# BBDecoder

[](https://pepy.tech/project/BBDecoder) [](https://pypi.org/project/BBDecoder/) [](https://pypi.org/project/BBDecoder/)
<p align="justify">
BBDecoder is a Python package designed to provide essential tools for visually analyzing various aspects of the training and testing processes of deep learning models. It offers functionalities to help researchers and developers gain insights into their model's performance and behavior through visualizations and metrics.
## Installation
First you need to install graphviz and torchview
```
pip install graphviz
```
```
pip install torchview
```
Then, continue with installing BBDecoder using pip
```
pip install BBDecoder
```
## How to use
### Initialization
Start by wrapping the entire model. Each layer in the model is assigned a name and a unique layer ID.
```
from BBDecoder import Master_analyzer
model = resnet50().to(device)
wrapped_model = Master_analyzer(model, save_path, input_size)
```
`model` is the model to be analyzed. `save_path` is the main path where all the analysis data will be saved. `input_size = [1, 3, 32, 32]` this shape is used to create the architecture graph using torchview.
### Gradient analysis
`wrapped_model.backward_propagation()` can be used to get gradients of each layer and also the L1 and L2 norms of the gradient for each itteration.
```
for data in tqdm(train_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = wrapped_model.forward_propagation(inputs)
loss = F.cross_entropy(outputs, labels)
optimizer.zero_grad()
wrapped_model.backward_propagation(loss, collect_grads = True, layer_inds = [0, 1, 2, 3, 4, 5, 6])
optimizer.step()
losses.append(loss.item())
print('Epoch: ', epoch)
print('Average Loss: ', sum(losses)/len(losses))
wrapped_model.save_collected_grads(ep = epoch, save_folder)
```
The graphs will be saved directly in the `save_folder` path, by default `save_folder = None` if a new path is not specified then the graphs will be saved on a separate folder in the path specified during `Master_analyzer` initialization.
`collect_grads = True` is grads need to be collected other wise `False`. `layer_inds` is the list of layers that need to be analyzed. Setting `collect_grads = True` needs to be accompanied by `wrapped_model.save_collected_grads()` to actually save the collected data.

_Mean and Max gradients through layers accross the entire dataset._
L1 and L2 norms of each selected layer in the model can highlight the stability of the training process.
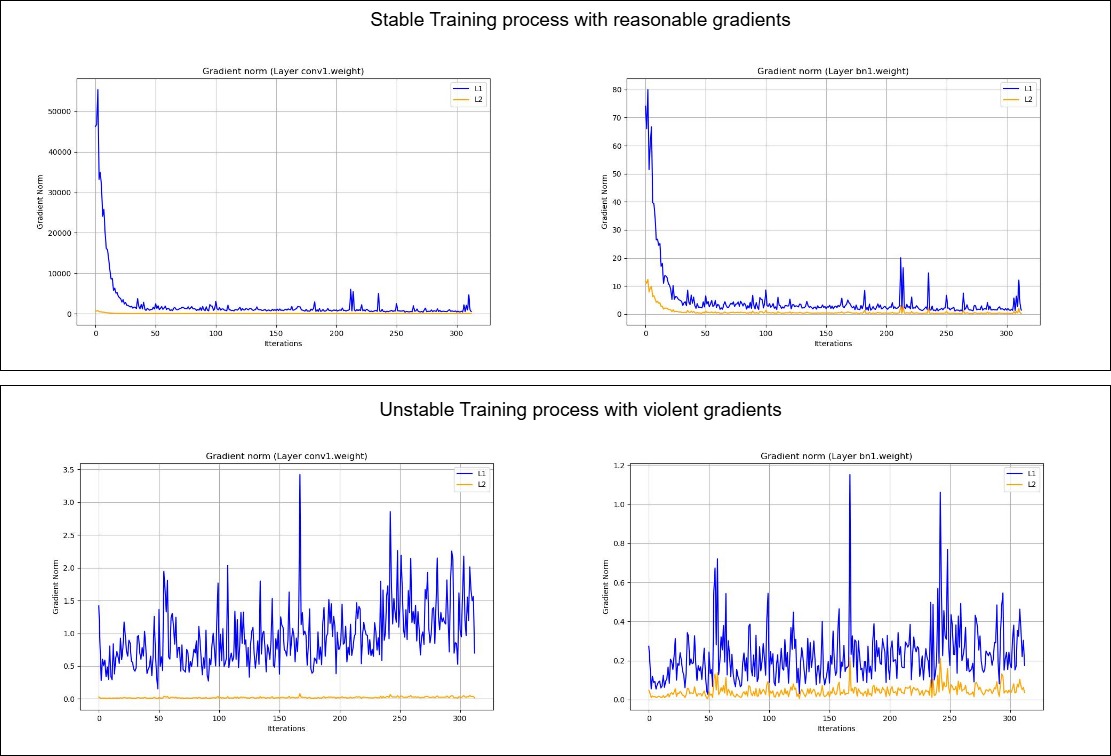
_L1 and L2 norms differentiating between stable and unstable training process._
### Weight histograms
`wrapped_model.visualize_weight_hist(layer_inds, save_folder)` can be used to save weight histograms for layers with unique ID specified in `layer_inds`. `save_folder = None` by default, results will be saved in the path specified during initialization if no path specified.
Weight histograms can be used to identify saturation, divergence and clustering in layer weights. Weights clustering at extreme ends can saturate activation functions. Clustering of weights around certain values in convolution operation can point towards kernels with similar values, this would prevent the network to distinguish between subtle features.
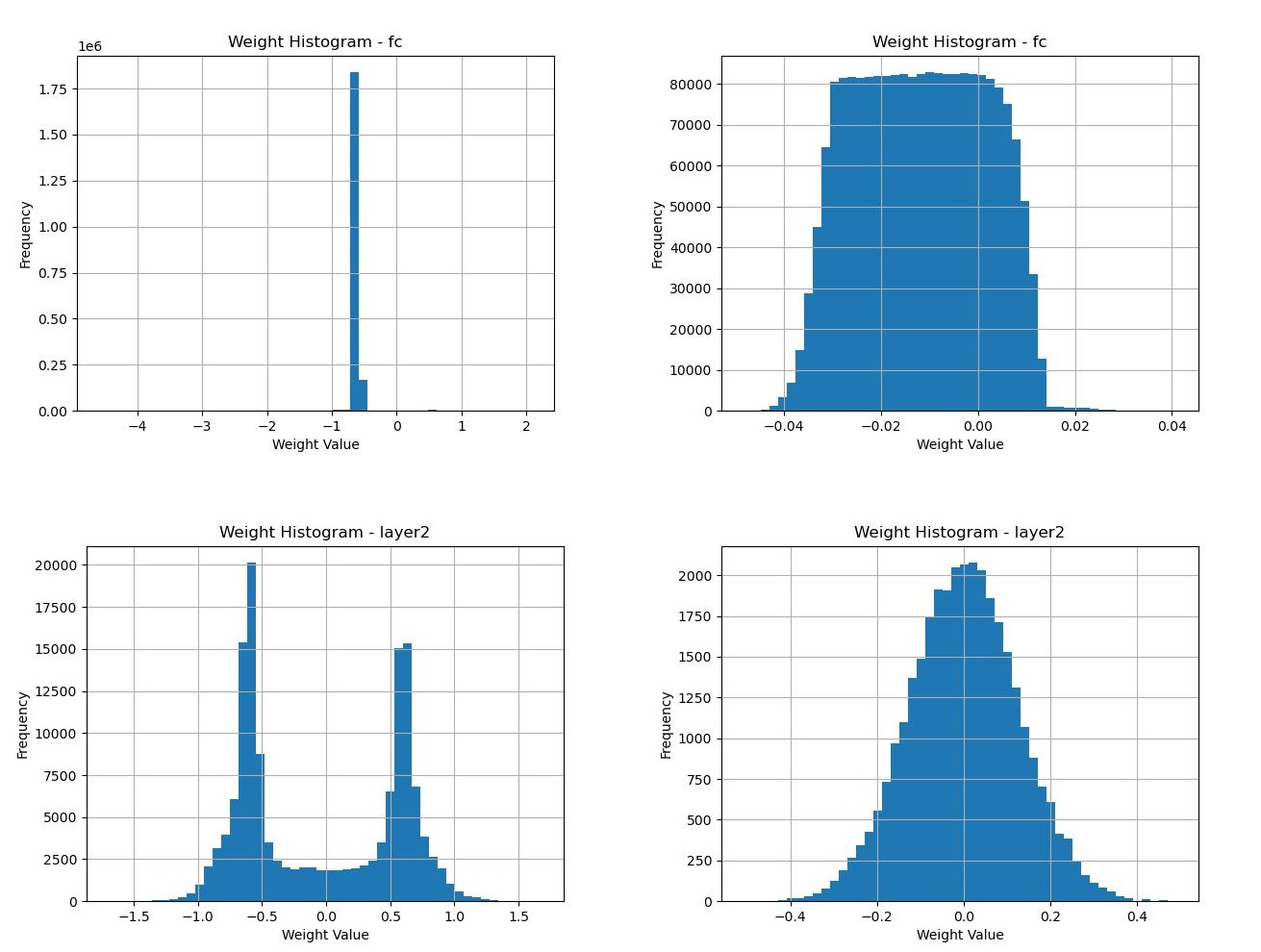
_Weight histograms of multi-layer perceptrons and convolutional layers._
### Divergence calculation
`get_sim(x, layer_inds, dim)` function can be used to calculate how similar the features are accross a certain dimension, this can be used to perform studies similar to [vision transformers with patch diversificattion](https://arxiv.org/pdf/2104.12753).
forward propagation on the input `x` will generate features, the features similarity accross dimension `dim` will be calculated on the intermediate features of `layer_inds`.
```
wrapped_model.get_sim(torch.unsqueeze(inputs.cuda()[0, :, :, :], dim=0), layer_inds = [0, 1, 2, 3, 4, 5, 6], dim = 1)
```
### Get Intermediate Features
You can easily record intermediate features from each layer in the model through `get_inter_features(test_input, layer, path, post_proc = None, dim = None)`. `test_input` is the input you want to use to extract the features, the output features of `layer` will be stored at path `path`. `post_proc` represents the function that will e applied on the output features of `layer` before being saved. If `dim` is not noen then only the specified dimension will be saved.
For example if you want to check the intermediate features of a certain layer after a training loop you can do so as follows
```
for epoch in EPOCHS:
for data in tqdm(train_loader):
.
.
training logic
.
.
sample = torch.tensor(test_sample)
sample = sample.unsqueeze(0).to(device).float()
wrapped_model.get_inter_features(sample, layer = 9, './saves', post_proc_function)
```
You can also generate a small video on how your intermediate features evolved throughout the entire training process. By using the `compile_feature_evaluation(layer, fps)` function. This function compiles all of the previously stored features of a certain specified layer.
```
for epoch in EPOCHS:
for data in tqdm(train_loader):
.
.
training logic
.
.
sample = torch.tensor(test_sample)
sample = sample.unsqueeze(0).to(device).float()
wrapped_model.get_inter_features(sample, layer = 9, './saves', post_proc_function)
# Compiles all of the previously stored features of layer with index 9 after each epoch.
wrapped_model.compile_feature_evolution(layer = 9, fps = 5)
```
Raw data
{
"_id": null,
"home_page": null,
"name": "BBDecoder",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.9",
"maintainer_email": "Sharjeel Masood <sharjeelmasood.sm@gmail.com>, Saeed Ahmed <saeedahmad.icp@gmail.com>",
"keywords": "pytorch, visualization, analysis, torch, deep learning, machine learning, ml, neural network",
"author": null,
"author_email": "Sharjeel Masood <sharjeelmasood.sm@gmail.com>, Saeed Ahmed <saeedahmad.icp@gmail.com>",
"download_url": "https://files.pythonhosted.org/packages/1c/53/f506d2211ea007af7f43f1ace8c3b95eae48744809d161db85e3f7a26ab2/bbdecoder-1.1.1.tar.gz",
"platform": null,
"description": "\n# BBDecoder\n\n\n\n[](https://pepy.tech/project/BBDecoder) [](https://pypi.org/project/BBDecoder/) [](https://pypi.org/project/BBDecoder/)\n\n<p align=\"justify\">\nBBDecoder is a Python package designed to provide essential tools for visually analyzing various aspects of the training and testing processes of deep learning models. It offers functionalities to help researchers and developers gain insights into their model's performance and behavior through visualizations and metrics.\n\n\n\n## Installation\nFirst you need to install graphviz and torchview\n```\npip install graphviz\n```\n```\npip install torchview\n```\n\nThen, continue with installing BBDecoder using pip\n```\npip install BBDecoder\n```\n\n## How to use\n\n### Initialization\n\nStart by wrapping the entire model. Each layer in the model is assigned a name and a unique layer ID. \n```\nfrom BBDecoder import Master_analyzer\n\nmodel = resnet50().to(device)\nwrapped_model = Master_analyzer(model, save_path, input_size)\n```\n`model` is the model to be analyzed. `save_path` is the main path where all the analysis data will be saved. `input_size = [1, 3, 32, 32]` this shape is used to create the architecture graph using torchview.\n\n### Gradient analysis\n\n`wrapped_model.backward_propagation()` can be used to get gradients of each layer and also the L1 and L2 norms of the gradient for each itteration.\n\n```\nfor data in tqdm(train_loader):\n inputs, labels = data\n inputs, labels = inputs.to(device), labels.to(device)\n \n outputs = wrapped_model.forward_propagation(inputs)\n loss = F.cross_entropy(outputs, labels)\n\n optimizer.zero_grad()\n wrapped_model.backward_propagation(loss, collect_grads = True, layer_inds = [0, 1, 2, 3, 4, 5, 6])\n optimizer.step()\n losses.append(loss.item())\n \nprint('Epoch: ', epoch)\nprint('Average Loss: ', sum(losses)/len(losses))\nwrapped_model.save_collected_grads(ep = epoch, save_folder)\n```\n\nThe graphs will be saved directly in the `save_folder` path, by default `save_folder = None` if a new path is not specified then the graphs will be saved on a separate folder in the path specified during `Master_analyzer` initialization.\n\n`collect_grads = True` is grads need to be collected other wise `False`. `layer_inds` is the list of layers that need to be analyzed. Setting `collect_grads = True` needs to be accompanied by `wrapped_model.save_collected_grads()` to actually save the collected data.\n\n\n\n_Mean and Max gradients through layers accross the entire dataset._\n\nL1 and L2 norms of each selected layer in the model can highlight the stability of the training process.\n\n\n\n_L1 and L2 norms differentiating between stable and unstable training process._\n\n### Weight histograms\n\n`wrapped_model.visualize_weight_hist(layer_inds, save_folder)` can be used to save weight histograms for layers with unique ID specified in `layer_inds`. `save_folder = None` by default, results will be saved in the path specified during initialization if no path specified.\n\nWeight histograms can be used to identify saturation, divergence and clustering in layer weights. Weights clustering at extreme ends can saturate activation functions. Clustering of weights around certain values in convolution operation can point towards kernels with similar values, this would prevent the network to distinguish between subtle features.\n\n\n\n_Weight histograms of multi-layer perceptrons and convolutional layers._\n\n\n\n### Divergence calculation\n\n`get_sim(x, layer_inds, dim)` function can be used to calculate how similar the features are accross a certain dimension, this can be used to perform studies similar to [vision transformers with patch diversificattion](https://arxiv.org/pdf/2104.12753).\n\nforward propagation on the input `x` will generate features, the features similarity accross dimension `dim` will be calculated on the intermediate features of `layer_inds`.\n\n```\nwrapped_model.get_sim(torch.unsqueeze(inputs.cuda()[0, :, :, :], dim=0), layer_inds = [0, 1, 2, 3, 4, 5, 6], dim = 1)\n```\n\n\n### Get Intermediate Features\n\nYou can easily record intermediate features from each layer in the model through `get_inter_features(test_input, layer, path, post_proc = None, dim = None)`. `test_input` is the input you want to use to extract the features, the output features of `layer` will be stored at path `path`. `post_proc` represents the function that will e applied on the output features of `layer` before being saved. If `dim` is not noen then only the specified dimension will be saved.\n\n\nFor example if you want to check the intermediate features of a certain layer after a training loop you can do so as follows\n```\nfor epoch in EPOCHS:\n for data in tqdm(train_loader):\n .\n .\n training logic\n .\n .\n\n sample = torch.tensor(test_sample)\n sample = sample.unsqueeze(0).to(device).float()\n wrapped_model.get_inter_features(sample, layer = 9, './saves', post_proc_function)\n```\n\nYou can also generate a small video on how your intermediate features evolved throughout the entire training process. By using the `compile_feature_evaluation(layer, fps)` function. This function compiles all of the previously stored features of a certain specified layer.\n\n```\nfor epoch in EPOCHS:\n for data in tqdm(train_loader):\n .\n .\n training logic\n .\n .\n\n sample = torch.tensor(test_sample)\n sample = sample.unsqueeze(0).to(device).float()\n wrapped_model.get_inter_features(sample, layer = 9, './saves', post_proc_function)\n\n\n# Compiles all of the previously stored features of layer with index 9 after each epoch.\nwrapped_model.compile_feature_evolution(layer = 9, fps = 5) \n```\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "Analysis of Pytorch Models",
"version": "1.1.1",
"project_urls": {
"homepage": "https://github.com/sharjeel1999/Black-Box-Decoder",
"repository": "https://github.com/sharjeel1999/Black-Box-Decoder"
},
"split_keywords": [
"pytorch",
" visualization",
" analysis",
" torch",
" deep learning",
" machine learning",
" ml",
" neural network"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "b37fbeb68ddbc41fc7e18e290222c5cadf01240c1f652a63a71ed94580552a4c",
"md5": "d9af88305b6865cbd7589dcb6f1d7140",
"sha256": "1fed4e809dd8957a57563c9f07a595d40b5a64b9a6a3d85ef068b0b59dd6b11b"
},
"downloads": -1,
"filename": "bbdecoder-1.1.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "d9af88305b6865cbd7589dcb6f1d7140",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.9",
"size": 23770,
"upload_time": "2025-08-07T12:52:13",
"upload_time_iso_8601": "2025-08-07T12:52:13.313011Z",
"url": "https://files.pythonhosted.org/packages/b3/7f/beb68ddbc41fc7e18e290222c5cadf01240c1f652a63a71ed94580552a4c/bbdecoder-1.1.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "1c53f506d2211ea007af7f43f1ace8c3b95eae48744809d161db85e3f7a26ab2",
"md5": "ad40ca5b96a21a433fc1cecd4de3d4f2",
"sha256": "654568a59b4f4b04535f10c04ee15f8fa12008c8b72cb4e46d96e94b6246604c"
},
"downloads": -1,
"filename": "bbdecoder-1.1.1.tar.gz",
"has_sig": false,
"md5_digest": "ad40ca5b96a21a433fc1cecd4de3d4f2",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.9",
"size": 20417,
"upload_time": "2025-08-07T12:52:15",
"upload_time_iso_8601": "2025-08-07T12:52:15.295174Z",
"url": "https://files.pythonhosted.org/packages/1c/53/f506d2211ea007af7f43f1ace8c3b95eae48744809d161db85e3f7a26ab2/bbdecoder-1.1.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-08-07 12:52:15",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "sharjeel1999",
"github_project": "Black-Box-Decoder",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "bbdecoder"
}

