4ee3\u65e5\u672c\u8a9e(\u65e7\u5b57\u65e7\u4eee\u540d)\u306e\u4fc2\u308a\u53d7\u3051\u89e3\u6790](http://hdl.handle.net/2433/254677), \u60c5\u5831\u51e6\u7406\u5b66\u4f1a\u7814\u7a76\u5831\u544a, Vol.2020-CH-124\u300c\u4eba\u6587\u79d1\u5b66\u3068\u30b3\u30f3\u30d4\u30e5\u30fc\u30bf\u300d, No.3 (2020\u5e749\u67085\u65e5), pp.1-8.\n* \u5b89\u5ca1\u5b5d\u4e00: [\u6f22\u65e5\u82f1Universal Dependencies\u5e73\u884c\u30b3\u30fc\u30d1\u30b9\u3068\u305d\u306e\u5dee\u7570](http://hdl.handle.net/2433/245218), \u4eba\u6587\u79d1\u5b66\u3068\u30b3\u30f3\u30d4\u30e5\u30fc\u30bf\u30b7\u30f3\u30dd\u30b8\u30a6\u30e0\u300c\u3058\u3093\u3082\u3093\u3053\u30932019\u300d\u8ad6\u6587\u96c6 (2019\u5e7412\u6708), pp.43-50.\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "Tokenizer POS-tagger Lemmatizer and Dependency-parser for modern and contemporary Japanese",
"version": "3.0.5",
"project_urls": {
"Homepage": "https://github.com/KoichiYasuoka/UniDic2UD",
"Source": "https://github.com/KoichiYasuoka/UniDic2UD",
"Tracker": "https://github.com/KoichiYasuoka/UniDic2UD/issues",
"japanese-modern": "https://github.com/UniversalDependencies/UD_Japanese-Modern",
"ud-ja-kanbun": "https://corpus.kanji.zinbun.kyoto-u.ac.jp/gitlab/Kanbun/ud-ja-kanbun"
},
"split_keywords": [
"unidic",
"udpipe",
"mecab",
"nlp"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "3529521a8b83a86559333dfaf70bc81957a1e846e06f89971d83c3d18931fd27",
"md5": "d1f3048fea799768f67051f88ecd95b2",
"sha256": "78200492dd7a4e4b0be6eb9bcc07c792706debeafd95284a51b53b2cd1c0d367"
},
"downloads": -1,
"filename": "unidic2ud-3.0.5.tar.gz",
"has_sig": false,
"md5_digest": "d1f3048fea799768f67051f88ecd95b2",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.6",
"size": 10066540,
"upload_time": "2024-10-30T03:12:13",
"upload_time_iso_8601": "2024-10-30T03:12:13.390394Z",
"url": "https://files.pythonhosted.org/packages/35/29/521a8b83a86559333dfaf70bc81957a1e846e06f89971d83c3d18931fd27/unidic2ud-3.0.5.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-10-30 03:12:13",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "KoichiYasuoka",
"github_project": "UniDic2UD",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "unidic2ud"
}

