| Name | tensorboard-reducer JSON |
| Version |
0.3.1
 JSON
JSON |
| download |
| home_page | |
| Summary | Reduce multiple TensorBoard runs to new event (or CSV) files |
| upload_time | 2023-09-21 18:59:00 |
| maintainer | |
| docs_url | None |
| author | |
| requires_python | >=3.8 |
| license | MIT License Copyright (c) 2021 Janosh Riebesell Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. The software is provided "as is", without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the software. |
| keywords |
aggregate
averaging
logs
machine-learning
pytorch
reducer
runs
statistics
tensorboard
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|

[](https://github.com/janosh/tensorboard-reducer/actions/workflows/test.yml)
[](https://results.pre-commit.ci/latest/github/janosh/tensorboard-reducer/main)
[](https://python.org/downloads)
[](https://pypi.org/project/tensorboard-reducer?logo=pypi&logoColor=white)
[](https://pypistats.org/packages/tensorboard-reducer)
[](https://zenodo.org/badge/latestdoi/354585417)
> This project can ingest both PyTorch and TensorFlow event files but was mostly tested with PyTorch. For a TF-only project, see [`tensorboard-aggregator`](https://github.com/Spenhouet/tensorboard-aggregator).
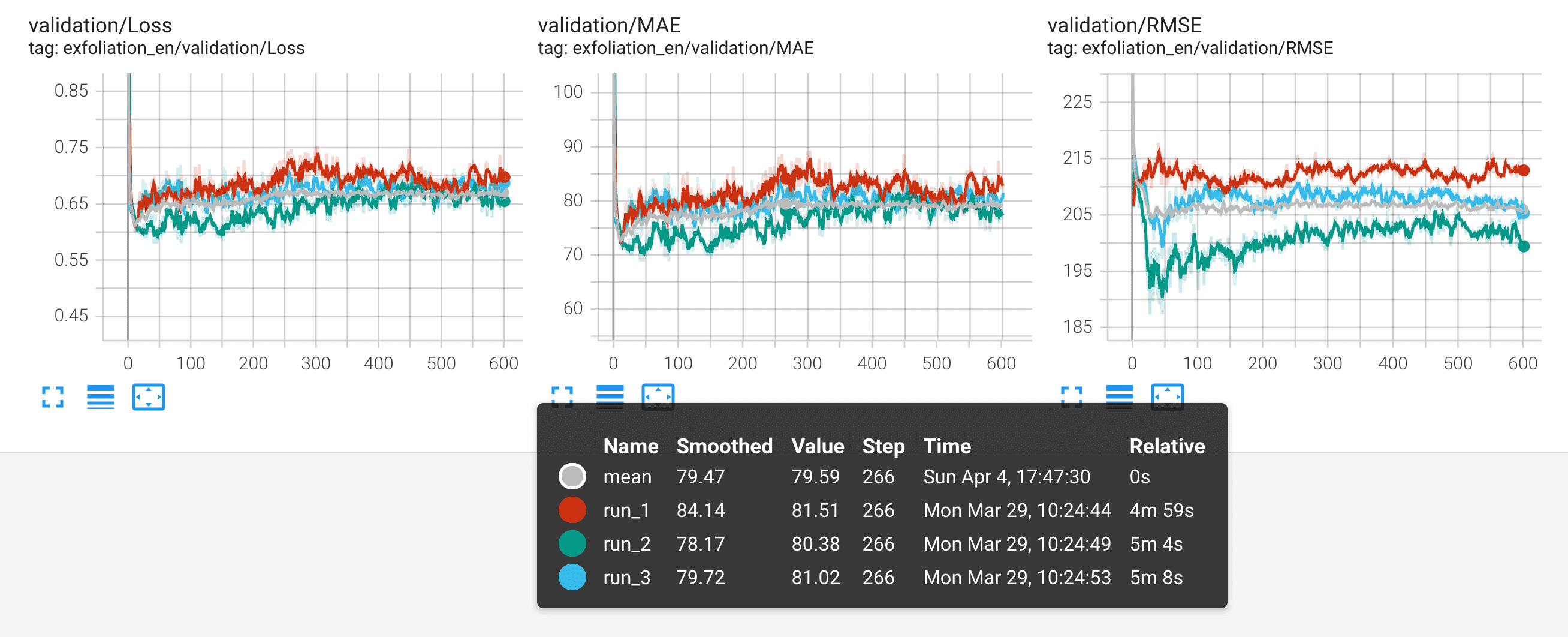
Compute statistics (`mean`, `std`, `min`, `max`, `median` or any other [`numpy` operation](https://numpy.org/doc/stable/reference/routines.statistics)) of multiple TensorBoard run directories. This can be used e.g. when training model ensembles to reduce noise in loss/accuracy/error curves and establish statistical significance of performance improvements or get a better idea of epistemic uncertainty. Results can be saved to disk either as new TensorBoard runs or CSV/JSON/Excel. More file formats are easy to add, PRs welcome.
## Example notebooks
| |         | |
| ---------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [**Basic Python API Demo**](https://github.com/janosh/tensorboard-reducer/blob/main/examples/basic_python_api_example.ipynb) | [![Launch Codespace]][codespace url] [![Launch Binder]](https://mybinder.org/v2/gh/janosh/tensorboard-reducer/main?labpath=examples%2Fbasic_python_api_example.ipynb) [![Open in Google Colab]](https://colab.research.google.com/github/janosh/tensorboard-reducer/blob/main/examples/basic_python_api_example.ipynb) | Demonstrates how to work with local TensorBoard event files. |
| [**Functorch MLP Ensemble**](https://github.com/janosh/tensorboard-reducer/blob/main/examples/functorch_mlp_ensemble.ipynb) | [![Launch Codespace]][codespace url] [![Launch Binder]](https://mybinder.org/v2/gh/janosh/tensorboard-reducer/main?labpath=examples%2Ffunctorch_mlp_ensemble.ipynb) [![Open in Google Colab]](https://colab.research.google.com/github/janosh/tensorboard-reducer/blob/main/examples/functorch_mlp_ensemble.ipynb) | Shows how to aggregate run metrics with TensorBoard Reducer<br>when training model ensembles using `functorch`. |
| [**Weights & Biases Integration**](https://github.com/janosh/tensorboard-reducer/blob/main/examples/wandb_integration.ipynb) | [![Launch Codespace]][codespace url] [![Launch Binder]](https://mybinder.org/v2/gh/janosh/tensorboard-reducer/main?labpath=examples%2Fwandb_integration.ipynb) [![Open in Google Colab]](https://colab.research.google.com/github/janosh/tensorboard-reducer/blob/main/examples/wandb_integration.ipynb) | Trains PyTorch CNN ensemble on MNIST, logs results to [WandB](https://wandb.ai), downloads metrics from multiple WandB runs, aggregates using `tb-reducer`, then re-uploads to WandB as new runs. |
[Launch Binder]: https://mybinder.org/badge_logo.svg
[Launch Codespace]: https://img.shields.io/badge/Launch-Codespace-darkblue?logo=github
[codespace url]: https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=354585417
[Open in Google Colab]: https://colab.research.google.com/assets/colab-badge.svg
*The mean of 3 runs shown in pink here is less noisy and better suited for comparisons between models or different training techniques than individual runs.*
## Installation
```sh
pip install tensorboard-reducer
```
Excel support requires installing extra dependencies:
```sh
pip install 'tensorboard-reducer[excel]'
```
## Usage
### CLI
```sh
tb-reducer runs/of-your-model* -o output-dir -r mean,std,min,max
```
All positional CLI arguments are interpreted as input directories and expected to contain TensorBoard event files. These can be specified individually or with wildcards using shell expansion. You can check you're getting the right input directories by running `echo runs/of-your-model*` before passing them to `tb-reducer`.
**Note**: By default, TensorBoard Reducer expects event files to contain identical tags and equal number of steps for all scalars. If you trained one model for 300 epochs and another for 400 and/or recorded different sets of metrics (tags in TensorBoard lingo) for each of them, see CLI flags `--lax-steps` and `--lax-tags` to disable this safeguard. The corresponding kwargs in the Python API are `strict_tags = True` and `strict_steps = True` on `load_tb_events()`.
In addition, `tb-reducer` has the following flags:
- **`-o/--outpath`** (required): File path or directory where to write output to disk. If `--outpath` is a directory, output will be saved as TensorBoard runs, one new directory created for each reduction suffixed by the `numpy` operation, e.g. `'out/path-mean'`, `'out/path-max'`, etc. If `--outpath` is a file path, it must have `'.csv'`/`'.json'` or `'.xlsx'` (supports compression by using e.g. `.csv.gz`, `json.bz2`) in which case a single file will be created. CSVs will have a two-level header containing one column for each combination of tag (`loss`, `accuracy`, ...) and reduce operation (`mean`, `std`, ...). Tag names will be in top-level header, reduce ops in second level. **Hint**: When saving data as CSV or Excel, use `pandas.read_csv("path/to/file.csv", header=[0, 1], index_col=0)` and `pandas.read_excel("path/to/file.xlsx", header=[0, 1], index_col=0)` to load reduction results into a multi-index dataframe.
- **`-r/--reduce-ops`** (optional, default: `mean`): Comma-separated names of numpy reduction ops (`mean`, `std`, `min`, `max`, ...). Each reduction is written to a separate `outpath` suffixed by its op name. E.g. if `outpath='reduced-run'`, the mean reduction will be written to `'reduced-run-mean'`.
- **`-f/--overwrite`** (optional, default: `False`): Whether to overwrite existing output directories/data files (CSV, JSON, Excel). For safety, the overwrite operation will abort with an error if the file/directory to overwrite is not a known data file and does not look like a TensorBoard run directory (i.e. does not start with `'events.out'`).
- **`--lax-tags`** (optional, default: `False`): Allow different runs have to different sets of tags. In this mode, each tag reduction will run over as many runs as are available for a given tag, even if that's just one. Proceed with caution as not all tags will have the same statistics in downstream analysis.
- **`--lax-steps`** (optional, default: `False`): Allow tags across different runs to have unequal numbers of steps. In this mode, each reduction will only use as many steps as are available in the shortest run (same behavior as `zip(short_list, long_list)` which stops when `short_list` is exhausted).
- **`--handle-dup-steps`** (optional, default: `None`): How to handle duplicate values recorded for the same tag and step in a single run. One of `'keep-first'`, `'keep-last'`, `'mean'`. `'keep-first/last'` will keep the first/last occurrence of duplicate steps while 'mean' computes their mean. Default behavior is to raise `ValueError` on duplicate steps.
- **`--min-runs-per-step`** (optional, default: `None`): Minimum number of runs across which a given step must be recorded to be kept. Steps present across less runs are dropped. Only plays a role if `lax_steps` is true. **Warning**: Be aware that with this setting, you'll be reducing variable number of runs, however many recorded a value for a given step as long as there are at least `--min-runs-per-step`. In other words, the statistics of a reduction will change mid-run. Say you're plotting the mean of an error curve, the sample size of that mean will drop from, say, 10 down to 4 mid-plot if 4 of your models trained for longer than the rest. Be sure to remember when using this.
- **`-v/--version`** (optional): Get the current version.
### Python API
You can also import `tensorboard_reducer` into a Python script or Jupyter notebook for more complex operations. Here's a simple example that uses all of the main functions [`load_tb_events`], [`reduce_events`], [`write_data_file`] and [`write_tb_events`] to get you started:
```py
from glob import glob
import tensorboard_reducer as tbr
input_event_dirs = sorted(glob("glob_pattern/of_tb_directories_to_reduce*"))
# where to write reduced TB events, each reduce operation will be in a separate subdirectory
tb_events_output_dir = "path/to/output_dir"
csv_out_path = "path/to/write/reduced-data-as.csv"
# whether to abort or overwrite when csv_out_path already exists
overwrite = False
reduce_ops = ("mean", "min", "max", "median", "std", "var")
events_dict = tbr.load_tb_events(input_event_dirs)
# number of recorded tags. e.g. would be 3 if you recorded loss, MAE and R^2
n_scalars = len(events_dict)
n_steps, n_events = list(events_dict.values())[0].shape
print(
f"Loaded {n_events} TensorBoard runs with {n_scalars} scalars and {n_steps} steps each"
)
print(", ".join(events_dict))
reduced_events = tbr.reduce_events(events_dict, reduce_ops)
for op in reduce_ops:
print(f"Writing '{op}' reduction to '{tb_events_output_dir}-{op}'")
tbr.write_tb_events(reduced_events, tb_events_output_dir, overwrite)
print(f"Writing results to '{csv_out_path}'")
tbr.write_data_file(reduced_events, csv_out_path, overwrite)
print("Reduction complete")
```
[`reduce_events`]: https://github.com/janosh/tensorboard-reducer/blob/6d3468610d2933a23bc355250f9c76e6b6bb0151/tensorboard_reducer/main.py#L12-L14
[`load_tb_events`]: https://github.com/janosh/tensorboard-reducer/blob/6d3468610d2933a23bc355250f9c76e6b6bb0151/tensorboard_reducer/load.py#L10-L16
[`write_data_file`]: https://github.com/janosh/tensorboard-reducer/blob/6d3468610d2933a23bc355250f9c76e6b6bb0151/tensorboard_reducer/write.py#L111-L115
[`write_tb_events`]: https://github.com/janosh/tensorboard-reducer/blob/6d3468610d2933a23bc355250f9c76e6b6bb0151/tensorboard_reducer/write.py#L45-L49
Raw data
{
"_id": null,
"home_page": "",
"name": "tensorboard-reducer",
"maintainer": "",
"docs_url": null,
"requires_python": ">=3.8",
"maintainer_email": "",
"keywords": "aggregate,averaging,logs,machine-learning,pytorch,reducer,runs,statistics,tensorboard",
"author": "",
"author_email": "Janosh Riebesell <janosh.riebesell@gmail.com>",
"download_url": "https://files.pythonhosted.org/packages/46/e3/cd4a4c093db6e0d0f8173e1071ee644e488b49a5afe66cc3de51d930e4e5/tensorboard-reducer-0.3.1.tar.gz",
"platform": null,
"description": "\n\n[](https://github.com/janosh/tensorboard-reducer/actions/workflows/test.yml)\n[](https://results.pre-commit.ci/latest/github/janosh/tensorboard-reducer/main)\n[](https://python.org/downloads)\n[](https://pypi.org/project/tensorboard-reducer?logo=pypi&logoColor=white)\n[](https://pypistats.org/packages/tensorboard-reducer)\n[](https://zenodo.org/badge/latestdoi/354585417)\n\n> This project can ingest both PyTorch and TensorFlow event files but was mostly tested with PyTorch. For a TF-only project, see [`tensorboard-aggregator`](https://github.com/Spenhouet/tensorboard-aggregator).\n\nCompute statistics (`mean`, `std`, `min`, `max`, `median` or any other [`numpy` operation](https://numpy.org/doc/stable/reference/routines.statistics)) of multiple TensorBoard run directories. This can be used e.g. when training model ensembles to reduce noise in loss/accuracy/error curves and establish statistical significance of performance improvements or get a better idea of epistemic uncertainty. Results can be saved to disk either as new TensorBoard runs or CSV/JSON/Excel. More file formats are easy to add, PRs welcome.\n\n## Example notebooks\n\n| |         | |\n| ---------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |\n| [**Basic Python API Demo**](https://github.com/janosh/tensorboard-reducer/blob/main/examples/basic_python_api_example.ipynb) | [![Launch Codespace]][codespace url] [![Launch Binder]](https://mybinder.org/v2/gh/janosh/tensorboard-reducer/main?labpath=examples%2Fbasic_python_api_example.ipynb) [![Open in Google Colab]](https://colab.research.google.com/github/janosh/tensorboard-reducer/blob/main/examples/basic_python_api_example.ipynb) | Demonstrates how to work with local TensorBoard event files. |\n| [**Functorch MLP Ensemble**](https://github.com/janosh/tensorboard-reducer/blob/main/examples/functorch_mlp_ensemble.ipynb) | [![Launch Codespace]][codespace url] [![Launch Binder]](https://mybinder.org/v2/gh/janosh/tensorboard-reducer/main?labpath=examples%2Ffunctorch_mlp_ensemble.ipynb) [![Open in Google Colab]](https://colab.research.google.com/github/janosh/tensorboard-reducer/blob/main/examples/functorch_mlp_ensemble.ipynb) | Shows how to aggregate run metrics with TensorBoard Reducer<br>when training model ensembles using `functorch`. |\n| [**Weights & Biases Integration**](https://github.com/janosh/tensorboard-reducer/blob/main/examples/wandb_integration.ipynb) | [![Launch Codespace]][codespace url] [![Launch Binder]](https://mybinder.org/v2/gh/janosh/tensorboard-reducer/main?labpath=examples%2Fwandb_integration.ipynb) [![Open in Google Colab]](https://colab.research.google.com/github/janosh/tensorboard-reducer/blob/main/examples/wandb_integration.ipynb) | Trains PyTorch CNN ensemble on MNIST, logs results to [WandB](https://wandb.ai), downloads metrics from multiple WandB runs, aggregates using `tb-reducer`, then re-uploads to WandB as new runs. |\n\n[Launch Binder]: https://mybinder.org/badge_logo.svg\n[Launch Codespace]: https://img.shields.io/badge/Launch-Codespace-darkblue?logo=github\n[codespace url]: https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=354585417\n[Open in Google Colab]: https://colab.research.google.com/assets/colab-badge.svg\n\n*The mean of 3 runs shown in pink here is less noisy and better suited for comparisons between models or different training techniques than individual runs.*\n\n\n## Installation\n\n```sh\npip install tensorboard-reducer\n```\n\nExcel support requires installing extra dependencies:\n\n```sh\npip install 'tensorboard-reducer[excel]'\n```\n\n## Usage\n\n### CLI\n\n```sh\ntb-reducer runs/of-your-model* -o output-dir -r mean,std,min,max\n```\n\nAll positional CLI arguments are interpreted as input directories and expected to contain TensorBoard event files. These can be specified individually or with wildcards using shell expansion. You can check you're getting the right input directories by running `echo runs/of-your-model*` before passing them to `tb-reducer`.\n\n**Note**: By default, TensorBoard Reducer expects event files to contain identical tags and equal number of steps for all scalars. If you trained one model for 300 epochs and another for 400 and/or recorded different sets of metrics (tags in TensorBoard lingo) for each of them, see CLI flags `--lax-steps` and `--lax-tags` to disable this safeguard. The corresponding kwargs in the Python API are `strict_tags = True` and `strict_steps = True` on `load_tb_events()`.\n\nIn addition, `tb-reducer` has the following flags:\n\n- **`-o/--outpath`** (required): File path or directory where to write output to disk. If `--outpath` is a directory, output will be saved as TensorBoard runs, one new directory created for each reduction suffixed by the `numpy` operation, e.g. `'out/path-mean'`, `'out/path-max'`, etc. If `--outpath` is a file path, it must have `'.csv'`/`'.json'` or `'.xlsx'` (supports compression by using e.g. `.csv.gz`, `json.bz2`) in which case a single file will be created. CSVs will have a two-level header containing one column for each combination of tag (`loss`, `accuracy`, ...) and reduce operation (`mean`, `std`, ...). Tag names will be in top-level header, reduce ops in second level. **Hint**: When saving data as CSV or Excel, use `pandas.read_csv(\"path/to/file.csv\", header=[0, 1], index_col=0)` and `pandas.read_excel(\"path/to/file.xlsx\", header=[0, 1], index_col=0)` to load reduction results into a multi-index dataframe.\n- **`-r/--reduce-ops`** (optional, default: `mean`): Comma-separated names of numpy reduction ops (`mean`, `std`, `min`, `max`, ...). Each reduction is written to a separate `outpath` suffixed by its op name. E.g. if `outpath='reduced-run'`, the mean reduction will be written to `'reduced-run-mean'`.\n- **`-f/--overwrite`** (optional, default: `False`): Whether to overwrite existing output directories/data files (CSV, JSON, Excel). For safety, the overwrite operation will abort with an error if the file/directory to overwrite is not a known data file and does not look like a TensorBoard run directory (i.e. does not start with `'events.out'`).\n- **`--lax-tags`** (optional, default: `False`): Allow different runs have to different sets of tags. In this mode, each tag reduction will run over as many runs as are available for a given tag, even if that's just one. Proceed with caution as not all tags will have the same statistics in downstream analysis.\n- **`--lax-steps`** (optional, default: `False`): Allow tags across different runs to have unequal numbers of steps. In this mode, each reduction will only use as many steps as are available in the shortest run (same behavior as `zip(short_list, long_list)` which stops when `short_list` is exhausted).\n- **`--handle-dup-steps`** (optional, default: `None`): How to handle duplicate values recorded for the same tag and step in a single run. One of `'keep-first'`, `'keep-last'`, `'mean'`. `'keep-first/last'` will keep the first/last occurrence of duplicate steps while 'mean' computes their mean. Default behavior is to raise `ValueError` on duplicate steps.\n- **`--min-runs-per-step`** (optional, default: `None`): Minimum number of runs across which a given step must be recorded to be kept. Steps present across less runs are dropped. Only plays a role if `lax_steps` is true. **Warning**: Be aware that with this setting, you'll be reducing variable number of runs, however many recorded a value for a given step as long as there are at least `--min-runs-per-step`. In other words, the statistics of a reduction will change mid-run. Say you're plotting the mean of an error curve, the sample size of that mean will drop from, say, 10 down to 4 mid-plot if 4 of your models trained for longer than the rest. Be sure to remember when using this.\n- **`-v/--version`** (optional): Get the current version.\n\n### Python API\n\nYou can also import `tensorboard_reducer` into a Python script or Jupyter notebook for more complex operations. Here's a simple example that uses all of the main functions [`load_tb_events`], [`reduce_events`], [`write_data_file`] and [`write_tb_events`] to get you started:\n\n```py\nfrom glob import glob\n\nimport tensorboard_reducer as tbr\n\ninput_event_dirs = sorted(glob(\"glob_pattern/of_tb_directories_to_reduce*\"))\n# where to write reduced TB events, each reduce operation will be in a separate subdirectory\ntb_events_output_dir = \"path/to/output_dir\"\ncsv_out_path = \"path/to/write/reduced-data-as.csv\"\n# whether to abort or overwrite when csv_out_path already exists\noverwrite = False\nreduce_ops = (\"mean\", \"min\", \"max\", \"median\", \"std\", \"var\")\n\nevents_dict = tbr.load_tb_events(input_event_dirs)\n\n# number of recorded tags. e.g. would be 3 if you recorded loss, MAE and R^2\nn_scalars = len(events_dict)\nn_steps, n_events = list(events_dict.values())[0].shape\n\nprint(\n f\"Loaded {n_events} TensorBoard runs with {n_scalars} scalars and {n_steps} steps each\"\n)\nprint(\", \".join(events_dict))\n\nreduced_events = tbr.reduce_events(events_dict, reduce_ops)\n\nfor op in reduce_ops:\n print(f\"Writing '{op}' reduction to '{tb_events_output_dir}-{op}'\")\n\ntbr.write_tb_events(reduced_events, tb_events_output_dir, overwrite)\n\nprint(f\"Writing results to '{csv_out_path}'\")\n\ntbr.write_data_file(reduced_events, csv_out_path, overwrite)\n\nprint(\"Reduction complete\")\n```\n\n[`reduce_events`]: https://github.com/janosh/tensorboard-reducer/blob/6d3468610d2933a23bc355250f9c76e6b6bb0151/tensorboard_reducer/main.py#L12-L14\n[`load_tb_events`]: https://github.com/janosh/tensorboard-reducer/blob/6d3468610d2933a23bc355250f9c76e6b6bb0151/tensorboard_reducer/load.py#L10-L16\n[`write_data_file`]: https://github.com/janosh/tensorboard-reducer/blob/6d3468610d2933a23bc355250f9c76e6b6bb0151/tensorboard_reducer/write.py#L111-L115\n[`write_tb_events`]: https://github.com/janosh/tensorboard-reducer/blob/6d3468610d2933a23bc355250f9c76e6b6bb0151/tensorboard_reducer/write.py#L45-L49\n",
"bugtrack_url": null,
"license": "MIT License Copyright (c) 2021 Janosh Riebesell Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. The software is provided \"as is\", without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the software. ",
"summary": "Reduce multiple TensorBoard runs to new event (or CSV) files",
"version": "0.3.1",
"project_urls": {
"Homepage": "https://github.com/janosh/tensorboard-reducer",
"Package": "https://pypi.org/project/tensorboard-reducer"
},
"split_keywords": [
"aggregate",
"averaging",
"logs",
"machine-learning",
"pytorch",
"reducer",
"runs",
"statistics",
"tensorboard"
],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "a4be8325bd474f40c49f47e9a2edce9a4cf4fe3babcaae001e43f591f14c59d7",
"md5": "4fa60e6dc2a116e64342777deaea3dba",
"sha256": "0196a8ec49b3c4535fe42a13dd5407953622e169985fc0ad5f7528bdfba5afbf"
},
"downloads": -1,
"filename": "tensorboard_reducer-0.3.1-py2.py3-none-any.whl",
"has_sig": false,
"md5_digest": "4fa60e6dc2a116e64342777deaea3dba",
"packagetype": "bdist_wheel",
"python_version": "py2.py3",
"requires_python": ">=3.8",
"size": 17541,
"upload_time": "2023-09-21T18:58:58",
"upload_time_iso_8601": "2023-09-21T18:58:58.756575Z",
"url": "https://files.pythonhosted.org/packages/a4/be/8325bd474f40c49f47e9a2edce9a4cf4fe3babcaae001e43f591f14c59d7/tensorboard_reducer-0.3.1-py2.py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "46e3cd4a4c093db6e0d0f8173e1071ee644e488b49a5afe66cc3de51d930e4e5",
"md5": "192273c2b4c7e18a7cc636e473eabb6f",
"sha256": "4e414d2c84c330e837c0acd728a2f74317d086003e87cb76429a24f082dbf66b"
},
"downloads": -1,
"filename": "tensorboard-reducer-0.3.1.tar.gz",
"has_sig": false,
"md5_digest": "192273c2b4c7e18a7cc636e473eabb6f",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.8",
"size": 23299,
"upload_time": "2023-09-21T18:59:00",
"upload_time_iso_8601": "2023-09-21T18:59:00.811350Z",
"url": "https://files.pythonhosted.org/packages/46/e3/cd4a4c093db6e0d0f8173e1071ee644e488b49a5afe66cc3de51d930e4e5/tensorboard-reducer-0.3.1.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2023-09-21 18:59:00",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "janosh",
"github_project": "tensorboard-reducer",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "tensorboard-reducer"
}
