# UIS-RNN
[](https://github.com/google/uis-rnn/actions/workflows/pythonapp.yml)
[](https://pypi.python.org/pypi/uisrnn)
[](https://pypi.org/project/uisrnn)
[](https://pepy.tech/project/uisrnn)
[](https://codecov.io/gh/google/uis-rnn)
[](https://google.github.io/uis-rnn)
## Overview
This is the library for the
*Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN)* algorithm.
UIS-RNN solves the problem of segmenting and clustering sequential data
by learning from examples.
This algorithm was originally proposed in the paper
[Fully Supervised Speaker Diarization](https://arxiv.org/abs/1810.04719).
The work has been introduced by
[Google AI Blog](https://ai.googleblog.com/2018/11/accurate-online-speaker-diarization.html).
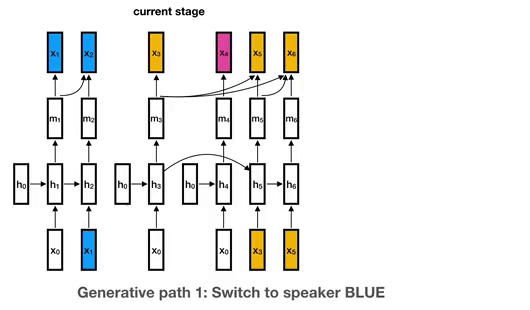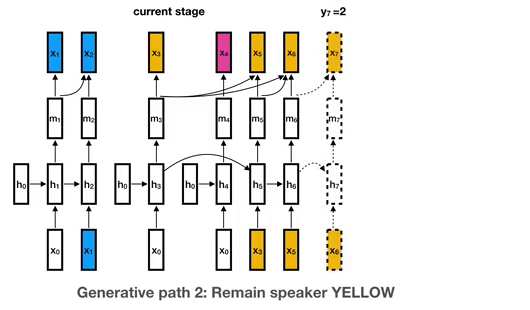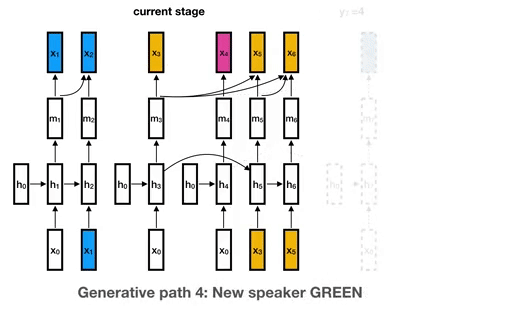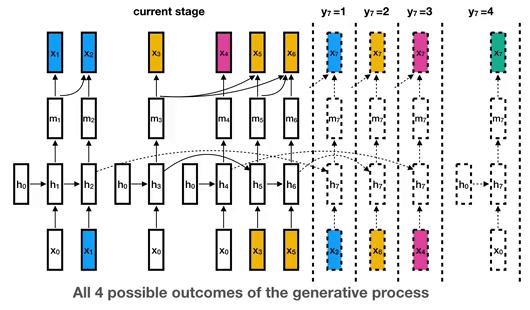
## Disclaimer
This open source implementation is slightly different than the internal one
which we used to produce the results in the
[paper](https://arxiv.org/abs/1810.04719), due to dependencies on
some internal libraries.
We CANNOT share the data, code, or model for the speaker recognition system
([d-vector embeddings](https://google.github.io/speaker-id/publications/GE2E/))
used in the paper, since the speaker recognition system
heavily depends on Google's internal infrastructure and proprietary data.
**This library is NOT an official Google product.**
We welcome community contributions ([guidelines](CONTRIBUTING.md))
to the [`uisrnn/contrib`](uisrnn/contrib) folder.
But we won't be responsible for the correctness of any community contributions.
## Dependencies
This library depends on:
* python 3.5+
* numpy 1.15.1
* pytorch 1.3.0
* scipy 1.1.0 (for evaluation only)
## Getting Started
[](https://www.youtube.com/watch?v=pGkqwRPzx9U)
### Install the package
Without downloading the repository, you can install the
[package](https://pypi.org/project/uisrnn/) by:
```
pip3 install uisrnn
```
or
```
python3 -m pip install uisrnn
```
### Run the demo
To get started, simply run this command:
```bash
python3 demo.py --train_iteration=1000 -l=0.001
```
This will train a UIS-RNN model using `data/toy_training_data.npz`,
then store the model on disk, perform inference on `data/toy_testing_data.npz`,
print the inference results, and save the averaged accuracy in a text file.
PS. The files under `data/` are manually generated *toy data*,
for demonstration purpose only.
These data are very simple, so we are supposed to get 100% accuracy on the
testing data.
### Run the tests
You can also verify the correctness of this library by running:
```bash
bash run_tests.sh
```
If you fork this library and make local changes, be sure to use these tests
as a sanity check.
Besides, these tests are also great examples for learning
the APIs, especially `tests/integration_test.py`.
## Core APIs
### Glossary
| General Machine Learning | Speaker Diarization |
|--------------------------|------------------------|
| Sequence | Utterance |
| Observation / Feature | Embedding / d-vector |
| Label / Cluster ID | Speaker |
### Arguments
In your main script, call this function to get the arguments:
```python
model_args, training_args, inference_args = uisrnn.parse_arguments()
```
### Model construction
All algorithms are implemented as the `UISRNN` class. First, construct a
`UISRNN` object by:
```python
model = uisrnn.UISRNN(args)
```
The definitions of the args are described in `uisrnn/arguments.py`.
See `model_parser`.
### Training
Next, train the model by calling the `fit()` function:
```python
model.fit(train_sequences, train_cluster_ids, args)
```
The definitions of the args are described in `uisrnn/arguments.py`.
See `training_parser`.
The `fit()` function accepts two types of input, as described below.
#### Input as list of sequences (recommended)
Here, `train_sequences` is a list of observation sequences.
Each observation sequence is a 2-dim numpy array of type `float`.
* The first dimension is the length of this sequence. And the length
can vary from one sequence to another.
* The second dimension is the size of each observation. This
must be consistent among all sequences. For speaker diarization,
the observation could be the
[d-vector embeddings](https://google.github.io/speaker-id/publications/GE2E/).
`train_cluster_ids` is also a list, which has the same length as
`train_sequences`. Each element of `train_cluster_ids` is a 1-dim list or
numpy array of strings, containing the ground truth labels for the
corresponding sequence in `train_sequences`.
For speaker diarization, these labels are the speaker identifiers for each
observation.
When calling `fit()` in this way, please be very careful with the argument
`--enforce_cluster_id_uniqueness`.
For example, assume:
```python
train_cluster_ids = [['a', 'b'], ['a', 'c']]
```
If the label `'a'` from the two sequences refers to the same cluster across
the entire dataset, then we should have `enforce_cluster_id_uniqueness=False`;
otherwise, if `'a'` is only a local indicator to distinguish from `'b'` in the
1st sequence, and to distinguish from `'c'` in the 2nd sequence, then we should
have `enforce_cluster_id_uniqueness=True`.
Also, please note that, when calling `fit()` in this way, we are going to
concatenate all sequences and all cluster IDs, and delegate to
the next section below.
#### Input as single concatenated sequence
Here, `train_sequences` should be a single 2-dim numpy array of type `float`,
for the **concatenated** observation sequences.
For example, if you have *M* training utterances,
and each utterance is a sequence of *L* embeddings. Each embedding is
a vector of *D* numbers. Then the shape of `train_sequences` is *N * D*,
where *N = M * L*.
`train_cluster_ids` is a 1-dim list or numpy array of strings, of length *N*.
It is the **concatenated** ground truth labels of all training data.
Since we are concatenating observation sequences, it is important to note that,
ground truth labels in `train_cluster_id` across different sequences are
supposed to be **globally unique**.
For example, if the set of labels in the first
sequence is `{'A', 'B', 'C'}`, and the set of labels in the second sequence
is `{'B', 'C', 'D'}`. Then before concatenation, we should rename them to
something like `{'1_A', '1_B', '1_C'}` and `{'2_B', '2_C', '2_D'}`,
unless `'B'` and `'C'` in the two sequences are meaningfully identical
(in speaker diarization, this means they are the same speakers across
utterances). This part will be automatically taken care of by the argument
`--enforce_cluster_id_uniqueness` for the previous section.
The reason we concatenate all training sequences is that, we will be resampling
and *block-wise* shuffling the training data as a **data augmentation**
process, such that we result in a robust model even when there is insufficient
number of training sequences.
#### Training on large datasets
For large datasets, the data usually could not be loaded into memory at once.
In such cases, the `fit()` function needs to be called multiple times.
Here we provide a few guidelines as our suggestions:
1. Do not feed different datasets into different calls of `fit()`. Instead,
for each call of `fit()`, the input should cover sequences from
different datasets.
2. For each call to the `fit()` function, make the size of input roughly the
same. And, don't make the input size too small.
### Prediction
Once we are done with training, we can run the trained model to perform
inference on new sequences by calling the `predict()` function:
```python
predicted_cluster_ids = model.predict(test_sequences, args)
```
Here `test_sequences` should be a list of 2-dim numpy arrays of type `float`,
corresponding to the observation sequences for testing.
The returned `predicted_cluster_ids` is a list of the same size as
`test_sequences`. Each element of `predicted_cluster_ids` is a list of integers,
with the same length as the corresponding test sequence.
You can also use a single test sequence for `test_sequences`. Then the returned
`predicted_cluster_ids` will also be a single list of integers.
The definitions of the args are described in `uisrnn/arguments.py`.
See `inference_parser`.
## Citations
Our paper is cited as:
```
@inproceedings{zhang2019fully,
title={Fully supervised speaker diarization},
author={Zhang, Aonan and Wang, Quan and Zhu, Zhenyao and Paisley, John and Wang, Chong},
booktitle={International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={6301--6305},
year={2019},
organization={IEEE}
}
```
## References
### Baseline diarization system
To learn more about our baseline diarization system based on
*unsupervised clustering* algorithms, check out
[this site](https://google.github.io/speaker-id/publications/LstmDiarization/).
A Python re-implementation of the *spectral clustering* algorithm used in this
paper is available [here](https://github.com/wq2012/SpectralCluster).
The ground truth labels for the
[NIST SRE 2000](https://catalog.ldc.upenn.edu/LDC2001S97)
dataset (Disk6 and Disk8) can be found
[here](https://github.com/google/speaker-id/tree/master/publications/LstmDiarization/evaluation/NIST_SRE2000).
For more public resources on speaker diarization, check out [awesome-diarization](https://github.com/wq2012/awesome-diarization).
### Speaker recognizer/encoder
To learn more about our speaker embedding system, check out
[this site](https://google.github.io/speaker-id/publications/GE2E/).
We are aware of several third-party implementations of this work:
* [Resemblyzer: PyTorch implementation by resemble-ai](https://github.com/resemble-ai/Resemblyzer)
* [TensorFlow implementation by Janghyun1230](https://github.com/Janghyun1230/Speaker_Verification)
* [PyTorch implementaion by HarryVolek](https://github.com/HarryVolek/PyTorch_Speaker_Verification) - with UIS-RNN integration
* [PyTorch implementation as part of SV2TTS](https://github.com/CorentinJ/Real-Time-Voice-Cloning)
Please use your own judgement to decide whether you want to use these
implementations.
**We are NOT responsible for the correctness of any third-party implementations.**
## Variants
Here we list the repositories that are based on UIS-RNN, but integrated with
other technologies or added some improvements.
| Link | Description |
| ---- | ----------- |
| [taylorlu/Speaker-Diarization](https://github.com/taylorlu/Speaker-Diarization)  | Speaker diarization using UIS-RNN and GhostVLAD. An easier way to support openset speakers. |
| [DonkeyShot21/uis-rnn-sml](https://github.com/DonkeyShot21/uis-rnn-sml)  | A variant of UIS-RNN, for the paper Supervised Online Diarization with Sample Mean Loss for Multi-Domain Data. |
Raw data
{
"_id": null,
"home_page": "https://github.com/google/uis-rnn",
"name": "uisrnn",
"maintainer": null,
"docs_url": null,
"requires_python": null,
"maintainer_email": null,
"keywords": null,
"author": "Quan Wang",
"author_email": "quanw@google.com",
"download_url": "https://files.pythonhosted.org/packages/ea/18/4c257f1735517ce17d2fd47fbce4e06f49370aae6417f89b3fb526d3e291/uisrnn-0.1.2.tar.gz",
"platform": null,
"description": "# UIS-RNN\n[](https://github.com/google/uis-rnn/actions/workflows/pythonapp.yml)\n[](https://pypi.python.org/pypi/uisrnn)\n[](https://pypi.org/project/uisrnn)\n[](https://pepy.tech/project/uisrnn)\n[](https://codecov.io/gh/google/uis-rnn)\n[](https://google.github.io/uis-rnn)\n\n## Overview\n\nThis is the library for the\n*Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN)* algorithm.\nUIS-RNN solves the problem of segmenting and clustering sequential data\nby learning from examples.\n\nThis algorithm was originally proposed in the paper\n[Fully Supervised Speaker Diarization](https://arxiv.org/abs/1810.04719).\n\nThe work has been introduced by\n[Google AI Blog](https://ai.googleblog.com/2018/11/accurate-online-speaker-diarization.html).\n\n\n\n## Disclaimer\n\nThis open source implementation is slightly different than the internal one\nwhich we used to produce the results in the\n[paper](https://arxiv.org/abs/1810.04719), due to dependencies on\nsome internal libraries.\n\nWe CANNOT share the data, code, or model for the speaker recognition system\n([d-vector embeddings](https://google.github.io/speaker-id/publications/GE2E/))\nused in the paper, since the speaker recognition system\nheavily depends on Google's internal infrastructure and proprietary data.\n\n**This library is NOT an official Google product.**\n\nWe welcome community contributions ([guidelines](CONTRIBUTING.md))\nto the [`uisrnn/contrib`](uisrnn/contrib) folder.\nBut we won't be responsible for the correctness of any community contributions.\n\n## Dependencies\n\nThis library depends on:\n\n* python 3.5+\n* numpy 1.15.1\n* pytorch 1.3.0\n* scipy 1.1.0 (for evaluation only)\n\n## Getting Started\n\n[](https://www.youtube.com/watch?v=pGkqwRPzx9U)\n\n### Install the package\n\nWithout downloading the repository, you can install the\n[package](https://pypi.org/project/uisrnn/) by:\n\n```\npip3 install uisrnn\n```\n\nor\n\n```\npython3 -m pip install uisrnn\n```\n\n### Run the demo\n\nTo get started, simply run this command:\n\n```bash\npython3 demo.py --train_iteration=1000 -l=0.001\n```\n\nThis will train a UIS-RNN model using `data/toy_training_data.npz`,\nthen store the model on disk, perform inference on `data/toy_testing_data.npz`,\nprint the inference results, and save the averaged accuracy in a text file.\n\nPS. The files under `data/` are manually generated *toy data*,\nfor demonstration purpose only.\nThese data are very simple, so we are supposed to get 100% accuracy on the\ntesting data.\n\n### Run the tests\n\nYou can also verify the correctness of this library by running:\n\n```bash\nbash run_tests.sh\n```\n\nIf you fork this library and make local changes, be sure to use these tests\nas a sanity check.\n\nBesides, these tests are also great examples for learning\nthe APIs, especially `tests/integration_test.py`.\n\n## Core APIs\n\n### Glossary\n\n| General Machine Learning | Speaker Diarization |\n|--------------------------|------------------------|\n| Sequence | Utterance |\n| Observation / Feature | Embedding / d-vector |\n| Label / Cluster ID | Speaker |\n\n### Arguments\n\nIn your main script, call this function to get the arguments:\n\n```python\nmodel_args, training_args, inference_args = uisrnn.parse_arguments()\n```\n\n### Model construction\n\nAll algorithms are implemented as the `UISRNN` class. First, construct a\n`UISRNN` object by:\n\n```python\nmodel = uisrnn.UISRNN(args)\n```\n\nThe definitions of the args are described in `uisrnn/arguments.py`.\nSee `model_parser`.\n\n### Training\n\nNext, train the model by calling the `fit()` function:\n\n```python\nmodel.fit(train_sequences, train_cluster_ids, args)\n```\n\nThe definitions of the args are described in `uisrnn/arguments.py`.\nSee `training_parser`.\n\nThe `fit()` function accepts two types of input, as described below.\n\n#### Input as list of sequences (recommended)\n\nHere, `train_sequences` is a list of observation sequences.\nEach observation sequence is a 2-dim numpy array of type `float`.\n\n* The first dimension is the length of this sequence. And the length\n can vary from one sequence to another.\n* The second dimension is the size of each observation. This\n must be consistent among all sequences. For speaker diarization,\n the observation could be the\n [d-vector embeddings](https://google.github.io/speaker-id/publications/GE2E/).\n\n`train_cluster_ids` is also a list, which has the same length as\n`train_sequences`. Each element of `train_cluster_ids` is a 1-dim list or\nnumpy array of strings, containing the ground truth labels for the\ncorresponding sequence in `train_sequences`.\nFor speaker diarization, these labels are the speaker identifiers for each\nobservation.\n\nWhen calling `fit()` in this way, please be very careful with the argument\n`--enforce_cluster_id_uniqueness`.\n\nFor example, assume:\n\n```python\ntrain_cluster_ids = [['a', 'b'], ['a', 'c']]\n```\n\nIf the label `'a'` from the two sequences refers to the same cluster across\nthe entire dataset, then we should have `enforce_cluster_id_uniqueness=False`;\notherwise, if `'a'` is only a local indicator to distinguish from `'b'` in the\n1st sequence, and to distinguish from `'c'` in the 2nd sequence, then we should\nhave `enforce_cluster_id_uniqueness=True`.\n\nAlso, please note that, when calling `fit()` in this way, we are going to\nconcatenate all sequences and all cluster IDs, and delegate to\nthe next section below.\n\n#### Input as single concatenated sequence\n\nHere, `train_sequences` should be a single 2-dim numpy array of type `float`,\nfor the **concatenated** observation sequences.\n\nFor example, if you have *M* training utterances,\nand each utterance is a sequence of *L* embeddings. Each embedding is\na vector of *D* numbers. Then the shape of `train_sequences` is *N * D*,\nwhere *N = M * L*.\n\n`train_cluster_ids` is a 1-dim list or numpy array of strings, of length *N*.\nIt is the **concatenated** ground truth labels of all training data.\n\nSince we are concatenating observation sequences, it is important to note that,\nground truth labels in `train_cluster_id` across different sequences are\nsupposed to be **globally unique**.\n\nFor example, if the set of labels in the first\nsequence is `{'A', 'B', 'C'}`, and the set of labels in the second sequence\nis `{'B', 'C', 'D'}`. Then before concatenation, we should rename them to\nsomething like `{'1_A', '1_B', '1_C'}` and `{'2_B', '2_C', '2_D'}`,\nunless `'B'` and `'C'` in the two sequences are meaningfully identical\n(in speaker diarization, this means they are the same speakers across\nutterances). This part will be automatically taken care of by the argument\n`--enforce_cluster_id_uniqueness` for the previous section.\n\nThe reason we concatenate all training sequences is that, we will be resampling\nand *block-wise* shuffling the training data as a **data augmentation**\nprocess, such that we result in a robust model even when there is insufficient\nnumber of training sequences.\n\n#### Training on large datasets\n\nFor large datasets, the data usually could not be loaded into memory at once.\nIn such cases, the `fit()` function needs to be called multiple times.\n\nHere we provide a few guidelines as our suggestions:\n\n1. Do not feed different datasets into different calls of `fit()`. Instead,\n for each call of `fit()`, the input should cover sequences from\n different datasets.\n2. For each call to the `fit()` function, make the size of input roughly the\n same. And, don't make the input size too small.\n\n### Prediction\n\nOnce we are done with training, we can run the trained model to perform\ninference on new sequences by calling the `predict()` function:\n\n```python\npredicted_cluster_ids = model.predict(test_sequences, args)\n```\n\nHere `test_sequences` should be a list of 2-dim numpy arrays of type `float`,\ncorresponding to the observation sequences for testing.\n\nThe returned `predicted_cluster_ids` is a list of the same size as\n`test_sequences`. Each element of `predicted_cluster_ids` is a list of integers,\nwith the same length as the corresponding test sequence.\n\nYou can also use a single test sequence for `test_sequences`. Then the returned\n`predicted_cluster_ids` will also be a single list of integers.\n\nThe definitions of the args are described in `uisrnn/arguments.py`.\nSee `inference_parser`.\n\n## Citations\n\nOur paper is cited as:\n\n```\n@inproceedings{zhang2019fully,\n title={Fully supervised speaker diarization},\n author={Zhang, Aonan and Wang, Quan and Zhu, Zhenyao and Paisley, John and Wang, Chong},\n booktitle={International Conference on Acoustics, Speech and Signal Processing (ICASSP)},\n pages={6301--6305},\n year={2019},\n organization={IEEE}\n}\n```\n\n## References\n\n### Baseline diarization system\n\nTo learn more about our baseline diarization system based on\n*unsupervised clustering* algorithms, check out\n[this site](https://google.github.io/speaker-id/publications/LstmDiarization/).\n\nA Python re-implementation of the *spectral clustering* algorithm used in this\npaper is available [here](https://github.com/wq2012/SpectralCluster).\n\nThe ground truth labels for the\n[NIST SRE 2000](https://catalog.ldc.upenn.edu/LDC2001S97)\ndataset (Disk6 and Disk8) can be found\n[here](https://github.com/google/speaker-id/tree/master/publications/LstmDiarization/evaluation/NIST_SRE2000).\n\nFor more public resources on speaker diarization, check out [awesome-diarization](https://github.com/wq2012/awesome-diarization).\n\n### Speaker recognizer/encoder\n\nTo learn more about our speaker embedding system, check out\n[this site](https://google.github.io/speaker-id/publications/GE2E/).\n\nWe are aware of several third-party implementations of this work:\n\n* [Resemblyzer: PyTorch implementation by resemble-ai](https://github.com/resemble-ai/Resemblyzer)\n* [TensorFlow implementation by Janghyun1230](https://github.com/Janghyun1230/Speaker_Verification)\n* [PyTorch implementaion by HarryVolek](https://github.com/HarryVolek/PyTorch_Speaker_Verification) - with UIS-RNN integration\n* [PyTorch implementation as part of SV2TTS](https://github.com/CorentinJ/Real-Time-Voice-Cloning)\n\nPlease use your own judgement to decide whether you want to use these\nimplementations.\n\n**We are NOT responsible for the correctness of any third-party implementations.**\n\n## Variants\n\nHere we list the repositories that are based on UIS-RNN, but integrated with\nother technologies or added some improvements.\n\n| Link | Description |\n| ---- | ----------- |\n| [taylorlu/Speaker-Diarization](https://github.com/taylorlu/Speaker-Diarization)  | Speaker diarization using UIS-RNN and GhostVLAD. An easier way to support openset speakers. |\n| [DonkeyShot21/uis-rnn-sml](https://github.com/DonkeyShot21/uis-rnn-sml)  | A variant of UIS-RNN, for the paper Supervised Online Diarization with Sample Mean Loss for Multi-Domain Data. |\n",
"bugtrack_url": null,
"license": null,
"summary": "Unbounded Interleaved-State Recurrent Neural Network",
"version": "0.1.2",
"project_urls": {
"Homepage": "https://github.com/google/uis-rnn"
},
"split_keywords": [],
"urls": [
{
"comment_text": "",
"digests": {
"blake2b_256": "6053ef80ed0ec309c2679665b7122c46c1ce1bc5c1ab67c7c0c97d8be259372b",
"md5": "b769c7ef8b9409e4f4a450eff56bc1ad",
"sha256": "17ae3b1a46b9ef183301958b456a2e8e1e66bff3e8de8b62d8452aaab27d6440"
},
"downloads": -1,
"filename": "uisrnn-0.1.2-py3-none-any.whl",
"has_sig": false,
"md5_digest": "b769c7ef8b9409e4f4a450eff56bc1ad",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": null,
"size": 28071,
"upload_time": "2024-09-25T14:33:05",
"upload_time_iso_8601": "2024-09-25T14:33:05.579097Z",
"url": "https://files.pythonhosted.org/packages/60/53/ef80ed0ec309c2679665b7122c46c1ce1bc5c1ab67c7c0c97d8be259372b/uisrnn-0.1.2-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": "",
"digests": {
"blake2b_256": "ea184c257f1735517ce17d2fd47fbce4e06f49370aae6417f89b3fb526d3e291",
"md5": "262ca9e93cad03a1ad572ad31f4ce137",
"sha256": "f3b45fcb45e80490094ef7d791a70ecbe949004656e0427134c26ffa4f2c919a"
},
"downloads": -1,
"filename": "uisrnn-0.1.2.tar.gz",
"has_sig": false,
"md5_digest": "262ca9e93cad03a1ad572ad31f4ce137",
"packagetype": "sdist",
"python_version": "source",
"requires_python": null,
"size": 27492,
"upload_time": "2024-09-25T14:33:06",
"upload_time_iso_8601": "2024-09-25T14:33:06.689655Z",
"url": "https://files.pythonhosted.org/packages/ea/18/4c257f1735517ce17d2fd47fbce4e06f49370aae6417f89b3fb526d3e291/uisrnn-0.1.2.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2024-09-25 14:33:06",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "google",
"github_project": "uis-rnn",
"travis_ci": false,
"coveralls": true,
"github_actions": true,
"requirements": [
{
"name": "numpy",
"specs": [
[
">=",
"1.18.0"
]
]
},
{
"name": "scipy",
"specs": [
[
">=",
"1.1.0"
]
]
},
{
"name": "torch",
"specs": [
[
">=",
"1.4.0"
]
]
},
{
"name": "codecov",
"specs": [
[
"==",
"2.1.13"
]
]
},
{
"name": "coverage",
"specs": [
[
"==",
"7.6.0"
]
]
},
{
"name": "colortimelog",
"specs": []
}
],
"lcname": "uisrnn"
}


