| Name | nodevectors JSON |
| Version |
0.2.0
 JSON
JSON |
| download |
| home_page | https://github.com/VHRanger/nodevectors/ |
| Summary | Fast network node embeddings |
| upload_time | 2024-12-25 18:39:44 |
| maintainer | None |
| docs_url | None |
| author | Matt Ranger |
| requires_python | >=3.12 |
| license | MIT License Copyright (c) 2018 YOUR NAME Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. |
| keywords |
graph
network
embedding
node2vec
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
csrgraph
gensim
networkx
numba
numpy
pandas
scipy
scikit-learn
|
| Travis-CI |

|
| coveralls test coverage |
No coveralls.
|
[](https://travis-ci.com/VHRanger/nodevectors)
This package implements fast/scalable node embedding algorithms. This can be used to embed the nodes in graph objects and arbitrary scipy [CSR Sparse Matrices](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.html). We support [NetworkX](https://networkx.github.io/) graph types natively.
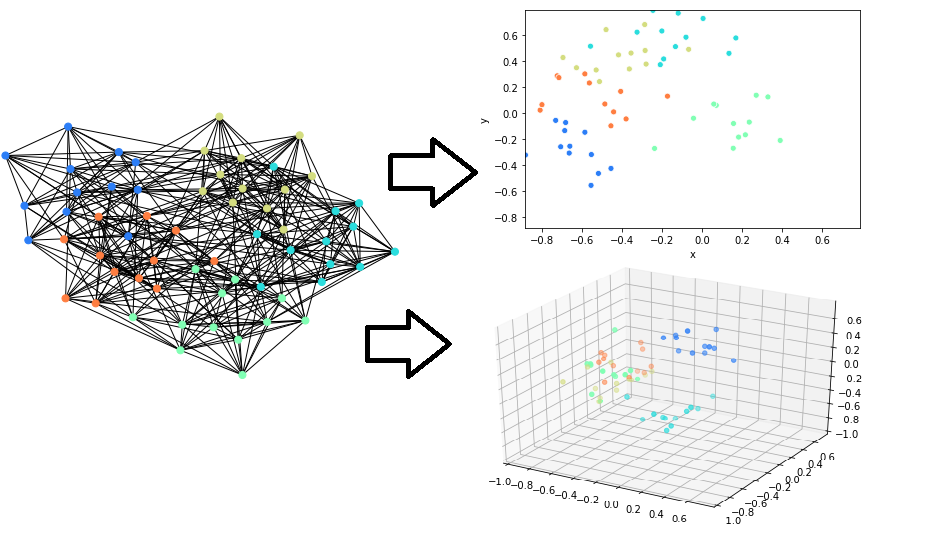
## Installing
`pip install nodevectors`
This package depends on the [CSRGraphs](https://github.com/VHRanger/CSRGraph) package, which is automatically installed along it using pip. Most development happens there, so running `pip install --upgrade csrgraph` once in a while can update the underlying graph library.
## Supported Algorithms
- [Node2Vec](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/node2vec.py) ([paper](https://cs.stanford.edu/~jure/pubs/node2vec-kdd16.pdf)). Note that despite popularity this isn't always the best method. We recommend trying ProNE or GGVec if you run into issues.
- [GGVec](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/ggvec.py) (paper upcoming). A flexible default algorithm. Best on large graphs and for visualization.
- [ProNE](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/prone.py) ([paper](https://www.ijcai.org/Proceedings/2019/0594.pdf)). The fastest and most reliable sparse matrix/graph embedding algorithm.
- [GraRep](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/grarep.py) ([paper](https://dl.acm.org/doi/pdf/10.1145/2806416.2806512))
- [GLoVe](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/glove.py) ([paper](https://nlp.stanford.edu/pubs/glove.pdf)). This is useful to embed sparse matrices of positive counts, like word co-occurence.
- Any [Scikit-Learn API model](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/embedders.py#L127) that supports the `fit_transform` method with the `n_component` attribute (eg. all [manifold learning](https://scikit-learn.org/stable/modules/manifold.html#manifold) models, [UMAP](https://github.com/lmcinnes/umap), etc.). Used with the `SKLearnEmbedder` object.
## Quick Example:
```python
import networkx as nx
from nodevectors import Node2Vec
# Test Graph
G = nx.generators.classic.wheel_graph(100)
# Fit embedding model to graph
g2v = Node2Vec(
n_components=32,
walklen=10
)
# way faster than other node2vec implementations
# Graph edge weights are handled automatically
g2v.fit(G)
# query embeddings for node 42
g2v.predict(42)
# Save and load whole node2vec model
# Uses a smart pickling method to avoid serialization errors
# Don't put a file extension after the `.save()` filename, `.zip` is automatically added
g2v.save('node2vec')
# You however need to specify the extension when reading it back
g2v = Node2Vec.load('node2vec.zip')
# Save model to gensim.KeyedVector format
g2v.save_vectors("wheel_model.bin")
# load in gensim
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format("wheel_model.bin")
model[str(43)] # need to make nodeID a str for gensim
```
**Warning:** Saving in Gensim format is only supported for the Node2Vec model at this point. Other models build a `Dict` or embeddings.
## Embedding a large graph
NetworkX doesn't support large graphs (>500,000 nodes) because it uses lots of memory for each node. We recommend using [CSRGraphs](https://github.com/VHRanger/CSRGraph) (which is installed with this package) to load the graph in memory:
```python
import csrgraph as cg
import nodevectors
G = cg.read_edgelist("path_to_file.csv", directed=False, sep=',')
ggvec_model = nodevectors.GGVec()
embeddings = ggvec_model.fit_transform(G)
```
The `read_edgelist` can take all the file-reading parameters of [pandas.read_csv](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html). You can also specify whether the graph is **undirected** (so all edges go both ways) or **directed** (so edges are one-way)
**Best algorithms to embed a large graph**
The ProNE and GGVec algorithms are the fastest. GGVec uses the least RAM to embed larger graphs. Additionally here are some recommendations:
- Don't use the `return_weight` and `neighbor_weight` if you are using the Node2Vec algorithm. It necessarily makes the walk generation step 40x-100x slower.
- If you are using GGVec, keep `order` at 1. Using higher order embeddings will take quadratically more time. Additionally, keep `negative_ratio` low (~0.05-0.1), `learning_rate` high (~0.1), and use aggressive early stopping values. GGVec generally only needs a few (less than 100) epochs to get most of the embedding quality you need.
- If you are using ProNE, keep the `step` parameter low.
- If you are using GraRep, keep the default embedder (TruncatedSVD) and keep the order low (1 or 2 at most).
## Preprocessing to visualize large graphs
You can use our algorithms to preprocess data for algorithms like [UMAP](https://github.com/lmcinnes/umap) or T-SNE. You can first embed the graph to 16-400 dimensions then use these embeddings in the final visualization algorithm.
Here is an example of this on the full english Wikipedia link graph (6M nodes) by [Owen Cornec](http://byowen.com):

The GGVec algorithm often produces the best visualizations, but can have some numerical instability with very high `n_components` or too high `negative_ratio`. Node2Vec tends to produce elongated and filamented structures in the visualizations due to the embedding graph being sampled on random walks.
## Embedding a VERY LARGE graph
(Upcoming).
GGVec can be used to learn embeddings directly from an edgelist file (or stream) when the `order` parameter is constrained to be 1. This means you can embed arbitrarily large graphs without ever loading them entirely into RAM.
## Related Projects
- [DGL](https://github.com/dmlc/dgl) for Graph Neural networks.
- [KarateClub](https://github.com/benedekrozemberczki/KarateClub) for node embeddings specifically on NetworkX graphs. The implementations are less scalable, because of it, but the package has more types of embedding algorithms.
- [GraphVite](https://github.com/DeepGraphLearning/graphvite) is not a python package but has GPU-enabled embedding algorithm implementations.
- [Cleora](https://github.com/Synerise/cleora), another fast/scalable node embedding algorithm implementation
## Why is it so fast?
We leverage [CSRGraphs](https://github.com/VHRanger/CSRGraph) for most algorithms. This uses CSR graph representations and a lot of Numba JIT'ed procedures.
Raw data
{
"_id": null,
"home_page": "https://github.com/VHRanger/nodevectors/",
"name": "nodevectors",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.12",
"maintainer_email": null,
"keywords": "graph, network, embedding, node2vec",
"author": "Matt Ranger",
"author_email": "Matt Ranger <matt@singlelunch.com>",
"download_url": "https://files.pythonhosted.org/packages/9d/c9/e3f5d80849c4a8e34eafd1d908f08407a809fb74f8116dd170bb5196999a/nodevectors-0.2.0.tar.gz",
"platform": null,
"description": "[](https://travis-ci.com/VHRanger/nodevectors)\n\nThis package implements fast/scalable node embedding algorithms. This can be used to embed the nodes in graph objects and arbitrary scipy [CSR Sparse Matrices](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.html). We support [NetworkX](https://networkx.github.io/) graph types natively.\n\n\n\n## Installing\n\n`pip install nodevectors`\n\nThis package depends on the [CSRGraphs](https://github.com/VHRanger/CSRGraph) package, which is automatically installed along it using pip. Most development happens there, so running `pip install --upgrade csrgraph` once in a while can update the underlying graph library.\n\n## Supported Algorithms\n\n- [Node2Vec](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/node2vec.py) ([paper](https://cs.stanford.edu/~jure/pubs/node2vec-kdd16.pdf)). Note that despite popularity this isn't always the best method. We recommend trying ProNE or GGVec if you run into issues.\n\n- [GGVec](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/ggvec.py) (paper upcoming). A flexible default algorithm. Best on large graphs and for visualization.\n\n- [ProNE](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/prone.py) ([paper](https://www.ijcai.org/Proceedings/2019/0594.pdf)). The fastest and most reliable sparse matrix/graph embedding algorithm.\n\n- [GraRep](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/grarep.py) ([paper](https://dl.acm.org/doi/pdf/10.1145/2806416.2806512))\n\n- [GLoVe](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/glove.py) ([paper](https://nlp.stanford.edu/pubs/glove.pdf)). This is useful to embed sparse matrices of positive counts, like word co-occurence.\n\n- Any [Scikit-Learn API model](https://github.com/VHRanger/nodevectors/blob/master/nodevectors/embedders.py#L127) that supports the `fit_transform` method with the `n_component` attribute (eg. all [manifold learning](https://scikit-learn.org/stable/modules/manifold.html#manifold) models, [UMAP](https://github.com/lmcinnes/umap), etc.). Used with the `SKLearnEmbedder` object.\n\n## Quick Example:\n```python\nimport networkx as nx\nfrom nodevectors import Node2Vec\n\n# Test Graph\nG = nx.generators.classic.wheel_graph(100)\n\n# Fit embedding model to graph\ng2v = Node2Vec(\n n_components=32,\n walklen=10\n)\n# way faster than other node2vec implementations\n# Graph edge weights are handled automatically\ng2v.fit(G)\n\n# query embeddings for node 42\ng2v.predict(42)\n\n# Save and load whole node2vec model\n# Uses a smart pickling method to avoid serialization errors\n# Don't put a file extension after the `.save()` filename, `.zip` is automatically added\ng2v.save('node2vec')\n# You however need to specify the extension when reading it back\ng2v = Node2Vec.load('node2vec.zip')\n\n# Save model to gensim.KeyedVector format\ng2v.save_vectors(\"wheel_model.bin\")\n\n# load in gensim\nfrom gensim.models import KeyedVectors\nmodel = KeyedVectors.load_word2vec_format(\"wheel_model.bin\")\nmodel[str(43)] # need to make nodeID a str for gensim\n\n```\n\n**Warning:** Saving in Gensim format is only supported for the Node2Vec model at this point. Other models build a `Dict` or embeddings.\n\n## Embedding a large graph\n\nNetworkX doesn't support large graphs (>500,000 nodes) because it uses lots of memory for each node. We recommend using [CSRGraphs](https://github.com/VHRanger/CSRGraph) (which is installed with this package) to load the graph in memory:\n\n```python\nimport csrgraph as cg\nimport nodevectors\n\nG = cg.read_edgelist(\"path_to_file.csv\", directed=False, sep=',')\nggvec_model = nodevectors.GGVec() \nembeddings = ggvec_model.fit_transform(G)\n```\n\nThe `read_edgelist` can take all the file-reading parameters of [pandas.read_csv](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html). You can also specify whether the graph is **undirected** (so all edges go both ways) or **directed** (so edges are one-way)\n\n**Best algorithms to embed a large graph**\n\nThe ProNE and GGVec algorithms are the fastest. GGVec uses the least RAM to embed larger graphs. Additionally here are some recommendations:\n\n- Don't use the `return_weight` and `neighbor_weight` if you are using the Node2Vec algorithm. It necessarily makes the walk generation step 40x-100x slower.\n\n- If you are using GGVec, keep `order` at 1. Using higher order embeddings will take quadratically more time. Additionally, keep `negative_ratio` low (~0.05-0.1), `learning_rate` high (~0.1), and use aggressive early stopping values. GGVec generally only needs a few (less than 100) epochs to get most of the embedding quality you need.\n\n- If you are using ProNE, keep the `step` parameter low.\n\n- If you are using GraRep, keep the default embedder (TruncatedSVD) and keep the order low (1 or 2 at most).\n\n## Preprocessing to visualize large graphs\n\nYou can use our algorithms to preprocess data for algorithms like [UMAP](https://github.com/lmcinnes/umap) or T-SNE. You can first embed the graph to 16-400 dimensions then use these embeddings in the final visualization algorithm. \n\nHere is an example of this on the full english Wikipedia link graph (6M nodes) by [Owen Cornec](http://byowen.com):\n\n\n\nThe GGVec algorithm often produces the best visualizations, but can have some numerical instability with very high `n_components` or too high `negative_ratio`. Node2Vec tends to produce elongated and filamented structures in the visualizations due to the embedding graph being sampled on random walks.\n\n## Embedding a VERY LARGE graph\n\n(Upcoming).\n\nGGVec can be used to learn embeddings directly from an edgelist file (or stream) when the `order` parameter is constrained to be 1. This means you can embed arbitrarily large graphs without ever loading them entirely into RAM.\n\n## Related Projects\n\n- [DGL](https://github.com/dmlc/dgl) for Graph Neural networks.\n\n- [KarateClub](https://github.com/benedekrozemberczki/KarateClub) for node embeddings specifically on NetworkX graphs. The implementations are less scalable, because of it, but the package has more types of embedding algorithms.\n\n- [GraphVite](https://github.com/DeepGraphLearning/graphvite) is not a python package but has GPU-enabled embedding algorithm implementations. \n\n- [Cleora](https://github.com/Synerise/cleora), another fast/scalable node embedding algorithm implementation\n\n## Why is it so fast?\n\nWe leverage [CSRGraphs](https://github.com/VHRanger/CSRGraph) for most algorithms. This uses CSR graph representations and a lot of Numba JIT'ed procedures.\n",
"bugtrack_url": null,
"license": "MIT License Copyright (c) 2018 YOUR NAME Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.",
"summary": "Fast network node embeddings",
"version": "0.2.0",
"project_urls": {
"Home Page": "https://github.com/VHRanger/nodevectors/",
"Homepage": "https://github.com/VHRanger/nodevectors/",
"github": "https://github.com/VHRanger/nodevectors/"
},
"split_keywords": [
"graph",
" network",
" embedding",
" node2vec"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "96ba53e8668350df3033fbbf654133d9880304be3eb6a2f2752a9c99cc4215d6",
"md5": "5bdbccd65d7f4513275b195ddbd24fb0",
"sha256": "48f53a11c847f91b597cce9ca191b75941415bbeb47f1e3968f13ce07a7a861e"
},
"downloads": -1,
"filename": "nodevectors-0.2.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "5bdbccd65d7f4513275b195ddbd24fb0",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.12",
"size": 22220,
"upload_time": "2024-12-25T18:39:43",
"upload_time_iso_8601": "2024-12-25T18:39:43.091533Z",
"url": "https://files.pythonhosted.org/packages/96/ba/53e8668350df3033fbbf654133d9880304be3eb6a2f2752a9c99cc4215d6/nodevectors-0.2.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "9dc9e3f5d80849c4a8e34eafd1d908f08407a809fb74f8116dd170bb5196999a",
"md5": "cecb70d3e7c447cfa62a39089efef44e",
"sha256": "1a376c12b839b942946d34009e002146af97429b1a7ff3d6030587deef0501ef"
},
"downloads": -1,
"filename": "nodevectors-0.2.0.tar.gz",
"has_sig": false,
"md5_digest": "cecb70d3e7c447cfa62a39089efef44e",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.12",
"size": 22765,
"upload_time": "2024-12-25T18:39:44",
"upload_time_iso_8601": "2024-12-25T18:39:44.358255Z",
"url": "https://files.pythonhosted.org/packages/9d/c9/e3f5d80849c4a8e34eafd1d908f08407a809fb74f8116dd170bb5196999a/nodevectors-0.2.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-12-25 18:39:44",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "VHRanger",
"github_project": "nodevectors",
"travis_ci": true,
"coveralls": false,
"github_actions": false,
"requirements": [
{
"name": "csrgraph",
"specs": []
},
{
"name": "gensim",
"specs": []
},
{
"name": "networkx",
"specs": [
[
"==",
"2.5.1"
]
]
},
{
"name": "numba",
"specs": []
},
{
"name": "numpy",
"specs": []
},
{
"name": "pandas",
"specs": []
},
{
"name": "scipy",
"specs": []
},
{
"name": "scikit-learn",
"specs": []
}
],
"lcname": "nodevectors"
}
