[](https://pypi.org/project/guwencombo/)
# GuwenCOMBO
Tokenizer, POS-Tagger, and Dependency-Parser for Classical Chinese Texts (漢文/文言文), working with [COMBO-pytorch](https://gitlab.clarin-pl.eu/syntactic-tools/combo).
## Basic usage
```py
>>> import guwencombo
>>> lzh=guwencombo.load()
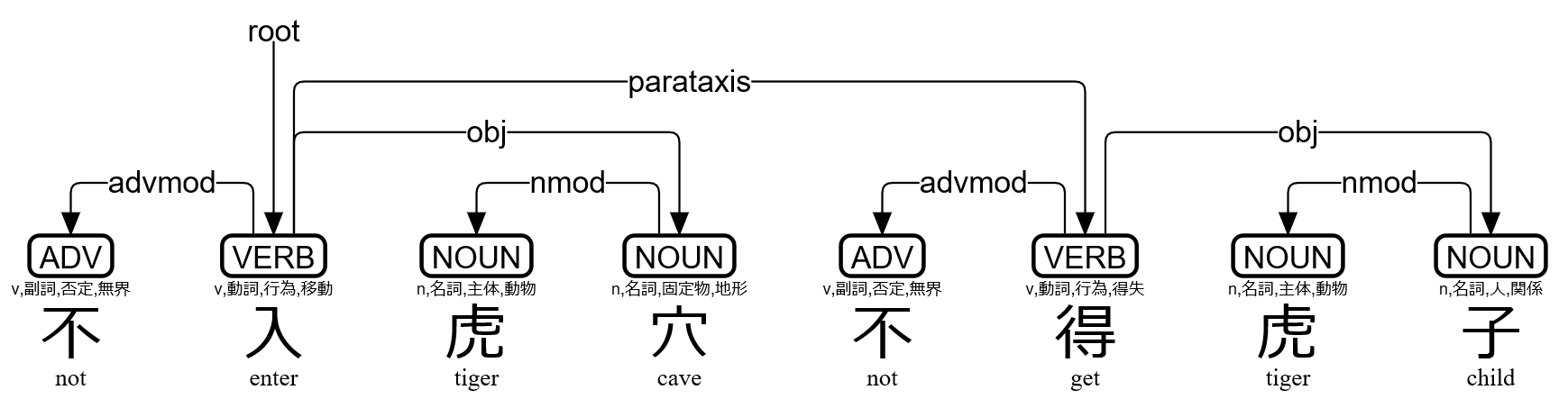
>>> s=lzh("不入虎穴不得虎子")
>>> print(s)
# text = 不入虎穴不得虎子
1 不 不 ADV v,副詞,否定,無界 Polarity=Neg 2 advmod _ Gloss=not|SpaceAfter=No
2 入 入 VERB v,動詞,行為,移動 _ 0 root _ Gloss=enter|SpaceAfter=No
3 虎 虎 NOUN n,名詞,主体,動物 _ 4 nmod _ Gloss=tiger|SpaceAfter=No
4 穴 穴 NOUN n,名詞,固定物,地形 Case=Loc 2 obj _ Gloss=cave|SpaceAfter=No
5 不 不 ADV v,副詞,否定,無界 Polarity=Neg 6 advmod _ Gloss=not|SpaceAfter=No
6 得 得 VERB v,動詞,行為,得失 _ 2 parataxis _ Gloss=get|SpaceAfter=No
7 虎 虎 NOUN n,名詞,主体,動物 _ 8 nmod _ Gloss=tiger|SpaceAfter=No
8 子 子 NOUN n,名詞,人,関係 _ 6 obj _ Gloss=child|SpaceAfter=No
>>> t=s[1]
>>> print(t.id,t.form,t.lemma,t.upos,t.xpos,t.feats,t.head.id,t.deprel,t.deps,t.misc)
1 不 不 ADV v,副詞,否定,無界 Polarity=Neg 2 advmod _ Gloss=not|SpaceAfter=No
>>> print(s.to_tree())
不 <════╗ advmod
入 ═══╗═╝═╗ root
虎 <╗ ║ ║ nmod
穴 ═╝<╝ ║ obj
不 <════╗ ║ advmod
得 ═══╗═╝<╝ parataxis
虎 <╗ ║ nmod
子 ═╝<╝ obj
>>> f=open("trial.svg","w")
>>> f.write(s.to_svg())
>>> f.close()
```
`guwencombo.load()` has two options `guwencombo.load(BERT="guwenbert-base",Danku=False)`. With the option `BERT="guwenbert-large"` the pipeline utilizes [GuwenBERT-large](https://huggingface.co/ethanyt/guwenbert-large). With the option `Danku=True` the pipeline tries to segment sentences automatically. `to_tree()` and `to_svg()` are borrowed from those of [UD-Kanbun](https://github.com/KoichiYasuoka/UD-Kanbun).
## Kundoku usage
```py
>>> import guwencombo
>>> lzh=guwencombo.load()
>>> s=lzh("不入虎穴不得虎子")
>>> t=guwencombo.translate(s)
>>> print(t)
# text = 虎の穴に入らずして虎の子を得ず
1 虎 虎 NOUN n,名詞,主体,動物 _ 3 nmod _ Gloss=tiger|SpaceAfter=No
2 の _ ADP _ _ 1 case _ SpaceAfter=No
3 穴 穴 NOUN n,名詞,固定物,地形 Case=Loc 5 obj _ Gloss=cave|SpaceAfter=No
4 に _ ADP _ _ 3 case _ SpaceAfter=No
5 入ら 入 VERB v,動詞,行為,移動 _ 0 root _ Gloss=enter|SpaceAfter=No
6 ずして 不 AUX v,副詞,否定,無界 Polarity=Neg 5 advmod _ Gloss=not|SpaceAfter=No
7 虎 虎 NOUN n,名詞,主体,動物 _ 9 nmod _ Gloss=tiger|SpaceAfter=No
8 の _ ADP _ _ 7 case _ SpaceAfter=No
9 子 子 NOUN n,名詞,人,関係 _ 11 obj _ Gloss=child|SpaceAfter=No
10 を _ ADP _ _ 9 case _ SpaceAfter=No
11 得 得 VERB v,動詞,行為,得失 _ 5 parataxis _ Gloss=get|SpaceAfter=No
12 ず 不 AUX v,副詞,否定,無界 Polarity=Neg 11 advmod _ Gloss=not|SpaceAfter=No
>>> print(t.sentence())
虎の穴に入らずして虎の子を得ず
>>> print(s.kaeriten())
不㆑入㆓虎穴㆒不㆑得㆓虎子㆒
>>> print(t.to_tree())
虎 ═╗<╗ nmod(体言による連体修飾語)
の <╝ ║ case(格表示)
穴 ═╗═╝<╗ obj(目的語)
に <╝ ║ case(格表示)
入 ═╗═══╝═╗ root(親)
ら ║ ║
ず <╝ ║ advmod(連用修飾語)
し ║
て ║
虎 ═╗<╗ ║ nmod(体言による連体修飾語)
の <╝ ║ ║ case(格表示)
子 ═╗═╝<╗ ║ obj(目的語)
を <╝ ║ ║ case(格表示)
得 ═╗═══╝<╝ parataxis(隣接表現)
ず <╝ advmod(連用修飾語)
```
`translate()` and `reorder()` are borrowed from those of [UD-Kundoku](https://github.com/KoichiYasuoka/UD-Kundoku).
## Installation for Linux
```sh
pip3 install allennlp@git+https://github.com/allenai/allennlp
pip3 install 'transformers<4.31'
pip3 install guwencombo
```
## Installation for Cygwin64
Make sure to get `python37-devel` `python37-pip` `python37-cython` `python37-numpy` `python37-cffi` `gcc-g++` `mingw64-x86_64-gcc-g++` `gcc-fortran` `git` `curl` `make` `cmake` `libopenblas` `liblapack-devel` `libhdf5-devel` `libfreetype-devel` `libuv-devel` packages, and then:
```sh
curl -L https://raw.githubusercontent.com/KoichiYasuoka/UniDic-COMBO/master/cygwin64.sh | sh
pip3.7 install guwencombo
```
## Reference
* 安岡孝一: [TransformersのBERTは共通テスト『国語』を係り受け解析する夢を見るか](http://hdl.handle.net/2433/261872), 東洋学へのコンピュータ利用, 第33回研究セミナー (2021年3月5日), pp.3-34.
Raw data
{
"_id": null,
"home_page": "https://github.com/KoichiYasuoka/GuwenCOMBO",
"name": "guwencombo",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.6",
"maintainer_email": null,
"keywords": "NLP Chinese",
"author": "Koichi Yasuoka",
"author_email": "yasuoka@kanji.zinbun.kyoto-u.ac.jp",
"download_url": null,
"platform": null,
"description": "[](https://pypi.org/project/guwencombo/)\n\n# GuwenCOMBO\n\nTokenizer, POS-Tagger, and Dependency-Parser for Classical Chinese Texts (\u6f22\u6587/\u6587\u8a00\u6587), working with [COMBO-pytorch](https://gitlab.clarin-pl.eu/syntactic-tools/combo).\n\n## Basic usage\n\n```py\n>>> import guwencombo\n>>> lzh=guwencombo.load()\n>>> s=lzh(\"\u4e0d\u5165\u864e\u7a74\u4e0d\u5f97\u864e\u5b50\")\n>>> print(s)\n# text = \u4e0d\u5165\u864e\u7a74\u4e0d\u5f97\u864e\u5b50\n1\t\u4e0d\t\u4e0d\tADV\tv,\u526f\u8a5e,\u5426\u5b9a,\u7121\u754c\tPolarity=Neg\t2\tadvmod\t_\tGloss=not|SpaceAfter=No\n2\t\u5165\t\u5165\tVERB\tv,\u52d5\u8a5e,\u884c\u70ba,\u79fb\u52d5\t_\t0\troot\t_\tGloss=enter|SpaceAfter=No\n3\t\u864e\t\u864e\tNOUN\tn,\u540d\u8a5e,\u4e3b\u4f53,\u52d5\u7269\t_\t4\tnmod\t_\tGloss=tiger|SpaceAfter=No\n4\t\u7a74\t\u7a74\tNOUN\tn,\u540d\u8a5e,\u56fa\u5b9a\u7269,\u5730\u5f62\tCase=Loc\t2\tobj\t_\tGloss=cave|SpaceAfter=No\n5\t\u4e0d\t\u4e0d\tADV\tv,\u526f\u8a5e,\u5426\u5b9a,\u7121\u754c\tPolarity=Neg\t6\tadvmod\t_\tGloss=not|SpaceAfter=No\n6\t\u5f97\t\u5f97\tVERB\tv,\u52d5\u8a5e,\u884c\u70ba,\u5f97\u5931\t_\t2\tparataxis\t_\tGloss=get|SpaceAfter=No\n7\t\u864e\t\u864e\tNOUN\tn,\u540d\u8a5e,\u4e3b\u4f53,\u52d5\u7269\t_\t8\tnmod\t_\tGloss=tiger|SpaceAfter=No\n8\t\u5b50\t\u5b50\tNOUN\tn,\u540d\u8a5e,\u4eba,\u95a2\u4fc2\t_\t6\tobj\t_\tGloss=child|SpaceAfter=No\n\n>>> t=s[1]\n>>> print(t.id,t.form,t.lemma,t.upos,t.xpos,t.feats,t.head.id,t.deprel,t.deps,t.misc)\n1 \u4e0d \u4e0d ADV v,\u526f\u8a5e,\u5426\u5b9a,\u7121\u754c Polarity=Neg 2 advmod _ Gloss=not|SpaceAfter=No\n\n>>> print(s.to_tree())\n\u4e0d <\u2550\u2550\u2550\u2550\u2557 advmod\n\u5165 \u2550\u2550\u2550\u2557\u2550\u255d\u2550\u2557 root\n\u864e <\u2557 \u2551 \u2551 nmod\n\u7a74 \u2550\u255d<\u255d \u2551 obj\n\u4e0d <\u2550\u2550\u2550\u2550\u2557 \u2551 advmod\n\u5f97 \u2550\u2550\u2550\u2557\u2550\u255d<\u255d parataxis\n\u864e <\u2557 \u2551 nmod\n\u5b50 \u2550\u255d<\u255d obj\n\n>>> f=open(\"trial.svg\",\"w\")\n>>> f.write(s.to_svg())\n>>> f.close()\n```\n\n`guwencombo.load()` has two options `guwencombo.load(BERT=\"guwenbert-base\",Danku=False)`. With the option `BERT=\"guwenbert-large\"` the pipeline utilizes [GuwenBERT-large](https://huggingface.co/ethanyt/guwenbert-large). With the option `Danku=True` the pipeline tries to segment sentences automatically. `to_tree()` and `to_svg()` are borrowed from those of [UD-Kanbun](https://github.com/KoichiYasuoka/UD-Kanbun).\n\n## Kundoku usage\n\n```py\n>>> import guwencombo\n>>> lzh=guwencombo.load()\n>>> s=lzh(\"\u4e0d\u5165\u864e\u7a74\u4e0d\u5f97\u864e\u5b50\")\n>>> t=guwencombo.translate(s)\n>>> print(t)\n# text = \u864e\u306e\u7a74\u306b\u5165\u3089\u305a\u3057\u3066\u864e\u306e\u5b50\u3092\u5f97\u305a\n1\t\u864e\t\u864e\tNOUN\tn,\u540d\u8a5e,\u4e3b\u4f53,\u52d5\u7269\t_\t3\tnmod\t_\tGloss=tiger|SpaceAfter=No\n2\t\u306e\t_\tADP\t_\t_\t1\tcase\t_\tSpaceAfter=No\n3\t\u7a74\t\u7a74\tNOUN\tn,\u540d\u8a5e,\u56fa\u5b9a\u7269,\u5730\u5f62\tCase=Loc\t5\tobj\t_\tGloss=cave|SpaceAfter=No\n4\t\u306b\t_\tADP\t_\t_\t3\tcase\t_\tSpaceAfter=No\n5\t\u5165\u3089\t\u5165\tVERB\tv,\u52d5\u8a5e,\u884c\u70ba,\u79fb\u52d5\t_\t0\troot\t_\tGloss=enter|SpaceAfter=No\n6\t\u305a\u3057\u3066\t\u4e0d\tAUX\tv,\u526f\u8a5e,\u5426\u5b9a,\u7121\u754c\tPolarity=Neg\t5\tadvmod\t_\tGloss=not|SpaceAfter=No\n7\t\u864e\t\u864e\tNOUN\tn,\u540d\u8a5e,\u4e3b\u4f53,\u52d5\u7269\t_\t9\tnmod\t_\tGloss=tiger|SpaceAfter=No\n8\t\u306e\t_\tADP\t_\t_\t7\tcase\t_\tSpaceAfter=No\n9\t\u5b50\t\u5b50\tNOUN\tn,\u540d\u8a5e,\u4eba,\u95a2\u4fc2\t_\t11\tobj\t_\tGloss=child|SpaceAfter=No\n10\t\u3092\t_\tADP\t_\t_\t9\tcase\t_\tSpaceAfter=No\n11\t\u5f97\t\u5f97\tVERB\tv,\u52d5\u8a5e,\u884c\u70ba,\u5f97\u5931\t_\t5\tparataxis\t_\tGloss=get|SpaceAfter=No\n12\t\u305a\t\u4e0d\tAUX\tv,\u526f\u8a5e,\u5426\u5b9a,\u7121\u754c\tPolarity=Neg\t11\tadvmod\t_\tGloss=not|SpaceAfter=No\n\n>>> print(t.sentence())\n\u864e\u306e\u7a74\u306b\u5165\u3089\u305a\u3057\u3066\u864e\u306e\u5b50\u3092\u5f97\u305a\n\n>>> print(s.kaeriten())\n\u4e0d\u3191\u5165\u3193\u864e\u7a74\u3192\u4e0d\u3191\u5f97\u3193\u864e\u5b50\u3192\n\n>>> print(t.to_tree())\n\u864e \u2550\u2557<\u2557 nmod(\u4f53\u8a00\u306b\u3088\u308b\u9023\u4f53\u4fee\u98fe\u8a9e)\n\u306e <\u255d \u2551 case(\u683c\u8868\u793a)\n\u7a74 \u2550\u2557\u2550\u255d<\u2557 obj(\u76ee\u7684\u8a9e)\n\u306b <\u255d \u2551 case(\u683c\u8868\u793a)\n\u5165 \u2550\u2557\u2550\u2550\u2550\u255d\u2550\u2557 root(\u89aa)\n\u3089 \u2551 \u2551\n\u305a <\u255d \u2551 advmod(\u9023\u7528\u4fee\u98fe\u8a9e)\n\u3057 \u2551\n\u3066 \u2551\n\u864e \u2550\u2557<\u2557 \u2551 nmod(\u4f53\u8a00\u306b\u3088\u308b\u9023\u4f53\u4fee\u98fe\u8a9e)\n\u306e <\u255d \u2551 \u2551 case(\u683c\u8868\u793a)\n\u5b50 \u2550\u2557\u2550\u255d<\u2557 \u2551 obj(\u76ee\u7684\u8a9e)\n\u3092 <\u255d \u2551 \u2551 case(\u683c\u8868\u793a)\n\u5f97 \u2550\u2557\u2550\u2550\u2550\u255d<\u255d parataxis(\u96a3\u63a5\u8868\u73fe)\n\u305a <\u255d advmod(\u9023\u7528\u4fee\u98fe\u8a9e)\n```\n\n`translate()` and `reorder()` are borrowed from those of [UD-Kundoku](https://github.com/KoichiYasuoka/UD-Kundoku).\n\n## Installation for Linux\n\n```sh\npip3 install allennlp@git+https://github.com/allenai/allennlp\npip3 install 'transformers<4.31'\npip3 install guwencombo\n```\n\n## Installation for Cygwin64\n\nMake sure to get `python37-devel` `python37-pip` `python37-cython` `python37-numpy` `python37-cffi` `gcc-g++` `mingw64-x86_64-gcc-g++` `gcc-fortran` `git` `curl` `make` `cmake` `libopenblas` `liblapack-devel` `libhdf5-devel` `libfreetype-devel` `libuv-devel` packages, and then:\n```sh\ncurl -L https://raw.githubusercontent.com/KoichiYasuoka/UniDic-COMBO/master/cygwin64.sh | sh\npip3.7 install guwencombo\n```\n\n## Reference\n\n* \u5b89\u5ca1\u5b5d\u4e00: [Transformers\u306eBERT\u306f\u5171\u901a\u30c6\u30b9\u30c8\u300e\u56fd\u8a9e\u300f\u3092\u4fc2\u308a\u53d7\u3051\u89e3\u6790\u3059\u308b\u5922\u3092\u898b\u308b\u304b](http://hdl.handle.net/2433/261872), \u6771\u6d0b\u5b66\u3078\u306e\u30b3\u30f3\u30d4\u30e5\u30fc\u30bf\u5229\u7528, \u7b2c33\u56de\u7814\u7a76\u30bb\u30df\u30ca\u30fc (2021\u5e743\u67085\u65e5), pp.3-34.\n\n",
"bugtrack_url": null,
"license": "GPL",
"summary": "Tokenizer POS-tagger and Dependency-parser for Classical Chinese",
"version": "1.6.1",
"project_urls": {
"COMBO-pytorch": "https://gitlab.clarin-pl.eu/syntactic-tools/combo",
"Homepage": "https://github.com/KoichiYasuoka/GuwenCOMBO",
"Source": "https://github.com/KoichiYasuoka/GuwenCOMBO",
"Tracker": "https://github.com/KoichiYasuoka/GuwenCOMBO/issues"
},
"split_keywords": [
"nlp",
"chinese"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "2158f5384623c19910666511a90fd5b480061150c86e0e97f0e14a11a58eada2",
"md5": "4d16bafc2bf3caf2beccf5e78508190e",
"sha256": "82de5cd5613d35da4662ef5a32479f18022653e456d653409b2bf9175cd5c7ae"
},
"downloads": -1,
"filename": "guwencombo-1.6.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "4d16bafc2bf3caf2beccf5e78508190e",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.6",
"size": 17434,
"upload_time": "2025-07-13T07:40:26",
"upload_time_iso_8601": "2025-07-13T07:40:26.329410Z",
"url": "https://files.pythonhosted.org/packages/21/58/f5384623c19910666511a90fd5b480061150c86e0e97f0e14a11a58eada2/guwencombo-1.6.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-07-13 07:40:26",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "KoichiYasuoka",
"github_project": "GuwenCOMBO",
"travis_ci": false,
"coveralls": false,
"github_actions": false,
"lcname": "guwencombo"
}

