<h1 align="center">ray-haystack</h1>
<p align="center">Run <a href="https://docs.haystack.deepset.ai/docs/intro"><i>Haystack Pipelines</i></a> on <a href="https://docs.ray.io/en/latest/ray-overview/getting-started.html"><i>Ray</i></a>.</p>
<p align="center">
<a href="https://github.com/prosto/ray-haystack/actions?query=workflow%3Aci">
<img alt="ci" src="https://github.com/prosto/ray-haystack/workflows/ci/badge.svg" />
</a>
<a href="https://pypi.org/project/ray-haystack/">
<img alt="pypi version" src="https://img.shields.io/pypi/v/ray-haystack.svg" />
</a>
<a href="https://img.shields.io/pypi/pyversions/ray-haystack.svg">
<img alt="python version" src="https://img.shields.io/pypi/pyversions/ray-haystack.svg" />
</a>
<a href="https://pypi.org/project/haystack-ai/">
<img alt="haystack version" src="https://img.shields.io/pypi/v/haystack-ai.svg?label=haystack" />
</a>
</p>
---
- [Overview](#overview)
- [Installation](#installation)
- [Usage](#usage)
- [Start with an example](#start-with-an-example)
- [Read pipeline events](#read-pipeline-events)
- [Component Serialization](#component-serialization)
- [DocumentStore with Ray](#documentstore-with-ray)
- [RayPipeline Settings](#raypipeline-settings)
- [Middleware](#middleware)
- [More Examples](#more-examples)
- [Trace Ray Pipeline execution in Browser](#trace-ray-pipeline-execution-in-browser)
- [Ray Pipeline on Kubernetes](#ray-pipeline-on-kubernetes)
- [Ray Pipeline with detached components](#ray-pipeline-with-detached-components)
- [Next Steps \& Enhancements](#next-steps--enhancements)
- [Acknowledgments](#acknowledgments)
## Overview
`ray-haystack` is a python package which allows running [Haystack pipelines](https://docs.haystack.deepset.ai/docs/pipelines) on [Ray](https://docs.ray.io/en/latest/ray-overview/index.html)
in distributed manner. The package provides same API to build and run Haystack pipelines but under the hood components are being distributed to remote nodes for execution using Ray primitives.
Specifically [Ray Actor](https://docs.ray.io/en/latest/ray-core/actors.html) is created for each component in a pipeline to `run` its logic.
The purpose of this library is to showcase the ability to run Haystack in a distributed setup with Ray featuring its options to configure the payload, e.g:
- Control with [resources](https://docs.ray.io/en/latest/ray-core/scheduling/resources.html) how much CPU/GPU is needed for a component to run (per each component if needed)
- Manage [environment dependencies](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html) for components to run on dedicated machines.
- Run pipeline on Kubernetes using [KubeRay](https://docs.ray.io/en/latest/cluster/kubernetes/getting-started.html)
Most of the times you will run Haystack pipelines on your local environment, even in production you will want to run pipeline on a single node in case the goal is to quickly return response to the user without overhead you would usually get with distributed setup. However in case of long running and complex RAG pipelines distributed way might help:
- Not every component needs GPU, most will use some external API calls. With Ray it should be possible to assign respective resource requirements (CPU, RAM) per component execution needs.
- Some components might take longer to run, so ideally if there should be an option to parallelize component execution it should decrease pipeline run time.
- With asynchronous execution it should be possible to interact with different component execution stages (e.g. fire an event before and after component starts).
`ray-haystack` provides a custom implementation for pipeline execution logic with the goal to stay **as complaint as possible with native Haystack implementation**.
You should expect in most cases same results (outputs) from pipeline runs. On top of that the package will parallelize component runs where possible.
Components with no active dependencies can be scheduled without waiting for currently running components.
<p align="center">
<img width="500" height="400" src="https://raw.githubusercontent.com/prosto/ray-haystack/main/docs/pipeline-watch-anime.gif">
</p>
## Installation
`ray-haystack` can be installed as any other Python library, using pip:
```shell
pip install ray-haystack
```
The package should work with python version 3.8 and onwards. If you plan to use `ray-haystack` with an existing Ray cluster make sure you align python and `ray` versions with those running in the cluster.
> **Note**
> The `ray-haystack` package will install both `haystack-ai` and `ray` as transitive dependencies. The minimum supported version of haystack is `2.6.0`. [`mergedeep`](https://pypi.org/project/mergedeep/) is also used internally to merge pipeline settings.
If you would like to see [Ray dashboard](https://docs.ray.io/en/latest/ray-observability/getting-started.html) when starting Ray cluster locally install Ray as follows:
```shell
pip install -U "ray[default]"
pip install ray-haystack
```
While pipeline is running locally access the dashboard in browser at [http://localhost:8265](http://localhost:8265).
## Usage
### Start with an example
Once `ray-haystack` is installed lets demonstrate how it works by running a simple example.
We will build a pipeline that fetches RSS news headlines from the list of given urls, converts each headline to a `Document` with content equal to the title of the headline. We then asks LLM (`OpenAIGenerator`) to create news summary from the list of converted Documents and given prompt `template`.
```python
import io
import os
from typing import List, Optional
from xml.etree.ElementTree import parse as parse_xml
import ray # Import ray
from haystack import Document, component
from haystack.components.builders import PromptBuilder
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.generators import OpenAIGenerator
from haystack.components.joiners import DocumentJoiner
from haystack.dataclasses import ByteStream
from ray_haystack import RayPipeline # Import RayPipeline (instead of `from haystack import Pipeline`)
# Please introduce your OpenAI Key here
os.environ["OPENAI_API_KEY"] = "You OpenAI Key"
@component
class XmlConverter:
"""
Custom component which parses given RSS feed (from ByteStream) and extracts values by a
given XPath, e.g. ".//channel/item/title" will find "title" for each RSS feed item.
A Document is created for each extracted title. The `category` attribute can be used as
an additional metadata field.
"""
def __init__(self, xpath: str = ".//channel/item/title", category: Optional[str] = None):
self.xpath = xpath
self.category = category
@component.output_types(documents=List[Document])
def run(self, sources: List[ByteStream]):
documents: List[Document] = []
for source in sources:
xml_content = io.StringIO(source.to_string())
documents.extend(
Document(content=elem.text, meta={"category": self.category})
for elem in parse_xml(xml_content).findall(self.xpath) # noqa: S314
if elem.text
)
return {"documents": documents}
template = """
Given news headlines below provide a summary of what is happening in the world right now in a couple of sentences.
You will be given headline titles in the following format: "<headline category>: <headline title>".
When creating summary pay attention to common news headlines as those could be most insightful.
HEADLINES:
{% for document in documents %}
{{ document.meta["category"] }}: {{ document.content }}
{% endfor %}
SUMMARY:
"""
# Create instance of Ray pipeline
pipeline = RayPipeline()
pipeline.add_component("tech-news-fetcher", LinkContentFetcher())
pipeline.add_component("business-news-fetcher", LinkContentFetcher())
pipeline.add_component("politics-news-fetcher", LinkContentFetcher())
pipeline.add_component("tech-xml-converter", XmlConverter(category="tech"))
pipeline.add_component("business-xml-converter", XmlConverter(category="business"))
pipeline.add_component("politics-xml-converter", XmlConverter(category="politics"))
pipeline.add_component("document_joiner", DocumentJoiner(sort_by_score=False))
pipeline.add_component("prompt_builder", PromptBuilder(template=template))
pipeline.add_component("generator", OpenAIGenerator()) # "gpt-4o-mini" is the default model
pipeline.connect("tech-news-fetcher", "tech-xml-converter.sources")
pipeline.connect("business-news-fetcher", "business-xml-converter.sources")
pipeline.connect("politics-news-fetcher", "politics-xml-converter.sources")
pipeline.connect("tech-xml-converter", "document_joiner")
pipeline.connect("business-xml-converter", "document_joiner")
pipeline.connect("politics-xml-converter", "document_joiner")
pipeline.connect("document_joiner", "prompt_builder")
pipeline.connect("prompt_builder", "generator.prompt")
# Draw pipeline and save it to `pipe.png`
# pipeline.draw("pipe.png")
# Start local Ray cluster
ray.init()
# Prepare pipeline inputs by specifying RSS urls for each fetcher
pipeline_inputs = {
"tech-news-fetcher": {
"urls": [
"https://www.theverge.com/rss/frontpage/",
"https://techcrunch.com/feed",
"https://cnet.com/rss/news",
"https://wired.com/feed/rss",
]
},
"business-news-fetcher": {
"urls": [
"https://search.cnbc.com/rs/search/combinedcms/view.xml?partnerId=wrss01&id=10001147",
"https://www.business-standard.com/rss/home_page_top_stories.rss",
"https://feeds.a.dj.com/rss/WSJcomUSBusiness.xml",
]
},
"politics-news-fetcher": {
"urls": [
"https://search.cnbc.com/rs/search/combinedcms/view.xml?partnerId=wrss01&id=10000113",
"https://rss.nytimes.com/services/xml/rss/nyt/Politics.xml",
]
},
}
# Run pipeline with inputs
result = pipeline.run(pipeline_inputs)
# Print response from LLM
print("RESULT: ", result["generator"]["replies"][0])
```
Can you notice the difference between native Haystack pipelines? Lets try to spot some of them:
- we import `ray` module
- we import `RayPipeline` (from `ray_haystack`) instead of `Pipeline` class from `haystack`
- before running the pipeline we start [local ray cluster](https://docs.ray.io/en/latest/ray-core/starting-ray.html#start-ray-init) with explicit `ray.init()` call (btw its not necessary as Ray `init` will automatically be called on the first use of a Ray remote API.)
If you change `RayPipeline` to native `Pipeline` implementation from Haystack you should get same results.
What happens under the hood? Is there a difference? Well, yes, lets summarize it in the following diagram:
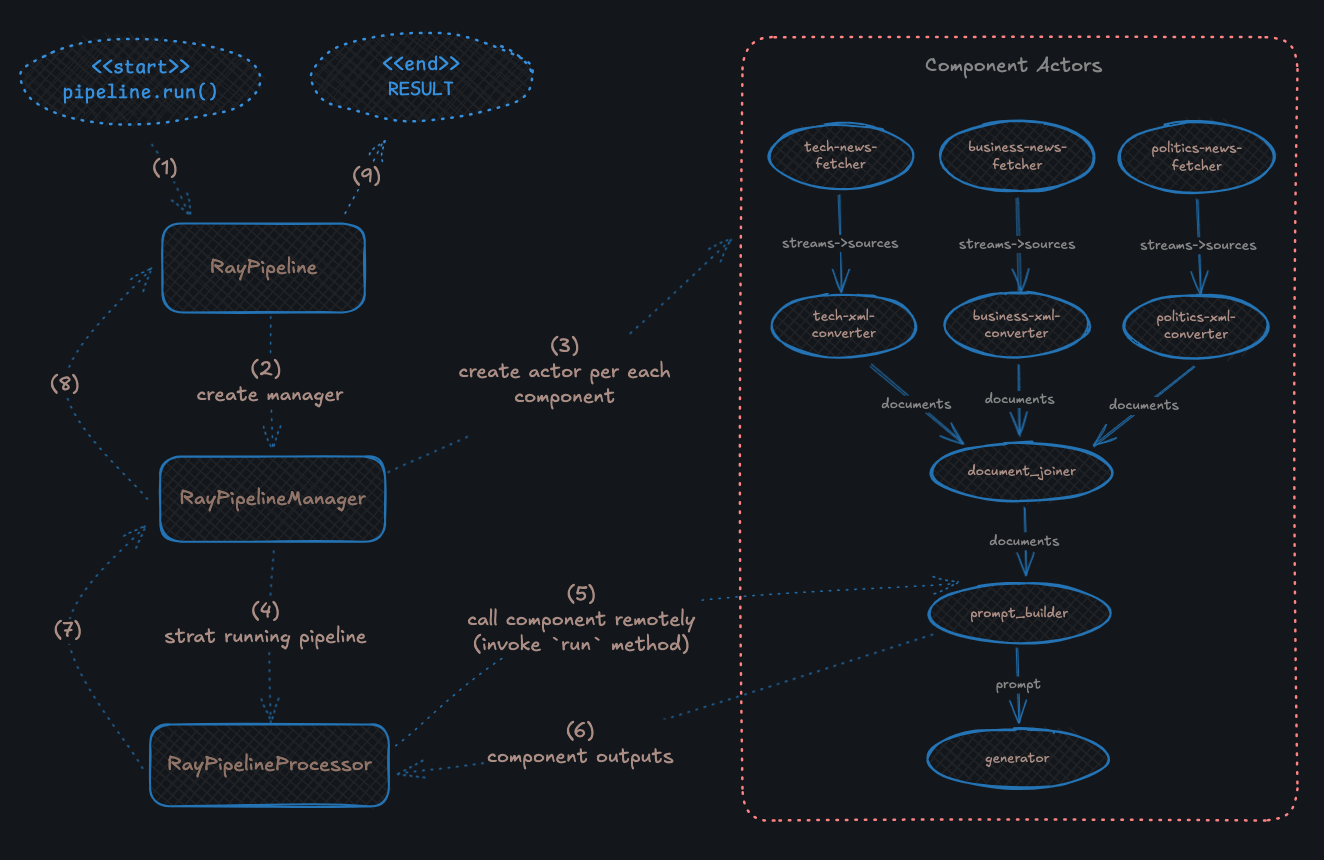
1. `RayPipeline` is started (same as native Haystack) with `pipeline.run` call
2. `RayPipelineManager` class is responsible for creating [actors](https://docs.ray.io/en/latest/ray-core/actors.html) per each component in the pipeline. It also maintains a graph representation of the pipeline (same way as native Haystack pipeline does internally)
3. Component actors are created with configurable options:
- Each actor can be a different process on same machine or a remote node (e.g. pod in kubernetes)
- Component is serialized using `to_dict` before traveling through network/process boundaries
- When actor is created component is instantiated (de-serialized) with `from_dict`
- Each actor can be configured with [options](https://docs.ray.io/en/latest/ray-core/api/doc/ray.actor.ActorClass.options.html) if needed. For example lifetime of the actor can be controlled with options, by default when pipeline finishes actors are destroyed
4. `RayPipelineProcessor` is the main module of the `ray-haystack` package and is responsible for traversing execution graph of the pipeline. It keeps track of what needs to be run next and stores outputs from each component until pipeline finishes its execution
- The processor is effectively workflow execution engine which respects rules of how Haystack pipelines should run. It does not reuse logic with native Haystack implementation because it allows parallelization where possible as well as pipeline events. For example in the diagram it is evident that fetcher components can start running at the same time (same for converters when connected fetcher finishes execution)
- Thee processor is itself a Ray Actor as it coordinates component execution logic asynchronously and keeps intermediate running state (e.g. component inputs/outputs)
5. `RayPipelineProcessor` calls component remotely with prepared inputs in case it is ready to run (has enough inputs)
- in case component needs `warm_up`, the actor calls it once during its lifetime
- internally Ray serializes component inputs using Pickle before calling actor's remote `run` method, so the expectation will be that input parameters are serializable
6. Once component actor finishes execution its outputs are stored in `RayPipelineProcessor` so that later on we could return results back to user
7. Results are composed out of stored component outputs and returned back to `RayPipelineManager`. **Please notice at this point we are not waiting for all components to finish but rather return deferred results as `RayPipelineProcessor` continues its execution**
8. `RayPipelineManager` prepares outputs which can be consumed by `RayPipeline`
9. `RayPipeline` will wait (usually block) until `RayPipelineProcessor` has no components to run. The output dictionary will be returned to the user.
### Read pipeline events
In some cases you would want to asynchronously react to particular pipeline execution points:
- when pipeline starts
- before component runs
- after component finishes
- after pipeline finishes
Internally `RayPipelineManager` creates an instance of [Ray Queue](https://docs.ray.io/en/latest/ray-core/api/doc/ray.util.queue.Queue.html) where such events are being stored and consumed from.
Except standard `run` method `RayPipeline` provides a method called `run_nowait` which returns pipeline execution result without blocking current logic:
```python
result = pipeline.run_nowait(pipeline_inputs)
# A non-blocking call, `pipeline_output_ref` is a reference
print("Object Ref", result.pipeline_output_ref)
# Will block until pipeline finishes and returns outputs
print("Result", ray.get(result.pipeline_output_ref))
```
`pipeline_output_ref` is a reference to pipeline outputs, see [Objects](https://docs.ray.io/en/latest/ray-core/objects.html) documentation for more details.
> **Note**
> Internally `run` calls `run_nowait` and uses `ray.get` to wait for pipeline to finish.
Apart from `pipeline_output_ref` there is another option to obtain results from pipeline execution but with much more details:
```python
result = pipeline.run_nowait(pipeline_inputs)
for pipeline_event in result.pipeline_events_sync():
# For better viewing experience inputs/outputs are truncated
# but you can comment out/remove lines below (before `print`)
# if you would like to see full event data set
if pipeline_event.type == "ray.haystack.pipeline-start":
pipeline_event.data["pipeline_inputs"] = "{...}"
if pipeline_event.type == "ray.haystack.component-start":
pipeline_event.data["input"] = "{...}"
if pipeline_event.type == "ray.haystack.component-end":
pipeline_event.data["output"] = "{...}"
print(
f"\n>>> [{pipeline_event.time}] Source: {pipeline_event.source} | Type: {pipeline_event.type} | Data={pipeline_event.data}"
)
```
Below is a sample output you should be able to see if you run the code above:
```bash
>>> [2024-10-09T22:16:27.073665+00:00] Source: ray-pipeline-processor | Type: ray.haystack.pipeline-start | Data={'pipeline_inputs': '{...}', 'runnable_nodes': ['business-news-fetcher', 'politics-news-fetcher', 'tech-news-fetcher']}
>>> [2024-10-09T22:16:27.535254+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-start | Data={'name': 'business-news-fetcher', 'sender_name': None, 'input': '{...}', 'iteration': 0}
>>> [2024-10-09T22:16:27.537959+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-start | Data={'name': 'politics-news-fetcher', 'sender_name': None, 'input': '{...}', 'iteration': 0}
>>> [2024-10-09T22:16:27.540466+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-start | Data={'name': 'tech-news-fetcher', 'sender_name': None, 'input': '{...}', 'iteration': 0}
>>> [2024-10-09T22:16:28.939877+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-end | Data={'name': 'politics-news-fetcher', 'output': '{...}', 'iteration': 0}
>>> [2024-10-09T22:16:28.944781+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-start | Data={'name': 'politics-xml-converter', 'sender_name': 'politics-news-fetcher', 'input': '{...}', 'iteration': 0}
```
> **Note**
> You can access directly the events queue and then use your own events listening logic.
```python
result = pipeline.run_nowait(pipeline_inputs)
# Wait for just one event and return
result.events_queue.get(block=True)
```
With available [Queue methods](https://docs.ray.io/en/latest/ray-core/api/doc/ray.util.queue.Queue.html) you should be able to implement `async` processing logic (see `get_async` method). The [pipeline_watch example](https://github.com/prosto/ray-haystack/blob/main/examples/pipeline_watch/README.md) actually uses `async` to read events from the queue and deliver those to browser as soon as event is available (using Server Sent Events)
### Component Serialization
As we saw earlier in the diagram when you run pipeline with `RayPipeline` each component gets serialized and then de-serialized when instantiated within an actor.
If you run native Haystack pipeline locally component remain in the same python process and there is no reason to care about distributed setup.
However in order for component to become available across boundaries we should be able to create instance of component based on its definition - much like you would have a [saved pipeline definition](https://docs.haystack.deepset.ai/docs/serialization) and then send it to some backend service for invocation. Ray distributes payload and should be able to [serialize](https://docs.ray.io/en/latest/ray-core/objects/serialization.html) objects before they end up in remote task or actor.
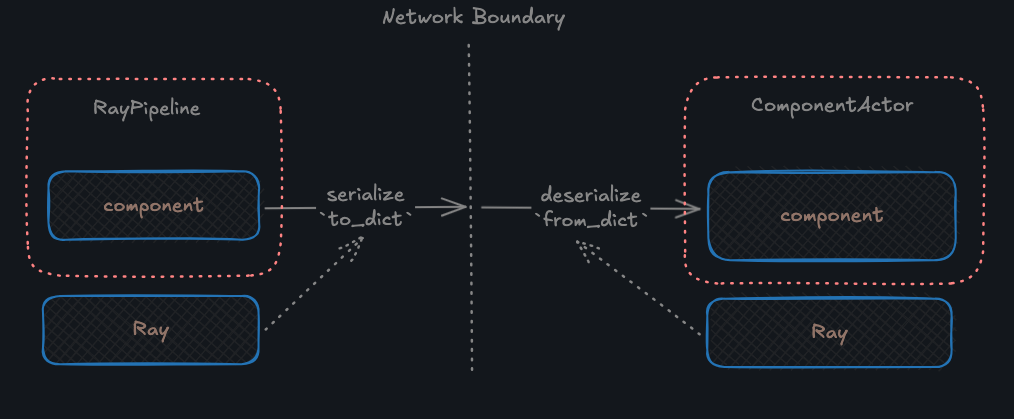
We could rely on default serialization behavior provided by Ray, but the trick is not every Haystack component (custom or provided) is going to be serializable with `pickle5 + cloudpickle` (e.g. document store connection etc). So we have to rely on what Haystack requires from each component as per protocol - `to_dict` and `from_dict` methods. **Any component that you intend to use with `RayPipeline` should have those methods defined and working as expected.**
There is another issue when it comes to component deserialization on a remote task or actor in Ray - whatever python package/module a component depends on should be available during component creation or invocation. This brings us to a relatively complex topic about [environment dependencies](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#concepts) in Ray. **You should read the documentation and plan accordingly before decide to deploy your pipeline to a fully fledged production setup.** In most of the cases you will be able to run and test pipelines with `RayPipeline` without noticing how Ray tries to bring in component's environment dependencies into remote actor. See [pipeline_kubernetes example](/examples/pipeline_kubernetes/README.md) for a simple demonstration of running pipeline on a pristine KubeRay cluster in kubernetes.
Lets see when serialization will become an issue by running the following example:
```python
import io
from typing import List
from xml.etree.ElementTree import parse as parse_xml
import ray
from haystack import Document
from haystack.components.converters import OutputAdapter
from haystack.components.fetchers import LinkContentFetcher
from haystack.dataclasses import ByteStream
from ray_haystack import RayPipeline
from ray_haystack.serialization import worker_asset
# Uncomment to fix the serialization issue
# @worker_asset
def parse_sources(sources: List[ByteStream]) -> List[Document]:
documents: List[Document] = []
for source in sources:
xml_content = io.StringIO(source.to_string())
documents.extend(
Document(content=elem.text)
for elem in parse_xml(xml_content).findall(".//channel/item/title") # noqa: S314
if elem.text
)
return documents
pipeline = RayPipeline()
pipeline.add_component("tech-news-fetcher", LinkContentFetcher())
pipeline.add_component(
"adapter",
OutputAdapter(
template="{{ sources | parse_sources }}",
output_type=List[Document],
custom_filters={"parse_sources": parse_sources},
),
)
pipeline.connect("tech-news-fetcher", "adapter.sources")
pipeline.draw("pipe.png")
pipeline_inputs = {
"tech-news-fetcher": {
"urls": [
"https://techcrunch.com/feed",
"https://cnet.com/rss/news",
]
},
}
ray.init()
result = pipeline.run(pipeline_inputs)
print("RESULT: ", result["adapter"]["output"])
```
The pipeline above is a simple one - first fetch RSS feed contents and then parse and extract documents from it using `OutputAdapter`. However we would get the following error:
```text
File ".../ray_haystack/serialization/component_wrapper.py", line 48, in __init__
self._component = component_from_dict(component_class, component_data, None)
File ".../haystack/core/serialization.py", line 118, in component_from_dict
return do_from_dict()
File ".../haystack/core/serialization.py", line 113, in do_from_dict
return cls.from_dict(data)
File ".../haystack/components/converters/output_adapter.py", line 170, in from_dict
init_params["custom_filters"] = {
File ".../haystack/components/converters/output_adapter.py", line 171, in <dictcomp>
name: deserialize_callable(filter_func) if filter_func else None
File ".../haystack/utils/callable_serialization.py", line 45, in deserialize_callable
raise DeserializationError(f"Could not locate the callable: {function_name}")
haystack.core.errors.DeserializationError: Could not locate the callable: parse_sources
```
Seems like the `parse_sources` function was not available to python interpreter during de-serialization of the `OutputAdapter` component. In order to understand what happens under the hood lets see how the component looks like in a serialized format:
```python
{
'type': 'haystack.components.converters.output_adapter.OutputAdapter',
'init_parameters': {
'template': '{{ sources | parse_sources }}',
'output_type': 'typing.List[haystack.dataclasses.document.Document]',
'custom_filters': {'parse_sources': '__main__.parse_sources'},
'unsafe': False
}
}
```
When component is deserialized the `__main__.parse_sources` function is not present in a remote Ray actor anymore. Which is understandable because we have not instructed Ray to push any module or package which contains the `parse_sources` function in it. (Moreover Ray's worker node which runs component actor has its own `__main__` module and `parse_sources` is not defined there).
To fix the issue what we need to import `worker_asset` decorator from `ray_haystack.serialization` package and apply the decorator to the `parse_sources` function. Please uncomment the decorator fix in the example and run the pipeline again. You should see Documents as a result.
`worker_asset` instructs serialization process to bring in the `parse_sources` function along with the component so that when it deserialized `parse_sources` is imported.
> **Important**
> Please use `@worker_asset` whenever you encounter issues with components like `OutputAdapter` where some functions are referenced by a component. Make sure you do not use lambdas but rather a dedicated python function with the decorator in place.
### DocumentStore with Ray
Unfortunately when you use [InMemoryDocumentStore](https://docs.haystack.deepset.ai/docs/inmemorydocumentstore) or any DocumentStore which runs in-memory (a singleton) with `RayPipeline` you will stumble upon an apparent issue: in distributed environment such DocumentStore will fail to operate as components which reference the store will not point to single instance but rather a copy of it.
`ray-haystack` package provides a wrapper around `InMemoryDocumentStore` by implementing a proxy pattern so that only a single instance of `InMemoryDocumentStore` across Ray cluster is present. With that pipeline components could share a single store. Use `RayInMemoryDocumentStore`, `RayInMemoryEmbeddingRetriever` or `RayInMemoryBM25Retriever` in case you need in-memory document store in your Ray pipelines. See below a conceptual diagram of how components refer to a single instance of the store:
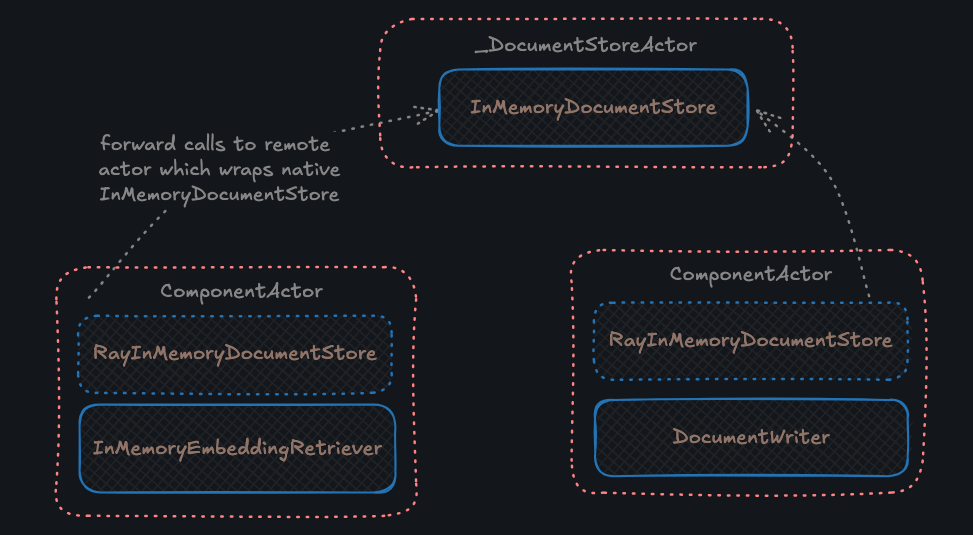
Whenever you create `RayInMemoryDocumentStore` internally an actor is created which wraps native `InMemoryDocumentStore` and acts as a singleton in cluster. `RayInMemoryDocumentStore` forwards calls to the remote actor.
Lets see it in action by running the [basic RAG pipeline](https://haystack.deepset.ai/tutorials/27_first_rag_pipeline).
Before running the script make sure additional dependencies have been installed:
```bash
pip install "datasets>=2.6.1"
pip install "sentence-transformers>=3.0.0"
```
```python
import os
import ray
from datasets import load_dataset
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack.components.embedders import (
SentenceTransformersDocumentEmbedder,
SentenceTransformersTextEmbedder,
)
from haystack.components.generators import OpenAIGenerator
from haystack.dataclasses import Document
from haystack.document_stores.types import DocumentStore
from ray_haystack.components import (
RayInMemoryDocumentStore,
RayInMemoryEmbeddingRetriever,
)
from ray_haystack.ray_pipeline import RayPipeline
os.environ["OPENAI_API_KEY"] = "Your OPenAI API Key"
def prepare_document_store(document_store: DocumentStore):
doc_embedder = SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
doc_embedder.warm_up()
dataset = load_dataset("bilgeyucel/seven-wonders", split="train")
docs = [Document(content=doc["content"], meta=doc["meta"]) for doc in dataset]
docs_with_embeddings = doc_embedder.run(docs)
document_store.write_documents(docs_with_embeddings["documents"])
template = """
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
# Start Ray cluster before defining `RayInMemoryDocumentStore` as internally it creates an actor
ray.init()
document_store = RayInMemoryDocumentStore() # from `ray-haystack`
# Create documents in document_store
prepare_document_store(document_store)
text_embedder = SentenceTransformersTextEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
retriever = RayInMemoryEmbeddingRetriever(document_store) # from `ray-haystack`
generator = OpenAIGenerator()
prompt_builder = PromptBuilder(template=template)
pipeline = RayPipeline()
pipeline.add_component("text_embedder", text_embedder)
pipeline.add_component("retriever", retriever)
pipeline.add_component("prompt_builder", prompt_builder)
pipeline.add_component("llm", generator)
pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
pipeline.connect("retriever", "prompt_builder.documents")
pipeline.connect("prompt_builder", "llm")
question = "What does Rhodes Statue look like?"
response = pipeline.run(
{
"text_embedder": {"text": question},
"prompt_builder": {"question": question},
}
)
print("RESULT: ", response["llm"]["replies"][0])
```
Please notice the components imported from the `ray_haystack.components` package and how a single instance of the `RayInMemoryDocumentStore` is used for both indexing (`prepare_document_store`) and then querying (`pipeline.run`).
> **Important**
> Existing implementation of the `RayInMemoryDocumentStore` might be a subject to change in future. In case you would like to introduce or use another store which also works in-memory take a look at implementation of the components in the `ray_haystack.components` package. It should not take much time implementing your own wrapper by following the example.
### RayPipeline Settings
When an actor is created in Ray we can control its behavior by providing certain [settings](https://docs.ray.io/en/latest/ray-core/api/doc/ray.actor.ActorClass.options.html).
Some examples are provided below:
- num_cpus – The quantity of CPU cores to reserve for this task or for the lifetime of the actor.
- num_gpus – The quantity of GPUs to reserve for this task or for the lifetime of the actor.
- name – The globally unique name for the actor, which can be used to retrieve the actor via ray.get_actor(name) as long as the actor is still alive.
- runtime_env (Dict[str, Any]) – Specifies the runtime environment for this actor or task and its children.
- etc
[`runtime_env`](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#runtime-environments) is a notable configuration option as it can control which `pip` dependencies needs to be installed for actor to run, environment variables, container image to use in a cluster etc. In our case we are specifically interested in [Specifying a Runtime Environment Per-Task or Per-Actor](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#specifying-a-runtime-environment-per-task-or-per-actor)
As you have already learned when we run pipeline with `RayPipeline` a couple of actors are created before the pipeline starts running. To control actor's runtime environment as well as resources like CPU/GPU/RAM per actor you can use `ray_haystack.RayPipelineSettings` configuration dictionary.
Below is the definition of the dictionary (see the [source](https://github.com/prosto/ray-haystack/blob/main/src/ray_haystack/ray_pipeline_settings.py) for more details):
```python
class RayPipelineSettings(TypedDict, total=False):
common: CommonSettings # settings common for all actors within pipeline
processor: ProcessorSettings # settings for pipeline processor
components: CommonComponentSettings # settings common for all components, and per component
events_queue: EventsQueueSettings # settings for events_queue actor
# controls how settings are merged, e.g. "common" <- "common components" <- "component specific"
merge_strategy: Literal["REPLACE", "ADDITIVE", "TYPESAFE_REPLACE", "TYPESAFE_ADDITIVE"]
```
There are two options how `RayPipelineSettings` can be provided for `RayPipeline`:
```python
from typing import Any, Dict
from ray_haystack import RayPipeline, RayPipelineSettings
settings: RayPipelineSettings = {
"common": {
"actor_options": {
"namespace": "haystack", # common namespace name for all actors
}
},
"components": {
"per_component": {
"generator": {
"actor_options": {
"num_cpus": 2, # component specific CPU resource requirement
}
}
}
},
}
# Option 1 - Pass settings through pipeline's metadata
pipeline = RayPipeline(metadata={"ray": settings})
pipeline_inputs: Dict[str, Any] = {}
# Option 2 - Pass settings when in the `run` method
pipeline.run(pipeline_inputs, ray_settings=settings)
```
Above code highlights two ways to supply settings for a pipeline:
1. pipeline's `metadata` with key `"ray"`
2. directly as keyword argument in `run` method (will override settings from `metadata`)
Above example also demonstrates that it is possible to configure actor options per component and also define common options which will be shared between all actors created by `RayPipeline`. Actor options are being merged with component specific values taking precedence. Internally `mergedeep` python package is being used to merge dictionaries and you can control how merging works by picking [strategy](https://mergedeep.readthedocs.io/en/latest/#merge-strategies). Default one is `ADDITIVE`.
Lets build a small example of a pipeline which uses component specific environment variables:
```python
import os
import ray
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.generators import OpenAIGenerator
from ray_haystack import RayPipeline, RayPipelineSettings
os.environ["OPENAI_API_KEY"] = "OpenAI API Key Here"
prompt_template = """You will be given a JSON document containing data about a random cocktail recipe.
The data will include fields with name of the drink, its ingredients and instructions how to make it.
Build a cocktail description card in markdown format based on the fields present in the json.
Ignore fields with "null" values. Keep instruction as is.
JSON: {{cocktail_json[0]}}
Cocktail Card:
"""
# Setup environment for the whole cluster (each worker node will get env var OPENAI_TIMEOUT=15)
ray.init(runtime_env={"env_vars": {"OPENAI_TIMEOUT": "15"}})
fetcher = LinkContentFetcher()
prompt = PromptBuilder(template=prompt_template)
generator = OpenAIGenerator()
pipeline = RayPipeline()
pipeline.add_component("cocktail_fetcher", fetcher)
pipeline.add_component("prompt", prompt)
pipeline.add_component("llm", generator)
pipeline.connect("cocktail_fetcher.streams", "prompt.cocktail_json")
pipeline.connect("prompt", "llm.prompt")
settings: RayPipelineSettings = {
# common settings will be applied for all actors created
"common": {
"actor_options": {"namespace": "haystack"},
},
"components": {
# Applies OPENAI_TIMEOUT to all components in pipeline
"actor_options": {"runtime_env": {"env_vars": {"OPENAI_TIMEOUT": "10"}}},
"per_component": {
# "llm" component will get a new value for OPENAI_TIMEOUT overriding common settings
# so the final value for OPENAI_TIMEOUT environment variable is 11
"llm": {
"actor_options": {"runtime_env": {"env_vars": {"OPENAI_TIMEOUT": "11"}}},
},
},
},
}
response = pipeline.run(
{
"cocktail_fetcher": {"urls": ["https://www.thecocktaildb.com/api/json/v1/1/random.php"]},
},
ray_settings=settings, # pass settings to pipeline execution
)
print("RESULT: ", response["llm"]["replies"][0])
```
Please notice how `OPENAI_TIMEOUT` environment variable is set globally by `ray.init` and then with `RayPipelineSettings` it gets overridden specifically for the "llm" component.
> **Note**
> You may ask why didn't we provide `OPENAI_API_KEY` same way as `OPENAI_TIMEOUT` as in the example above. And the reason is hidden in the implementation of the `OpenAIGenerator` constructor which raises error if there is no value for the `OPENAI_API_KEY` env var. So `OPENAI_API_KEY` value is required before `RayPipeline` creates component actors when it starts.
Explore available options in [ray_pipeline_settings.py](https://github.com/prosto/ray-haystack/blob/main/src/ray_haystack/ray_pipeline_settings.py), `RayPipelineSettings` is just a python `TypedDict` which helps creating settings in your IDE of choice.
### Middleware
> **Warning**
> This feature is experimental and implementation details as well as API might change in future.
Sometimes it might be useful to let custom logic run before and after component actor runs the component:
- Fire a custom event and put it into events queue
- Tweak component inputs before they are sent to component
- Tweak component outputs before they are sent to other components (through connections)
- Additional logging/tracing
- Custom time delays in order to slow down component execution
- An external trigger which blocks component run until some event occurs
- Debugging breakpoints for components (e.g. stop component running until a trigger unblocks the breakpoint)
Above is just a high level vision of what I would expect middleware to do.
Lets build an example of how custom middleware can be introduced and applied. We will intercept `LinkContentFetcher` component and see the order of execution of middleware.
```python
from typing import Any, Literal
import ray
from haystack.components.fetchers import LinkContentFetcher
from ray_haystack import RayPipeline, RayPipelineSettings
from ray_haystack.middleware import ComponentMiddleware, ComponentMiddlewareContext
from ray_haystack.serialization import worker_asset
ray.init()
@worker_asset
class TraceMiddleware(ComponentMiddleware):
def __init__(self, capture: Literal["input", "output", "input_and_output"] = "input_and_output"):
self.capture = capture
def __call__(self, component_input, ctx: ComponentMiddlewareContext) -> Any:
print(f"Tracer: Before running component '{ctx['component_name']}' with inputs: '{component_input}'")
outputs = self.next(component_input, ctx)
print(f"Tracer: After running component '{ctx['component_name']}' with outputs: '{outputs}'")
return outputs
@worker_asset
class MessageMiddleware(ComponentMiddleware):
def __init__(self, message: str):
self.message = message
def __call__(self, component_input, ctx: ComponentMiddlewareContext) -> Any:
print(f"Message: Before running component '{ctx['component_name']}' : '{self.message}'")
outputs = self.next(component_input, ctx)
print(f"Message: After running component '{ctx['component_name']}' : '{self.message}'")
return outputs
pipeline = RayPipeline()
pipeline.add_component("cocktail_fetcher", LinkContentFetcher())
settings: RayPipelineSettings = {
"components": {
"per_component": {
# Middleware applies only to "cocktail_fetcher" component
"cocktail_fetcher": {
"middleware": {
"trace": {"type": "__main__.TraceMiddleware"},
"message": {
"type": "__main__.MessageMiddleware",
"init_parameters": {"message": "Hello Fetcher"},
},
},
},
}
},
}
response = pipeline.run(
{
"cocktail_fetcher": {"urls": ["https://www.thecocktaildb.com/api/json/v1/1/random.php"]},
},
ray_settings=settings,
)
```
Please notice the following from the example above:
- When defining custom middleware extend from `ComponentMiddleware` class. It provides a basic implementation of the `set_next` method. In case you do not want to extend from the base class make sure you implement `set_next` yourself
- Middleware is applied to a component in a pipeline with `RayPipelineSettings` (see `middleware` key in the dictionary)
- Middleware is applied by decorating the component's `run` method in the order it is defined in the settings dictionary
- "message" (before)
- "trace" (before)
- "trace" (after)
- "message" (after)
- `@worker_asset` decorator is applied to custom middleware so that during component actor creation Ray worker is able to deserialize (instantiate) middleware class. For example `"__main__.MessageMiddleware"` will be imported before creating instance of the `MessageMiddleware` class
As of now `ray-haystack` provides `DelayMiddleware` for adding time "sleeps" for components so that we could slow down all components or specific ones.
It was introduced to allow easier tracing experience when you consume events from events queue in order to see how components run in "slow motion". You can apply it aas follows:
```python
settings: RayPipelineSettings = {
"components": {
# Applies to all component in pipeline
"middleware": {
"delay": {
# full module path is required, will be used during deserialization in component actor
"type": "ray_haystack.middleware.delay_middleware.DelayMiddleware",
"init_parameters": {
"delay": 2, # default is 1
"delay_type": "before", # could be "after" or "before_and_after"
},
}
}
},
}
```
## More Examples
### Trace Ray Pipeline execution in Browser
[`pipeline_watch`](https://github.com/prosto/ray-haystack/blob/main/examples/pipeline_watch/README.md) is a sample application which runs Ray Pipelines with Ray Serve in backend and provides UI in browser to track running pipeline (component by component). It uses pipeline events which are streamed to browser using Server Sent Events. Please follow instructions inside the `pipeline-watch` folder in order to install and run the example.
Please check it out, you may like it!
### Ray Pipeline on Kubernetes
The ability to run Ray Pipeline on a remote Ray Cluster was an important step to test its "non-local" setup use case. The [`pipeline_kubernetes`](https://github.com/prosto/ray-haystack/blob/main/examples/pipeline_kubernetes/README.md) example provides instructions on how to install a local Ray Cluster by deploying KubeRay operator in Kubernetes and then run pipeline using [ray job submission SDK](https://docs.ray.io/en/latest/cluster/kubernetes/getting-started/raycluster-quick-start.html#method-2-submit-a-ray-job-to-the-raycluster-via-ray-job-submission-sdk)
### Ray Pipeline with detached components
Some of [Actor Options](https://docs.ray.io/en/latest/ray-core/api/doc/ray.actor.ActorClass.options.html) which are configurable per component can result in an interesting effect on how Ray Pipeline runs. One of such options is `lifetime`. When it is "detached" the actor will live as a global object independent of the creator, thus if `RayPipeline` finishes component actor will remain alive. [`pipeline_detached_actors`](https://github.com/prosto/ray-haystack/tree/main/examples/pipeline_detached_actors) explores such case and also runs pipeline in a Notebook.
## Next Steps & Enhancements
- [ ] Introduce logging configuration, e.g. control log level & format per component
- [ ] Better error handling in case pipeline output is consumed with pipeline events
- [ ] Create middleware to allow breakpoints in pipeline execution (stop at certain component until certain event is triggered)
- [ ] Write API documentation for main package components
- [ ] Introduce more tests for pipeline processing logic to cover more scenarios (e.g. complex cycles)
- [ ] Explore fault tolerance options and see what happens when certain parts fail during execution
- [ ] Explore the option of running Haystack pipeline on a Ray cluster with GPU available
- [ ] Improve DocumentStore proxy implementation so that other DocumentStores which run in-memory could be quickly adapted to `RayPipeline` without much boilerplate code
## Acknowledgments
I would have spent much more time testing pipeline execution logic if a [awesome testing suite](https://github.com/deepset-ai/haystack/tree/main/test/core/pipeline/features) was not available. I have adopted tests to make sure pipeline behavior is on par with Haystack. Thanks @silvanocerza for the tests and also clarifications on pipeline internals.
Raw data
{
"_id": null,
"home_page": null,
"name": "ray-haystack",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": null,
"keywords": "AI, Haystack, RAG, Ray, semantic-search",
"author": null,
"author_email": "Sergey Bondarenco <sergey.bondarenco@outlook.com>",
"download_url": "https://files.pythonhosted.org/packages/e3/55/9dc7adaa3a3301668b06e5561dbdc59e29e6cfb381dd8a43d18be018436f/ray_haystack-0.1.0.tar.gz",
"platform": null,
"description": "<h1 align=\"center\">ray-haystack</h1>\n\n<p align=\"center\">Run <a href=\"https://docs.haystack.deepset.ai/docs/intro\"><i>Haystack Pipelines</i></a> on <a href=\"https://docs.ray.io/en/latest/ray-overview/getting-started.html\"><i>Ray</i></a>.</p>\n\n<p align=\"center\">\n <a href=\"https://github.com/prosto/ray-haystack/actions?query=workflow%3Aci\">\n <img alt=\"ci\" src=\"https://github.com/prosto/ray-haystack/workflows/ci/badge.svg\" />\n </a>\n <a href=\"https://pypi.org/project/ray-haystack/\">\n <img alt=\"pypi version\" src=\"https://img.shields.io/pypi/v/ray-haystack.svg\" />\n </a>\n <a href=\"https://img.shields.io/pypi/pyversions/ray-haystack.svg\">\n <img alt=\"python version\" src=\"https://img.shields.io/pypi/pyversions/ray-haystack.svg\" />\n </a>\n <a href=\"https://pypi.org/project/haystack-ai/\">\n <img alt=\"haystack version\" src=\"https://img.shields.io/pypi/v/haystack-ai.svg?label=haystack\" />\n </a>\n</p>\n\n---\n\n- [Overview](#overview)\n- [Installation](#installation)\n- [Usage](#usage)\n - [Start with an example](#start-with-an-example)\n - [Read pipeline events](#read-pipeline-events)\n - [Component Serialization](#component-serialization)\n - [DocumentStore with Ray](#documentstore-with-ray)\n - [RayPipeline Settings](#raypipeline-settings)\n - [Middleware](#middleware)\n- [More Examples](#more-examples)\n - [Trace Ray Pipeline execution in Browser](#trace-ray-pipeline-execution-in-browser)\n - [Ray Pipeline on Kubernetes](#ray-pipeline-on-kubernetes)\n - [Ray Pipeline with detached components](#ray-pipeline-with-detached-components)\n- [Next Steps \\& Enhancements](#next-steps--enhancements)\n- [Acknowledgments](#acknowledgments)\n\n## Overview\n\n`ray-haystack` is a python package which allows running [Haystack pipelines](https://docs.haystack.deepset.ai/docs/pipelines) on [Ray](https://docs.ray.io/en/latest/ray-overview/index.html)\nin distributed manner. The package provides same API to build and run Haystack pipelines but under the hood components are being distributed to remote nodes for execution using Ray primitives.\nSpecifically [Ray Actor](https://docs.ray.io/en/latest/ray-core/actors.html) is created for each component in a pipeline to `run` its logic.\n\nThe purpose of this library is to showcase the ability to run Haystack in a distributed setup with Ray featuring its options to configure the payload, e.g:\n\n- Control with [resources](https://docs.ray.io/en/latest/ray-core/scheduling/resources.html) how much CPU/GPU is needed for a component to run (per each component if needed)\n- Manage [environment dependencies](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html) for components to run on dedicated machines.\n- Run pipeline on Kubernetes using [KubeRay](https://docs.ray.io/en/latest/cluster/kubernetes/getting-started.html)\n\nMost of the times you will run Haystack pipelines on your local environment, even in production you will want to run pipeline on a single node in case the goal is to quickly return response to the user without overhead you would usually get with distributed setup. However in case of long running and complex RAG pipelines distributed way might help:\n\n- Not every component needs GPU, most will use some external API calls. With Ray it should be possible to assign respective resource requirements (CPU, RAM) per component execution needs.\n- Some components might take longer to run, so ideally if there should be an option to parallelize component execution it should decrease pipeline run time.\n- With asynchronous execution it should be possible to interact with different component execution stages (e.g. fire an event before and after component starts).\n\n`ray-haystack` provides a custom implementation for pipeline execution logic with the goal to stay **as complaint as possible with native Haystack implementation**.\nYou should expect in most cases same results (outputs) from pipeline runs. On top of that the package will parallelize component runs where possible.\nComponents with no active dependencies can be scheduled without waiting for currently running components.\n\n<p align=\"center\">\n <img width=\"500\" height=\"400\" src=\"https://raw.githubusercontent.com/prosto/ray-haystack/main/docs/pipeline-watch-anime.gif\">\n</p>\n\n## Installation\n\n`ray-haystack` can be installed as any other Python library, using pip:\n\n```shell\npip install ray-haystack\n```\n\nThe package should work with python version 3.8 and onwards. If you plan to use `ray-haystack` with an existing Ray cluster make sure you align python and `ray` versions with those running in the cluster.\n\n> **Note**\n> The `ray-haystack` package will install both `haystack-ai` and `ray` as transitive dependencies. The minimum supported version of haystack is `2.6.0`. [`mergedeep`](https://pypi.org/project/mergedeep/) is also used internally to merge pipeline settings.\n\nIf you would like to see [Ray dashboard](https://docs.ray.io/en/latest/ray-observability/getting-started.html) when starting Ray cluster locally install Ray as follows:\n\n```shell\npip install -U \"ray[default]\"\npip install ray-haystack\n```\n\nWhile pipeline is running locally access the dashboard in browser at [http://localhost:8265](http://localhost:8265).\n\n## Usage\n\n### Start with an example\n\nOnce `ray-haystack` is installed lets demonstrate how it works by running a simple example.\n\nWe will build a pipeline that fetches RSS news headlines from the list of given urls, converts each headline to a `Document` with content equal to the title of the headline. We then asks LLM (`OpenAIGenerator`) to create news summary from the list of converted Documents and given prompt `template`.\n\n```python\nimport io\nimport os\nfrom typing import List, Optional\nfrom xml.etree.ElementTree import parse as parse_xml\n\nimport ray # Import ray\nfrom haystack import Document, component\nfrom haystack.components.builders import PromptBuilder\nfrom haystack.components.fetchers import LinkContentFetcher\nfrom haystack.components.generators import OpenAIGenerator\nfrom haystack.components.joiners import DocumentJoiner\nfrom haystack.dataclasses import ByteStream\n\nfrom ray_haystack import RayPipeline # Import RayPipeline (instead of `from haystack import Pipeline`)\n\n# Please introduce your OpenAI Key here\nos.environ[\"OPENAI_API_KEY\"] = \"You OpenAI Key\"\n\n@component\nclass XmlConverter:\n \"\"\"\n Custom component which parses given RSS feed (from ByteStream) and extracts values by a\n given XPath, e.g. \".//channel/item/title\" will find \"title\" for each RSS feed item.\n A Document is created for each extracted title. The `category` attribute can be used as\n an additional metadata field.\n \"\"\"\n\n def __init__(self, xpath: str = \".//channel/item/title\", category: Optional[str] = None):\n self.xpath = xpath\n self.category = category\n\n @component.output_types(documents=List[Document])\n def run(self, sources: List[ByteStream]):\n documents: List[Document] = []\n for source in sources:\n xml_content = io.StringIO(source.to_string())\n documents.extend(\n Document(content=elem.text, meta={\"category\": self.category})\n for elem in parse_xml(xml_content).findall(self.xpath) # noqa: S314\n if elem.text\n )\n return {\"documents\": documents}\n\ntemplate = \"\"\"\nGiven news headlines below provide a summary of what is happening in the world right now in a couple of sentences.\nYou will be given headline titles in the following format: \"<headline category>: <headline title>\".\nWhen creating summary pay attention to common news headlines as those could be most insightful.\n\nHEADLINES:\n{% for document in documents %}\n {{ document.meta[\"category\"] }}: {{ document.content }}\n{% endfor %}\n\nSUMMARY:\n\"\"\"\n\n# Create instance of Ray pipeline\npipeline = RayPipeline()\n\npipeline.add_component(\"tech-news-fetcher\", LinkContentFetcher())\npipeline.add_component(\"business-news-fetcher\", LinkContentFetcher())\npipeline.add_component(\"politics-news-fetcher\", LinkContentFetcher())\npipeline.add_component(\"tech-xml-converter\", XmlConverter(category=\"tech\"))\npipeline.add_component(\"business-xml-converter\", XmlConverter(category=\"business\"))\npipeline.add_component(\"politics-xml-converter\", XmlConverter(category=\"politics\"))\npipeline.add_component(\"document_joiner\", DocumentJoiner(sort_by_score=False))\npipeline.add_component(\"prompt_builder\", PromptBuilder(template=template))\npipeline.add_component(\"generator\", OpenAIGenerator()) # \"gpt-4o-mini\" is the default model\n\npipeline.connect(\"tech-news-fetcher\", \"tech-xml-converter.sources\")\npipeline.connect(\"business-news-fetcher\", \"business-xml-converter.sources\")\npipeline.connect(\"politics-news-fetcher\", \"politics-xml-converter.sources\")\npipeline.connect(\"tech-xml-converter\", \"document_joiner\")\npipeline.connect(\"business-xml-converter\", \"document_joiner\")\npipeline.connect(\"politics-xml-converter\", \"document_joiner\")\npipeline.connect(\"document_joiner\", \"prompt_builder\")\npipeline.connect(\"prompt_builder\", \"generator.prompt\")\n\n# Draw pipeline and save it to `pipe.png`\n# pipeline.draw(\"pipe.png\")\n\n# Start local Ray cluster\nray.init()\n\n# Prepare pipeline inputs by specifying RSS urls for each fetcher\npipeline_inputs = {\n \"tech-news-fetcher\": {\n \"urls\": [\n \"https://www.theverge.com/rss/frontpage/\",\n \"https://techcrunch.com/feed\",\n \"https://cnet.com/rss/news\",\n \"https://wired.com/feed/rss\",\n ]\n },\n \"business-news-fetcher\": {\n \"urls\": [\n \"https://search.cnbc.com/rs/search/combinedcms/view.xml?partnerId=wrss01&id=10001147\",\n \"https://www.business-standard.com/rss/home_page_top_stories.rss\",\n \"https://feeds.a.dj.com/rss/WSJcomUSBusiness.xml\",\n ]\n },\n \"politics-news-fetcher\": {\n \"urls\": [\n \"https://search.cnbc.com/rs/search/combinedcms/view.xml?partnerId=wrss01&id=10000113\",\n \"https://rss.nytimes.com/services/xml/rss/nyt/Politics.xml\",\n ]\n },\n}\n\n# Run pipeline with inputs\nresult = pipeline.run(pipeline_inputs)\n\n# Print response from LLM\nprint(\"RESULT: \", result[\"generator\"][\"replies\"][0])\n```\n\nCan you notice the difference between native Haystack pipelines? Lets try to spot some of them:\n\n- we import `ray` module\n- we import `RayPipeline` (from `ray_haystack`) instead of `Pipeline` class from `haystack`\n- before running the pipeline we start [local ray cluster](https://docs.ray.io/en/latest/ray-core/starting-ray.html#start-ray-init) with explicit `ray.init()` call (btw its not necessary as Ray `init` will automatically be called on the first use of a Ray remote API.)\n\nIf you change `RayPipeline` to native `Pipeline` implementation from Haystack you should get same results.\n\nWhat happens under the hood? Is there a difference? Well, yes, lets summarize it in the following diagram:\n\n\n\n1. `RayPipeline` is started (same as native Haystack) with `pipeline.run` call\n2. `RayPipelineManager` class is responsible for creating [actors](https://docs.ray.io/en/latest/ray-core/actors.html) per each component in the pipeline. It also maintains a graph representation of the pipeline (same way as native Haystack pipeline does internally)\n3. Component actors are created with configurable options:\n - Each actor can be a different process on same machine or a remote node (e.g. pod in kubernetes)\n - Component is serialized using `to_dict` before traveling through network/process boundaries\n - When actor is created component is instantiated (de-serialized) with `from_dict`\n - Each actor can be configured with [options](https://docs.ray.io/en/latest/ray-core/api/doc/ray.actor.ActorClass.options.html) if needed. For example lifetime of the actor can be controlled with options, by default when pipeline finishes actors are destroyed\n4. `RayPipelineProcessor` is the main module of the `ray-haystack` package and is responsible for traversing execution graph of the pipeline. It keeps track of what needs to be run next and stores outputs from each component until pipeline finishes its execution\n - The processor is effectively workflow execution engine which respects rules of how Haystack pipelines should run. It does not reuse logic with native Haystack implementation because it allows parallelization where possible as well as pipeline events. For example in the diagram it is evident that fetcher components can start running at the same time (same for converters when connected fetcher finishes execution)\n - Thee processor is itself a Ray Actor as it coordinates component execution logic asynchronously and keeps intermediate running state (e.g. component inputs/outputs)\n5. `RayPipelineProcessor` calls component remotely with prepared inputs in case it is ready to run (has enough inputs)\n - in case component needs `warm_up`, the actor calls it once during its lifetime\n - internally Ray serializes component inputs using Pickle before calling actor's remote `run` method, so the expectation will be that input parameters are serializable\n6. Once component actor finishes execution its outputs are stored in `RayPipelineProcessor` so that later on we could return results back to user\n7. Results are composed out of stored component outputs and returned back to `RayPipelineManager`. **Please notice at this point we are not waiting for all components to finish but rather return deferred results as `RayPipelineProcessor` continues its execution**\n8. `RayPipelineManager` prepares outputs which can be consumed by `RayPipeline`\n9. `RayPipeline` will wait (usually block) until `RayPipelineProcessor` has no components to run. The output dictionary will be returned to the user.\n\n### Read pipeline events\n\nIn some cases you would want to asynchronously react to particular pipeline execution points:\n\n- when pipeline starts\n- before component runs\n- after component finishes\n- after pipeline finishes\n\nInternally `RayPipelineManager` creates an instance of [Ray Queue](https://docs.ray.io/en/latest/ray-core/api/doc/ray.util.queue.Queue.html) where such events are being stored and consumed from.\n\nExcept standard `run` method `RayPipeline` provides a method called `run_nowait` which returns pipeline execution result without blocking current logic:\n\n```python\nresult = pipeline.run_nowait(pipeline_inputs)\n\n# A non-blocking call, `pipeline_output_ref` is a reference\nprint(\"Object Ref\", result.pipeline_output_ref)\n\n# Will block until pipeline finishes and returns outputs\nprint(\"Result\", ray.get(result.pipeline_output_ref))\n```\n\n`pipeline_output_ref` is a reference to pipeline outputs, see [Objects](https://docs.ray.io/en/latest/ray-core/objects.html) documentation for more details.\n\n> **Note**\n> Internally `run` calls `run_nowait` and uses `ray.get` to wait for pipeline to finish.\n\nApart from `pipeline_output_ref` there is another option to obtain results from pipeline execution but with much more details:\n\n```python\nresult = pipeline.run_nowait(pipeline_inputs)\n\nfor pipeline_event in result.pipeline_events_sync():\n # For better viewing experience inputs/outputs are truncated\n # but you can comment out/remove lines below (before `print`)\n # if you would like to see full event data set\n if pipeline_event.type == \"ray.haystack.pipeline-start\":\n pipeline_event.data[\"pipeline_inputs\"] = \"{...}\"\n if pipeline_event.type == \"ray.haystack.component-start\":\n pipeline_event.data[\"input\"] = \"{...}\"\n if pipeline_event.type == \"ray.haystack.component-end\":\n pipeline_event.data[\"output\"] = \"{...}\"\n\n print(\n f\"\\n>>> [{pipeline_event.time}] Source: {pipeline_event.source} | Type: {pipeline_event.type} | Data={pipeline_event.data}\"\n )\n```\n\nBelow is a sample output you should be able to see if you run the code above:\n\n```bash\n>>> [2024-10-09T22:16:27.073665+00:00] Source: ray-pipeline-processor | Type: ray.haystack.pipeline-start | Data={'pipeline_inputs': '{...}', 'runnable_nodes': ['business-news-fetcher', 'politics-news-fetcher', 'tech-news-fetcher']}\n\n>>> [2024-10-09T22:16:27.535254+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-start | Data={'name': 'business-news-fetcher', 'sender_name': None, 'input': '{...}', 'iteration': 0}\n\n>>> [2024-10-09T22:16:27.537959+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-start | Data={'name': 'politics-news-fetcher', 'sender_name': None, 'input': '{...}', 'iteration': 0}\n\n>>> [2024-10-09T22:16:27.540466+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-start | Data={'name': 'tech-news-fetcher', 'sender_name': None, 'input': '{...}', 'iteration': 0}\n\n>>> [2024-10-09T22:16:28.939877+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-end | Data={'name': 'politics-news-fetcher', 'output': '{...}', 'iteration': 0}\n\n>>> [2024-10-09T22:16:28.944781+00:00] Source: ray-pipeline-processor | Type: ray.haystack.component-start | Data={'name': 'politics-xml-converter', 'sender_name': 'politics-news-fetcher', 'input': '{...}', 'iteration': 0}\n```\n\n> **Note**\n> You can access directly the events queue and then use your own events listening logic.\n\n```python\nresult = pipeline.run_nowait(pipeline_inputs)\n\n# Wait for just one event and return\nresult.events_queue.get(block=True)\n```\n\nWith available [Queue methods](https://docs.ray.io/en/latest/ray-core/api/doc/ray.util.queue.Queue.html) you should be able to implement `async` processing logic (see `get_async` method). The [pipeline_watch example](https://github.com/prosto/ray-haystack/blob/main/examples/pipeline_watch/README.md) actually uses `async` to read events from the queue and deliver those to browser as soon as event is available (using Server Sent Events)\n\n### Component Serialization\n\nAs we saw earlier in the diagram when you run pipeline with `RayPipeline` each component gets serialized and then de-serialized when instantiated within an actor.\nIf you run native Haystack pipeline locally component remain in the same python process and there is no reason to care about distributed setup.\nHowever in order for component to become available across boundaries we should be able to create instance of component based on its definition - much like you would have a [saved pipeline definition](https://docs.haystack.deepset.ai/docs/serialization) and then send it to some backend service for invocation. Ray distributes payload and should be able to [serialize](https://docs.ray.io/en/latest/ray-core/objects/serialization.html) objects before they end up in remote task or actor.\n\n\n\nWe could rely on default serialization behavior provided by Ray, but the trick is not every Haystack component (custom or provided) is going to be serializable with `pickle5 + cloudpickle` (e.g. document store connection etc). So we have to rely on what Haystack requires from each component as per protocol - `to_dict` and `from_dict` methods. **Any component that you intend to use with `RayPipeline` should have those methods defined and working as expected.**\n\nThere is another issue when it comes to component deserialization on a remote task or actor in Ray - whatever python package/module a component depends on should be available during component creation or invocation. This brings us to a relatively complex topic about [environment dependencies](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#concepts) in Ray. **You should read the documentation and plan accordingly before decide to deploy your pipeline to a fully fledged production setup.** In most of the cases you will be able to run and test pipelines with `RayPipeline` without noticing how Ray tries to bring in component's environment dependencies into remote actor. See [pipeline_kubernetes example](/examples/pipeline_kubernetes/README.md) for a simple demonstration of running pipeline on a pristine KubeRay cluster in kubernetes.\n\nLets see when serialization will become an issue by running the following example:\n\n```python\nimport io\nfrom typing import List\nfrom xml.etree.ElementTree import parse as parse_xml\n\nimport ray\nfrom haystack import Document\nfrom haystack.components.converters import OutputAdapter\nfrom haystack.components.fetchers import LinkContentFetcher\nfrom haystack.dataclasses import ByteStream\n\nfrom ray_haystack import RayPipeline\nfrom ray_haystack.serialization import worker_asset\n\n\n# Uncomment to fix the serialization issue\n# @worker_asset\ndef parse_sources(sources: List[ByteStream]) -> List[Document]:\n documents: List[Document] = []\n for source in sources:\n xml_content = io.StringIO(source.to_string())\n documents.extend(\n Document(content=elem.text)\n for elem in parse_xml(xml_content).findall(\".//channel/item/title\") # noqa: S314\n if elem.text\n )\n return documents\n\n\npipeline = RayPipeline()\n\npipeline.add_component(\"tech-news-fetcher\", LinkContentFetcher())\npipeline.add_component(\n \"adapter\",\n OutputAdapter(\n template=\"{{ sources | parse_sources }}\",\n output_type=List[Document],\n custom_filters={\"parse_sources\": parse_sources},\n ),\n)\n\npipeline.connect(\"tech-news-fetcher\", \"adapter.sources\")\n\npipeline.draw(\"pipe.png\")\n\npipeline_inputs = {\n \"tech-news-fetcher\": {\n \"urls\": [\n \"https://techcrunch.com/feed\",\n \"https://cnet.com/rss/news\",\n ]\n },\n}\n\nray.init()\n\nresult = pipeline.run(pipeline_inputs)\n\nprint(\"RESULT: \", result[\"adapter\"][\"output\"])\n```\n\nThe pipeline above is a simple one - first fetch RSS feed contents and then parse and extract documents from it using `OutputAdapter`. However we would get the following error:\n\n```text\n File \".../ray_haystack/serialization/component_wrapper.py\", line 48, in __init__\n self._component = component_from_dict(component_class, component_data, None)\n File \".../haystack/core/serialization.py\", line 118, in component_from_dict\n return do_from_dict()\n File \".../haystack/core/serialization.py\", line 113, in do_from_dict\n return cls.from_dict(data)\n File \".../haystack/components/converters/output_adapter.py\", line 170, in from_dict\n init_params[\"custom_filters\"] = {\n File \".../haystack/components/converters/output_adapter.py\", line 171, in <dictcomp>\n name: deserialize_callable(filter_func) if filter_func else None\n File \".../haystack/utils/callable_serialization.py\", line 45, in deserialize_callable\n raise DeserializationError(f\"Could not locate the callable: {function_name}\")\nhaystack.core.errors.DeserializationError: Could not locate the callable: parse_sources\n```\n\nSeems like the `parse_sources` function was not available to python interpreter during de-serialization of the `OutputAdapter` component. In order to understand what happens under the hood lets see how the component looks like in a serialized format:\n\n```python\n{\n 'type': 'haystack.components.converters.output_adapter.OutputAdapter',\n 'init_parameters': {\n 'template': '{{ sources | parse_sources }}',\n 'output_type': 'typing.List[haystack.dataclasses.document.Document]',\n 'custom_filters': {'parse_sources': '__main__.parse_sources'},\n 'unsafe': False\n }\n}\n```\n\nWhen component is deserialized the `__main__.parse_sources` function is not present in a remote Ray actor anymore. Which is understandable because we have not instructed Ray to push any module or package which contains the `parse_sources` function in it. (Moreover Ray's worker node which runs component actor has its own `__main__` module and `parse_sources` is not defined there).\n\nTo fix the issue what we need to import `worker_asset` decorator from `ray_haystack.serialization` package and apply the decorator to the `parse_sources` function. Please uncomment the decorator fix in the example and run the pipeline again. You should see Documents as a result.\n\n`worker_asset` instructs serialization process to bring in the `parse_sources` function along with the component so that when it deserialized `parse_sources` is imported.\n\n> **Important**\n> Please use `@worker_asset` whenever you encounter issues with components like `OutputAdapter` where some functions are referenced by a component. Make sure you do not use lambdas but rather a dedicated python function with the decorator in place.\n\n### DocumentStore with Ray\n\nUnfortunately when you use [InMemoryDocumentStore](https://docs.haystack.deepset.ai/docs/inmemorydocumentstore) or any DocumentStore which runs in-memory (a singleton) with `RayPipeline` you will stumble upon an apparent issue: in distributed environment such DocumentStore will fail to operate as components which reference the store will not point to single instance but rather a copy of it.\n\n`ray-haystack` package provides a wrapper around `InMemoryDocumentStore` by implementing a proxy pattern so that only a single instance of `InMemoryDocumentStore` across Ray cluster is present. With that pipeline components could share a single store. Use `RayInMemoryDocumentStore`, `RayInMemoryEmbeddingRetriever` or `RayInMemoryBM25Retriever` in case you need in-memory document store in your Ray pipelines. See below a conceptual diagram of how components refer to a single instance of the store:\n\n\n\nWhenever you create `RayInMemoryDocumentStore` internally an actor is created which wraps native `InMemoryDocumentStore` and acts as a singleton in cluster. `RayInMemoryDocumentStore` forwards calls to the remote actor.\n\nLets see it in action by running the [basic RAG pipeline](https://haystack.deepset.ai/tutorials/27_first_rag_pipeline).\n\nBefore running the script make sure additional dependencies have been installed:\n\n```bash\npip install \"datasets>=2.6.1\"\npip install \"sentence-transformers>=3.0.0\"\n```\n\n```python\nimport os\n\nimport ray\nfrom datasets import load_dataset\nfrom haystack.components.builders.prompt_builder import PromptBuilder\nfrom haystack.components.embedders import (\n SentenceTransformersDocumentEmbedder,\n SentenceTransformersTextEmbedder,\n)\nfrom haystack.components.generators import OpenAIGenerator\nfrom haystack.dataclasses import Document\nfrom haystack.document_stores.types import DocumentStore\n\nfrom ray_haystack.components import (\n RayInMemoryDocumentStore,\n RayInMemoryEmbeddingRetriever,\n)\nfrom ray_haystack.ray_pipeline import RayPipeline\n\nos.environ[\"OPENAI_API_KEY\"] = \"Your OPenAI API Key\"\n\n\ndef prepare_document_store(document_store: DocumentStore):\n doc_embedder = SentenceTransformersDocumentEmbedder(model=\"sentence-transformers/all-MiniLM-L6-v2\")\n doc_embedder.warm_up()\n\n dataset = load_dataset(\"bilgeyucel/seven-wonders\", split=\"train\")\n docs = [Document(content=doc[\"content\"], meta=doc[\"meta\"]) for doc in dataset]\n\n docs_with_embeddings = doc_embedder.run(docs)\n document_store.write_documents(docs_with_embeddings[\"documents\"])\n\n\ntemplate = \"\"\"\nGiven the following information, answer the question.\n\nContext:\n{% for document in documents %}\n {{ document.content }}\n{% endfor %}\n\nQuestion: {{question}}\nAnswer:\n\"\"\"\n\n# Start Ray cluster before defining `RayInMemoryDocumentStore` as internally it creates an actor\nray.init()\n\ndocument_store = RayInMemoryDocumentStore() # from `ray-haystack`\n\n# Create documents in document_store\nprepare_document_store(document_store)\n\ntext_embedder = SentenceTransformersTextEmbedder(model=\"sentence-transformers/all-MiniLM-L6-v2\")\nretriever = RayInMemoryEmbeddingRetriever(document_store) # from `ray-haystack`\ngenerator = OpenAIGenerator()\n\nprompt_builder = PromptBuilder(template=template)\n\npipeline = RayPipeline()\n\npipeline.add_component(\"text_embedder\", text_embedder)\npipeline.add_component(\"retriever\", retriever)\npipeline.add_component(\"prompt_builder\", prompt_builder)\npipeline.add_component(\"llm\", generator)\n\npipeline.connect(\"text_embedder.embedding\", \"retriever.query_embedding\")\npipeline.connect(\"retriever\", \"prompt_builder.documents\")\npipeline.connect(\"prompt_builder\", \"llm\")\n\nquestion = \"What does Rhodes Statue look like?\"\n\nresponse = pipeline.run(\n {\n \"text_embedder\": {\"text\": question},\n \"prompt_builder\": {\"question\": question},\n }\n)\n\nprint(\"RESULT: \", response[\"llm\"][\"replies\"][0])\n```\n\nPlease notice the components imported from the `ray_haystack.components` package and how a single instance of the `RayInMemoryDocumentStore` is used for both indexing (`prepare_document_store`) and then querying (`pipeline.run`).\n\n> **Important**\n> Existing implementation of the `RayInMemoryDocumentStore` might be a subject to change in future. In case you would like to introduce or use another store which also works in-memory take a look at implementation of the components in the `ray_haystack.components` package. It should not take much time implementing your own wrapper by following the example.\n\n### RayPipeline Settings\n\nWhen an actor is created in Ray we can control its behavior by providing certain [settings](https://docs.ray.io/en/latest/ray-core/api/doc/ray.actor.ActorClass.options.html).\nSome examples are provided below:\n\n- num_cpus \u2013 The quantity of CPU cores to reserve for this task or for the lifetime of the actor.\n- num_gpus \u2013 The quantity of GPUs to reserve for this task or for the lifetime of the actor.\n- name \u2013 The globally unique name for the actor, which can be used to retrieve the actor via ray.get_actor(name) as long as the actor is still alive.\n- runtime_env (Dict[str, Any]) \u2013 Specifies the runtime environment for this actor or task and its children.\n- etc\n\n[`runtime_env`](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#runtime-environments) is a notable configuration option as it can control which `pip` dependencies needs to be installed for actor to run, environment variables, container image to use in a cluster etc. In our case we are specifically interested in [Specifying a Runtime Environment Per-Task or Per-Actor](https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#specifying-a-runtime-environment-per-task-or-per-actor)\n\nAs you have already learned when we run pipeline with `RayPipeline` a couple of actors are created before the pipeline starts running. To control actor's runtime environment as well as resources like CPU/GPU/RAM per actor you can use `ray_haystack.RayPipelineSettings` configuration dictionary.\n\nBelow is the definition of the dictionary (see the [source](https://github.com/prosto/ray-haystack/blob/main/src/ray_haystack/ray_pipeline_settings.py) for more details):\n\n```python\nclass RayPipelineSettings(TypedDict, total=False):\n common: CommonSettings # settings common for all actors within pipeline\n\n processor: ProcessorSettings # settings for pipeline processor\n components: CommonComponentSettings # settings common for all components, and per component\n events_queue: EventsQueueSettings # settings for events_queue actor\n\n # controls how settings are merged, e.g. \"common\" <- \"common components\" <- \"component specific\"\n merge_strategy: Literal[\"REPLACE\", \"ADDITIVE\", \"TYPESAFE_REPLACE\", \"TYPESAFE_ADDITIVE\"]\n```\n\nThere are two options how `RayPipelineSettings` can be provided for `RayPipeline`:\n\n```python\nfrom typing import Any, Dict\n\nfrom ray_haystack import RayPipeline, RayPipelineSettings\n\nsettings: RayPipelineSettings = {\n \"common\": {\n \"actor_options\": {\n \"namespace\": \"haystack\", # common namespace name for all actors\n }\n },\n \"components\": {\n \"per_component\": {\n \"generator\": {\n \"actor_options\": {\n \"num_cpus\": 2, # component specific CPU resource requirement\n }\n }\n }\n },\n}\n\n# Option 1 - Pass settings through pipeline's metadata\npipeline = RayPipeline(metadata={\"ray\": settings})\n\npipeline_inputs: Dict[str, Any] = {}\n\n# Option 2 - Pass settings when in the `run` method\npipeline.run(pipeline_inputs, ray_settings=settings)\n```\n\nAbove code highlights two ways to supply settings for a pipeline:\n\n1. pipeline's `metadata` with key `\"ray\"`\n2. directly as keyword argument in `run` method (will override settings from `metadata`)\n\nAbove example also demonstrates that it is possible to configure actor options per component and also define common options which will be shared between all actors created by `RayPipeline`. Actor options are being merged with component specific values taking precedence. Internally `mergedeep` python package is being used to merge dictionaries and you can control how merging works by picking [strategy](https://mergedeep.readthedocs.io/en/latest/#merge-strategies). Default one is `ADDITIVE`.\n\nLets build a small example of a pipeline which uses component specific environment variables:\n\n```python\nimport os\n\nimport ray\nfrom haystack.components.builders.prompt_builder import PromptBuilder\nfrom haystack.components.fetchers import LinkContentFetcher\nfrom haystack.components.generators import OpenAIGenerator\n\nfrom ray_haystack import RayPipeline, RayPipelineSettings\n\nos.environ[\"OPENAI_API_KEY\"] = \"OpenAI API Key Here\"\n\nprompt_template = \"\"\"You will be given a JSON document containing data about a random cocktail recipe.\nThe data will include fields with name of the drink, its ingredients and instructions how to make it.\nBuild a cocktail description card in markdown format based on the fields present in the json.\nIgnore fields with \"null\" values. Keep instruction as is.\n\nJSON: {{cocktail_json[0]}}\n\nCocktail Card:\n\"\"\"\n\n# Setup environment for the whole cluster (each worker node will get env var OPENAI_TIMEOUT=15)\nray.init(runtime_env={\"env_vars\": {\"OPENAI_TIMEOUT\": \"15\"}})\n\nfetcher = LinkContentFetcher()\nprompt = PromptBuilder(template=prompt_template)\ngenerator = OpenAIGenerator()\n\npipeline = RayPipeline()\npipeline.add_component(\"cocktail_fetcher\", fetcher)\npipeline.add_component(\"prompt\", prompt)\npipeline.add_component(\"llm\", generator)\n\npipeline.connect(\"cocktail_fetcher.streams\", \"prompt.cocktail_json\")\npipeline.connect(\"prompt\", \"llm.prompt\")\n\nsettings: RayPipelineSettings = {\n # common settings will be applied for all actors created\n \"common\": {\n \"actor_options\": {\"namespace\": \"haystack\"},\n },\n \"components\": {\n # Applies OPENAI_TIMEOUT to all components in pipeline\n \"actor_options\": {\"runtime_env\": {\"env_vars\": {\"OPENAI_TIMEOUT\": \"10\"}}},\n \"per_component\": {\n # \"llm\" component will get a new value for OPENAI_TIMEOUT overriding common settings\n # so the final value for OPENAI_TIMEOUT environment variable is 11\n \"llm\": {\n \"actor_options\": {\"runtime_env\": {\"env_vars\": {\"OPENAI_TIMEOUT\": \"11\"}}},\n },\n },\n },\n}\n\nresponse = pipeline.run(\n {\n \"cocktail_fetcher\": {\"urls\": [\"https://www.thecocktaildb.com/api/json/v1/1/random.php\"]},\n },\n ray_settings=settings, # pass settings to pipeline execution\n)\n\nprint(\"RESULT: \", response[\"llm\"][\"replies\"][0])\n```\n\nPlease notice how `OPENAI_TIMEOUT` environment variable is set globally by `ray.init` and then with `RayPipelineSettings` it gets overridden specifically for the \"llm\" component.\n\n> **Note**\n> You may ask why didn't we provide `OPENAI_API_KEY` same way as `OPENAI_TIMEOUT` as in the example above. And the reason is hidden in the implementation of the `OpenAIGenerator` constructor which raises error if there is no value for the `OPENAI_API_KEY` env var. So `OPENAI_API_KEY` value is required before `RayPipeline` creates component actors when it starts.\n\nExplore available options in [ray_pipeline_settings.py](https://github.com/prosto/ray-haystack/blob/main/src/ray_haystack/ray_pipeline_settings.py), `RayPipelineSettings` is just a python `TypedDict` which helps creating settings in your IDE of choice.\n\n### Middleware\n\n> **Warning**\n> This feature is experimental and implementation details as well as API might change in future.\n\nSometimes it might be useful to let custom logic run before and after component actor runs the component:\n\n- Fire a custom event and put it into events queue\n- Tweak component inputs before they are sent to component\n- Tweak component outputs before they are sent to other components (through connections)\n- Additional logging/tracing\n- Custom time delays in order to slow down component execution\n- An external trigger which blocks component run until some event occurs\n- Debugging breakpoints for components (e.g. stop component running until a trigger unblocks the breakpoint)\n\nAbove is just a high level vision of what I would expect middleware to do.\n\nLets build an example of how custom middleware can be introduced and applied. We will intercept `LinkContentFetcher` component and see the order of execution of middleware.\n\n```python\nfrom typing import Any, Literal\n\nimport ray\nfrom haystack.components.fetchers import LinkContentFetcher\n\nfrom ray_haystack import RayPipeline, RayPipelineSettings\nfrom ray_haystack.middleware import ComponentMiddleware, ComponentMiddlewareContext\nfrom ray_haystack.serialization import worker_asset\n\nray.init()\n\n\n@worker_asset\nclass TraceMiddleware(ComponentMiddleware):\n def __init__(self, capture: Literal[\"input\", \"output\", \"input_and_output\"] = \"input_and_output\"):\n self.capture = capture\n\n def __call__(self, component_input, ctx: ComponentMiddlewareContext) -> Any:\n print(f\"Tracer: Before running component '{ctx['component_name']}' with inputs: '{component_input}'\")\n\n outputs = self.next(component_input, ctx)\n\n print(f\"Tracer: After running component '{ctx['component_name']}' with outputs: '{outputs}'\")\n\n return outputs\n\n\n@worker_asset\nclass MessageMiddleware(ComponentMiddleware):\n def __init__(self, message: str):\n self.message = message\n\n def __call__(self, component_input, ctx: ComponentMiddlewareContext) -> Any:\n print(f\"Message: Before running component '{ctx['component_name']}' : '{self.message}'\")\n\n outputs = self.next(component_input, ctx)\n\n print(f\"Message: After running component '{ctx['component_name']}' : '{self.message}'\")\n\n return outputs\n\n\npipeline = RayPipeline()\npipeline.add_component(\"cocktail_fetcher\", LinkContentFetcher())\n\nsettings: RayPipelineSettings = {\n \"components\": {\n \"per_component\": {\n # Middleware applies only to \"cocktail_fetcher\" component\n \"cocktail_fetcher\": {\n \"middleware\": {\n \"trace\": {\"type\": \"__main__.TraceMiddleware\"},\n \"message\": {\n \"type\": \"__main__.MessageMiddleware\",\n \"init_parameters\": {\"message\": \"Hello Fetcher\"},\n },\n },\n },\n }\n },\n}\n\nresponse = pipeline.run(\n {\n \"cocktail_fetcher\": {\"urls\": [\"https://www.thecocktaildb.com/api/json/v1/1/random.php\"]},\n },\n ray_settings=settings,\n)\n```\n\nPlease notice the following from the example above:\n\n- When defining custom middleware extend from `ComponentMiddleware` class. It provides a basic implementation of the `set_next` method. In case you do not want to extend from the base class make sure you implement `set_next` yourself\n- Middleware is applied to a component in a pipeline with `RayPipelineSettings` (see `middleware` key in the dictionary)\n- Middleware is applied by decorating the component's `run` method in the order it is defined in the settings dictionary\n - \"message\" (before)\n - \"trace\" (before)\n - \"trace\" (after)\n - \"message\" (after)\n- `@worker_asset` decorator is applied to custom middleware so that during component actor creation Ray worker is able to deserialize (instantiate) middleware class. For example `\"__main__.MessageMiddleware\"` will be imported before creating instance of the `MessageMiddleware` class\n\nAs of now `ray-haystack` provides `DelayMiddleware` for adding time \"sleeps\" for components so that we could slow down all components or specific ones.\nIt was introduced to allow easier tracing experience when you consume events from events queue in order to see how components run in \"slow motion\". You can apply it aas follows:\n\n```python\nsettings: RayPipelineSettings = {\n \"components\": {\n # Applies to all component in pipeline\n \"middleware\": {\n \"delay\": {\n # full module path is required, will be used during deserialization in component actor\n \"type\": \"ray_haystack.middleware.delay_middleware.DelayMiddleware\",\n \"init_parameters\": {\n \"delay\": 2, # default is 1\n \"delay_type\": \"before\", # could be \"after\" or \"before_and_after\"\n },\n }\n }\n },\n}\n```\n\n## More Examples\n\n### Trace Ray Pipeline execution in Browser\n\n[`pipeline_watch`](https://github.com/prosto/ray-haystack/blob/main/examples/pipeline_watch/README.md) is a sample application which runs Ray Pipelines with Ray Serve in backend and provides UI in browser to track running pipeline (component by component). It uses pipeline events which are streamed to browser using Server Sent Events. Please follow instructions inside the `pipeline-watch` folder in order to install and run the example.\n\nPlease check it out, you may like it!\n\n### Ray Pipeline on Kubernetes\n\nThe ability to run Ray Pipeline on a remote Ray Cluster was an important step to test its \"non-local\" setup use case. The [`pipeline_kubernetes`](https://github.com/prosto/ray-haystack/blob/main/examples/pipeline_kubernetes/README.md) example provides instructions on how to install a local Ray Cluster by deploying KubeRay operator in Kubernetes and then run pipeline using [ray job submission SDK](https://docs.ray.io/en/latest/cluster/kubernetes/getting-started/raycluster-quick-start.html#method-2-submit-a-ray-job-to-the-raycluster-via-ray-job-submission-sdk)\n\n### Ray Pipeline with detached components\n\nSome of [Actor Options](https://docs.ray.io/en/latest/ray-core/api/doc/ray.actor.ActorClass.options.html) which are configurable per component can result in an interesting effect on how Ray Pipeline runs. One of such options is `lifetime`. When it is \"detached\" the actor will live as a global object independent of the creator, thus if `RayPipeline` finishes component actor will remain alive. [`pipeline_detached_actors`](https://github.com/prosto/ray-haystack/tree/main/examples/pipeline_detached_actors) explores such case and also runs pipeline in a Notebook.\n\n## Next Steps & Enhancements\n\n- [ ] Introduce logging configuration, e.g. control log level & format per component\n- [ ] Better error handling in case pipeline output is consumed with pipeline events\n- [ ] Create middleware to allow breakpoints in pipeline execution (stop at certain component until certain event is triggered)\n- [ ] Write API documentation for main package components\n- [ ] Introduce more tests for pipeline processing logic to cover more scenarios (e.g. complex cycles)\n- [ ] Explore fault tolerance options and see what happens when certain parts fail during execution\n- [ ] Explore the option of running Haystack pipeline on a Ray cluster with GPU available\n- [ ] Improve DocumentStore proxy implementation so that other DocumentStores which run in-memory could be quickly adapted to `RayPipeline` without much boilerplate code\n\n## Acknowledgments\n\nI would have spent much more time testing pipeline execution logic if a [awesome testing suite](https://github.com/deepset-ai/haystack/tree/main/test/core/pipeline/features) was not available. I have adopted tests to make sure pipeline behavior is on par with Haystack. Thanks @silvanocerza for the tests and also clarifications on pipeline internals.\n",
"bugtrack_url": null,
"license": null,
"summary": "Haystack pipelines with Ray",
"version": "0.1.0",
"project_urls": {
"Documentation": "https://github.com/prosto/ray-haystack",
"Issues": "https://github.com/prosto/ray-haystack/issues",
"Source": "https://github.com/prosto/ray-haystack"
},
"split_keywords": [
"ai",
" haystack",
" rag",
" ray",
" semantic-search"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "67e296226a4a37ecf2edc0403e7d2c86ae2a856ddb21e25cc03a562a148b3a54",
"md5": "58dc58c4b9deb1faac9add742468f5a0",
"sha256": "9d96d748d904f928ceef813c4b31f6e6327af3cd8d423fed0b64dcd9edb4352c"
},
"downloads": -1,
"filename": "ray_haystack-0.1.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "58dc58c4b9deb1faac9add742468f5a0",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.8",
"size": 38276,
"upload_time": "2024-10-16T19:59:10",
"upload_time_iso_8601": "2024-10-16T19:59:10.166682Z",
"url": "https://files.pythonhosted.org/packages/67/e2/96226a4a37ecf2edc0403e7d2c86ae2a856ddb21e25cc03a562a148b3a54/ray_haystack-0.1.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "e3559dc7adaa3a3301668b06e5561dbdc59e29e6cfb381dd8a43d18be018436f",
"md5": "01ccbda4965d1cbfb8acfdbc00d16427",
"sha256": "f4b9ccdef63b9be570d18eca0cdd7592a3762febb5de4047c58c3b54455a8367"
},
"downloads": -1,
"filename": "ray_haystack-0.1.0.tar.gz",
"has_sig": false,
"md5_digest": "01ccbda4965d1cbfb8acfdbc00d16427",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 1926923,
"upload_time": "2024-10-16T19:59:12",
"upload_time_iso_8601": "2024-10-16T19:59:12.874862Z",
"url": "https://files.pythonhosted.org/packages/e3/55/9dc7adaa3a3301668b06e5561dbdc59e29e6cfb381dd8a43d18be018436f/ray_haystack-0.1.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-10-16 19:59:12",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "prosto",
"github_project": "ray-haystack",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "ray-haystack"
}

