| Name | unifair JSON |
| Version |
0.1.0
 JSON
JSON |
| download |
| home_page | |
| Summary | |
| upload_time | 2022-12-09 11:56:33 |
| maintainer | |
| docs_url | None |
| author | Sveinung Gundersen |
| requires_python | >=3.10,<4.0 |
| license | |
| keywords |
|
| VCS |
|
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# uniFAIR
(NOTE: Read the section [Transformation on the FAIRtracks.net website](https://fairtracks.net/fair/#fair-07-transformation)
for a more detailed and better formatted version of the following description!)
## Generic functionality
uniFAIR is designed primarily to simplify development and deployment of (meta)data transformation
processes in the context of FAIRification and data brokering efforts. However, the functionality is
very generic and can also be used to support research data (and metadata) transformations in a range
of fields and contexts beyond life science, including day-to-day research scenarios:

**Data wrangling in day-to-day research:** Researchers in life science and other data-centric fields
often need to extract, manipulate and integrate data and/or metadata from different sources, such as
repositories, databases or flat files. Much research time is spent on trivial and not-so-trivial
details of such ["data wrangling"](https://en.wikipedia.org/wiki/Data_wrangling):
- reformat data structures
- clean up errors
- remove duplicate data
- map and integrate dataset fields
- etc.
General software for data wrangling and analysis, such as [Pandas](https://pandas.pydata.org/),
[R](https://www.r-project.org/) or [Frictionless](https://frictionlessdata.io/), are useful, but
researchers still regularly end up with hard-to-reuse scripts, often with manual steps.
**Step-wise data model transformations:** With the uniFAIR
Python package, researchers can import (meta)data in almost any shape or form: _nested JSON; tabular
(relational) data; binary streams; or other data structures_. Through a step-by-step process, data
is continuously parsed and reshaped according to a series of data model transformations.
<ui-quote-text quote='uniFAIR tasks (single steps) and flows (workflows) are defined as transformations from specific input data models to specific output data models.'>
</ui-quote-text>
**"Parse, don't validate":** uniFAIR follows the principles of "Type-driven design" (read
_Technical note #2: "Parse, don't validate"_ on the
[FAIRtracks.net website](https://fairtracks.net/fair/#fair-07-transformation) for more info). It
makes use of cutting-edge [Python type hints](https://peps.python.org/pep-0484/) and the popular
[pydantic](https://pydantic-docs.helpmanual.io/) package to "pour" data into precisely defined data
models that can range from very general (e.g. _"any kind of JSON data", "any kind of tabular data"_,
etc.) to very specific (e.g. _"follow the FAIRtracks JSON Schema for track files with the extra
restriction of only allowing BigBED files"_).
**Data types as contracts:** uniFAIR _tasks_ (single steps) or _flows_ (workflows) are defined as
transformations from specific _input_ data models to specific _output_ data models.
[pydantic](https://pydantic-docs.helpmanual.io/)-based parsing guarantees that the input and output
data always follows the data models (i.e. data types). Thus, the data models defines "contracts"
that simplifies reuse of tasks and flows in a _mix-and-match_ fashion.
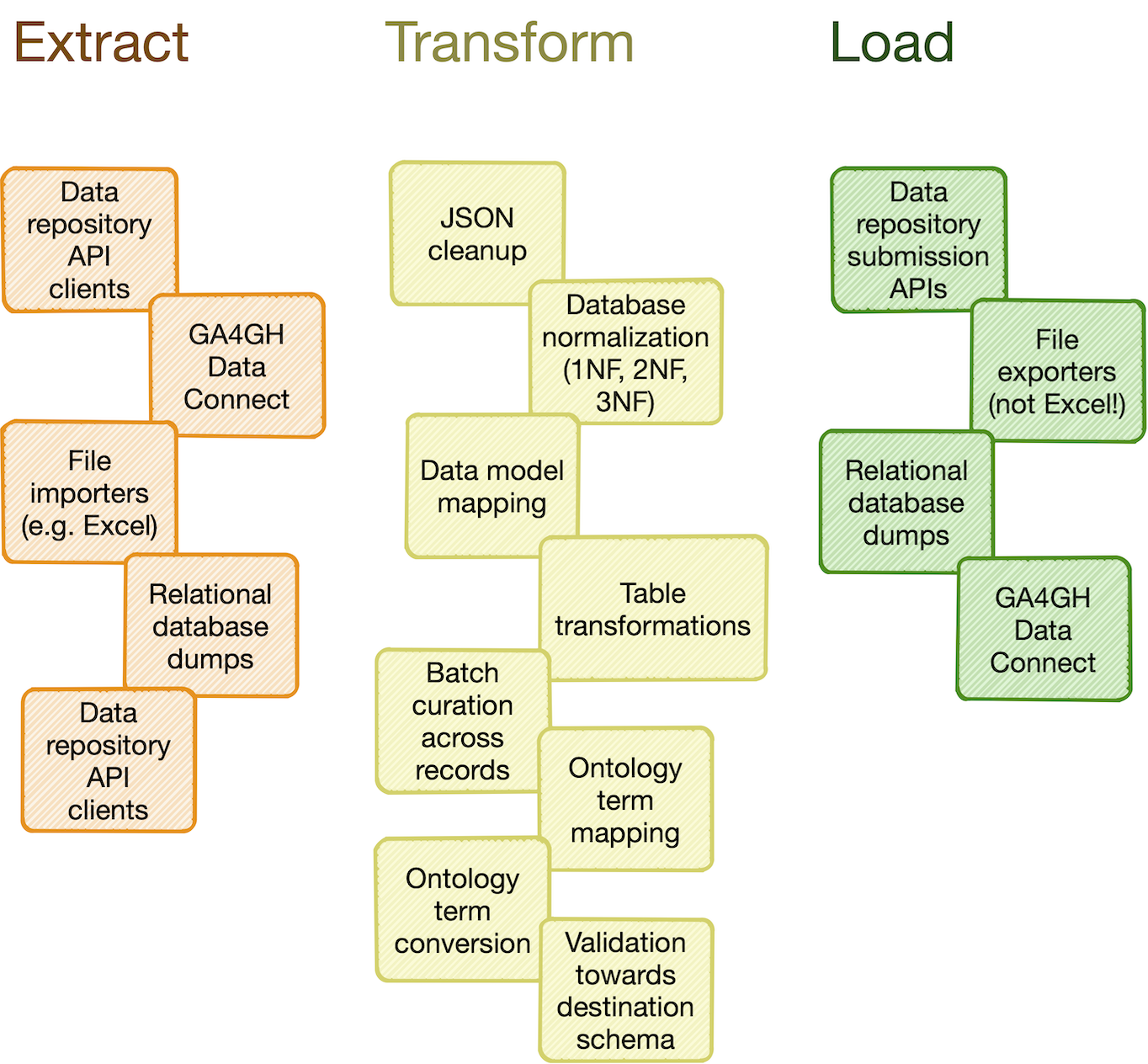
**Catalog of common processing steps:** uniFAIR is built from the ground up to be modular. We aim
to provide a catalog of commonly useful functionality ranging from:
- data import from REST API endpoints, common flat file formats, database dumps, etc.
- flattening of complex, nested JSON structures
- standardization of relational tabular data (i.e. removing redundancy)
- mapping of tabular data between schemas
- lookup and mapping of ontology terms
- semi-automatic data cleaning (through e.g. [Open Refine](https://openrefine.org/))
- support for common data manipulation software and libraries, such as
[Pandas](https://pandas.pydata.org/), [R](https://www.r-project.org/),
[Frictionless](https://frictionlessdata.io/), etc.
In particular, we will provide a _FAIRtracks_ module that contains data models and processing steps
to transform metadata to follow the [FAIRtracks standard](/standards/#standards-01-fairtracks).
**Refine and apply templates:** A uniFAIR module typically consists of a set of generic _task_ and
_flow templates_ with related data models, (de)serializers, and utility functions. The user can then
pick task and flow templates from this extensible, modular catalog, further refine them in the
context of a custom, use case-specific flow, and apply them to the desired compute engine to carry
out the transformations needed to wrangle data into the required shape.
**Rerun only when needed:** When piecing together a custom flow in uniFAIR, the user has persistent
access to the state of the data at every step of the process. Persistent intermediate data allows
for caching of tasks based on the input data and parameters. Hence, if the input data and parameters
of a task does not change between runs, the task is not rerun. This is particularly useful for
importing from REST API endpoints, as a flow can be continuously rerun without taxing the remote
server; data import will only carried out in the initial iteration or when the REST API signals that
the data has changed.
**Scale up with external compute resources:** In the case of large datasets, the researcher can set
up a flow based on a representative sample of the full dataset, in a size that is suited for running
locally on, say, a laptop. Once the flow has produced the correct output on the sample data, the
operation can be seamlessly scaled up to the full dataset and sent off in
[software containers](https://www.docker.com/resources/what-container/) to run on external compute
resources, using e.g. [Kubernetes](https://kubernetes.io/). Such offloaded flows
can be easily monitored using a web GUI.

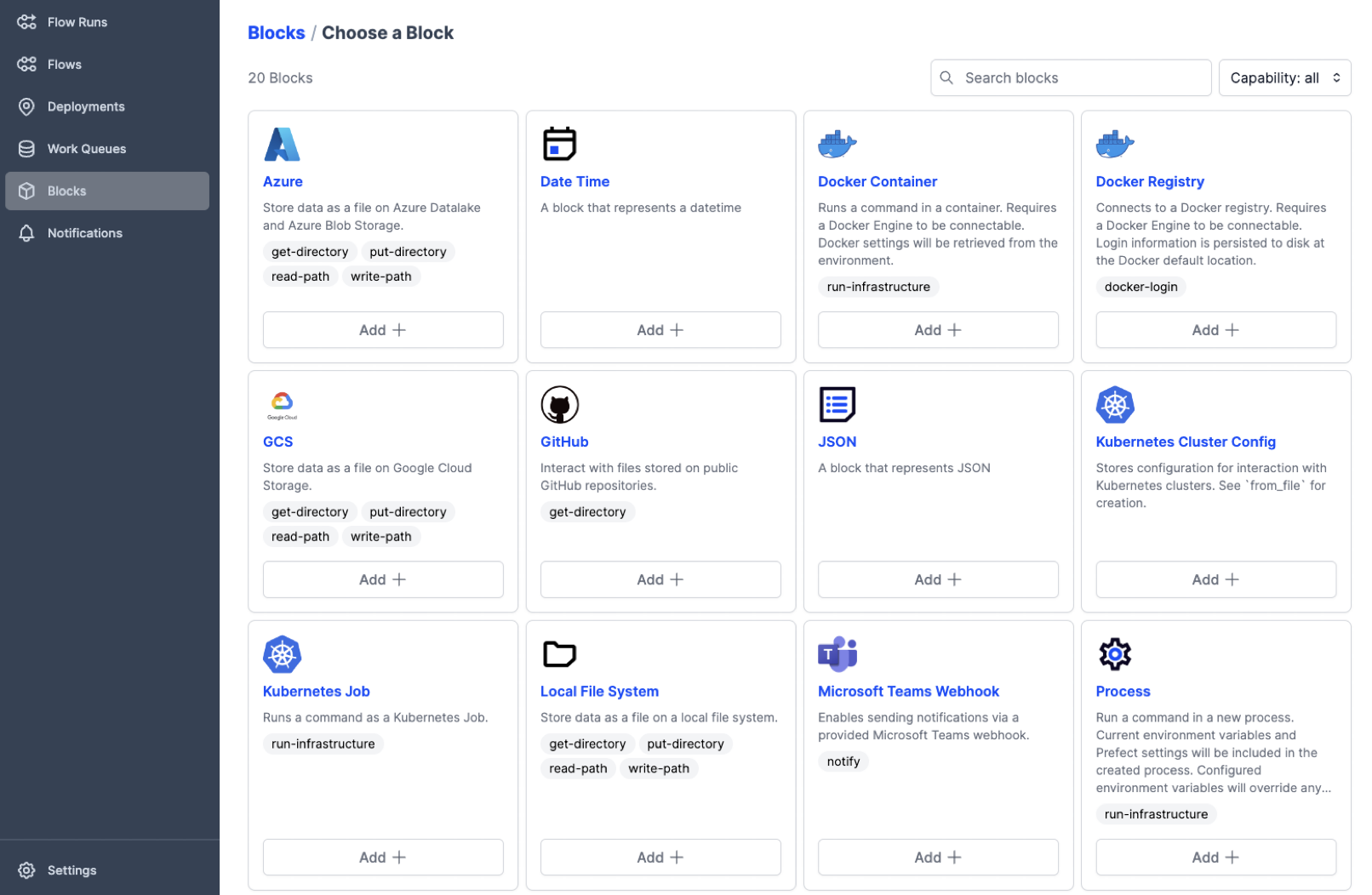
**Industry-standard ETL backbone:** Offloading of flows to external compute resources is provided by
the integration of uniFAIR with a workflow engine based on the [Prefect](https://www.prefect.io/)
Python package. Prefect is an industry-leading platform for dataflow automation and orchestration
that brings a [series of powerful features](https://www.prefect.io/opensource/) to uniFAIR:
- Predefined integrations with a range of compute infrastructure solutions
- Predefined integration with various services to support extraction, transformation, and loading
(ETL) of data and metadata
- Code as workflow ("If Python can write it, Prefect can run it")
- Dynamic workflows: no predefined Direct Acyclic Graphs (DAGs) needed!
- Command line and web GUI-based visibility and control of jobs
- Trigger jobs from external events such as GitHub commits, file uploads, etc.
- Define continuously running workflows that still respond to external events
- Run tasks concurrently through support for asynchronous tasks
**Pluggable workflow engines:** It is also possible to integrate uniFAIR with other workflow
backends by implementing new workflow engine plugins. This is relatively easy to do, as the core
architecture of uniFAIR allows the user to easily switch the workflow engine at runtime. uniFAIR
supports both traditional DAG-based and the more _avant garde_ code-based definition of flows. Two
workflow engines are currently supported: _local_ and _prefect_.
## Scenarios
As initial use cases, we will consider the following two scenarios:
* Transforming ENCODE metadata into FAIRtracks format
* Transforming TCGA metadata into FAIRtracks format
## Nomenclature:
* uniFAIR is designed to work with content which could be classified both as data and metadata in their original context. For simplicity, we will refer to all such content as "data".
## Overview of the proposed FAIRification process:
* ### Step 1: Import data from original source:
* #### 1A: From API endpoints
* _Input:_ API endpoint producing JSON data
* _Output:_ JSON files (possibly with embedded JSON objects/lists [as strings])
* _Description:_ General interface to support various API endpoints. Import all data by crawling API endpoints providing JSON content
* _Generalizable:_ Partly (at least reuse of utility functions)
* _Manual/automatic:_ Automatic
* _Details:_
* GDC/TCGA substeps (implemented as Step objects with file input/output)
* 1A. Filtering step:
* Input: parameters defining how to filter, e.g.:
* For all endpoints (projects, cases, files, annotations), support:
* Filter on list of IDs
* Specific number of items
* All
* Example config:
* projects: 2 items
* cases: 2 items
* files: all
* annotations: all
* Define standard configurations, e.g.:
* Default: limited extraction (3 projects * 3 cases * 5 files? (+ annotations?))
* All TCGA
* List of projects
* Hierarchical for loop through endpoints to create filter definitions
* Output: Filter definitions as four files, e.g. as JSON,
as they should be input to the filter parameter to the API:
```
projects_filter.json:
{
"op": "in",
"content": {
"field": "project_id",
"value": ['TCGA_ABCD', 'TCGA_BCDE']
}
}
cases_filter.json:
{
"op": "in",
"content": {
"field": "case_id",
"value": ['1234556', '234567', '3456789', '4567890']
}
}
files_filter.json:
{
"op": "in",
"content": {
"field": "file_id",
"value": ['1234556', '234567', '3456789', '4567890']
}
}
annotations.json
{
"op": "in",
"content": {
"field": "annotation_id",
"value": ['1234556', '234567', '3456789', '4567890']
}
}
```
* 1B. Fetch and divide all fields step:
* Input: None
* Output: JSON files specifying all the fields of an endpoint fetched from the `mapping` API.
The fields should be divided into chunks of a size that is small enough for the endpoints to
handle. The JSON output should also specify the primary_key field, that needs to be added to
all the API calls in order for the results to be joinable.
Example JSON files:
```
projects_fields.json:
{
"primary_key": "project_id",
"fields_divided": [
["field_a", "field_b"],
["field_c.subfield_a", "field_c.subfield_b", "field_d"]
]
}
(...) # For all endpoints
```
* 1C. Download from all endpoints according to the filters and the field divisions.
If there is a limitation on the number of hits that the endpoint is able to return, divide into smaller
API calls for a certain number of hits and concatenate the results. Make sure that proper waiting time
(1 second?) is added between the calls (to not overload the endpoint).
* 1D. Extract identifiers from nested objects (when present) and insert into parents objects
* ENCODE:
* Identify where to start (Cart? Experiment?)
* To get all data for a table (double-check this): `https://www.encodeproject.org/experiments/@@listing?format=json&frame=object`
* Download all tables directly.
* #### 1b: From JSON files
* _Input:_ JSON content as files
* _Output:_ Pandas DataFrames (possibly with embedded JSON objects/lists)
* _Description:_ Import data from files. Requires specific parsers to be implemented.
* _Generalizable:_ Fully
* _Manual/automatic:_ Automatic
* #### 1c: From non-JSON files
* _Input:_ File content in some supported format (e.g. GSuite)
* _Output:_ Pandas DataFrames (possibly containing lists of identifiers as Pandas Series) + reference metadata
* _Description:_ Import data from files. Requires specific parsers to be implemented.
* _Generalizable:_ Partly (generating reference metadata might be tricky)
* _Manual/automatic:_ Automatic
* #### 1d: From database
* _Input:_ Direct access to relational database
* _Output:_ Pandas DataFrames (possibly containing lists of identifiers as Pandas Series) + reference metadata
* _Description:_ Import data from database
* _Generalizable:_ Fully
* _Manual/automatic:_ Automatic
* ### Step 2: JSON cleanup
* _Input:_ Pandas DataFrames (possibly with embedded JSON objects/lists)
* _Output:_ Pandas DataFrames (possibly containing lists of identifiers as Pandas Series) + reference metadata
* _Description:_ Replace embedded objects with identifiers (possibly as lists)
* _Generalizable:_ Partly (generating reference metadata might be tricky)
* _Manual/automatic:_ Depending on original input
* _Details:_
* If there are embedded objects from other tables:
* ENCODE update:
* By using the `frame=object` parameter, we will not get any embedded objects from the APIs for the main tables. There is, however, some "auditing" fields that contain JSON objects. We can ignore these in the first iteration.
* If the original table of the embedded objects can be retrieved directly from an API, replace such embedded objects with unique identifiers to the object in another table (maintaining a reference to the name of the table, if needed)
* Record the reference metadata `(table_from, attr_from) -> (table_to, attr_to)` for joins:
* Example: `(table: "experiment", column: "replicates") -> (table: "replicate", column: "@id")`
* If the original table of the embedded objects are not directly available from an API, one needs to fill out the other table with the content that is embedded in the current object, creating the table if needed.
* For all fields with identifiers that reference other tables:
* Record the reference metadata `(table_from, attr_from) -> (table_to, attr_to)` for joins.
* If the field contains a list of identifiers
* Convert into Pandas Series
* ### Step 3: Create reference tables to satisfy 1NF
* _Input:_ Pandas DataFrames (possibly containing lists of identifiers as Pandas Series) + reference metadata
* _Output:_ Pandas DataFrames (original tables without reference column) [1NF] + reference tables + reference metadata
* _Description:_ Move references into separate tables, transforming the tables in first normal form ([1NF](https://en.wikipedia.org/wiki/Database_normalization#Satisfying_1NF))
* _Generalizable:_ Fully
* _Manual/automatic:_ Automatic
* _Details:_
* For each reference pair:
* Create a reference table
* For each item in the "from"-reference column:
* Add new rows in the reference table for each "to"-identifier, using the same "from"-identifier
* Example: Table "experiment-replicate" with columns "experiment.@id", "replicate.@id"
* Delete the complete column from the original table
* ### Step 4: Satisfy 2NF
* _Input:_ Pandas DataFrames (original tables without reference column) [1NF] + reference tables
* _Output:_ Pandas DataFrames (original tables without reference column) [2NF] + reference tables
* _Description:_ Automatic transformation of original tables into second normal form ([2NF](https://en.wikipedia.org/wiki/Database_normalization#Satisfying_2NF)):
* _Generalizable:_ Fully (if not, we skip it)
* _Manual/automatic:_ Automatic
* _Details:_
* Use existing library.
* ### Step 5: Satisfy 3NF
* _Input:_ Pandas DataFrames (original tables without reference column) [2NF] + reference tables
* _Output:_ Pandas DataFrames (original tables without reference column) [3NF] + reference tables
* _Description:_ Automatic transformation of original tables into third normal form ([3NF](https://en.wikipedia.org/wiki/Database_normalization#Satisfying_3NF)):
* _Generalizable:_ Fully (if not, we skip it)
* _Manual/automatic:_ Automatic
* _Details:_
* Use existing library.
* ### Step 6: Create model map
* _Input:_ Pandas DataFrames (original tables without reference column) [Any NF] + reference tables + FAIRtracks JSON schemas
* _Output:_ Model map [some data structure (to be defined) mapping FAIRtracks objects and attributes to tables/columns in the original data]
* _Description:_ Manual mapping of FAIRtracks objects and attributes to corresponding tables and columns in the original data.
* _Generalizable:_ Fully
* _Manual/automatic:_ Manual
* Details:
* For each FAIRtracks object:
* Define a start table in the original data
* For each FAIRtracks attribute:
* Manually find the path (or paths) to the original table/column that this maps to
* _Example:_ `Experiments:organism (FAIRtracks) -> Experiments.Biosamples.Organism.scientific_name`
* ### Step 7: Apply model map to generate initial FAIRtracks tables
* _Input:_ Pandas DataFrames (original tables without reference column) [Any NF] + reference tables + Model map
* _Output:_ Pandas DataFrames (initial FAIRtracks tables, possibly with multimapped attributes)
* Example: `Experiment.target_from_origcolumn1` and `Experimentl.target_from_origcolumn2` contain content from two different attributes from the original data that both corresponds to `Experiment.target`
* _Description:_ Generate initial FAIRtracks tables by applying the model map, mapping FAIRtracks attributes with one or more attributes (columns) in the original table.
* _Generalizable:_ Fully
* _Manual/automatic:_ Automatic
* _Details:_
* For every FAIRtracks object:
* Create a new pandas DataFrame
* For every FAIRtracks attribute:
* From the model map, get the path to the corresponding original table/column, or a list of such paths in case of multimapping
* For each path:
* Automatically join tables to get primary keys and attribute value in the same table:
* _Example:_ `experiment-biosample JOIN biosample-organism JOIN organism` will create mapping table with two columns: `Experiments.local_id` and `Organism.scientific_name`
* Add column to FAIRtracks DataFrame
* In case of multimodeling, record the relation between FAIRtracks attribute and corresponding multimapped attributes, e.g. by generating unique attribute names for each path, such as `Experiment.target_from_origcolumn1` and `Experiment.target_from_origcolumn2`, which one can derive directly from the model map.
* ### Step 8: Harmonize multimapped attributes
* _Input:_ Pandas DataFrames (initial FAIRtracks tables, possibly with multimapped attributes) + model map
* _Output:_ Pandas DataFrames (initial FAIRtracks tables)
* _Description:_ Harmonize multimapped attributes manually, or possibly by applying scripts
* _Generalizable:_ Limited (mostly by reusing util functions)
* _Manual/automatic:_ Mixed (possibly scriptable)
* _Details:_
* For all multimapped attributes:
* Manually review values (in batch mode) and generate a single output value for each combination:
* Hopefully Open Refine can be used for this. If so, one needs to implement data input/output mechanisms.
* ### Further steps to be detailed:
* For all FAIRtracks attributes with ontology terms: Convert terms using required ontologies
* Other FAIRtracks specific value conversion
* Manual batch correction of values (possibly with errors), probably using Open Refine
* Validation of FAIRtracks document
Suggestion: we will use Pandas DataFrames as the core data structure for tables, given that the library provides the required features (specifically Foreign key and Join capabilities)
Raw data
{
"_id": null,
"home_page": "",
"name": "unifair",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.10,<4.0",
"maintainer_email": "",
"keywords": "",
"author": "Sveinung Gundersen",
"author_email": "sveinugu@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/07/e5/3f29fb1d9f4dc78717be96a47a8641f8678a9bd87477983b148481eab825/unifair-0.1.0.tar.gz",
"platform": null,
"description": "# uniFAIR\n\n(NOTE: Read the section [Transformation on the FAIRtracks.net website](https://fairtracks.net/fair/#fair-07-transformation)\nfor a more detailed and better formatted version of the following description!)\n\n## Generic functionality\n\nuniFAIR is designed primarily to simplify development and deployment of (meta)data transformation \nprocesses in the context of FAIRification and data brokering efforts. However, the functionality is \nvery generic and can also be used to support research data (and metadata) transformations in a range \nof fields and contexts beyond life science, including day-to-day research scenarios:\n\n\n\n**Data wrangling in day-to-day research:** Researchers in life science and other data-centric fields\noften need to extract, manipulate and integrate data and/or metadata from different sources, such as\nrepositories, databases or flat files. Much research time is spent on trivial and not-so-trivial\ndetails of such [\"data wrangling\"](https://en.wikipedia.org/wiki/Data_wrangling):\n\n- reformat data structures\n- clean up errors\n- remove duplicate data\n- map and integrate dataset fields\n- etc.\n\nGeneral software for data wrangling and analysis, such as [Pandas](https://pandas.pydata.org/),\n[R](https://www.r-project.org/) or [Frictionless](https://frictionlessdata.io/), are useful, but\nresearchers still regularly end up with hard-to-reuse scripts, often with manual steps.\n\n**Step-wise data model transformations:** With the uniFAIR\nPython package, researchers can import (meta)data in almost any shape or form: _nested JSON; tabular\n(relational) data; binary streams; or other data structures_. Through a step-by-step process, data\nis continuously parsed and reshaped according to a series of data model transformations.\n\n<ui-quote-text quote='uniFAIR tasks (single steps) and flows (workflows) are defined as transformations from specific input data models to specific output data models.'>\n</ui-quote-text>\n\n**\"Parse, don't validate\":** uniFAIR follows the principles of \"Type-driven design\" (read \n_Technical note #2: \"Parse, don't validate\"_ on the \n[FAIRtracks.net website](https://fairtracks.net/fair/#fair-07-transformation) for more info). It \nmakes use of cutting-edge [Python type hints](https://peps.python.org/pep-0484/) and the popular\n[pydantic](https://pydantic-docs.helpmanual.io/) package to \"pour\" data into precisely defined data\nmodels that can range from very general (e.g. _\"any kind of JSON data\", \"any kind of tabular data\"_,\netc.) to very specific (e.g. _\"follow the FAIRtracks JSON Schema for track files with the extra\nrestriction of only allowing BigBED files\"_).\n\n**Data types as contracts:** uniFAIR _tasks_ (single steps) or _flows_ (workflows) are defined as\ntransformations from specific _input_ data models to specific _output_ data models.\n[pydantic](https://pydantic-docs.helpmanual.io/)-based parsing guarantees that the input and output\ndata always follows the data models (i.e. data types). Thus, the data models defines \"contracts\"\nthat simplifies reuse of tasks and flows in a _mix-and-match_ fashion.\n\n**Catalog of common processing steps:** uniFAIR is built from the ground up to be modular. We aim \nto provide a catalog of commonly useful functionality ranging from:\n\n- data import from REST API endpoints, common flat file formats, database dumps, etc.\n- flattening of complex, nested JSON structures\n- standardization of relational tabular data (i.e. removing redundancy)\n- mapping of tabular data between schemas\n- lookup and mapping of ontology terms\n- semi-automatic data cleaning (through e.g. [Open Refine](https://openrefine.org/))\n- support for common data manipulation software and libraries, such as\n [Pandas](https://pandas.pydata.org/), [R](https://www.r-project.org/),\n [Frictionless](https://frictionlessdata.io/), etc.\n\nIn particular, we will provide a _FAIRtracks_ module that contains data models and processing steps\nto transform metadata to follow the [FAIRtracks standard](/standards/#standards-01-fairtracks).\n\n\n\n**Refine and apply templates:** A uniFAIR module typically consists of a set of generic _task_ and\n_flow templates_ with related data models, (de)serializers, and utility functions. The user can then\npick task and flow templates from this extensible, modular catalog, further refine them in the\ncontext of a custom, use case-specific flow, and apply them to the desired compute engine to carry\nout the transformations needed to wrangle data into the required shape.\n\n**Rerun only when needed:** When piecing together a custom flow in uniFAIR, the user has persistent\naccess to the state of the data at every step of the process. Persistent intermediate data allows\nfor caching of tasks based on the input data and parameters. Hence, if the input data and parameters\nof a task does not change between runs, the task is not rerun. This is particularly useful for\nimporting from REST API endpoints, as a flow can be continuously rerun without taxing the remote\nserver; data import will only carried out in the initial iteration or when the REST API signals that\nthe data has changed.\n\n**Scale up with external compute resources:** In the case of large datasets, the researcher can set\nup a flow based on a representative sample of the full dataset, in a size that is suited for running\nlocally on, say, a laptop. Once the flow has produced the correct output on the sample data, the\noperation can be seamlessly scaled up to the full dataset and sent off in\n[software containers](https://www.docker.com/resources/what-container/) to run on external compute\nresources, using e.g. [Kubernetes](https://kubernetes.io/). Such offloaded flows\ncan be easily monitored using a web GUI.\n\n\n\n**Industry-standard ETL backbone:** Offloading of flows to external compute resources is provided by\nthe integration of uniFAIR with a workflow engine based on the [Prefect](https://www.prefect.io/)\nPython package. Prefect is an industry-leading platform for dataflow automation and orchestration\nthat brings a [series of powerful features](https://www.prefect.io/opensource/) to uniFAIR:\n\n- Predefined integrations with a range of compute infrastructure solutions\n- Predefined integration with various services to support extraction, transformation, and loading\n (ETL) of data and metadata\n- Code as workflow (\"If Python can write it, Prefect can run it\")\n- Dynamic workflows: no predefined Direct Acyclic Graphs (DAGs) needed!\n- Command line and web GUI-based visibility and control of jobs\n- Trigger jobs from external events such as GitHub commits, file uploads, etc.\n- Define continuously running workflows that still respond to external events\n- Run tasks concurrently through support for asynchronous tasks\n\n\n\n**Pluggable workflow engines:** It is also possible to integrate uniFAIR with other workflow\nbackends by implementing new workflow engine plugins. This is relatively easy to do, as the core\narchitecture of uniFAIR allows the user to easily switch the workflow engine at runtime. uniFAIR\nsupports both traditional DAG-based and the more _avant garde_ code-based definition of flows. Two\nworkflow engines are currently supported: _local_ and _prefect_.\n\n## Scenarios\nAs initial use cases, we will consider the following two scenarios:\n* Transforming ENCODE metadata into FAIRtracks format\n* Transforming TCGA metadata into FAIRtracks format\n\n## Nomenclature:\n* uniFAIR is designed to work with content which could be classified both as data and metadata in their original context. For simplicity, we will refer to all such content as \"data\".\n\n## Overview of the proposed FAIRification process:\n\n* ### Step 1: Import data from original source:\n * #### 1A: From API endpoints\n * _Input:_ API endpoint producing JSON data\n * _Output:_ JSON files (possibly with embedded JSON objects/lists [as strings])\n * _Description:_ General interface to support various API endpoints. Import all data by crawling API endpoints providing JSON content\n * _Generalizable:_ Partly (at least reuse of utility functions)\n * _Manual/automatic:_ Automatic\n * _Details:_\n * GDC/TCGA substeps (implemented as Step objects with file input/output)\n * 1A. Filtering step:\n * Input: parameters defining how to filter, e.g.:\n * For all endpoints (projects, cases, files, annotations), support:\n * Filter on list of IDs\n * Specific number of items\n * All\n * Example config:\n * projects: 2 items\n * cases: 2 items\n * files: all\n * annotations: all\n * Define standard configurations, e.g.:\n * Default: limited extraction (3 projects * 3 cases * 5 files? (+ annotations?))\n * All TCGA\n * List of projects\n * Hierarchical for loop through endpoints to create filter definitions\n * Output: Filter definitions as four files, e.g. as JSON, \n as they should be input to the filter parameter to the API:\n ```\n projects_filter.json:\n {\n \"op\": \"in\",\n \"content\": {\n \"field\": \"project_id\",\n \"value\": ['TCGA_ABCD', 'TCGA_BCDE']\n }\n }\n \n cases_filter.json:\n {\n \"op\": \"in\",\n \"content\": {\n \"field\": \"case_id\",\n \"value\": ['1234556', '234567', '3456789', '4567890']\n }\n }\n \n files_filter.json:\n {\n \"op\": \"in\",\n \"content\": {\n \"field\": \"file_id\",\n \"value\": ['1234556', '234567', '3456789', '4567890']\n }\n }\n \n annotations.json\n {\n \"op\": \"in\",\n \"content\": {\n \"field\": \"annotation_id\",\n \"value\": ['1234556', '234567', '3456789', '4567890']\n }\n }\n ```\n \n * 1B. Fetch and divide all fields step:\n * Input: None\n * Output: JSON files specifying all the fields of an endpoint fetched from the `mapping` API. \n The fields should be divided into chunks of a size that is small enough for the endpoints to \n handle. The JSON output should also specify the primary_key field, that needs to be added to \n all the API calls in order for the results to be joinable.\n \n Example JSON files:\n ```\n projects_fields.json:\n {\n \"primary_key\": \"project_id\",\n \"fields_divided\": [\n [\"field_a\", \"field_b\"],\n [\"field_c.subfield_a\", \"field_c.subfield_b\", \"field_d\"] \n ]\n }\n \n (...) # For all endpoints\n ```\n * 1C. Download from all endpoints according to the filters and the field divisions.\n If there is a limitation on the number of hits that the endpoint is able to return, divide into smaller\n API calls for a certain number of hits and concatenate the results. Make sure that proper waiting time\n (1 second?) is added between the calls (to not overload the endpoint).\n * 1D. Extract identifiers from nested objects (when present) and insert into parents objects\n * ENCODE:\n * Identify where to start (Cart? Experiment?)\n * To get all data for a table (double-check this): `https://www.encodeproject.org/experiments/@@listing?format=json&frame=object`\n * Download all tables directly.\n * #### 1b: From JSON files\n * _Input:_ JSON content as files\n * _Output:_ Pandas DataFrames (possibly with embedded JSON objects/lists)\n * _Description:_ Import data from files. Requires specific parsers to be implemented.\n * _Generalizable:_ Fully\n * _Manual/automatic:_ Automatic\n * #### 1c: From non-JSON files\n * _Input:_ File content in some supported format (e.g. GSuite)\n * _Output:_ Pandas DataFrames (possibly containing lists of identifiers as Pandas Series) + reference metadata\n * _Description:_ Import data from files. Requires specific parsers to be implemented.\n * _Generalizable:_ Partly (generating reference metadata might be tricky)\n * _Manual/automatic:_ Automatic\n * #### 1d: From database\n * _Input:_ Direct access to relational database\n * _Output:_ Pandas DataFrames (possibly containing lists of identifiers as Pandas Series) + reference metadata\n * _Description:_ Import data from database\n * _Generalizable:_ Fully\n * _Manual/automatic:_ Automatic\n* ### Step 2: JSON cleanup\n * _Input:_ Pandas DataFrames (possibly with embedded JSON objects/lists)\n * _Output:_ Pandas DataFrames (possibly containing lists of identifiers as Pandas Series) + reference metadata\n * _Description:_ Replace embedded objects with identifiers (possibly as lists)\n * _Generalizable:_ Partly (generating reference metadata might be tricky)\n * _Manual/automatic:_ Depending on original input\n * _Details:_\n * If there are embedded objects from other tables:\n * ENCODE update: \n * By using the `frame=object` parameter, we will not get any embedded objects from the APIs for the main tables. There is, however, some \"auditing\" fields that contain JSON objects. We can ignore these in the first iteration.\n * If the original table of the embedded objects can be retrieved directly from an API, replace such embedded objects with unique identifiers to the object in another table (maintaining a reference to the name of the table, if needed)\n * Record the reference metadata `(table_from, attr_from) -> (table_to, attr_to)` for joins:\n * Example: `(table: \"experiment\", column: \"replicates\") -> (table: \"replicate\", column: \"@id\")`\n * If the original table of the embedded objects are not directly available from an API, one needs to fill out the other table with the content that is embedded in the current object, creating the table if needed.\n * For all fields with identifiers that reference other tables:\n * Record the reference metadata `(table_from, attr_from) -> (table_to, attr_to)` for joins.\n * If the field contains a list of identifiers\n * Convert into Pandas Series\n* ### Step 3: Create reference tables to satisfy 1NF\n * _Input:_ Pandas DataFrames (possibly containing lists of identifiers as Pandas Series) + reference metadata\n * _Output:_ Pandas DataFrames (original tables without reference column) [1NF] + reference tables + reference metadata\n * _Description:_ Move references into separate tables, transforming the tables in first normal form ([1NF](https://en.wikipedia.org/wiki/Database_normalization#Satisfying_1NF))\n * _Generalizable:_ Fully\n * _Manual/automatic:_ Automatic\n * _Details:_\n * For each reference pair: \n * Create a reference table\n * For each item in the \"from\"-reference column:\n * Add new rows in the reference table for each \"to\"-identifier, using the same \"from\"-identifier\n * Example: Table \"experiment-replicate\" with columns \"experiment.@id\", \"replicate.@id\"\n * Delete the complete column from the original table\n* ### Step 4: Satisfy 2NF\n * _Input:_ Pandas DataFrames (original tables without reference column) [1NF] + reference tables\n * _Output:_ Pandas DataFrames (original tables without reference column) [2NF] + reference tables\n * _Description:_ Automatic transformation of original tables into second normal form ([2NF](https://en.wikipedia.org/wiki/Database_normalization#Satisfying_2NF)):\n * _Generalizable:_ Fully (if not, we skip it)\n * _Manual/automatic:_ Automatic\n * _Details:_\n * Use existing library.\n* ### Step 5: Satisfy 3NF\n * _Input:_ Pandas DataFrames (original tables without reference column) [2NF] + reference tables\n * _Output:_ Pandas DataFrames (original tables without reference column) [3NF] + reference tables\n * _Description:_ Automatic transformation of original tables into third normal form ([3NF](https://en.wikipedia.org/wiki/Database_normalization#Satisfying_3NF)):\n * _Generalizable:_ Fully (if not, we skip it)\n * _Manual/automatic:_ Automatic\n * _Details:_\n * Use existing library.\n* ### Step 6: Create model map\n * _Input:_ Pandas DataFrames (original tables without reference column) [Any NF] + reference tables + FAIRtracks JSON schemas\n * _Output:_ Model map [some data structure (to be defined) mapping FAIRtracks objects and attributes to tables/columns in the original data]\n * _Description:_ Manual mapping of FAIRtracks objects and attributes to corresponding tables and columns in the original data.\n * _Generalizable:_ Fully\n * _Manual/automatic:_ Manual\n * Details:\n * For each FAIRtracks object:\n * Define a start table in the original data\n * For each FAIRtracks attribute:\n * Manually find the path (or paths) to the original table/column that this maps to\n * _Example:_ `Experiments:organism (FAIRtracks) -> Experiments.Biosamples.Organism.scientific_name`\n* ### Step 7: Apply model map to generate initial FAIRtracks tables\n * _Input:_ Pandas DataFrames (original tables without reference column) [Any NF] + reference tables + Model map \n * _Output:_ Pandas DataFrames (initial FAIRtracks tables, possibly with multimapped attributes)\n * Example: `Experiment.target_from_origcolumn1` and `Experimentl.target_from_origcolumn2` contain content from two different attributes from the original data that both corresponds to `Experiment.target`\n * _Description:_ Generate initial FAIRtracks tables by applying the model map, mapping FAIRtracks attributes with one or more attributes (columns) in the original table.\n * _Generalizable:_ Fully\n * _Manual/automatic:_ Automatic\n * _Details:_\n * For every FAIRtracks object:\n * Create a new pandas DataFrame\n * For every FAIRtracks attribute:\n * From the model map, get the path to the corresponding original table/column, or a list of such paths in case of multimapping\n * For each path:\n * Automatically join tables to get primary keys and attribute value in the same table:\n * _Example:_ `experiment-biosample JOIN biosample-organism JOIN organism` will create mapping table with two columns: `Experiments.local_id` and `Organism.scientific_name`\n * Add column to FAIRtracks DataFrame\n * In case of multimodeling, record the relation between FAIRtracks attribute and corresponding multimapped attributes, e.g. by generating unique attribute names for each path, such as `Experiment.target_from_origcolumn1` and `Experiment.target_from_origcolumn2`, which one can derive directly from the model map.\n* ### Step 8: Harmonize multimapped attributes\n * _Input:_ Pandas DataFrames (initial FAIRtracks tables, possibly with multimapped attributes) + model map\n * _Output:_ Pandas DataFrames (initial FAIRtracks tables)\n * _Description:_ Harmonize multimapped attributes manually, or possibly by applying scripts\n * _Generalizable:_ Limited (mostly by reusing util functions)\n * _Manual/automatic:_ Mixed (possibly scriptable)\n * _Details:_\n * For all multimapped attributes:\n * Manually review values (in batch mode) and generate a single output value for each combination:\n * Hopefully Open Refine can be used for this. If so, one needs to implement data input/output mechanisms.\n\n* ### Further steps to be detailed:\n * For all FAIRtracks attributes with ontology terms: Convert terms using required ontologies\n * Other FAIRtracks specific value conversion \n * Manual batch correction of values (possibly with errors), probably using Open Refine\n * Validation of FAIRtracks document\n\nSuggestion: we will use Pandas DataFrames as the core data structure for tables, given that the library provides the required features (specifically Foreign key and Join capabilities)\n\n\n",
"bugtrack_url": null,
"license": "",
"summary": "",
"version": "0.1.0",
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"md5": "9f92a64afea614ee272fef38ee2037c2",
"sha256": "0baa44187805e4c41a10f3b6d6e1e3ea923964fc587c1e8f89832f1819f24237"
},
"downloads": -1,
"filename": "unifair-0.1.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "9f92a64afea614ee272fef38ee2037c2",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.10,<4.0",
"size": 52450,
"upload_time": "2022-12-09T11:56:31",
"upload_time_iso_8601": "2022-12-09T11:56:31.957549Z",
"url": "https://files.pythonhosted.org/packages/cd/49/bb6f7b7992f2f340cce37ec961a62ea63e3001be0ea075b4e264c26d34a6/unifair-0.1.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"md5": "cce37101e85dede5b1dc65a490879e2c",
"sha256": "b534b064f8ebe479a141748dc87a79e37714c874600d706dbe9b7a9567606b00"
},
"downloads": -1,
"filename": "unifair-0.1.0.tar.gz",
"has_sig": false,
"md5_digest": "cce37101e85dede5b1dc65a490879e2c",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.10,<4.0",
"size": 104617,
"upload_time": "2022-12-09T11:56:33",
"upload_time_iso_8601": "2022-12-09T11:56:33.540834Z",
"url": "https://files.pythonhosted.org/packages/07/e5/3f29fb1d9f4dc78717be96a47a8641f8678a9bd87477983b148481eab825/unifair-0.1.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2022-12-09 11:56:33",
"github": false,
"gitlab": false,
"bitbucket": false,
"lcname": "unifair"
}
