| Name | vaex JSON |
| Version |
4.17.0
 JSON
JSON |
| download |
| home_page | https://www.github.com/vaexio/vaex |
| Summary | Out-of-Core DataFrames to visualize and explore big tabular datasets |
| upload_time | 2023-07-21 10:41:32 |
| maintainer | |
| docs_url | https://pythonhosted.org/vaex/ |
| author | Maarten A. Breddels |
| requires_python | |
| license | MIT |
| keywords |
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |

|
| coveralls test coverage |
No coveralls.
|
[](https://pypi.org/project/vaex-core/)
[](https://docs.vaex.io)
[](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ)
# What is Vaex?
Vaex is a high performance Python library for lazy **Out-of-Core DataFrames**
(similar to Pandas), to visualize and explore big tabular datasets. It
calculates *statistics* such as mean, sum, count, standard deviation etc, on an
*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per
second**. Visualization is done using **histograms**, **density plots** and **3d
volume rendering**, allowing interactive exploration of big data. Vaex uses
memory mapping, zero memory copy policy and lazy computations for best
performance (no memory wasted).
# Installing
With pip:
```
$ pip install vaex
```
Or conda:
```
$ conda install -c conda-forge vaex
```
[For more details, see the documentation](https://docs.vaex.io/en/latest/installing.html)
# Key features
## Instant opening of Huge data files (memory mapping)
[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported.

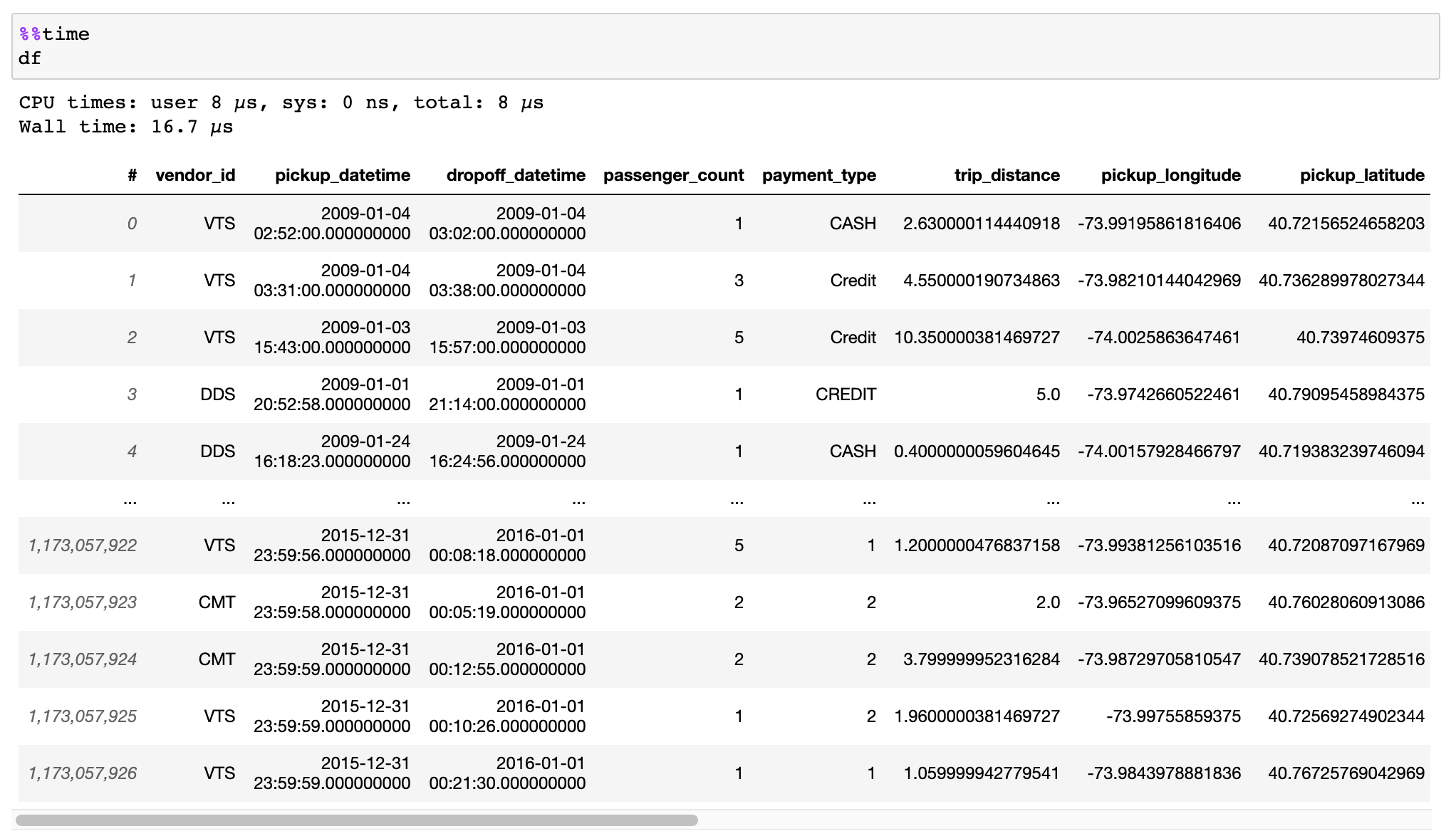
[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources.
Lazy streaming from S3 supported in combination with memory mapping.

## Expression system
Don't waste memory or time with feature engineering, we (lazily) transform your data when needed.
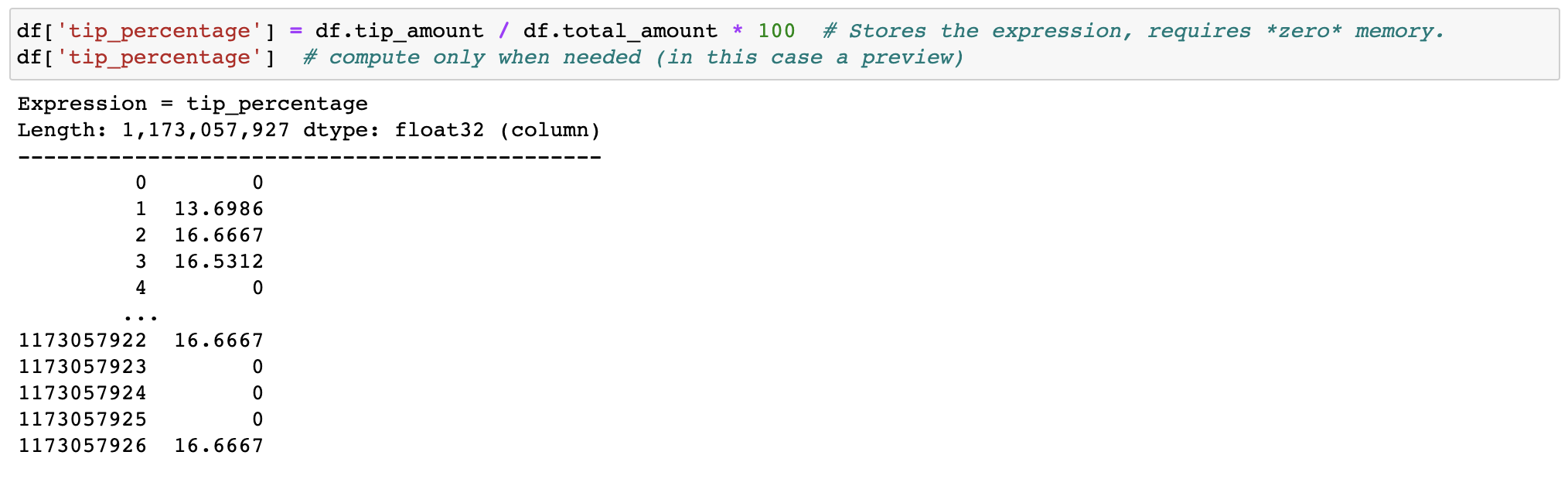
## Out-of-core DataFrame
Filtering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster.

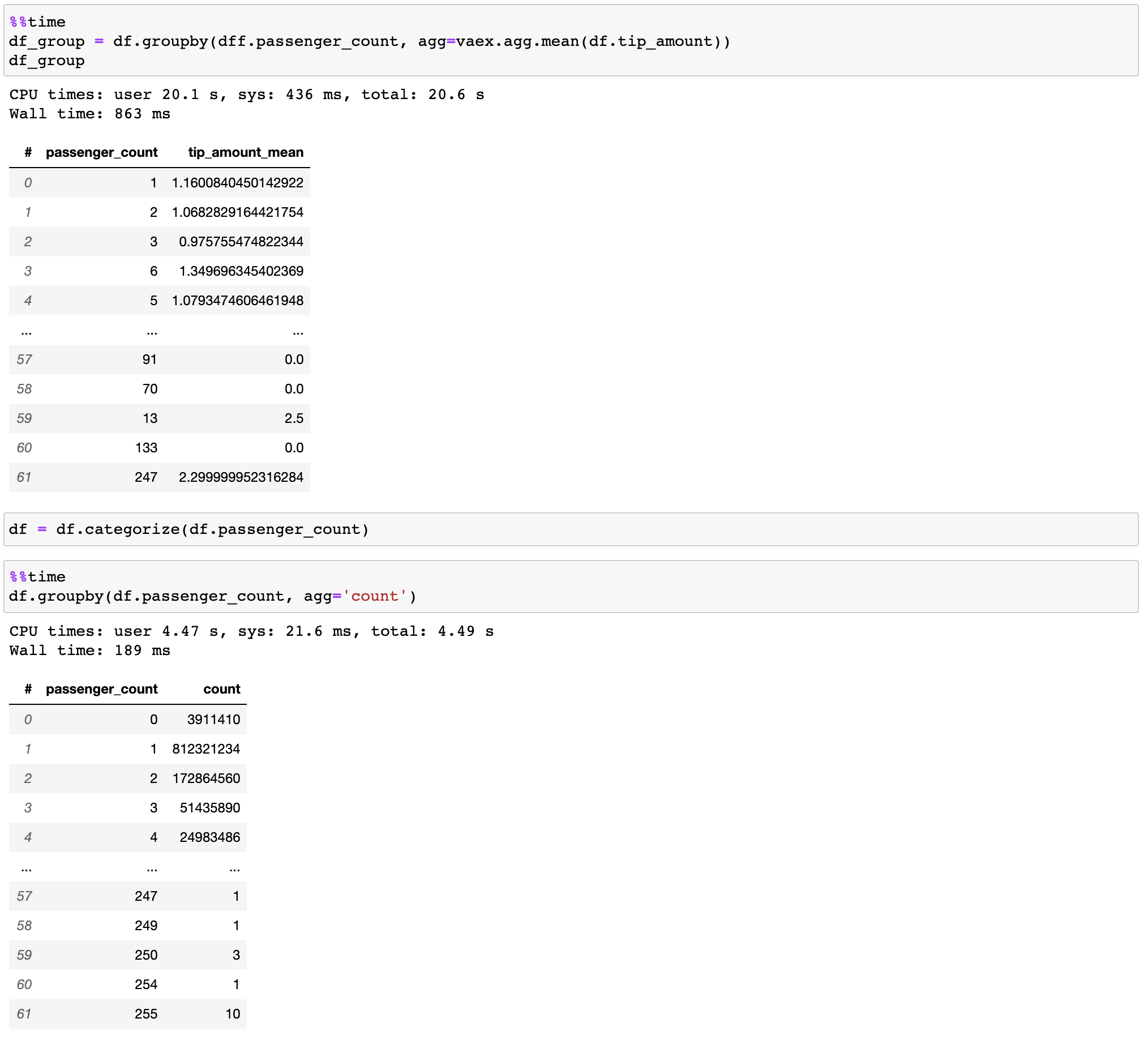
## Fast groupby / aggregations
Vaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second).
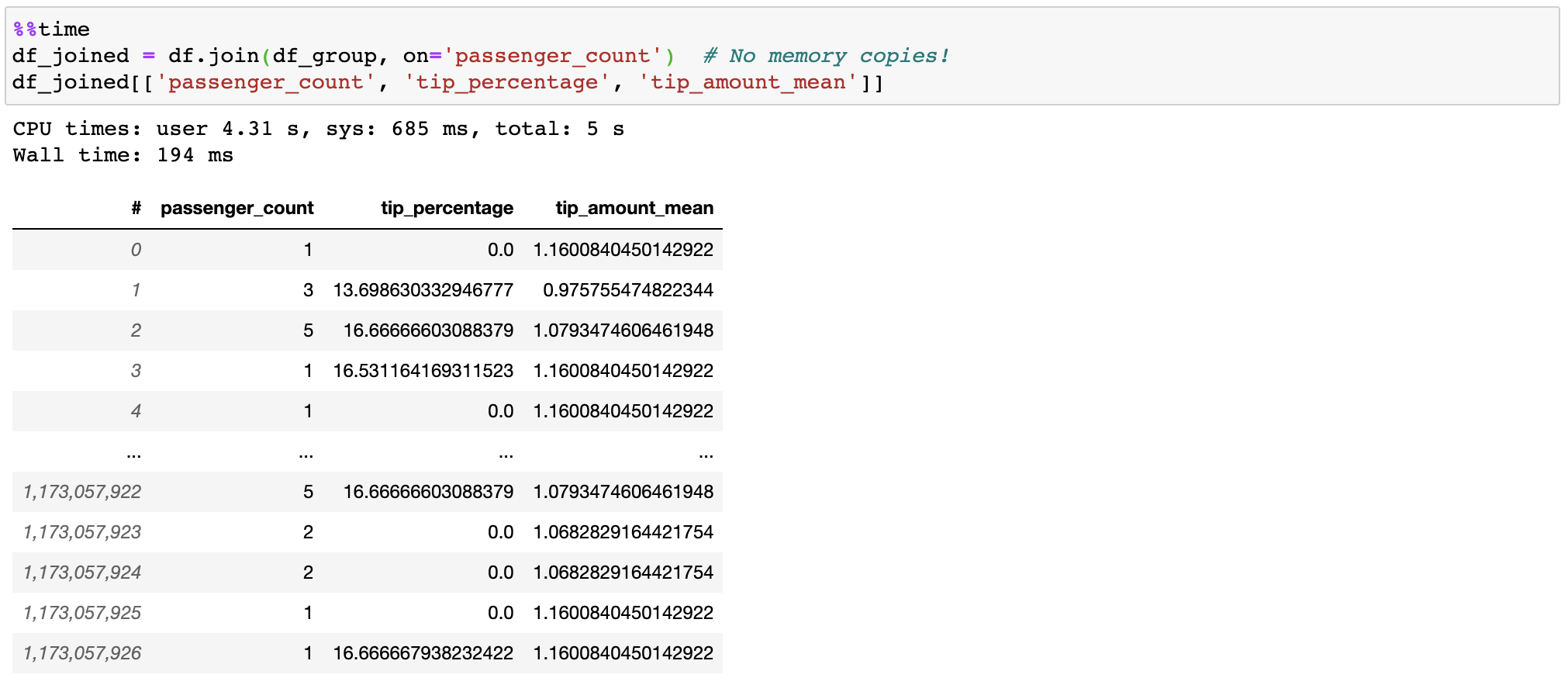
## Fast and efficient join
Vaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast!
## More features
* Remote DataFrames (documentation coming soon)
* Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html)
* [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html)
## Contributing
See [contributing](CONTRIBUTING.md) page.
## Slack
Join the discussion in our [Slack](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) channel!
# Learn more about Vaex
* Articles
* [Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head](https://towardsdatascience.com/beyond-pandas-spark-dask-vaex-and-other-big-data-technologies-battling-head-to-head-a453a1f8cc13) (includes benchmarks)
* [7 reasons why I love Vaex for data science](https://towardsdatascience.com/7-reasons-why-i-love-vaex-for-data-science-99008bc8044b) (tips and trics)
* [ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn](https://towardsdatascience.com/ml-impossible-train-a-1-billion-sample-model-in-20-minutes-with-vaex-and-scikit-learn-on-your-9e2968e6f385)
* [How to analyse 100 GB of data on your laptop with Python](https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94)
* [Flying high with Vaex: analysis of over 30 years of flight data in Python](https://towardsdatascience.com/https-medium-com-jovan-veljanoski-flying-high-with-vaex-analysis-of-over-30-years-of-flight-data-in-python-b224825a6d56)
* [Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x
](https://towardsdatascience.com/vaex-a-dataframe-with-super-strings-789b92e8d861)
* [Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop](https://towardsdatascience.com/vaex-out-of-core-dataframes-for-python-and-fast-visualization-12c102db044a)
* [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html)
* Watch our more recent talks:
* [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec)
* [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is)
* Contact us for data science solutions, training, or enterprise support at https://vaex.io/
Raw data
{
"_id": null,
"home_page": "https://www.github.com/vaexio/vaex",
"name": "vaex",
"maintainer": "",
"docs_url": "https://pythonhosted.org/vaex/",
"requires_python": "",
"maintainer_email": "",
"keywords": "",
"author": "Maarten A. Breddels",
"author_email": "maartenbreddels@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/85/3c/49233556ef1401d2b9cec3e8b6bcb7f25f8fc5db1931b0090d1d749ecd5e/vaex-4.17.0.tar.gz",
"platform": null,
"description": "[](https://pypi.org/project/vaex-core/)\n[](https://docs.vaex.io)\n[](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ)\n\n# What is Vaex?\n\nVaex is a high performance Python library for lazy **Out-of-Core DataFrames**\n(similar to Pandas), to visualize and explore big tabular datasets. It\ncalculates *statistics* such as mean, sum, count, standard deviation etc, on an\n*N-dimensional grid* for more than **a billion** (`10^9`) samples/rows **per\nsecond**. Visualization is done using **histograms**, **density plots** and **3d\nvolume rendering**, allowing interactive exploration of big data. Vaex uses\nmemory mapping, zero memory copy policy and lazy computations for best\nperformance (no memory wasted).\n\n# Installing\nWith pip:\n```\n$ pip install vaex\n```\nOr conda:\n```\n$ conda install -c conda-forge vaex\n```\n\n[For more details, see the documentation](https://docs.vaex.io/en/latest/installing.html)\n\n# Key features\n## Instant opening of Huge data files (memory mapping)\n[HDF5](https://en.wikipedia.org/wiki/Hierarchical_Data_Format) and [Apache Arrow](https://arrow.apache.org/) supported.\n\n\n\n\n\n\n[Read the documentation on how to efficiently convert your data](https://docs.vaex.io/en/latest/example_io.html) from CSV files, Pandas DataFrames, or other sources.\n\n\nLazy streaming from S3 supported in combination with memory mapping.\n\n\n\n\n## Expression system\nDon't waste memory or time with feature engineering, we (lazily) transform your data when needed.\n\n\n\n\n\n\n## Out-of-core DataFrame\nFiltering and evaluating expressions will not waste memory by making copies; the data is kept untouched on disk, and will be streamed only when needed. Delay the time before you need a cluster.\n\n\n\n\n## Fast groupby / aggregations\nVaex implements parallelized, highly performant `groupby` operations, especially when using categories (>1 billion/second).\n\n\n\n\n\n## Fast and efficient join\nVaex doesn't copy/materialize the 'right' table when joining, saving gigabytes of memory. With subsecond joining on a billion rows, it's pretty fast!\n\n\n\n## More features\n\n * Remote DataFrames (documentation coming soon)\n * Integration into [Jupyter and Voila for interactive notebooks and dashboards](https://vaex.readthedocs.io/en/latest/tutorial_jupyter.html)\n * [Machine Learning without (explicit) pipelines](https://vaex.readthedocs.io/en/latest/tutorial_ml.html)\n\n\n## Contributing\n\nSee [contributing](CONTRIBUTING.md) page.\n\n## Slack\n\nJoin the discussion in our [Slack](https://join.slack.com/t/vaexio/shared_invite/zt-shhxzf5i-Cf5n2LtkoYgUjOjbB3bGQQ) channel!\n\n# Learn more about Vaex\n * Articles\n * [Beyond Pandas: Spark, Dask, Vaex and other big data technologies battling head to head](https://towardsdatascience.com/beyond-pandas-spark-dask-vaex-and-other-big-data-technologies-battling-head-to-head-a453a1f8cc13) (includes benchmarks)\n * [7 reasons why I love Vaex for data science](https://towardsdatascience.com/7-reasons-why-i-love-vaex-for-data-science-99008bc8044b) (tips and trics)\n * [ML impossible: Train 1 billion samples in 5 minutes on your laptop using Vaex and Scikit-Learn](https://towardsdatascience.com/ml-impossible-train-a-1-billion-sample-model-in-20-minutes-with-vaex-and-scikit-learn-on-your-9e2968e6f385)\n * [How to analyse 100 GB of data on your laptop with Python](https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94)\n * [Flying high with Vaex: analysis of over 30 years of flight data in Python](https://towardsdatascience.com/https-medium-com-jovan-veljanoski-flying-high-with-vaex-analysis-of-over-30-years-of-flight-data-in-python-b224825a6d56)\n * [Vaex: A DataFrame with super strings - Speed up your text processing up to a 1000x\n](https://towardsdatascience.com/vaex-a-dataframe-with-super-strings-789b92e8d861)\n * [Vaex: Out of Core Dataframes for Python and Fast Visualization - 1 billion row datasets on your laptop](https://towardsdatascience.com/vaex-out-of-core-dataframes-for-python-and-fast-visualization-12c102db044a)\n\n * [Follow our tutorials](https://docs.vaex.io/en/latest/tutorials.html)\n * Watch our more recent talks:\n * [PyData London 2019](https://www.youtube.com/watch?v=2Tt0i823-ec)\n * [SciPy 2019](https://www.youtube.com/watch?v=ELtjRdPT8is)\n * Contact us for data science solutions, training, or enterprise support at https://vaex.io/\n\n\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "Out-of-Core DataFrames to visualize and explore big tabular datasets",
"version": "4.17.0",
"project_urls": {
"Homepage": "https://www.github.com/vaexio/vaex"
},
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "174de42547bc4d263bd15fb3c097f3f5510ec4752766d4ee32d80db58898f70b",
"md5": "4b67c5b2c4e07573d27a6f6f072b5721",
"sha256": "b48dafa590028b103d7a21dcf31d0ea511d83714899a97644eca96f3725bf7cc"
},
"downloads": -1,
"filename": "vaex-4.17.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "4b67c5b2c4e07573d27a6f6f072b5721",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": null,
"size": 4767,
"upload_time": "2023-07-21T10:41:31",
"upload_time_iso_8601": "2023-07-21T10:41:31.143926Z",
"url": "https://files.pythonhosted.org/packages/17/4d/e42547bc4d263bd15fb3c097f3f5510ec4752766d4ee32d80db58898f70b/vaex-4.17.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "853c49233556ef1401d2b9cec3e8b6bcb7f25f8fc5db1931b0090d1d749ecd5e",
"md5": "e7a455319e4b8cc0cbfe2ab4f2039a42",
"sha256": "2303a5382f2048f50389bbd2f24c06147599cdc09e585b138c5b52e0369d5787"
},
"downloads": -1,
"filename": "vaex-4.17.0.tar.gz",
"has_sig": false,
"md5_digest": "e7a455319e4b8cc0cbfe2ab4f2039a42",
"packagetype": "sdist",
"python_version": "source",
"requires_python": null,
"size": 4835,
"upload_time": "2023-07-21T10:41:32",
"upload_time_iso_8601": "2023-07-21T10:41:32.561124Z",
"url": "https://files.pythonhosted.org/packages/85/3c/49233556ef1401d2b9cec3e8b6bcb7f25f8fc5db1931b0090d1d749ecd5e/vaex-4.17.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-07-21 10:41:32",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "vaexio",
"github_project": "vaex",
"travis_ci": true,
"coveralls": false,
"github_actions": true,
"circle": true,
"lcname": "vaex"
}
