| Name | voice-mode-azure JSON |
| Version |
2.13.0
 JSON
JSON |
| download |
| home_page | None |
| Summary | VoiceMode with Azure OpenAI support - Voice interaction capabilities for AI assistants |
| upload_time | 2025-07-13 01:42:09 |
| maintainer | None |
| docs_url | None |
| author | None |
| requires_python | >=3.10 |
| license | MIT |
| keywords |
ai
livekit
llm
mcp
speech
stt
tts
voice
|
| VCS |
 |
| bugtrack_url |
|
| requirements |
No requirements were recorded.
|
| Travis-CI |
No Travis.
|
| coveralls test coverage |
No coveralls.
|
# Voice Mode
> **Install via:** `uvx voice-mode` | `pip install voice-mode` | [getvoicemode.com](https://getvoicemode.com)
[](https://pepy.tech/project/voice-mode)
[](https://pepy.tech/project/voice-mode)
[](https://pepy.tech/project/voice-mode)
[](https://voice-mode.readthedocs.io/en/latest/?badge=latest)
Natural voice conversations for AI assistants. Voice Mode brings human-like voice interactions to Claude, ChatGPT, and other LLMs through the Model Context Protocol (MCP).
## 🖥️ Compatibility
**Runs on:** Linux • macOS • Windows (WSL) | **Python:** 3.10+
## ✨ Features
- **🎙️ Voice conversations** with Claude - ask questions and hear responses
- **🔄 Multiple transports** - local microphone or LiveKit room-based communication
- **🗣️ OpenAI-compatible** - works with any STT/TTS service (local or cloud)
- **⚡ Real-time** - low-latency voice interactions with automatic transport selection
- **🔧 MCP Integration** - seamless with Claude Desktop and other MCP clients
- **🎯 Silence detection** - automatically stops recording when you stop speaking (no more waiting!)
## 🎯 Simple Requirements
**All you need to get started:**
1. **🔑 OpenAI API Key** (or compatible service) - for speech-to-text and text-to-speech
2. **🎤 Computer with microphone and speakers** OR **☁️ LiveKit server** ([LiveKit Cloud](https://docs.livekit.io/home/cloud/) or [self-hosted](https://github.com/livekit/livekit))
## Quick Start
> 📖 **Using a different tool?** See our [Integration Guides](docs/integrations/README.md) for Cursor, VS Code, Gemini CLI, and more!
```bash
npm install -g @anthropic-ai/claude-code
curl -LsSf https://astral.sh/uv/install.sh | sh
claude mcp add --scope user voice-mode uvx voice-mode
export OPENAI_API_KEY=your-openai-key
claude converse
```
## 🎬 Demo
Watch Voice Mode in action with Claude Code:
[](https://www.youtube.com/watch?v=cYdwOD_-dQc)
### Voice Mode with Gemini CLI
See Voice Mode working with Google's Gemini CLI (their implementation of Claude Code):
[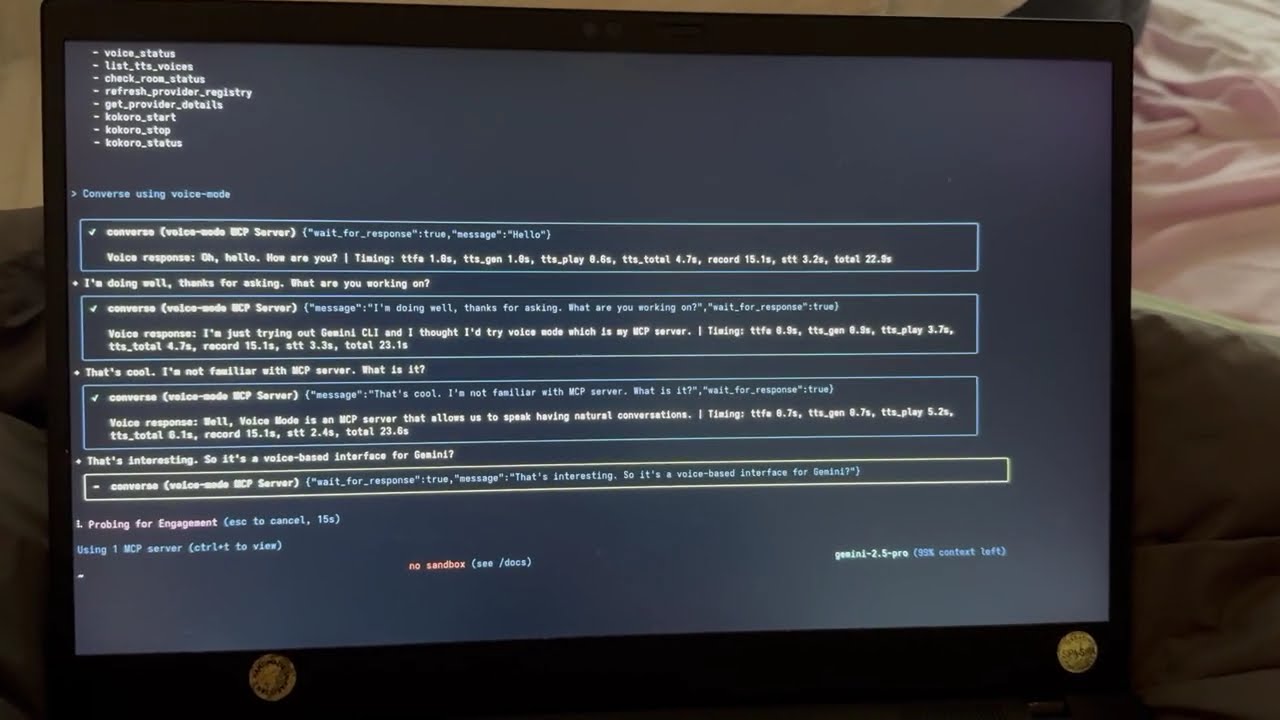](https://www.youtube.com/watch?v=HC6BGxjCVnM)
## Example Usage
Once configured, try these prompts with Claude:
### 👨💻 Programming & Development
- `"Let's debug this error together"` - Explain the issue verbally, paste code, and discuss solutions
- `"Walk me through this code"` - Have Claude explain complex code while you ask questions
- `"Let's brainstorm the architecture"` - Design systems through natural conversation
- `"Help me write tests for this function"` - Describe requirements and iterate verbally
### 💡 General Productivity
- `"Let's do a daily standup"` - Practice presentations or organize your thoughts
- `"Interview me about [topic]"` - Prepare for interviews with back-and-forth Q&A
- `"Be my rubber duck"` - Explain problems out loud to find solutions
### 🎯 Voice Control Features
- `"Read this error message"` (Claude speaks, then waits for your response)
- `"Just give me a quick summary"` (Claude speaks without waiting)
- Use `converse("message", wait_for_response=False)` for one-way announcements
The `converse` function makes voice interactions natural - it automatically waits for your response by default, creating a real conversation flow.
## Supported Tools
Voice Mode works with your favorite AI coding assistants:
- 🤖 **[Claude Code](docs/integrations/claude-code/README.md)** - Anthropic's official CLI
- 🖥️ **[Claude Desktop](docs/integrations/claude-desktop/README.md)** - Desktop application
- 🌟 **[Gemini CLI](docs/integrations/gemini-cli/README.md)** - Google's CLI tool
- ⚡ **[Cursor](docs/integrations/cursor/README.md)** - AI-first code editor
- 💻 **[VS Code](docs/integrations/vscode/README.md)** - With MCP preview support
- 🦘 **[Roo Code](docs/integrations/roo-code/README.md)** - AI dev team in VS Code
- 🔧 **[Cline](docs/integrations/cline/README.md)** - Autonomous coding agent
- ⚡ **[Zed](docs/integrations/zed/README.md)** - High-performance editor
- 🏄 **[Windsurf](docs/integrations/windsurf/README.md)** - Agentic IDE by Codeium
- 🔄 **[Continue](docs/integrations/continue/README.md)** - Open-source AI assistant
## Installation
### Prerequisites
- Python >= 3.10
- [Astral UV](https://github.com/astral-sh/uv) - Package manager (install with `curl -LsSf https://astral.sh/uv/install.sh | sh`)
- OpenAI API Key (or compatible service)
#### System Dependencies
<details>
<summary><strong>Ubuntu/Debian</strong></summary>
```bash
sudo apt update
sudo apt install -y python3-dev libasound2-dev libasound2-plugins libportaudio2 portaudio19-dev ffmpeg pulseaudio pulseaudio-utils
```
**Note for WSL2 users**: WSL2 requires additional audio packages (pulseaudio, libasound2-plugins) for microphone access. See our [WSL2 Microphone Access Guide](docs/troubleshooting/wsl2-microphone-access.md) if you encounter issues.
</details>
<details>
<summary><strong>Fedora/RHEL</strong></summary>
```bash
sudo dnf install python3-devel alsa-lib-devel portaudio-devel ffmpeg
```
</details>
<details>
<summary><strong>macOS</strong></summary>
```bash
# Install Homebrew if not already installed
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# Install dependencies
brew install portaudio ffmpeg
```
</details>
<details>
<summary><strong>Windows (WSL)</strong></summary>
Follow the Ubuntu/Debian instructions above within WSL.
</details>
### Quick Install
```bash
# Using Claude Code (recommended)
claude mcp add --scope user voice-mode uvx voice-mode
# Using UV
uvx voice-mode
# Using pip
pip install voice-mode
```
### Configuration for AI Coding Assistants
> 📖 **Looking for detailed setup instructions?** Check our comprehensive [Integration Guides](docs/integrations/README.md) for step-by-step instructions for each tool!
Below are quick configuration snippets. For full installation and setup instructions, see the integration guides above.
<details>
<summary><strong>Claude Code (CLI)</strong></summary>
```bash
claude mcp add voice-mode -- uvx voice-mode
```
Or with environment variables:
```bash
claude mcp add voice-mode --env OPENAI_API_KEY=your-openai-key -- uvx voice-mode
```
</details>
<details>
<summary><strong>Claude Desktop</strong></summary>
**macOS**: `~/Library/Application Support/Claude/claude_desktop_config.json`
**Windows**: `%APPDATA%\Claude\claude_desktop_config.json`
```json
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Cline</strong></summary>
Add to your Cline MCP settings:
**Windows**:
```json
{
"mcpServers": {
"voice-mode": {
"command": "cmd",
"args": ["/c", "uvx", "voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
```
**macOS/Linux**:
```json
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Continue</strong></summary>
Add to your `.continue/config.json`:
```json
{
"experimental": {
"modelContextProtocolServers": [
{
"transport": {
"type": "stdio",
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
]
}
}
```
</details>
<details>
<summary><strong>Cursor</strong></summary>
Add to `~/.cursor/mcp.json`:
```json
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
```
</details>
<details>
<summary><strong>VS Code</strong></summary>
Add to your VS Code MCP config:
```json
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Windsurf</strong></summary>
```json
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
```
</details>
<details>
<summary><strong>Zed</strong></summary>
Add to your Zed settings.json:
```json
{
"context_servers": {
"voice-mode": {
"command": {
"path": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
}
```
</details>
<details>
<summary><strong>Roo Code</strong></summary>
1. Open VS Code Settings (`Ctrl/Cmd + ,`)
2. Search for "roo" in the settings search bar
3. Find "Roo-veterinaryinc.roo-cline → settings → Mcp_settings.json"
4. Click "Edit in settings.json"
5. Add Voice Mode configuration:
```json
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
```
</details>
### Alternative Installation Options
<details>
<summary><strong>Using Docker</strong></summary>
```bash
docker run -it --rm \
-e OPENAI_API_KEY=your-openai-key \
--device /dev/snd \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-e DISPLAY=$DISPLAY \
ghcr.io/mbailey/voicemode:latest
```
</details>
<details>
<summary><strong>Using pipx</strong></summary>
```bash
pipx install voice-mode
```
</details>
<details>
<summary><strong>From source</strong></summary>
```bash
git clone https://github.com/mbailey/voicemode.git
cd voicemode
pip install -e .
```
</details>
## Tools
| Tool | Description | Key Parameters |
|------|-------------|----------------|
| `converse` | Have a voice conversation - speak and optionally listen | `message`, `wait_for_response` (default: true), `listen_duration` (default: 30s), `transport` (auto/local/livekit) |
| `listen_for_speech` | Listen for speech and convert to text | `duration` (default: 5s) |
| `check_room_status` | Check LiveKit room status and participants | None |
| `check_audio_devices` | List available audio input/output devices | None |
| `start_kokoro` | Start the Kokoro TTS service | `models_dir` (optional, defaults to ~/Models/kokoro) |
| `stop_kokoro` | Stop the Kokoro TTS service | None |
| `kokoro_status` | Check the status of Kokoro TTS service | None |
**Note:** The `converse` tool is the primary interface for voice interactions, combining speaking and listening in a natural flow.
## Configuration
- 📖 **[Integration Guides](docs/integrations/README.md)** - Step-by-step setup for each tool
- 🔧 **[Configuration Reference](docs/configuration.md)** - All environment variables
- 📁 **[Config Examples](config-examples/)** - Ready-to-use configuration files
### Quick Setup
The only required configuration is your OpenAI API key:
```bash
export OPENAI_API_KEY="your-key"
```
### Optional Settings
```bash
# Custom STT/TTS services (OpenAI-compatible)
export STT_BASE_URL="http://127.0.0.1:2022/v1" # Local Whisper
export TTS_BASE_URL="http://127.0.0.1:8880/v1" # Local TTS
export TTS_VOICE="alloy" # Voice selection
# Or use voice preference files (see Configuration docs)
# Project: /your-project/voices.txt or /your-project/.voicemode/voices.txt
# User: ~/voices.txt or ~/.voicemode/voices.txt
# LiveKit (for room-based communication)
# See docs/livekit/ for setup guide
export LIVEKIT_URL="wss://your-app.livekit.cloud"
export LIVEKIT_API_KEY="your-api-key"
export LIVEKIT_API_SECRET="your-api-secret"
# Debug mode
export VOICEMODE_DEBUG="true"
# Save all audio (TTS output and STT input)
export VOICEMODE_SAVE_AUDIO="true"
# Audio format configuration (default: pcm)
export VOICEMODE_AUDIO_FORMAT="pcm" # Options: pcm, mp3, wav, flac, aac, opus
export VOICEMODE_TTS_AUDIO_FORMAT="pcm" # Override for TTS only (default: pcm)
export VOICEMODE_STT_AUDIO_FORMAT="mp3" # Override for STT upload
# Format-specific quality settings
export VOICEMODE_OPUS_BITRATE="32000" # Opus bitrate (default: 32kbps)
export VOICEMODE_MP3_BITRATE="64k" # MP3 bitrate (default: 64k)
```
### Audio Format Configuration
Voice Mode uses **PCM** audio format by default for TTS streaming for optimal real-time performance:
- **PCM** (default for TTS): Zero latency, best streaming performance, uncompressed
- **MP3**: Wide compatibility, good compression for uploads
- **WAV**: Uncompressed, good for local processing
- **FLAC**: Lossless compression, good for archival
- **AAC**: Good compression, Apple ecosystem
- **Opus**: Small files but NOT recommended for streaming (quality issues)
The audio format is automatically validated against provider capabilities and will fallback to a supported format if needed.
## Local STT/TTS Services
For privacy-focused or offline usage, Voice Mode supports local speech services:
- **[Whisper.cpp](docs/whisper.cpp.md)** - Local speech-to-text with OpenAI-compatible API
- **[Kokoro](docs/kokoro.md)** - Local text-to-speech with multiple voice options
These services provide the same API interface as OpenAI, allowing seamless switching between cloud and local processing.
### OpenAI API Compatibility Benefits
By strictly adhering to OpenAI's API standard, Voice Mode enables powerful deployment flexibility:
- **🔀 Transparent Routing**: Users can implement their own API proxies or gateways outside of Voice Mode to route requests to different providers based on custom logic (cost, latency, availability, etc.)
- **🎯 Model Selection**: Deploy routing layers that select optimal models per request without modifying Voice Mode configuration
- **💰 Cost Optimization**: Build intelligent routers that balance between expensive cloud APIs and free local models
- **🔧 No Lock-in**: Switch providers by simply changing the `BASE_URL` - no code changes required
Example: Simply set `OPENAI_BASE_URL` to point to your custom router:
```bash
export OPENAI_BASE_URL="https://router.example.com/v1"
export OPENAI_API_KEY="your-key"
# Voice Mode now uses your router for all OpenAI API calls
```
The OpenAI SDK handles this automatically - no Voice Mode configuration needed!
## Architecture
```
┌─────────────────────┐ ┌──────────────────┐ ┌─────────────────────┐
│ Claude/LLM │ │ LiveKit Server │ │ Voice Frontend │
│ (MCP Client) │◄────►│ (Optional) │◄───►│ (Optional) │
└─────────────────────┘ └──────────────────┘ └─────────────────────┘
│ │
│ │
▼ ▼
┌─────────────────────┐ ┌──────────────────┐
│ Voice MCP Server │ │ Audio Services │
│ • converse │ │ • OpenAI APIs │
│ • listen_for_speech│◄───►│ • Local Whisper │
│ • check_room_status│ │ • Local TTS │
│ • check_audio_devices └──────────────────┘
└─────────────────────┘
```
## Troubleshooting
### Common Issues
- **No microphone access**: Check system permissions for terminal/application
- **WSL2 Users**: See [WSL2 Microphone Access Guide](docs/troubleshooting/wsl2-microphone-access.md)
- **UV not found**: Install with `curl -LsSf https://astral.sh/uv/install.sh | sh`
- **OpenAI API error**: Verify your `OPENAI_API_KEY` is set correctly
- **No audio output**: Check system audio settings and available devices
### Debug Mode
Enable detailed logging and audio file saving:
```bash
export VOICEMODE_DEBUG=true
```
Debug audio files are saved to: `~/voicemode_recordings/`
### Audio Diagnostics
Run the diagnostic script to check your audio setup:
```bash
python scripts/diagnose-wsl-audio.py
```
This will check for required packages, audio services, and provide specific recommendations.
### Audio Saving
To save all audio files (both TTS output and STT input):
```bash
export VOICEMODE_SAVE_AUDIO=true
```
Audio files are saved to: `~/voicemode_audio/` with timestamps in the filename.
## Documentation
📚 **[Read the full documentation at voice-mode.readthedocs.io](https://voice-mode.readthedocs.io)**
### Getting Started
- **[Integration Guides](docs/integrations/README.md)** - Step-by-step setup for all supported tools
- **[Configuration Guide](docs/configuration.md)** - Complete environment variable reference
### Development
- **[Using uv/uvx](docs/uv.md)** - Package management with uv and uvx
- **[Local Development](docs/local-development-uvx.md)** - Development setup guide
- **[Audio Formats](docs/audio-format-migration.md)** - Audio format configuration and migration
- **[Statistics Dashboard](docs/statistics-dashboard.md)** - Performance monitoring and metrics
### Service Guides
- **[Whisper.cpp Setup](docs/whisper.cpp.md)** - Local speech-to-text configuration
- **[Kokoro Setup](docs/kokoro.md)** - Local text-to-speech configuration
- **[LiveKit Integration](docs/livekit/README.md)** - Real-time voice communication
### Troubleshooting
- **[WSL2 Microphone Access](docs/troubleshooting/wsl2-microphone-access.md)** - WSL2 audio setup
- **[Migration Guide](docs/migration-guide.md)** - Upgrading from older versions
## Links
- **Website**: [getvoicemode.com](https://getvoicemode.com)
- **Documentation**: [voice-mode.readthedocs.io](https://voice-mode.readthedocs.io)
- **GitHub**: [github.com/mbailey/voicemode](https://github.com/mbailey/voicemode)
- **PyPI**: [pypi.org/project/voice-mode](https://pypi.org/project/voice-mode/)
- **npm**: [npmjs.com/package/voicemode](https://www.npmjs.com/package/voicemode)
### Community
- **Discord**: [Join our community](https://discord.gg/Hm7dF3uCfG)
- **Twitter/X**: [@getvoicemode](https://twitter.com/getvoicemode)
- **YouTube**: [@getvoicemode](https://youtube.com/@getvoicemode)
## See Also
- 🚀 [Integration Guides](docs/integrations/README.md) - Setup instructions for all supported tools
- 🔧 [Configuration Reference](docs/configuration.md) - Environment variables and options
- 🎤 [Local Services Setup](docs/kokoro.md) - Run TTS/STT locally for privacy
- 🐛 [Troubleshooting](docs/troubleshooting/README.md) - Common issues and solutions
## License
MIT - A [Failmode](https://failmode.com) Project
---
<sub>[Project Statistics](docs/project-stats/README.md)</sub>
Raw data
{
"_id": null,
"home_page": null,
"name": "voice-mode-azure",
"maintainer": null,
"docs_url": null,
"requires_python": ">=3.10",
"maintainer_email": null,
"keywords": "ai, livekit, llm, mcp, speech, stt, tts, voice",
"author": null,
"author_email": "mbailey <mbailey@example.com>",
"download_url": "https://files.pythonhosted.org/packages/f1/46/e2edf19c84b04ec12fda711dec9639343b62e2baae169044f906143b10f1/voice_mode_azure-2.13.0.tar.gz",
"platform": null,
"description": "# Voice Mode\n\n> **Install via:** `uvx voice-mode` | `pip install voice-mode` | [getvoicemode.com](https://getvoicemode.com)\n\n[](https://pepy.tech/project/voice-mode)\n[](https://pepy.tech/project/voice-mode)\n[](https://pepy.tech/project/voice-mode)\n[](https://voice-mode.readthedocs.io/en/latest/?badge=latest)\n\nNatural voice conversations for AI assistants. Voice Mode brings human-like voice interactions to Claude, ChatGPT, and other LLMs through the Model Context Protocol (MCP).\n\n## \ud83d\udda5\ufe0f Compatibility\n\n**Runs on:** Linux \u2022 macOS \u2022 Windows (WSL) | **Python:** 3.10+\n\n## \u2728 Features\n\n- **\ud83c\udf99\ufe0f Voice conversations** with Claude - ask questions and hear responses\n- **\ud83d\udd04 Multiple transports** - local microphone or LiveKit room-based communication \n- **\ud83d\udde3\ufe0f OpenAI-compatible** - works with any STT/TTS service (local or cloud)\n- **\u26a1 Real-time** - low-latency voice interactions with automatic transport selection\n- **\ud83d\udd27 MCP Integration** - seamless with Claude Desktop and other MCP clients\n- **\ud83c\udfaf Silence detection** - automatically stops recording when you stop speaking (no more waiting!)\n\n## \ud83c\udfaf Simple Requirements\n\n**All you need to get started:**\n\n1. **\ud83d\udd11 OpenAI API Key** (or compatible service) - for speech-to-text and text-to-speech\n2. **\ud83c\udfa4 Computer with microphone and speakers** OR **\u2601\ufe0f LiveKit server** ([LiveKit Cloud](https://docs.livekit.io/home/cloud/) or [self-hosted](https://github.com/livekit/livekit))\n\n## Quick Start\n\n> \ud83d\udcd6 **Using a different tool?** See our [Integration Guides](docs/integrations/README.md) for Cursor, VS Code, Gemini CLI, and more!\n\n```bash\nnpm install -g @anthropic-ai/claude-code\ncurl -LsSf https://astral.sh/uv/install.sh | sh\nclaude mcp add --scope user voice-mode uvx voice-mode\nexport OPENAI_API_KEY=your-openai-key\nclaude converse\n```\n\n## \ud83c\udfac Demo\n\nWatch Voice Mode in action with Claude Code:\n\n[](https://www.youtube.com/watch?v=cYdwOD_-dQc)\n\n### Voice Mode with Gemini CLI\n\nSee Voice Mode working with Google's Gemini CLI (their implementation of Claude Code):\n\n[](https://www.youtube.com/watch?v=HC6BGxjCVnM)\n\n## Example Usage\n\nOnce configured, try these prompts with Claude:\n\n### \ud83d\udc68\u200d\ud83d\udcbb Programming & Development\n- `\"Let's debug this error together\"` - Explain the issue verbally, paste code, and discuss solutions\n- `\"Walk me through this code\"` - Have Claude explain complex code while you ask questions\n- `\"Let's brainstorm the architecture\"` - Design systems through natural conversation\n- `\"Help me write tests for this function\"` - Describe requirements and iterate verbally\n\n### \ud83d\udca1 General Productivity \n- `\"Let's do a daily standup\"` - Practice presentations or organize your thoughts\n- `\"Interview me about [topic]\"` - Prepare for interviews with back-and-forth Q&A\n- `\"Be my rubber duck\"` - Explain problems out loud to find solutions\n\n### \ud83c\udfaf Voice Control Features\n- `\"Read this error message\"` (Claude speaks, then waits for your response)\n- `\"Just give me a quick summary\"` (Claude speaks without waiting)\n- Use `converse(\"message\", wait_for_response=False)` for one-way announcements\n\nThe `converse` function makes voice interactions natural - it automatically waits for your response by default, creating a real conversation flow.\n\n## Supported Tools\n\nVoice Mode works with your favorite AI coding assistants:\n\n- \ud83e\udd16 **[Claude Code](docs/integrations/claude-code/README.md)** - Anthropic's official CLI\n- \ud83d\udda5\ufe0f **[Claude Desktop](docs/integrations/claude-desktop/README.md)** - Desktop application\n- \ud83c\udf1f **[Gemini CLI](docs/integrations/gemini-cli/README.md)** - Google's CLI tool\n- \u26a1 **[Cursor](docs/integrations/cursor/README.md)** - AI-first code editor\n- \ud83d\udcbb **[VS Code](docs/integrations/vscode/README.md)** - With MCP preview support\n- \ud83e\udd98 **[Roo Code](docs/integrations/roo-code/README.md)** - AI dev team in VS Code\n- \ud83d\udd27 **[Cline](docs/integrations/cline/README.md)** - Autonomous coding agent\n- \u26a1 **[Zed](docs/integrations/zed/README.md)** - High-performance editor\n- \ud83c\udfc4 **[Windsurf](docs/integrations/windsurf/README.md)** - Agentic IDE by Codeium\n- \ud83d\udd04 **[Continue](docs/integrations/continue/README.md)** - Open-source AI assistant\n\n## Installation\n\n### Prerequisites\n- Python >= 3.10\n- [Astral UV](https://github.com/astral-sh/uv) - Package manager (install with `curl -LsSf https://astral.sh/uv/install.sh | sh`)\n- OpenAI API Key (or compatible service)\n\n#### System Dependencies\n\n<details>\n<summary><strong>Ubuntu/Debian</strong></summary>\n\n```bash\nsudo apt update\nsudo apt install -y python3-dev libasound2-dev libasound2-plugins libportaudio2 portaudio19-dev ffmpeg pulseaudio pulseaudio-utils\n```\n\n**Note for WSL2 users**: WSL2 requires additional audio packages (pulseaudio, libasound2-plugins) for microphone access. See our [WSL2 Microphone Access Guide](docs/troubleshooting/wsl2-microphone-access.md) if you encounter issues.\n</details>\n\n<details>\n<summary><strong>Fedora/RHEL</strong></summary>\n\n```bash\nsudo dnf install python3-devel alsa-lib-devel portaudio-devel ffmpeg\n```\n</details>\n\n<details>\n<summary><strong>macOS</strong></summary>\n\n```bash\n# Install Homebrew if not already installed\n/bin/bash -c \"$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)\"\n\n# Install dependencies\nbrew install portaudio ffmpeg\n```\n</details>\n\n<details>\n<summary><strong>Windows (WSL)</strong></summary>\n\nFollow the Ubuntu/Debian instructions above within WSL.\n</details>\n\n### Quick Install\n\n```bash\n# Using Claude Code (recommended)\nclaude mcp add --scope user voice-mode uvx voice-mode\n\n# Using UV\nuvx voice-mode\n\n# Using pip\npip install voice-mode\n```\n\n### Configuration for AI Coding Assistants\n\n> \ud83d\udcd6 **Looking for detailed setup instructions?** Check our comprehensive [Integration Guides](docs/integrations/README.md) for step-by-step instructions for each tool!\n\nBelow are quick configuration snippets. For full installation and setup instructions, see the integration guides above.\n\n<details>\n<summary><strong>Claude Code (CLI)</strong></summary>\n\n```bash\nclaude mcp add voice-mode -- uvx voice-mode\n```\n\nOr with environment variables:\n```bash\nclaude mcp add voice-mode --env OPENAI_API_KEY=your-openai-key -- uvx voice-mode\n```\n</details>\n\n<details>\n<summary><strong>Claude Desktop</strong></summary>\n\n**macOS**: `~/Library/Application Support/Claude/claude_desktop_config.json` \n**Windows**: `%APPDATA%\\Claude\\claude_desktop_config.json`\n\n```json\n{\n \"mcpServers\": {\n \"voice-mode\": {\n \"command\": \"uvx\",\n \"args\": [\"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n}\n```\n</details>\n\n<details>\n<summary><strong>Cline</strong></summary>\n\nAdd to your Cline MCP settings:\n\n**Windows**:\n```json\n{\n \"mcpServers\": {\n \"voice-mode\": {\n \"command\": \"cmd\",\n \"args\": [\"/c\", \"uvx\", \"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n}\n```\n\n**macOS/Linux**:\n```json\n{\n \"mcpServers\": {\n \"voice-mode\": {\n \"command\": \"uvx\",\n \"args\": [\"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n}\n```\n</details>\n\n<details>\n<summary><strong>Continue</strong></summary>\n\nAdd to your `.continue/config.json`:\n```json\n{\n \"experimental\": {\n \"modelContextProtocolServers\": [\n {\n \"transport\": {\n \"type\": \"stdio\",\n \"command\": \"uvx\",\n \"args\": [\"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n ]\n }\n}\n```\n</details>\n\n<details>\n<summary><strong>Cursor</strong></summary>\n\nAdd to `~/.cursor/mcp.json`:\n```json\n{\n \"mcpServers\": {\n \"voice-mode\": {\n \"command\": \"uvx\",\n \"args\": [\"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n}\n```\n</details>\n\n<details>\n<summary><strong>VS Code</strong></summary>\n\nAdd to your VS Code MCP config:\n```json\n{\n \"mcpServers\": {\n \"voice-mode\": {\n \"command\": \"uvx\",\n \"args\": [\"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n}\n```\n</details>\n\n<details>\n<summary><strong>Windsurf</strong></summary>\n\n```json\n{\n \"mcpServers\": {\n \"voice-mode\": {\n \"command\": \"uvx\",\n \"args\": [\"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n}\n```\n</details>\n\n<details>\n<summary><strong>Zed</strong></summary>\n\nAdd to your Zed settings.json:\n```json\n{\n \"context_servers\": {\n \"voice-mode\": {\n \"command\": {\n \"path\": \"uvx\",\n \"args\": [\"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n }\n}\n```\n</details>\n\n<details>\n<summary><strong>Roo Code</strong></summary>\n\n1. Open VS Code Settings (`Ctrl/Cmd + ,`)\n2. Search for \"roo\" in the settings search bar\n3. Find \"Roo-veterinaryinc.roo-cline \u2192 settings \u2192 Mcp_settings.json\"\n4. Click \"Edit in settings.json\"\n5. Add Voice Mode configuration:\n\n```json\n{\n \"mcpServers\": {\n \"voice-mode\": {\n \"command\": \"uvx\",\n \"args\": [\"voice-mode\"],\n \"env\": {\n \"OPENAI_API_KEY\": \"your-openai-key\"\n }\n }\n }\n}\n```\n</details>\n\n### Alternative Installation Options\n\n<details>\n<summary><strong>Using Docker</strong></summary>\n\n```bash\ndocker run -it --rm \\\n -e OPENAI_API_KEY=your-openai-key \\\n --device /dev/snd \\\n -v /tmp/.X11-unix:/tmp/.X11-unix \\\n -e DISPLAY=$DISPLAY \\\n ghcr.io/mbailey/voicemode:latest\n```\n</details>\n\n<details>\n<summary><strong>Using pipx</strong></summary>\n\n```bash\npipx install voice-mode\n```\n</details>\n\n<details>\n<summary><strong>From source</strong></summary>\n\n```bash\ngit clone https://github.com/mbailey/voicemode.git\ncd voicemode\npip install -e .\n```\n</details>\n\n## Tools\n\n| Tool | Description | Key Parameters |\n|------|-------------|----------------|\n| `converse` | Have a voice conversation - speak and optionally listen | `message`, `wait_for_response` (default: true), `listen_duration` (default: 30s), `transport` (auto/local/livekit) |\n| `listen_for_speech` | Listen for speech and convert to text | `duration` (default: 5s) |\n| `check_room_status` | Check LiveKit room status and participants | None |\n| `check_audio_devices` | List available audio input/output devices | None |\n| `start_kokoro` | Start the Kokoro TTS service | `models_dir` (optional, defaults to ~/Models/kokoro) |\n| `stop_kokoro` | Stop the Kokoro TTS service | None |\n| `kokoro_status` | Check the status of Kokoro TTS service | None |\n\n**Note:** The `converse` tool is the primary interface for voice interactions, combining speaking and listening in a natural flow.\n\n## Configuration\n\n- \ud83d\udcd6 **[Integration Guides](docs/integrations/README.md)** - Step-by-step setup for each tool\n- \ud83d\udd27 **[Configuration Reference](docs/configuration.md)** - All environment variables\n- \ud83d\udcc1 **[Config Examples](config-examples/)** - Ready-to-use configuration files\n\n### Quick Setup\n\nThe only required configuration is your OpenAI API key:\n\n```bash\nexport OPENAI_API_KEY=\"your-key\"\n```\n\n### Optional Settings\n\n```bash\n# Custom STT/TTS services (OpenAI-compatible)\nexport STT_BASE_URL=\"http://127.0.0.1:2022/v1\" # Local Whisper\nexport TTS_BASE_URL=\"http://127.0.0.1:8880/v1\" # Local TTS\nexport TTS_VOICE=\"alloy\" # Voice selection\n\n# Or use voice preference files (see Configuration docs)\n# Project: /your-project/voices.txt or /your-project/.voicemode/voices.txt\n# User: ~/voices.txt or ~/.voicemode/voices.txt\n\n# LiveKit (for room-based communication)\n# See docs/livekit/ for setup guide\nexport LIVEKIT_URL=\"wss://your-app.livekit.cloud\"\nexport LIVEKIT_API_KEY=\"your-api-key\"\nexport LIVEKIT_API_SECRET=\"your-api-secret\"\n\n# Debug mode\nexport VOICEMODE_DEBUG=\"true\"\n\n# Save all audio (TTS output and STT input)\nexport VOICEMODE_SAVE_AUDIO=\"true\"\n\n# Audio format configuration (default: pcm)\nexport VOICEMODE_AUDIO_FORMAT=\"pcm\" # Options: pcm, mp3, wav, flac, aac, opus\nexport VOICEMODE_TTS_AUDIO_FORMAT=\"pcm\" # Override for TTS only (default: pcm)\nexport VOICEMODE_STT_AUDIO_FORMAT=\"mp3\" # Override for STT upload\n\n# Format-specific quality settings\nexport VOICEMODE_OPUS_BITRATE=\"32000\" # Opus bitrate (default: 32kbps)\nexport VOICEMODE_MP3_BITRATE=\"64k\" # MP3 bitrate (default: 64k)\n```\n\n### Audio Format Configuration\n\nVoice Mode uses **PCM** audio format by default for TTS streaming for optimal real-time performance:\n\n- **PCM** (default for TTS): Zero latency, best streaming performance, uncompressed\n- **MP3**: Wide compatibility, good compression for uploads\n- **WAV**: Uncompressed, good for local processing\n- **FLAC**: Lossless compression, good for archival\n- **AAC**: Good compression, Apple ecosystem\n- **Opus**: Small files but NOT recommended for streaming (quality issues)\n\nThe audio format is automatically validated against provider capabilities and will fallback to a supported format if needed.\n\n## Local STT/TTS Services\n\nFor privacy-focused or offline usage, Voice Mode supports local speech services:\n\n- **[Whisper.cpp](docs/whisper.cpp.md)** - Local speech-to-text with OpenAI-compatible API\n- **[Kokoro](docs/kokoro.md)** - Local text-to-speech with multiple voice options\n\nThese services provide the same API interface as OpenAI, allowing seamless switching between cloud and local processing.\n\n### OpenAI API Compatibility Benefits\n\nBy strictly adhering to OpenAI's API standard, Voice Mode enables powerful deployment flexibility:\n\n- **\ud83d\udd00 Transparent Routing**: Users can implement their own API proxies or gateways outside of Voice Mode to route requests to different providers based on custom logic (cost, latency, availability, etc.)\n- **\ud83c\udfaf Model Selection**: Deploy routing layers that select optimal models per request without modifying Voice Mode configuration\n- **\ud83d\udcb0 Cost Optimization**: Build intelligent routers that balance between expensive cloud APIs and free local models\n- **\ud83d\udd27 No Lock-in**: Switch providers by simply changing the `BASE_URL` - no code changes required\n\nExample: Simply set `OPENAI_BASE_URL` to point to your custom router:\n```bash\nexport OPENAI_BASE_URL=\"https://router.example.com/v1\"\nexport OPENAI_API_KEY=\"your-key\"\n# Voice Mode now uses your router for all OpenAI API calls\n```\n\nThe OpenAI SDK handles this automatically - no Voice Mode configuration needed!\n\n## Architecture\n\n```\n\u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2510 \u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2510 \u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2510\n\u2502 Claude/LLM \u2502 \u2502 LiveKit Server \u2502 \u2502 Voice Frontend \u2502\n\u2502 (MCP Client) \u2502\u25c4\u2500\u2500\u2500\u2500\u25ba\u2502 (Optional) \u2502\u25c4\u2500\u2500\u2500\u25ba\u2502 (Optional) \u2502\n\u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2518 \u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2518 \u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2518\n \u2502 \u2502\n \u2502 \u2502\n \u25bc \u25bc\n\u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2510 \u250c\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2510\n\u2502 Voice MCP Server \u2502 \u2502 Audio Services \u2502\n\u2502 \u2022 converse \u2502 \u2502 \u2022 OpenAI APIs \u2502\n\u2502 \u2022 listen_for_speech\u2502\u25c4\u2500\u2500\u2500\u25ba\u2502 \u2022 Local Whisper \u2502\n\u2502 \u2022 check_room_status\u2502 \u2502 \u2022 Local TTS \u2502\n\u2502 \u2022 check_audio_devices \u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2518\n\u2514\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2518\n```\n\n## Troubleshooting\n\n### Common Issues\n\n- **No microphone access**: Check system permissions for terminal/application\n - **WSL2 Users**: See [WSL2 Microphone Access Guide](docs/troubleshooting/wsl2-microphone-access.md)\n- **UV not found**: Install with `curl -LsSf https://astral.sh/uv/install.sh | sh`\n- **OpenAI API error**: Verify your `OPENAI_API_KEY` is set correctly\n- **No audio output**: Check system audio settings and available devices\n\n### Debug Mode\n\nEnable detailed logging and audio file saving:\n\n```bash\nexport VOICEMODE_DEBUG=true\n```\n\nDebug audio files are saved to: `~/voicemode_recordings/`\n\n### Audio Diagnostics\n\nRun the diagnostic script to check your audio setup:\n\n```bash\npython scripts/diagnose-wsl-audio.py\n```\n\nThis will check for required packages, audio services, and provide specific recommendations.\n\n### Audio Saving\n\nTo save all audio files (both TTS output and STT input):\n\n```bash\nexport VOICEMODE_SAVE_AUDIO=true\n```\n\nAudio files are saved to: `~/voicemode_audio/` with timestamps in the filename.\n\n## Documentation\n\n\ud83d\udcda **[Read the full documentation at voice-mode.readthedocs.io](https://voice-mode.readthedocs.io)**\n\n### Getting Started\n- **[Integration Guides](docs/integrations/README.md)** - Step-by-step setup for all supported tools\n- **[Configuration Guide](docs/configuration.md)** - Complete environment variable reference\n\n### Development\n- **[Using uv/uvx](docs/uv.md)** - Package management with uv and uvx\n- **[Local Development](docs/local-development-uvx.md)** - Development setup guide\n- **[Audio Formats](docs/audio-format-migration.md)** - Audio format configuration and migration\n- **[Statistics Dashboard](docs/statistics-dashboard.md)** - Performance monitoring and metrics\n\n### Service Guides\n- **[Whisper.cpp Setup](docs/whisper.cpp.md)** - Local speech-to-text configuration\n- **[Kokoro Setup](docs/kokoro.md)** - Local text-to-speech configuration\n- **[LiveKit Integration](docs/livekit/README.md)** - Real-time voice communication\n\n### Troubleshooting\n- **[WSL2 Microphone Access](docs/troubleshooting/wsl2-microphone-access.md)** - WSL2 audio setup\n- **[Migration Guide](docs/migration-guide.md)** - Upgrading from older versions\n\n## Links\n\n- **Website**: [getvoicemode.com](https://getvoicemode.com)\n- **Documentation**: [voice-mode.readthedocs.io](https://voice-mode.readthedocs.io)\n- **GitHub**: [github.com/mbailey/voicemode](https://github.com/mbailey/voicemode)\n- **PyPI**: [pypi.org/project/voice-mode](https://pypi.org/project/voice-mode/)\n- **npm**: [npmjs.com/package/voicemode](https://www.npmjs.com/package/voicemode)\n\n### Community\n\n- **Discord**: [Join our community](https://discord.gg/Hm7dF3uCfG)\n- **Twitter/X**: [@getvoicemode](https://twitter.com/getvoicemode)\n- **YouTube**: [@getvoicemode](https://youtube.com/@getvoicemode)\n\n## See Also\n\n- \ud83d\ude80 [Integration Guides](docs/integrations/README.md) - Setup instructions for all supported tools\n- \ud83d\udd27 [Configuration Reference](docs/configuration.md) - Environment variables and options\n- \ud83c\udfa4 [Local Services Setup](docs/kokoro.md) - Run TTS/STT locally for privacy\n- \ud83d\udc1b [Troubleshooting](docs/troubleshooting/README.md) - Common issues and solutions\n\n## License\n\nMIT - A [Failmode](https://failmode.com) Project\n\n---\n\n<sub>[Project Statistics](docs/project-stats/README.md)</sub>\n",
"bugtrack_url": null,
"license": "MIT",
"summary": "VoiceMode with Azure OpenAI support - Voice interaction capabilities for AI assistants",
"version": "2.13.0",
"project_urls": {
"Homepage": "https://github.com/mbailey/voicemode",
"Issues": "https://github.com/mbailey/voicemode/issues",
"Repository": "https://github.com/mbailey/voicemode"
},
"split_keywords": [
"ai",
" livekit",
" llm",
" mcp",
" speech",
" stt",
" tts",
" voice"
],
"urls": [
{
"comment_text": null,
"digests": {
"blake2b_256": "466471d80e6a7fa93a49d4b41c7aa09474daaedab82fd1506e77daa083e7ce43",
"md5": "6a4b16bd2504577796032cc72a5bdc55",
"sha256": "0815d383fd831fbf1e6b5d5e2bab95e47ca086eb9f8e31efa77c0c199cedcc1c"
},
"downloads": -1,
"filename": "voice_mode_azure-2.13.0-py3-none-any.whl",
"has_sig": false,
"md5_digest": "6a4b16bd2504577796032cc72a5bdc55",
"packagetype": "bdist_wheel",
"python_version": "py3",
"requires_python": ">=3.10",
"size": 96927,
"upload_time": "2025-07-13T01:42:07",
"upload_time_iso_8601": "2025-07-13T01:42:07.411395Z",
"url": "https://files.pythonhosted.org/packages/46/64/71d80e6a7fa93a49d4b41c7aa09474daaedab82fd1506e77daa083e7ce43/voice_mode_azure-2.13.0-py3-none-any.whl",
"yanked": false,
"yanked_reason": null
},
{
"comment_text": null,
"digests": {
"blake2b_256": "f146e2edf19c84b04ec12fda711dec9639343b62e2baae169044f906143b10f1",
"md5": "ea575e4674883a252bab5ac725b8f72a",
"sha256": "0b0f99fc54ce84f2db4fee1c1b2bdd4ba0722e63769c66e531ca16eb82fc0426"
},
"downloads": -1,
"filename": "voice_mode_azure-2.13.0.tar.gz",
"has_sig": false,
"md5_digest": "ea575e4674883a252bab5ac725b8f72a",
"packagetype": "sdist",
"python_version": "source",
"requires_python": ">=3.10",
"size": 89139,
"upload_time": "2025-07-13T01:42:09",
"upload_time_iso_8601": "2025-07-13T01:42:09.150040Z",
"url": "https://files.pythonhosted.org/packages/f1/46/e2edf19c84b04ec12fda711dec9639343b62e2baae169044f906143b10f1/voice_mode_azure-2.13.0.tar.gz",
"yanked": false,
"yanked_reason": null
}
],
"upload_time": "2025-07-13 01:42:09",
"github": true,
"gitlab": false,
"bitbucket": false,
"codeberg": false,
"github_user": "mbailey",
"github_project": "voicemode",
"travis_ci": false,
"coveralls": false,
"github_actions": true,
"lcname": "voice-mode-azure"
}
