[](https://arxiv.org/abs/2109.13731) [](https://colab.research.google.com/drive/1HYYUepIsl2aXsdET6P_AmNVXuWP1MCMf?usp=sharing) [](https://badge.fury.io/py/voicefixer) [](https://haoheliu.github.io/demopage-voicefixer)[](https://huggingface.co/spaces/akhaliq/VoiceFixer)
- [:speaking_head: :wrench: VoiceFixer](#speaking_head-wrench-voicefixer)
- [Demo](#demo)
- [Usage](#usage)
- [Command line](#command-line)
- [Desktop App](#desktop-app)
- [Python Examples](#python-examples)
- [Docker](#docker)
- [Others Features](#others-features)
- [Materials](#materials)
- [Change log](#change-log)
# :speaking_head: :wrench: VoiceFixer
*Voicefixer* aims to restore human speech regardless how serious its degraded. It can handle noise, reveberation, low resolution (2kHz~44.1kHz) and clipping (0.1-1.0 threshold) effect within one model.
This package provides:
- A pretrained *Voicefixer*, which is build based on neural vocoder.
- A pretrained 44.1k universal speaker-independent neural vocoder.

- If you found this repo helpful, please consider citing or [](https://www.buymeacoffee.com/haoheliuP)
```bib
@misc{liu2021voicefixer,
title={VoiceFixer: Toward General Speech Restoration With Neural Vocoder},
author={Haohe Liu and Qiuqiang Kong and Qiao Tian and Yan Zhao and DeLiang Wang and Chuanzeng Huang and Yuxuan Wang},
year={2021},
eprint={2109.13731},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
## Demo
Please visit [demo page](https://haoheliu.github.io/demopage-voicefixer/) to view what voicefixer can do.
## Usage
### Run Modes
| Mode | Description |
| ---- | ----------- |
| `0` | Original Model (suggested by default) |
| `1` | Add preprocessing module (remove higher frequency) |
| `2` | Train mode (might work sometimes on seriously degraded real speech) |
| `all` | Run all modes - will output 1 wav file for each supported mode. |
### Command line
First, install voicefixer via pip:
```shell
pip install voicefixer
```
Process a file:
```shell
# Specify the input .wav file. Output file is outfile.wav.
voicefixer --infile test/utterance/original/original.wav
# Or specify a output path
voicefixer --infile test/utterance/original/original.wav --outfile test/utterance/original/original_processed.wav
```
Process files in a folder:
```shell
voicefixer --infolder /path/to/input --outfolder /path/to/output
```
Change mode (The default mode is 0):
```shell
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode 1
```
Run all modes:
```shell
# output file saved to `/path/to/output-modeX.wav`.
voicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode all
```
Pre-load the weights only without any actual processing:
```shell
voicefixer --weight_prepare
```
For more helper information please run:
```shell
voicefixer -h
```
### Desktop App
[Demo on Youtube](https://www.youtube.com/watch?v=d_j8UKTZ7J8) (Thanks @Justin John)
Install voicefixer via pip:
```shell script
pip install voicefixer
```
You can test audio samples on your desktop by running website (powered by [streamlit](https://streamlit.io/))
1. Clone the repo first.
```shell script
git clone https://github.com/haoheliu/voicefixer.git
cd voicefixer
```
:warning: **For windows users**, please make sure you have installed [WGET](https://eternallybored.org/misc/wget) and added the wget command to the system path (thanks @justinjohn0306).
2. Initialize and start web page.
```shell script
# Run streamlit
streamlit run test/streamlit.py
```
- If you run for the first time: the web page may leave blank for several minutes for downloading models. You can checkout the terminal for downloading progresses.
- You can use [this low quality speech file](https://github.com/haoheliu/voicefixer/blob/main/test/utterance/original/original.wav) we provided for a test run. The page after processing will look like the following.
<p align="center"><img src="test/streamlit.png" alt="figure" width="400"/></p>
- For users from main land China, if you experience difficulty on downloading checkpoint. You can access them alternatively on [百度网盘](https://pan.baidu.com/s/194ufkUR_PYf1nE1KqkEZjQ) (提取密码: qis6). Please download the two checkpoints inside and place them in the following folder.
- Place **vf.ckpt** inside *~/.cache/voicefixer/analysis_module/checkpoints*. (The "~" represents your home directory)
- Place **model.ckpt-1490000_trimed.pt** inside *~/.cache/voicefixer/synthesis_module/44100*. (The "~" represents your home directory)
### Python Examples
First, install voicefixer via pip:
```shell script
pip install voicefixer
```
Then run the following scripts for a test run:
```shell script
git clone https://github.com/haoheliu/voicefixer.git; cd voicefixer
python3 test/test.py # test script
```
We expect it will give you the following output:
```shell script
Initializing VoiceFixer...
Test voicefixer mode 0, Pass
Test voicefixer mode 1, Pass
Test voicefixer mode 2, Pass
Initializing 44.1kHz speech vocoder...
Test vocoder using groundtruth mel spectrogram...
Pass
```
*test/test.py* mainly contains the test of the following two APIs:
- voicefixer.restore
- vocoder.oracle
```python
...
# TEST VOICEFIXER
## Initialize a voicefixer
print("Initializing VoiceFixer...")
voicefixer = VoiceFixer()
# Mode 0: Original Model (suggested by default)
# Mode 1: Add preprocessing module (remove higher frequency)
# Mode 2: Train mode (might work sometimes on seriously degraded real speech)
for mode in [0,1,2]:
print("Testing mode",mode)
voicefixer.restore(input=os.path.join(git_root,"test/utterance/original/original.flac"), # low quality .wav/.flac file
output=os.path.join(git_root,"test/utterance/output/output_mode_"+str(mode)+".flac"), # save file path
cuda=False, # GPU acceleration
mode=mode)
if(mode != 2):
check("output_mode_"+str(mode)+".flac")
print("Pass")
# TEST VOCODER
## Initialize a vocoder
print("Initializing 44.1kHz speech vocoder...")
vocoder = Vocoder(sample_rate=44100)
### read wave (fpath) -> mel spectrogram -> vocoder -> wave -> save wave (out_path)
print("Test vocoder using groundtruth mel spectrogram...")
vocoder.oracle(fpath=os.path.join(git_root,"test/utterance/original/p360_001_mic1.flac"),
out_path=os.path.join(git_root,"test/utterance/output/oracle.flac"),
cuda=False) # GPU acceleration
...
```
You can clone this repo and try to run test.py inside the *test* folder.
### Docker
> Currently the the Docker image is not published and needs to be built locally, but this way you make sure you're running it with all the expected configuration.
> The generated image size is about 10GB and that is mainly due to the dependencies that consume around 9.8GB on their own.
> However, the layer containing `voicefixer` is the last added layer, making any rebuild if you change sources relatively small (~200MB at a time as the weights get refreshed on image build).
The `Dockerfile` can be viewed [here](Dockerfile).
After cloning the repo:
#### OS Agnostic
```shell
# To build the image
cd voicefixer
docker build -t voicefixer:cpu .
# To run the image
docker run --rm -v "$(pwd)/data:/opt/voicefixer/data" voicefixer:cpu <all_other_cli_args_here>
## Example: docker run --rm -v "$(pwd)/data:/opt/voicefixer/data" voicefixer:cpu --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode all
```
#### Wrapper script: Linux and MacOS
```bash
# To build the image
cd voicefixer
./docker-build-local.sh
# To run the image
./run.sh <all_other_cli_args_here>
## Example: ./run.sh --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode all
```
### Others Features
- How to use your own vocoder, like pre-trained HiFi-Gan?
First you need to write a following helper function with your model. Similar to the helper function in this repo: https://github.com/haoheliu/voicefixer/blob/main/voicefixer/vocoder/base.py#L35
```shell script
def convert_mel_to_wav(mel):
"""
:param non normalized mel spectrogram: [batchsize, 1, t-steps, n_mel]
:return: [batchsize, 1, samples]
"""
return wav
```
Then pass this function to *voicefixer.restore*, for example:
```
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0,
your_vocoder_func = convert_mel_to_wav)
```
Note:
- For compatibility, your vocoder should working on 44.1kHz wave with mel frequency bins 128.
- The input mel spectrogram to the helper function should not be normalized by the width of each mel filter.
## Materials
- Voicefixer training: https://github.com/haoheliu/voicefixer_main.git
- Demo page: https://haoheliu.github.io/demopage-voicefixer/
[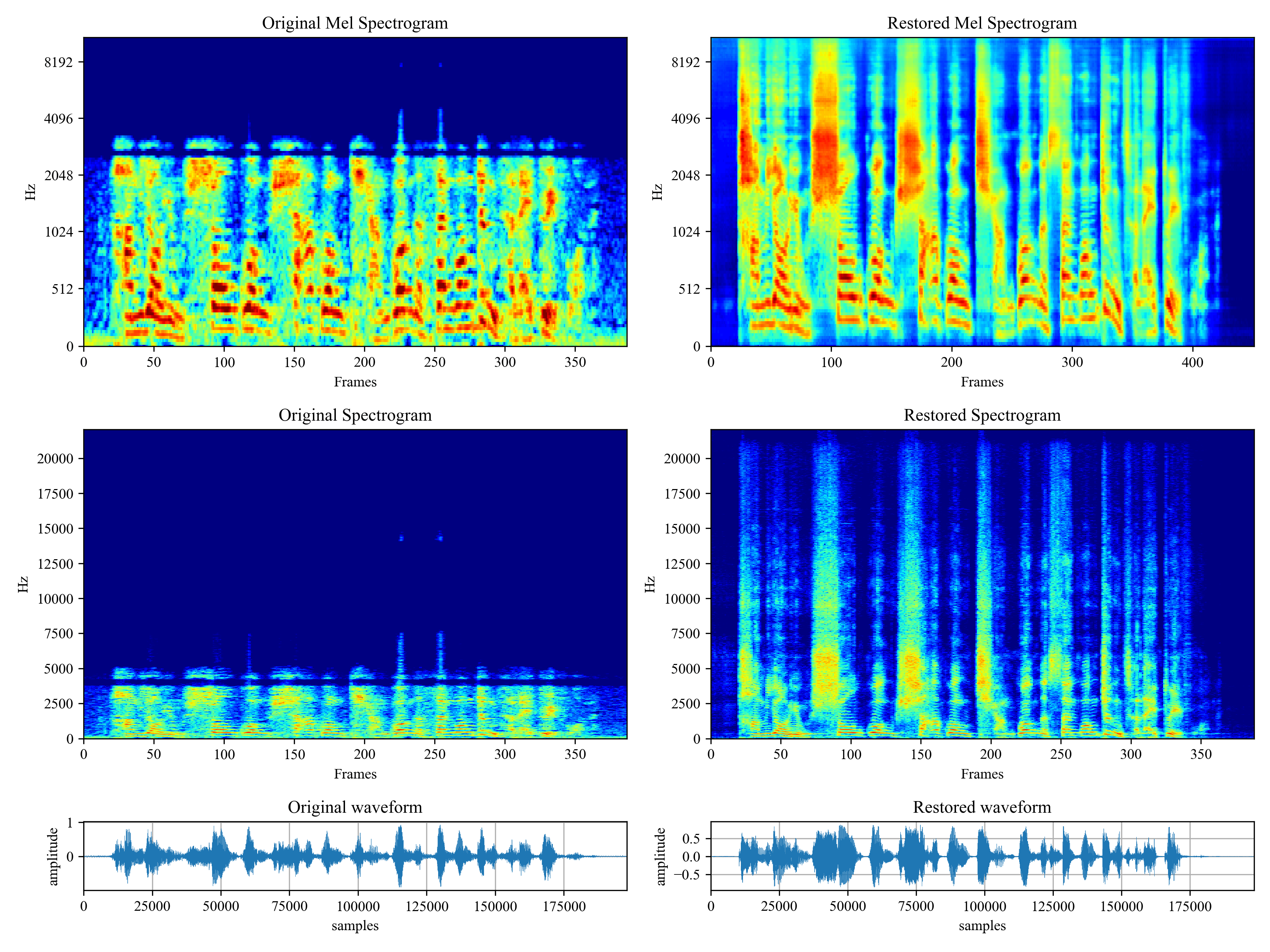](https://imgtu.com/i/46dnPO)
[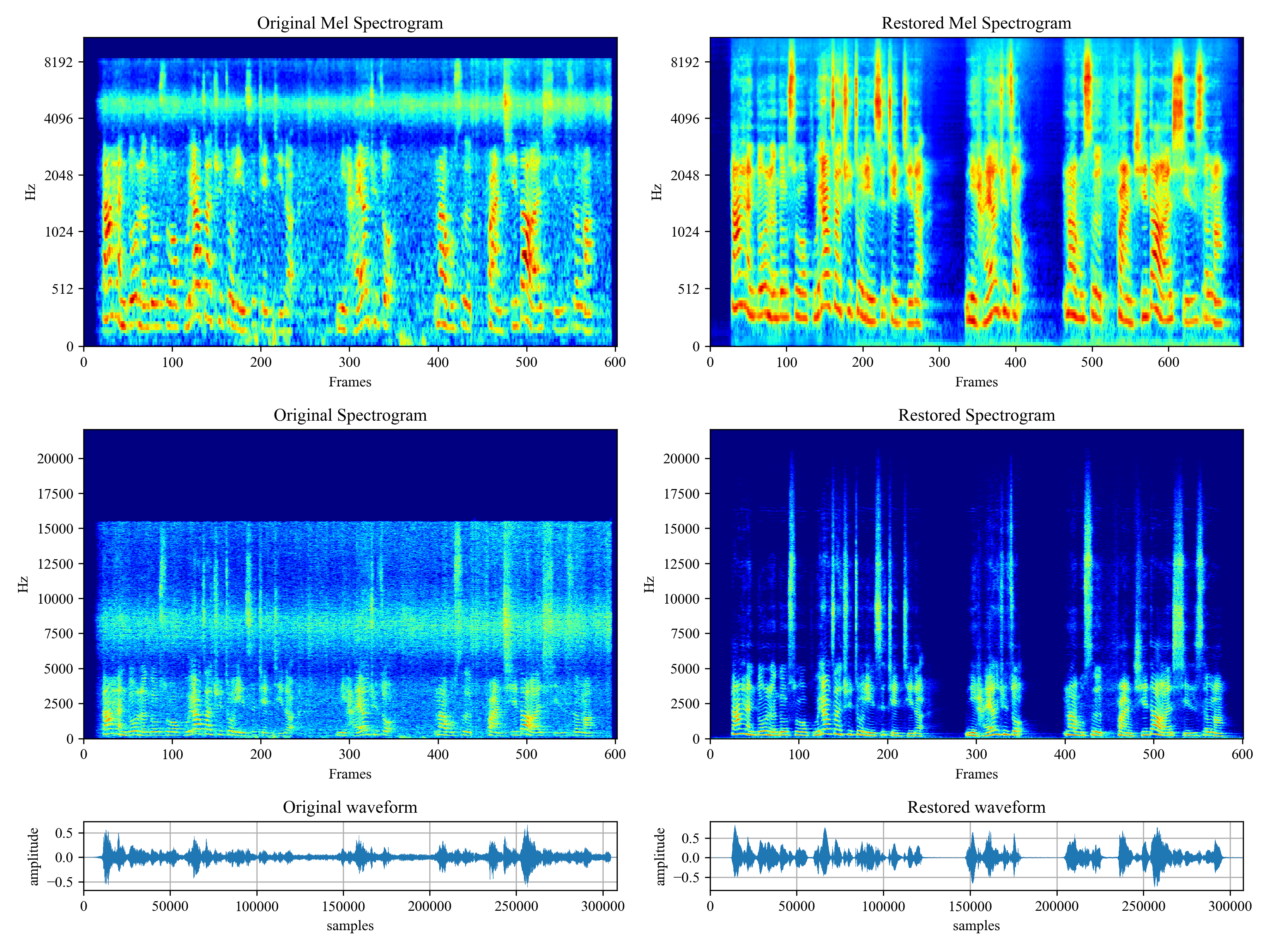](https://imgtu.com/i/46dMxH)
## Change log
See [CHANGELOG.md](CHANGELOG.md).
Raw data
{
"_id": null,
"home_page": "https://github.com/haoheliu/voicefixer",
"name": "voicefixer",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.7.0",
"maintainer_email": "",
"keywords": "",
"author": "Haohe Liu",
"author_email": "haoheliu@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/75/51/f17056d957015813bd0d82c2d780a1cc0709d9cf26a5280a87fd35536415/voicefixer-0.1.3.tar.gz",
"platform": null,
"description": "\n[](https://arxiv.org/abs/2109.13731) [](https://colab.research.google.com/drive/1HYYUepIsl2aXsdET6P_AmNVXuWP1MCMf?usp=sharing) [](https://badge.fury.io/py/voicefixer) [](https://haoheliu.github.io/demopage-voicefixer)[](https://huggingface.co/spaces/akhaliq/VoiceFixer)\n\n- [:speaking_head: :wrench: VoiceFixer](#speaking_head-wrench-voicefixer)\n - [Demo](#demo)\n - [Usage](#usage)\n - [Command line](#command-line)\n - [Desktop App](#desktop-app)\n - [Python Examples](#python-examples)\n - [Docker](#docker)\n - [Others Features](#others-features)\n - [Materials](#materials)\n - [Change log](#change-log)\n \n# :speaking_head: :wrench: VoiceFixer \n\n *Voicefixer* aims to restore human speech regardless how serious its degraded. It can handle noise, reveberation, low resolution (2kHz~44.1kHz) and clipping (0.1-1.0 threshold) effect within one model.\n\nThis package provides: \n- A pretrained *Voicefixer*, which is build based on neural vocoder.\n- A pretrained 44.1k universal speaker-independent neural vocoder.\n\n\n\n- If you found this repo helpful, please consider citing or [](https://www.buymeacoffee.com/haoheliuP)\n\n```bib\n @misc{liu2021voicefixer, \n title={VoiceFixer: Toward General Speech Restoration With Neural Vocoder}, \n author={Haohe Liu and Qiuqiang Kong and Qiao Tian and Yan Zhao and DeLiang Wang and Chuanzeng Huang and Yuxuan Wang}, \n year={2021}, \n eprint={2109.13731}, \n archivePrefix={arXiv}, \n primaryClass={cs.SD} \n }\n```\n\n## Demo\n\nPlease visit [demo page](https://haoheliu.github.io/demopage-voicefixer/) to view what voicefixer can do.\n\n## Usage\n\n### Run Modes\n\n| Mode | Description |\n| ---- | ----------- |\n| `0` | Original Model (suggested by default) |\n| `1` | Add preprocessing module (remove higher frequency) |\n| `2` | Train mode (might work sometimes on seriously degraded real speech) |\n| `all` | Run all modes - will output 1 wav file for each supported mode. |\n\n### Command line\n\nFirst, install voicefixer via pip:\n```shell\npip install voicefixer\n```\n\nProcess a file:\n```shell\n# Specify the input .wav file. Output file is outfile.wav.\nvoicefixer --infile test/utterance/original/original.wav\n# Or specify a output path\nvoicefixer --infile test/utterance/original/original.wav --outfile test/utterance/original/original_processed.wav\n```\n\nProcess files in a folder:\n```shell\nvoicefixer --infolder /path/to/input --outfolder /path/to/output\n```\n\nChange mode (The default mode is 0):\n```shell\nvoicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode 1\n```\n\nRun all modes:\n```shell\n# output file saved to `/path/to/output-modeX.wav`.\nvoicefixer --infile /path/to/input.wav --outfile /path/to/output.wav --mode all\n```\n\nPre-load the weights only without any actual processing:\n```shell\nvoicefixer --weight_prepare\n```\n\nFor more helper information please run:\n\n```shell\nvoicefixer -h\n```\n\n### Desktop App\n\n[Demo on Youtube](https://www.youtube.com/watch?v=d_j8UKTZ7J8) (Thanks @Justin John)\n\nInstall voicefixer via pip:\n```shell script\npip install voicefixer\n```\n\nYou can test audio samples on your desktop by running website (powered by [streamlit](https://streamlit.io/))\n\n1. Clone the repo first.\n```shell script\ngit clone https://github.com/haoheliu/voicefixer.git\ncd voicefixer\n```\n:warning: **For windows users**, please make sure you have installed [WGET](https://eternallybored.org/misc/wget) and added the wget command to the system path (thanks @justinjohn0306).\n\n\n2. Initialize and start web page.\n```shell script\n# Run streamlit \nstreamlit run test/streamlit.py\n```\n\n- If you run for the first time: the web page may leave blank for several minutes for downloading models. You can checkout the terminal for downloading progresses. \n\n- You can use [this low quality speech file](https://github.com/haoheliu/voicefixer/blob/main/test/utterance/original/original.wav) we provided for a test run. The page after processing will look like the following.\n\n<p align=\"center\"><img src=\"test/streamlit.png\" alt=\"figure\" width=\"400\"/></p>\n\n- For users from main land China, if you experience difficulty on downloading checkpoint. You can access them alternatively on [\u767e\u5ea6\u7f51\u76d8](https://pan.baidu.com/s/194ufkUR_PYf1nE1KqkEZjQ) (\u63d0\u53d6\u5bc6\u7801: qis6). Please download the two checkpoints inside and place them in the following folder.\n - Place **vf.ckpt** inside *~/.cache/voicefixer/analysis_module/checkpoints*. (The \"~\" represents your home directory)\n - Place **model.ckpt-1490000_trimed.pt** inside *~/.cache/voicefixer/synthesis_module/44100*. (The \"~\" represents your home directory)\n\n### Python Examples \n\nFirst, install voicefixer via pip:\n```shell script\npip install voicefixer\n```\n\nThen run the following scripts for a test run:\n\n```shell script\ngit clone https://github.com/haoheliu/voicefixer.git; cd voicefixer\npython3 test/test.py # test script\n```\nWe expect it will give you the following output:\n```shell script\nInitializing VoiceFixer...\nTest voicefixer mode 0, Pass\nTest voicefixer mode 1, Pass\nTest voicefixer mode 2, Pass\nInitializing 44.1kHz speech vocoder...\nTest vocoder using groundtruth mel spectrogram...\nPass\n```\n*test/test.py* mainly contains the test of the following two APIs:\n- voicefixer.restore\n- vocoder.oracle\n\n```python\n...\n\n# TEST VOICEFIXER\n## Initialize a voicefixer\nprint(\"Initializing VoiceFixer...\")\nvoicefixer = VoiceFixer()\n# Mode 0: Original Model (suggested by default)\n# Mode 1: Add preprocessing module (remove higher frequency)\n# Mode 2: Train mode (might work sometimes on seriously degraded real speech)\nfor mode in [0,1,2]:\n print(\"Testing mode\",mode)\n voicefixer.restore(input=os.path.join(git_root,\"test/utterance/original/original.flac\"), # low quality .wav/.flac file\n output=os.path.join(git_root,\"test/utterance/output/output_mode_\"+str(mode)+\".flac\"), # save file path\n cuda=False, # GPU acceleration\n mode=mode)\n if(mode != 2):\n check(\"output_mode_\"+str(mode)+\".flac\")\n print(\"Pass\")\n\n# TEST VOCODER\n## Initialize a vocoder\nprint(\"Initializing 44.1kHz speech vocoder...\")\nvocoder = Vocoder(sample_rate=44100)\n\n### read wave (fpath) -> mel spectrogram -> vocoder -> wave -> save wave (out_path)\nprint(\"Test vocoder using groundtruth mel spectrogram...\")\nvocoder.oracle(fpath=os.path.join(git_root,\"test/utterance/original/p360_001_mic1.flac\"),\n out_path=os.path.join(git_root,\"test/utterance/output/oracle.flac\"),\n cuda=False) # GPU acceleration\n\n...\n```\n\nYou can clone this repo and try to run test.py inside the *test* folder.\n\n### Docker\n\n> Currently the the Docker image is not published and needs to be built locally, but this way you make sure you're running it with all the expected configuration.\n> The generated image size is about 10GB and that is mainly due to the dependencies that consume around 9.8GB on their own.\n\n> However, the layer containing `voicefixer` is the last added layer, making any rebuild if you change sources relatively small (~200MB at a time as the weights get refreshed on image build).\n\nThe `Dockerfile` can be viewed [here](Dockerfile).\n\nAfter cloning the repo:\n\n#### OS Agnostic\n\n```shell\n# To build the image\ncd voicefixer\ndocker build -t voicefixer:cpu .\n\n# To run the image\ndocker run --rm -v \"$(pwd)/data:/opt/voicefixer/data\" voicefixer:cpu <all_other_cli_args_here>\n\n## Example: docker run --rm -v \"$(pwd)/data:/opt/voicefixer/data\" voicefixer:cpu --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode all\n```\n\n#### Wrapper script: Linux and MacOS\n```bash\n# To build the image\ncd voicefixer\n./docker-build-local.sh\n\n# To run the image\n./run.sh <all_other_cli_args_here>\n\n## Example: ./run.sh --infile data/my-input.wav --outfile data/my-output.mode-all.wav --mode all\n```\n\n### Others Features\n\n- How to use your own vocoder, like pre-trained HiFi-Gan?\n\nFirst you need to write a following helper function with your model. Similar to the helper function in this repo: https://github.com/haoheliu/voicefixer/blob/main/voicefixer/vocoder/base.py#L35\n\n```shell script\n def convert_mel_to_wav(mel):\n \"\"\"\n :param non normalized mel spectrogram: [batchsize, 1, t-steps, n_mel]\n :return: [batchsize, 1, samples]\n \"\"\"\n return wav\n```\n\nThen pass this function to *voicefixer.restore*, for example:\n```\nvoicefixer.restore(input=\"\", # input wav file path\n output=\"\", # output wav file path\n cuda=False, # whether to use gpu acceleration\n mode = 0,\n your_vocoder_func = convert_mel_to_wav)\n```\n\nNote: \n- For compatibility, your vocoder should working on 44.1kHz wave with mel frequency bins 128. \n- The input mel spectrogram to the helper function should not be normalized by the width of each mel filter. \n\n## Materials\n- Voicefixer training: https://github.com/haoheliu/voicefixer_main.git\n- Demo page: https://haoheliu.github.io/demopage-voicefixer/ \n\n[](https://imgtu.com/i/46dnPO)\n[](https://imgtu.com/i/46dMxH)\n\n\n## Change log\n\nSee [CHANGELOG.md](CHANGELOG.md).\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "This package is written for the restoration of degraded speech",
"version": "0.1.3",
"project_urls": {
"Homepage": "https://github.com/haoheliu/voicefixer"
},
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "eadc6a2a507531647e6fc05e10d8197b38733df112e4ae8a313c643a62889d22",
"md5": "d27c49977b6597d35f46c107e2940836",
"sha256": "7ee61b71c25fbdf1ef4e5407fe870ec0b351f8a82765806a8b09c37eb3a1162d"
},
"downloads": -1,
"filename": "voicefixer-0.1.3-py3-none-any.whl",
"has_sig": false,
"md5_digest": "d27c49977b6597d35f46c107e2940836",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.7.0",
"size": 53161,
"upload_time": "2023-11-12T16:46:52",
"upload_time_iso_8601": "2023-11-12T16:46:52.884662Z",
"url": "https://files.pythonhosted.org/packages/ea/dc/6a2a507531647e6fc05e10d8197b38733df112e4ae8a313c643a62889d22/voicefixer-0.1.3-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "7551f17056d957015813bd0d82c2d780a1cc0709d9cf26a5280a87fd35536415",
"md5": "ee889c36252cc8dcbf5cd59c80d47c78",
"sha256": "40902d1d8fce2a6f8d23ddee4e86038450e8f8fd41c7e71deeb6da2cd0dae218"
},
"downloads": -1,
"filename": "voicefixer-0.1.3.tar.gz",
"has_sig": false,
"md5_digest": "ee889c36252cc8dcbf5cd59c80d47c78",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.7.0",
"size": 48792,
"upload_time": "2023-11-12T16:46:55",
"upload_time_iso_8601": "2023-11-12T16:46:55.083212Z",
"url": "https://files.pythonhosted.org/packages/75/51/f17056d957015813bd0d82c2d780a1cc0709d9cf26a5280a87fd35536415/voicefixer-0.1.3.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-11-12 16:46:55",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "haoheliu",
"github_project": "voicefixer",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "voicefixer"
}

