English | [中文](README_CN.md)
# pdf2docx-headless

[](https://pypi.python.org/pypi/pdf2docx/)


- Extract data from PDF with `PyMuPDF`, e.g. text, images and drawings
- Parse layout with rule, e.g. sections, paragraphs, images and tables
- Generate docx with `python-docx`
## Difference to original pdf2docx
**Important**: This package is a fork of the original package, using `opencv-python-headless` as dependency instead of `opencv-python` to remove any gui dependencies.
[Reference issue](https://github.com/opencv/opencv-python/issues/370)
## Features
- Parse and re-create page layout
- page margin
- section and column (1 or 2 columns only)
- page header and footer [TODO]
- Parse and re-create paragraph
- OCR text [TODO]
- text in horizontal/vertical direction: from left to right, from bottom to top
- font style, e.g. font name, size, weight, italic and color
- text format, e.g. highlight, underline, strike-through
- list style [TODO]
- external hyper link
- paragraph horizontal alignment (left/right/center/justify) and vertical spacing
- Parse and re-create image
- in-line image
- image in Gray/RGB/CMYK mode
- transparent image
- floating image, i.e. picture behind text
- Parse and re-create table
- border style, e.g. width, color
- shading style, i.e. background color
- merged cells
- vertical direction cell
- table with partly hidden borders
- nested tables
- Parsing pages with multi-processing
*It can also be used as a tool to extract table contents since both table content and format/style is parsed.*
## Limitations
- Text-based PDF file
- Left to right language
- Normal reading direction, no word transformation / rotation
- Rule-based method can't 100% convert the PDF layout
## Documentation
- [Installation](https://dothinking.github.io/pdf2docx/installation.html)
- [Quickstart](https://dothinking.github.io/pdf2docx/quickstart.html)
- [Convert PDF](https://dothinking.github.io/pdf2docx/quickstart.convert.html)
- [Extract table](https://dothinking.github.io/pdf2docx/quickstart.table.html)
- [Command Line Interface](https://dothinking.github.io/pdf2docx/quickstart.cli.html)
- [Technical Documentation (In Chinese)](https://dothinking.github.io/pdf2docx/techdoc.html)
- [API Documentation](https://dothinking.github.io/pdf2docx/modules.html)
## Sample
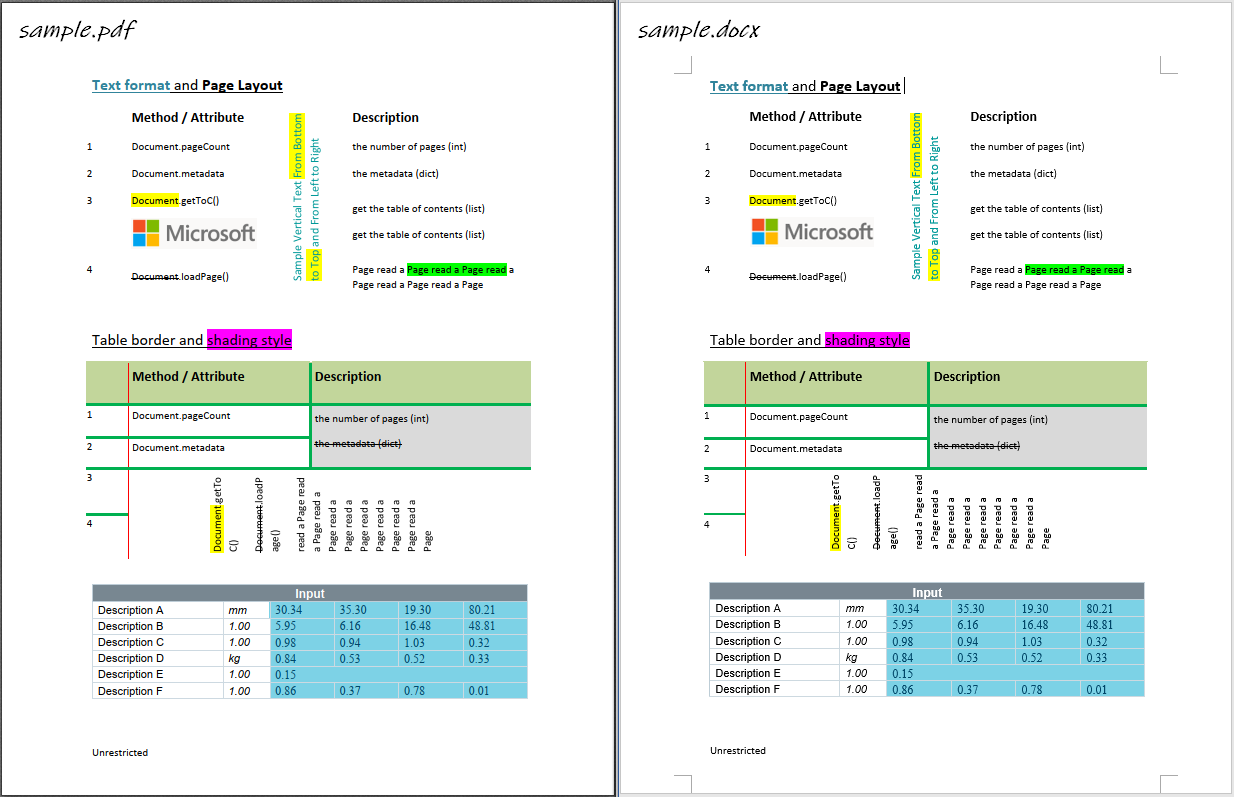
Raw data
{
"_id": null,
"home_page": "https://github.com/embiem/pdf2docx-headless",
"name": "pdf2docx-headless",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.6",
"maintainer_email": "",
"keywords": "pdf-to-word,pdf-to-docx",
"author": "embiem",
"author_email": "mbeierling@gmail.com",
"download_url": "https://files.pythonhosted.org/packages/25/2d/8eb130ef597fdd141e2c7df6bb54f5396e59451cc32b66c773f76ec34263/pdf2docx-headless-0.5.8.tar.gz",
"platform": null,
"description": "English | [\u4e2d\u6587](README_CN.md)\n\n# pdf2docx-headless \n\n\n[](https://pypi.python.org/pypi/pdf2docx/)\n\n\n\n- Extract data from PDF with `PyMuPDF`, e.g. text, images and drawings \n- Parse layout with rule, e.g. sections, paragraphs, images and tables\n- Generate docx with `python-docx`\n\n## Difference to original pdf2docx\n\n**Important**: This package is a fork of the original package, using `opencv-python-headless` as dependency instead of `opencv-python` to remove any gui dependencies.\n\n[Reference issue](https://github.com/opencv/opencv-python/issues/370)\n\n\n## Features\n\n- Parse and re-create page layout\n - page margin\n - section and column (1 or 2 columns only)\n - page header and footer [TODO]\n\n- Parse and re-create paragraph\n - OCR text [TODO]\n - text in horizontal/vertical direction: from left to right, from bottom to top\n - font style, e.g. font name, size, weight, italic and color\n - text format, e.g. highlight, underline, strike-through\n - list style [TODO]\n - external hyper link\n - paragraph horizontal alignment (left/right/center/justify) and vertical spacing\n \n- Parse and re-create image\n\t- in-line image\n - image in Gray/RGB/CMYK mode\n - transparent image\n - floating image, i.e. picture behind text\n\n- Parse and re-create table\n - border style, e.g. width, color\n - shading style, i.e. background color\n - merged cells\n - vertical direction cell\n - table with partly hidden borders\n - nested tables\n\n- Parsing pages with multi-processing\n\n*It can also be used as a tool to extract table contents since both table content and format/style is parsed.*\n\n## Limitations\n\n- Text-based PDF file\n- Left to right language\n- Normal reading direction, no word transformation / rotation\n- Rule-based method can't 100% convert the PDF layout\n\n\n## Documentation\n\n- [Installation](https://dothinking.github.io/pdf2docx/installation.html)\n- [Quickstart](https://dothinking.github.io/pdf2docx/quickstart.html)\n - [Convert PDF](https://dothinking.github.io/pdf2docx/quickstart.convert.html)\n - [Extract table](https://dothinking.github.io/pdf2docx/quickstart.table.html)\n - [Command Line Interface](https://dothinking.github.io/pdf2docx/quickstart.cli.html)\n- [Technical Documentation (In Chinese)](https://dothinking.github.io/pdf2docx/techdoc.html)\n- [API Documentation](https://dothinking.github.io/pdf2docx/modules.html)\n\n## Sample\n\n\n",
"bugtrack_url": null,
"license": "GPL v3",
"summary": "Open source Python library converting pdf to docx.",
"version": "0.5.8",
"project_urls": {
"Homepage": "https://github.com/embiem/pdf2docx-headless"
},
"split_keywords": [
"pdf-to-word",
"pdf-to-docx"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "da51da326bf6ec481c63e8c23de31f5b04dfc20ae1337d5177b41d9eb988d12e",
"md5": "0baf3b538647755a8fc8667856c2743b",
"sha256": "1e471d78f0e7e34b4527f74393189a13335c254858f4258c939eec3689ad7522"
},
"downloads": -1,
"filename": "pdf2docx_headless-0.5.8-py3-none-any.whl",
"has_sig": false,
"md5_digest": "0baf3b538647755a8fc8667856c2743b",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.6",
"size": 129038,
"upload_time": "2023-11-02T10:44:20",
"upload_time_iso_8601": "2023-11-02T10:44:20.605349Z",
"url": "https://files.pythonhosted.org/packages/da/51/da326bf6ec481c63e8c23de31f5b04dfc20ae1337d5177b41d9eb988d12e/pdf2docx_headless-0.5.8-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "252d8eb130ef597fdd141e2c7df6bb54f5396e59451cc32b66c773f76ec34263",
"md5": "8db039ef6cf30419add126fa07a8ed65",
"sha256": "ce7f499a6bad84543f6c37e18668d11b1b413bc0866d37f037196cf5383e70df"
},
"downloads": -1,
"filename": "pdf2docx-headless-0.5.8.tar.gz",
"has_sig": false,
"md5_digest": "8db039ef6cf30419add126fa07a8ed65",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.6",
"size": 3064399,
"upload_time": "2023-11-02T10:44:22",
"upload_time_iso_8601": "2023-11-02T10:44:22.374120Z",
"url": "https://files.pythonhosted.org/packages/25/2d/8eb130ef597fdd141e2c7df6bb54f5396e59451cc32b66c773f76ec34263/pdf2docx-headless-0.5.8.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-11-02 10:44:22",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "embiem",
"github_project": "pdf2docx-headless",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"requirements": [
{
"name": "PyMuPDF",
"specs": [
[
">=",
"1.19.0"
]
]
},
{
"name": "python-docx",
"specs": [
[
">=",
"0.8.10"
]
]
},
{
"name": "fonttools",
"specs": [
[
">=",
"4.24.0"
]
]
},
{
"name": "numpy",
"specs": [
[
">=",
"1.17.2"
]
]
},
{
"name": "opencv-python",
"specs": [
[
">=",
"4.5"
]
]
},
{
"name": "fire",
"specs": [
[
">=",
"0.3.0"
]
]
}
],
"lcname": "pdf2docx-headless"
}

