# Nkocr: The OCR tool for nutritional tables

[](https://badge.fury.io/py/nkocr)
[](https://github.com/Lucs1590/Nkocr/blob/master/LICENSE)


[](https://www.codefactor.io/repository/github/lucs1590/nkocr)
[](https://codecov.io/gh/Lucs1590/Nkocr)
[](https://colab.research.google.com/github/Lucs1590/Nkocr/blob/master/ocr_table.ipynb)
[](https://twitter.com/intent/tweet?text=try%20to%20apply%20OCR%20techniques%20on%20a%20nutritional%20table%20with%20Nkocr&url=https://github.com/Lucs1590/Nkocr&hashtags=ocr,github,opensource,developer,dev)
This is a module to make specifics OCRs at food products and nutritional tables.
# Contents
- [Prerequisites](#prerequisites)
- [Tesseract OCR](#tesseract)
- [OpenCV](#opencv)
- [Installation](#install)
- [Pip](#pip)
- [Conda](#conda)
- [Usage](#usage)
- [Example](#example)
- [Under the Hood](#uth)
- [Choosing the Language](#lang)
- [Pipeline](#pipeline)
- [Supporting](#sup)
# 📝 Prerequisites <a id="prerequisites"></a>
As a prerequisite of this project, we have the [tesseract library](https://github.com/tesseract-ocr/tesseract) and [OpenCV](https://docs.opencv.org/master/da/df6/tutorial_py_table_of_contents_setup.html), so next we will install this preßsites.
## Tesseract OCR <a id="tesseract"></a>
The installation of tesseract on the **Linux** system can be done in a few commands:
```bash
sudo apt install tesseract-ocr libtesseract-dev
```
And the same goes for **macOS**. There is a variation between MacPorts and Homebrew, but in this post I will only quote the version of Homebrew:
```bash
brew install tesseract
```
After performing the tesseract installation, it is possible to perform OCR in just one command, thus already extracting some words from the image.
## OpenCV <a id="opencv"></a>
The installation of opencv on the **Linux** system can be done in a command:
```bash
sudo apt install python3-opencv
```
And to **macOS** running the following command:
```bash
brew install opencv
```
# ⚙️ Installation <a id="install"></a>
Now, assuming the prerequisites have already been installed, you're ready to install the Nkocr environment to modify, contribute and work!
**But, if you just want to use the project, go to the [usage](#usage) part.**
## Pip <a id="pip"></a>
You can install the project requirements in a Python environment by running:
```bash
pip install -r requirements.txt --user
```
## Conda <a id="conda"></a>
But if you are used to using a conda environment to keep everything organized, or if you want to test using it this time, feel free to run the following command and have a unique environment for Nkocr.
```bash
conda env create -f environment.yml
```
# 👨💻 Usage <a id="usage"></a>
To use this package, it's very easy, first you need to install it by running:
```bash
pip install nkocr --user
```
And after installing, you can import the packages in a Python script like the example below.
```python
from nkocr import OcrTable, OcrProduct
```
## Example <a id="example"></a>
To make it even easier, below is an example of code snippet.
```python
from nkocr import OcrTable
text = OcrTable("paste_image_url_here")
print(text) # or print(text.text)
```
# ℹ️ Under the Hood <a id="uth"></a>
From now on we will be talking about a little more technical details of the library.
## Changing Language <a id="lang"></a>
The default language is English, so depending on the text, it will not be possible to capture the desired words / phrases.
Therefore, if you want to work with another language, you will need to make some changes inherent to the language that the algorithm executes.
The first thing is to download the desired language with tesseract support, and on Linux this can be done by running the following command:
Don't forget to change ```<lang>``` with the desired language. If you would like more details, please feel free to access the [tesseract documentation](https://github.com/tesseract-ocr/tessdoc/blob/master/Data-Files-in-different-versions.md).
```bash
sudo apt install tesseract-ocr-<lang>
```
If you are a macOS user, your command will be a little different. You will need to run the following command, and don't worry about the language, after running this command you will have access to all languages.
```bash
brew install tesseract-lang
```
After downloading the support languages, to perform the translations in the desired language you will have to change the code in the [ocr_product.py](https://github.com/Lucs1590/Nkocr/blob/cdf0024850617bf24261ad1b028b5b924ae96720/src/ocr_product.py#L13), [ocr_table.py](https://github.com/Lucs1590/Nkocr/blob/cdf0024850617bf24261ad1b028b5b924ae96720/src/ocr_table.py#L15) and [auxiliary.py](https://github.com/Lucs1590/Nkocr/blob/a6c2cd045edfb12f664a8832b1349b1e1dc4b00f/src/auxiliary.py#L349).
## Operating Pipeline <a id="pipeline"></a>
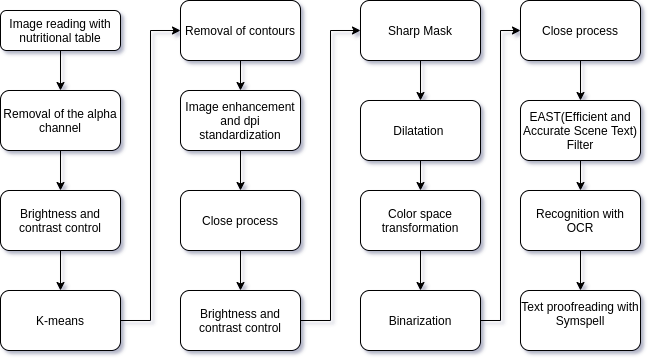
The main algorithm was built working, mainly, with structures and methods of computer vision and digital image processing. The image below clearly depicts the line followed for the operational pipeline combinations.
# 🤝 Supporting <a id="sup"></a>
Many hours of hard work have gone into this project. Your support will be very appreciated!
<a href="https://www.buymeacoffee.com/Lucs1590" target="_blank"><img src="https://www.buymeacoffee.com/assets/img/custom_images/orange_img.png" alt="Buy Me A Coffee" style="height: auto !important;width: auto !important;" ></a>
Raw data
{
"_id": null,
"home_page": "https://github.com/Lucs1590/Nkocr",
"name": "nkocr",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.6",
"maintainer_email": null,
"keywords": "ocr, tesseract-ocr, nk, python3, python-3, food-products",
"author": "Lucas de Brito Silva",
"author_email": "lucasbsilva29@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/d6/c6/6e2589271a512c1b190952b8b810d351e8f415f9d7ee102530f9f0e677b0/nkocr-2.5.1.tar.gz",
"platform": null,
"description": "# Nkocr: The OCR tool for nutritional tables\n\n\n\n[](https://badge.fury.io/py/nkocr)\n[](https://github.com/Lucs1590/Nkocr/blob/master/LICENSE)\n\n\n\n[](https://www.codefactor.io/repository/github/lucs1590/nkocr)\n[](https://codecov.io/gh/Lucs1590/Nkocr)\n[](https://colab.research.google.com/github/Lucs1590/Nkocr/blob/master/ocr_table.ipynb)\n\n[](https://twitter.com/intent/tweet?text=try%20to%20apply%20OCR%20techniques%20on%20a%20nutritional%20table%20with%20Nkocr&url=https://github.com/Lucs1590/Nkocr&hashtags=ocr,github,opensource,developer,dev)\n\nThis is a module to make specifics OCRs at food products and nutritional tables.\n\n# Contents\n\n- [Prerequisites](#prerequisites)\n - [Tesseract OCR](#tesseract)\n - [OpenCV](#opencv)\n- [Installation](#install)\n - [Pip](#pip)\n - [Conda](#conda)\n- [Usage](#usage)\n - [Example](#example)\n- [Under the Hood](#uth)\n - [Choosing the Language](#lang)\n - [Pipeline](#pipeline)\n- [Supporting](#sup)\n\n# \ud83d\udcdd Prerequisites <a id=\"prerequisites\"></a>\n\nAs a prerequisite of this project, we have the [tesseract library](https://github.com/tesseract-ocr/tesseract) and [OpenCV](https://docs.opencv.org/master/da/df6/tutorial_py_table_of_contents_setup.html), so next we will install this pre\u00dfsites.\n\n## Tesseract OCR <a id=\"tesseract\"></a>\n\nThe installation of tesseract on the **Linux** system can be done in a few commands:\n\n```bash\nsudo apt install tesseract-ocr libtesseract-dev\n```\n\nAnd the same goes for **macOS**. There is a variation between MacPorts and Homebrew, but in this post I will only quote the version of Homebrew:\n\n```bash\nbrew install tesseract\n```\n\nAfter performing the tesseract installation, it is possible to perform OCR in just one command, thus already extracting some words from the image.\n\n## OpenCV <a id=\"opencv\"></a>\n\nThe installation of opencv on the **Linux** system can be done in a command:\n\n```bash\nsudo apt install python3-opencv\n```\n\nAnd to **macOS** running the following command:\n\n```bash\nbrew install opencv\n```\n\n# \u2699\ufe0f Installation <a id=\"install\"></a>\n\nNow, assuming the prerequisites have already been installed, you're ready to install the Nkocr environment to modify, contribute and work!\n\n**But, if you just want to use the project, go to the [usage](#usage) part.**\n\n## Pip <a id=\"pip\"></a>\n\nYou can install the project requirements in a Python environment by running:\n\n```bash\npip install -r requirements.txt --user\n```\n\n## Conda <a id=\"conda\"></a>\n\nBut if you are used to using a conda environment to keep everything organized, or if you want to test using it this time, feel free to run the following command and have a unique environment for Nkocr.\n\n```bash\nconda env create -f environment.yml\n```\n\n# \ud83d\udc68\u200d\ud83d\udcbb Usage <a id=\"usage\"></a>\n\nTo use this package, it's very easy, first you need to install it by running:\n\n```bash\npip install nkocr --user\n```\n\nAnd after installing, you can import the packages in a Python script like the example below.\n\n```python\nfrom nkocr import OcrTable, OcrProduct\n```\n\n## Example <a id=\"example\"></a>\n\nTo make it even easier, below is an example of code snippet.\n\n```python\nfrom nkocr import OcrTable\n\ntext = OcrTable(\"paste_image_url_here\")\nprint(text) # or print(text.text)\n```\n\n# \u2139\ufe0f Under the Hood <a id=\"uth\"></a>\n\nFrom now on we will be talking about a little more technical details of the library.\n\n## Changing Language <a id=\"lang\"></a>\n\nThe default language is English, so depending on the text, it will not be possible to capture the desired words / phrases.\nTherefore, if you want to work with another language, you will need to make some changes inherent to the language that the algorithm executes.\n\nThe first thing is to download the desired language with tesseract support, and on Linux this can be done by running the following command:\nDon't forget to change ```<lang>``` with the desired language. If you would like more details, please feel free to access the [tesseract documentation](https://github.com/tesseract-ocr/tessdoc/blob/master/Data-Files-in-different-versions.md).\n\n```bash\nsudo apt install tesseract-ocr-<lang>\n```\n\nIf you are a macOS user, your command will be a little different. You will need to run the following command, and don't worry about the language, after running this command you will have access to all languages.\n\n```bash\nbrew install tesseract-lang\n```\n\nAfter downloading the support languages, to perform the translations in the desired language you will have to change the code in the [ocr_product.py](https://github.com/Lucs1590/Nkocr/blob/cdf0024850617bf24261ad1b028b5b924ae96720/src/ocr_product.py#L13), [ocr_table.py](https://github.com/Lucs1590/Nkocr/blob/cdf0024850617bf24261ad1b028b5b924ae96720/src/ocr_table.py#L15) and [auxiliary.py](https://github.com/Lucs1590/Nkocr/blob/a6c2cd045edfb12f664a8832b1349b1e1dc4b00f/src/auxiliary.py#L349).\n\n## Operating Pipeline <a id=\"pipeline\"></a>\n\nThe main algorithm was built working, mainly, with structures and methods of computer vision and digital image processing. The image below clearly depicts the line followed for the operational pipeline combinations.\n\n\n\n# \ud83e\udd1d Supporting <a id=\"sup\"></a>\n\nMany hours of hard work have gone into this project. Your support will be very appreciated!\n\n<a href=\"https://www.buymeacoffee.com/Lucs1590\" target=\"_blank\"><img src=\"https://www.buymeacoffee.com/assets/img/custom_images/orange_img.png\" alt=\"Buy Me A Coffee\" style=\"height: auto !important;width: auto !important;\" ></a>\n",
"bugtrack_url": null,
"license": "Apache License 2.0",
"summary": "This is a module to make specifics OCRs at food products and nutricional tables.",
"version": "2.5.1",
"project_urls": {
"Download": "https://github.com/Lucs1590/Nkocr",
"Homepage": "https://github.com/Lucs1590/Nkocr"
},
"split_keywords": [
"ocr",
" tesseract-ocr",
" nk",
" python3",
" python-3",
" food-products"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "a3e88946f98601965cf7d54b49aaae7fe9608d779920a307a78460d304f597c4",
"md5": "05ba25216de3ca02310d4e58e337f314",
"sha256": "9af2aec5e63f848d65ec6d2d58b7a32bf584d96f1a341b4ca346edcbb51ec768"
},
"downloads": -1,
"filename": "nkocr-2.5.1-py3-none-any.whl",
"has_sig": false,
"md5_digest": "05ba25216de3ca02310d4e58e337f314",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.6",
"size": 17282,
"upload_time": "2024-10-25T18:08:48",
"upload_time_iso_8601": "2024-10-25T18:08:48.084436Z",
"url": "https://files.pythonhosted.org/packages/a3/e8/8946f98601965cf7d54b49aaae7fe9608d779920a307a78460d304f597c4/nkocr-2.5.1-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "d6c66e2589271a512c1b190952b8b810d351e8f415f9d7ee102530f9f0e677b0",
"md5": "cafd782fb47e25ad72c94a80829de282",
"sha256": "5a759baecbb837e234301e66a533d7b21b2647e8cf34f8b91337956ec46d24d0"
},
"downloads": -1,
"filename": "nkocr-2.5.1.tar.gz",
"has_sig": false,
"md5_digest": "cafd782fb47e25ad72c94a80829de282",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.6",
"size": 84958360,
"upload_time": "2024-10-25T18:08:51",
"upload_time_iso_8601": "2024-10-25T18:08:51.082850Z",
"url": "https://files.pythonhosted.org/packages/d6/c6/6e2589271a512c1b190952b8b810d351e8f415f9d7ee102530f9f0e677b0/nkocr-2.5.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-10-25 18:08:51",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "Lucs1590",
"github_project": "Nkocr",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"requirements": [
{
"name": "tesseract",
"specs": [
[
"==",
"0.1.3"
]
]
},
{
"name": "pytesseract",
"specs": [
[
"==",
"0.3.10"
]
]
},
{
"name": "requests",
"specs": [
[
"==",
"2.32.0"
]
]
},
{
"name": "wheel",
"specs": [
[
"==",
"0.43.*"
]
]
},
{
"name": "Pillow",
"specs": [
[
">=",
"10.2.0"
]
]
},
{
"name": "numpy",
"specs": [
[
"==",
"1.26.0"
]
]
},
{
"name": "opencv-contrib-python",
"specs": [
[
"==",
"4.10.0.84"
]
]
},
{
"name": "scikit-learn",
"specs": [
[
"==",
"1.5.0"
]
]
},
{
"name": "gdown",
"specs": [
[
"==",
"5.1.0"
]
]
},
{
"name": "pytest-socket",
"specs": [
[
"==",
"0.6.0"
]
]
},
{
"name": "imutils",
"specs": [
[
"==",
"0.5.4"
]
]
},
{
"name": "symspellpy",
"specs": [
[
"==",
"6.7.7"
]
]
},
{
"name": "commitizen",
"specs": [
[
"==",
"3.10.0"
]
]
},
{
"name": "pre-commit",
"specs": [
[
"==",
"3.4.0"
]
]
}
],
"tox": true,
"lcname": "nkocr"
}

